LakeFlow
Acquisisci, trasforma e orchestra i dati con una soluzione unificata per il data engineering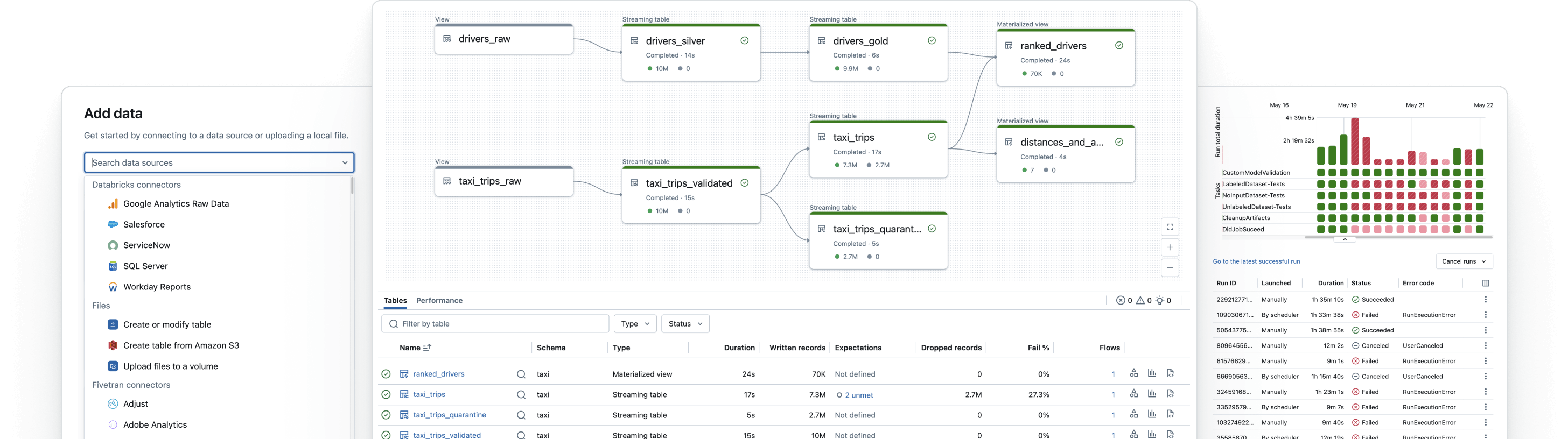
LE PRINCIPALI AZIENDE CHE UTILIZZANO LAKEFLOW
La soluzione end-to-end per fornire dati di alta qualità.
Strumenti che facilitano la creazione di pipeline di dati affidabili per l'analisi e l'AI.Stack di strumenti unificato
Riduci i costi e la complessità dell'integrazione con una soluzione unica per raccogliere e ripulire tutti i tuoi dati. Mantieni il controllo con governance e tracciabilità integrate e unificate.
Data engineering agentica
Utilizza il linguaggio naturale per accelerare lo sviluppo con agenti che comprendono i tuoi dati e possono creare pipeline di dati, effettuarne la manutenzione e la risoluzione dei problemi.
Elaborazione efficiente dei dati
Un potente motore di base ottimizza automaticamente l'uso delle risorse per un miglior rapporto qualità/prezzo, sia per carichi batch che per casi d'uso a bassa latenza e in tempo reale.
85% di velocità di sviluppo in più
50% di riduzione dei costi
99% di riduzione nella latenza delle pipeline
Strumenti unificati per qualsiasi carico di lavoro di data engineering

