Gli agenti LLM sono bravi nell'ottimizzazione dell'ordine di join?
- Cos'è: Esploriamo l'applicazione di agenti LLM (Large Language Model) all'avanguardia al classico problema del database dell'ottimizzazione dell'ordine dei join SQL.
- La Sfida: Gli ottimizzatori di query tradizionali spesso faticano con l'ordinamento dei join, dove il numero di piani possibili cresce esponenzialmente con il numero di tabelle, portando spesso a prestazioni scadenti a causa di una stima errata della cardinalità. Gli agenti LLM affrontano questo problema agendo come un DBA guidato dai dati, ragionando attraverso statistiche di runtime effettive e contesto semantico che le euristiche automatizzate spesso trascurano.
- Risultati e Esiti: Nei benchmark sperimentali, l'agente prototipo ha migliorato l'ottimizzatore Databricks nell'80% dei casi, migliorando la latenza delle query di un fattore 1,3x complessivo.
Introduzione
Nella piattaforma di intelligenza Databricks, esploriamo e utilizziamo regolarmente nuove tecniche di IA per migliorare le prestazioni del motore e semplificare l'esperienza utente. Qui presentiamo i risultati sperimentali sull'applicazione di modelli all'avanguardia a una delle sfide più antiche dei database: l'ordinamento dei join.
Questo blog fa parte di una collaborazione di ricerca con UPenn.
Il Problema: Ordinamento dei Join
Fin dalla loro nascita, gli ottimizzatori di query nei database relazionali hanno faticato a trovare buoni ordinamenti dei join per le query SQL. Per illustrare la difficoltà dell'ordinamento dei join, considera la seguente query:
Quanti film sono stati prodotti da Sony e interpretati da Scarlett Johansson?
Supponiamo di voler eseguire questa query sullo schema seguente:
| Nome tabella | Colonne tabella |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Company | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Movie | movieID, movieName, movieYear , … |
Le tabelle delle entità Actor, Company e Movie sono collegate tramite le tabelle di relazione Produces e Stars (ad esempio, tramite chiavi esterne). Una versione di questa query in SQL potrebbe essere:
Logicamente, vogliamo eseguire una semplice operazione di join: Actor ⋈ Stars ⋈ Movie ⋈ Produces ⋈ Company. Ma fisicamente, poiché ciascuno di questi join è commutativo e associativo, abbiamo molte opzioni. L'ottimizzatore di query potrebbe scegliere di:
- Trovare prima tutti i film interpretati da Scarlett Johansson, quindi filtrare solo i film prodotti da Sony,
- Trovare prima tutti i film prodotti da Sony, quindi filtrare quei film interpretati da Scarlett Johansson,
- In parallelo, calcolare i film di Sony e i film di Scarlett Johansson, quindi prendere l'intersezione.
Quale piano sia ottimale dipende dai dati: se Scarlett Johansson ha recitato in un numero significativamente inferiore di film rispetto a quelli prodotti da Sony, il primo piano potrebbe essere ottimale. Sfortunatamente, stimare questa quantità è difficile quanto eseguire la query stessa (in generale). Ancora peggio, ci sono normalmente molti più di 3 piani tra cui scegliere, poiché il numero di piani possibili cresce esponenzialmente con il numero di tabelle e le query analitiche uniscono regolarmente 20-30 tabelle diverse.
Come funziona oggi l'ordinamento dei join? I tradizionali ottimizzatori di query risolvono questo problema con tre componenti: un estimatore di cardinalità progettato per indovinare rapidamente la dimensione delle sottoquery (ad esempio, per indovinare quanti film ha prodotto Sony), un modello di costo per confrontare diversi piani potenziali e una procedura di ricerca che naviga nello spazio esponenzialmente grande. La stima della cardinalità è particolarmente difficile e ha portato a una vasta gamma di ricerche volte a migliorare l'accuratezza della stima utilizzando una vasta gamma di approcci [A].
