Utilizzo di un Knowledge Graph per potenziare un livello semantico dei dati per Databricks
di Prasad Kona e Aaron Wallace
Questo è un post collaborativo tra Databricks e Stardog. Ringraziamo Aaron Wallace, Sr. Product Manager presso Stardog, per il suo contributo.
I Knowledge Graph sono diventati onnipresenti, anche se non ce ne rendiamo conto. Li sperimentiamo ogni giorno quando cerchiamo su Google o guardiamo i feed che scorrono sui nostri account di social media di persone che conosciamo, aziende che seguiamo o contenuti che ci piacciono. Allo stesso modo, gli Enterprise Knowledge Graph forniscono una base per strutturare i contenuti, i dati e gli asset informativi della tua organizzazione estraendo, relazionando e fornendo conoscenza come risposte, raccomandazioni e insight a ogni applicazione data-driven, dai chatbot ai motori di raccomandazione o potenziando il tuo BI e Analytics.
In questo blog, imparerai come Databricks e Stardog risolvono la sfida dell'ultimo miglio nella democratizzazione dei dati e degli insight. Databricks fornisce una piattaforma lakehouse per carichi di lavoro di dati, analytics e intelligenza artificiale (AI) su una piattaforma multi-cloud. Stardog fornisce una piattaforma di knowledge graph che può modellare relazioni complesse contro dati ampi, e non solo grandi, per descrivere persone, luoghi, cose e come sono correlati. La Databricks Lakehouse Platform, abbinata al livello semantico abilitato dal Knowledge Graph di Stardog, fornisce alle organizzazioni una base per un'architettura di enterprise data fabric che consente a team interfunzionali, inter-aziendali o inter-organizzativi di porre e rispondere a query complesse attraverso i silos di dominio.
La crescente necessità di un'architettura Data Fabric
La rapida innovazione e la disruption nel settore della gestione dei dati stanno aiutando le organizzazioni a sbloccare valore dai dati disponibili sia all'interno che all'esterno dell'azienda. Le organizzazioni che operano attraverso confini fisici e digitali stanno trovando nuove opportunità per servire i clienti nel modo in cui desiderano essere serviti.
Queste organizzazioni hanno collegato tutti i dati rilevanti attraverso la supply chain dei dati per creare un quadro completo e accurato nel contesto dei loro casi d'uso. La maggior parte dei settori che cercano di operare e condividere dati attraverso confini organizzativi per armonizzare i dati e abilitare la condivisione dei dati stanno adottando standard aperti sotto forma di ontologie prescritte, da FIBO nei Servizi Finanziari a D3FEND nel dominio della Cybersecurity. Queste ontologie aziendali (o modelli semantici) riflettono come pensiamo ai dati con significato associato, cioè "cose" piuttosto che come i dati sono strutturati e archiviati, cioè "stringhe", e rendono possibile la condivisione e il riutilizzo dei dati.
L'idea di un livello semantico non è nuova. Esiste da oltre 30 anni, spesso promossa da fornitori di BI che aiutano le aziende a costruire dashboard specifici per lo scopo. Tuttavia, un'adozione diffusa è stata ostacolata, data la natura incorporata di quel livello come parte di un sistema BI proprietario. Questo livello è spesso troppo rigido e complesso, soffrendo delle stesse limitazioni di un sistema di database relazionale fisico che modella i dati per ottimizzare il suo linguaggio di query strutturato piuttosto che come i dati sono correlati nel mondo reale—molti-a-molti. Un livello di dati semantico potenziato da knowledge graph che opera tra i livelli di storage e di consumo fornisce quella colla e quel moltiplicatore che collega tutti i dati per fornire valore nel contesto del caso d'uso aziendale a data scientist e analisti cittadini che altrimenti non sarebbero in grado di partecipare e collaborare in architetture data-centriche al di fuori di una manciata di specialisti.
