Caricamento di una dimensione a variazione lenta (Slowly Changing Dimension Type 2) di un data warehouse utilizzando Matillion sulla Databricks Lakehouse Platform
Gestione di SCD Tipo 2 con Matillion su Databricks
di David Wilmer e Abhishek Dey
Questo è un post collaborativo tra Databricks e Matillion. Ringraziamo David Willmer, Product Marketing di Matillion, per il suo contributo.
Poiché sempre più clienti modernizzano i loro legacy Enterprise Data Warehouse e le vecchie piattaforme ETL, stanno cercando di adottare uno stack dati cloud moderno utilizzando la Databricks Lakehouse Platform e Matillion per l'ETL basato su GUI. La piattaforma ELT visuale e low-code di Matillion rende facile per chiunque integrare dati da qualsiasi origine in Databricks SQL Warehouse, rendendo così i dati per analytics e AI pronti per il business e più veloci.
Questo blog ti mostrerà come creare una pipeline ETL che carica una Slowly Changing Dimensions (SCD) Type 2 utilizzando Matillion nella Databricks Lakehouse Platform. Matillion dispone di un'interfaccia utente moderna basata su browser con funzionalità ETL/ELT push-down. Puoi facilmente integrare i tuoi warehouse o cluster Databricks SQL con Matillion. Ora, se ti stai chiedendo come connetterti a Matillion usando Databricks, il modo più semplice per farlo è usare Partner Connect, che semplifica il processo di connessione di un SQL Warehouse o cluster esistente nel tuo workspace Databricks a Matillion. Ecco i passaggi dettagliati.
Cos'è una Slowly Changing Dimension (SCD) di tipo 2?
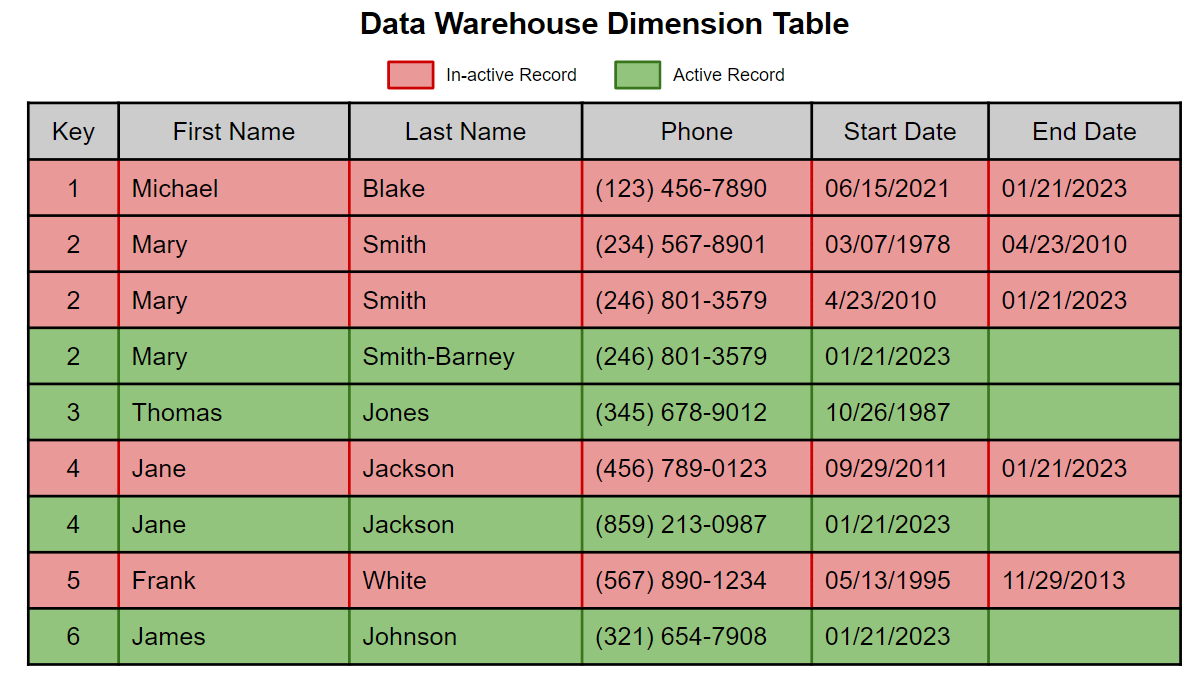
Una SCD di tipo 2 è una tecnica comune per preservare la cronologia in una tabella dimensionale utilizzata in qualsiasi architettura di data warehousing/modellazione. Le righe inattive hanno un flag booleano come la colonna ACTIVE_RECORD impostata su 'F' o una data di inizio e fine. Tutte le righe attive vengono visualizzate restituendo una query in cui la data di fine è null o ACTIVE_RECORD non è uguale a 'F'