Tutte queste soluzioni aggiungono una notevole complessità a un ottimizzatore di query e richiedono un notevole sforzo di ingegneria per l'integrazione, la manutenzione e la messa in produzione. Ma cosa succederebbe se gli agenti potenziati da LLM, con le loro capacità di adattarsi a nuovi domini tramite il prompting, avessero la chiave per risolvere questo problema decennale?
Ordinamento dei join agentivo
Quando gli ottimizzatori di query selezionano un ordinamento dei join errato1, gli esperti umani possono correggerlo diagnosticando il problema (spesso una cardinalità stimata erroneamente) e istruendo l'ottimizzatore di query a scegliere un ordinamento diverso. Questo processo spesso richiede più cicli di test (ad esempio, l'esecuzione della query) e l'ispezione manuale dei risultati intermedi.
Gli ottimizzatori di query devono tipicamente scegliere gli ordinamenti dei join in poche centinaia di millisecondi, quindi integrare un LLM nel percorso critico dell'ottimizzatore di query, sebbene potenzialmente promettente, non è possibile oggi. Ma il processo iterativo e manuale di ottimizzazione dell'ordinamento dei join per una query, che potrebbe richiedere a un esperto umano diverse ore, potrebbe potenzialmente essere automatizzato con un agente LLM! Questo agente cerca di automatizzare quel processo di ottimizzazione manuale.
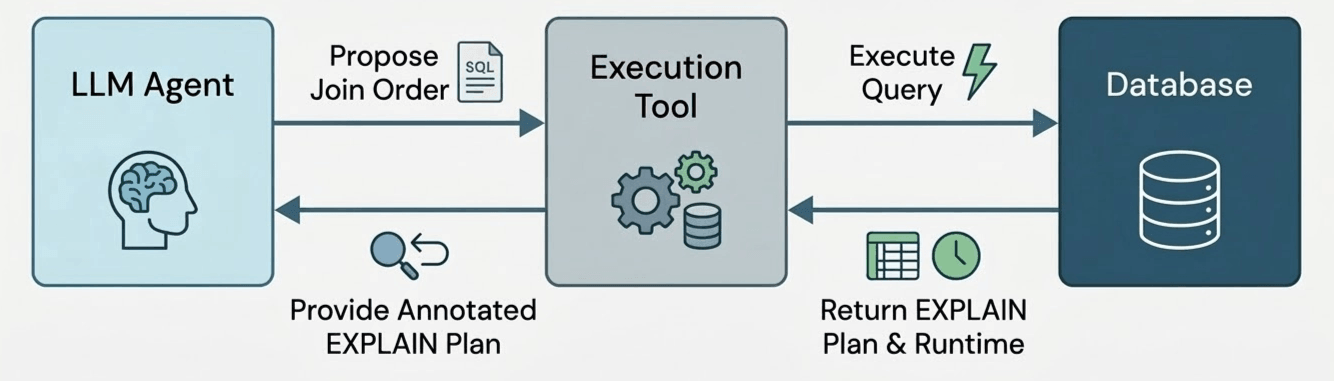
Per testare questo, abbiamo sviluppato un prototipo di agente di ottimizzazione delle query. L'agente ha accesso a un singolo strumento, che esegue un potenziale ordinamento dei join per una query e restituisce il tempo di esecuzione dell'ordinamento dei join (con un timeout pari al tempo di esecuzione della query originale) e la dimensione di ogni sotto-piano calcolato (ad esempio, il piano EXPLAIN EXTENDED).
Abbiamo lasciato che l'agente eseguisse 50 iterazioni, consentendo all'agente di provare liberamente diversi ordinamenti dei join. L'agente è libero di utilizzare queste 50 iterazioni per testare piani promettenti (“sfruttamento”) o per esplorare alternative rischiose ma informative (“esplorazione”). Successivamente, raccogliamo l'ordinamento dei join con le migliori prestazioni testato dall'agente, che diventa il nostro risultato finale. Ma come sappiamo che l'agente ha scelto un ordinamento dei join valido? Per garantire la correttezza, ogni chiamata allo strumento genera un ordinamento dei join utilizzando output strutturati del modello, che forza l'output del modello a corrispondere a una grammatica che specifichiamo per ammettere solo riordinamenti dei join validi. Si noti che ciò differisce dal lavoro precedente [B] che chiede all'LLM di scegliere un ordinamento dei join istantaneamente nel “percorso critico” dell'ottimizzatore di query; invece, l'LLM può agire come uno sperimentatore offline che prova molti piani candidati e impara dai risultati osservati – proprio come un essere umano che ottimizza manualmente un ordinamento dei join!
