Riepilogo del 2025: Databricks SQL, più veloce per ogni carico di lavoro
Analitiche e carichi di lavoro AI più rapidi, anche con la crescita di dati, governance dei dati e utilizzo.
di Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens e Ina Felsheim
- Nel 2025, Databricks SQL ha fornito prestazioni fino al 40% più veloci sui carichi di lavoro di produzione, con miglioramenti applicati automaticamente.
- Le query sono migliorate in ambito BI, ETL, analisi spaziale e AI, anche con dati gestiti e condivisi e con una maggiore contemporaneità.
- Tutti i miglioramenti sono già disponibili in Databricks SQL Serverless, ottimizzando le prestazioni e l'efficienza dei costi per i carichi di lavoro esistenti senza necessità di tuning o riscritture.
Per la maggior parte dei team di dati, le prestazioni non riguardano più l'ottimizzazione una tantum. Si tratta di rendere le analitiche più rapide man mano che dati, utenti e governance crescono, senza aumentare i costi.
Con Databricks SQL (DBSQL), questa aspettativa è integrata nella piattaforma. Nel 2025, le prestazioni medie dei carichi di lavoro di produzione sono migliorate fino al 40%, senza richiedere ottimizzazioni, riscritture di query o interventi manuali.
Il discorso più ampio va oltre un singolo benchmark. Le prestazioni sono migliorate su tutta la piattaforma, da caricamenti più rapidi delle dashboard e pipeline più efficienti a query che rimangono reattive anche con governance e dati condivisi, mentre le funzioni di analitiche geospaziali e di IA continuano a scalare senza aggiungere complessità.
L'obiettivo rimane semplice: rendere i carichi di lavoro più veloci e ridurre il costo totale per impostazione predefinita. Con DBSQL Serverless, le tabelle gestite di Unity Catalog e Predictive Optimization, i miglioramenti vengono applicati automaticamente in tutto l'ambiente, in modo che i carichi di lavoro esistenti traggano vantaggio dall'evoluzione del motore.
Questo post analizza i miglioramenti delle prestazioni ottenuti nel 2025 per il motore di query, Unity Catalog, Delta Sharing, lo storage, Spatial SQL e le funzioni di IA.
Prestazioni veloci delle query per ogni carico di lavoro.
Databricks SQL misura le prestazioni utilizzando milioni di query di clienti reali che vengono eseguite ripetutamente in produzione. Monitorando come questi carichi di lavoro cambiano nel tempo, misuriamo l'impatto effettivo dei miglioramenti e delle ottimizzazioni della piattaforma piuttosto che benchmark isolati.
Nel 2025, Databricks SQL ha garantito miglioramenti costanti delle prestazioni per tutti i principali tipi di carichi di lavoro. Questi miglioramenti vengono applicati per impostazione predefinita tramite ottimizzazioni a livello di motore come Predictive Query Execution e Photon Vectorized Shuffle, senza richiedere modifiche alla configurazione.
- I carichi di lavoro esplorativi hanno registrato i maggiori miglioramenti, con un'esecuzione in media più veloce del 40% e consentendo ad analisti e data scientist di iterare più rapidamente su set di dati di grandi dimensioni.
- I carichi di lavoro di business intelligence sono migliorati di circa il 20%, con dashboard più reattive e un'analisi interattiva più fluida in condizioni di concorrenza.
- Anche i carichi di lavoro ETL ne hanno beneficiato, con un'esecuzione di circa il 10% più veloce e una riduzione dei tempi di esecuzione delle pipeline senza alcuna rielaborazione.