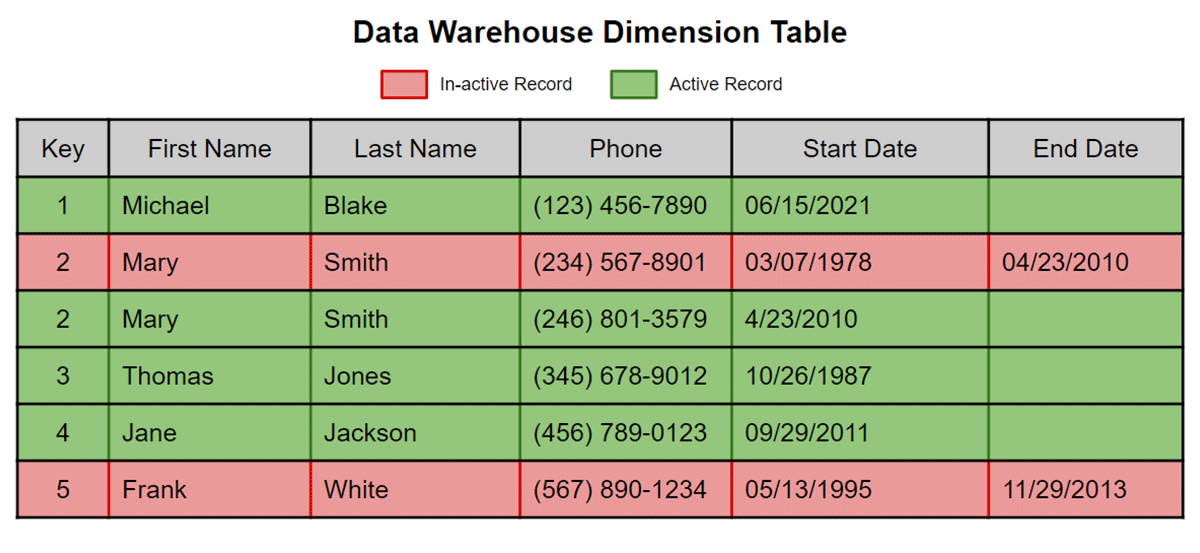
Matillion ETL for Delta Lake on Databricks utilizza un approccio in due fasi per la gestione delle Slowly Changing Dimensions di tipo 2. Questo approccio in due fasi prevede prima l'identificazione delle modifiche nei record in arrivo e la loro marcatura in una tabella o vista temporanea. Una volta che tutti i record in arrivo sono marcati, è possibile intervenire sulla tabella dimensionale di destinazione per completare l'aggiornamento.
Ora, diamo un'occhiata più da vicino all'implementazione delle trasformazioni SCD Type 2 utilizzando Matillion, dove il tuo target è una tabella Delta Lake e l'opzione di calcolo sottostante utilizzata è un Databricks SQL Warehouse.
Fase 1: Preparazione delle modifiche dimensionali
Guardando alla Fase 1 qui sotto, la pipeline ETL legge i dati dalla nostra tabella dimensionale Delta Lake esistente e identifica solo i record più recenti o attivi (questo è il flusso dati inferiore). Allo stesso tempo, leggeremo tutti i nostri nuovi dati, assicurandoci che la chiave primaria prevista sia univoca in modo da non interrompere il processo di rilevamento delle modifiche (questo è il flusso dati superiore). Questi due percorsi convergono quindi nel componente di rilevamento delle modifiche.
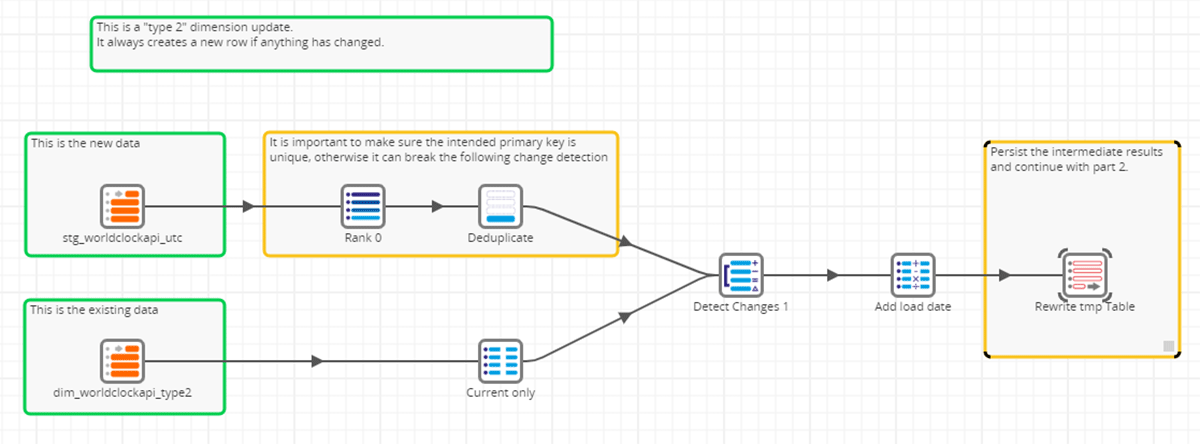
All'interno di Matillion ETL, il componente Detect Changes è un meccanismo centrale per determinare gli aggiornamenti e le inserzioni per i record modificati. Confronta un set di dati in arrivo con un set di dati di destinazione e determina se i record sono Identici, Modificati, Nuovi o Eliminati utilizzando un elenco di colonne di confronto configurate all'interno del componente. Ogni record dal nuovo set di dati viene valutato e gli viene assegnato un campo indicatore nell'output del componente Detect Changes: 'I' per Identico, 'C' per Modificato, 'N' per Nuovo e 'D' per Eliminato.