Per valutare il nostro agente in DBR, abbiamo utilizzato il Join Order Benchmark (JOB), un set di query progettate per essere difficili da ottimizzare. Poiché il set di dati utilizzato da JOB, il set di dati IMDb, è di soli 2 GB (e quindi Databricks potrebbe elaborare anche ordinamenti dei join scadenti abbastanza rapidamente), abbiamo aumentato le dimensioni del set di dati duplicando ogni riga 10 volte [C].
Abbiamo lasciato che il nostro agente testasse 15 ordinamenti dei join (rollout) per query per tutte le 113 query nel benchmark di ordinamento dei join. Riportiamo i risultati sul miglior ordinamento dei join trovato per ciascuna query. Utilizzando un modello all'avanguardia, l'agente è stato in grado di migliorare la latenza delle query di un fattore 1.288 (geomean). Questo supera l'uso di stime di cardinalità perfette (intratabili in pratica), modelli più piccoli e il recente ottimizzatore offline BayesQO (sebbene BayesQO sia stato progettato per PostgreSQL, non per Databricks).
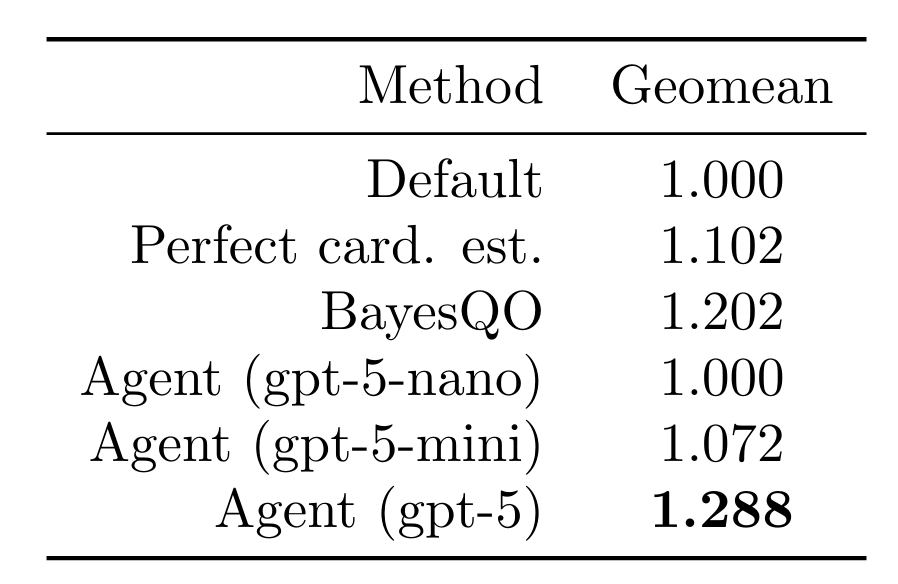
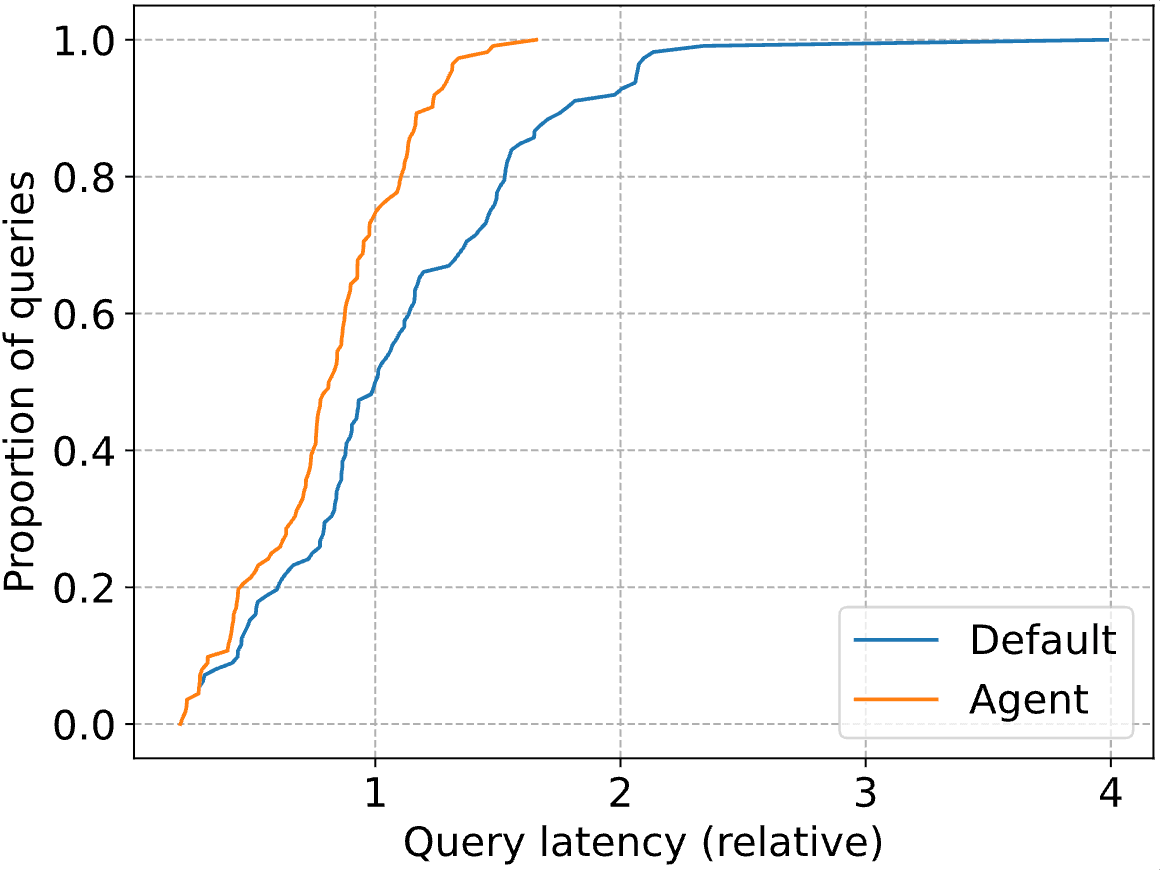
I veri guadagni impressionanti si trovano nella coda della distribuzione, con la latenza delle query P90 ridotta del 41%. Di seguito, tracciamo l'intera CDF sia per l'ottimizzatore Databricks standard (“Default”) che per il nostro agente (“Agent). Le latenze delle query sono normalizzate alla latenza mediana dell'ottimizzatore Databricks (cioè, a 1, la linea blu raggiunge una proporzione di 0.5).
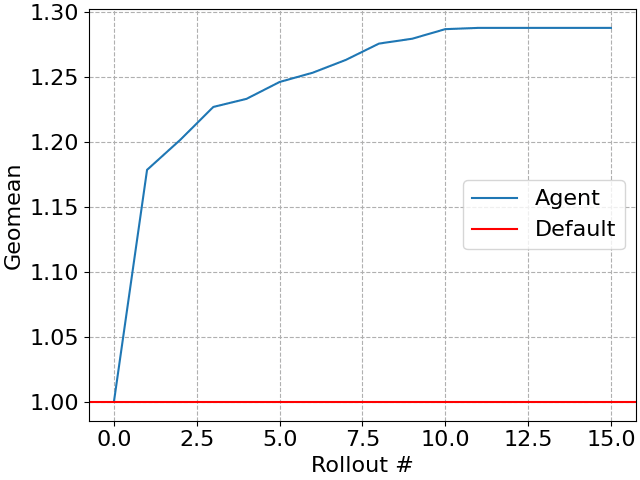
Il nostro agente migliora progressivamente il carico di lavoro con ogni piano testato (a volte chiamato rollout), creando un semplice “algoritmo anytime” in cui budget di tempo maggiori possono essere tradotti in ulteriori prestazioni delle query. Naturalmente, alla fine le prestazioni delle query smetteranno di migliorare.
