Modellazione dei dati: best practice e implementazione su un Lakehouse moderno
Molti dei nostri clienti stanno migrando i loro data warehouse legacy a Databricks Lakehouse poiché consente loro di modernizzare non solo il loro Data Warehouse, ma ottengono anche un accesso immediato a una piattaforma matura per lo streaming e l'analisi avanzata. Lakehouse può fare tutto poiché è un'unica piattaforma per tutte le tue esigenze di streaming, ETL, BI e AI, e aiuta i tuoi team aziendali e di dati a collaborare su un'unica piattaforma.
Mentre aiutiamo i clienti sul campo, scopriamo che molti cercano le best practice relative alla corretta modellazione dei dati e all'implementazione di modelli di dati fisici in Databricks.
In questo articolo, miriamo ad approfondire la best practice della modellazione dimensionale sulla Databricks Lakehouse Platform e a fornire un esempio pratico di implementazione di un modello di dati fisico utilizzando le nostre best practice per la creazione di tabelle e DDL.
Ecco gli argomenti di alto livello che tratteremo in questo blog:
- L'importanza della modellazione dei dati
- Tecniche comuni di modellazione dei dati
- Implementazione DDL per la modellazione del Data Warehouse
- Best practice e raccomandazioni per la modellazione dei dati sul Databricks Lakehouse
L'importanza della modellazione dei dati per il Data Warehouse
I modelli di dati sono al centro della creazione di un Data Warehouse. Tipicamente il processo inizia con la difesa del Modello Semantico di Informazioni Aziendali, poi un Modello Dati Logico e infine un Modello Dati Fisico (PDM). Tutto inizia con una corretta fase di Analisi e Progettazione dei Sistemi in cui vengono creati prima un modello di informazioni aziendali e flussi di processo, e vengono catturate le entità aziendali chiave, gli attributi e le loro interazioni in base ai processi aziendali all'interno dell'organizzazione. Il Modello Dati Logico viene quindi creato raffigurando come le entità sono correlate tra loro ed è un modello indipendente dalla tecnologia. Infine, viene creato un PDM basato sulla piattaforma tecnologica sottostante per garantire che le scritture e le letture possano essere eseguite in modo efficiente. Come tutti sappiamo, per il Data Warehousing, gli stili di modellazione adatti all'analisi come lo Star-schema e il Data Vault sono piuttosto popolari.
Best practice per la creazione di un modello di dati fisico in Databricks
Sulla base del problema aziendale definito, l'obiettivo della progettazione del modello di dati è rappresentare i dati in modo semplice per riutilizzabilità, flessibilità e scalabilità. Ecco un tipico modello di dati a schema a stella che mostra una tabella dei fatti di vendita che contiene ogni transazione e varie tabelle dimensionali come clienti, prodotti, negozi, data, ecc. per cui è possibile affettare e tagliare i dati. Le dimensioni possono essere unite alla tabella dei fatti per rispondere a specifiche domande aziendali come quali sono i prodotti più popolari per un dato mese o quali negozi stanno performando meglio per il trimestre. Vediamo come implementarlo in Databricks.
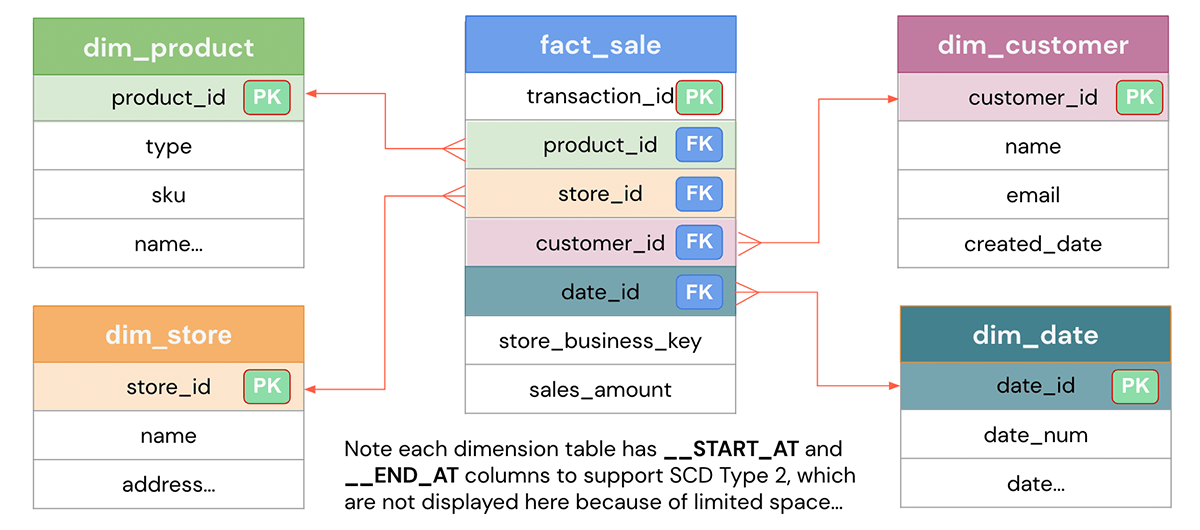
Implementazione DDL per la modellazione del Data Warehouse su Databricks
Nelle sezioni seguenti, dimostreremo quanto segue utilizzando i nostri esempi.
