Annuncio della sincronizzazione nativa del Lakehouse da Lakebase
Aprire i dati di Lakebase a modelli, analisi e altri motori
- La sincronizzazione nativa del Lakehouse (anteprima pubblica) replica automaticamente i dati di Lakebase Postgres in tabelle gestite da Unity Catalog, senza pipeline o calcolo esterno.
- Gli stack CDC tradizionali falliscono sotto carichi di lavoro guidati da agenti. Poiché Lakebase e il Lakehouse condividono lo stesso storage aperto, la sincronizzazione diventa una proprietà nativa del database con impatto zero sulle prestazioni di Postgres, nessun costo aggiuntivo e propagazione automatica dello schema.
- Funzionalità ML live basate sullo stato attuale dell'app, dati operativi come livello Bronze di un'architettura medallion con cronologia SCD di tipo 2 completa e acquisizione di audit integrata per ogni modifica.
Oggi siamo entusiasti di annunciare l'anteprima pubblica di Sincronizzazione nativa del Lakehouse, una funzionalità principale di Lakebase Postgres che replica i dati di Lakebase in tabelle gestite da Unity Catalog, senza pipeline o calcolo esterno. La sincronizzazione nativa del Lakehouse è disponibile in tutte le regioni Lakebase su AWS e Azure.
Perché l'abbiamo creata
Le applicazioni venivano eseguite su un singolo database operativo. Con l'espansione dei casi d'uso, un database non è più stato sufficiente. Analisi, ML e ricerca vivono tutti al di fuori del database operativo, il che significa che i dati devono essere spostati.
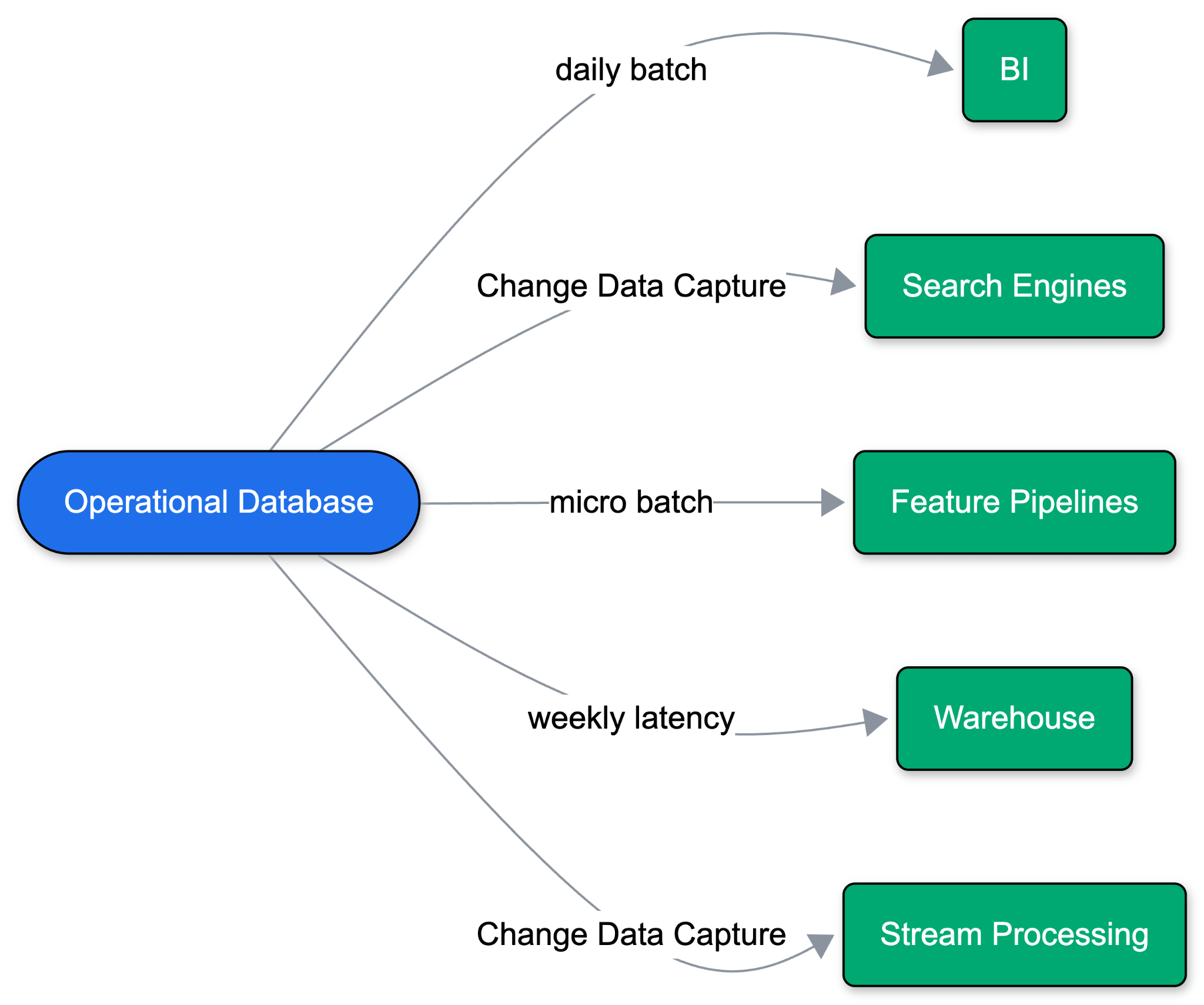
Storicamente, ciò significava dump batch giornalieri in un data warehouse, che alla fine si sono evoluti in Change Data Capture (CDC). Gli hyperscaler hanno impacchettato questo come sincronizzazioni "gestite" ("zero-ETL"), distribuendo pipeline di dati accanto al database. Ma queste sincronizzazioni gestite si basano su