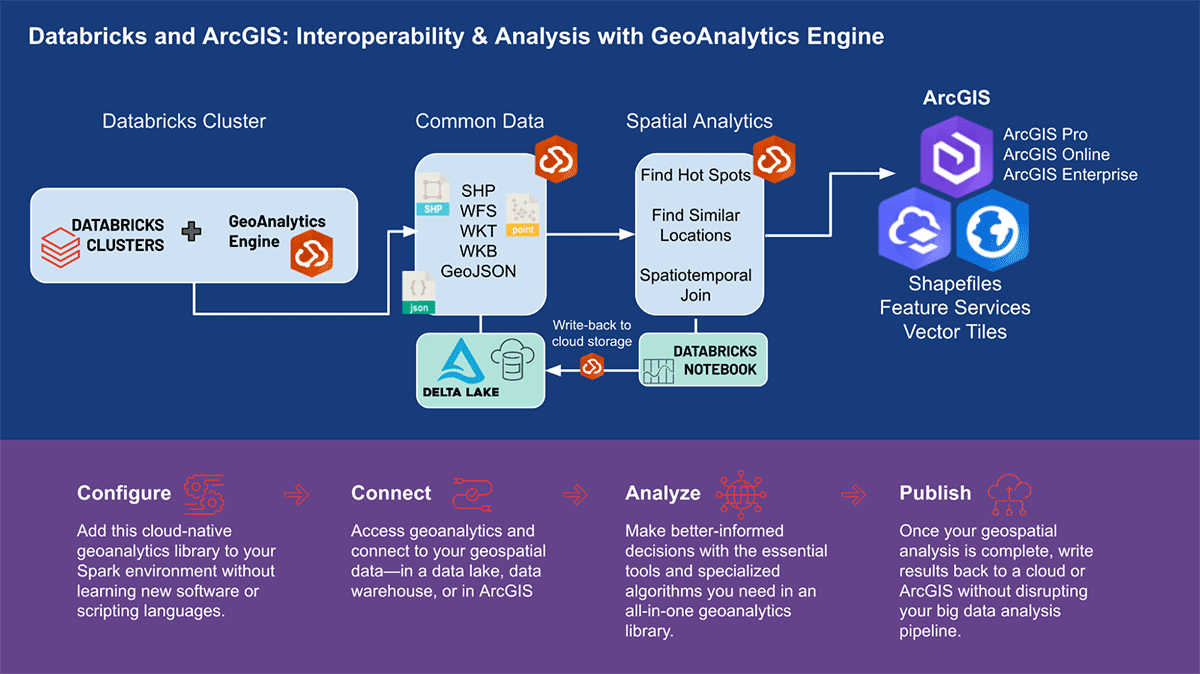
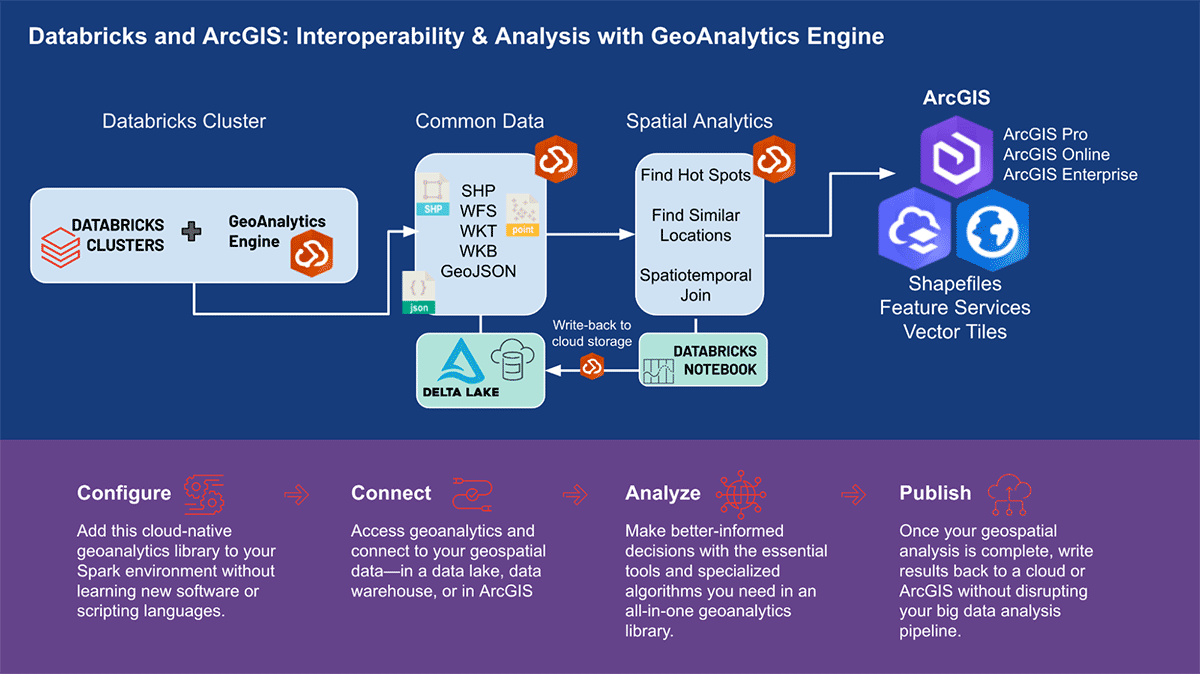
ArcGIS GeoAnalytics Engine in Databricks
Analisi Geospaziali Scalabili in un Flusso di Lavoro di Data Science
di Kent Marten e Arif Masrur
Questo è un post collaborativo di Esri e Databricks. Ringraziamo il Senior Solution Engineer Arif Masrur, Ph.D. di Esri per il suo contributo.
I progressi nel campo dei big data hanno permesso alle organizzazioni di tutti i settori di affrontare questioni scientifiche, sociali e di business di importanza critica. Lo sviluppo di infrastrutture per big data assiste analisti, ingegneri e scienziati dei dati nell'affrontare le sfide fondamentali del lavoro con i big data: volume, velocità, veridicità, valore e varietà. Tuttavia, l'elaborazione e l'analisi di enormi quantità di dati geospaziali presentano una serie di sfide proprie. Ogni giorno vengono generati centinaia di exabyte di dati geolocalizzati. Questi set di dati contengono un'ampia gamma di connessioni e relazioni complesse tra entità del mondo reale, richiedendo strumenti avanzati in grado di collegare efficacemente queste relazioni sfaccettate attraverso operazioni ottimizzate come join spaziali e spazio-temporali. I numerosi formati geospaziali che devono essere acquisiti, verificati e standardizzati per un'analisi scalabile ed efficiente aumentano la complessità.
Alcune delle difficoltà nel lavorare con dati geografici sono affrontate dal recentemente annunciato supporto per espressioni H3 integrate in Databricks. Tuttavia, ci sono molti casi d'uso geospaziali, alcuni dei quali sono più complessi o incentrati sulla geometria piuttosto che sugli indici di griglia. Gli utenti possono lavorare con una serie di strumenti e librerie sulla piattaforma Databricks sfruttando le numerose funzionalità di Lakehouse.
