Avanzamento del Lakehouse con Apache Iceberg v3 su Databricks
Databricks supporta Apache Iceberg v3, offrendo ai clienti un livello dati unificato, ad alte prestazioni e interoperabile
di Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu e Aniruth Narayanan
• Databricks supporta Apache Iceberg v3, consentendo ai clienti di eseguire carichi di lavoro interoperabili e governati su una singola copia dei dati
• Con Iceberg v3, i vettori di cancellazione, la lineage a livello di riga e il tipo di dato Variant sono ora disponibili su tutte le tabelle gestite
• Con queste funzionalità, Databricks porta la Piattaforma di Intelligenza dei Dati a tutti i formati per le migliori prestazioni
Databricks supporta Apache Iceberg v3 nella Piattaforma di Intelligenza dei Dati, offrendo ai clienti un livello dati unificato e aperto con prestazioni, interoperabilità e governance di prim'ordine.
Con questa release, i clienti Databricks che eseguono carichi di lavoro Iceberg possono ora sfruttare le funzionalità della v3, tra cui i vettori di cancellazione, la lineage a livello di riga e il tipo di dato Variant. Queste funzionalità consentono ai team di eseguire carichi di lavoro moderni in modo efficiente e coerente su tutte le piattaforme. Queste funzionalità funzionano anche in modo impeccabile sia con le tabelle Delta che Iceberg, consentendo l'interoperabilità senza la necessità di riscrivere i dati.

Questa release rafforza l'impegno di Databricks verso gli standard aperti e aiuta i clienti a costruire sulla base del lakehouse di Delta Lake, Apache Iceberg, Apache Parquet e Apache Spark, il tutto con piena governance e flessibilità.
In questo blog, esploreremo:
- Un livello dati unificato con Iceberg v3
- Efficienti carichi di lavoro Iceberg v3 su Databricks
- Avanzamento dei formati di tabella aperti
Un livello dati unificato con Iceberg v3
Delta Lake e Apache Iceberg sono diventati il fondamento del moderno lakehouse, ognuno con solide capacità per affidabilità, governance e gestione scalabile dei dati. Entrambi utilizzano file di metadati per tracciare i file di dati Parquet e le cancellazioni a livello di riga. Tuttavia, le piccole differenze tra i formati in questi file di dati e di cancellazione hanno spesso costretto le organizzazioni a scegliere un formato e le sue funzionalità, solitamente in base alle piattaforme dati utilizzate. Questa scelta era spesso irreversibile, poiché la riscrittura di petabyte di dati è impraticabile.
Iceberg v3 colma questo divario. Introduce funzionalità che si allineano strettamente con Delta e l'ecosistema aperto più ampio, come Parquet e Spark, consentendo ai team di utilizzare una singola copia dei dati con comportamento e prestazioni coerenti tra i formati.
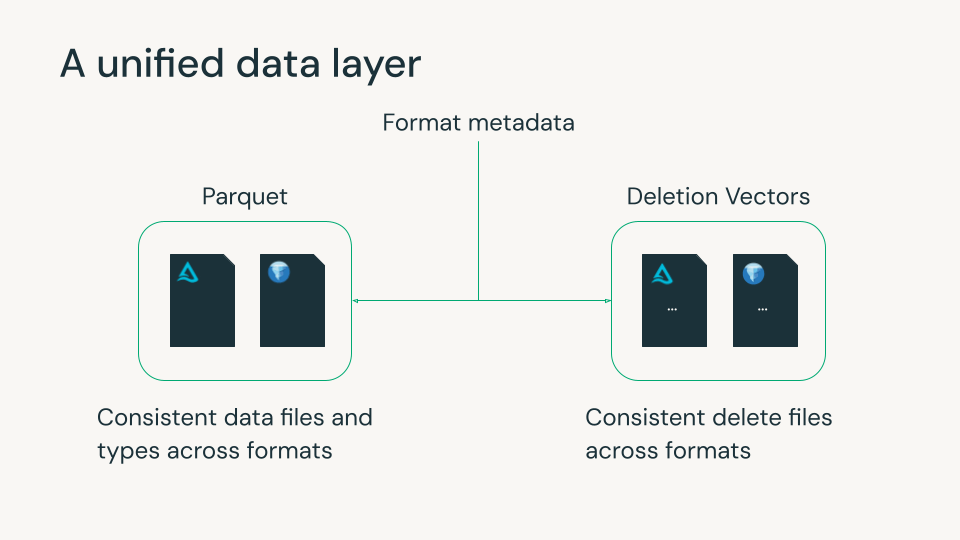
Databricks crede da tempo che il futuro del lakehouse sia l'opzionalità senza frammentazione. I nostri contributi a Iceberg v3 riflettono questo impegno: aiutare a unificare i comportamenti fondamentali delle tabelle in modo che i clienti possano utilizzare i motori e gli strumenti che preferiscono, governando tutto in modo coerente con Unity Catalog.