GENIE CODE
Crea e gestisci pipeline di dati con un'AI agentica che comprende i tuoi dati.
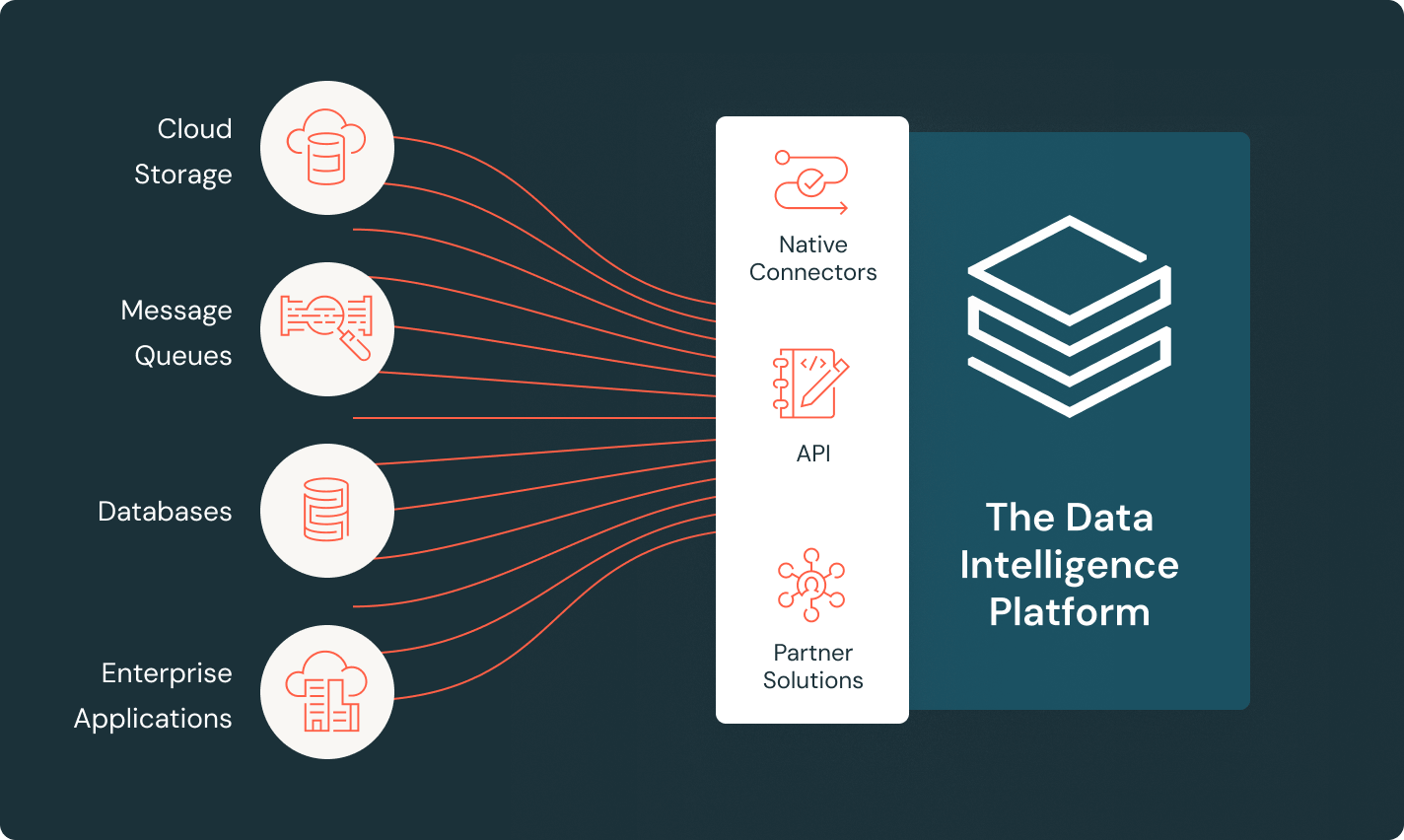
LakeFlow Connect
Connettori efficienti per l'acquisizione di dati e integrazione nativa con la Data Intelligence Platform facilitano l'accesso all'analisi e all'AI, con una governance unificata.

Apache Spark™ Declarative Pipelines
Semplifica l’ETL batch e in streaming grazie a funzionalità automatizzate per la qualità dei dati, il Change Data Capture (CDC), l’ingestione, la trasformazione e la governance centralizzata.