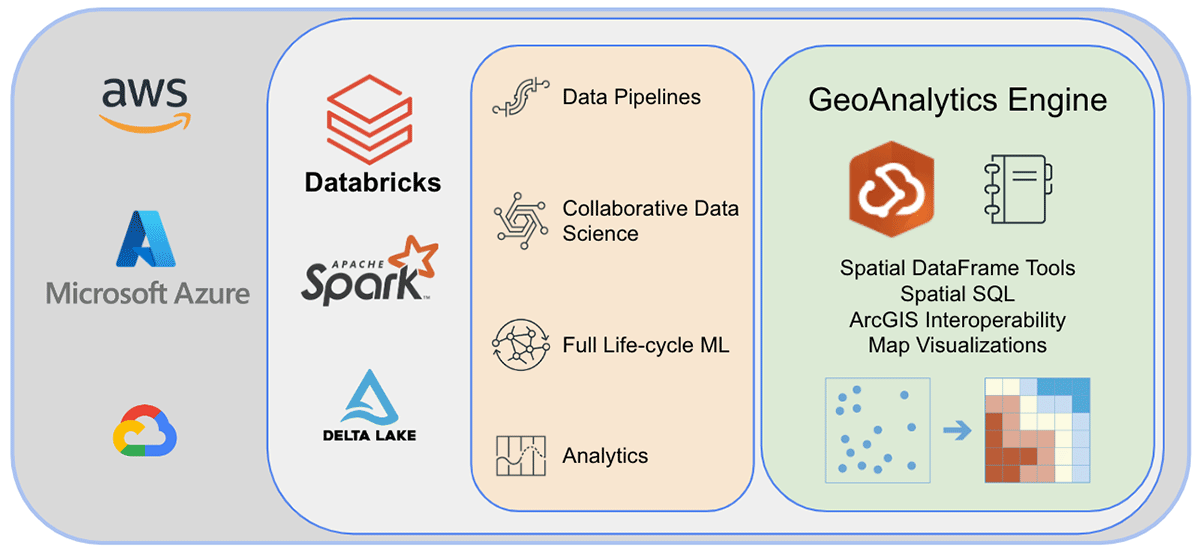
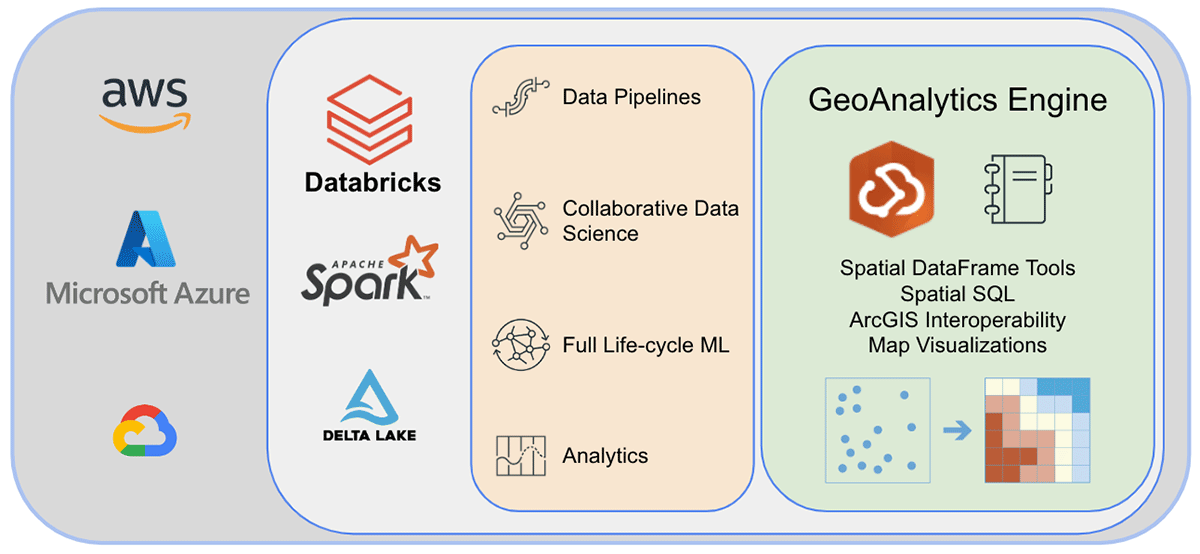
Esri, il principale fornitore di software GIS al mondo, offre un set completo di strumenti, tra cui ArcGIS Enterprise, ArcGIS Pro e ArcGIS Online, per risolvere le sfide di geo-analisi sopra menzionate. Le organizzazioni e i professionisti dei dati che utilizzano Databricks necessitano di accedere agli strumenti con cui svolgono il loro lavoro quotidiano al di fuori dell'ambiente ArcGIS. È per questo che siamo entusiasti di annunciare la prima versione di ArcGIS GeoAnalytics Engine (di seguito denominato GA Engine), che consente a data scientist, ingegneri e analisti di analizzare i propri dati geospaziali all'interno dei loro ambienti di analisi di big data esistenti. Nello specifico, questo engine è un plugin per Apache Spark™ che estende i data frame con elaborazione e analisi spaziale molto veloci, pronto per essere eseguito in Databricks.
Benefici dell'ArcGIS GeoAnalytics Engine
Il GA Engine di Esri consente ai data scientist di accedere a funzioni e strumenti geoanalitici all'interno del loro ambiente Databricks. Le caratteristiche principali del GA Engine sono:
- Oltre 120 funzioni SQL spaziali—Crea geometrie, testa relazioni spaziali e altro ancora utilizzando la sintassi Python o SQL
- Potenti strumenti di analisi—Esegui flussi di lavoro comuni di analisi spazio-temporale e statistica con poche righe di codice
- Indicizzazione spaziale automatica—Esegui join spaziali ottimizzati e altre operazioni immediatamente
- Interoperabilità con sorgenti dati GIS comuni —Carica e salva dati da shapefile, feature service e vector tile
- Cloud-native e Spark-native—Testato e pronto per l'installazione su Databricks
- Facile da usare—Crea pipeline di big data spazialmente abilitate con un'API Python intuitiva che estende PySpark
Funzioni SQL e strumenti di analisi
Attualmente il GA Engine fornisce oltre 120 funzioni SQL e più di 15 strumenti di analisi spaziale che supportano analisi spaziali e spazio-temporali avanzate. Essenzialmente, le funzioni del GA Engine estendono l'API Spark SQL abilitando query spaziali su colonne di DataFrame. Queste funzioni possono essere chiamate con funzioni Python o in un'istruzione di query PySpark SQL e consentono di creare geometrie, operare su geometrie, valutare relazioni spaziali, riassumere geometrie e altro ancora. A differenza delle funzioni SQL che operano riga per riga utilizzando una o due colonne, gli strumenti del GA Engine sono consapevoli di tutte le colonne di un DataFrame e utilizzano tutte le righe per calcolare un risultato, se necessario. Queste ampie gamme di strumenti di analisi consentono di gestire, arricchire, riassumere o analizzare interi set di dati.
|
|
Il GA Engine è un potente strumento di analisi. Non va però trascurato quanto il GA Engine semplifichi il lavoro con i formati GIS comuni. La documentazione del GA Engine include numerosi tutorial per leggere e scrivere da e verso Shapefile e Feature Service. La capacità di elaborare dati geospaziali utilizzando formati GIS offre una grande interoperabilità tra Databricks e i prodotti Esri.
{kind=link}
GA engine per diversi casi d'uso
Esaminiamo alcuni scenari d'uso di vari settori per mostrare come il GA Engine di ESRI gestisce grandi quantità di dati spaziali. Il supporto per l'analisi spaziale e spazio-temporale scalabile è pensato per aiutare qualsiasi azienda a prendere decisioni critiche. In tre diversi domini di analisi dei dati: mobilità, transazioni dei consumatori e servizi pubblici, ci concentreremo sulla rivelazione di insight geografici.
Analisi dei dati di mobilità
I dati di mobilità sono in costante crescita e possono essere suddivisi in due categorie: movimento umano e movimento dei veicoli. I dati sulla mobilità umana raccolti dagli utenti di smartphone nelle aree di servizio dei telefoni cellulari forniscono uno sguardo più approfondito sui modelli di attività umana. I dati di movimento di milioni di veicoli connessi forniscono ricche informazioni in tempo reale sui volumi di traffico direzionale, flussi di traffico, velocità medie, congestione e altro ancora. Questi set di dati sono tipicamente grandi (miliardi di record) e complessi (centinaia di attributi). Questi dati richiedono analisi spaziali e spazio-temporali che vanno oltre l'analisi spaziale di base, con accesso immediato a strumenti statistici avanzati e funzioni di geoanalisi specializzate.
Iniziamo esaminando un esempio di analisi del movimento umano basato sui dati Cell Analytics™ del partner Esri Ookla®. Ookla® raccoglie big data sulle prestazioni del servizio wireless globale, sulla copertura e sulle misurazioni del segnale basate sull'applicazione Speedtest®. I dati includono informazioni sul dispositivo sorgente, sulla connettività della rete mobile, sulla posizione e sul timestamp. In questo caso, abbiamo lavorato con un sottoinsieme di dati contenente circa 16 miliardi di record. Con strumenti non ottimizzati per operazioni parallele in Apache Spark™, la lettura di questi dati ad alto volume e la loro abilitazione per operazioni spazio-temporali potrebbero richiedere ore di elaborazione. Utilizzando una singola riga di codice con GeoAnalytics Engine, questi dati possono essere acquisiti da file parquet in pochi secondi.
