Apache Iceberg™ v3: Spostare l'ecosistema verso l'unificazione
Apache Iceberg™ v3 contiene importanti nuove funzionalità (vettori di cancellazione, lineage delle righe, dati semi-strutturati, tipi geospaziali) e unifica il livello dati tra i formati
- Apache Iceberg™ v3 contiene nuove funzionalità e miglioramenti: Vettori di cancellazione, Lineage delle righe, Dati semi-strutturati e Tipi geospaziali
- Con queste funzionalità, Iceberg v3 unifica il livello dati tra Apache Iceberg™, Delta Lake, Apache Parquet e Apache Spark™
- Databricks sta integrando Iceberg v3 nella Data Intelligence Platform ed è entusiasta dell'adozione di Iceberg v3 da parte del settore
Apache Iceberg™ v3, ora approvato dalla community di Apache Iceberg™, introduce nuove funzionalità avanzate e tipi di dati. Iceberg v3 include miglioramenti importanti come i vettori di cancellazione (deletion vectors), la lineage delle righe (row lineage) e nuovi tipi per dati semi-strutturati e casi d'uso geospaziali. Queste funzionalità consentono ai clienti di elaborare ed eseguire query sui dati in modo efficiente. Inoltre, questi miglioramenti sono coerenti tra Delta Lake, Apache Parquet e Apache Spark™, quindi i clienti possono interoperare tra Delta e Apache Iceberg™ senza dover riscrivere dati o file di cancellazione a livello di riga.
In questo post del blog, trattiamo gli sviluppi più recenti in Iceberg v3:
- Vettori di cancellazione (Deletion Vectors)
- Lineage delle righe (Row Lineage)
- Tipi di dati semi-strutturati e geospaziali
- Interoperabilità tra Delta Lake, Apache Parquet e Apache Spark
Vettori di cancellazione (Deletion Vectors)
Iceberg v3 introduce un nuovo formato per le cancellazioni a livello di riga per migliorare le prestazioni di lettura: i vettori di cancellazione. Le cancellazioni a livello di riga riducono significativamente l'amplificazione di scrittura ottimizzando come le righe cancellate vengono memorizzate e tracciate, portando a ETL e ingestione più veloci. In Iceberg v2, i motori non erano tenuti a compattare i file di cancellazione durante le scritture. L'intento era che i clienti utilizzassero la manutenzione asincrona. Tuttavia, molti clienti non pianificavano i servizi di manutenzione, quindi le loro tabelle avevano troppi file di cancellazione non mantenuti. Ciò ha portato a lente prestazioni di lettura quando i motori dovevano unire molti file di cancellazione a livello di riga durante la lettura.

Iceberg v3 introduce un nuovo formato di vettori di cancellazione e nuovi requisiti di compattazione per i file di cancellazione. Questo nuovo formato evita la traduzione tra file Parquet e rappresentazioni in memoria utilizzate per applicare le cancellazioni. Inoltre, i motori devono mantenere un singolo vettore di cancellazione per file al momento della scrittura. Questo requisito migliora le prestazioni e le statistiche sui file di dati. Rende inoltre facile confrontare le cancellazioni precedenti e attuali, il che semplifica l'elaborazione delle modifiche a livello di riga di una tabella come uno stream.
Lineage delle righe (Row Lineage)
Un'altra funzionalità importante di Iceberg v3 è la lineage delle righe, utilizzata per semplificare l'elaborazione incrementale. Con la lineage delle righe, i motori trovano le modifiche a livello di riga abbinando le versioni delle righe tra i commit.
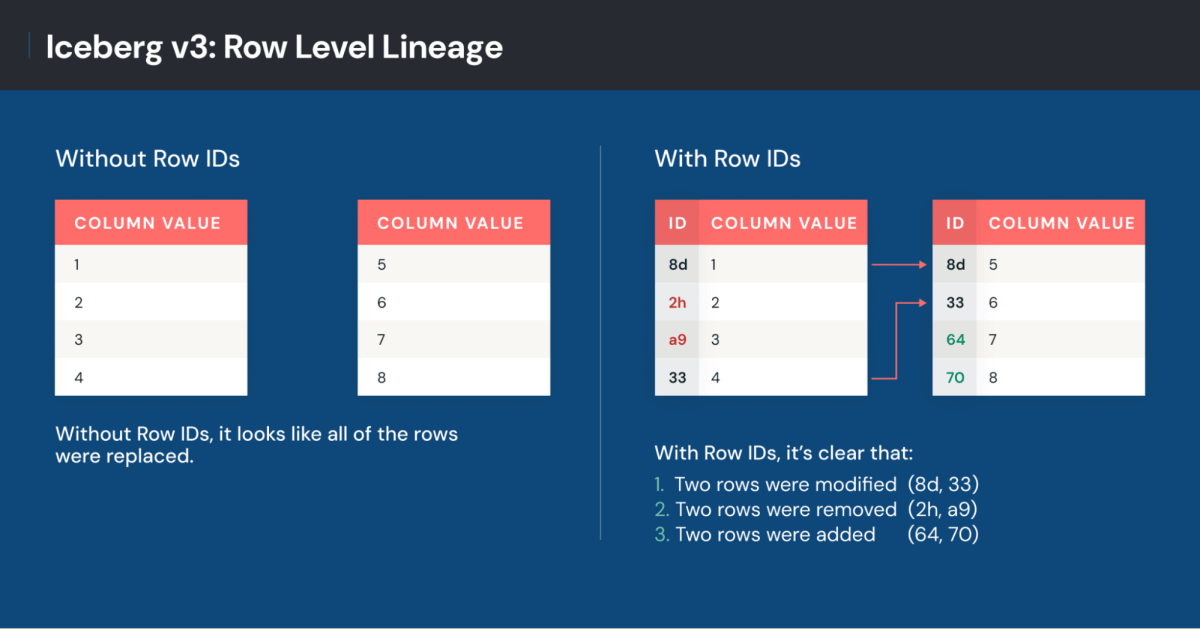
Iceberg v3 introduce la lineage delle righe utilizzando metadati a livello di riga: un ID di riga e il numero di sequenza al momento dell'ultima modifica o aggiunta della riga. Gli ID identificano la stessa riga tra le versioni. I numeri di sequenza annotano quando le righe sono state modificate l'ultima volta, non solo spostate tra i file. Ciò consente ai motori di elaborare selettivamente le modifiche, semplificando gli aggiornamenti downstream con flussi di lavoro più veloci ed economici.
