Databricks stabilisce il record ufficiale di prestazioni di data warehouse
Oggi, siamo orgogliosi di annunciare che Databricks SQL ha stabilito un nuovo record mondiale nel TPC-DS da 100 TB, il benchmark delle prestazioni gold standard per il data warehousing. Databricks SQL ha superato il record precedente di 2,2 volte. A differenza della maggior parte delle altre notizie sui benchmark, questo risultato è stato formalmente verificato e revisionato dal consiglio TPC.
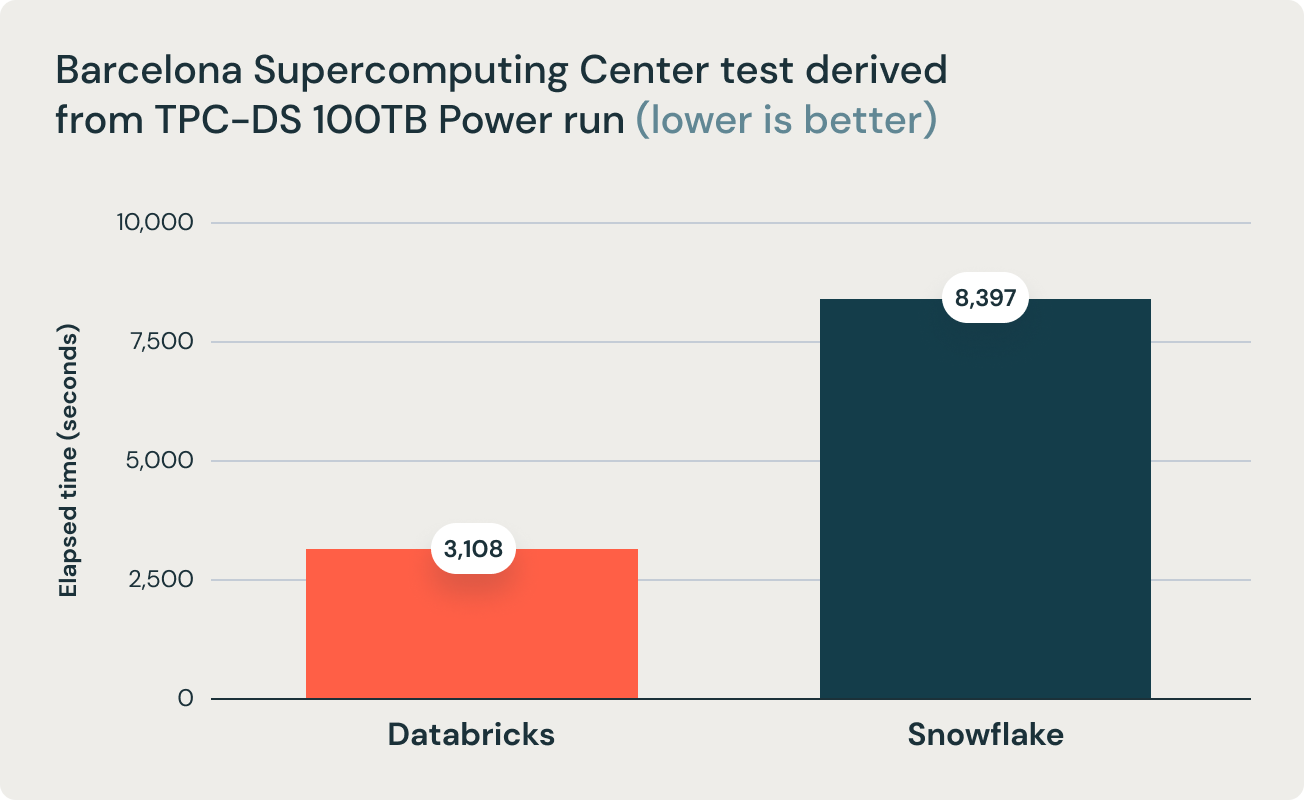
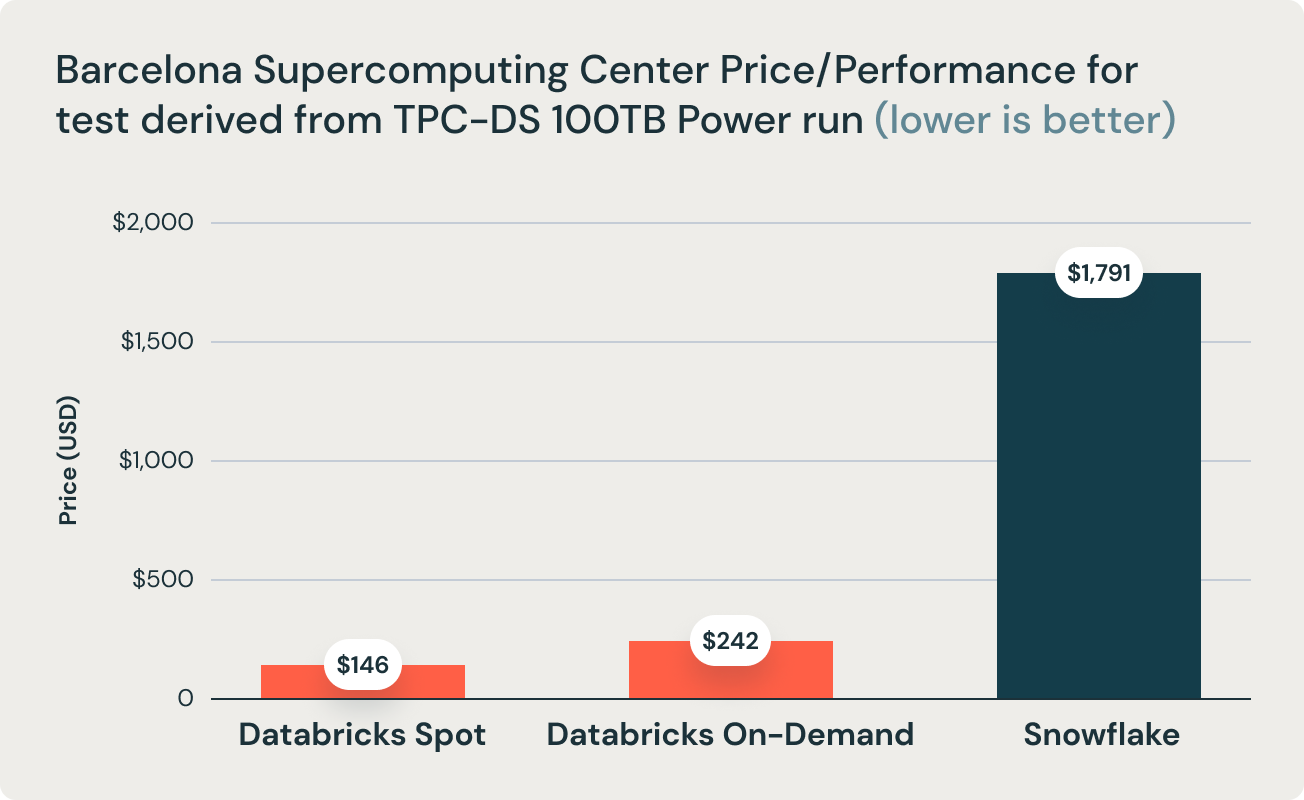
Questi risultati sono stati confermati da una ricerca del Barcelona Supercomputing Center, che esegue frequentemente benchmark derivati da TPC-DS sui data warehouse più diffusi. La loro ultima ricerca ha confrontato Databricks e Snowflake e ha rilevato che Databricks è 2,7 volte più veloce e 12 volte migliore in termini di rapporto prezzo/prestazioni. Questo risultato ha convalidato la tesi secondo cui i data warehouse come Snowflake diventano proibitivamente costosi all'aumentare delle dimensioni dei dati in produzione.