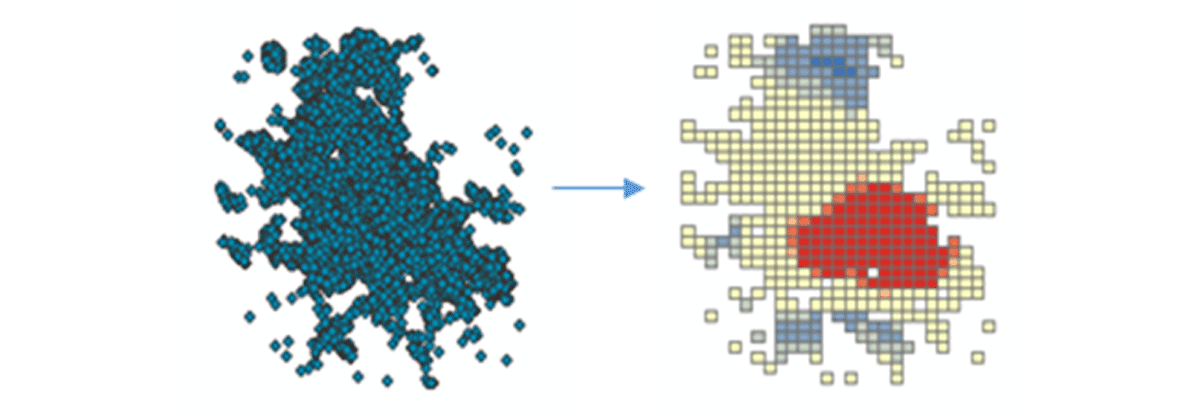
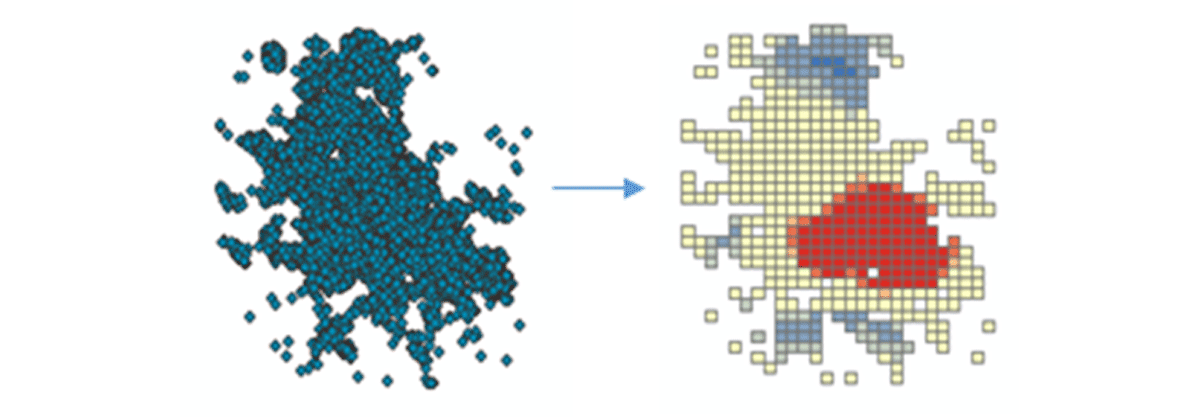
Per iniziare a derivare insight azionabili, approfondiremo i dati con una semplice domanda: Qual è il modello spaziale dei dispositivi mobili negli Stati Uniti continentali? Ciò ci consentirà di iniziare a caratterizzare la presenza e l'attività umana. Lo strumento FindHotSpots può essere utilizzato per identificare cluster spaziali statisticamente significativi di valori elevati (hot spot) e valori bassi (cold spot).
{kind=link}
Il DataFrame risultante delle aree ad alta densità è stato visualizzato e stilizzato usando Matplotlib (Figura 2). Ha mostrato molti record di connessioni di dispositivi (rosso) rispetto alle posizioni con bassa densità di dispositivi connessi (blu) negli Stati Uniti contigui. Come previsto, le principali aree urbane hanno indicato una maggiore densità di dispositivi connessi.
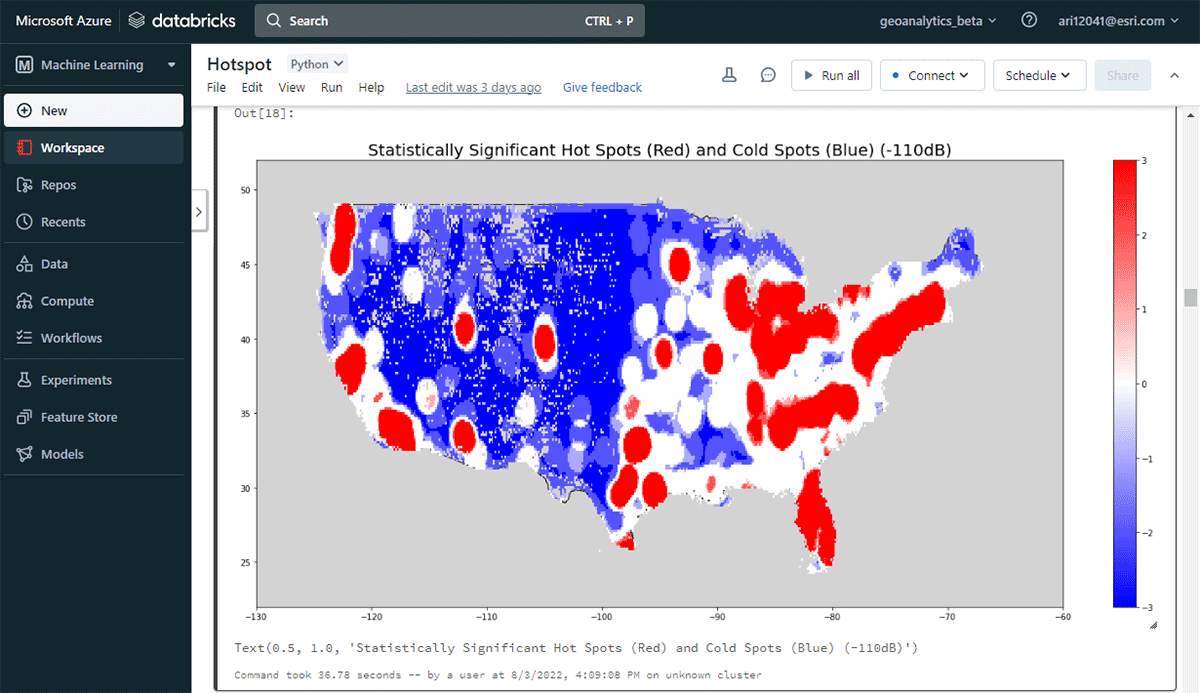
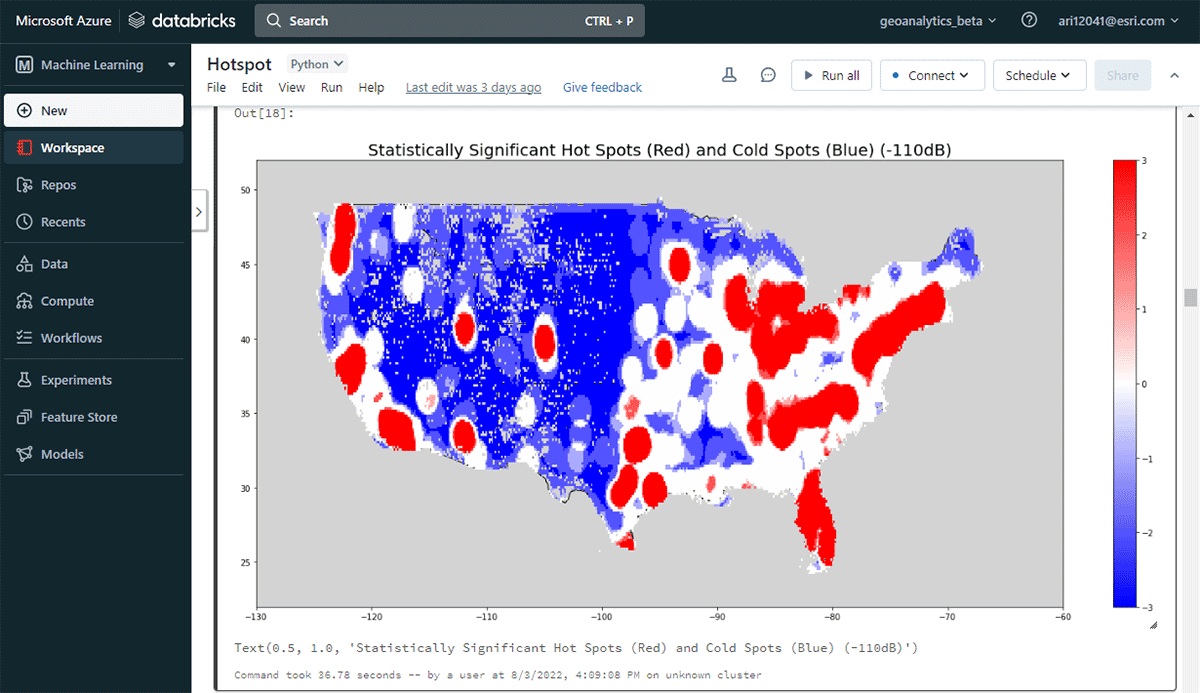{kind=link}
Successivamente, ci siamo chiesti: la potenza del segnale della rete mobile segue uno schema omogeneo negli Stati Uniti? Per rispondere a ciò, lo strumento AggregatePoints è stato utilizzato per riassumere le osservazioni dei dispositivi in celle esagonali per identificare aree con un servizio cellulare particolarmente forte e particolarmente debole (Figura 3). Abbiamo utilizzato rsrp (reference signal received power) – un valore utilizzato per misurare la potenza del segnale della rete mobile – per calcolare la statistica media su celle da 15 km. Questa analisi ha illuminato che la potenza del segnale cellulare non è coerente - invece tende ad essere più forte lungo le principali reti stradali e le aree urbane.
Oltre a tracciare il risultato utilizzando st_plotting, abbiamo utilizzato il modulo arcgis, pubblicato il DataFrame risultante come feature layer in ArcGIS Online e creato una visualizzazione interattiva basata su mappe.
