Presentazione del tipo di dati Variant open source in Delta Lake e Apache Spark
Elaborazione più veloce e maggiore flessibilità quando si lavora con dati semi-strutturati
di Kent Marten, Gene Pang, Chenhao Li e Han Xiao
Siamo entusiasti di annunciare un nuovo tipo di dati chiamato variant per dati semi-strutturati. Variant offre miglioramenti delle prestazioni di un ordine di grandezza rispetto alla memorizzazione di questi dati come stringhe JSON, pur mantenendo la flessibilità per supportare schemi altamente nidificati ed evolutivi.
Lavorare con dati semi-strutturati è da tempo una funzionalità fondamentale del Lakehouse. Endpoint Detection & Response (EDR), analisi di click pubblicitari e telemetria IoT sono solo alcuni dei casi d'uso più diffusi che si basano su dati semi-strutturati. Mentre migriamo sempre più clienti dai data warehouse proprietari, abbiamo sentito dire che si affidano al tipo di dati variant offerto da tali data warehouse proprietari e che vorrebbero vedere uno standard open source per evitare qualsiasi lock-in.
Il tipo variant open source è il risultato della nostra collaborazione sia con la community open source di Apache Spark sia con la community di Linux Foundation Delta Lake:
- Il tipo di dati Variant, le espressioni binarie Variant e il formato di codifica binaria Variant sono già stati integrati in Spark open source. I dettagli sulla codifica binaria possono essere consultati qui.
- Il formato di codifica binaria consente un accesso e una navigazione più rapidi dei dati rispetto alle stringhe. L'implementazione del formato di codifica binaria Variant è impacchettata in una libreria open-source, in modo che possa essere utilizzata in altri progetti.
- Il supporto per il tipo di dati Variant è anche open-sourced per Delta, e il protocollo RFC può essere trovato qui. Il supporto Variant sarà incluso in Spark 4.0 e Delta 4.0.
“Siamo sostenitori della community open source con un focus sui dati attraverso la nostra piattaforma dati open source Legend,” ha affermato Neema Raphael, Chief Data Officer e Head of Data Engineering presso Goldman Sachs. “Il lancio di Open Source Variant in Spark è un altro grande passo avanti per un ecosistema di dati aperto.”
E a partire da DBR 15.3, tutte le capacità sopra menzionate saranno disponibili per i nostri clienti.
Cos'è Variant?
Variant è un nuovo tipo di dati per la memorizzazione di dati semi-strutturati. Nella Public Preview della prossima release di Databricks Runtime 15.3, sarà supportato l'ingress e l'egress di dati gerarchici tramite JSON. Senza Variant, i clienti dovevano scegliere tra flessibilità e prestazioni. Per mantenere la flessibilità, i clienti memorizzavano JSON in singole colonne come stringhe. Per ottenere prestazioni migliori, i clienti applicavano approcci di schematizzazione rigorosi con struct, che richiedono processi separati per la manutenzione e l'aggiornamento in caso di modifiche allo schema. Con Variant, i clienti possono mantenere la flessibilità (non è necessario definire uno schema esplicito) e ottenere prestazioni notevolmente migliorate rispetto all'interrogazione del JSON come stringa.
Variant è particolarmente utile quando le origini JSON hanno schemi sconosciuti, mutevoli e in continua evoluzione. Ad esempio, i clienti hanno condiviso casi d'uso di Endpoint Detection & Response (EDR), con la necessità di leggere e combinare log contenenti schemi JSON diversi. Allo stesso modo, per utilizzi che coinvolgono click pubblicitari e telemetria di applicazioni, dove lo schema è sconosciuto e cambia continuamente, Variant è ben adatto. In entrambi i casi, la flessibilità del tipo di dati Variant consente l'ingestione dei dati e prestazioni elevate senza richiedere uno schema esplicito.