Databricks ha sviluppato rapidamente funzionalità complete di data warehousing direttamente sui data lake, unendo il meglio di entrambi i mondi in un'unica architettura di dati denominata data lakehouse. Abbiamo annunciato la nostra suite completa di funzionalità di data warehousing con il nome di Databricks SQL nel novembre 2020. Da allora, la questione aperta è stata se un'architettura aperta basata su un lakehouse possa offrire le prestazioni, la velocità e il costo dei data warehouse classici. Questo risultato dimostra senza ombra di dubbio che ciò è possibile e realizzabile con l'architettura lakehouse.
Piuttosto che condividere semplicemente i risultati, vorremmo cogliere l'occasione per raccontarvi come abbiamo raggiunto questo livello di prestazioni e tutto l'impegno che ci è voluto. Ma partiamo dai risultati:
Record mondiale TPC-DS
Databricks SQL ha raggiunto 32.941.245 QphDS @ 100TB. Questo supera di 2,2 volte il precedente record mondiale detenuto dal sistema personalizzato di Alibaba, che ha raggiunto 14,861,137 QphDS @ 100TB. (Alibaba aveva un sistema impressionante a supporto della più grande piattaforma di e-commerce al mondo). Databricks SQL non solo ha battuto in modo significativo il record precedente, ma lo ha fatto riducendo il costo totale del sistema del 10% (in base ai prezzi di listino pubblicati, senza sconti).
È assolutamente normale se non sai cosa significa l'unità QphDS. (Non lo sappiamo neanche noi senza guardare la formula.) QphDS è la metrica principale per TPC-DS, che rappresenta le prestazioni di una combinazione di carichi di lavoro, tra cui (1) il caricamento del set di dati, (2) l'elaborazione di una sequenza di query (test di potenza), (3) l'elaborazione di più Stream di query simultanei (test di throughput) e (4) l'esecuzione di funzioni di manutenzione dei dati che inseriscono ed eliminano dati.
Questa conclusione è ulteriormente supportata dal team di ricerca del Barcelona Supercomputing Center (BSC), che ha recentemente eseguito un benchmark diverso derivato da TPC-DS confrontando Databricks SQL e Snowflake e ha rilevato che Databricks SQL era 2,7 volte più veloce rispetto a una configurazione Snowflake di dimensioni simili.
Cos'è TPC-DS?
TPC-DS è un benchmark di data warehousing definito dal Transaction Processing Performance Council (TPC). Il TPC è un'organizzazione no-profit avviata dalla community dei database alla fine degli anni '80, focalizzata sulla creazione di benchmark che emulano scenari reali e che, di conseguenza, possono essere usati oggettivamente per misurare le prestazioni dei sistemi di database. Il TPC ha avuto un impatto profondo nel campo dei database, con "guerre di benchmarking" decennali tra fornitori affermati come Oracle, Microsoft e IBM che hanno contribuito al progresso del settore.
La sigla "DS" in TPC-DS sta per "supporto decisionale". Include 99 query di complessità variabile, da aggregazioni molto semplici a complesse attività di pattern mining. È un benchmark relativamente nuovo (il lavoro è iniziato a metà degli anni 2000) per riflettere la crescente complessità delle analitiche. Nell'ultimo decennio circa, TPC-DS è diventato il benchmark standard de facto per il data warehousing, adottato praticamente da tutti i fornitori.
Tuttavia, a causa della sua complessità, molti sistemi di data warehouse, anche quelli creati dai fornitori più affermati, hanno modificato il benchmark ufficiale in modo che i propri sistemi ottenessero prestazioni migliori. (Alcune modifiche comuni includono la rimozione di alcune funzionalità SQL come i rollup o la modifica della distribuzione dei dati per eliminare l'asimmetria). Questo è uno dei motivi per cui ci sono state pochissime sottomissioni al benchmark ufficiale TPC-DS, nonostante su Internet esistano più di 4 milioni di pagine relative a TPC-DS. Le modifiche spiegano anche apparentemente perché la maggior parte dei fornitori sembra battere tutti gli altri in base ai propri benchmark.