- Creazione di Cataloghi, Database e Tabelle a 3 livelli
- Definizioni di Primary Key e Foreign Key
- Colonne Identity per Surrogate Key
- Vincoli di colonna per la Data Quality
- Indice, ottimizzazione e analisi
- Tecniche avanzate
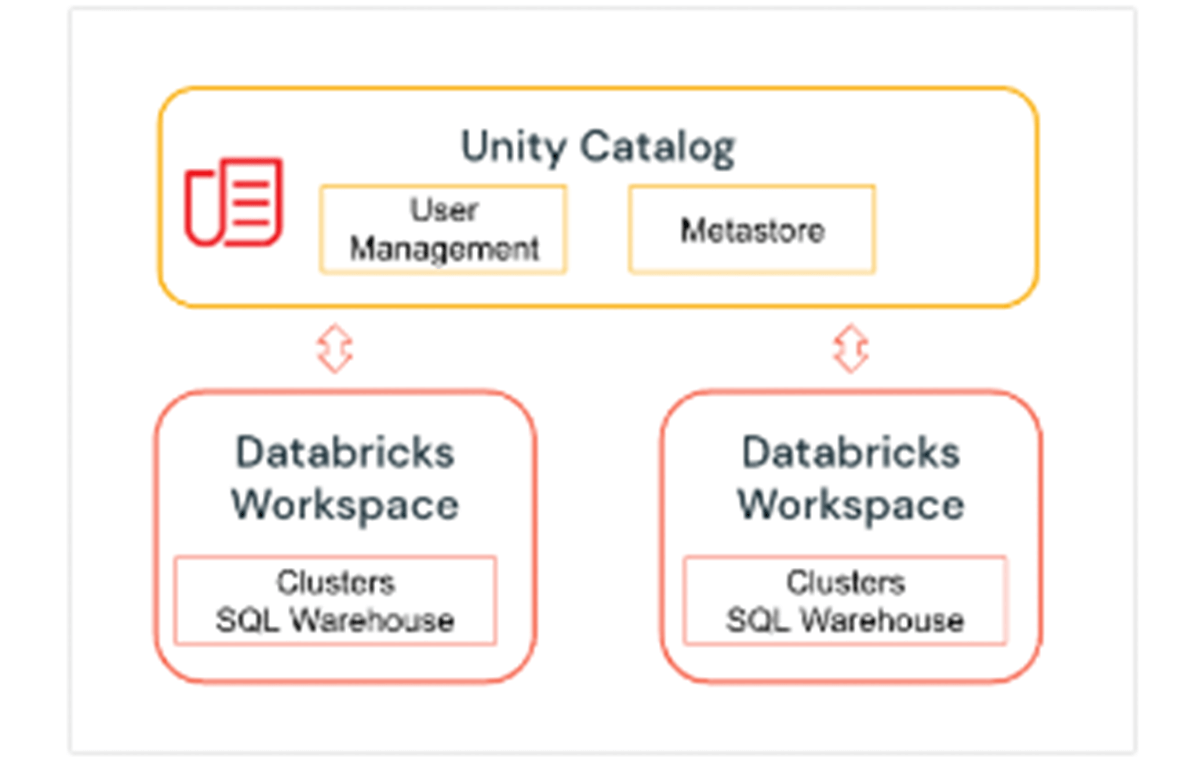
1. Unity Catalog - Namespace a 3 livelli
Unity Catalog è un livello di governance di Databricks che consente agli amministratori Databricks e agli steward dei dati di gestire centralmente utenti e il loro accesso ai dati in tutti gli spazi di lavoro di un account Databricks utilizzando un unico Metastore. Gli utenti in diversi spazi di lavoro possono condividere l'accesso agli stessi dati, a seconda dei privilegi concessi centralmente in Unity Catalog. Unity Catalog ha un namespace a 3 livelli (catalog.schema(database).table) che organizza i tuoi dati. Scopri di più su Unity Catalog qui.