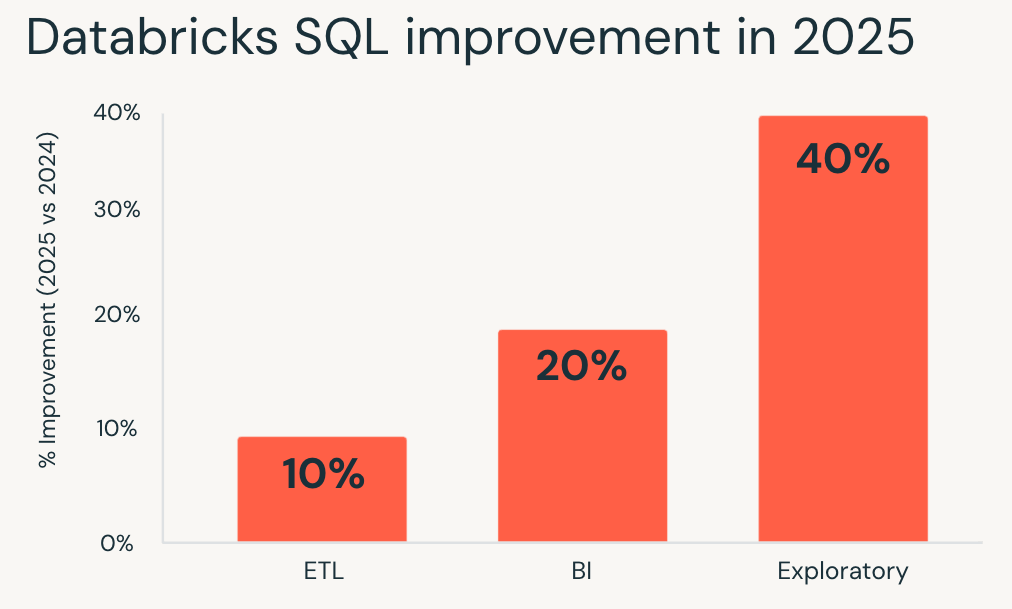
Se hai valutato Databricks SQL per l'ultima volta un anno fa, i tuoi carichi di lavoro esistenti oggi sono già più veloci.
Analitiche che restano veloci man mano che la governance si espande con Unity Catalog
Con la crescita dei patrimoni di dati, la governance diventa spesso una fonte nascosta di latenza. I controlli delle autorizzazioni, l'accesso ai metadati e le ricerche di lineage possono rallentare le query, specialmente in ambienti interattivi e ad alta concorrenza.
Nel 2025, Unity Catalog ha ridotto in modo significativo questo sovraccarico. La latenza del catalogo end-to-end è migliorata fino a 10 volte, grazie a ottimizzazioni apportate al servizio di catalogo, allo stack di rete, al client Databricks Runtime e ai servizi dipendenti.
Il risultato è visibile dove conta di più:
- Le dashboard rimangono reattive anche con controlli di accesso granulari.
- I carichi di lavoro ad alta concorrenza scalano senza colli di bottiglia dovuti all'accesso ai metadati.
- Le analitiche interattive risulta più veloce man mano che gli utenti esplorano i dati governati su vasta scala.
I team non devono più scegliere tra una governance solida e le prestazioni. Con Unity Catalog, le analitiche rimangono veloci man mano che la governance si espande a più dati e più utenti.
Delta Sharing, dati condivisi performanti come quelli nativi
La condivisione dei dati tra team o organizzazioni ha tradizionalmente comportato un costo. Le query eseguite su tabelle condivise erano spesso più lente e le ottimizzazioni venivano applicate in modo non uniforme rispetto ai dati nativi.
Nel 2025, Databricks SQL ha colmato questo divario. Grazie a miglioramenti nell'esecuzione delle query e nella propagazione delle statistiche, le query sulle tabelle condivise tramite Delta Sharing sono state eseguite fino al 30% più velocemente, allineando le prestazioni dei dati condivisi a quelle delle tabelle native.

Questa modifica è particolarmente importante negli scenari in cui i dati esterni devono comportarsi come dati interni. I marketplace di dati, le analisi interaziendali e il reporting basato sui partner possono ora essere eseguiti su set di dati condivisi senza sacrificare l'interattività o la prevedibilità.
Con Delta Sharing, i team possono condividere ampiamente i dati governati, preservando al contempo le aspettative in termini di prestazioni per le analitiche moderne.
Costi di archiviazione inferiori, ottimizzazioni automatiche integrate
Con la crescita dei volumi di dati, l'efficienza dello storage diventa una parte sempre più importante del costo totale. La compressione svolge un ruolo fondamentale, ma la scelta dei formati e la gestione delle migrazioni hanno tradizionalmente comportato un sovraccarico operativo.
Nel 2025, Databricks ha reso la compressione Zstandard il default per tutte le nuove Unity Catalog Managed Tables. Zstandard è un formato di compressione open source che offre un risparmio sui costi di storage fino al 40% rispetto ai formati meno recenti, senza compromettere le prestazioni delle query.

