Come accelerare il flusso di dati tra Databricks e SAS
di Oleg Mikhov e Satish Garla
Questo è un post collaborativo tra Databricks e T1A. Ringraziamo Oleg Mikhov, Solutions Architect presso T1A, per il suo contributo.
Questo è il primo post di una serie di blog sulle best practice per unire la Databricks Lakehouse Platform e SAS. Un precedente post di Databricks ha introdotto Databricks e PySpark agli sviluppatori SAS. In questo post, discutiamo i modi per scambiare dati tra la Databricks Lakehouse Platform e SAS e i modi per velocizzare il flusso di dati. Nei post futuri, esploreremo la creazione di pipeline di dati e analytics efficienti che coinvolgono entrambe le tecnologie.
Le organizzazioni data-driven stanno adottando rapidamente la piattaforma Lakehouse per tenere il passo con le crescenti esigenze aziendali. La piattaforma Lakehouse è diventata la nuova normalità per le organizzazioni che desiderano costruire piattaforme e architetture dati. La modernizzazione implica lo spostamento di dati, applicazioni o altri elementi aziendali nel cloud. Tuttavia, la transizione al cloud è un processo graduale ed è di importanza critica per il business continuare a sfruttare gli investimenti legacy il più a lungo possibile. Con questo in mente, molte aziende tendono ad avere più piattaforme dati e analytics, dove le piattaforme coesistono e si completano a vicenda.
Una delle combinazioni che vediamo è l'uso di SAS con la Databricks Lakehouse. Ci sono molti vantaggi nell'abilitare le due piattaforme a lavorare insieme in modo efficiente, come:
- Capacità di archiviazione dati maggiori e scalabili delle piattaforme cloud
- Maggiore capacità di calcolo utilizzando tecnologie come Apache Spark™, costruite nativamente con capacità di elaborazione parallela
- Raggiungere una maggiore conformità con la governance e la gestione dei dati utilizzando Delta Lake
- Ridurre il costo dell'infrastruttura di analisi dei dati con architetture semplificate
Alcuni casi d'uso e motivi comuni di data science e data analysis osservati sono:
- I professionisti SAS sfruttano SAS per i suoi pacchetti statistici principali per sviluppare output di analisi avanzate che soddisfano i requisiti normativi, mentre utilizzano Databricks Lakehouse per la gestione dei dati, l'elaborazione di tipo ELT e la governance dei dati
- I modelli di machine learning sviluppati in SAS vengono valutati su enormi quantità di dati utilizzando l'architettura di elaborazione parallela del motore Apache Spark nella piattaforma Lakehouse
- I data analyst SAS ottengono un accesso più rapido a grandi quantità di dati nella Lakehouse Platform per analisi ad hoc e reporting utilizzando gli endpoint Databricks SQL e i connettori ad alta larghezza di banda
- Semplificare il percorso di modernizzazione e migrazione al cloud stabilendo un flusso di lavoro ibrido che coinvolge sia l'architettura cloud che la piattaforma SAS on-premise
Tuttavia, una sfida chiave di questa coesistenza è come i dati vengono condivisi in modo performante tra le due piattaforme. In questo blog, condividiamo le best practice implementate da T1A per i propri clienti e i risultati dei benchmark che confrontano diversi metodi di spostamento dei dati tra Databricks e SAS.
Scenari
Il caso d'uso più popolare è uno sviluppatore SAS che cerca di accedere ai dati nel lakehouse. Le pipeline di analisi che coinvolgono entrambe le tecnologie richiedono flussi di dati in entrambe le direzioni: dati spostati da Databricks a SAS e dati spostati da SAS a Databricks.
- Accedere a Delta Lake da SAS: Un utente SAS vuole accedere a big data in Delta Lake utilizzando il linguaggio di programmazione SAS.
- Accedere ai dataset SAS da Databricks: Un utente Databricks vuole accedere ai dataset SAS, generalmente i dataset sas7bdat, come DataFrame per elaborarli nelle pipeline Databricks o archiviarli in Delta Lake per l'accesso a livello aziendale.
