Una Nuova Era per i Database: Lakebase
di Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin e Matei Zaharia
Per decenni, i database sono stati la spina dorsale del software: alimentano silenziosamente tutto, dai flussi di checkout dell'e-commerce alla pianificazione delle risorse aziendali. Ogni pezzo di software al mondo, ogni applicazione, ogni flusso di lavoro, ogni riga di codice generata dall'IA dipende in ultima analisi da un database sottostante. Lungo il percorso, abbiamo completamente reinventato il modo in cui vengono costruite le applicazioni, ma i database sottostanti sono cambiati molto poco dagli anni '80. Si basano in gran parte su architetture che precedono il cloud moderno e soffrono di quanto segue:
- Operazioni fragili e costose: i database tradizionali sono considerati uno dei pezzi di infrastruttura più delicati e gestirli in modo affidabile richiede tipicamente un esercito di specialisti per “camminare sulle uova”. Aggregano calcolo e archiviazione in un'unità monolitica rigida. Ciò costringe i team a effettuare il provisioning per la capacità di picco, con conseguenti costose risorse inattive. Quando il carico supera la capacità di provisioning, i database possono diventare non reattivi. Peggio ancora, semplici attività di manutenzione come lo snapshot di un database o l'esecuzione di una query di pulizia GDPR possono potenzialmente mettere fuori servizio l'intero database.
- Esperienza di sviluppo goffa: i database tradizionali si scontrano con i flussi di lavoro di sviluppo moderni e agili. Per il codice, ci vuole meno di un secondo per creare un branch git per lo sviluppo che sia un clone completamente isolato della codebase. Per i database, ci vogliono molti minuti, se non ore, per effettuarne il provisioning, e prendere un clone ad alta fedeltà del database di produzione è molto costoso e rischia di mettere fuori servizio il database di produzione. L'ascesa dello sviluppo guidato dall'IA ha solo intensificato questa pressione. Gli agenti IA necessitano di ambienti temporanei e isolati da avviare istantaneamente per la sperimentazione.
- Estremo vendor lock-in: Le migrazioni di database sono uno dei progetti tecnici più spaventosi in qualsiasi organizzazione. L'architettura monolitica significa che l'unico modo per inserire o estrarre dati è attraverso il motore del database stesso. Ciò impone un significativo vendor lock-in, rendendo le organizzazioni profondamente dipendenti dal fornitore specifico.
È ora che i database si evolvano.
Cos'è una Lakebase?
Stanno emergendo nuovi sistemi che affrontano i limiti dei database tradizionali. Una Lakebase è una nuova architettura aperta che combina i migliori elementi dei database transazionali con la flessibilità e l'economia del data lake. Le Lakebase sono abilitate da un design fondamentalmente nuovo: separare il calcolo dall'archiviazione e posizionare i dati del database direttamente nell'archiviazione cloud a basso costo (“lake”) in formati aperti, consentendo al livello di calcolo transazionale di funzionare in modo indipendente sopra.
Questa separazione è la svolta fondamentale. I database tradizionali aggregano CPU e archiviazione in un unico sistema monolitico che deve essere sottoposto a provisioning, gestito e pagato come una singola grande macchina. La Lakebase separa questi livelli. I dati vivono apertamente nel lake, mentre il motore del database diventa un livello di calcolo serverless completamente gestito (ad es. Postgres) che può scalare istantaneamente. Questa architettura elimina gran parte dei costi, della complessità e del lock-in che hanno definito i database per decenni, ed è particolarmente potente per i moderni carichi di lavoro AI e guidati da agenti, dove gli sviluppatori vogliono lanciare molte istanze, sperimentare liberamente e pagare solo per ciò che utilizzano.
Una Lakebase ha le seguenti caratteristiche chiave:
Archiviazione separata dal calcolo: i dati vengono archiviati in modo economico negli object store cloud (“lake”), mentre il calcolo viene eseguito in modo indipendente ed elastico. Ciò consente una scalabilità massiccia, un'elevata concorrenza e la possibilità di scalare fino a zero in meno di un secondo (cosa non possibile nei sistemi di database legacy), eliminando la necessità di mantenere costose macchine di database inattive.