Questi vantaggi si applicano automaticamente alle nuove tabelle e anche le tabelle esistenti possono essere migrate a Zstandard, con semplici strumenti di migrazione in arrivo a breve. Tabelle dei fatti di grandi dimensioni, set di dati a lunga conservazione e domini in rapida crescita ottengono riduzioni immediate dei costi senza modifiche al modo in cui le query vengono scritte o eseguite.
Il risultato è un costo di archiviazione inferiore per default, ottenuto senza sacrificare le prestazioni o aggiungere nuove fasi di ottimizzazione.
Analitiche geospaziali senza sistemi specializzati
Le analitiche geospaziali sollecitano pesantemente l'esecuzione delle query. Join spaziali, query di intervallo e calcoli geometrici richiedono un'elevata potenza di calcolo e, su larga scala, spesso necessitano di sistemi specializzati o di un'attenta ottimizzazione.
Nel 2025, Databricks SQL ha migliorato in modo significativo le prestazioni per questi carichi di lavoro. le query SQL spaziali sono state eseguite fino a 17 volte più velocemente, grazie a ottimizzazioni a livello di motore come l'indicizzazione R-tree, join spaziali ottimizzati in Photon e l'ottimizzazione intelligente dei join di intervallo.
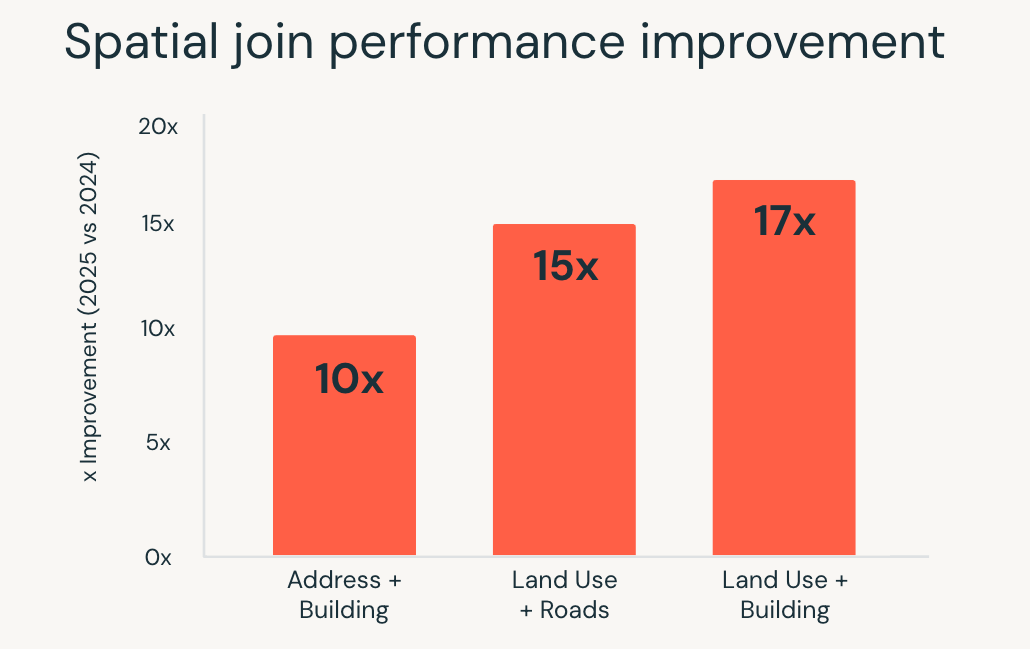
Questi miglioramenti consentono ai team di lavorare con i dati di localizzazione utilizzando l'SQL standard, mentre il motore gestisce automaticamente la complessità dell'esecuzione. Casi d'uso come le analitiche della localizzazione in tempo reale, il geofencing su larga scala e l'arricchimento geografico vengono eseguiti in modo più rapido e coerente man mano che i volumi di dati aumentano.
Le analitiche spaziali non richiedono più strumenti separati o un'ottimizzazione manuale. I carichi di lavoro geospaziali complessi scalano direttamente all'interno di Databricks SQL.
AI Functions, AI scalabile direttamente in SQL
L'applicazione dell'IA ai dati ha tradizionalmente richiesto del lavoro al di fuori del warehouse. La classificazione del testo, il parsing dei documenti e la traduzione spesso significavano creare pipeline separate, gestire l'infrastruttura dei modelli e reintegrare i risultati nei flussi di lavoro di analitiche.
