Retriever Istruito: abilitare il ragionamento a livello di sistema negli agenti di ricerca
Gli agenti basati sul recupero sono al centro di molti casi d'uso aziendali mission-critical. I clienti enterprise si aspettano che eseguano compiti di ragionamento che richiedono di seguire istruzioni specifiche dell'utente e di operare efficacemente su fonti di conoscenza eterogenee. Tuttavia, molto spesso, la tradizionale generazione aumentata dal recupero (RAG) non riesce a tradurre l'intento dettagliato dell'utente e le specifiche delle fonti di conoscenza in query di ricerca precise. La maggior parte delle soluzioni esistenti ignora di fatto questo problema, impiegando strumenti di ricerca standard. Altre sottovalutano drasticamente la sfida, affidandosi esclusivamente a modelli personalizzati per l'embedding e il riordinamento, che sono fondamentalmente limitati nella loro espressività. In questo blog, presentiamo l'Instructed Retriever, una nuova architettura di recupero che affronta i limiti della RAG e reinventa la ricerca per l'era degli agenti. Illustriamo quindi come questa architettura consenta agenti basati sul recupero più capaci, inclusi sistemi come Agent Bricks: Knowledge Assistant, che devono ragionare su dati aziendali complessi e mantenere una rigorosa aderenza alle istruzioni dell'utente.
Si consideri, ad esempio, l'esempio nella Figura 1, in cui un utente chiede informazioni sull'aspettativa di vita della batteria di un prodotto fittizio FooBrand. Inoltre, le specifiche di sistema includono istruzioni sulla data di aggiornamento, sui tipi di documento da considerare e sulla lunghezza della risposta. Per seguire correttamente le specifiche di sistema, la richiesta dell'utente deve prima essere tradotta in query di ricerca strutturate che contengano gli appositi filtri di colonna oltre alle parole chiave. Successivamente, deve essere generata una risposta concisa basata sui risultati della query, in base alle istruzioni dell'utente. Un'esecuzione così complessa e deliberata delle istruzioni non è realizzabile con una semplice pipeline di recupero incentrata solo sulla query dell'utente.
![Figura 1. Esempio del flusso di lavoro di recupero con istruzioni per la query [Qual è l'autonomia prevista della batteria per i prodotti FooBrand]. Le istruzioni dell'utente vengono tradotte in (a) due query di recupero strutturate, che recuperano sia le recensioni recenti che una descrizione ufficiale del prodotto (b) una risposta breve, basata sui risultati di ricerca.](https://www.databricks.com/sites/default/files/inline-images/image7_24.png)
Le pipeline RAG tradizionali si basano sul recupero in un unico passaggio utilizzando solo la query dell'utente e non incorporano altre specifiche di sistema come istruzioni, esempi o schemi di origini dati. Tuttavia, come mostrato nella Figura 1, queste specifiche sono fondamentali per una corretta esecuzione delle istruzioni nei sistemi di ricerca basati su agenti. Per ovviare a queste limitazioni e per completare correttamente attività come quella descritta nella Figura 1, la nostra architettura Instructed Retriever consente il flusso di specifiche di sistema in ciascuno dei componenti del sistema.
Anche al di là di RAG, nei sistemi di ricerca agentivi più avanzati che consentono l'esecuzione iterativa della ricerca, la capacità di seguire le istruzioni e la comprensione dello schema della fonte di conoscenza sottostante sono capacità chiave che non possono essere abilitate semplicemente eseguendo RAG come strumento per più passaggi, come illustrato nella Tabella 1. Pertanto, l'architettura dell'Instructed Retriever fornisce un'alternativa a RAG altamente performante quando sono richieste bassa latenza e un footprint ridotto del modello, abilitando al contempo agenti di ricerca più efficaci per scenari come la ricerca approfondita.
Retrieval Augmented Generation (RAG, Generazione potenziata dal recupero) | Retriever istruito | Agente multi-passo (RAG) | Agente a più passaggi (Retriever Istruito) | |
Numero di passaggi di ricerca | Singolo | Singolo | Multipli | Multipli |
Capacità di seguire le istruzioni | ✖️ | ✅ | ✖️ | ✅ |
Comprensione della fonte di conoscenza | ✖️ | ✅ | ✖️ | ✅ |
Bassa latenza | ✅ | ✅ | ✖️ | ✖️ |
Impronta ridotta del modello | ✅ | ✅ | ✖️ | ✖️ |
Ragionamento sugli output | ✖️ | ✖️ | ✅ | ✅ |
Tabella 1. Riepilogo delle funzionalità del RAG tradizionale, dell'Instructed Retriever e di un agente di ricerca multi-passaggio implementato utilizzando uno dei due approcci come strumento
Per dimostrare i vantaggi dell'Instructed Retriever, la Figura 2 mostra in anteprima le sue prestazioni rispetto alle baseline basate su RAG su una suite di set di dati di domande e risposte aziendali1. Su questi benchmark complessi, l'Instructed Retriever aumenta le prestazioni di oltre il 70% rispetto al RAG tradizionale. L'Instructed Retriever supera persino del 10% un agente multi-passaggio basato su RAG. Incorporarlo come strumento in un agente multi-passaggio comporta ulteriori vantaggi, riducendo al contempo il numero di passaggi di esecuzione, rispetto a RAG.