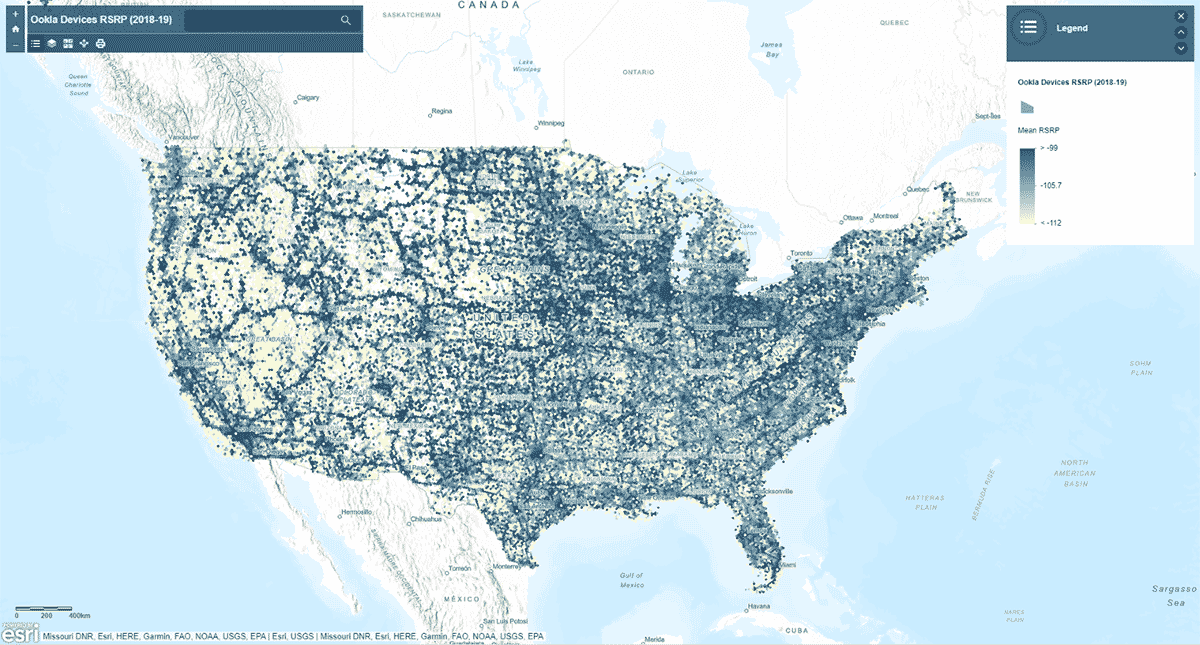
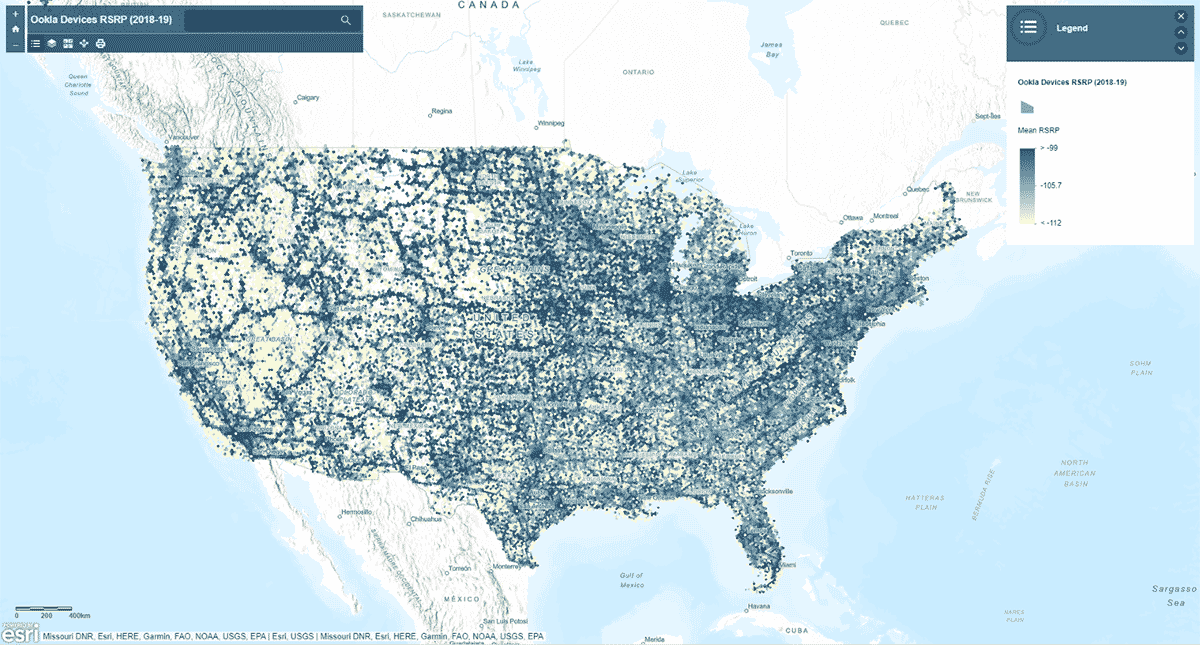{kind=link}
Ora che comprendiamo gli ampi pattern spaziali dei dispositivi mobili, come possiamo ottenere informazioni più approfondite sui pattern di attività umana? Dove trascorrono il tempo le persone? Per rispondere a ciò, abbiamo utilizzato FindDwellLocations per cercare dispositivi a Denver, CO che hanno trascorso almeno 5 minuti nella stessa area generale il 31 maggio 2019 (venerdì). Questa analisi può aiutarci a comprendere le posizioni con attività più prolungate, ovvero le destinazioni dei consumatori, e separarle dall'attività di viaggio generale.
Il dataframe result_dwell ci fornisce i dispositivi o gli individui che si sono soffermati in diverse posizioni. La heatmap della durata di permanenza nella Figura 4 fornisce una panoramica di dove le persone trascorrono il loro tempo a Denver.
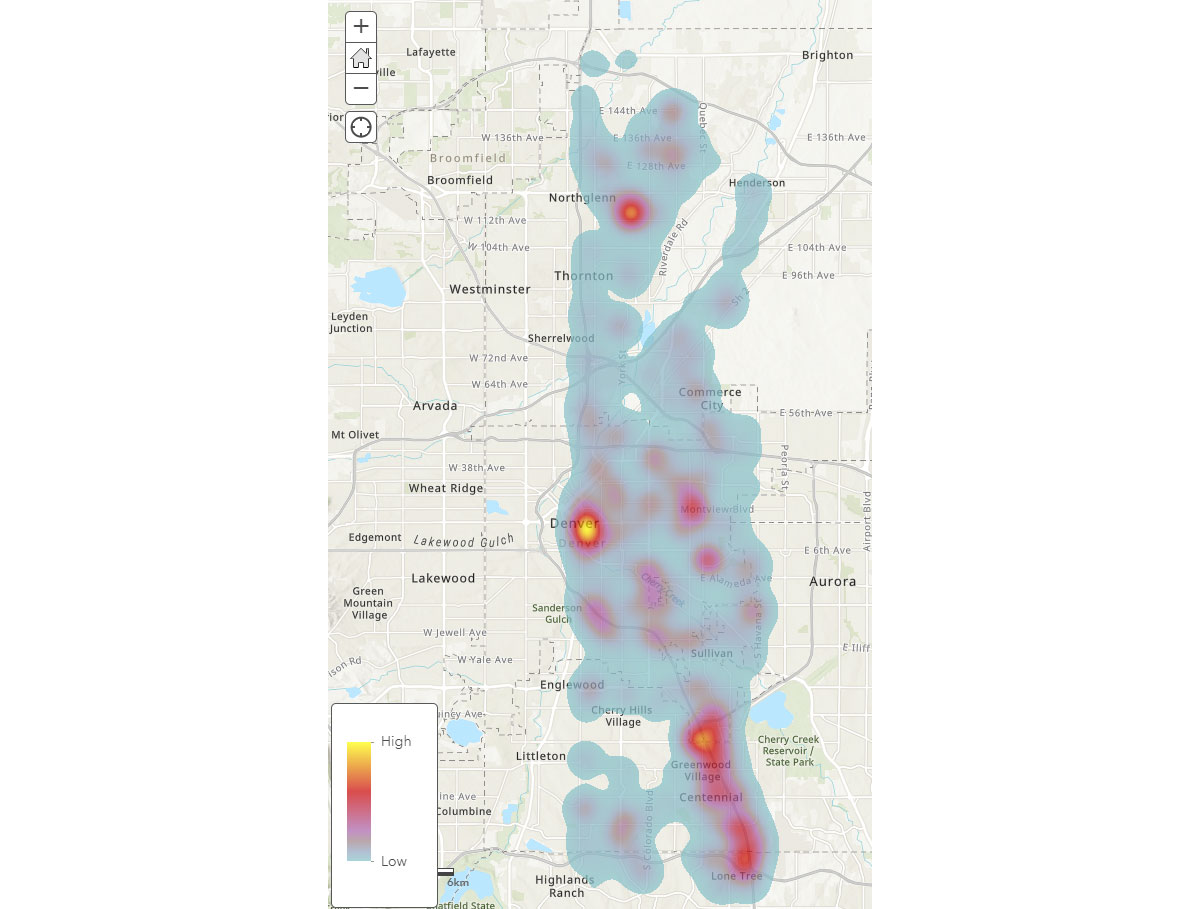
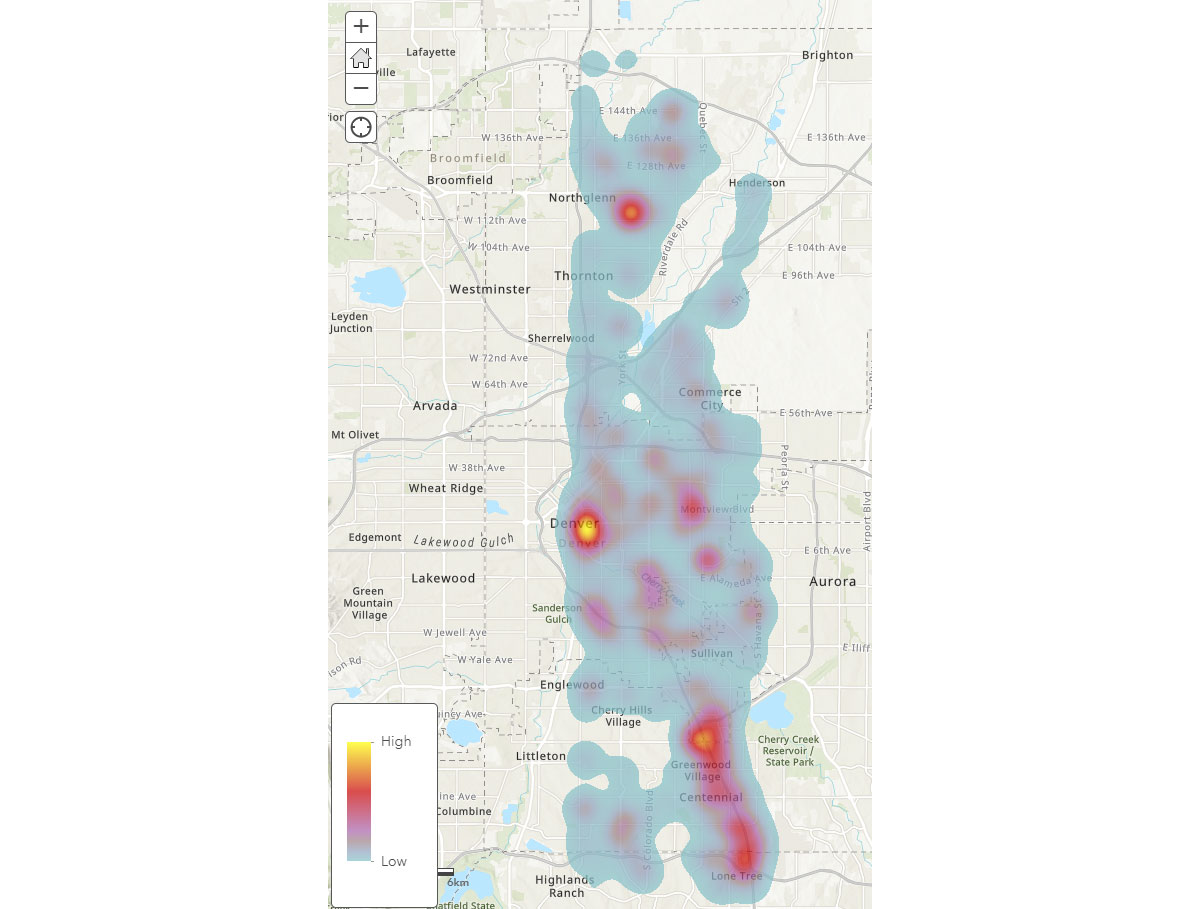{kind=link}
Abbiamo anche voluto esplorare le posizioni che le persone visitano per durate più lunghe. Per raggiungere questo obiettivo, abbiamo utilizzato Overlay per identificare quali impronte di punti di interesse (POI) dai dati Geometry di SafeGraph intersecavano le posizioni di permanenza (dal DataFrame result_dwell) il 31 maggio 2019. Utilizzando