Come abbiamo fatto?
Come accennato in precedenza, ci si è chiesti se sia possibile per Databricks SQL superare le prestazioni dei data warehouse in termini di prestazioni SQL. La maggior parte delle sfide può essere riassunta nei seguenti quattro problemi:
- I data warehouse sfruttano formati di dati proprietari e, di conseguenza, possono evolverli rapidamente, mentre Databricks (basato su Lakehouse) si affida a formati aperti (come Apache Parquet e Delta Lake) che non cambiano altrettanto velocemente. Di conseguenza, gli EDW avrebbero un vantaggio intrinseco.
- Per ottenere ottime prestazioni SQL è necessaria l'architettura MPP (massively parallel processing), e Databricks e Apache Spark non erano MPP.
- Il classico compromesso tra throughput e latenza implica che un sistema può essere eccellente per query di grandi dimensioni (incentrate sul throughput) o per query di piccole dimensioni (incentrate sulla latenza), ma non per entrambe. Poiché Databricks si è concentrato su query di grandi dimensioni, le nostre prestazioni dovevano essere scarse per le query di piccole dimensioni.
- Anche se fosse possibile, l'opinione comune è che ci vorrebbe un decennio o più per creare un sistema di data warehouse. È impossibile fare progressi così in fretta.
Nel resto di questo post su un blog, li discuteremo uno per uno.
Formati di dati proprietari vs aperti
Uno dei principi chiave dell'architettura Lakehouse è il formato di archiviazione aperto. "Aperto" non solo evita il vendor lock-in, ma consente anche lo sviluppo di un ecosistema di strumenti indipendenti dal fornitore. Uno dei principali vantaggi dei formati aperti è la standardizzazione. Grazie a questa standardizzazione, la maggior parte dei dati aziendali si trova in data lake aperti e Apache Parquet è diventato lo standard de facto per l'archiviazione dei dati. Portando prestazioni di livello data warehouse ai formati aperti, speriamo di ridurre al minimo lo spostamento dei dati e di semplificare l'architettura dei dati per i carichi di lavoro di BI e AI.
Una critica ovvia all'approccio "aperto" è che i formati aperti sono difficili da modificare e di conseguenza difficili da migliorare. Sebbene in teoria questa argomentazione abbia senso, in pratica non è accurata.
Innanzitutto, è assolutamente possibile che i formati aperti si evolvano. Parquet, il formato aperto più diffuso per l'archiviazione di grandi quantità di dati, è passato attraverso diverse iterazioni di miglioramenti. Una delle principali motivazioni che ci ha spinto a introdurre Delta Lake è stata quella di offrire funzionalità aggiuntive difficili da implementare a livello di Parquet. Delta Lake ha aggiunto indicizzazione e statistiche aggiuntive a Parquet.
In secondo luogo, il sistema Databricks esegue automaticamente la transcodifica dei dati grezzi di Delta Lake e Parquet in un formato più efficiente durante il caricamento dei dati dagli archivi di oggetti agli SSD NVMe locali (senza l'intervento dell'utente). Ciò consente ulteriori opportunità di ottimizzazione.
Detto questo, per la maggior parte dei carichi di lavoro di data warehousing, Delta Lake e Parquet forniscono già ottimizzazioni sufficienti rispetto ai formati proprietari utilizzati dai data warehouse. Per questi carichi di lavoro, le opportunità di ottimizzazione derivano principalmente dalla capacità di elaborare le query più velocemente, invece di analizzare più dati più velocemente. In effetti, per TPC-DS, l'esecuzione di query su dati memorizzati nella cache in un formato interno più ottimizzato è solo il 10% più veloce rispetto all'esecuzione di query su dati cold in S3 (abbiamo riscontrato che questo è vero sia per i data warehouse che abbiamo sottoposto a benchmark, sia per Databricks).