Nei nostri test di benchmark, abbiamo utilizzato la seguente configurazione dell'ambiente:
- Microsoft Azure come piattaforma cloud
- SAS 9.4M7 su Azure (VM Standard D8s v3 a nodo singolo)
- Databricks runtime 9.0, Apache Spark 3.1.2 (cluster Standard DS4v2 a 2 nodi)
La Figura 1 mostra il diagramma concettuale dell'architettura con i componenti discussi. Databricks Lakehouse risiede sullo storage Azure Data Lake con architettura a medaglione Delta Lake. SAS 9.4 installato su Azure VM si connette a Databricks Lakehouse per leggere/scrivere dati utilizzando le opzioni di connessione discusse nelle sezioni seguenti.
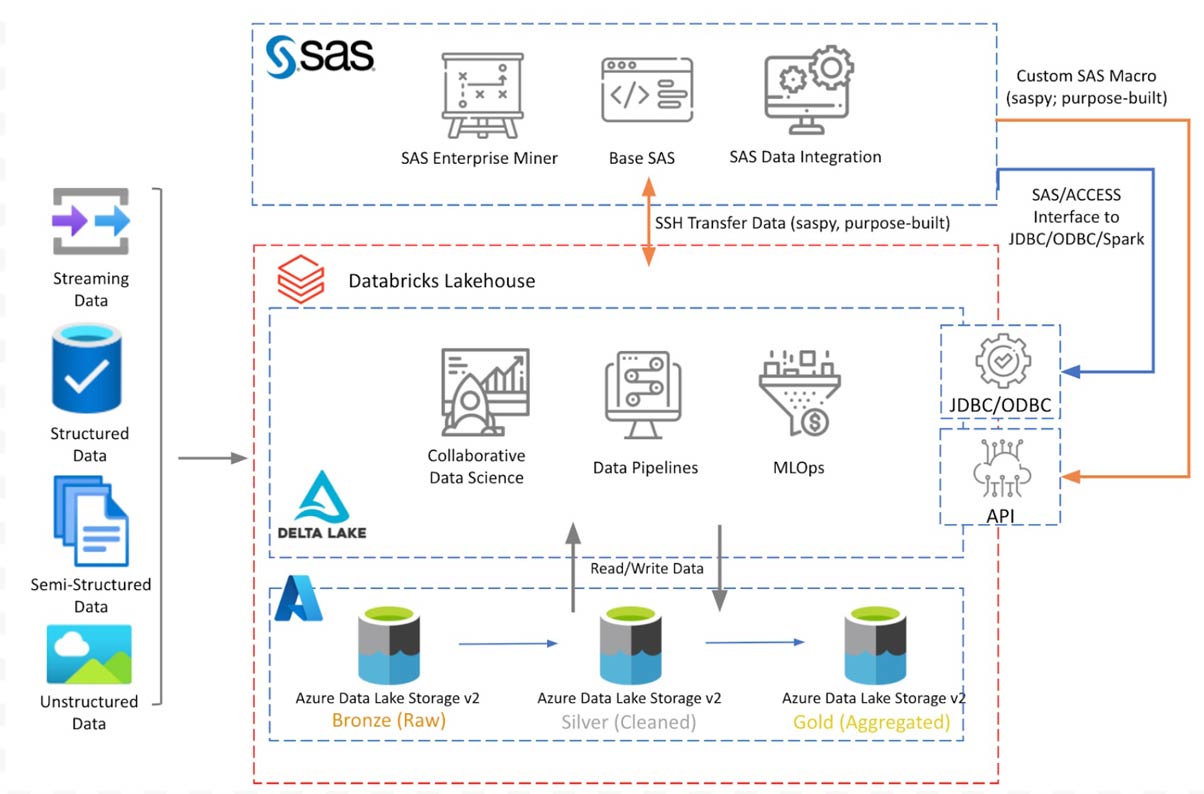
Il diagramma sopra mostra un'architettura concettuale di Databricks distribuito su Azure. L'architettura sarà simile su altre piattaforme cloud. In questo blog, discutiamo solo l'integrazione con la piattaforma SAS 9.4. In un post successivo, estenderemo questa discussione all'accesso ai dati del lakehouse da SAS Viya.