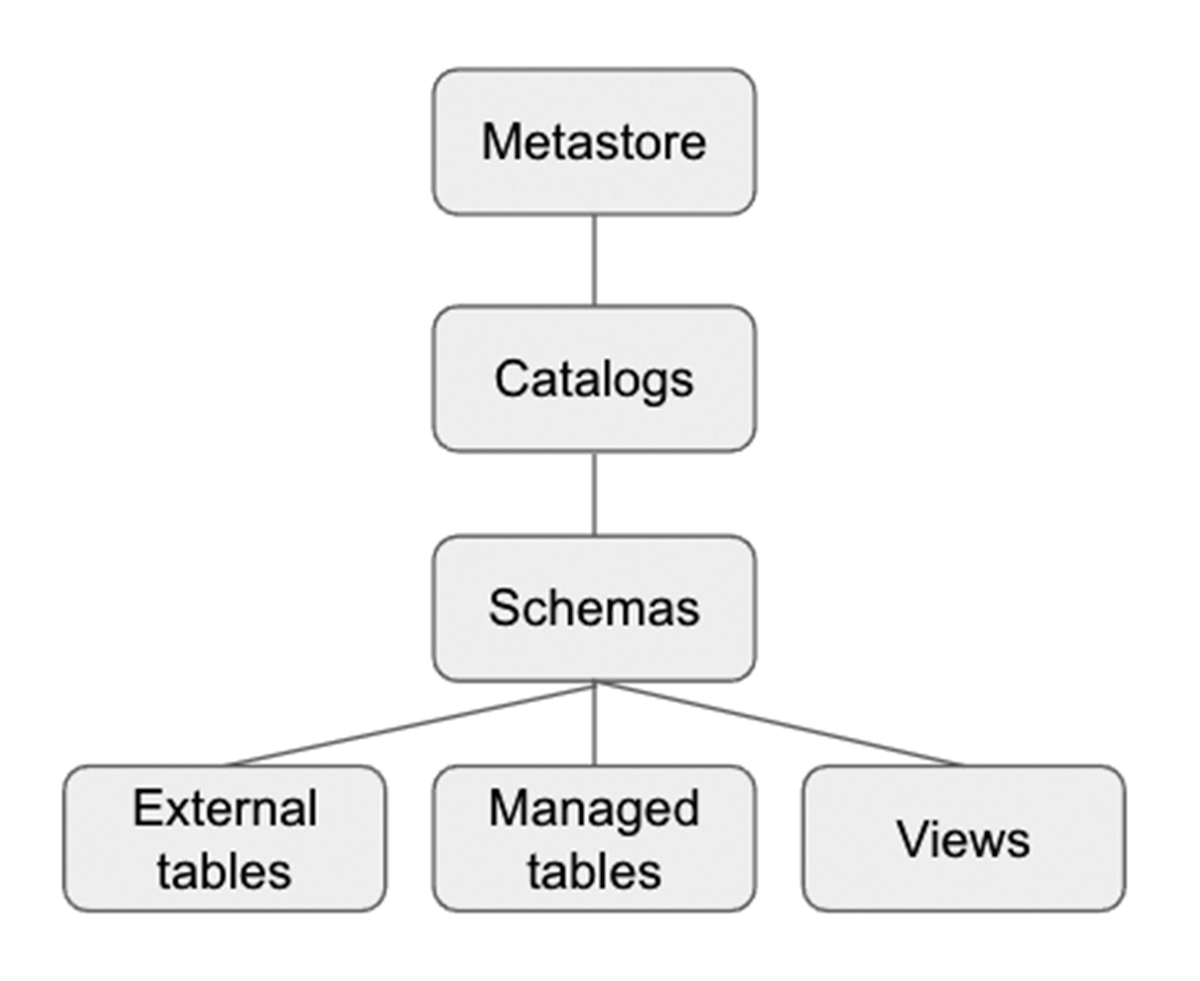
Ecco come impostare il catalogo e lo schema prima di creare tabelle all'interno del database. Per il nostro esempio, creiamo un catalogo US_Stores e uno schema (database) Sales_DW come segue, e li utilizziamo per la parte successiva della sezione.