Architettura MPP
Un malinteso comune è che i data warehouse utilizzino l'architettura MPP, ottima per le prestazioni SQL, mentre Databricks no. L'architettura MPP si riferisce alla capacità di sfruttare più nodi per elaborare una singola query. È esattamente così che è strutturato Databricks SQL. Non si basa su Apache Spark, ma piuttosto su Photon, una riscrittura completa di un motore, creato da zero in C++, per l'hardware SIMD moderno e che esegue un'intensa elaborazione parallela delle query. Photon è quindi un motore MPP.
Compromesso tra throughput e latenza
Throughput e latenza rappresentano il classico compromesso nei sistemi informatici, il che significa che un sistema non può ottenere contemporaneamente un throughput elevato e una bassa latenza. Se un design privilegia il throughput (ad esempio, tramite il batching dei dati), dovrebbe sacrificare la latenza. Nel contesto dei sistemi di dati, ciò significa che un sistema non può elaborare in modo efficiente query di grandi e piccole dimensioni contemporaneamente.
Non neghiamo che questo compromesso esista. In effetti, ne discutiamo spesso nei nostri documenti di progettazione tecnica. Tuttavia, gli attuali sistemi all'avanguardia, inclusi il nostro e tutti i warehouse più diffusi, sono molto lontani dalla frontiera ottimale sia sul fronte del throughput che della latenza.
Di conseguenza, è del tutto possibile ideare un nuovo design e una nuova implementazione che migliorino contemporaneamente sia il throughput che la latenza. È esattamente così che abbiamo costruito quasi tutte le nostre principali tecnologie abilitanti negli ultimi due anni: Photon, Delta Lake e molte altre tecnologie all'avanguardia hanno migliorato le prestazioni sia delle query grandi che di quelle piccole, spingendo la frontiera verso un nuovo record di prestazioni.
Tempo e concentrazione
Infine, l'opinione comune è che ci voglia almeno un decennio perché un sistema di database maturi. Data la recente attenzione di Databricks su Lakehouse (per supportare i carichi di lavoro SQL), sarebbe necessario un ulteriore sforzo per rendere SQL performante. Questo è valido, ma ti spieghiamo come l'abbiamo fatto molto più velocemente del previsto.
Innanzitutto, questo investimento non è iniziato solo un anno o due fa. Fin dalla nascita di Databricks, abbiamo investito in diverse tecnologie fondamentali per supportare i carichi di lavoro SQL che andrebbero a vantaggio anche dei carichi di lavoro di IA su Databricks. Questo include un ottimizzatore di query completo basato sui costi, un motore di esecuzione vettorizzato nativo e varie funzionalità come le funzioni finestra. La stragrande maggioranza dei carichi di lavoro su Databricks viene eseguita grazie all'API DataFrame di Spark, che si mappa sul suo motore SQL; di conseguenza, questi componenti hanno beneficiato di anni di test e ottimizzazione. Non abbiamo posto la stessa enfasi sui carichi di lavoro SQL. Il recente cambio di posizionamento verso il Lakehouse è guidato dal desiderio dei nostri clienti di semplificare le loro architetture dati.
In secondo luogo, il modello SaaS ha accelerato i cicli di sviluppo del software. In passato, la maggior parte dei fornitori aveva cicli di rilascio annuali e poi un altro ciclo pluriennale per consentire ai clienti di installare e adottare il software. Con il SaaS, il nostro team di ingegneri può elaborare un nuovo progetto, implementarlo e rilasciarlo a un sottoinsieme di clienti in pochi giorni. Questo ciclo di sviluppo abbreviato ha permesso ai team di ottenere rapidamente un feedback e di innovare più velocemente.
In terzo luogo, Databricks potrebbe dedicare a questo problema un'attenzione significativamente maggiore, sia in termini di impegno da parte della leadership che di capitale. I tentativi passati di creare un nuovo sistema di data warehouse sono stati effettuati da startup o da un nuovo team all'interno di una grande azienda. Non c'è mai stata una startup di database così ben finanziata come Databricks (con oltre 3,5 miliardi di dollari raccolti) in grado di attrarre i talenti necessari per realizzare questo progetto. Una nuova iniziativa all'interno di una grande azienda sarebbe solo un'iniziativa in più e non avrebbe la piena attenzione dei vertici.