presupposti legacy: carichi di lavoro sempre attivi, schemi stabili, volumi di query prevedibili e un singolo data warehouse di destinazione. Il problema si aggrava con ogni nuova destinazione dei dati: le prestazioni operative degradano, gli schemi cambiano e i punti di errore si moltiplicano in tutto lo stack.
Lo sviluppo basato su agenti rompe completamente questo modello. Gli agenti ramificano i dati rapidamente per iterare in sicurezza, scalare a zero tra le attività e avviare ambienti di breve durata. La gestione di una pipeline personalizzata per ogni ramo e ogni destinazione semplicemente non è scalabile.
Collegarsi a un data warehouse è l'approccio sbagliato. I consumatori downstream raramente sono solo dashboard; stanno incorporando modelli, LLM, servizi di previsione e pipeline di funzionalità. Formati di tabella aperti come Delta Lake e Apache Iceberg™ forniscono il primitivo ideale: archiviare i dati una volta in uno storage di oggetti economico per alimentare ogni carico di lavoro senza duplicazione. È un dato di fatto noto: hai bisogno di un Lakehouse e vuoi dati operativi freschi al suo interno.
Ma la scrittura di dati operativi in un Lakehouse ha creato nuove sfide. I team sono stati costretti a configurare slot di replica Postgres, connettori Debezium, motori di elaborazione stream per scrivere in formati aperti e calcolo separato solo per ottimizzare le tabelle. Ogni salto aggiunge un punto di errore.
Sincronizzazione come proprietà di Lakebase
Lakebase è costruito su un presupposto fondamentalmente diverso: un database operativo dovrebbe essere eseguito sullo stesso storage cloud aperto ed economico del tuo Lakehouse. Poiché OLTP e OLAP condividono questa base di archiviazione unificata, possiamo eliminare completamente la pipeline ETL. Il movimento dei dati diventa una proprietà nativa del database stesso.
