Apache Spark e Photon ricevono i premi SIGMOD
di Reynold Xin e Matei Zaharia
Questa settimana, molti degli ingegneri e dei ricercatori più influenti della community della gestione dei dati si riuniscono di persona a Filadelfia per la conferenza ACM SIGMOD, dopo due anni di incontri virtuali. Nell'ambito dell'evento, siamo stati entusiasti di assistere all'assegnazione dei seguenti due premi:
- Apache Spark ha ricevuto il SIGMOD Systems Award.
- A Databricks Photon è stato assegnato il premio Best Industry Paper
Abbiamo pensato di cogliere l'occasione per discutere il contesto e come siamo arrivati a questo punto.
Che cos'è l'ACM SIGMOD e quali sono i premi?
ACM SIGMOD sta per Association of Computing Machinery’s Special Interest Group in the Management of Data. Lo sappiamo, è un nome lungo. Tutti dicono semplicemente SIGMOD. È la conferenza più prestigiosa per ricercatori e ingegneri di database, poiché molte delle idee più fondamentali nel campo dei database, dagli archivi a colonne (column store) alle ottimizzazioni delle query, sono state pubblicate in questa sede.
Il SIGMOD Systems Award viene assegnato ogni anno a un "sistema i cui contributi tecnici hanno avuto un impatto significativo sulla teoria o sulla pratica dei sistemi di gestione dei dati su larga scala". Questi sistemi tendono ad avere applicazioni reali su larga scala, oltre ad aver influenzato il modo in cui vengono progettati i sistemi di database futuri. Tra i vincitori del passato figurano Postgres, SQLite, BerkeleyDB e Aurora.
Il Best Industry Paper Award viene assegnato annualmente a un paper sulla base della combinazione di impatto sul mondo reale, innovazione e qualità della presentazione.
Le origini di Apache Spark per i dati e l'AI
Circa un decennio fa, Netflix ha indetto una competizione chiamata Netflix Prize, in cui ha reso anonima la sua vasta raccolta di valutazioni di film degli utenti e ha chiesto ai concorrenti di elaborare algoritmi per prevedere come gli utenti avrebbero valutato i film. Il trofeo da 1 milione di dollari sarebbe andato al team con il miglior modello di machine learning.
Un gruppo di dottorandi della UC Berkeley ha deciso di competere. La prima sfida in cui si sono imbattuti è stata che il tooling semplicemente non era abbastanza buono. Per creare modelli migliori, avevano bisogno di un modo rapido e iterativo per pulire, analizzare ed elaborare grandi quantità di dati (che non entravano nel laptop di uno studente) e di un framework sufficientemente espressivo per comporre algoritmi di ML sperimentali.
I data warehouse, che erano lo standard per i dati aziendali, non erano in grado di gestire i dati non strutturati e mancavano di espressività. Hanno discusso di questa sfida con un altro dottorando, Matei Zaharia. Insieme, hanno progettato un nuovo framework di calcolo parallelo chiamato Spark, con una nuova e innovativa struttura di dati distribuiti chiamata RDD. Spark ha permesso ai suoi utenti di eseguire attività operative parallele sui dati in modo rapido e conciso.
O, per dirla in altro modo, è veloce da programmare e veloce da eseguire. La rapidità di scrittura è importante perché rende il programma più comprensibile e può essere utilizzata per comporre facilmente algoritmi più complessi. La rapidità di esecuzione consente agli utenti di ottenere feedback più velocemente e di creare i propri modelli utilizzando dati in continua crescita.

Si è scoperto che gli studenti non erano soli. Erano i primi tempi delle applicazioni di dati e IA nel settore industriale e tutti si trovavano di fronte a sfide simili. A grande richiesta, il progetto è passato alla Apache Software Foundation ed è cresciuto fino a diventare una grandissima community.
Oggi, Spark è lo standard de facto per l'elaborazione dei dati ed è in continua crescita:
- Il mese scorso è stato scaricato 45 milioni di volte, solo su PyPI e Maven Central. Ciò rappresenta una crescita del 90% su base annua per quanto riguarda i download.
- È utilizzato in almeno 204 Paesi e regioni.
- Si classifica al primo posto tra le tecnologie più pagate nel sondaggio per sviluppatori del 2021 di Stack Overflow.
Il SIGMOD Systems Award è una conferma dell'adozione del progetto e della sua influenza sulle generazioni di sistemi a venire nel considerare i dati e l'IA come un pacchetto unificato.