Accedere a Delta Lake da SAS
Immagina di avere una tabella Delta Lake che deve essere elaborata in un programma SAS. Vogliamo le migliori prestazioni nell'accesso a questa tabella, evitando al contempo eventuali problemi di compatibilità con l'integrità dei dati o i tipi di dati. Esistono diversi modi per ottenere integrità e compatibilità dei dati. Di seguito discutiamo alcuni metodi e li confrontiamo per facilità d'uso e prestazioni.
Nei nostri test, abbiamo utilizzato il set di dati sul comportamento eCommerce (5,67 GB, 9 colonne, ~ 42 milioni di record) da Kaggle.
Crediti fonte dati: Dati sul comportamento eCommerce da un negozio multi-categoria e REES46 Marketing Platform.
Metodi testati
1. Utilizzo dei connettori SAS/ACCESS Interface
Tradizionalmente, gli utenti SAS sfruttano il software SAS/ACCESS per connettersi a origini dati esterne. È possibile utilizzare un'istruzione SAS LIBNAME che punta al cluster Databricks o utilizzare la funzionalità SQL pass-through. Attualmente, per SAS 9.4, sono disponibili tre opzioni di connessione.
SAS/ACCESS Interface a Spark è stato recentemente caricato con funzionalità con supporto esclusivo per i cluster Databricks. Vedere questo video per una breve dimostrazione. Il video menziona SAS Viya ma lo stesso è applicabile a SAS 9.4.
Esempi di codice su come utilizzare questi connettori si trovano in questo repository git: T1A Git - Esempi di librerie SAS.
2. Utilizzo del pacchetto saspy
La libreria open-source, saspy, di SAS Institute consente agli utenti di Databricks Notebook di eseguire istruzioni SAS da una cella Python nel notebook per eseguire codice sul server SAS, nonché per importare ed esportare dati da dataset SAS a Pandas DataFrame.
Poiché l'obiettivo di questa sezione è l'accesso ai dati del lakehouse da parte di un programmatore SAS utilizzando la programmazione SAS, questo metodo è stato incapsulato in un programma macro SAS simile al metodo di integrazione dedicato discusso successivamente.
Per ottenere prestazioni migliori con questo pacchetto, abbiamo testato la configurazione con un'opzione char_length definita (dettagli disponibili qui). Con questa opzione, possiamo definire le lunghezze dei campi carattere nel dataset. Nei nostri test, l'uso di questa opzione ha portato un ulteriore aumento del 15% delle prestazioni. Per il trasporto tra ambienti, abbiamo utilizzato la configurazione saspy con una connessione SSH al server SAS.
3. Utilizzo di un'integrazione dedicata
Sebbene i due metodi sopra menzionati abbiano i loro vantaggi, le prestazioni possono essere ulteriormente migliorate affrontando alcune carenze, discusse nella sezione successiva (Risultati dei test), dei metodi precedenti. Con questo in mente, abbiamo sviluppato un'utility di integrazione basata su macro SAS con un focus primario sulle prestazioni e sull'usabilità per gli utenti SAS. La macro SAS può essere facilmente integrata nel codice SAS esistente senza alcuna conoscenza della piattaforma Databricks, Apache Spark o Python.
La macro orchestra un processo multi-fase utilizzando l'API Databricks:
- Istruisci il cluster Databricks a interrogare ed estrarre dati in base alla query SQL fornita e a memorizzare nella cache i risultati in DBFS, sfruttando le sue capacità di elaborazione distribuita Spark SQL.
- Comprimi e trasferisci in modo sicuro il dataset al server SAS (CSV in GZIP) tramite SSH
- Decomprimi e importa i dati in SAS per renderli disponibili all'utente nella libreria SAS. In questo passaggio, sfrutta i metadati delle colonne dal catalogo dati Databricks (tipi di colonna, lunghezze e formati) per una presentazione dei dati coerente, corretta ed efficiente in SAS
Nota che per i tipi di dati a lunghezza variabile, l'integrazione supporta diverse opzioni di configurazione, a seconda di ciò che meglio si adatta ai requisiti dell'utente, come ad esempio:
- necessità di utilizzare un valore predefinito configurabile
- profilazione fino a 10.000 righe (+ aggiunta di margine) per identificare il valore più grande
- profilazione dell'intera colonna nel dataset per identificare il valore più grande
Una versione semplificata del codice è disponibile qui T1A Git - SAS DBR Custom Integration.