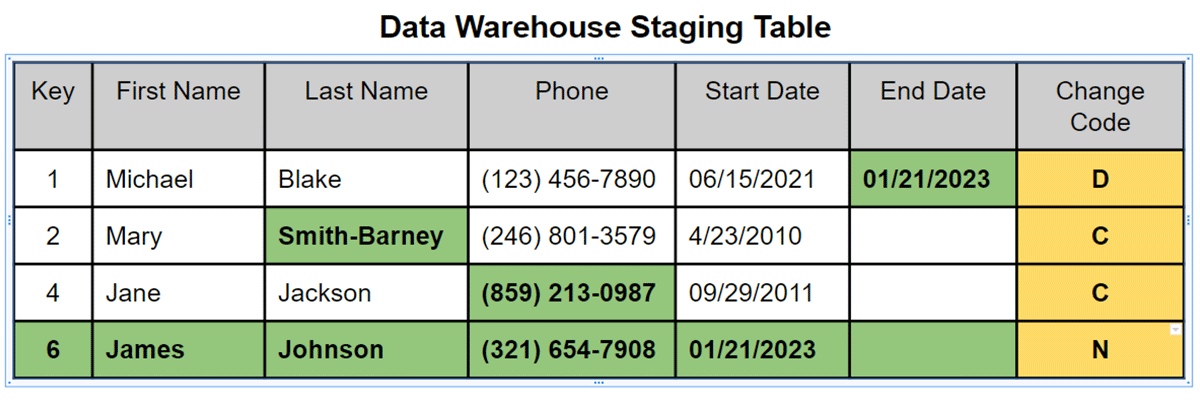
L'azione finale nella Fase 1 di questo approccio in due fasi è aggiungere una data di caricamento a ciascun record prima di scrivere ciascun nuovo record, ora contrassegnato con il suo indicatore di modifica, in una tabella temporanea Delta Lake dimensionale. Questo diventerà l'input per la Fase 2.
Fase 2: Finalizzazione delle modifiche dimensionali
Passando alla Fase 2, iniziamo leggendo la tabella dimensionale intermedia o temporanea nel nostro lakehouse. Utilizzeremo il campo indicatore derivato dal componente Detect Changes e creeremo 3 percorsi separati utilizzando un semplice componente Filter. Non faremo nulla per i record Identici (identificati con 'I') poiché non sono necessarie modifiche, quindi questi record vengono filtrati. Per essere espliciti nella nostra spiegazione all'interno di questo blog, abbiamo lasciato questo percorso. Tuttavia, sarebbe non necessario per scopi pratici a meno che non dovesse essere fatto qualcosa di specifico con questi record.