Efficienti carichi di lavoro Iceberg v3 su Databricks
Con Iceberg v3, Databricks porta le funzionalità della Piattaforma di Intelligenza dei Dati a tutte le tabelle gestite da Unity Catalog.
Vettori di cancellazione per aggiornamenti più rapidi
I vettori di cancellazione consentono di eliminare o aggiornare righe senza riscrivere i file Parquet. Invece, le cancellazioni vengono memorizzate come file separati e unite durante la lettura. La maggior parte dei carichi di lavoro di data engineering modifica solo poche righe alla volta, rendendo questa una funzionalità critica per scritture efficienti.

Ora puoi sfruttare le prestazioni ETL di prim'ordine di Databricks per eseguire carichi di lavoro Iceberg utilizzando i vettori di cancellazione. Rispetto alle normali istruzioni MERGE, i vettori di cancellazione possono accelerare gli aggiornamenti fino a 10 volte. I motori Iceberg possono leggere e scrivere su tabelle Iceberg gestite utilizzando le API REST Catalog di Iceberg di Unity Catalog. Come osserva Geodis:
“Ora che i Vettori di Cancellazione sono arrivati su Iceberg, possiamo centralizzare il nostro patrimonio di dati Iceberg in Unity Catalog, sfruttando il motore di nostra scelta e mantenendo prestazioni di prim'ordine.” —Delio Amato, Chief Architect & Data Officer, Geodis
Lineage di riga per la concorrenza a livello di riga
La lineage di riga assegna a ogni riga un ID univoco, rendendo facile tracciare le modifiche nel tempo. La lineage di riga è richiesta per tutte le tabelle Iceberg v3.
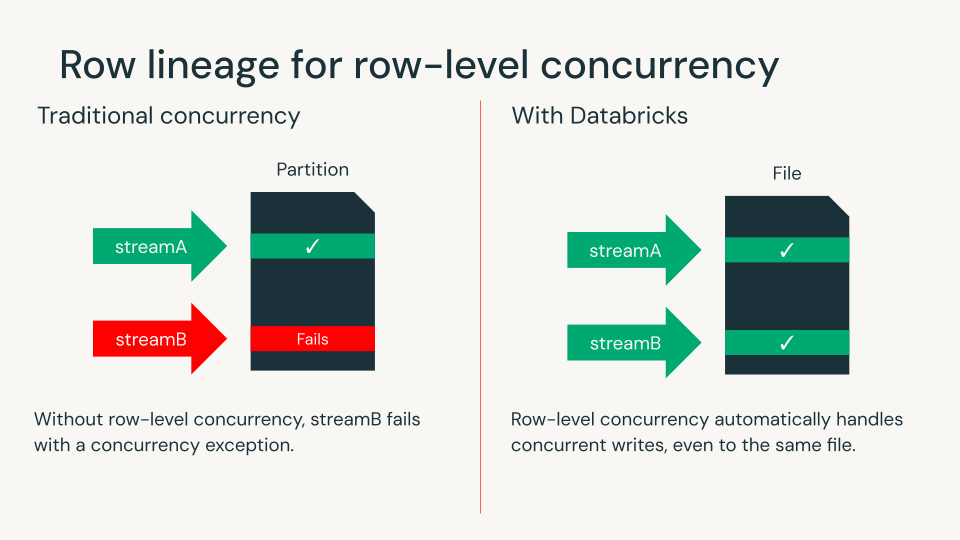
Con i vettori di cancellazione e la lineage di riga, i clienti Databricks possono ora utilizzare la concorrenza a livello di riga per rilevare conflitti di scrittura a livello di riga. Ciò elimina la necessità di progettare layout di dati complessi o coordinare i carichi di lavoro per garantire la concorrenza. Databricks rimane l'unico motore lakehouse che porta questa capacità ai formati di tabella aperti.