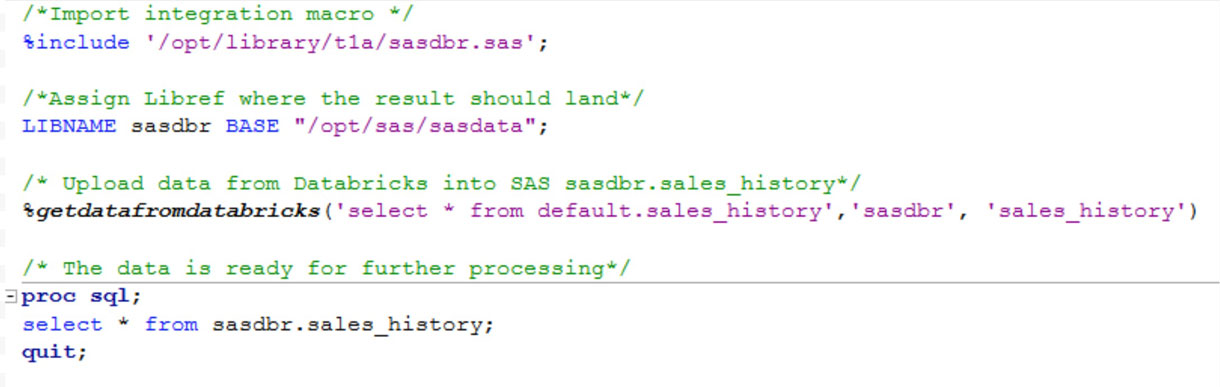
L'utilizzo da parte dell'utente finale di questa macro SAS appare come mostrato di seguito e richiede tre input:
- Query SQL, in base alla quale i dati verranno estratti da Databricks
- Libref SAS in cui i dati devono essere archiviati
- Nome da assegnare al dataset SAS
Risultati del test
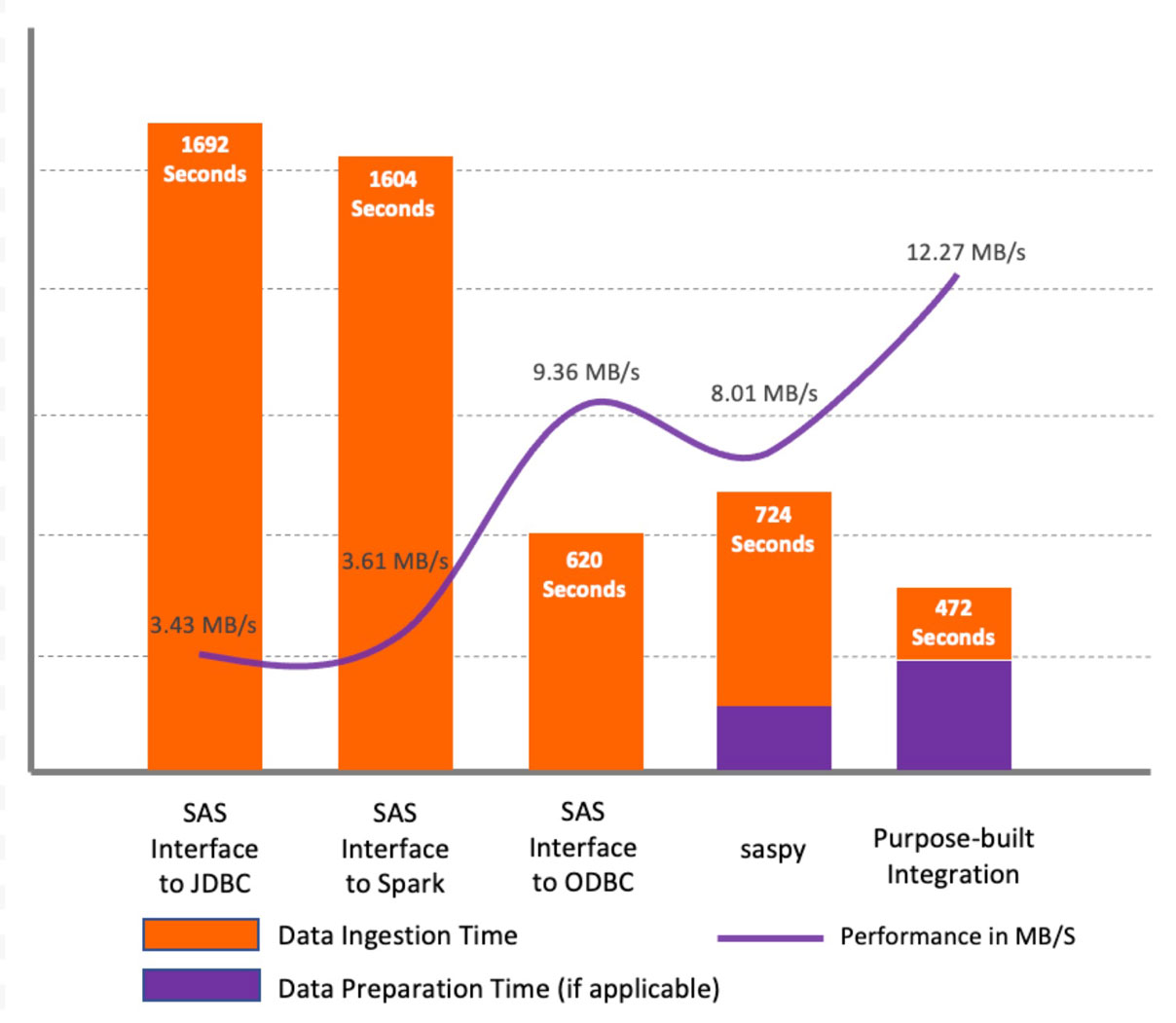
Come mostrato nel grafico sopra, per il dataset di test, i risultati indicano che SAS/ACCESS Interface to JDBC e SAS/ACCESS Interface to Apache Spark hanno mostrato prestazioni simili e inferiori rispetto ad altri metodi. Il motivo principale è che i metodi JDBC non profilano le colonne carattere nei dataset per impostare una lunghezza di colonna corretta nel dataset SAS. Invece, definiscono la lunghezza predefinita per tutti i tipi di colonna carattere (String e Varchar) come 765 simboli. Ciò causa non solo problemi di prestazioni durante il recupero iniziale dei dati, ma anche per tutte le elaborazioni successive. Inoltre, consuma spazio di archiviazione aggiuntivo significativo. Nei nostri test, per il dataset di origine di 5,6 GB, abbiamo finito con un file da 216 GB nella libreria WORK. Tuttavia, con SAS/ACCESS Interface to ODBC, la lunghezza predefinita era di 255 simboli, il che ha comportato un aumento significativo delle prestazioni.
L'utilizzo dei metodi SAS/ACCESS Interface è l'opzione più conveniente per gli utenti SAS esistenti. Ci sono alcune considerazioni importanti quando si utilizzano questi metodi