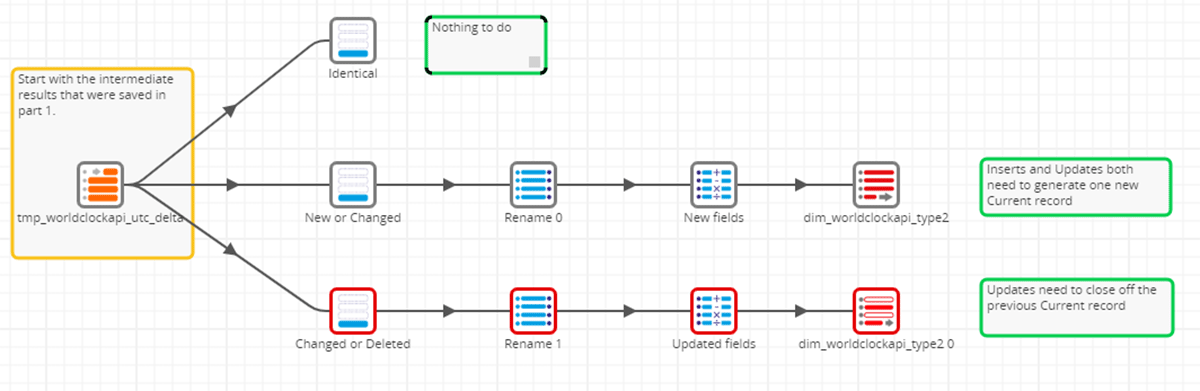
Il percorso successivo, per i record Nuovi o Modificati, genererà un nuovo record corrente per ogni record nuovo o modificato identificato. Il componente Filter elabora solo i record con 'N' (per Nuovo) o 'C' (per Modificato) come identificati dal componente Detect Changes. Il componente Rename agisce come un mappatore di colonne per mappare i dati modificati dai campi dei nuovi record (identificati dal prefisso compare_) ai nomi delle colonne effettivi come definiti dalla tabella dimensionale di destinazione Delta Lake. Infine, il componente "New fields" è un componente Calculator configurato per impostare il timestamp di scadenza dei record attivi su "infinito", identificandoli così come il record più recente.
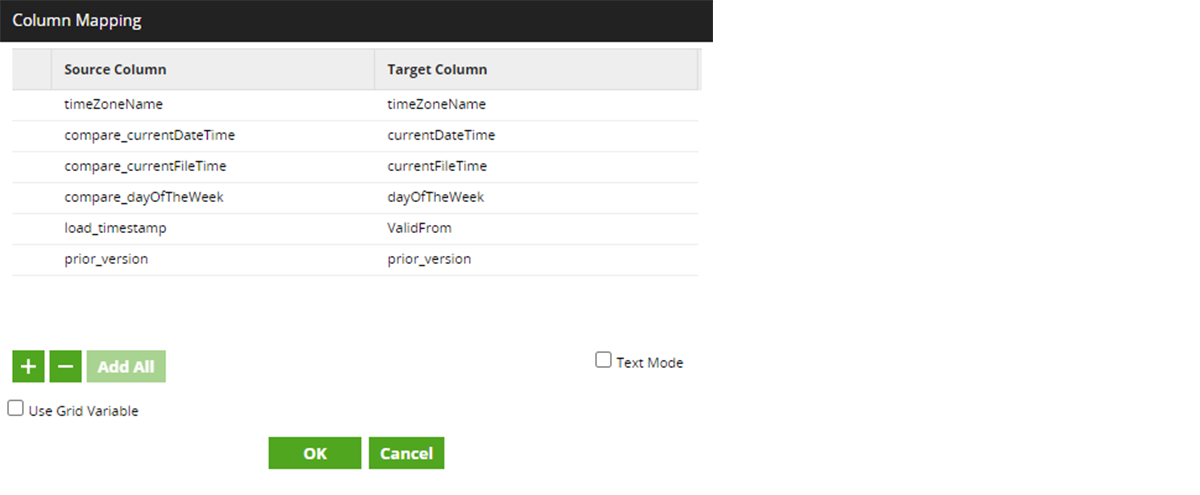
Il percorso finale consiste nel chiudere o scadere i record esistenti identificati come Modificati o Eliminati. Ricorda, in SCD2, le modifiche vengono aggiunte come un nuovo record (come descritto nel percorso Nuovo o Modificato sopra) e quindi ogni record precedente deve essere contrassegnato come scaduto o inattivo. Allo stesso modo, i record eliminati necessitano di una data di scadenza in modo che non siano più identificati come attivi. Qui, il percorso Modificato o Eliminato elabora ogni 'C' (per Modificato) o 'D' (per Eliminato) mappando le colonne appropriate che identificano univocamente il record per la scadenza. Una volta identificata, la data di scadenza viene impostata sul timestamp corrente e l'aggiornamento viene apportato all'interno della tabella dimensionale di destinazione Delta Lake.
Conclusione
Abbiamo mostrato come implementare dimensioni a variazione lenta sulla piattaforma Databricks Lakehouse utilizzando l'integrazione dati low-code/no-code di Matillion. È un'ottima opzione per tutte quelle organizzazioni che preferiscono strumenti ETL basati su GUI, come Matillion, per implementare e mantenere pipeline di data engineering, data science e machine learning sul cloud. Sfrutta veramente la potenza di Delta Lake su Databricks e migliora la produttività dei dati, offrendoti prestazioni, velocità e scalabilità per potenziare la tua analisi dati sul cloud.
Se desideri saperne di più sull'integrazione tra Matillion e Databricks, non esitare a consultare la documentazione dettagliata qui.
Prova Databricks gratuitamente per 14 giorni.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.