Photon
Il motore di nuova generazione per il lakehouse
Photon è il motore di nuova generazione sulla Databricks Lakehouse Platform che offre prestazioni di query estremamente rapide a costi contenuti, per acquisizione di dati, ETL, streaming, data science e query interattive, direttamente sul data lake aziendale. Photon è compatibile con le API di Apache Spark™, quindi è una soluzione "chiavi in mano", che non necessita di modifiche al codice o altri vincoli.
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
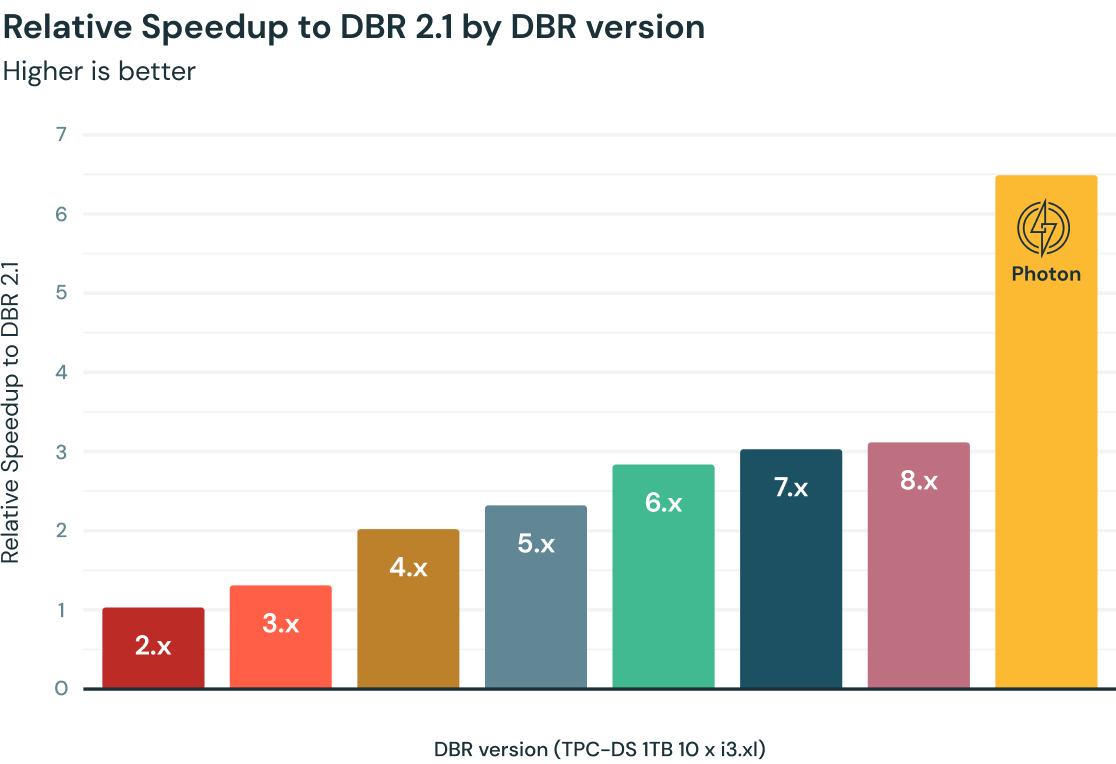
Perché Photon?
Le prestazioni delle query su Databricks sono migliorate progressivamente negli anni, grazie ad Apache Spark e a migliaia di ottimizzazioni fornite come parte integrante dei Databricks Runtimes (DBR). Photon, un nuovo motore nativo vettorizzato interamente scritto in C++, offre un ulteriore raddoppio della velocità secondo il benchmark TPC-DS 1TB; inoltre, i clienti hanno osservato velocità da 3 a 8 volte superiori in media, a seconda del carico di lavoro, rispetto alle versioni DBR più recenti.
Casi d'uso

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
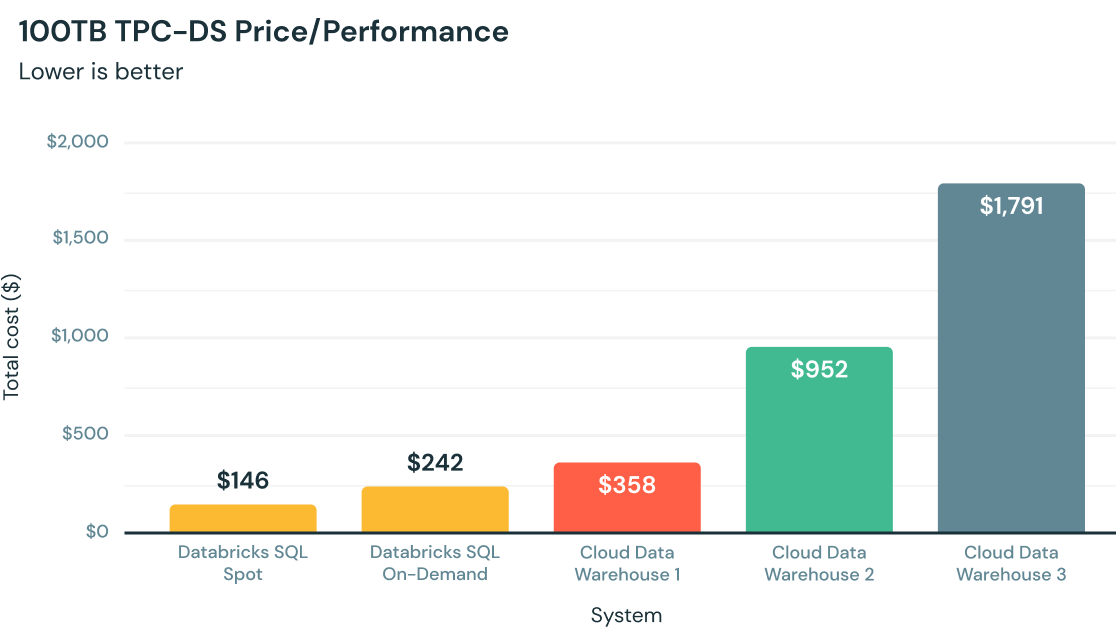
Come funziona?