la funzione groupBy, abbiamo contato i tempi di permanenza dei dispositivi connessi per ciascuna delle principali categorie di POI. La Figura 5 evidenzia che alcuni POI urbani a Denver coincidevano con tempi di permanenza più lunghi, tra cui negozi di forniture per ufficio, cartoleria e regali, e uffici di appaltatori commerciali.
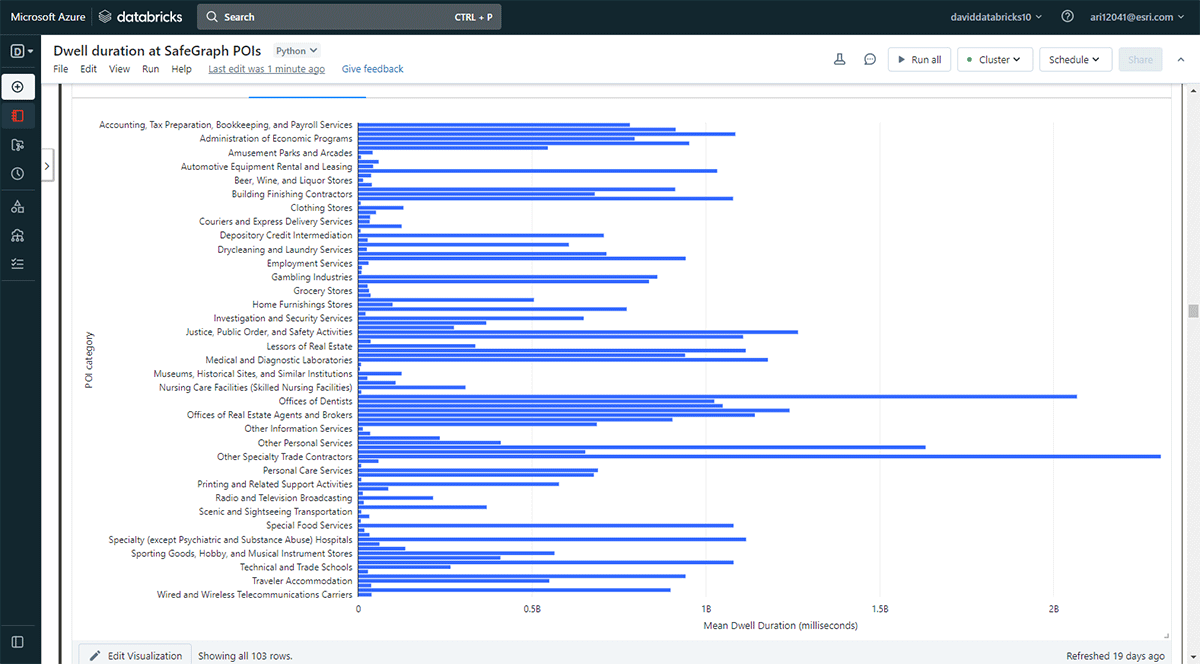
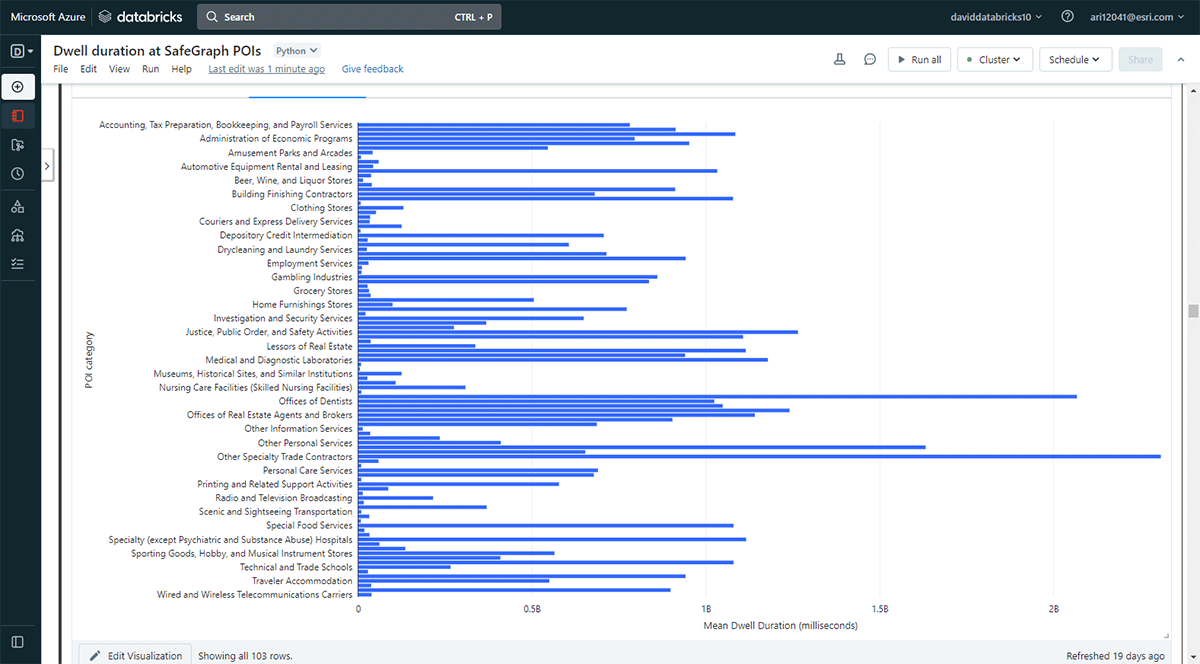{kind=link}
Questo flusso di lavoro analitico di esempio con dati Cell AnalyticsTM potrebbe essere applicato o riutilizzato per caratterizzare più specificamente le attività delle persone. Ad esempio, potremmo utilizzare i dati per ottenere informazioni sul comportamento dei consumatori nei pressi di punti vendita al dettaglio. Quali ristoranti o caffetterie hanno visitato questi dispositivi o individui dopo aver fatto acquisti da Walmart o Costco? Inoltre, questi set di dati possono essere utili per la gestione di pandemie e disastri naturali. Ad esempio, le persone seguono le linee guida di emergenza per la salute pubblica durante una pandemia? Quali aree urbane potrebbero essere i prossimi punti critici di COVID-19 o di scarsa qualità dell'aria indotta da incendi boschivi? Vediamo disparità nelle mobilità e nelle attività umane dovute alla disuguaglianza di reddito su una scala geografica più ampia?