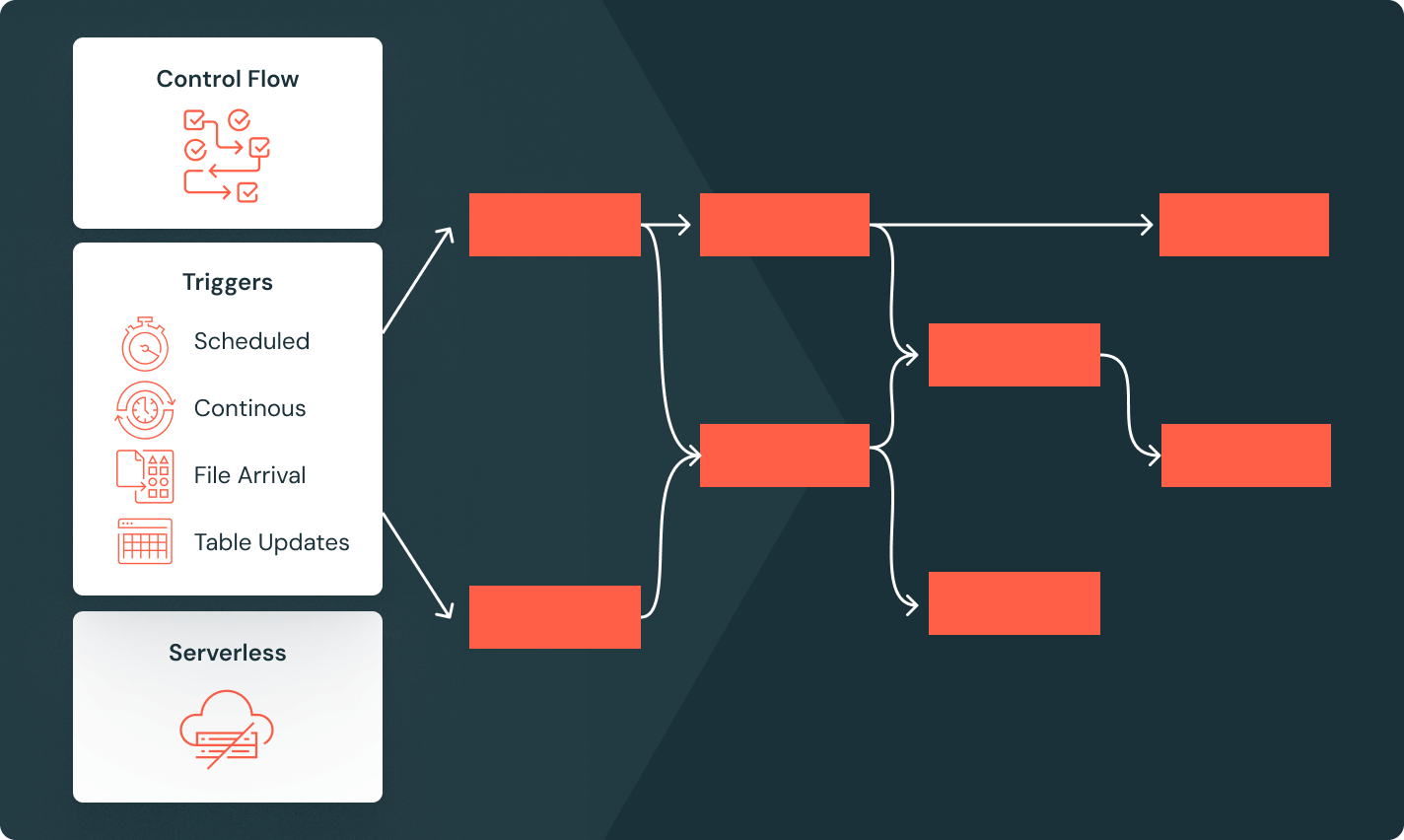
Job di Lakeflow
Fornisci ai team gli strumenti per automatizzare e orchestrare al meglio qualsiasi flusso di lavoro ETL, di analisi o AI, con osservabilità avanzata, alta affidabilità e supporto per una vasta gamma di attività.

Unity Catalog
Gestisci tutti i tuoi asset di dati con l'unica soluzione di governance unificata e aperta del settore per dati e AI, integrata nella Databricks Data Intelligence Platform.
Lakeflow Designer
Prepara e trasforma i dati con l'authoring basato sull'AI, direttamente su Databricks.
Crea pipeline di dati affidabili

Trasforma i dati grezzi in tabelle Gold di alta qualità
Implementa pipeline ETL per filtrare, arricchire, ripulire e aggregare i dati in modo che siano pronti per analisi, AI e BI. Segui l'architettura a medaglione per elaborare i dati dai livelli Bronze Silver fino a Gold.

Fai il passo successivo




FAQ sul data engineering
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati