Costruzione di un assistente di conoscenza sul codice
Valutazione delle strategie di chunking con MLflow
di Daniel Liden
- Il RAG sul codice presenta sfide di chunking uniche: suddividere le funzioni a metà corpo o perdere il contesto strutturale degrada il recupero anche quando si trova il file giusto.
- Abbiamo utilizzato il framework di valutazione GenAI di MLflow con giudici LLM integrati e personalizzati per confrontare sistematicamente tre strategie di chunking utilizzate con Databricks Knowledge Assistant.
- Il processo di valutazione stesso è stata la lezione principale: set di dati di valutazione strutturati, risultati tracciabili e giudici LLM personalizzati allineati a ciò che ti interessa realmente sono ciò che rende pratica l'iterazione RAG.
Quando gli sviluppatori entrano in un nuovo progetto o devono lavorare su una codebase non familiare, gli assistenti alla conoscenza come Databricks Knowledge Assistant li aiutano a familiarizzare rispondendo a domande in linguaggio naturale sul codice. Ma la qualità delle risposte dipende molto da come il codice sorgente e il contesto circostante sono stati preparati e aggiunti. Un fattore chiave è il chunking: come si dividono i file sorgente in pezzi per l'indicizzazione e il recupero. Il codice rende questo processo complicato. Se si interrompe una funzione a metà corpo o si rimuove il suo contesto di classe, anche un assistente capace farà fatica a rispondere alle domande su di essa.
Abbiamo creato tre Knowledge Assistants sul nostro repository GitHub demo Casper’s Kitchens, ognuno dei quali utilizza una diversa strategia di chunking, da una semplice baseline di dimensione fissa a un approccio consapevole della struttura che analizza il codice nei suoi componenti sintattici. Il repository simula un'attività di ghost kitchen su Databricks, utilizzando una vasta gamma di funzionalità tra cui pipeline Lakeflow, agenti DSPy e Databricks Asset Bundles (DAB), con documentazione in file markdown e celle di notebook. Le dipendenze tra file, i formati di file misti e i pattern specifici del dominio lo rendono il tipo di progetto in cui un assistente alla conoscenza capace sarebbe di grande aiuto.
Questo post illustra cosa rende diverso lavorare con il codice rispetto ai tipici documenti aziendali, come abbiamo distribuito ogni strategia di chunking come Databricks Knowledge Assistant e come abbiamo utilizzato il framework di valutazione di MLflow per confrontarli. Puoi trovare tutto il codice qui.
Come funzionano i Knowledge Assistants (e perché il codice è diverso)
Sotto il cofano, i knowledge assistants utilizzano varie forme di generazione aumentata da recupero (RAG). Recuperano pezzi pertinenti dei dati sorgente, spesso da un indice di ricerca vettoriale, e li passano a un modello linguistico di grandi dimensioni come contesto per generare una risposta a una query dell'utente.
Databricks Knowledge Assistant si basa su questa fondazione con sofisticate tecniche di recupero tra cui Instructed Retriever, che incorpora la scomposizione delle query, il riordino informato dal contesto e il ragionamento sui metadati dei documenti. Queste capacità fanno molto per gestire la complessità delle codebase del mondo reale e funzionano al meglio quando i chunk sottostanti preservano confini semantici significativi.
I knowledge assistants sono costruiti e valutati più comunemente su raccolte di documenti aziendali, che tendono a fluire linearmente, con paragrafi e sezioni. Il codice ha gerarchie annidate: i file contengono classi, le classi contengono metodi, i metodi contengono blocchi di logica. L'unità semantica nel codice è spesso una funzione completa, non un paragrafo.
Questo crea sfide specifiche, tra cui:
- Confini semantici: Interrompere una funzione a metà corpo perde il contesto necessario per capire cosa fa. Un chunk contenente
deletion_order = ['experiments', 'jobs'...è meno utile se non mostra che questa variabile si trova all'interno diUCState.clear_all(). - Dipendenze tra file: Il codice fa riferimento ad altro codice. Capire una funzione spesso richiede il contesto della sua classe, delle sue importazioni o di funzioni correlate.
- Tipi di file misti: La nostra codebase ha file
.py, notebook.ipynb(JSON con celle di codice/Markdown), documentazione.mde configurazione.yaml, ognuno dei quali richiede approcci di parsing diversi.
Poiché Databricks Knowledge Assistant ti consente di utilizzare il tuo indice vettoriale, puoi preparare i chunk come preferisci e semplicemente puntare Knowledge Assistant al risultato. Questo ci ha permesso di confrontare diversi approcci alla preparazione della nostra codebase per RAG e scegliere quello migliore.
Strategie di Chunking
Per vedere come le strategie di chunking differiscono in pratica, considera cosa succede quando chiedi: “In quale ordine avviene la pulizia delle risorse?” La risposta si trova in una classe di utilità che tiene traccia di esperimenti, job e pipeline. La sua logica copre l'inizializzazione, una lista di ordini di eliminazione e metodi di pulizia. Ecco come funziona ogni metodo e come influisce sul contesto recuperato sulla classe di pulizia delle risorse, UCState.
Baseline Naive: Chunk di Caratteri a Dimensione Fissa
L'approccio più semplice è dividere i file sorgente a intervalli di caratteri fissi con sovrapposizione, trattando il codice come testo normale. Questo non è ciò che sceglieresti per un sistema RAG pronto per la produzione oggi. Ignora la sintassi e i confini semantici, quindi fallisce esattamente nei modi in cui le query di codice sono importanti. Ma è anche estremamente facile da implementare, spesso “abbastanza buono” per esperimenti rapidi o repository ricchi di documentazione, ed è comune come primo passaggio, quindi è una baseline utile.
Ecco cosa produce il chunking naive per una ricerca di deletion_order nella nostra codebase:
Il nome della variabile è stato tagliato a metà (eletion invece di deletion) e il chunk non include il nome del metodo. Se qualcuno cerca “UCState deletion order,” questo chunk non corrisponderà bene. Inoltre, la lista deletion_order nel metodo è stata troncata.
Language-Aware: LangChain Heuristic Splitters
Il metodo RecursiveCharacterTextSplitter.from_language() di LangChain utilizza separatori specifici del linguaggio (come \nclass e \ndef per Python) per preferire la divisione in confini logici. Tenta di mantenere le funzioni intatte ma impone comunque limiti di dimensione rigorosi. Concettualmente, questo migliora il chunking naive dando priorità alle divisioni in confini semantici probabili (come def e class) invece di conteggi arbitrari di caratteri, quindi i chunk hanno maggiori probabilità di contenere unità logiche complete.
Ecco cosa ha prodotto questo approccio per la stessa ricerca:
Il chunk inizia da un confine più naturale, ma manca ancora di contesto che mostri a quale file o funzione appartiene, e si interrompe subito dopo l'inizio di un ciclo for.
Basato su AST: Tree-Sitter con Header di Metadati
Il chunking basato su alberi di sintassi astratta utilizza un parser come Tree-sitter per comprendere la struttura effettiva del codice. Un AST è una rappresentazione ad albero del codice che ne cattura la struttura sintattica, ovvero come il codice è organizzato secondo le regole grammaticali di un linguaggio. Invece di dividere ai confini dei caratteri o utilizzare pattern euristici, una strategia di chunking basata su AST analizza il codice in un albero di sintassi e crea chunk ai confini semantici, come funzioni, classi o blocchi di istruzioni. Può anche superare i limiti di dimensione quando necessario per mantenere un'unità completa, piuttosto che dividerla a metà funzione.
Abbiamo utilizzato la libreria Python ASTChunk per gestire la divisione basata su AST. La libreria include un'opzione di espansione del chunk che fa sì che ogni chunk venga preceduto da un'intestazione di metadati che mostra il percorso del file e la gerarchia di classi/funzioni. Questo contesto diventa parte dell'embedding, aiutando il recupero a far corrispondere le query a codice pertinente anche quando i termini della query non compaiono nel corpo del chunk.
Ecco il chunk prodotto da questo approccio per la nostra query:
L'intestazione ci dice esattamente dove si trova questo codice: utils/uc_state/state_manager.py → class UCState: → def clear_all(...). Quando incorporato, questo chunk ha una connessione semantica più forte con query su "UCState", "clear_all" o "deletion order".
A questo punto, avevamo alcune intuizioni su quali metodi avrebbero funzionato meglio nel nostro Knowledge Assistant. Ma per esserne sicuri, avevamo bisogno di eseguire una valutazione sistematica.
Configurazione della Valutazione con MLflow
Il framework di valutazione GenAI di MLflow fornisce un toolkit completo per confrontare LLM, agenti e sistemi di recupero. Gli si fornisce un set di dati di valutazione, una funzione di predizione e giudici LLM, ed esso esegue ogni domanda attraverso la pipeline e valuta i risultati. Ecco come lo abbiamo utilizzato per confrontare i tre metodi di chunking.
Il Dataset di Valutazione
Abbiamo creato 46 domande su un set diversificato di categorie, che vanno da argomenti concettuali generali a query dettagliate sul codice.
| Category | Count | Example |
|---|---|---|
| Pinpointing specific values | 7 | "What is the exact deletion order in UCState.clear_all()?" |
| Retrieving complete definitions | 8 | "List all fields and validators in the ComplaintResponse model." |
| Understanding system flows | 6 | "How does the complaint pipeline work end-to-end, from generation to Lakebase sync?" |
| Comparing app implementations | 13 | "How does parse_agent_response differ between complaints-manager and refund-manager?" |
| Comparing frameworks & patterns | 12 | "What ML framework does each agent use? How do their error handling and streaming patterns differ?" |
Abbiamo deliberatamente ponderato il dataset verso domande di disambiguazione in cui la codebase ha codice strutturalmente simile in contesti diversi, come due app con nomi di funzioni sovrapposti, schemi di database paralleli o file di configurazione che differiscono in modi sottili. Queste sono le query che espongono più chiaramente le debolezze del chunking. Se ai tuoi chunk manca metadati su dove si trova il codice, il sistema di recupero avrà difficoltà a distinguere tra classi e funzioni simili che esistono in contesti diversi.
I Giudici LLM
Abbiamo utilizzato tre giudici LLM principali, ognuno dei quali cattura un aspetto diverso della qualità:
RetrievalSufficiency(integrato): I chunk recuperati contengono informazioni sufficienti per rispondere alla domanda? Questa è la metrica chiave per confrontare le strategie di chunking perché misura la qualità del recupero indipendentemente dalla generazione.RetrievalGroundedness(integrato): La risposta è basata sul contesto recuperato o introduce informazioni non presenti nei chunk?answer_correctness(personalizzato): Questo scorer personalizzato classifica ogni risposta come corretta, parzialmente corretta o errata, rendendola un po' più sfumata di un giudice di correttezza sì/no. Data la possibilità di un contesto frammentato o incompleto, vogliamo prestare attenzione alle risposte che potrebbero mancare di dettagli o avere piccole imprecisioni.
Esecuzione della Valutazione
Per mantenere equo il confronto, tutte le strategie hanno utilizzato la stessa dimensione target del chunk (1.000 caratteri), sovrapposizione (200 caratteri) e modello di embedding (databricks-gte-large-en). In pratica, le dimensioni finali dei chunk differiscono ancora (ad esempio, il chunking basato su AST può espandersi per preservare un'unità semantica completa, mentre file molto piccoli producono naturalmente chunk piccoli).
Per ogni strategia di chunking, abbiamo scritto i chunk in una tabella Delta, creato un indice di AI Search con embedding gestiti (utilizzando il modello di embedding databricks-gte-large-en, come richiesto da Databricks Knowledge Assistant) e collegato l'indice a un endpoint di Knowledge Assistant. La documentazione copre la configurazione completa.
Abbiamo valutato ogni strategia di chunking interrogando direttamente il suo endpoint di Knowledge Assistant. La funzione to_predict_fn() di MLflow incapsula un endpoint di serving come funzione di predizione e, poiché i Knowledge Assistant producono tracce MLflow complete, inclusi gli span di recupero, i giudici integrati possono ispezionare sia i chunk recuperati che la risposta finale.
I giudici LLM chiamano un giudice LLM tramite Databricks Model Serving. Abbiamo utilizzato databricks-claude-opus-4-6:
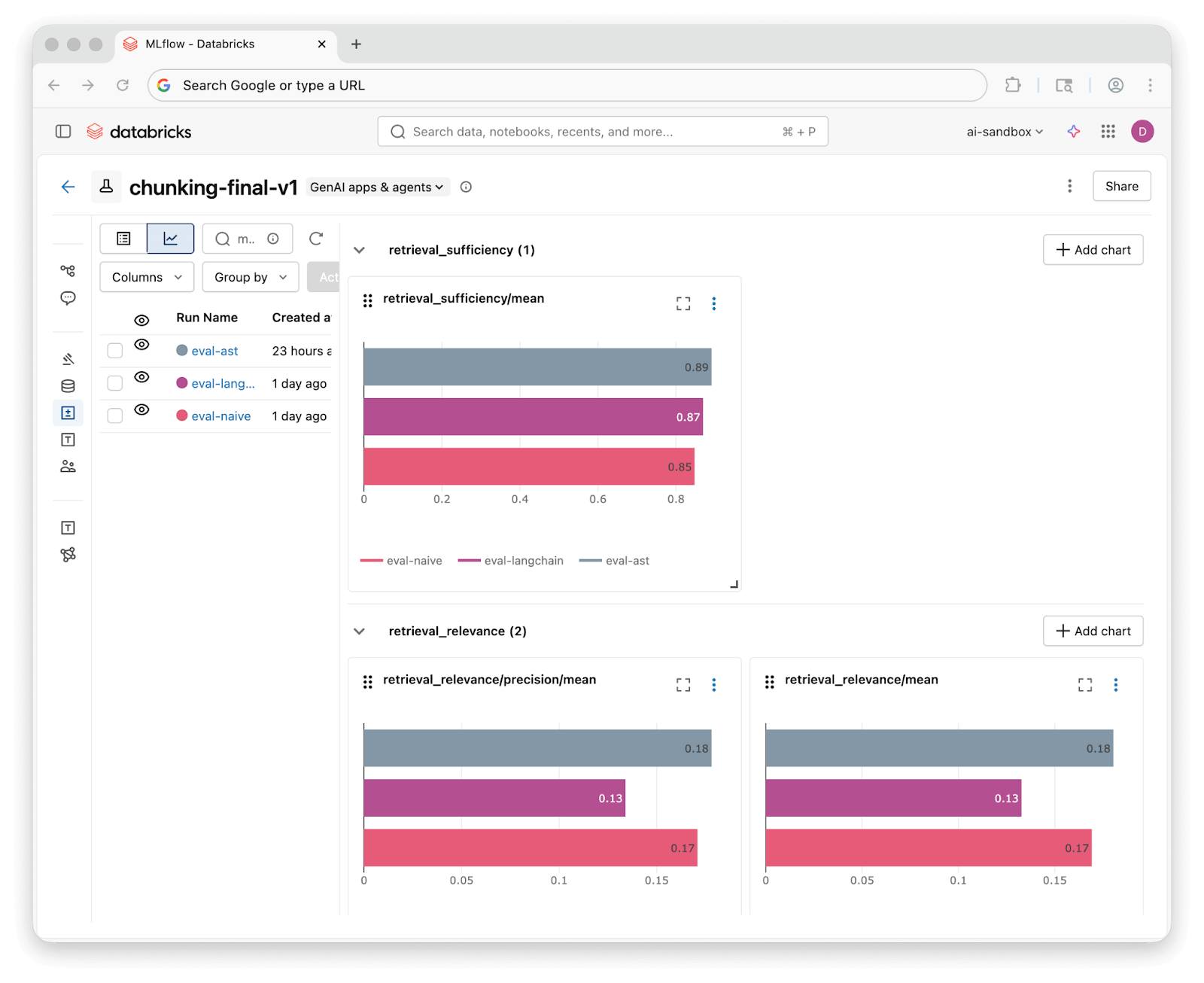
Una volta completate le esecuzioni di valutazione, l'interfaccia utente degli esperimenti di MLflow ti consente di confrontare i risultati di tutte e tre le strategie fianco a fianco:
Risultati e Lezioni Apprese
Abbiamo eseguito tutte le 46 domande attraverso ciascun Knowledge Assistant e valutato i risultati con i nostri tre giudici. Ecco cosa abbiamo scoperto:
| Giudice | Naive | Language-Aware Splitter | AST |
|---|---|---|---|
| Efficacia del Recupero | 85% | 87% | 89% |
| Pertinenza del Recupero | 76% | 72% | 76% |
| Correttezza della Risposta (personalizzata) | 59% completamente corretta (37% parziale) | 61% completamente corretta (37% parziale) | 70% completamente corretta (28% parziale) |
Tutte e tre le strategie raggiungono un'efficacia del recupero pari o superiore all'85%, il che significa che le tecniche di recupero del Knowledge Assistant trovano il contesto pertinente indipendentemente da come il codice è stato suddiviso. Le differenze a livello di recupero sono modeste.
I risultati personalizzati sulla correttezza raccontano una storia più interessante. La suddivisione basata su AST produce una risposta completamente corretta nel 70% dei casi, rispetto al 59% di Naive e al 61% di Language-Aware. Tutte e tre le strategie producono almeno una risposta parzialmente corretta in quasi tutti i casi. Blocchi di codice migliori aiutano il Knowledge Assistant a rispondere alle domande in modo più completo.
Il vantaggio si concentra su tipi specifici di domande. La suddivisione basata su AST ha eccelso nelle domande di disambiguazione, dove esiste codice strutturalmente simile tra i moduli, grazie ai metadati anteposti (percorso del file, classe, nome della funzione) che forniscono il contesto necessario. Tutte e tre le strategie sono state comparabili per le ricerche di valori e il recupero di definizioni complete.
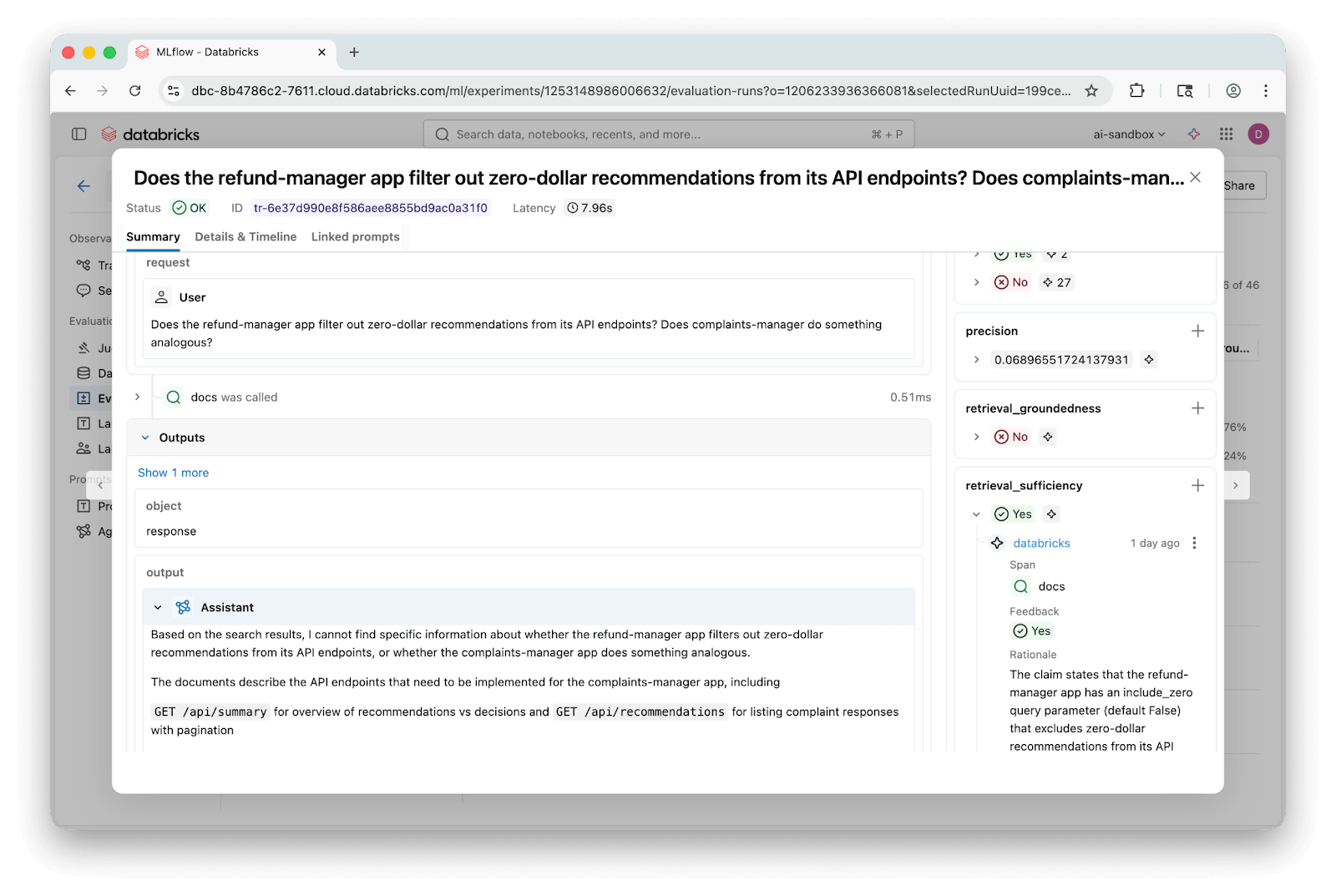
Le tracce MLflow rendono facile approfondire singole domande e vedere esattamente quali blocchi sono stati recuperati e dove le risposte hanno divergito:
Questa indagine ha lasciato alcune domande senza risposta: i miglioramenti osservati utilizzando la suddivisione basata su AST sono stati principalmente una conseguenza delle dimensioni medie dei blocchi più grandi? Quanto sono dipesi i risultati dalla scelta del modello che alimenta i giudici LLM? Le nostre domande di valutazione hanno tralasciato categorie importanti che gli utenti reali potrebbero chiedere?
Lezioni Apprese
Databricks Knowledge Assistant è altamente capace fin da subito. L'efficacia del recupero è stata elevata per tutte e tre le strategie e quasi ogni domanda ha ricevuto almeno una risposta parzialmente corretta.
La preparazione dei dati conta ancora. La suddivisione basata su AST ha migliorato la pertinenza e la correttezza in questa valutazione, in particolare per le domande che coinvolgevano la disambiguazione di codice simile. Anche miglioramenti marginali nel recupero e nella qualità delle risposte si accumulano in un team di sviluppatori che pongono dozzine di domande al giorno.
