Loading a Data Warehouse Slowly Changing Dimension Type 2 Using Matillion on Databricks Lakehouse Platform
Managing SCD Type 2 using Matillion on Databricks
by David Wilmer and Abhishek Dey
This is a collaborative post between Databricks and Matillion. We thank David Willmer, Product Marketing at Matillion, for his contributions.
As more and more customers modernize their legacy Enterprise Data Warehouse and older ETL platforms, they are looking to adopt a modern cloud data stack using Databricks Lakehouse Platform and Matillion for GUI-based ETL. Matillion's low-code, visual ELT platform makes it easy for anyone to integrate data from any source into Databricks SQL Warehouse thus making analytics and AI data business-ready, and faster.
This blog will show you how to create an ETL pipeline that loads a Slowly Changing Dimensions (SCD) Type 2 using Matillion into the Databricks Lakehouse Platform. Matillion has a modern, browser-based UI with push-down ETL/ELT functionality. You can easily integrate your Databricks SQL warehouses or clusters with Matillion. Now, if you are wondering how to connect to Matillion using Databricks, the easiest way to do that is to use Partner Connect, which simplifies the process of connecting an existing SQL warehouse or cluster in your Databricks workspace to Matillion. Here are the detailed steps.
What is a Slowly Changing Dimension (SCD) type 2?
A SCD Type 2 is a common technique to preserve history in a dimension table used throughout any data warehousing/modeling architecture. Inactive rows have a boolean flag such as the ACTIVE_RECORD column set to 'F' or a start and end date. All active rows are displayed by returning a query where the end date is null or ACTIVE_RECORD not equal to 'F'
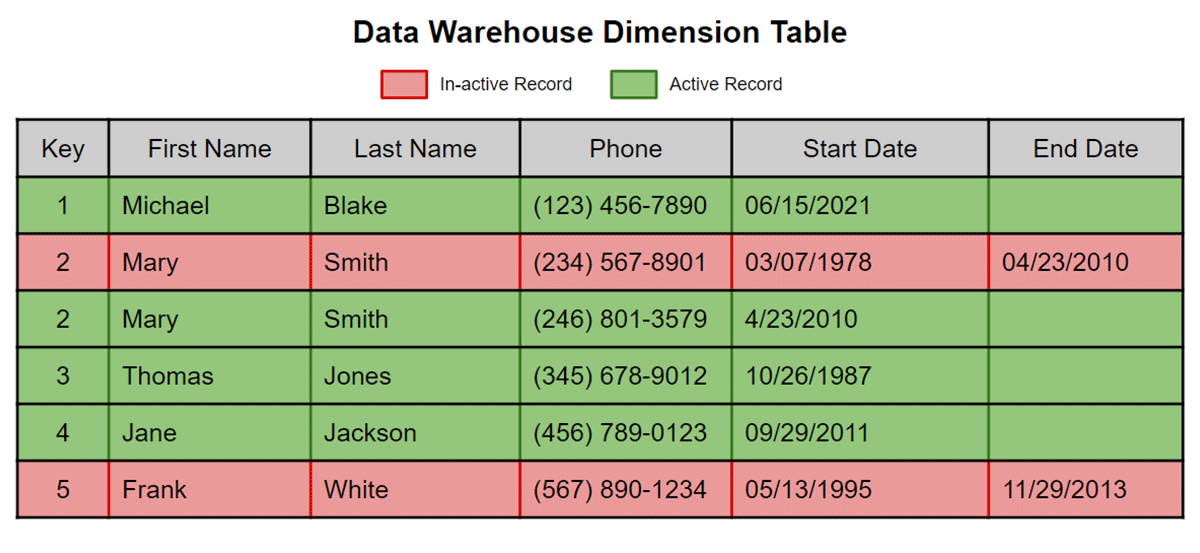
Matillion ETL for Delta Lake on Databricks uses a two-step approach for managing Type 2 Slowly Changing Dimensions. This two-step approach involves first identifying changes in incoming records and flagging them in a temporary table or view. Once all incoming records are flagged, actions can be taken on the target dimension table to complete the update.
Now, let's take a closer look at implementing the SCD Type 2 transformations using Matillion, where your target is a Delta Lake table, and the underlying compute option used is a Databricks SQL Warehouse.