- Entrambe le soluzioni supportano il pass-through implicito delle query ma con alcune limitazioni:
- SAS/ACCESS Interface to JDBC/ODBC supporta solo il pass-through per le istruzioni PROC SQL
- Oltre al pass-through di PROC SQL, SAS/ACCESS Interface to Apache Spark supporta il pass-through per la maggior parte delle funzioni SQL. Questo metodo consente anche di inviare procedure SAS comuni ai cluster Databricks.
- Il problema con l'impostazione della lunghezza per le colonne carattere descritto in precedenza. Come soluzione alternativa, suggeriamo di utilizzare l'opzione DBSASTYPE per impostare esplicitamente la lunghezza della colonna per le tabelle SAS. Ciò aiuterà nell'ulteriore elaborazione del dataset, ma non influenzerà il recupero iniziale dei dati da Databricks
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC non consente di combinare tabelle da diversi database Databricks (schemi) assegnati come libref diversi nella stessa query (unendoli) con la funzionalità di pass-through. Invece, causerà l'esportazione di intere tabelle in SAS e l'elaborazione in SAS. Come soluzione alternativa, suggeriamo di creare uno schema dedicato in Databricks che conterrà viste basate su tabelle di database (schemi) diversi.
L'utilizzo del metodo saspy ha mostrato prestazioni leggermente migliori rispetto ai metodi SAS/ACCESS Interface to JDBC/Spark, tuttavia, il principale svantaggio è che la libreria saspy funziona solo con DataFrame pandas e mette un carico significativo sul programma driver Apache Spark e richiede che l'intero DataFrame venga caricato in memoria.