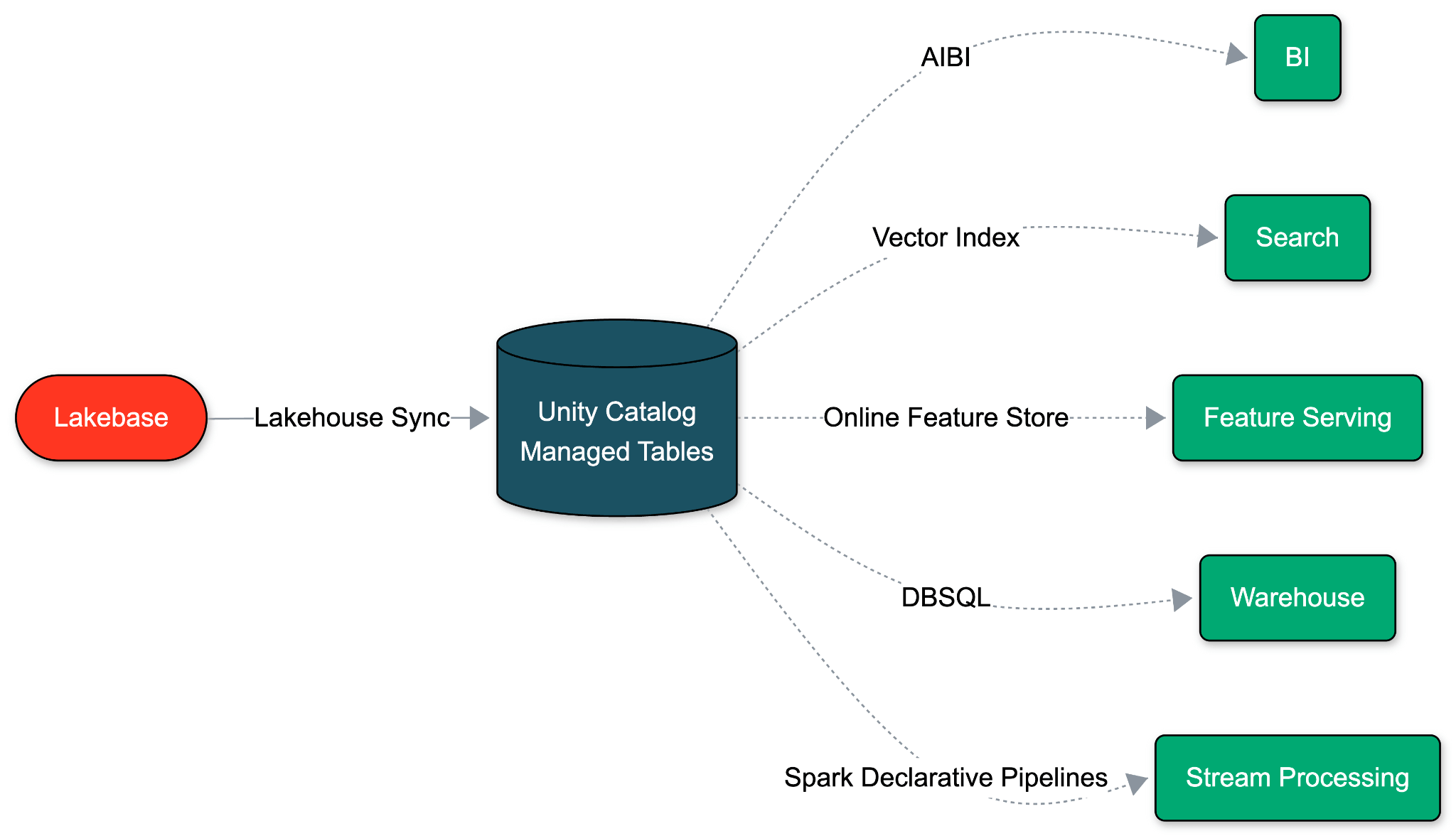
Con la sincronizzazione nativa del Lakehouse, Lakebase decodifica il suo Write-Ahead-Log (WAL) e scrive direttamente nelle tabelle gestite da Unity Catalog. Un singolo interruttore a livello di schema lo abilita in meno di un minuto. Questa sincronizzazione non ha alcun impatto sulle prestazioni di Postgres e nessun costo aggiuntivo. E poiché Databricks controlla entrambe le estremità, le modifiche allo schema fluiscono automaticamente, eliminando la deriva e il ritardo.