Step 1: Staging the Dimension Changes
As we look at Step 1 below, the ETL pipeline reads the data from our existing Delta Lake dimension table and identifies only the most current or active records (this is the bottom data flow). At the same time, we will read all our new data, making sure the intended primary key is unique so as not to break the change detection process (this is the top data flow). These two paths then converge into the detect changes component.
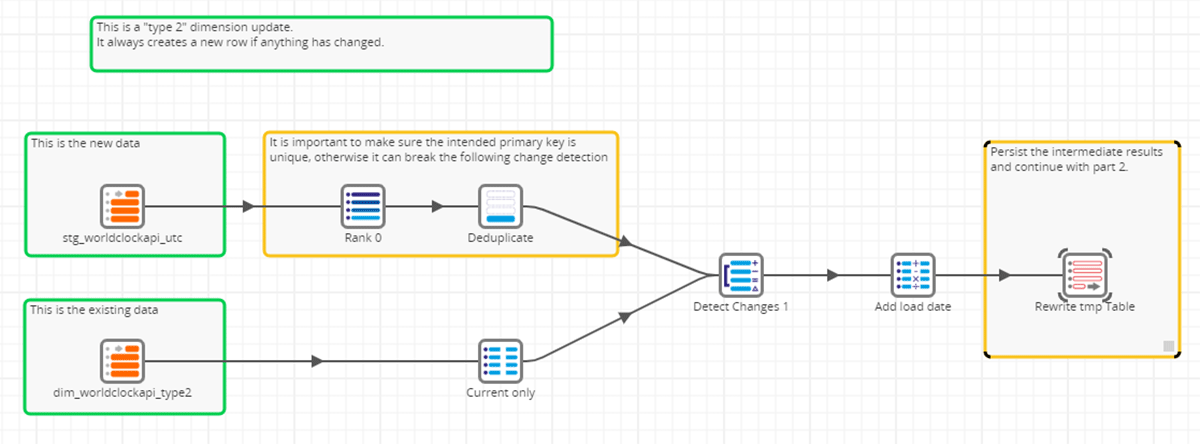
Within Matillion ETL, the Detect Changes component is a central mechanism for determining the updates and inserts for changed records. It compares an incoming data set to a target data set and determines if the records are Identical, Changed, New, or Deleted by using a list of comparison columns configured within the component. Each record from the new data set is evaluated and assigned an Indicator Field in the output of the Detect Changes component - 'I' for Identical, 'C' for Changed, 'N' for New and 'D' for Deleted.
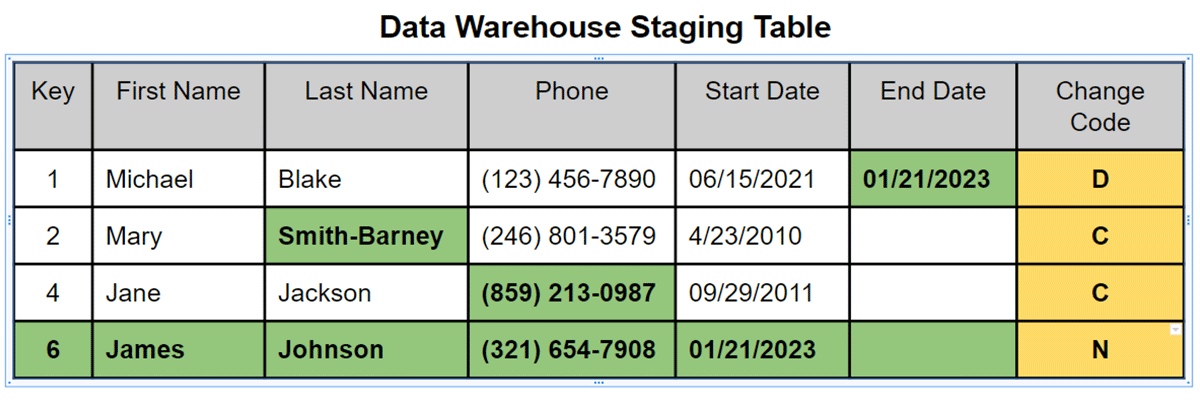
The final action in Step 1 of this two-step approach is to add a load date to each record before writing each new record, now flagged with its change indicator, into a temporary dimension Delta Lake table. This will become the input of Step 2.
