Sviluppa e distribuisci JAR Serverless
di Achille Negrier, Edward Feng, Giorgi Kikolashvili e Shiyu Wang
- Esegui JAR Serverless scritti in Scala o Java, con tempi di avvio istantanei e zero gestione dei cluster.
- Sviluppa nel tuo IDE preferito utilizzando Databricks Connect, testando su dati reali e ambienti simili alla produzione.
- Paga solo per il lavoro svolto con fatturazione elastica basata sull'utilizzo, non per tempi di inattività o acquisizione di istanze.
JAR Serverless e Databricks Connect per Scala
I JAR Serverless consentono ai team di creare ed eseguire processi Spark Scala e Java su un'infrastruttura Serverless completamente gestita. I team possono continuare a creare pipeline Spark di livello enterprise nei linguaggi di cui si fidano già, con aggiornamenti automatici e senza l'overhead operativo della gestione dei cluster:
- Avvio rapido: Con Serverless, i processi Scala e Java si avviano in secondi anziché in minuti. Gli ingegneri possono eseguire e iterare sul codice immediatamente, senza attendere l'avvio dei cluster.
- Aggiornamenti senza versioni: Serverless viene eseguito continuamente sull'ultima versione supportata di Spark, quindi non dovrai mai pianificare o gestire gli aggiornamenti di Databricks Runtime.
- Nessuna infrastruttura da gestire: Non c'è provisioning di cluster, pianificazione della capacità o gestione del runtime. Databricks gestisce automaticamente l'infrastruttura, il ridimensionamento e l'ottimizzazione delle prestazioni, in modo che gli sviluppatori possano concentrarsi sulla scrittura del codice.
- Paga solo per ciò che usi: Invece di pagare per cluster sempre attivi o capacità inutilizzata, i team pagano solo per il calcolo effettivamente utilizzato.