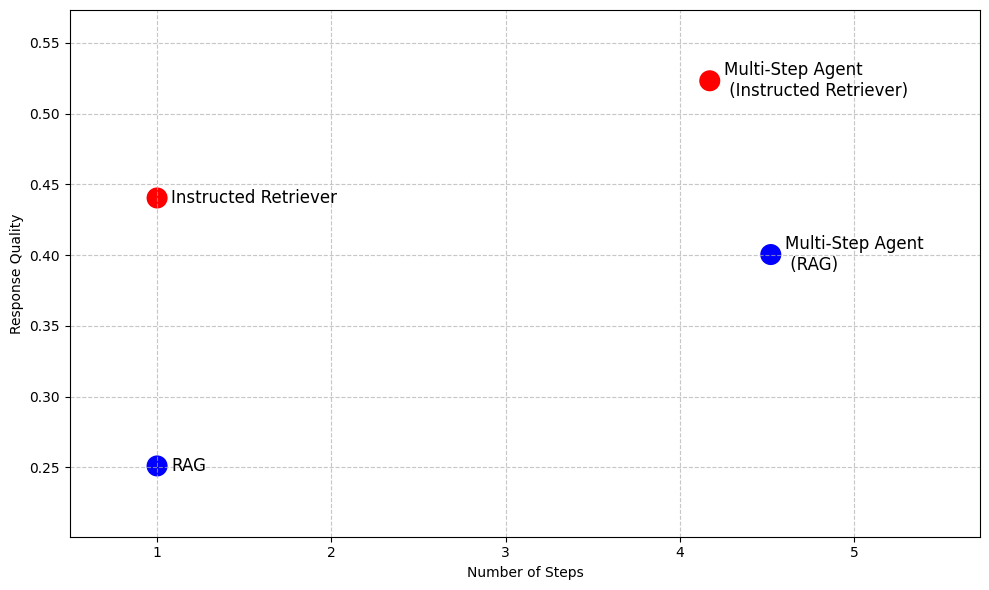
Nel resto del post su un blog, discutiamo la progettazione e l'implementazione di questa nuova architettura Instructed Retriever. Dimostriamo che l'instructed retriever porta a un'esecuzione precisa e solida delle istruzioni nella fase di generazione della query, il che si traduce in miglioramenti significativi nella recall di recupero. Inoltre, mostriamo che queste funzionalità di generazione di query possono essere sbloccate anche in modelli di piccole dimensioni tramite l'apprendimento per rinforzo offline. Infine, analizziamo ulteriormente le prestazioni end-to-end dell'instructed retriever, sia in configurazioni agentiche a singolo passaggio che a più passaggi. Mostriamo che consente costantemente miglioramenti significativi nella qualità della risposta rispetto alle architetture RAG tradizionali.
Architettura Instructed Retriever
Per affrontare le sfide del ragionamento a livello di sistema nei sistemi di recupero agentivi, proponiamo una nuova architettura Instructed Retriever, mostrata nella Figura 3. L'Instructed Retriever può essere richiamato in un flusso di lavoro statico o esposto come strumento a un agente. L'innovazione chiave è che questa nuova architettura fornisce un modo semplificato non solo per rispondere alla query immediata dell'utente, ma anche per propagare l'interezza delle specifiche di sistema sia ai componenti di recupero che a quelli di generazione del sistema. Questo rappresenta un cambiamento fondamentale rispetto alle pipeline RAG tradizionali, in cui le specifiche di sistema possono (nel migliore dei casi) influenzare la query iniziale ma vengono poi perse, costringendo il retriever e il generatore di risposte a operare senza il contesto vitale di queste specifiche.
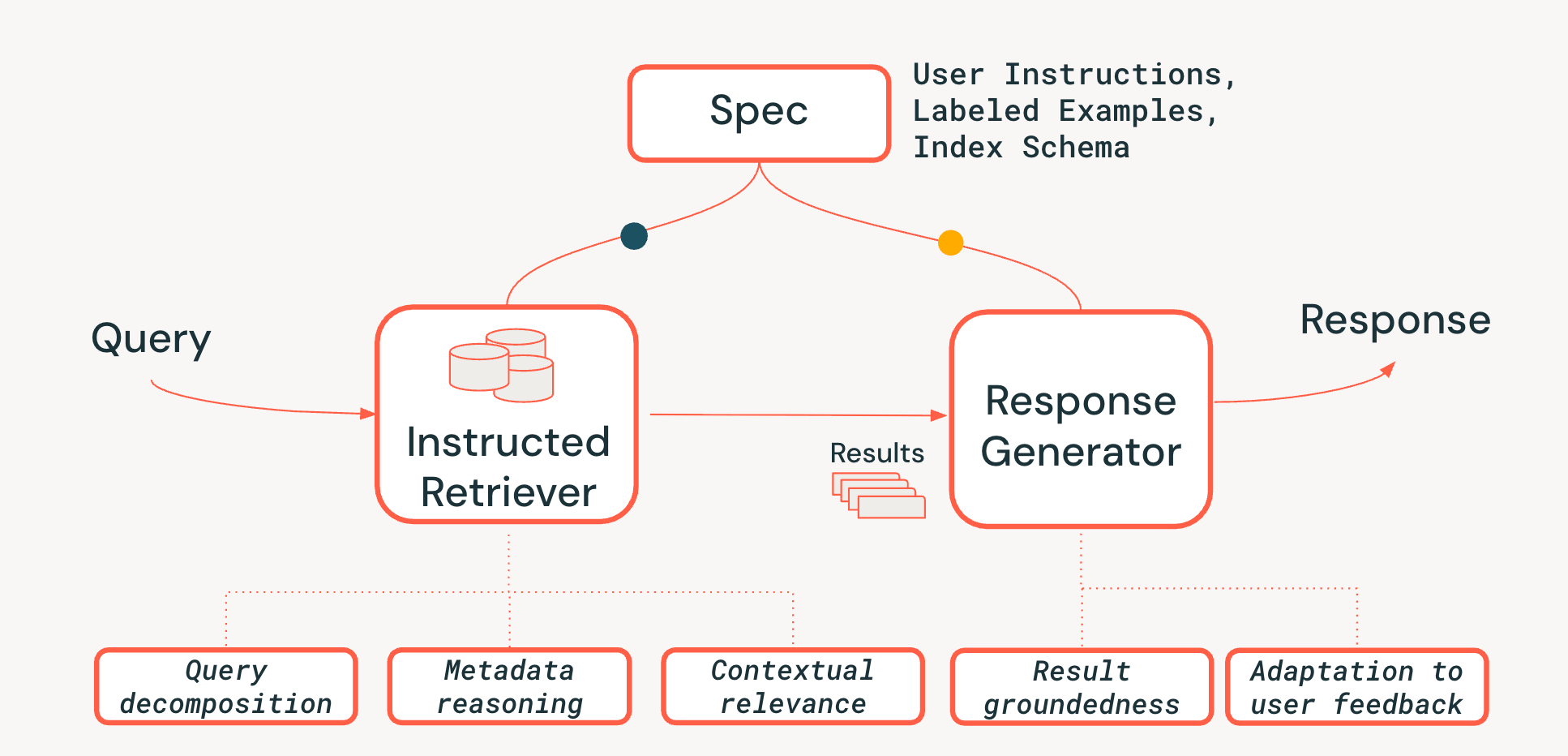
Le specifiche di sistema sono quindi un insieme di principi guida e istruzioni che l'agente deve seguire per soddisfare fedelmente la richiesta dell'utente e possono includere:
- Istruzioni utente: Preferenze o vincoli generali, come "focalizzati sulle recensioni degli ultimi anni" o "Non mostrare nessun prodotto FooBrand nei risultati".
- Esempi etichettati: campioni concreti di coppie <query, document> pertinenti/non pertinenti che aiutano a definire come si presenta un recupero di alta qualità e conforme alle istruzioni per un'attività specifica.
- Descrizioni dell'indice: Uno schema che indica all'agente quali metadati sono effettivamente disponibili per il recupero (ad esempio, product_brand, doc_timestamp, nell'esempio della Figura 1).2
Per sbloccare la persistenza delle specifiche lungo l'intera pipeline, aggiungiamo tre funzionalità critiche al processo di recupero:
- Scomposizione della query: La capacità di scomporre una richiesta complessa e articolata ("Trovami un prodotto FooBrand, ma solo dell'anno scorso e non un modello 'lite'") in un piano di ricerca completo, contenente più ricerche per parole chiave e istruzioni di filtro.
- Rilevanza contestuale: Andare oltre la semplice somiglianza testuale verso una reale comprensione della rilevanza nel contesto della query e delle istruzioni di sistema. Ciò significa che il re-ranker, ad esempio, può utilizzare le istruzioni per dare maggiore risalto ai documenti che corrispondono all'intento dell'utente (ad es. "recency"), anche se le parole chiave hanno una corrispondenza più debole.
- Ragionamento sui metadati: Uno dei principali elementi di differenziazione della nostra architettura Instructed Retriever è la capacità di tradurre istruzioni in linguaggio naturale ("dell'anno scorso") in filtri di ricerca precisi ed eseguibili ("doc_timestamp > TO_TIMESTAMP('2024-11-01')").
Garantiamo inoltre che la fase di generazione della risposta sia conforme ai risultati recuperati, alle specifiche di sistema e a qualsiasi cronologia o feedback precedente dell'utente (come descritto più dettagliatamente in questo blog).
L'aderenza alle istruzioni negli agenti di ricerca è una sfida perché le esigenze informative dell'utente possono essere complesse, vaghe o addirittura contrastanti, spesso accumulate attraverso molti cicli di feedback in linguaggio naturale. Il recuperatore deve anche essere consapevole dello schema , in grado di tradurre il linguaggio dell'utente in filtri, campi e metadati strutturati che esistono effettivamente nell'indice. Infine, i componenti devono lavorare insieme in modo trasparente per soddisfare questi vincoli complessi, a volte a più livelli, senza tralasciarne o malinterpretarne nessuno. Tale coordinamento richiede un ragionamento olistico a livello di sistema. Come dimostrano i nostri esperimenti nelle prossime due sezioni, l'architettura Instructed Retriever rappresenta un importante passo avanti per sbloccare questa capacità nei flussi di lavoro e negli agenti di ricerca.
Valutazione del rispetto delle istruzioni nella generazione di query
La maggior parte dei benchmark di recupero esistenti trascura il modo in cui i modelli interpretano ed eseguono le specifiche in linguaggio naturale, in particolare quelle che comportano vincoli strutturati basati sullo schema dell'indice. Pertanto, per valutare le capacità della nostra architettura Instructed Retriever, abbiamo esteso il set di dati StaRK (Semi-Structured Retrieval Benchmark) e progettato un nuovo benchmark di recupero basato su istruzioni, StaRK-Instruct, utilizzando il suo sottoinsieme di e-commerce, STaRK-Amazon.
Per il nostro set di dati, ci concentriamo su tre tipi comuni di istruzioni per l'utente che richiedono al modello di ragionare oltre la semplice somiglianza testuale:
- Istruzioni di inclusione – selezione di documenti che devono contenere un determinato attributo (ad es. “trova una giacca di FooBrand con la valutazione migliore per il freddo”).
- Istruzioni di esclusione – filtrare gli elementi che non devono apparire nei risultati (ad esempio, “consigliami un SUV a basso consumo, ma ho avuto esperienze negative con FooBrand, quindi evita qualsiasi loro prodotto”).
- Recency boosting – preferire gli articoli più recenti quando sono disponibili metadati relativi al tempo (ad es. “Quali portatili FooBrand sono invecchiati bene? Dai priorità alle recensioni degli ultimi 2-3 anni: le recensioni più vecchie sono meno importanti a causa delle modifiche dell'OS”).
Per creare StaRK-Instruct, pur essendo in grado di riutilizzare i giudizi di pertinenza esistenti di StaRK-Amazon, seguiamo lavori precedenti sull'esecuzione di istruzioni nel recupero di informazioni e sintetizziamo le query esistenti in query più specifiche includendo vincoli aggiuntivi che restringono le definizioni di pertinenza esistenti. I set di documenti pertinenti vengono quindi filtrati a livello di codice per garantire l'allineamento con le query riscritte. Tramite questo processo, sintetizziamo 81 query StaRK-Amazon (19,5 documenti pertinenti per query) in 198 query in StaRK-Instruct (11,7 documenti pertinenti per query, per i tre tipi di istruzioni).
Per valutare le capacità di generazione di query di Instructed Retriever utilizzando StaRK-Instruct, valutiamo i seguenti metodi (in una configurazione di recupero a passo singolo)
- Query non elaborata: come baseline, usiamo la query originale dell'utente per il recupero, senza ulteriori fasi di generazione delle query. Questo è simile a un approccio RAG tradizionale.
- GPT5-nano, GPT5.2, Claude4.5-Sonnet – utilizziamo ciascuno dei rispettivi modelli per generare query di recupero, usando le query utente originali, le specifiche di sistema (comprese le istruzioni utente) e lo schema dell'indice.
- InstructedRetriever-4B – Anche se i modelli di frontiera come GPT5.2 e Claude4.5-Sonnet sono molto efficaci, possono anche essere troppo costosi per attività come la generazione di query e filtri, specialmente per implementazioni su larga scala. Pertanto, applichiamo il meccanismo Test-time Adaptive Optimization (TAO), che sfrutta il test-time compute e l'apprendimento per rinforzo offline (RL) per insegnare a un modello a svolgere meglio un'attività basandosi su esempi di input passati. Nello specifico, utilizziamo il sottoinsieme di query "sintetizzate" da StaRK-Amazon, e generiamo ulteriori query di esecuzione delle istruzioni utilizzando queste query sintetizzate. Utilizziamo direttamente la recall come segnale di ricompensa per il fine-tuning di un piccolo modello da 4B parameter, campionando chiamate a strumenti candidati e rinforzando quelle che ottengono punteggi di recall più alti.
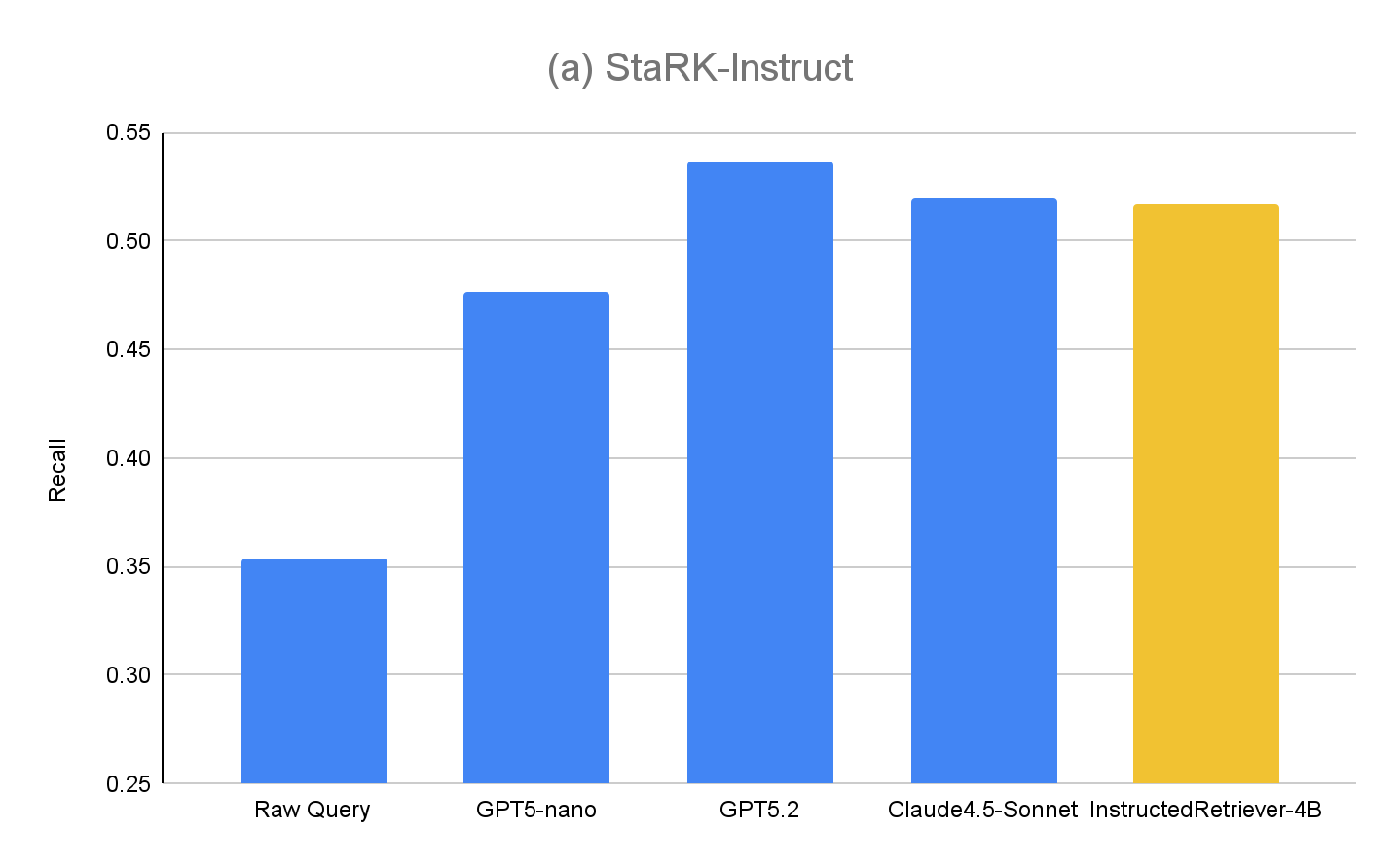
I risultati per StaRK-Instruct sono mostrati nella Figura 4(a). La generazione di query guidata da istruzioni ottiene un recall più alto del 35–50% sul benchmark StaRK-Instruct rispetto alla baseline Raw Query. I miglioramenti sono costanti per tutte le dimensioni dei modelli, a conferma che un efficace parsing delle istruzioni e una formulazione di query strutturate possono fornire miglioramenti misurabili anche con budget computazionali limitati. I modelli piùgrandi generalmente mostrano ulteriori miglioramenti, suggerendo la scalabilità dell'approccio con la capacità del modello. Tuttavia, il nostro modello InstructedRetriever-4B sottoposto a fine-tuning eguaglia quasi le prestazioni di modelli di frontiera molto più grandi e supera quelle del modelloGPT5-nano, dimostrando che l'allineamento può migliorare sostanzialmente l'efficacia dell'esecuzione delle istruzioni nei sistemi di recupero basati su agenti, anche con modelli più piccoli.
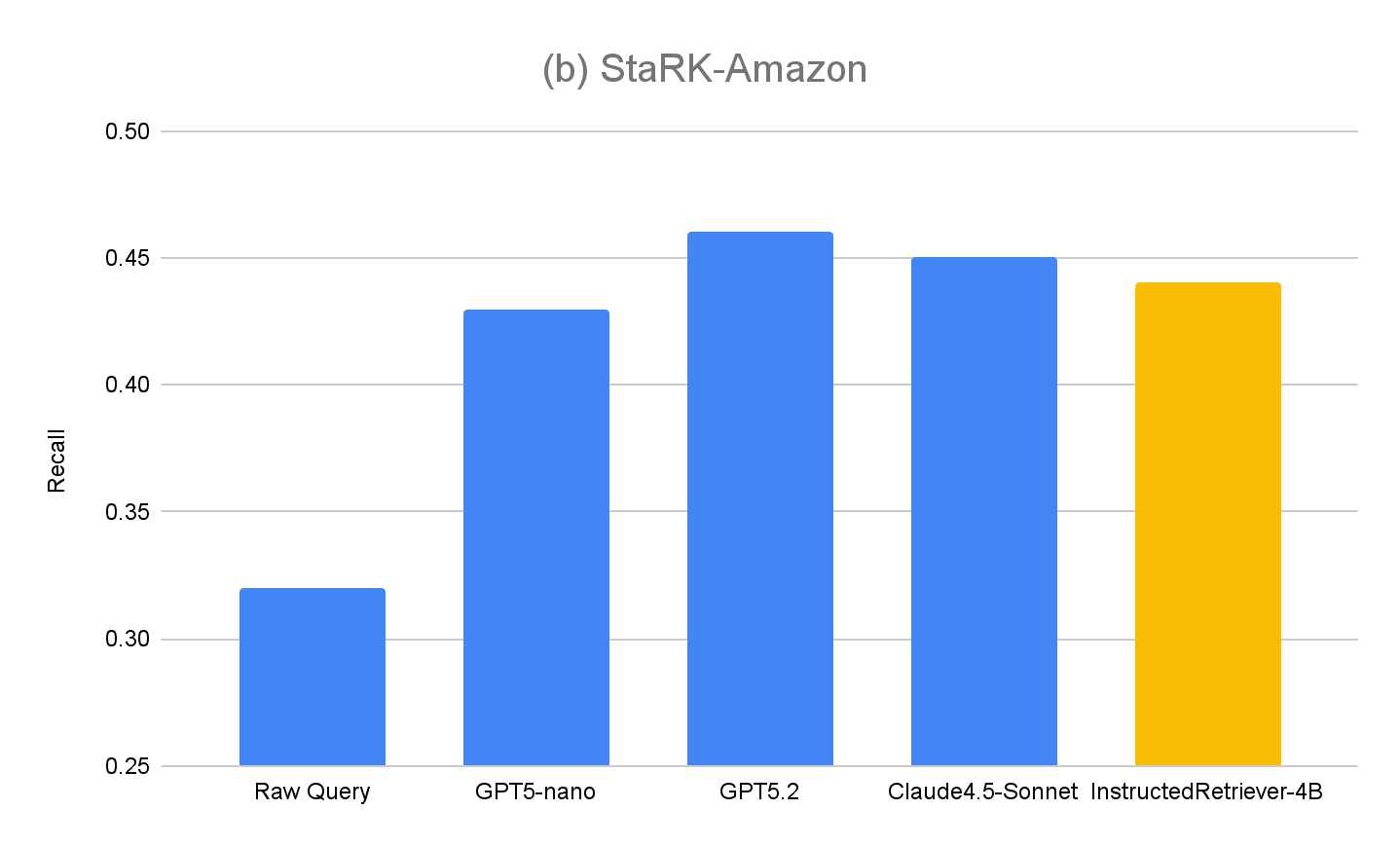
Per valutare ulteriormente la generalizzazione del nostro approccio, misuriamo anche le prestazioni sul set di valutazione originale, StaRK-Amazon, in cui le query non hanno istruzioni esplicite relative ai metadati. Come mostrato nella Figura 4(b), tutti i metodi di generazione di query istruiti superano il richiamo della query non elaborata su StaRK-Amazon di circa il 10%, confermando che il rispetto delle istruzioni è vantaggioso anche in scenari di generazione di query non vincolati. Inoltre, non osserviamo alcun degrado nelle prestazioni di InstructedRetriever-4B rispetto ai modelli non sottoposti a fine-tuning, a conferma del fatto che la specializzazione nella generazione di query strutturate non ne pregiudica le capacità generali di generazione di query.
Implementazione di Instructed Retriever in Agent Bricks
Nella sezione precedente, abbiamo dimostrato i significativi miglioramenti nella qualità del recupero ottenibili utilizzando la generazione di query guidata da istruzioni. In questa sezione, esploriamo ulteriormente l'utilità di un retriever istruito come parte di un sistema di recupero basato su agenti di livello produttivo. In particolare, Instructed Retriever è implementato in Agent Bricks Knowledge Assistant, un chatbot di QA a cui è possibile porre domande e ricevere risposte affidabili basate sulla conoscenza specializzata del dominio fornita.
Consideriamo due soluzioni DIY RAG come baseline:
- RAG Forniamo in input i migliori risultati recuperati dalla nostra vector search a elevate prestazioni a un modello linguistico di grandi dimensioni di frontiera per la generazione.
- RAG + Rerank Facciamo seguire alla fase di recupero una di riordinamento, che, come dimostrato in test precedenti, aumenta l'accuratezza del recupero di una media di 15 punti percentuali. I risultati riordinati vengono forniti a un modello linguistico di grandi dimensioni all'avanguardia per la generazione.