Step 2: Finalizing the Dimension Changes
As we move into Step 2, we start by reading the intermediate or temporary dimension table in our lakehouse. We will use the Indicator Field that was derived from the Detect Changes component and create 3 separate paths using a simple Filter Component. We will do nothing for Identical records (identified with an 'I') since no changes are necessary, so these records are filtered. To be explicit in our explanation within this blog, we have left this path. Still, it would be unnecessary for practical purposes unless something specific needed to be done with these records.
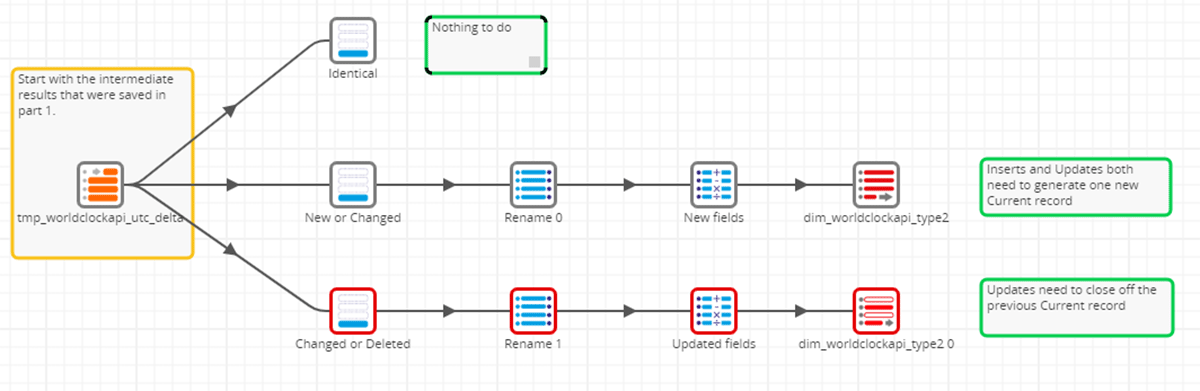
The next path, for New or Changed records, will generate one new, current record for each identified new or changed record. The Filter Component processes only those records with an 'N' (for New) or 'C' (for Changed) as identified by the Detect Changes component. The Rename Component acts as a column mapper to map the changed data from the new records' fields (identified by the compare_ prefix) to the actual column names as defined by the Delta Lake target dimension table. Finally, the "New fields" component is a Calculator Component configured to set the active records' expiration timestamp to "infinity" thus identifying them as the most current record.
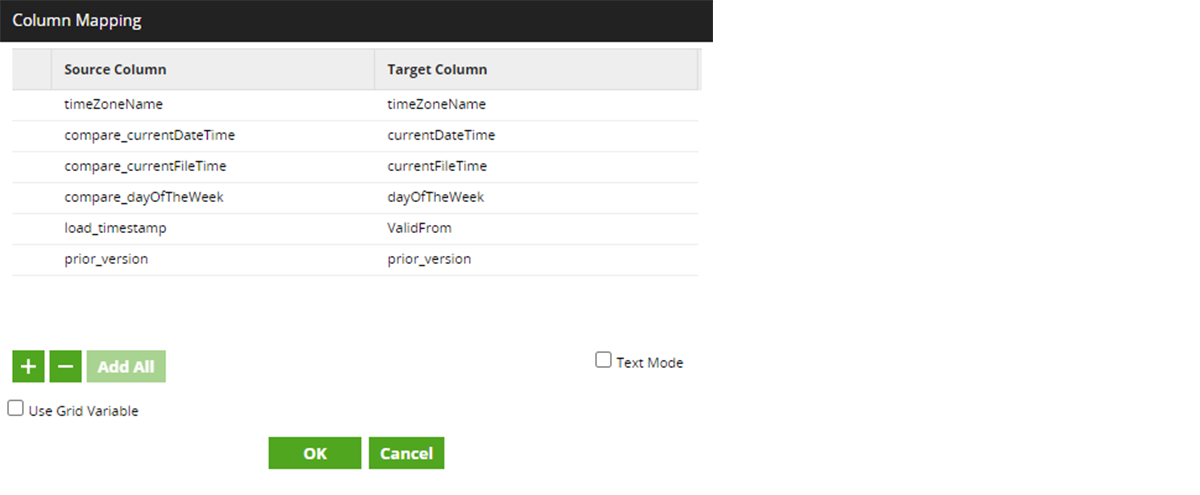
The final path is to close or expire the existing records identified as being Changed or Deleted. Remember, in SCD2, changes are added as a new record (as described in the New or Changed path above) and thus each previous record must be marked as expired or inactive. Similarly, deleted records need an expiry date so they are no longer identified as being active. Here, the Changed or Deleted path processes each 'C' (for Changed) or 'D' (for Deleted) by mapping the appropriate columns that uniquely identify the record for expiry. Once identified, the expiration date is set to the current timestamp and the update is made within the Delta Lake target dimension table.