Abilita un caso d'uso assicurativo
Consideriamo un esempio reale di un'organizzazione assicurativa multi-compagnia per illustrare come Stardog e Databricks lavorano insieme. Come la maggior parte delle grandi aziende, molte compagnie di assicurazione lottano con sfide simili quando si tratta di dati, come la mancanza di ampia disponibilità di dati da fonti interne ed esterne per il processo decisionale da parte degli stakeholder critici. Tutti, dalla valutazione del rischio di sottoscrizione all'amministrazione delle polizze, alla gestione dei sinistri e alle agenzie, faticano a sfruttare i dati e gli insight giusti per prendere decisioni critiche. Tutti necessitano di un data fabric aziendale che porti gli elementi di un'architettura moderna di dati e analytics per rendere i dati FAIR - Findable, Accessible, Interoperable e Reusable. La maggior parte delle aziende inizia il proprio percorso portando tutte le fonti di dati in un data lake. L'approccio lakehouse di Databricks fornisce alle aziende un'ottima base per archiviare tutti i loro dati analitici e rendere tutti i dati accessibili a chiunque all'interno dell'azienda. In questo livello di dati avviene tutta la pulizia, la trasformazione e la disambiguazione. Il passo successivo in quel percorso è l'armonizzazione dei dati, collegando i dati in base al loro significato per fornire un contesto più ricco. Un livello semantico, fornito da un knowledge graph, sposta l'attenzione sull'analisi e l'elaborazione dei dati e fornisce un tessuto connesso di insight cross-dominio a sottoscrittori, analisti del rischio, agenti e team di assistenza clienti per gestire il rischio e offrire un'esperienza cliente eccezionale.
Esamineremo come ciò funzionerebbe con un modello semantico semplificato come punto di partenza.
Modella facilmente entità specifiche del dominio e relazioni cross-dominio
La creazione visiva di un modello di dati semantico attraverso un'esperienza simile a una lavagna è il primo passo nella creazione di un livello di dati semantico. All'interno del progetto Stardog Designer, basta cliccare per creare classi specifiche (o entità) che sono critiche per rispondere alle tue domande di business. Una volta creata una classe, puoi aggiungere tutti gli attributi e i tipi di dati necessari per descrivere questa nuova entità. Collegare classi (o entità) è facile. Con un'entità selezionata, basta cliccare per aggiungere un collegamento e trascinare il punto della nuova relazione finché non scatta sull'altra entità. Dai a questa nuova relazione un nome che descriva il significato aziendale (ad esempio, un "Cliente" "possiede" un "Veicolo").
Aggiungi una nuova classe e collegala a una classe esistente per creare una relazione
Mappa i metadati dalla Databricks Lakehouse Platform
Cos'è un modello senza dati? Gli utenti Stardog possono connettersi a una varietà di fonti di dati strutturate, semi-strutturate e non strutturate persistendo o virtualizzando i dati, o una combinazione di entrambi, quando e dove ha senso. In Designer, è facile connettere dati da fonti esistenti come Delta Lake per connettere i metadati da tabelle specificate dall'utente. Ciò consente l'accesso iniziale a tali dati attraverso il suo livello di virtualizzazione senza spostarli o copiarli nel knowledge graph. Il livello di virtualizzazione traduce automaticamente le query in arrivo da Stardog da SPARQL basato su standard aperti a query SQL push-down ottimizzate in Databricks SQL.
Aggiungi una nuova origine dati come risorsa di progetto
Fai clic per aggiungere una nuova risorsa di progetto e seleziona da una delle connessioni disponibili, come Databricks. Questa connessione sfrutta il nuovo endpoint SQL rilasciato di recente da Databricks. Definisci uno scope per i dati e specifica eventuali proprietà aggiuntive. Utilizza il riquadro di anteprima per dare una rapida occhiata ai dati prima di aggiungerli al tuo progetto.
Incorpora dati aggiuntivi da una varietà di posizioni
Designer semplifica l'incorporazione di dati da altre origini dati e file come CSV, per i team che cercano di condurre analisi dati ad hoc, combinando dati da Delta con queste nuove informazioni. Una volta aggiunti come risorsa, è sufficiente aggiungere un collegamento e trascinare e rilasciare su una classe per mappare i dati. Dai alla mappatura un nome significativo, specifica una colonna di dati per l'identificatore primario, l'etichetta e qualsiasi altra colonna di dati che corrisponda agli attributi dell'entità.
Mappa i dati da una risorsa di progetto a una classe
Pubblica il tuo lavoro
All'interno di Designer puoi pubblicare il modello e i dati di questo progetto direttamente sul tuo server Stardog per l'uso in Stardog Explorer. Il designer ti consente anche di pubblicare e consumare l'output del knowledge graph in vari modi. Puoi pubblicare direttamente su una cartella compressa di file, inclusi il tuo modello e le tue mappature, nel tuo sistema di controllo versione.