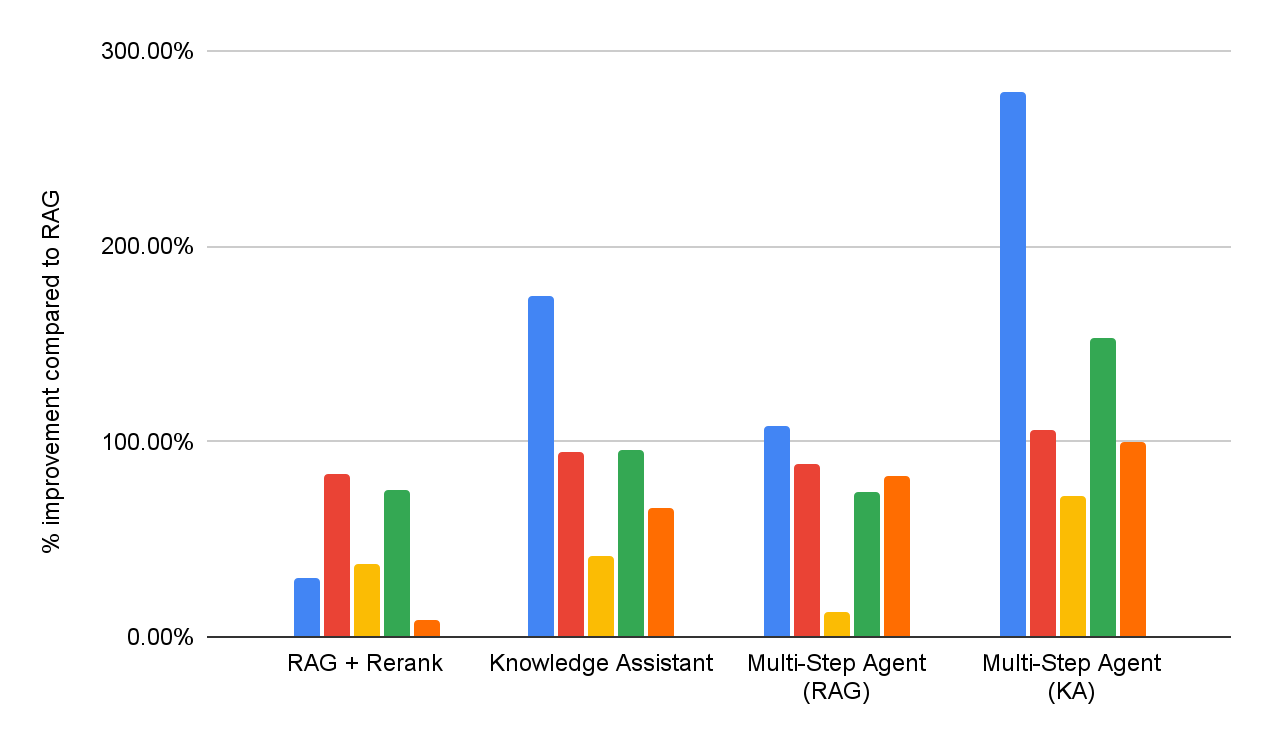
Per valutare l'efficacia sia delle soluzioni RAG DIY, sia di Knowledge Assistant, conduciamo una valutazione della qualità delle risposte sulla stessa suite di benchmark di question answering aziendale riportata nella Figura 1. Inoltre, implementiamo due agenti multi-passaggio che hanno accesso rispettivamente a RAG o a Knowledge Assistant come strumento di ricerca. Le prestazioni dettagliate per ciascun set di dati sono riportate nella Figura 5 (come miglioramento percentuale rispetto alla baseline RAG).
Nel complesso, possiamo vedere che tutti i sistemi superano costantemente la baseline RAG semplice su tutti i set di dati, riflettendo la sua incapacità di interpretare e applicare in modo coerente specifiche in più parti. L'aggiunta di una fase di re-ranking migliora i risultati, dimostrando un certo vantaggio derivante dalla modellazione della rilevanza post-hoc. Knowledge Assistant, implementato utilizzando l'architettura dell'Instructed Retriever, apporta ulteriori miglioramenti, indicando l'importanza di mantenere le specifiche di sistema – vincoli, esclusioni, preferenze temporali e filtri di metadati – in ogni fase del recupero e della generazione.