Le AI Functions semplificano quel modello portando l'AI direttamente in SQL. Nel 2025, Databricks SQL ha ampliato in modo significativo la Scale e le prestazioni di queste funzionalità. Una nuova infrastruttura ottimizzata per i batch ha fornito prestazioni fino a 85 volte più veloci per funzioni come ai_classify, ai_summarize e ai_translate, consentendo di completare in pochi minuti grandi Job batch che una volta richiedevano ore.
Databricks ha inoltre introdotto ai_parse_document e l'ha rapidamente ottimizzata per la Scale. I modelli appositamente creati per l'analisi dei documenti, ospitati su Databricks Model Serving, hanno offerto prestazioni fino a 30 volte più veloci rispetto alle alternative generiche, rendendo pratica l'elaborazione di grandi volumi di contenuti non strutturati direttamente nei flussi di lavoro di analitiche.
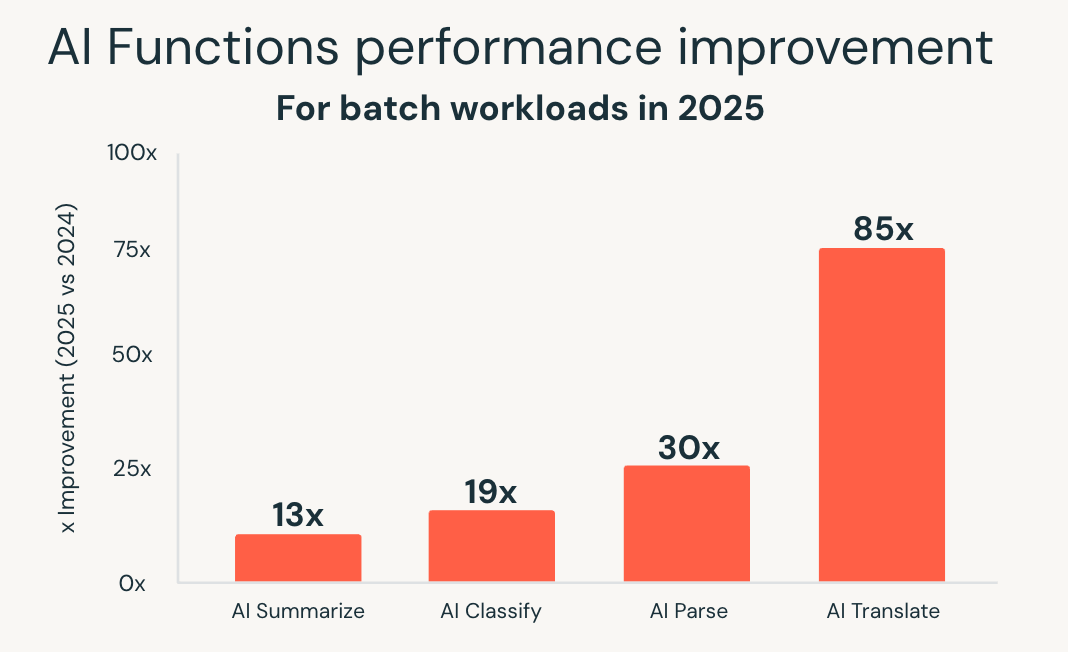
Questi miglioramenti consentono l'elaborazione intelligente dei documenti, l'estrazione di informazioni dettagliate da dati non strutturati e l'analisi predittiva utilizzando le consuete interfacce SQL. I carichi di lavoro di IA si scalano insieme ai carichi di lavoro di analitiche, senza richiedere sistemi separati o pipeline personalizzate.
Con le AI Functions, Databricks SQL si estende oltre le analitiche a carichi di lavoro basati sull'AI, preservando la semplicità e le aspettative in termini di prestazioni del warehouse.
Guida introduttiva
Tutti questi miglioramenti sono già attivi in Databricks SQL Serverless, senza necessità di abilitazione o configurazione.
Se non hai ancora provato DBSQL Serverless, crea un warehouse serverless e inizia a eseguire query. I carichi di lavoro esistenti ottengono vantaggi immediati, con miglioramenti delle prestazioni e dei costi applicati automaticamente man mano che la piattaforma continua a evolversi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.