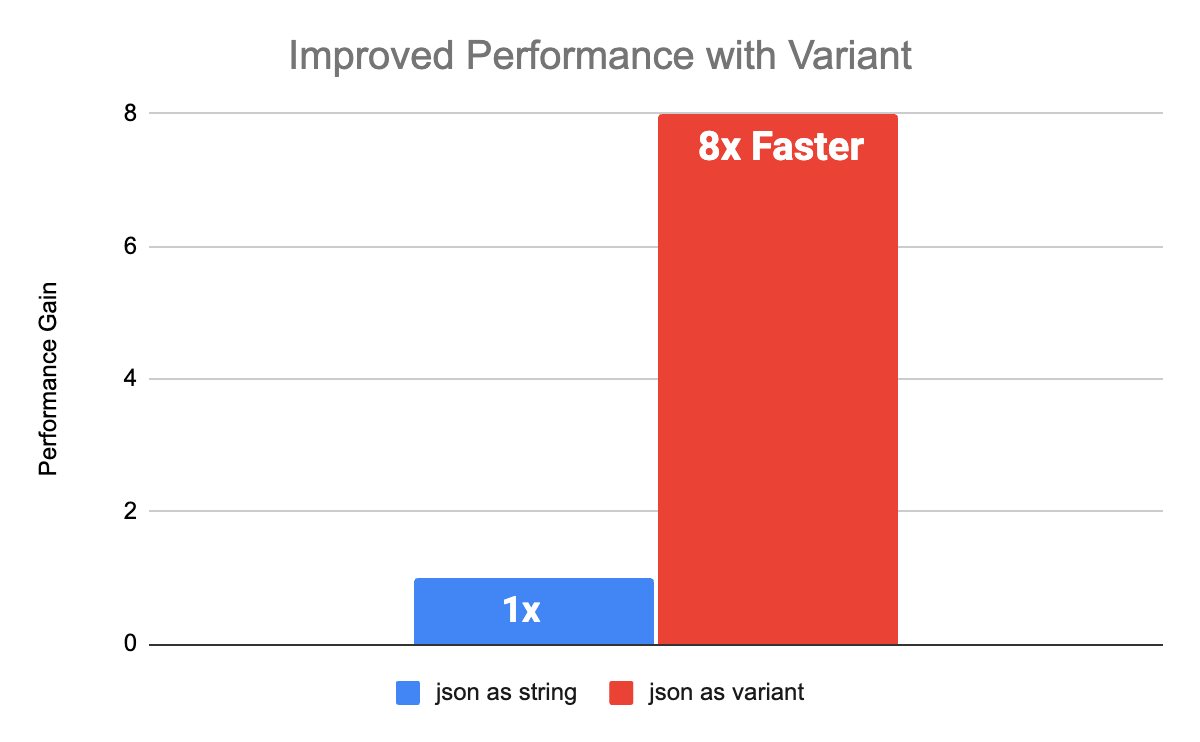
Benchmark delle prestazioni
Variant offrirà prestazioni migliorate rispetto ai carichi di lavoro esistenti che mantengono JSON come stringa. Abbiamo eseguito numerosi benchmark con schemi ispirati ai dati dei clienti per confrontare le prestazioni tra String e Variant. Sia per schemi nidificati che piatti, le prestazioni con Variant sono migliorate di 8 volte rispetto alle colonne String. I benchmark sono stati condotti con Databricks Runtime 15.0 con Photon abilitato.
Come posso usare Variant?
Ci sono diverse nuove funzioni per supportare i tipi Variant, che consentono di ispezionare lo schema di un variant, espandere una colonna variant e convertirla in JSON. La funzione PARSE_JSON() verrà comunemente utilizzata per restituire un valore variant che rappresenta l'input della stringa JSON.
Per caricare dati Variant, è possibile creare una colonna di tabella con il tipo Variant. È possibile convertire qualsiasi stringa formattata JSON in Variant con la funzione PARSE_JSON() e inserirla in una colonna Variant.
È possibile utilizzare CTAS per creare una tabella con colonne Variant. Lo schema della tabella che viene creata deriva dal risultato della query. Pertanto, il risultato della query deve avere colonne Variant nello schema di output per poter creare una tabella con colonne Variant.
È inoltre possibile utilizzare COPY INTO per copiare dati JSON in una tabella con una o più colonne Variant.
La navigazione del percorso segue una sintassi intuitiva a notazione puntata.
Completamente open-sourced, nessun lock-in di dati proprietari
Ricapitoliamo:
- Il tipo di dati Variant, le espressioni binarie e il formato di codifica binaria sono già stati integrati in Apache Spark. Il formato di codifica binaria può essere esaminato in dettaglio qui.
- Il formato di codifica binaria è ciò che consente un accesso e una navigazione più rapidi dei dati rispetto alle stringhe. L'implementazione del formato di codifica binaria è impacchettata in una libreria open-source, in modo che possa essere utilizzata in altri progetti.
- Il supporto per il tipo di dati Variant è anche open-sourced per Delta, e il protocollo RFC può essere trovato qui. Il supporto Variant sarà incluso in Spark 4.0 e Delta 4.0.
Inoltre, abbiamo in programma l'implementazione dello shredding/sub-columnarization per il tipo Variant. Lo shredding è una tecnica per migliorare le prestazioni dell'interrogazione di percorsi specifici all'interno dei dati Variant. Con lo shredding, i percorsi possono essere memorizzati nella propria colonna, riducendo così l'I/O e il calcolo necessari per interrogare quel percorso. Lo shredding consente inoltre il pruning dei dati per evitare lavoro aggiuntivo non necessario. Lo shredding sarà disponibile anche in Apache Spark e Delta Lake.
Parteciperai al DATA + AI Summit di quest'anno dal 10 al 13 giugno a San Francisco?
Partecipa a "Variant Data Type - Making Semi-Structured Data Fast and Simple".
Variant sarà abilitato per impostazione predefinita in Databricks Runtime 15.3 in Public Preview e nel canale DBSQL Preview poco dopo. Prova i tuoi casi d'uso di dati semi-strutturati e avvia una conversazione sui forum della community Databricks se hai pensieri o domande. Ci piacerebbe sapere cosa ne pensa la community!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.