Uno dei maggiori miglioramenti riscontrati dal nostro agente è stato nella query 5b, una semplice join a 5 vie che cerca società di produzione americane che hanno pubblicato un film post-2010 su VHS con una nota che fa riferimento al 1994. L'ottimizzatore Databricks si è concentrato prima sulla ricerca di società di produzione VHS americane (che è effettivamente selettiva, producendo solo 12 righe). L'agente trova un piano che cerca prima le pubblicazioni VHS che fanno riferimento al 1994, il che risulta significativamente più veloce. Questo perché la query utilizza predicati LIKE (con stile="color:#e51600;">LIKE) per identificare le pubblicazioni VHS, che sono eccezionalmente difficili per i stimatori di cardinalità.
Il nostro prototipo dimostra la promessa dei sistemi agentivi nel riparare e migliorare autonomamente le query di database. Questo esercizio ha sollevato diverse domande sulla progettazione degli agenti nelle nostre menti:
- Quali strumenti dovremmo fornire all'agente? Nel nostro approccio attuale, l'agente può eseguire ordini di join candidati. Perché non lasciare che l'agente emetta query di cardinalità specifiche (ad esempio, calcolare la dimensione di un particolare sotto-piano), o query per testare determinate ipotesi sui dati (ad esempio, per determinare che non ci sono state pubblicazioni DVD prima del 1995).
- Quando dovrebbe essere attivata questa ottimizzazione agentiva? Sicuramente, un utente può segnalare manualmente una query problematica per l'intervento. Ma potremmo anche applicare proattivamente questa ottimizzazione a query in esecuzione regolare? Come possiamo determinare se una query ha il “potenziale” per l'ottimizzazione?
- Possiamo comprendere automaticamente i miglioramenti? Quando l'agente trova un ordine di join migliore di quello trovato dall'ottimizzatore predefinito, questo ordine di join può essere visto come una prova che l'ottimizzatore predefinito sta scegliendo un ordine subottimale. Se l'agente corregge un errore sistematico nell'ottimizzatore sottostante, possiamo scoprirlo e usarlo per migliorare l'ottimizzatore?
Naturalmente, non siamo gli unici a pensare al potenziale degli LLM per l'ottimizzazione delle query [D]. In Databricks, siamo entusiasti della possibilità di sfruttare la generalizzabilità degli LLM per migliorare gli stessi sistemi di dati.
Se sei interessato a questo argomento, consulta anche il nostro successivo blog UCB su "How do LLM agents think through SQL join orders?".
Unisciti a noi
Guardando al futuro, siamo entusiasti di continuare a spingere i confini di come l'IA può plasmare le ottimizzazioni dei database. Se sei appassionato nel costruire la prossima generazione di motori di database, unisciti a noi!
1 Databricks utilizza tecniche come i filtri di runtime per mitigare l'impatto di ordini di join scadenti. I risultati presentati qui includono tali tecniche.
Note
A. Le tecniche per la stima della cardinalità hanno incluso, ad esempio, feedback adattivo, apprendimento profondo, modellazione della distribuzione, teoria dei database, teoria dell'apprendimento e decomposizioni fattoriali. Lavori precedenti hanno anche tentato di sostituire interamente l'architettura tradizionale dell'ottimizzatore di query con deep reinforcement learning, multi-armed bandits, ottimizzazione Bayesiana, o algoritmi di join più avanzati.
B. Approcci basati su RAG (RAG-based approaches), ad esempio, sono stati utilizzati per costruire sistemi "LLM in the hot path".
C. Sebbene grezzo, questo approccio è stato utilizzato in lavori precedenti.
D. Altri ricercatori hanno proposto sistemi di riparazione di query basati su RAG, sistemi di riscrittura di query potenziati da LLM, e persino interi sistemi di database sintetizzati da LLM.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.