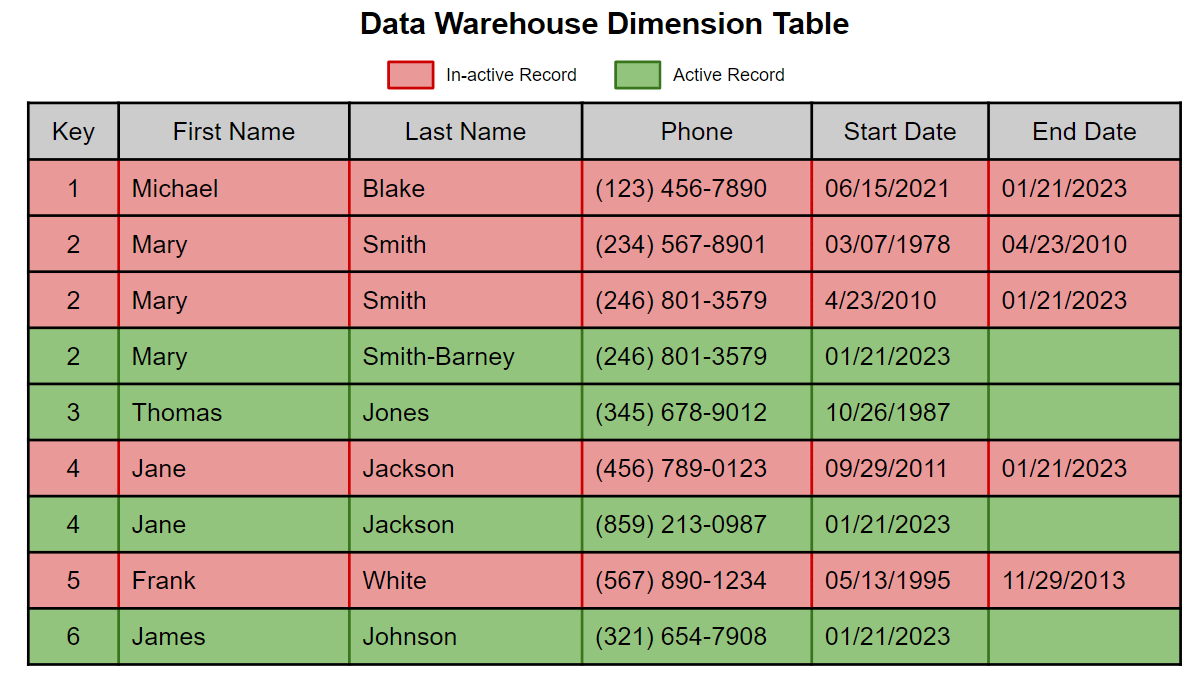
Conclusion
We showed you how to implement slowly changing dimensions on the Databricks Lakehouse platform using Matillion's low-code/no-code data integration. It is an excellent option for all those organizations who prefer GUI-based ETL tools, like Matillion, to implement and maintain data engineering, data science, and machine learning pipelines on the cloud. It truly unlocks the power of Delta Lake on Databricks, and improves data productivity, giving you the performance, speed, and scalability to power your cloud data analytics.
If you wish to learn more about Matillion and Databricks integration, feel free to check out the detailed documentation here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.