Agent-first da un capo all'altro
Gli agenti creano app su Lakebase. Agenti come Databricks Genie analizzano i dati. Per mantenere autonomo l'intero ciclo di vita, la sincronizzazione nativa del Lakehouse è costruita come una proprietà principale di Lakebase. Eredita i comportamenti esatti di cui gli agenti hanno bisogno per operare senza intoppi:
- Scalabilità a zero: La sincronizzazione si interrompe quando il database scala a zero e riprende dall'ultimo LSN al risveglio.
- Gestione zero del calcolo: La sincronizzazione è una parte nativa di Lakebase. Tutto il monitoraggio e l'osservabilità rimangono all'interno del tuo progetto Lakebase.
- Propagazione automatica dello schema: Le modifiche allo schema fluiscono automaticamente. L'aggiunta di una colonna si propaga istantaneamente. L'eliminazione di una colonna la mantiene nella destinazione. Gli agenti non devono mai ricreare la sincronizzazione.
Primitivi del Lakehouse sul lato destinazione
Poiché la destinazione è una tabella gestita da Unity Catalog, ogni funzionalità del Lakehouse è disponibile sui dati sincronizzati dal momento in cui arrivano.
- Analisi AI-native: Immediatamente disponibili per l'interrogazione, l'analisi e la generazione di pipeline da parte di agenti come Databricks Genie e Genie Code.
- Leggibilità universale: Leggibile da Databricks SQL, Apache Spark, pipeline dichiarative Spark Lakeflow, notebook ML e qualsiasi strumento che parli Delta o Iceberg.
- Governance unificata: Lineage, policy di accesso, tag e audit sono ereditati da Unity Catalog.
- Ottimizzazione automatica: L'ottimizzazione predittiva e il clustering liquido si applicano senza alcuna configurazione.
- Versioning predefinito: Ogni inserimento, aggiornamento ed eliminazione viene registrato come cronologia SCD di tipo 2. Log di audit, ripristini e semantica CDF sono integrati.
Cosa puoi creare con la sincronizzazione nativa del Lakehouse
Insieme, questi comportamenti di origine e destinazione sbloccano tre pattern che in precedenza richiedevano uno stack personalizzato di Change Data Capture (CDC):
Memoria agentiva e funzionalità ML live. Le scritture delle applicazioni arrivano in Unity Catalog entro un minuto, in modo che i modelli si riaddestrino e vengano valutati sullo stato corrente dell'applicazione senza una pipeline di ingestione separata.
Dati operativi nell'architettura medallion. Usa Lakebase come tabelle Bronze nell'architettura medallion. Aggiornamenti ad alta velocità avvengono in Postgres e l'intera cronologia delle modifiche fluisce automaticamente nel Lakehouse come SCD di tipo 2.
Conformità e audit. Ogni inserimento, aggiornamento ed eliminazione viene acquisito come riga di cronologia in Unity Catalog. Nessun tracciamento della cronologia lato applicazione, nessuna pipeline di audit separata.
Inizia
Sincronizzazione nativa del Lakehouse è in anteprima pubblica. L'avvio di un Lakebase è istantaneo. Attiva la sincronizzazione su uno schema una volta e ogni tabella esistente e futura apparirà in Unity Catalog entro un minuto
Lakebase è costruito sulla stessa base di dati aperta del Lakehouse. La sincronizzazione nativa del Lakehouse rende questa visione una realtà, consentendo ai dati di Lakebase di fluire automaticamente in formati aperti senza una pipeline separata.
Il prossimo passo: portare la stessa apertura dal Lakehouse alle tabelle Lakebase. Resta sintonizzato.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.