Tipo di dato Variant per un'ingestione flessibile
I dati moderni raramente rientrano ordinatamente in righe e colonne. Log, eventi e dati delle applicazioni arrivano spesso in formato JSON. Il tipo di dato Variant memorizza direttamente dati semi-strutturati, offrendo prestazioni eccellenti senza la necessità di schemi complessi o pipeline fragili.

Utilizzando il tipo di dato Variant in Databricks, puoi caricare dati grezzi direttamente nelle tue tabelle lakehouse utilizzando le funzioni di ingestione. Queste funzioni supportano il caricamento di dati JSON, CSV e XML. Variant supporta lo shredding, che estrae campi comuni in blocchi separati per fornire prestazioni simili a quelle colonnari. Ciò accelera le query per pipeline BI, dashboard e alerting a bassa latenza.
Variant funziona sia con Delta che con Iceberg. I team che utilizzano motori diversi possono interrogare la stessa tabella, comprese le colonne Variant, senza duplicazione dei dati:
“Sono finiti i giorni dei semplici dati scalari, in particolare per casi d'uso che richiedono log di sicurezza e applicativi. Unity Catalog e Iceberg v3 sbloccano la potenza dei dati semi-strutturati attraverso Variant. Ciò consente l'interoperabilità e la raccolta di log su scala petabyte, conveniente.” —Russell Leighton, Chief Architect, Panther
Avanzamento dei formati di tabella aperti
Iceberg v3 segna un passo importante verso l'unificazione dei formati di tabella aperti a livello dati. La prossima frontiera è migliorare il modo in cui i formati gestiscono e sincronizzano i metadati su larga scala. Gli sforzi della community, come l'albero dei metadati adattivo introdotto per la prima volta all' Iceberg Summit, possono ridurre l'overhead dei metadati e accelerare le operazioni sulle tabelle su larga scala.
Man mano che queste idee maturano, avvicinano le community Delta e Iceberg, con obiettivi condivisi riguardo a commit più rapidi, gestione efficiente dei metadati e operazioni scalabili su più tabelle. Databricks continua a contribuire a questa evoluzione, consentendo ai clienti di ottenere le migliori prestazioni e interoperabilità senza essere vincolati dalle differenze a livello di formato.
Prova Iceberg v3 Oggi con Databricks
Queste funzionalità di Iceberg v3 sono ora disponibili su Databricks, offrendo ai clienti l'implementazione più orientata al futuro dello standard, supportata dalla governance di Unity Catalog. Con Iceberg v3, i clienti Databricks possono sfruttare le migliori funzionalità sia delle tabelle Delta che Iceberg. Creare una tabella gestita da Unity Catalog con Iceberg v3 è facile:
Inizia con Unity Catalog e Iceberg v3 e unisciti a noi ai prossimi eventi Open Lakehouse + AI per saperne di più sul nostro lavoro nell'ecosistema aperto.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.