Come funzionano i JAR Serverless?
Puoi eseguire JAR con Lakeflow Jobs su Serverless compute. I JAR Serverless sono basati su Spark 4 (Scala 2.13) e Spark Connect, utilizzando la stessa architettura di Python. Il disaccoppiamento del codice utente dal motore abilita aggiornamenti senza versioni, rimuove conflitti di dipendenze e consente controlli di accesso granulari nativi con Lakeguard.
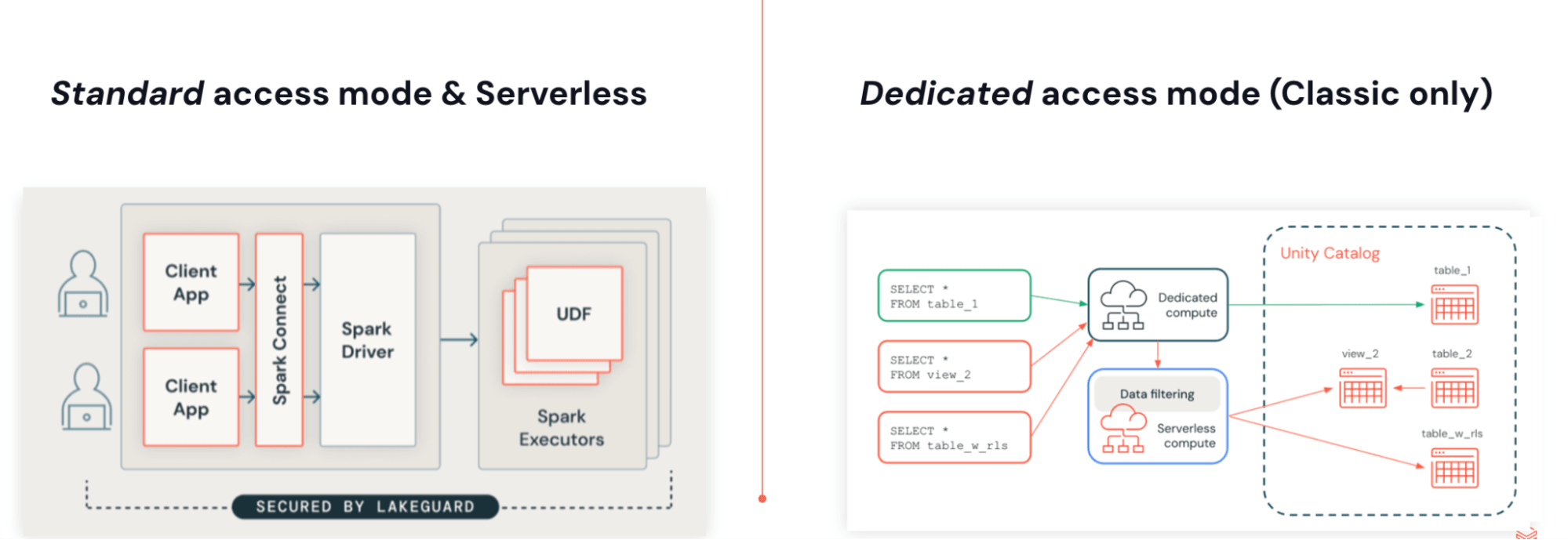
Questa architettura presenta alcuni vantaggi chiave:
- Esecuzione senza versioni: Le applicazioni non sono più legate a una specifica versione di Databricks Runtime. Serverless viene eseguito sempre sull'ultima versione supportata, eliminando la necessità di pianificare, programmare o gestire gli aggiornamenti di Databricks Runtime.
- Controlli di accesso granulari nativi con Lakeguard: Poiché tutta l'esecuzione avviene sul server, Databricks può applicare filtri a livello di riga e controlli di accesso basati sugli attributi (ABAC) a basso costo.
- Set di dipendenze snello e indipendente: L'ambiente Serverless viene eseguito isolato da Spark, quindi può fornire un set di dipendenze indipendente e ridotto che elimina anche i conflitti di dipendenze.
Sviluppa utilizzando Databricks Connect e Databricks Asset Bundles
Con Databricks Connect, puoi scrivere e debuggare codice interattivamente nel tuo IDE preferito, come IntelliJ o Cursor, utilizzando il calcolo Serverless con tempi di avvio quasi istantanei.
Ciò rende i cicli di sviluppo più rapidi e affidabili, poiché puoi testare su dati reali e ambienti di produzione senza lasciare il tuo IDE. Una volta terminato lo sviluppo, puoi mettere in produzione il tuo processo utilizzando Databricks Asset Bundles.