Analisi dei dati transazionali
I dati transazionali aggregati su punti di interesse contengono ricche informazioni su come e quando le persone spendono i loro soldi in luoghi specifici. La pura mole e velocità di questi dati richiedono strumenti di analisi spaziale avanzati per comprendere chiaramente il comportamento di spesa dei consumatori: Come differisce il comportamento dei consumatori in base alla geografia? Quali attività tendono a co-localizzarsi per essere redditizie? Quali merci acquistano i consumatori in un negozio fisico (ad esempio, Walmart) rispetto ai prodotti che acquistano online? Il comportamento dei consumatori cambia durante eventi estremi come il COVID-19?
Queste domande possono essere risolte utilizzando i dati SafeGraph Spend e il GeoAnalytics Engine. Ad esempio, volevamo identificare come i modelli di viaggio delle persone sono stati influenzati durante il COVID-19 negli Stati Uniti. Per raggiungere questo obiettivo, abbiamo analizzato i dati SafeGraph Spend a livello nazionale dal 2020 al 2021. Di seguito, mostriamo la spesa annuale (USD) dei consumatori per auto a noleggio aziendali, aggregata alle contee statunitensi. Dopo aver pubblicato il DataFrame su ArcGIS Online, abbiamo creato una mappa interattiva utilizzando il widget Swipe di ArcGIS Web AppBuilder per esplorare rapidamente quali contee hanno mostrato cambiamenti nel tempo (Figura 6).
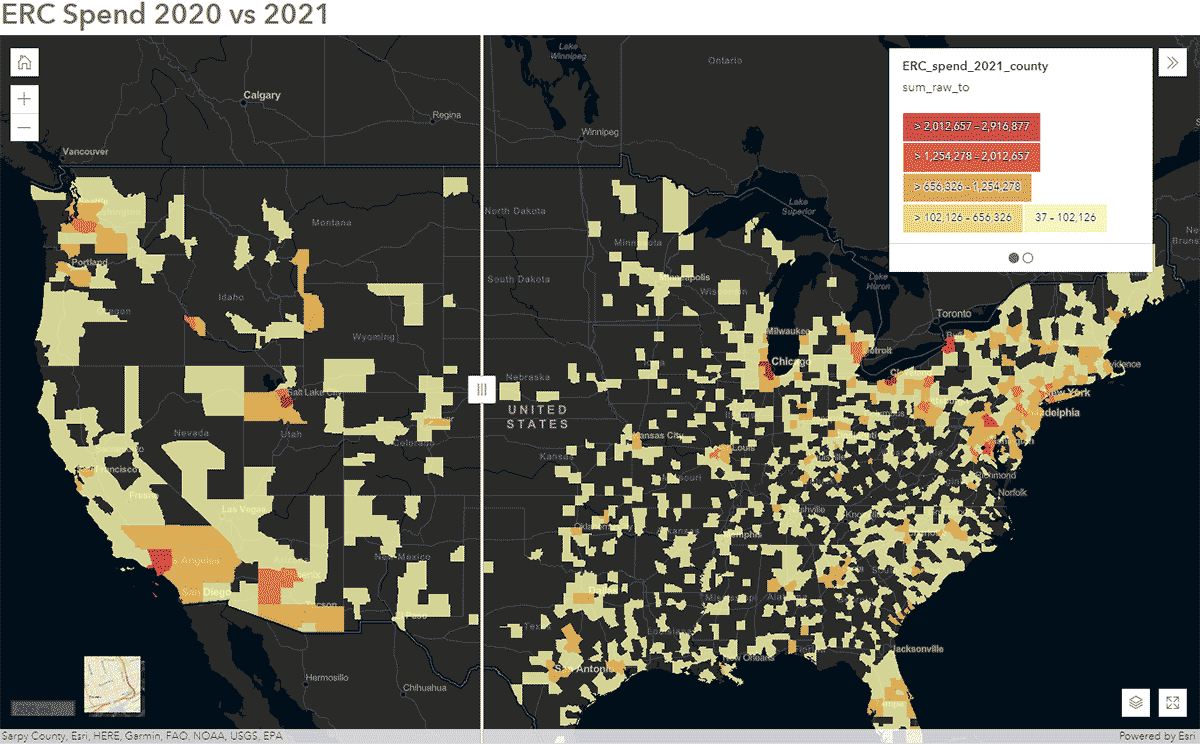
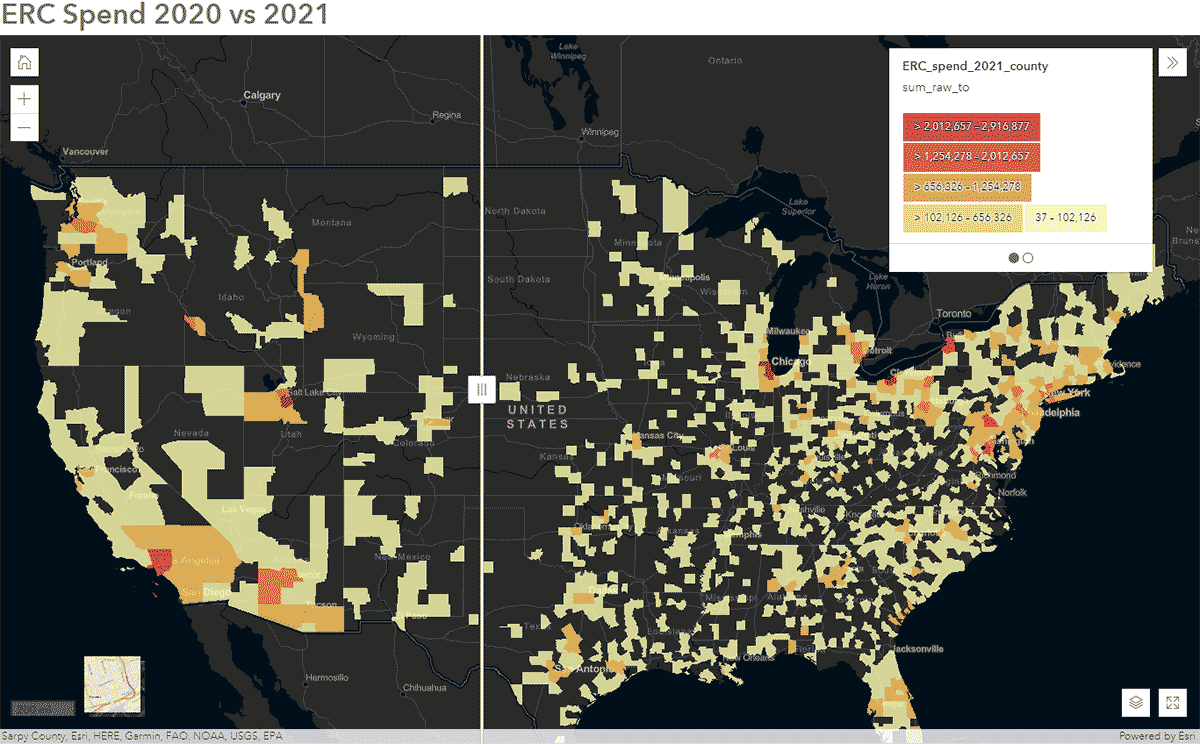{kind=link}
Successivamente, abbiamo esplorato quale contea degli Stati Uniti avesse la spesa online più alta in un anno e altre contee con modelli di spesa simili per lo shopping online, considerando le somiglianze nella popolazione e nei modelli di vendita di prodotti agricoli. Sulla base del filtraggio degli attributi del DataFrame della spesa, abbiamo identificato che Sacramento era in cima alla lista per la spesa di shopping online nel 2020. Per esaminare aree simili, abbiamo utilizzato lo strumento FindSimilarLocations per identificare le contee più simili o dissimili a Sacramento in termini di shopping e spesa online, ma rispetto alle somiglianze nella popolazione e nell'agricoltura (area totale di terreni coltivati e vendite medie di prodotti agricoli) (Figura 7).