Ci trovavamo in una situazione unica: inizialmente ci siamo concentrati sulla creazione della nostra attività non sul data warehousing, ma su campi correlati (data science e AI) che condividevano molti dei problemi tecnologici comuni. Questo successo iniziale ci ha poi permesso di finanziare la più aggressiva creazione di un team SQL della storia; in un breve periodo di tempo, abbiamo messo insieme un team con una vasta esperienza nel data warehouse, un'impresa che per molte altre aziende richiederebbe circa un decennio. Tra questi ci sono ingegneri e progettisti principali di alcuni dei sistemi di dati di maggior successo, tra cui Amazon Redshift, BigQuery di Google, F1 (il sistema di data warehouse interno di Google) e Procella (il sistema di data warehouse interno di YouTube), Oracle, IBM DB2 e Microsoft SQL Server.
In sintesi, sono necessari diversi anni per ottenere ottime prestazioni SQL. Non solo abbiamo accelerato questo processo sfruttando le nostre circostanze uniche, ma abbiamo anche iniziato anni fa, anche se non abbiamo usato un megafono per pubblicizzare il piano.
Carichi di lavoro reali dei clienti
Siamo entusiasti di vedere questi risultati di benchmark convalidati dai nostri clienti. Oltre 5.000 organizzazioni globali sfruttano la Databricks Lakehouse Platform per risolvere alcuni dei problemi più difficili del mondo. Ad esempio:
- Bread Finance è una piattaforma di pagamenti basata sulla tecnologia con casi d'uso di Big Data come il reporting finanziario, il rilevamento delle frodi, il rischio di credito, la stima delle perdite e un motore di raccomandazione full-funnel. Sulla Databricks Lakehouse Platform, sono in grado di passare da Job batch notturni all'ingestion quasi in tempo reale e di ridurre i tempi di elaborazione dei dati del 90%. Inoltre, la piattaforma dati può scalare fino a 140 volte il volume dei dati con un costo solo 1,5 volte superiore.
- Shell utilizza la nostra piattaforma lakehouse per consentire a centinaia di data analyst di eseguire query rapide su set di dati su scala petabyte utilizzando strumenti BI standard, cosa che considerano una "svolta epocale".
- Regeneron sta accelerando l'identificazione di bersagli farmacologici, fornendo informazioni dettagliate più rapide ai biologi computazionali riducendo il tempo necessario per eseguire query sull'intero set di dati da 30 minuti a 3 secondi, un miglioramento di 600 volte.
Riepilogo
Databricks SQL, basato sull'architettura Lakehouse, è il data warehouse più veloce sul mercato e offre il miglior rapporto prezzo/prestazioni. Ora puoi ottenere ottime prestazioni su tutti i tuoi dati a bassa latenza non appena i nuovi dati vengono inseriti, senza doverli esportare in un sistema diverso.
Questo testimonia la visione di Lakehouse di portare le prestazioni di data warehousing di livello mondiale nei data lake. Naturalmente, non abbiamo creato solo un data warehouse. L'architettura Lakehouse permette di gestire tutti i carichi di lavoro relativi ai dati, dal warehousing alla data science e al machine learning.
Ma non abbiamo ancora finito. Abbiamo messo insieme il miglior team sul mercato e stanno lavorando sodo per offrire la prossima svolta in termini di prestazioni. Oltre alle prestazioni, stiamo anche lavorando a una miriade di miglioramenti per la facilità d'uso e la governance. Aspettatevi altre notizie da parte nostra nel prossimo anno.
Il TPC non controlla né convalida i risultati dei benchmark derivati dal TPC-DS e non considera i risultati dei benchmark derivati comparabili con i risultati pubblicati del TPC-DS.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.