Archiviazione illimitata, a basso costo e durevole: con i dati che risiedono nel lake, l'archiviazione diventa essenzialmente infinita e drasticamente più economica rispetto ai sistemi di database tradizionali che richiedono un'infrastruttura a capacità fissa. E la sua archiviazione è supportata dalla durabilità dell'archiviazione di oggetti cloud (ad es. S3), offrendo il 99,999999999% di durabilità per impostazione predefinita. Questo è molto superiore alla configurazione tradizionale del database di avere repliche per la ridondanza di archiviazione (aggiornate più frequentemente in modo asincrono, il che significa che c'è una possibilità di perdita di dati in molte configurazioni in caso di doppi errori).
Calcolo Postgres elastico e serverless: Lakebase fornisce Postgres serverless completamente gestito che scala istantaneamente con la domanda e si riduce quando è inattivo. I costi si allineano direttamente con l'utilizzo, rendendolo ideale per carichi di lavoro a raffica, ambienti di sviluppo e agenti IA che avviano istanze temporanee.
Branching, clonazione e ripristino istantanei: i database possono essere sottoposti a branching e clonazione nel modo in cui gli sviluppatori sottopongono a branching il codice. Anche database su scala petabyte possono essere copiati in secondi, consentendo una rapida sperimentazione, rollback sicuri e ripristino istantaneo senza overhead operativo.
Carichi di lavoro transazionali e analitici unificati: Lakebase si integra perfettamente con il Lakehouse, condividendo lo stesso livello di archiviazione tra OLTP e OLAP. Ciò consente di eseguire analisi in tempo reale, machine learning e ottimizzazione guidata dall'IA direttamente sui dati transazionali senza spostarli o duplicarli.
Aperto e multicloud per progettazione: i dati archiviati in formati aperti evitano il lock-in proprietario e consentono una vera portabilità tra AWS, Azure e oltre. La flessibilità multicloud integrata supporta il disaster recovery, la libertà a lungo termine e migliori economie nel tempo.
Questi sono gli attributi chiave di Lakebase. I sistemi transazionali di livello enterprise richiedono funzionalità aggiuntive come sicurezza, governance, auditing e alta disponibilità, ma con una Lakebase, queste funzionalità devono essere implementate e gestite solo una volta, su un'unica base aperta. Lakebase rappresenta la prossima evoluzione dei database: sistemi transazionali ricostruiti per il cloud, per gli sviluppatori e per l'era dell'IA.
Evoluzione dell'architettura del database
Per capire perché è necessaria una nuova era, è utile esaminare come l'architettura del database si è evoluta negli ultimi cinquant'anni. Vediamo questa evoluzione in tre generazioni distinte:
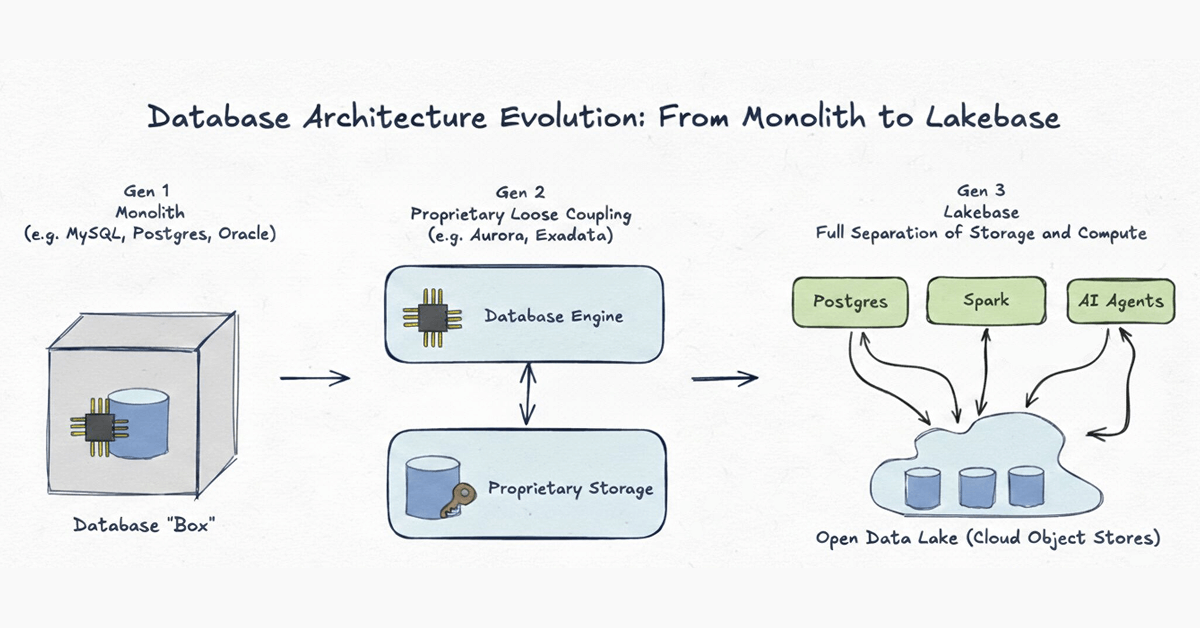
Generazione 1: Monolite
Esempi: MySQL, Postgres, Oracle classico
I sistemi di database sono iniziati come veri e propri monoliti. Nell'era pre-cloud, la rete era la parte più lenta di qualsiasi sistema. L'unico modo per progettare un database ad alte prestazioni era legare strettamente il calcolo (CPU/RAM) e l'archiviazione (disco) all'interno di una singola macchina fisica. Sebbene ciò avesse senso per i limiti hardware degli anni '80, ha creato una gabbia rigida in cui i dati erano intrappolati in formati proprietari e scalare significava acquistare una scatola più grande.