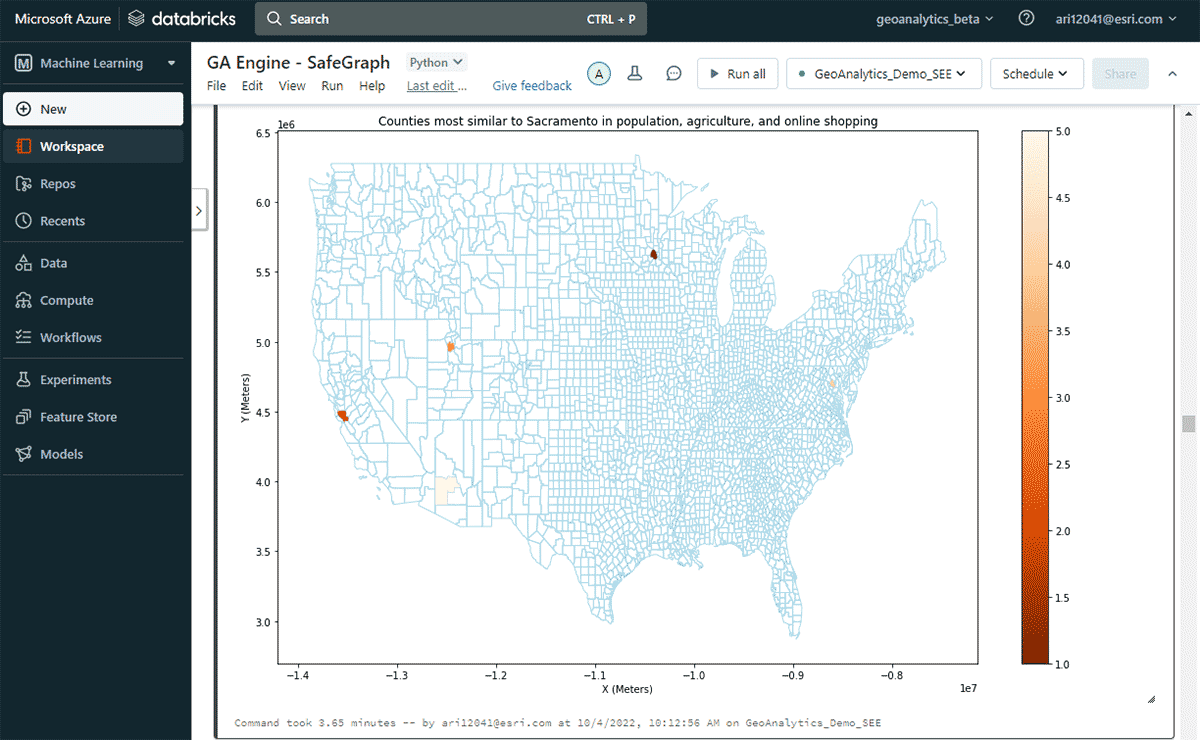
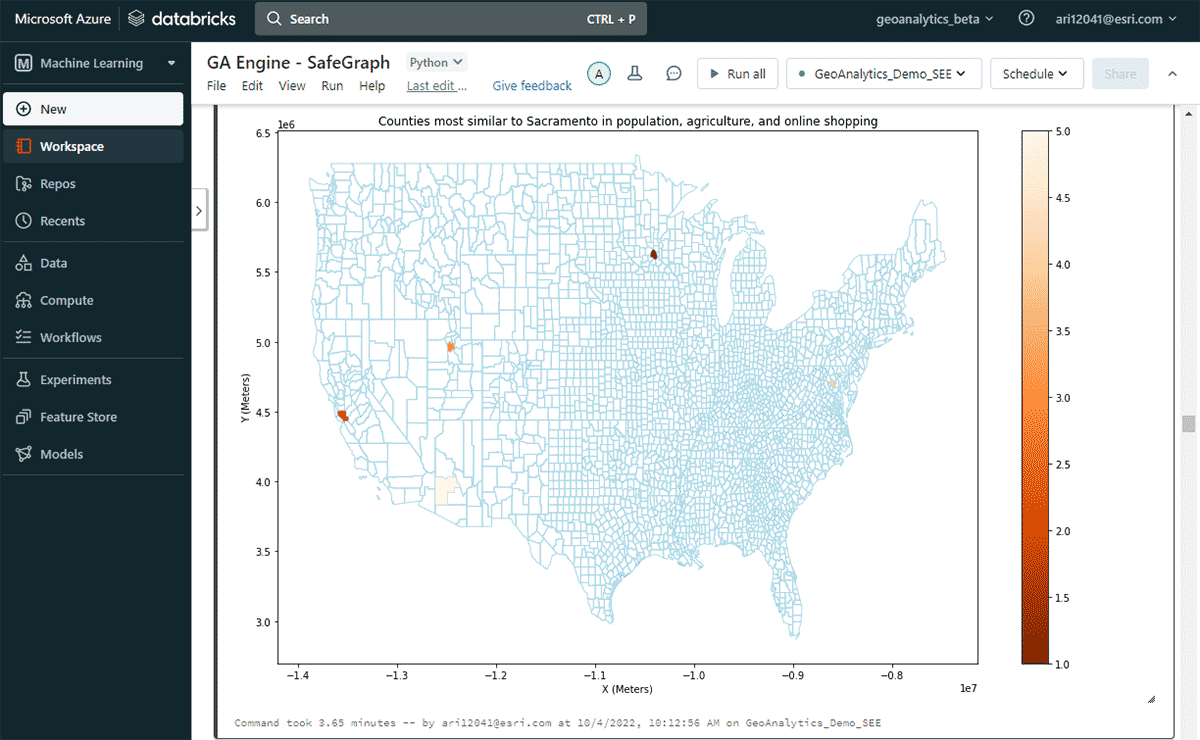{kind=link}
Analisi di dati di servizi pubblici
I set di dati dei servizi pubblici, come i registri delle chiamate al 311, contengono informazioni preziose sui servizi non di emergenza forniti ai residenti. Il monitoraggio tempestivo e l'identificazione di pattern spazio-temporali in questi dati possono aiutare i governi locali a pianificare e allocare risorse per una risoluzione efficiente delle chiamate al 311.
In questo esempio, il nostro obiettivo era leggere, elaborare/pulire e filtrare rapidamente circa 27 milioni di record di richieste di servizio 311 di New York dal 2010 a febbraio 2022, e quindi rispondere alle seguenti domande per l'area di New York City:
- Quali sono le aree con i tempi medi di risposta 311 più lunghi?
- Ci sono pattern nei tipi di reclamo con tempi medi di risposta lunghi?
Per rispondere alla prima domanda, sono state identificate le chiamate con i tempi di risposta più lunghi. Successivamente, i dati sono stati filtrati per includere record più lunghi della media più tre deviazioni standard.
Per rispondere alla seconda domanda sulla ricerca di gruppi significativi di reclami, abbiamo utilizzato lo strumento GroupByProximity per cercare reclami dello stesso tipo che rientrassero entro 500 piedi e 5 giorni l'uno dall'altro. Abbiamo quindi filtrato per gruppi con più di 10 record e creato un inviluppo convesso per ciascun gruppo di reclami, che sarà utile per visualizzare i loro pattern spaziali (Figura 8). Utilizzando st.plot() - un metodo di plotting leggero incluso con ArcGIS GeoAnalytics Engine - le geometrie memorizzate in un DataFrame possono essere visualizzate istantaneamente.