Impostazione del Catalogo e del Database
Ecco un esempio di query sulla tabella fact_sales con un namespace a 3 livelli.
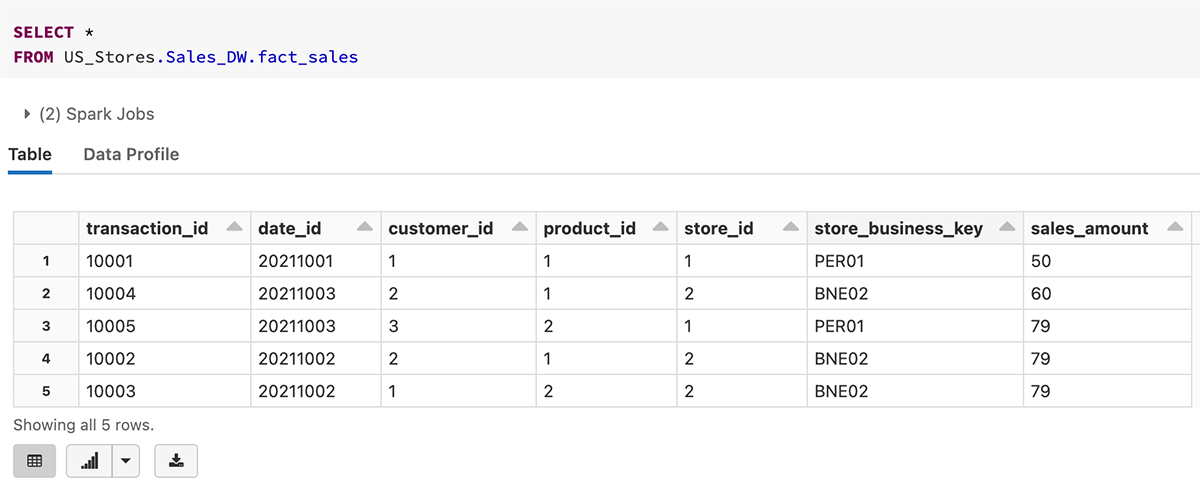
2. Definizioni di Primary Key e Foreign Key
Le definizioni di Primary Key e Foreign Key sono molto importanti nella creazione di un modello di dati. La capacità di supportare la definizione di PK/FK rende la definizione del modello di dati molto semplice in Databricks. Aiuta anche gli analisti a capire rapidamente le relazioni di join in Databricks SQL Warehouse in modo che possano scrivere query in modo efficace. Come la maggior parte degli altri MPP (Massively Parallel Processing), EDW e Cloud Data Warehouse, i vincoli PK/FK sono solo informativi. Databricks non supporta l'applicazione della relazione PK/FK, ma offre la possibilità di definirla per semplificare la progettazione del Modello Dati Semantico.
Ecco un esempio di creazione della tabella dim_store con store_id come colonna Identity e definita contemporaneamente come Primary Key.
Implementazione DDL per la creazione della dimensione negozio con definizioni di Primary Key
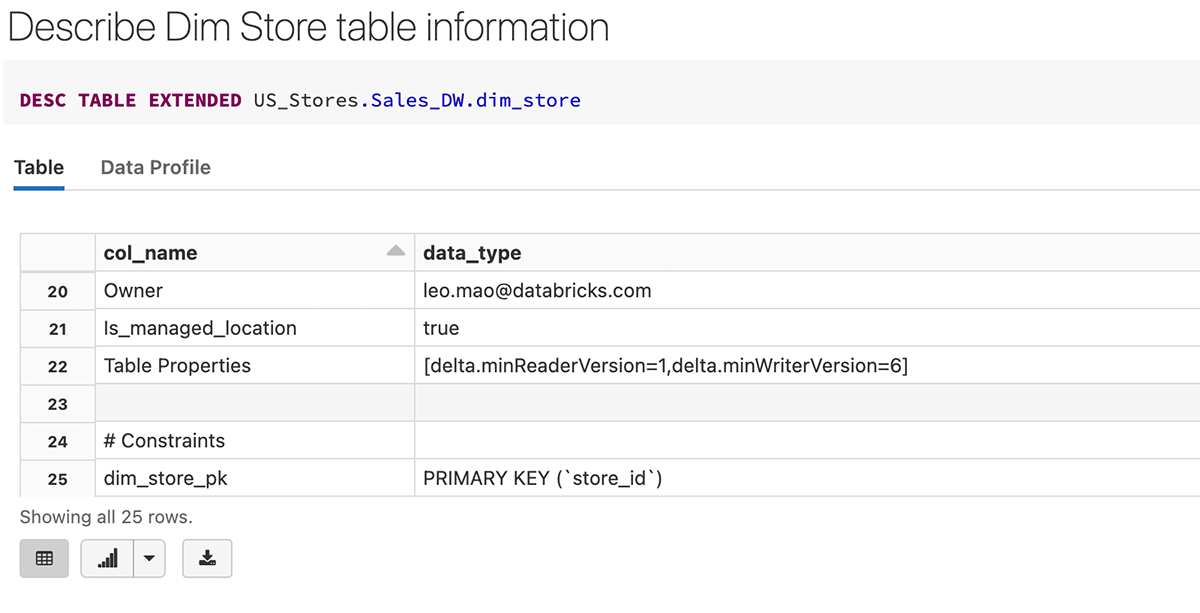
Dopo la creazione della tabella, possiamo vedere che la primary key (store_id) è stata creata come vincolo nella definizione della tabella di seguito.
Ecco un esempio di creazione della tabella fact_sales con transaction_id come Primary Key, nonché foreign key che fanno riferimento alle tabelle dimensionali.
Implementazione DDL per la creazione del fatto di vendita con definizioni di Foreign Key
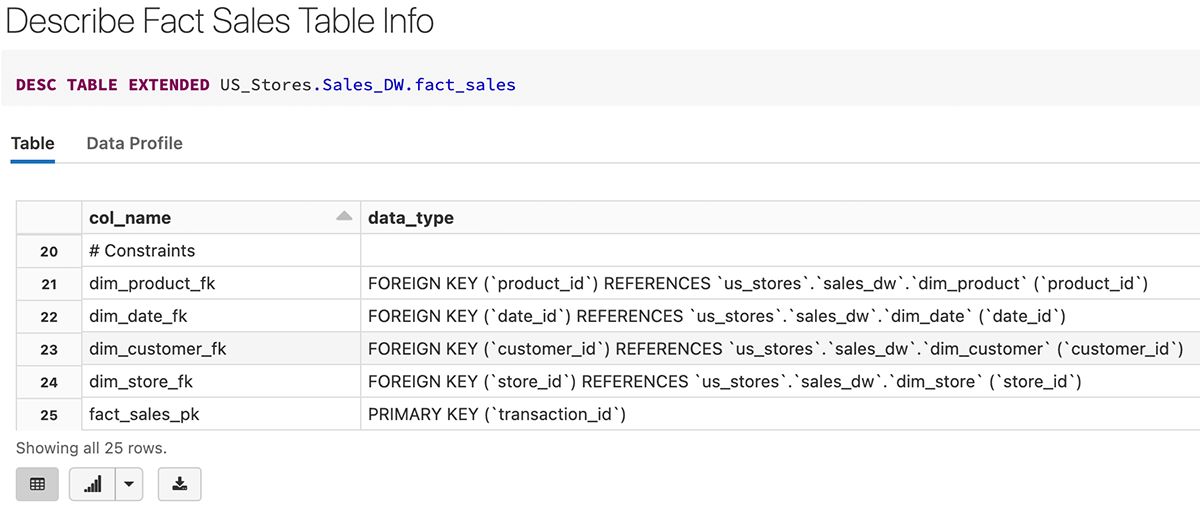
Dopo la creazione della tabella dei fatti, possiamo vedere che la primary key (transaction_id) e le foreign key sono state create come vincoli nella definizione della tabella di seguito.
3. Colonne Identity per Surrogate Key
Una colonna identity è una colonna in un database che genera automaticamente un numero ID univoco per ogni nuova riga di dati. Queste vengono comunemente utilizzate per creare surrogate key nei data warehouse. Le surrogate key sono chiavi generate dal sistema, prive di significato, in modo da non dover fare affidamento su varie Natural Primary Key e concatenazioni su diversi campi per identificare l'unicità della riga. Tipicamente queste surrogate key vengono utilizzate come Primary e Foreign key nei data warehouse. I dettagli sulle colonne Identity sono discussi in questo blog. Di seguito è riportato un esempio di creazione di una colonna identity customer_id, con valori assegnati automaticamente a partire da 1 e incrementati di 1.