Miglior rapporto prezzo/prestazioni per l'analisi in cloud
Scritto da zero in C++, Photon sfrutta l'hardware moderno per query più veloci, con un rapporto prezzo/prestazioni fino a 12 volte migliori rispetto ad altri data warehouse in cloud, tutto in modo nativo sul data lake aziendale.
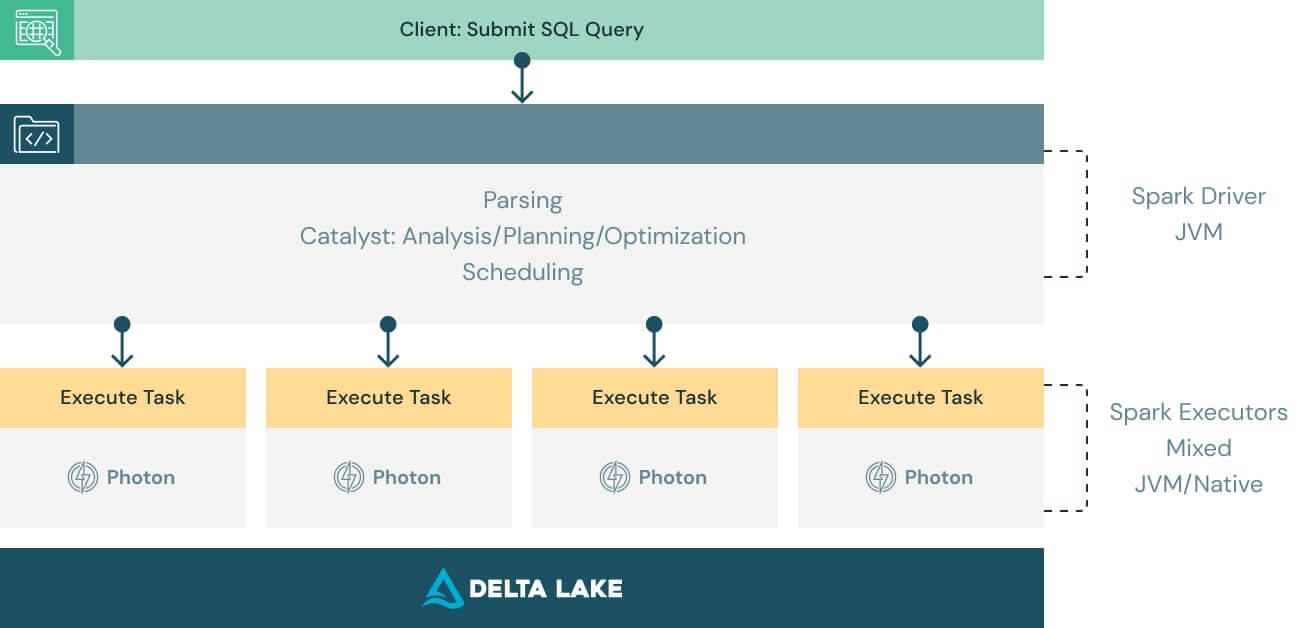
Funziona con il codice esistente e non vincola a nessun fornitore
Photon è progettato per essere compatibile con Apache Spark DataFrame e API SQL, per garantire che i carichi di lavoro vengano eseguiti fluidamente senza modifiche al codice. Per cogliere i vantaggi di Photon basta solo iniziare a utilizzarlo. Photon coordinerà lavoro e risorse in modo pienamente integrato e accelererà in maniera trasparente porzioni delle query SQL e Spark. Non servono aggiustamenti né interventi dell'utente.

Ottimizzazione per tutti i casi d'uso e i carichi di lavoro dei dati
Photon è nato con un'attenzione particolare a SQL per fornire ai clienti prestazioni di data warehouse avanzato sui rispettivi data lake, ma in seguito abbiamo ampliato l'offerta di sorgenti di acquisizione, formati, API e metodi supportati da Photon. I clienti hanno così beneficiato di una drastica riduzione dei costi di infrastruttura e di una maggiore velocità su Photon per tutti i loro carichi di lavoro Spark (ad es. Spark SQL e DataFrame).
Risorse
Risorse
Paper
Eventi
Blog
Pronto per cominciare?