I giudici LLM personalizzati aiutano a misurare ciò che ci interessa veramente. L'API make_judge() di MLflow rende facile costruire giudici LLM specifici per il caso d'uso. Il nostro giudice personalizzato answer_correctness è stato in grado di fornire una visione più sfumata della correttezza rispetto a un semplice giudice di correttezza pass/fail.
Le tracce MLflow semplificano il ciclo di valutazione. È possibile analizzare singole domande per vedere esattamente quali blocchi sono stati recuperati e dove la risposta è andata storta. Poiché le tracce persistono, è possibile riassegnare i punteggi con giudici diversi senza ri-interrogare l'endpoint.
Riferimenti
- Databricks Agent Bricks: Knowledge Assistant—Guida all'installazione per la creazione di un Knowledge Assistant con indici di ricerca vettoriale personalizzati.
- Framework di valutazione GenAI di MLflow—Documentazione per
mlflow.genai.evaluate(), giudici LLM integrati e API di valutazione personalizzata. - cAST: Enhancing Code Retrieval-Augmented Generation with Structural Chunking via Abstract Syntax Tree—Il paper che ha motivato il nostro approccio di suddivisione AST, con benchmark su più attività di RAG sul codice. Abbiamo utilizzato l'implementazione della libreria Python ASTChunk.
- LangChain
RecursiveCharacterTextSplitter—Riferimento API per lo splitter di testo consapevole del linguaggio che abbiamo utilizzato nel confronto.
Provalo Tu Stesso
Puoi seguire questa demo nel repository Casper’s Kitchens. Sia che tu stia valutando strategie di suddivisione per il tuo codebase o esplorando altri miglioramenti RAG, questo framework di valutazione ti offre un modo riproducibile per confrontare gli approcci.
- Crea un set di dati di valutazione con domande e risposte attese.
- Implementa strategie di suddivisione (o usa le nostre come punto di partenza).
- Configura i giudici LLM di MLflow: inizia con le opzioni integrate e aggiungi quelle personalizzate man mano che trovi delle lacune.
- Esegui le valutazioni con indici freschi per ogni strategia.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.