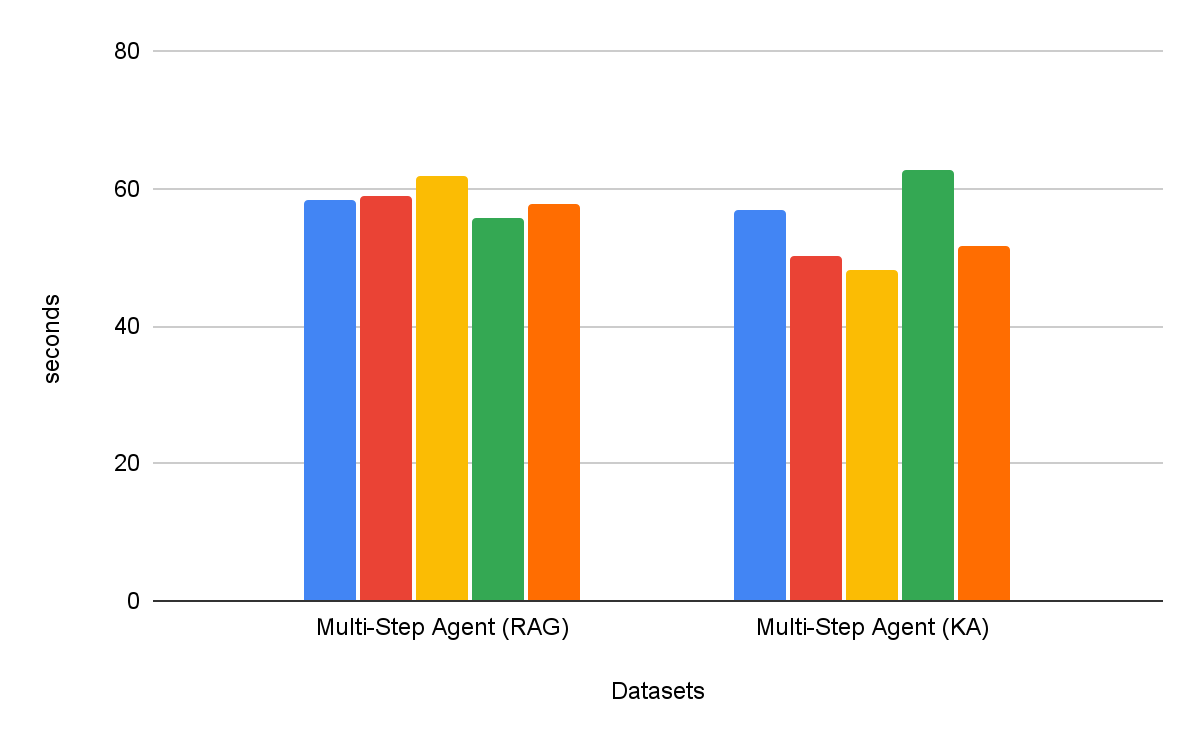
Gli agenti di ricerca multi-passo sono costantemente più efficaci dei flussi di lavoro di recupero a passo singolo. Inoltre, la scelta dello strumento è importante: Knowledge Assistant come strumento supera le prestazioni di RAG come strumento di oltre il 30%, con un miglioramento costante in tutti i set di dati. È interessante notare che non solo migliora la qualità, ma riduce anche il tempo di completamento dell'attività nella maggior parte dei set di dati, con una riduzione media dell'8% (Figura 6).
Conclusione
La creazione di agenti enterprise affidabili richiede la capacità di seguire istruzioni in modo completo e un ragionamento a livello di sistema durante il recupero di informazioni da fonti di conoscenza eterogenee. A tal fine, in questo blog presentiamo l'architettura Instructed Retriever, la cui innovazione principale consiste nel propagare le specifiche di sistema complete, dalle istruzioni agli esempi e allo schema dell'indice, in ogni fase della pipeline di ricerca.
Abbiamo anche presentato un nuovo set di dati StaRK-Instruct, che valuta la capacità di un agente di recupero di gestire istruzioni del mondo reale come inclusione, esclusione e data di aggiornamento. Su questo benchmark, l'architettura Instructed Retriever ha fornito sostanziali guadagni del 35-50% nella recall di recupero, dimostrando empiricamente i vantaggi di una consapevolezza delle istruzioni a livello di sistema per la generazione di query. Mostriamo anche che un modello piccolo ed efficiente può essere ottimizzato per eguagliare le prestazioni di esecuzione delle istruzioni di modelli proprietari più grandi, rendendo Instructed Retriever un'architettura agentica economica adatta per le implementazioni aziendali nel mondo reale.
Se integrata con un Agent Bricks Knowledge Assistant, l'architettura Instructed Retriever si traduce direttamente in risposte di qualità superiore e più accurate per l'utente finale. Nella nostra suite completa di benchmark ad alta difficoltà, offre miglioramenti superiori al 70% rispetto a una soluzione RAG semplicistica e un miglioramento della qualità superiore al 15% rispetto a soluzioni fai da te più sofisticate che incorporano il reranking. Inoltre, se integrato come strumento per un agente di ricerca multi-step, Instructed Retriever non solo può migliorare le prestazioni di oltre il 30%, ma anche ridurre il tempo di completamento delle attività dell'8%, rispetto a RAG utilizzato come strumento.
Instructed Retriever, insieme a molte innovazioni pubblicate in precedenza come l'ottimizzazione dei prompt, ALHF, TAO, RLVR, è ora disponibile nel prodotto Agent Bricks. Il principio fondamentale di Agent Bricks è aiutare le aziende a sviluppare agenti che ragionino accuratamente sui loro dati proprietari, apprendano continuamente dal feedback e raggiungano qualità ed efficienza dei costi all'avanguardia in attività specifiche del dominio. Incoraggiamo i clienti a provare il Knowledge Assistant e altri prodotti Agent Bricks per creare agenti indirizzabili ed efficaci per i propri casi d'uso aziendali.
Autori: Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 La nostra suite contiene un mix di cinque benchmark proprietari e accademici che testano le seguenti capacità: esecuzione delle istruzioni, ricerca specifica per dominio, generazione di report, generazione di elenchi e ricerca su PDF con layout complessi. Ogni benchmark è associato a un giudice di qualità personalizzato, basato sul tipo di risposta.
2 Ledescrizioni dell'indice possono essere incluse nell'istruzione specificata dall'utente o costruite automaticamente tramite metodi per il collegamento di schemi che sono spesso impiegati in sistemi per text-to-SQL, ad esempio, il recupero di valori.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.