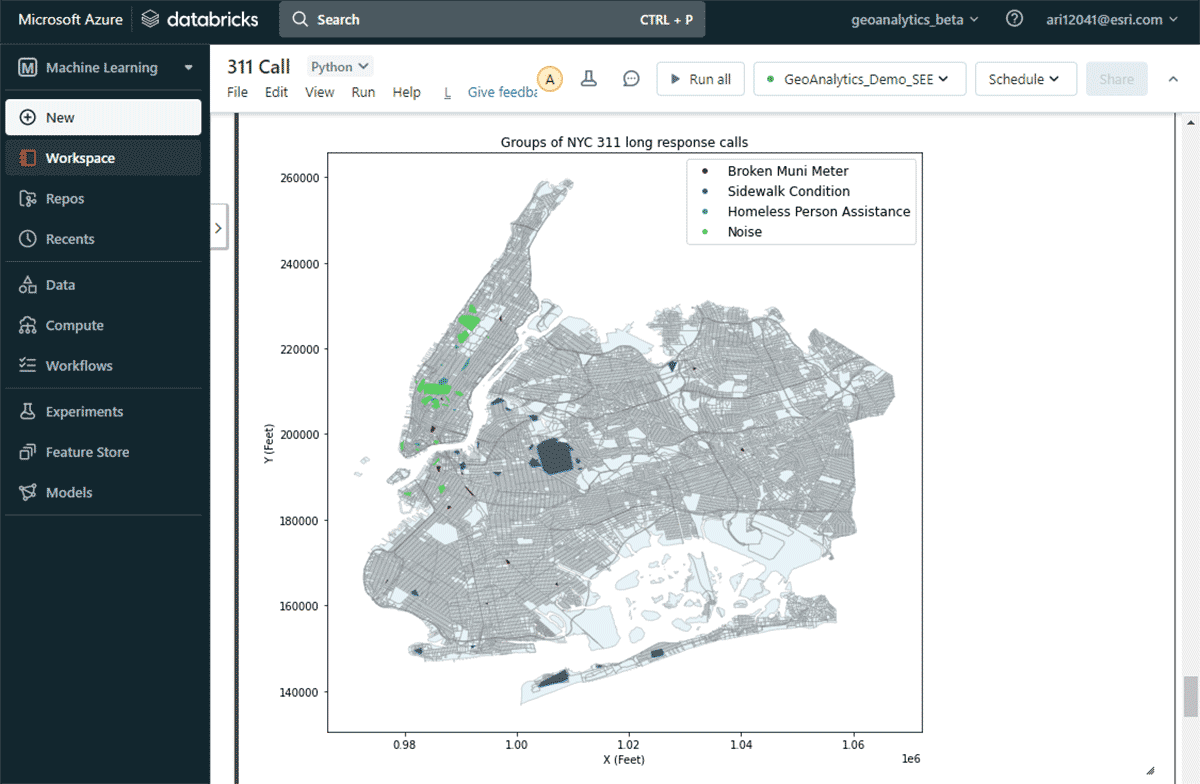
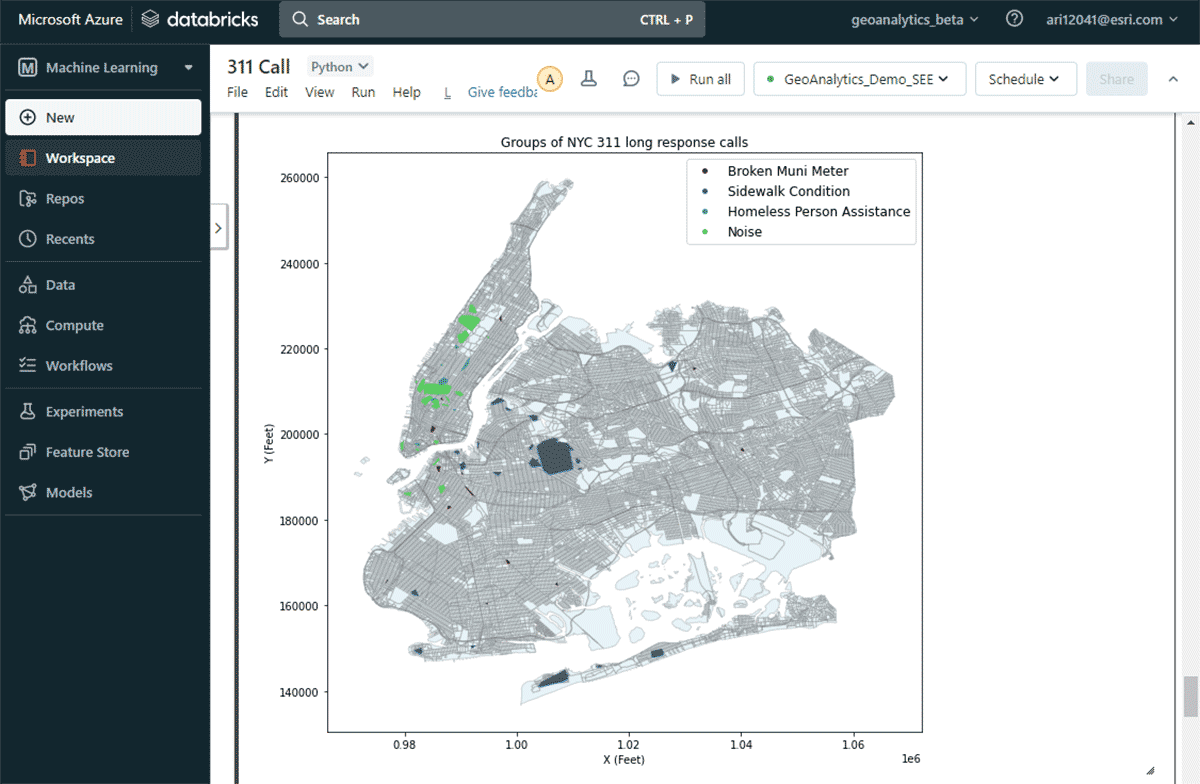{kind=link}
Con questa mappa, è stato facile identificare le distribuzioni spaziali dei diversi tipi di reclamo a New York City. Ad esempio, c'è stato un numero considerevole di reclami per rumore nelle aree centrali e meridionali di Manhattan, mentre le condizioni dei marciapiedi sono una preoccupazione principale intorno a Brooklyn e Queens. Queste rapide informazioni basate sui dati possono aiutare i decisori a intraprendere azioni concrete.
Benchmark
Le prestazioni sono un fattore decisivo per molti clienti che cercano di scegliere una soluzione di analisi. I test di benchmark di Esri hanno dimostrato che GA Engine offre prestazioni significativamente migliori nell'esecuzione di analisi spaziali su big data rispetto ai pacchetti open-source. I miglioramenti delle prestazioni aumentano all'aumentare delle dimensioni dei dati, quindi gli utenti vedranno prestazioni ancora migliori per set di dati più grandi. Ad esempio, la tabella seguente mostra i tempi di calcolo per un'attività di intersezione spaziale che unisce due set di dati di input (punti e poligoni) con dimensioni variabili fino a milioni di record di dati. Ogni scenario di join è stato testato su un cluster Databricks singolo e multi-macchina.
| Input per l'intersezione spaziale | Tempo di calcolo (secondi) | ||
|---|---|---|---|
| Dataset sinistro | Dataset destro | Macchina singola | Multi-macchina |
| 50 poligoni | 6K punti | 6 | 5 |
| 3K poligoni | 6K punti | 10 | 5 |
| 3K poligoni | 2M punti | 19 | 9 |
| 3K poligoni | 17M punti | 46 | 16 |
| 220K poligoni | 17M punti | 80 | 29 |
| 11M poligoni | 17M punti | 515 (8.6 min) | 129 (2.1 min) |
| 11M poligoni | 19M punti | 1.373 (22 min) | 310 (5 min) |
Architettura e installazione
Prima di concludere, diamo un'occhiata sotto il cofano dell'architettura di GeoAnalytics Engine ed esploriamo come funziona. Poiché è cloud-native e Spark-native, possiamo utilizzare facilmente la libreria GeoAnalytics in un ambiente Spark basato su cloud. L'installazione del deployment di GeoAnalytics Engine nell'ambiente Databricks richiede una configurazione minima. Caricherai il modulo tramite un file JAR, e quindi verrà eseguito utilizzando le risorse fornite dal cluster.
L'installazione prevede 2 passaggi di base che si applicano ad AWS, Azure e GCP:
- Prepara l'area di lavoro
- Crea o avvia un'area di lavoro Databricks
- Carica il file JAR di GeoAnalytics nel DBFS
- Aggiungi e abilita uno script di inizializzazione
- Crea un cluster
{kind=link}
Dopo l'installazione, gli utenti analizzeranno utilizzando un notebook Python collegato all'ambiente Spark. Puoi accedere istantaneamente ai dati della Databricks Lakehouse Platform ed eseguire analisi. Dopo l'analisi, puoi persistere i risultati scrivendoli nel tuo data lake, SQL Warehouse, servizi BI (Business Intelligence) o ArcGIS.
{kind=link}
Strada da percorrere
In questo blog, abbiamo introdotto la potenza di ArcGIS GeoAnalytics Engine su Databricks e dimostrato come possiamo affrontare insieme i casi d'uso geospaziali più impegnativi. Fai riferimento a questo Notebook di Databricks per un riferimento dettagliato degli esempi mostrati sopra. In futuro, GeoAnalytics Engine sarà potenziato con funzionalità aggiuntive tra cui l'esportazione GeoJSON, il supporto per H3 binning e algoritmi di clustering come K-Nearest Neighbor.
GeoAnalytics Engine funziona con Databricks su Azure, AWS e GCP. Ti preghiamo di contattare i tuoi team di account Databricks ed Esri per i dettagli sulla distribuzione della libreria GeoAnalytics nel tuo ambiente Databricks preferito. Per saperne di più su GeoAnalytics Engine ed esplorare come accedere a questo potente prodotto, visita il sito web di Esri.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.