Pubblica direttamente su un database Stardog
Una volta che i dati sono stati pubblicati su Stardog, gli analisti di dati possono anche utilizzare strumenti di BI popolari come Tableau per connettersi tramite l'endpoint BI/SQL di Stardog per recuperare dati attraverso il livello semantico in un report o dashboard. Lo schema generato automaticamente in qualsiasi strumento compatibile con SQL consente agli utenti di scrivere query SQL sul Knowledge Graph. Le query provenienti dal livello SQL vengono automaticamente tradotte in SPARQL, il linguaggio di query del Knowledge Graph, e inviate tramite query ottimizzate per sorgenti generate automaticamente, attraverso il livello virtuale, per il calcolo alla sorgente, in questo caso, Databricks tramite l'endpoint Databricks SQL. Le stesse informazioni possono anche essere rese disponibili agli utenti Databricks in un notebook utilizzando l'API Python di Stardog, pystardog. Puoi anche incorporare il grafo virtuale per l'uso diretto all'interno delle tue applicazioni utilizzando l'API GraphQL di Stardog. Il livello semantico sopra il lakehouse fornisce un ambiente unico per tutti i tipi di utenti e i loro strumenti preferiti, mantenendo le operazioni supportate da un set di dati coerente.
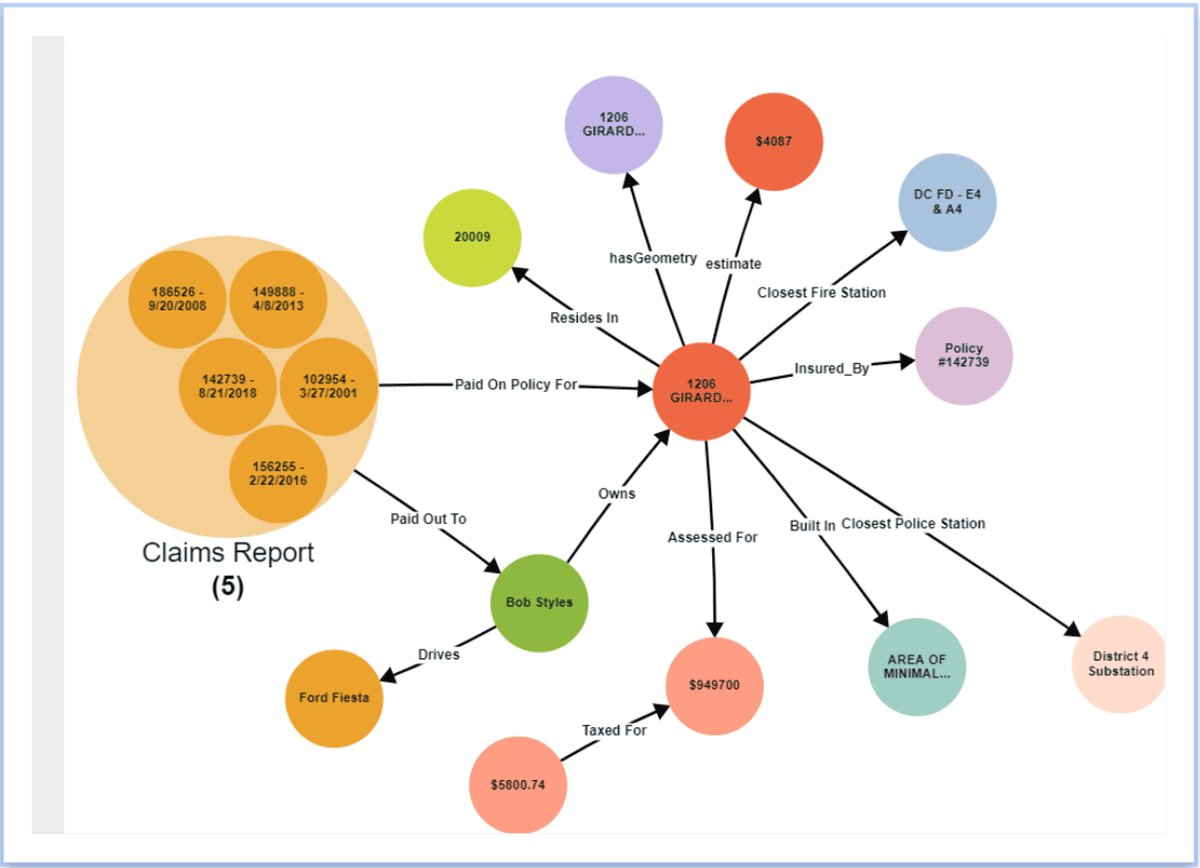
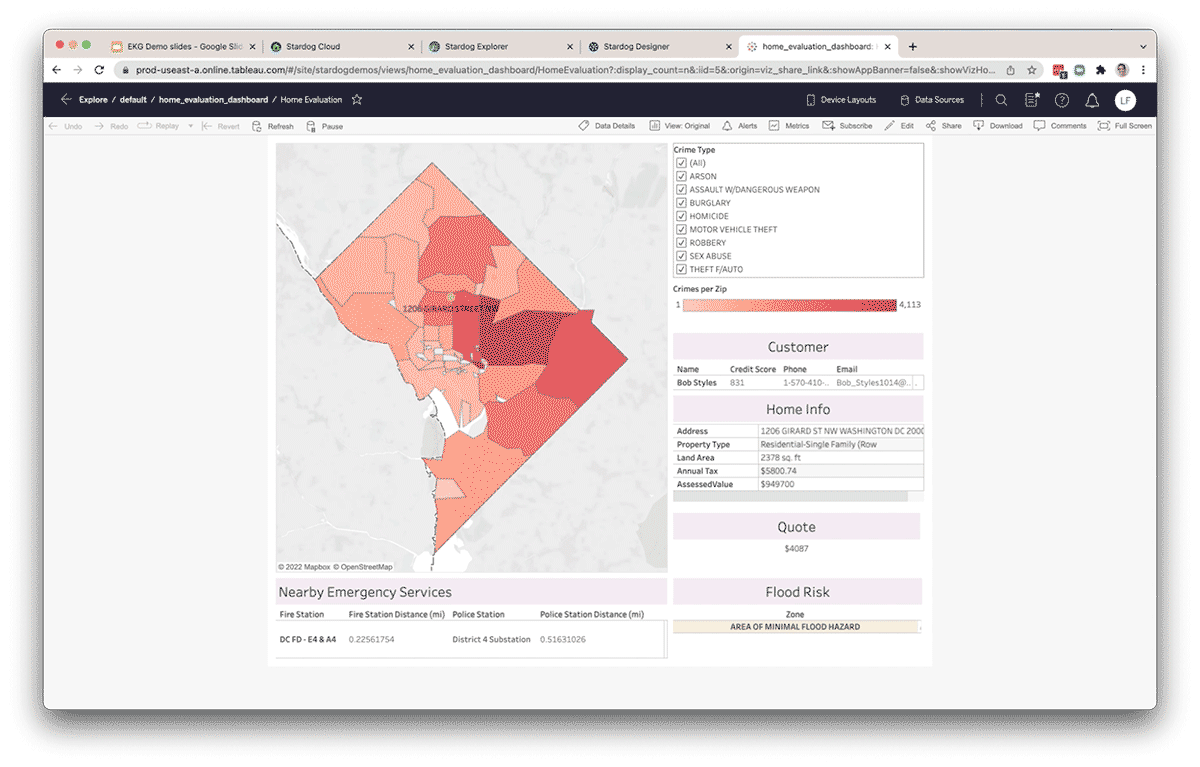
Aumenta la produttività e scopri nuove intuizioni