Le informazioni sull'ID di riga sono particolarmente vantaggiose se combinate con oggetti di elaborazione incrementale come le viste materializzate. Questi oggetti sono ottimizzati per calcolare solo i dati nuovi o modificati dall'ultimo ciclo di elaborazione.
Tipi di dati semi-strutturati e geospaziali
Iceberg v3 aggiunge anche nuovi tipi di dati per dati semi-strutturati e dati geospaziali.
I dati semi-strutturati sono difficili da memorizzare perché hanno schemi variabili, che non rientrano nelle colonne delle tabelle strutturate. Una soluzione è estrarre singoli campi da questi dati in un formato strutturato. Tuttavia, ciò crea tabelle estremamente ampie con molte colonne e valori NULL a causa di schemi incoerenti. Un'altra alternativa è memorizzare JSON in colonne stringa. Sfortunatamente, ciò si traduce in scarse prestazioni di lettura perché i motori devono analizzare i dati da queste stringhe. Senza tipi di dati semi-strutturati, i motori non possono applicare filtri (push down filters), quindi devono leggere ogni riga in ogni file di dati. Iceberg v3 introduce VARIANT per rappresentare in modo efficiente i dati semi-strutturati. VARIANT codifica la struttura dei dati per migliorare le prestazioni mantenendo la flessibilità dello schema.
Allo stesso modo, i dati geospaziali — informazioni associate a posizioni sulla superficie terrestre come strade, parchi o confini cittadini — sono anche difficili da gestire e interrogare in modo efficiente. Senza tipi geospaziali, i clienti dovevano utilizzare colonne binarie per memorizzare le posizioni geodati. Tuttavia, questa rappresentazione non supportava la ricerca geografica, poiché le colonne binarie non possono essere filtrate per trovare oggetti all'interno di un'area specificata. Iceberg v3 risolve questo problema introducendo nuovi tipi di dati geometry e geography. I tipi geometry sono per dati spaziali planari, mentre i tipi geography sono per dati globali che tengono conto della curvatura della terra. Con questi tipi, i clienti trovano facilmente i dati utilizzando bounding box che rappresentano regioni geografiche e localizzano in modo efficiente oggetti geospaziali.

Interoperabilità con Delta Lake, Apache Parquet e Apache Spark™
Le nuove funzionalità e i tipi di dati di Iceberg v3 espandono le funzionalità e migliorano le prestazioni. Queste funzionalità di Apache Iceberg sono anche importanti perché promuovono l'interoperabilità tra i formati lakehouse.
Storicamente, i clienti sono stati costretti a scegliere tra due dei formati lakehouse più popolari: Delta Lake e Apache Iceberg. Questo perché la maggior parte delle piattaforme supporta un solo formato. La riscrittura dei dati può essere costosa e impraticabile su larga scala, rendendo questa scelta a lungo termine. I formati sono molto simili: entrambi sono livelli di metadati sopra i file di dati Parquet per fornire semantica tabellare. Tuttavia, piccole differenze nei formati delle tabelle causano problemi ai clienti.
Iceberg v3 unifica il livello dati tra i formati. Con l'unificazione dei dati, i clienti possono interoperare tra Delta e Iceberg senza la necessità di riscrivere dati o file di cancellazione. Questo perché le funzionalità di Iceberg v3 hanno implementazioni compatibili tra Delta Lake, Apache Parquet e Apache Spark:
- I vettori di cancellazione utilizzano le stesse codifiche binarie tra i formati delle tabelle
- La lineage a livello di riga in Iceberg v3 è compatibile con il tracciamento delle righe in Delta Lake
VARIANTe i tipi geodati sono in fase di sviluppo nelle community upstream di Apache Parquet e Apache Spark™, il che si estende ad Apache Iceberg e Delta Lake
Avendo funzionalità compatibili tra progetti open-source, Iceberg v3 evita di costringere i clienti a scegliere un formato. Invece, i clienti possono interoperare liberamente tra i formati su una copia dei loro dati.
Ulteriori informazioni su Iceberg v3
Iceberg v3 sposta l'intero settore verso un mondo più performante, capace e interoperabile. Stiamo integrando Iceberg v3 nella Databricks Data Intelligence Platform e attendiamo con impazienza che altri fornitori adottino Iceberg v3. L'open-source è un valore fondamentale in Databricks, dove contribuiamo attivamente con funzionalità come i vettori di cancellazione a Iceberg v3. Per promuovere una community open-source fiorente, supportiamo e incoraggiamo i contributi ad Apache Iceberg. Per i nuovi contributori, consigliamo di iniziare con un "buon primo problema".
Per saperne di più su come intendiamo integrare le funzionalità di Iceberg v3 nella nostra offerta di tabelle gestite e sul futuro dei formati di tabelle aperte, registrati al Data and AI Summit dal 9 al 12 giugno 2025.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.