Implementazione DDL per la creazione della dimensione cliente con colonna identity
4. Vincoli di colonna per la qualità dei dati
Oltre ai vincoli informativi di chiave primaria e chiave esterna, Databricks supporta anche vincoli di controllo della qualità dei dati a livello di colonna che vengono applicati per garantire la qualità e l'integrità dei dati aggiunti a una tabella. I vincoli vengono verificati automaticamente. Buoni esempi sono i vincoli NOT NULL e i vincoli sui valori delle colonne. A differenza degli altri Data Warehouse Cloud, Databricks ha fatto un passo avanti per fornire vincoli di controllo sui valori delle colonne, molto utili per garantire la qualità dei dati di una data colonna. Come possiamo vedere di seguito, il vincolo di controllo valid_sales_amount verificherà che tutte le righe esistenti soddisfino il vincolo (cioè sales amount > 0) prima di aggiungerle alla tabella. Maggiori informazioni sono disponibili qui.
Ecco alcuni esempi per aggiungere vincoli rispettivamente a dim_store e fact_sales per garantire che store_id e sales_amount abbiano valori validi.
Aggiungi vincoli di colonna a tabelle esistenti per garantire la qualità dei dati
5. Indice, Ottimizza e Analizza
I database tradizionali hanno indici b-tree e bitmap, Databricks ha una forma di indicizzazione molto avanzata: l'indicizzazione clusterizzata Z-order multidimensionale e supportiamo anche l'indicizzazione Bloom filter. Innanzitutto, il formato file Delta utilizza il formato file Parquet, che è un formato file compresso colonnare, quindi è già molto efficiente nella potatura delle colonne e, in aggiunta, l'uso dell'indicizzazione z-order ti dà la capacità di setacciare dati su scala petabyte in pochi secondi. Sia Z-order che l'indicizzazione Bloom filter riducono drasticamente la quantità di dati che devono essere scansionati per rispondere a query altamente selettive su grandi tabelle Delta, il che si traduce tipicamente in miglioramenti dell'ordine di grandezza nei tempi di esecuzione e risparmi sui costi. Usa Z-order sulle tue chiavi primarie e chiavi esterne che vengono utilizzate per le join più frequenti. E usa l'indicizzazione Bloom filter aggiuntiva secondo necessità.
Ottimizza fact_sales su customer_id e product_id per migliori prestazioni
Crea un indice Bloomfilter per abilitare il data skipping su una data colonna
E come ogni altro Data Warehouse, puoi ANALYZE TABLE per aggiornare le statistiche per garantire che l'ottimizzatore di query abbia le migliori statistiche per creare il miglior piano di query.
Raccogli statistiche per tutte le colonne per un miglior piano di esecuzione delle query
6. Tecniche avanzate
Mentre Databricks supporta tecniche avanzate come il Table Partitioning, usa queste funzionalità con parsimonia, solo quando hai molti Terabyte di dati compressi, perché la maggior parte delle volte i nostri indici OPTIMIZE e Z-ORDER ti daranno il miglior file e data pruning, il che rende il partizionamento di una tabella per data o mese quasi una cattiva pratica. È tuttavia una buona pratica assicurarsi che i DDL della tua tabella siano impostati per l'ottimizzazione automatica e la compattazione automatica. Questi garantiranno che i tuoi dati scritti frequentemente in piccoli file vengano compattati in formati colonnari compressi più grandi di Delta.
Stai cercando di sfruttare uno strumento di modellazione dati visuale? Il nostro partner erwin Data Modeler di Quest può essere utilizzato per eseguire il reverse engineering, creare e implementare Star-schema, Data Vault e qualsiasi modello dati industriale in Databricks con pochi clic.
Esempio di Notebook Databricks
Con la piattaforma Databricks, è possibile progettare e implementare facilmente vari modelli di dati. Per vedere tutti gli esempi sopra in un flusso di lavoro completo, consulta questo esempio.
Dai anche un'occhiata al nostro blog correlato - Cinque semplici passaggi per implementare uno Star Schema in Databricks con Delta Lake.
Inizia a costruire i tuoi modelli dimensionali nel Lakehouse
Prova Databricks gratuitamente per 14 giorni.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.