Il database che i tuoi
agenti AI meritano
Lakebase è un Postgres serverless per applicazioni scalabili
Sviluppa ed esegui applicazioni, agenti
e AI sui tuoi dati
Databricks Platform
Unifica dati, analisi e AI. Usala per alimentare agenti, applicazioni e insight in linguaggio naturale.
Lakebase
Il primo database Postgres serverless integrato con il lakehouse, progettato per l'era dell'AI.
Genie
L'alleato AI che conosce i tuoi dati, per un lavoro più rapido e analisi più profonde.
Agent Bricks
Crea agenti AI che migliorano continuamente qualità e accuratezza, ottimizzati sui tuoi dati.
Lakehouse
Data warehousing serverless su dati open del lakehouse, con governance e AI integrate.
Gli innovatori che vincono con dati e AI
PREMI E RICONOSCIMENTI
Riconosciuta per l'innovazione nel campo dei dati e dell'AI
0%
Oltre il 60% delle aziende Fortune 500 usa Databricks
0k+
Oltre 20.000 clienti in tutto il mondo
0x
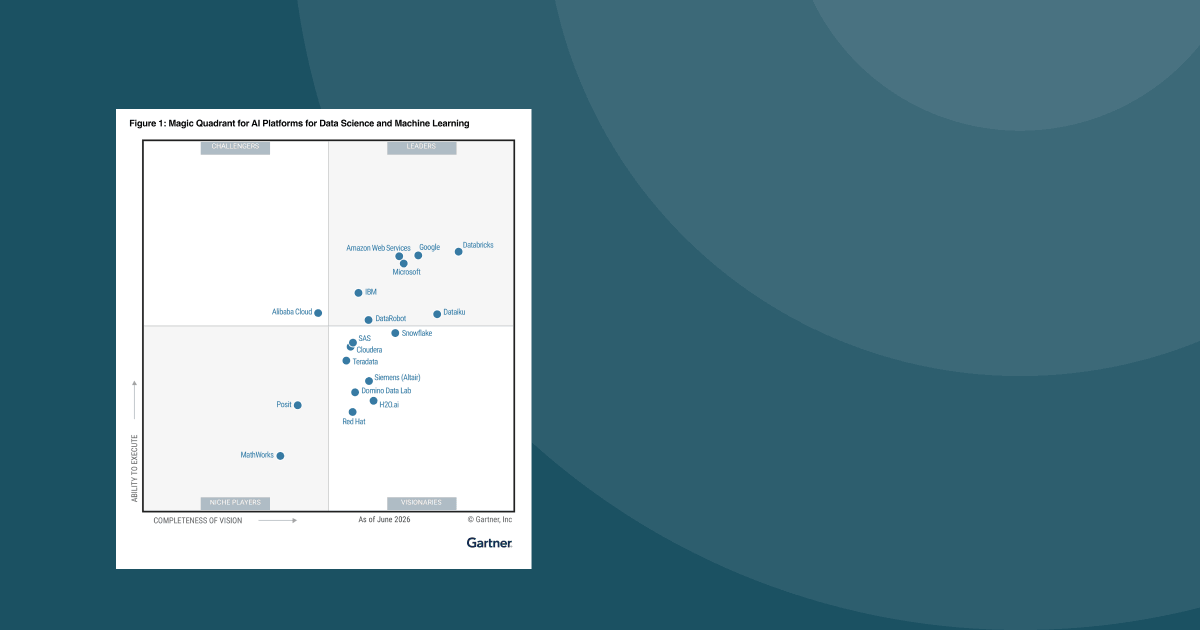
5 volte Leader nei report Gartner® Magic Quadrant™






Inizia il tuo percorso con dati e AI