Organizzando i dati in un Knowledge Graph, i team di dati aumentano la loro produttività riducendo il tempo impiegato nella manipolazione di dati da fonti esterne a supporto dell'analisi ad hoc. I dati esterni a Databricks possono essere federati attraverso il livello di virtualizzazione di Stardog e connessi ai dati all'interno di Databricks. Inoltre, è possibile inferire nuove relazioni tra entità senza modellarle esplicitamente nel knowledge graph utilizzando tecniche come l'inferenza statistica e/o logica. Poiché Databricks e Stardog lavorano insieme in modo impeccabile, la combinazione fornisce un'esperienza end-to-end che semplifica query e analisi complesse cross-domain. Inoltre, il livello semantico diventa un livello vivo, condivisibile e facile da usare come parte di una fondazione di enterprise data fabric, fornendo conoscenza a livello aziendale a supporto di nuove iniziative data-driven.
Iniziare con Databricks e Stardog
In questo blog, abbiamo fornito una panoramica di alto livello su come Stardog abilita un livello di dati semantico basato su knowledge graph sulla Databricks Lakehouse Platform. Per una panoramica approfondita, consulta la nostra demo dettagliata. Stardog fornisce ai knowledge worker insight critici just-in-time su un universo connesso di asset di dati per potenziare le loro analisi e accelerare il valore dei loro investimenti in data lake. Utilizzando Databricks e Stardog insieme, i team di dati e analytics possono stabilire rapidamente una data fabric che si evolve con le crescenti esigenze della tua organizzazione.
Per iniziare con Databricks e Stardog, richiedi una prova gratuita qui sotto:
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.