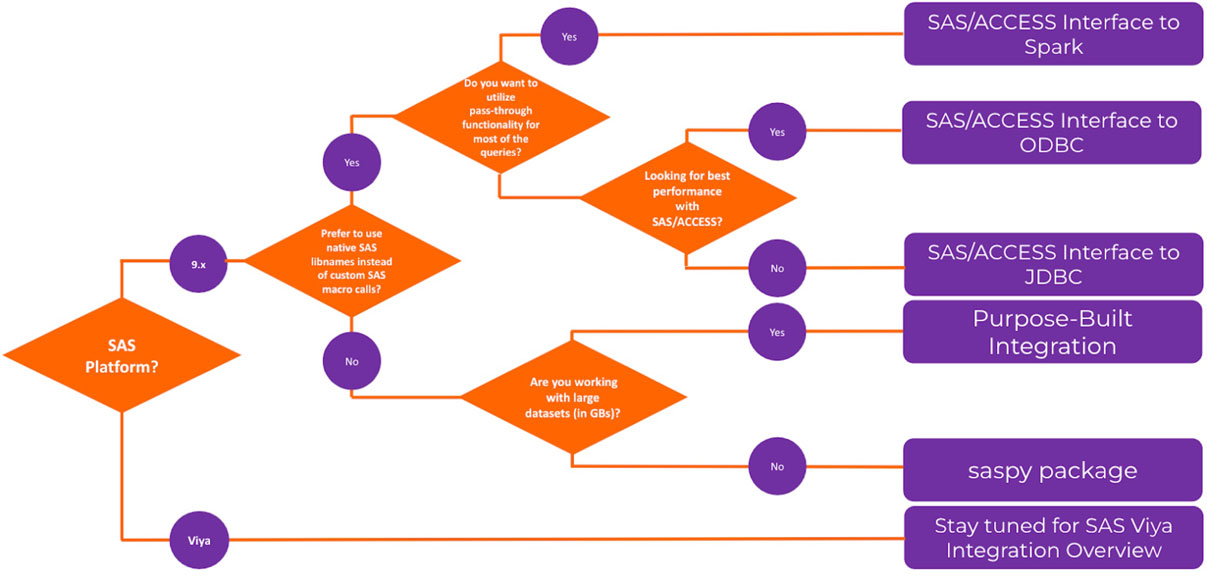
Il metodo di integrazione creata appositamente ha mostrato le migliori prestazioni rispetto ad altri metodi testati. La Figura 3 mostra un diagramma di flusso con indicazioni di alto livello nella scelta tra i metodi discussi.
Accedi ai dataset SAS da Databricks
Questa sezione affronta la necessità per gli sviluppatori Databricks di ingerire un dataset SAS in Delta Lake e renderlo disponibile in Databricks per l'intelligence aziendale, l'analisi visiva e altri casi d'uso di analisi avanzate. Sebbene alcuni dei metodi descritti in precedenza siano applicabili qui, vengono discussi alcuni metodi aggiuntivi.
Nel test, partiamo da un dataset SAS (in formato sas7bdat) sul server SAS e, alla fine, abbiamo questo dataset disponibile come Spark DataFrame (se l'invocazione lazy è applicabile forziamo il caricamento dei dati in un DataFrame e misuriamo il tempo complessivo) in Databricks.
Abbiamo utilizzato lo stesso ambiente e lo stesso dataset per questo scenario che è stato utilizzato nello scenario precedente. I test non considerano il caso d'uso in cui un utente SAS scrive un dataset in Delta Lake utilizzando la programmazione SAS. Ciò implica la considerazione degli strumenti e delle funzionalità del provider cloud che verranno discussi in un post del blog successivo.
Metodi testati
1. Utilizzo del pacchetto saspy da SAS
Il metodo sd2df nella libreria saspy converte un dataset SAS in un DataFrame pandas, utilizzando SSH per il trasferimento dei dati. Offre diverse opzioni per lo spazio di archiviazione temporaneo (Memoria, CSV, DISK) durante il trasferimento. Nel nostro test, l'opzione CSV, che utilizza PROC EXPORT file csv e i metodi pandas read_csv(), che è l'opzione consigliata per set di dati di grandi dimensioni, ha mostrato le migliori prestazioni.