Photon: nuovi carichi di lavoro e Lakehouse
Con la crescente popolarità di Apache Spark, abbiamo scoperto che le organizzazioni volevano utilizzarlo per andare oltre l'elaborazione di dati su larga scala e il machine learning: volevano eseguire applicazioni di data warehousing interattive tradizionali sugli stessi set di dati che utilizzavano in altre aree della loro attività, eliminando la necessità di gestire più sistemi di dati. Questo ha portato al concetto di sistemi lakehouse: un unico data store in grado di eseguire elaborazioni su larga scala e query SQL interattive, combinando i vantaggi dei sistemi data warehouse e data lake.
Per supportare questi tipi di casi d'uso, abbiamo sviluppato Photon, un motore di esecuzione C++ veloce e vettorizzato per carichi di lavoro Spark e SQL che viene eseguito dietro le interfacce di programmazione esistenti di Spark. Photon consente query interattive molto più veloci e una concorrenza molto più elevata rispetto a Spark, supportando al contempo le stesse API e gli stessi workload, comprese le applicazioni SQL, Python e Java. Abbiamo ottenuto ottimi risultati con Photon su carichi di lavoro di ogni dimensione, dal raggiungimento del record mondiale nel benchmark per data warehouse su larga scala TPC-DS l'anno scorso fino a prestazioni 3 volte superiori su query piccole e simultanee.
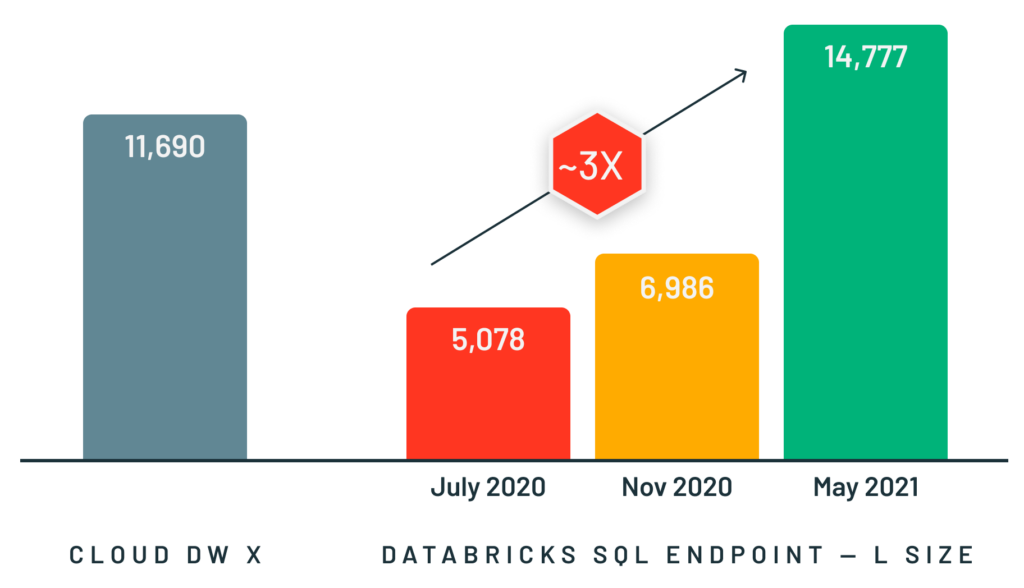
Progettare e implementare Photon è stata una sfida perché avevamo bisogno che il motore mantenesse l'espressività e la flessibilità di Spark (per supportare un'ampia gamma di applicazioni), non fosse mai più lento (per evitare regressioni delle prestazioni) e fosse significativamente più veloce nei nostri carichi di lavoro target. Inoltre, a differenza di un motore di data warehouse tradizionale che presuppone che tutti i dati siano stati caricati in un formato proprietario, Photon doveva funzionare nell'ambiente lakehouse, elaborando dati in formati aperti come Delta Lake e Apache Parquet, con ipotesi minime sul processo di ingestion (ad es. disponibilità di indici o statistiche sui dati). Il nostro paper SIGMOD descrive come abbiamo affrontato queste sfide e molti dei dettagli tecnici dell'implementazione di Photon.
Siamo stati entusiasti di vedere questo lavoro riconosciuto come miglior paper del settore e speriamo che offra a ingegneri di database e ricercatori spunti interessanti sulle sfide di questo nuovo modello di sistemi lakehouse. Naturalmente, siamo anche molto entusiasti di ciò che i nostri clienti hanno fatto finora con Photon: il nuovo motore gestisce già una parte significativa del nostro carico di lavoro.
Se partecipi a SIGMOD, passa allo stand di Databricks per un saluto. Ci piacerebbe parlare insieme del futuro dei sistemi di dati. In cambio, ti regaleremo la t-shirt “the best data warehouse is a lakehouse”!

Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.