Generazione 2: Disaccoppiamento proprietario dell'archiviazione
Esempi: Aurora, Oracle Exadata
Poiché l'infrastruttura cloud è migliorata, i fornitori hanno separato fisicamente l'archiviazione dal calcolo, spostando l'archiviazione in livelli di backend proprietari. Questi sistemi erano meraviglie ingegneristiche che hanno spinto i limiti della produttività. Tuttavia, non sono andati abbastanza lontano. La separazione era puramente un'ottimizzazione interna. Poiché i dati rimangono bloccati all'interno di un formato proprietario accessibile solo da un singolo motore, i sistemi di Gen 2 soffrono di vicoli ciechi strutturali:
- Stretta del singolo motore: I dati sono accessibili solo attraverso il motore del database primario, che diventa il collo di bottiglia. È difficile per gli agenti IA o i motori analitici accedere ai dati su larga scala.
- Attrito analitico: Poiché non è possibile che motori OLAP separati accedano direttamente ai file del database su larga scala, l'esecuzione di query analitiche rimane difficile e in genere richiede complessi ETL per spostare i dati.
- Cloud lock-in: Il livello di archiviazione è spesso strettamente accoppiato all'infrastruttura proprietaria dello specifico provider cloud. Ciò rende difficile l'interoperabilità multicloud e rende impossibili un vero High Availability e Disaster Recovery (HADR) cross-cloud. Se la regione del fornitore fallisce, i tuoi dati sono bloccati.
Pensiamo che questi sistemi siano in uno stato di transizione verso la terza generazione definitiva.
Generazione 3: Lakebase - Archiviazione aperta sul Lake
Una Lakebase porta l'architettura disaccoppiata alla sua conclusione logica definitiva. Come la Gen 2, separa il calcolo dall'archiviazione, ma con una differenza fondamentale: sia l'infrastruttura di archiviazione che i formati dei dati sono completamente aperti.
Basandosi su questa architettura, può risolvere le 3 sfide sopra menzionate:
- Maggiore affidabilità e costi inferiori grazie a operazioni semplificate: Operazioni comuni come provisioning, scalabilità su/giù, branching, snapshotting e recupero possono essere completate in pochi secondi. Query costose possono essere eseguite su diverse istanze di calcolo elastiche senza impattare il traffico di produzione.
- Esperienza di sviluppo simile a Git: Diventa più veloce sperimentare e sviluppare applicazioni, basandosi su una copia ad alta fedeltà dei database di produzione. Per sviluppatori e agenti AI, questo significa che il database si muove veloce quanto il loro codice.
- Risolve l'estremo vendor lock-in: Con i dati in formati aperti archiviati negli object store cloud, sei molto meno vincolato. Possiedi i tuoi dati, indipendentemente dal motore.
In molti modi, un Lakebase è ciò che costruiresti se dovessi ridisegnare i database OLTP oggi, ora che sono disponibili storage a oggetti economici e affidabili ed elasticità cloud. Man mano che le organizzazioni accelerano adottando cloud e AI, ci aspettiamo che questo modello diventi una base standard per la creazione di sistemi transazionali.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.