2. Utilizzo del metodo pandas
Fin dalle prime versioni, pandas ha consentito agli utenti di leggere file sas7bdat utilizzando l'API pandas.read_sas. Il file SAS deve essere accessibile al programma Python. I metodi comunemente utilizzati sono FTP, HTTP o lo spostamento su storage di oggetti cloud come S3. Noi abbiamo utilizzato piuttosto un approccio più semplice per spostare un file SAS dal server SAS remoto al cluster Databricks utilizzando SCP.
3. Utilizzo di spark-sas7bdat
Spark-sas7bdat è un pacchetto open-source sviluppato specificamente per Apache Spark. Simile al metodo pandas.read_sas(), il file SAS deve essere disponibile sul filesystem. Abbiamo scaricato il file sas7bdat da un server SAS remoto utilizzando SCP.
4. Utilizzo di un'integrazione creata appositamente
Un altro metodo esplorato è l'utilizzo di tecniche convenzionali con un focus sul bilanciamento tra praticità e prestazioni. Questo metodo astrae le integrazioni principali ed è reso disponibile all'utente come libreria Python che viene eseguita dal Notebook Databricks.
- Utilizzare il pacchetto saspy per eseguire un codice macro SAS (su un server SAS) che esegue quanto segue
- Esporta sas7bdat in file CSV utilizzando codice SAS
- Comprime il file CSV in GZIP
- Sposta il file compresso sul nodo driver del cluster Databricks utilizzando SCP
- Decomprime il file CSV
- Legge il file CSV in un DataFrame Apache Spark
Risultati del test
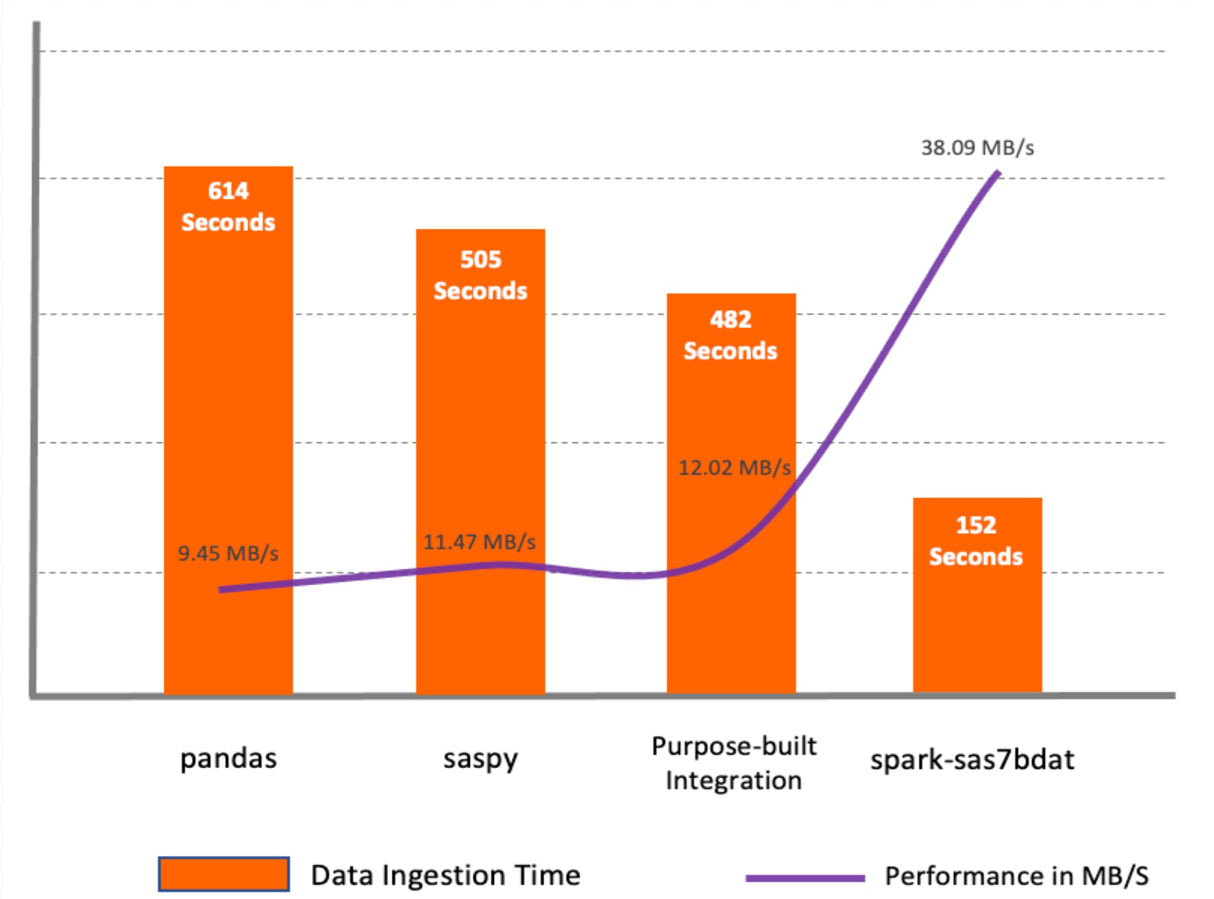
Il pacchetto spark-sas7bdat ha mostrato le migliori prestazioni tra tutti i metodi. Questo pacchetto sfrutta appieno l'elaborazione parallela in Apache Spark. Distribuisce blocchi di file sas7bdat sui nodi worker. Il principale svantaggio di questo metodo è che sas7bdat è un formato binario proprietario e la libreria è stata costruita basandosi sul reverse engineering di questo formato binario, quindi non supporta tutti i tipi di file sas7bdat, né è ufficialmente supportato dal fornitore (commercialmente).
I metodi saspy e pandas sono simili nel modo in cui sono entrambi costruiti per un ambiente a nodo singolo e leggono entrambi i dati in un DataFrame pandas, richiedendo un passaggio aggiuntivo prima che i dati siano disponibili come DataFrame Spark.
La macro integrazione specifica per lo scopo ha mostrato prestazioni migliori rispetto a saspy e pandas perché legge i dati da CSV tramite le API di Apache Spark. Tuttavia, non supera le prestazioni del pacchetto spark-sas7bdat. Il metodo specifico per lo scopo può essere conveniente in alcuni casi in quanto consente di aggiungere trasformazioni di dati intermedie sul server SAS.
Conclusione
Sempre più aziende stanno convergendo verso la creazione di un Databricks Lakehouse e ci sono molteplici modi per accedere ai dati dal Lakehouse tramite altre tecnologie. Questo blog discute come gli sviluppatori SAS, i data scientist e altri utenti aziendali possono sfruttare i dati nel Lakehouse e scrivere i risultati nel cloud. Nel nostro esperimento, abbiamo testato diversi metodi per leggere e scrivere dati tra Databricks e SAS. I metodi variano non solo per prestazioni ma anche per convenienza e funzionalità aggiuntive che forniscono.
Per questo test, abbiamo utilizzato la piattaforma SAS 9.4M7. SAS Viya supporta la maggior parte degli approcci discussi ma offre anche opzioni aggiuntive. Se desideri saperne di più sui metodi o su altri approcci di integrazione specializzati non trattati qui, non esitare a contattarci all'Databricks o a databricks@t1a.com.
Nei prossimi post di questa serie di blog, discuteremo le best practice nell'implementazione di pipeline di dati integrate, flussi di lavoro end-to-end, utilizzando SAS e Databricks e come sfruttare le tecnologie SAS In-Database per l'esecuzione di modelli SAS in cluster Databricks.
SAS® e tutti gli altri nomi di prodotti o servizi di SAS Institute Inc. sono marchi registrati o marchi commerciali di SAS Institute Inc. negli Stati Uniti e in altri paesi. ® indica la registrazione negli Stati Uniti.
Inizia
Prova il corso, Databricks per utenti SAS, su Databricks Academy per acquisire un'esperienza pratica di base con la programmazione PySpark per costrutti del linguaggio di programmazione SAS e contattaci per saperne di più su come possiamo assistere il tuo team SAS nell'integrazione dei loro carichi di lavoro ETL in Databricks e nell'abilitazione delle best practice.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.