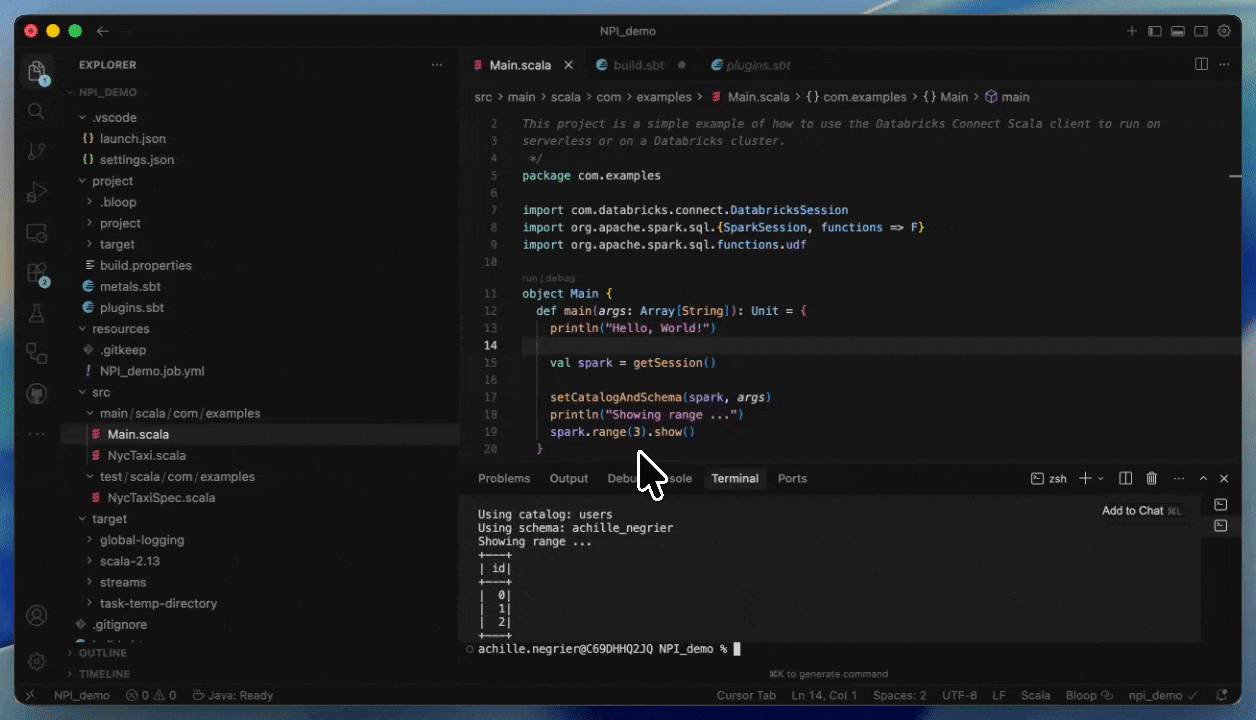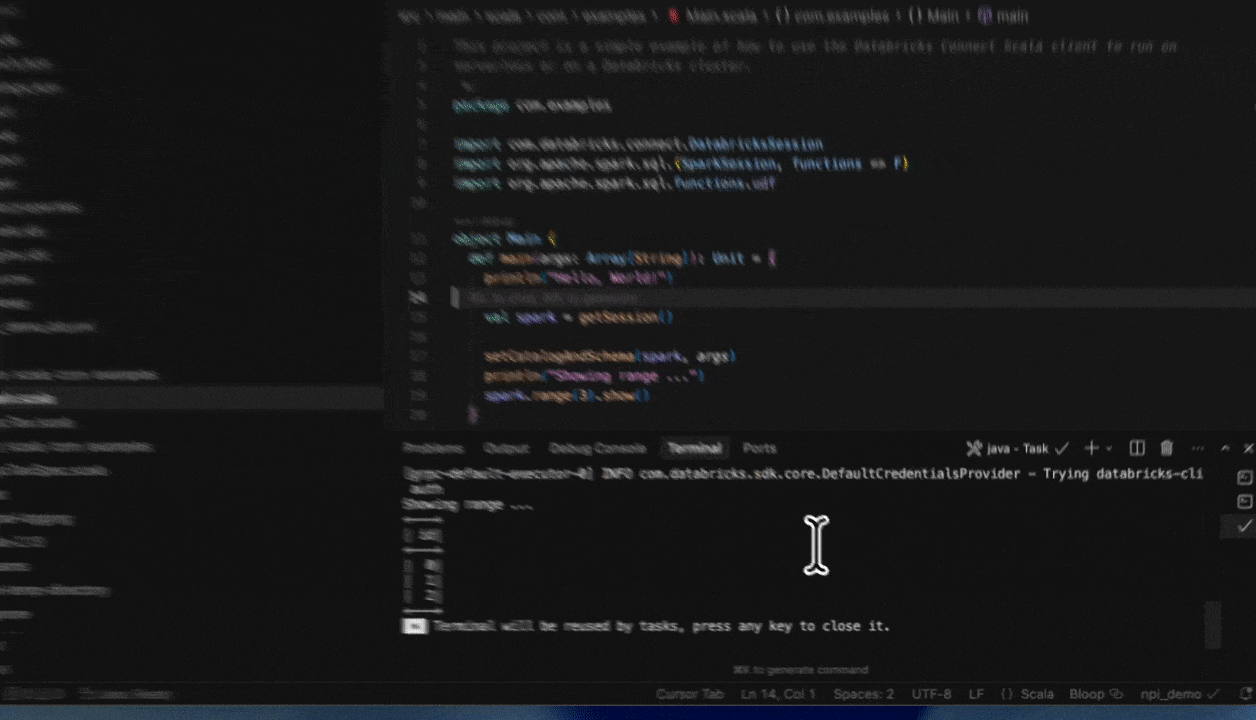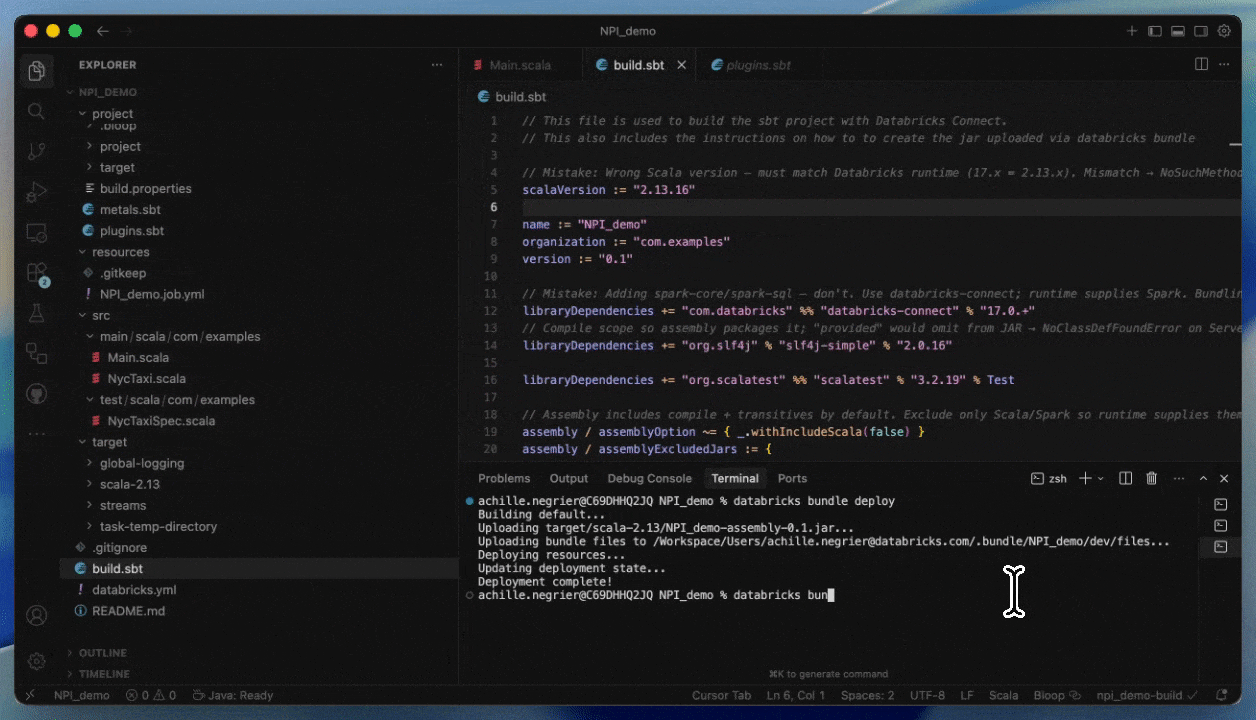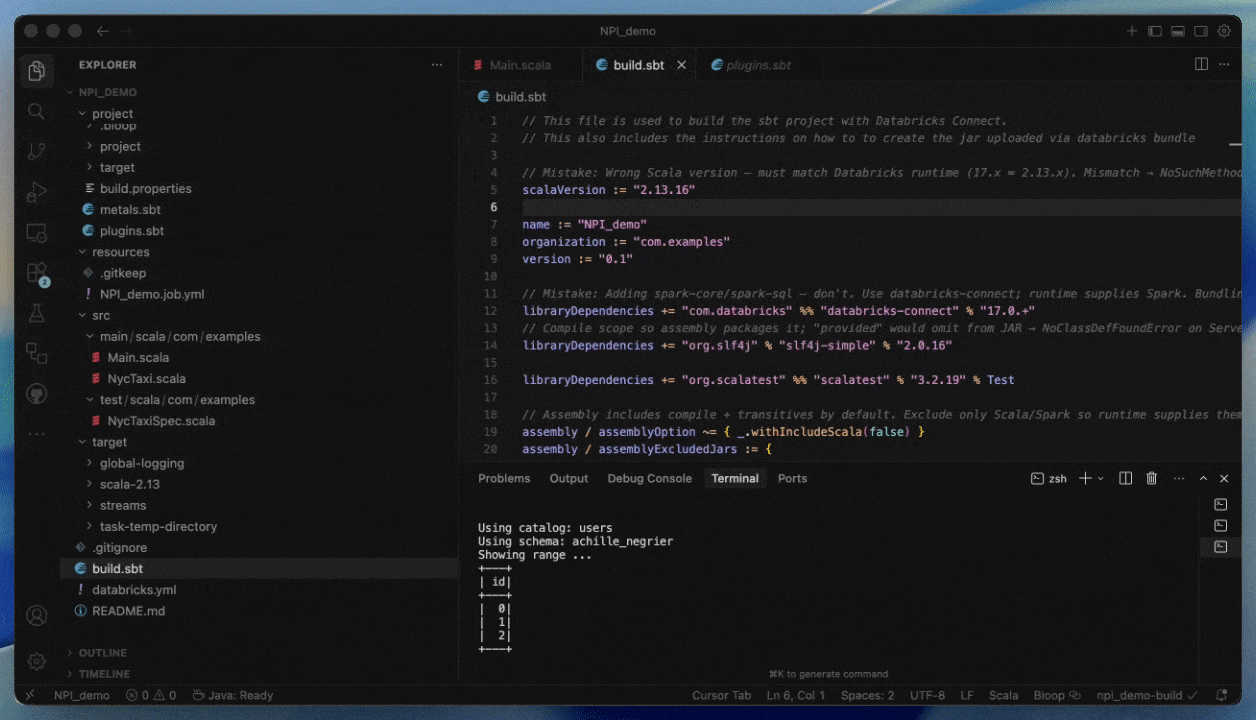
Come distribuire su Serverless fornendo un JAR
Passaggio 1: Compila il tuo JAR per Serverless
- Compila con Spark 4 (Scala 2.13) e Spark Connect
- Includi tutte le dipendenze non-Spark esplicitamente o forniscile come JAR aggiuntivi
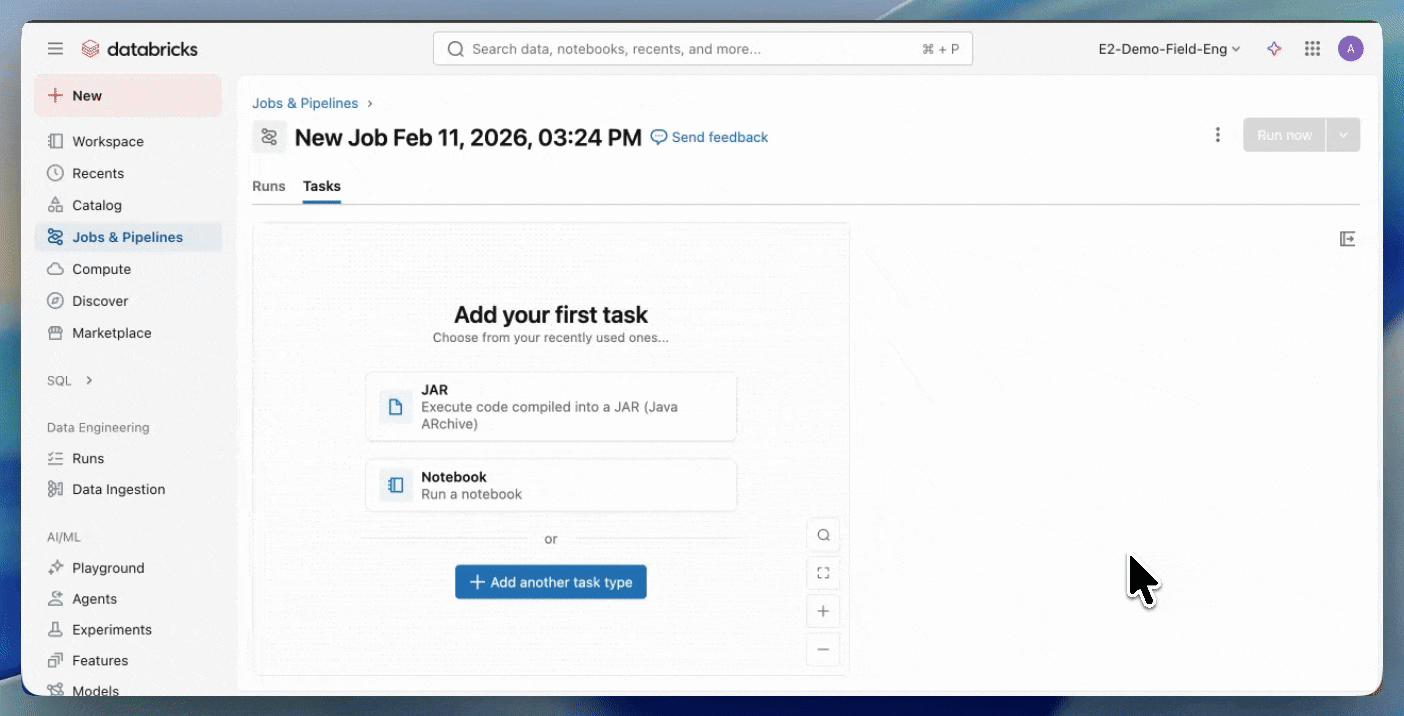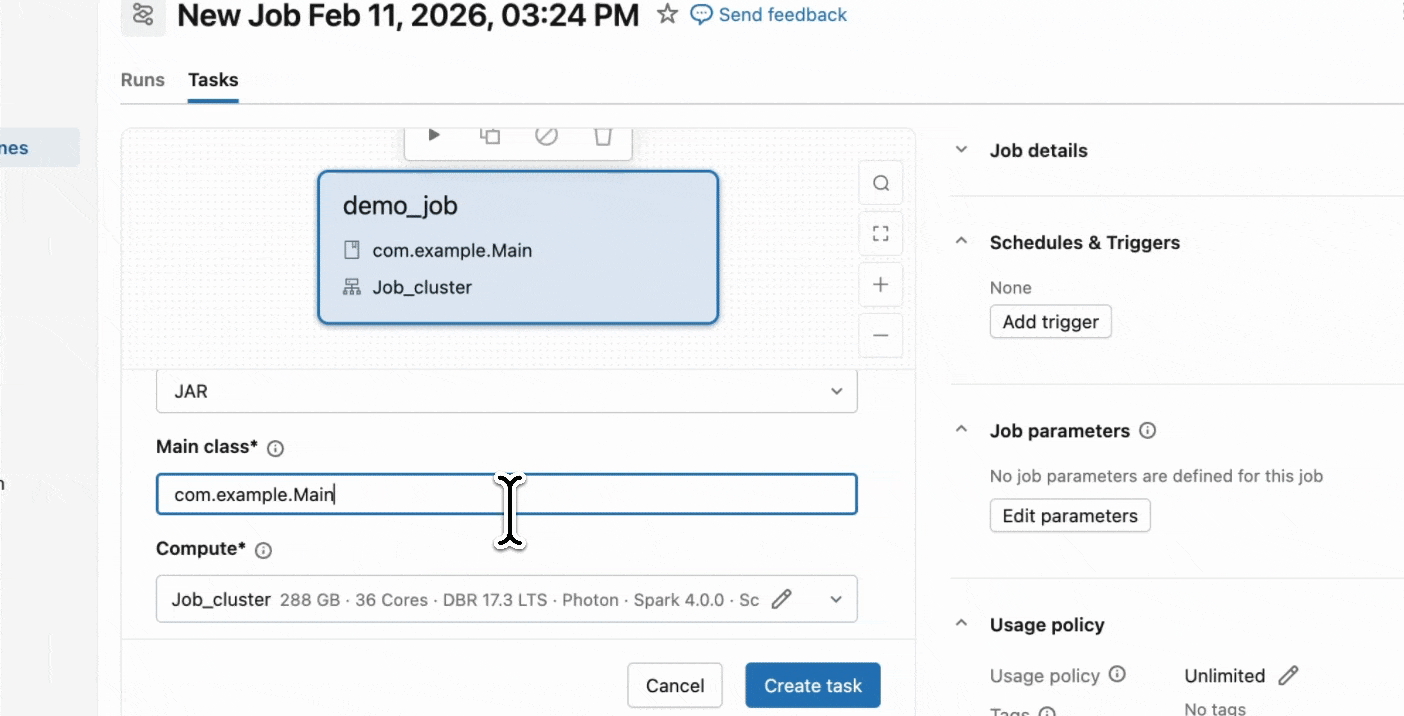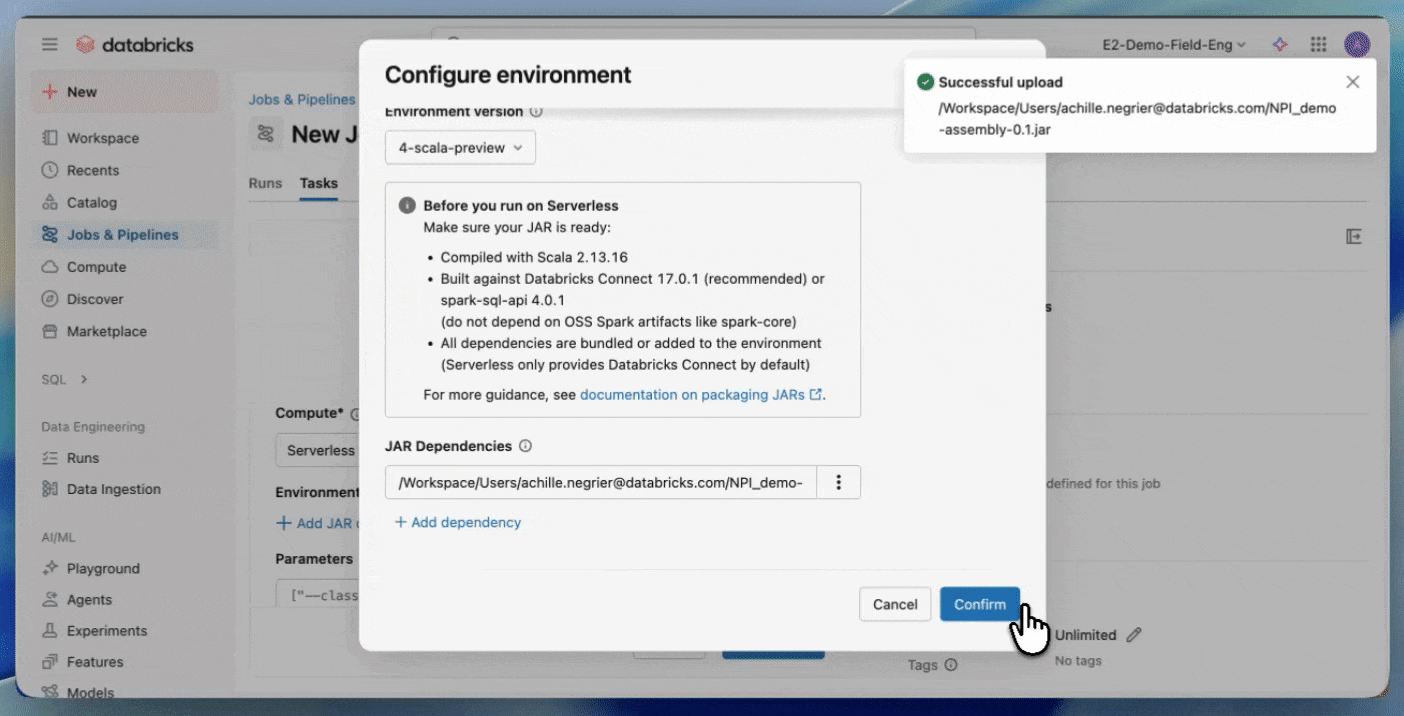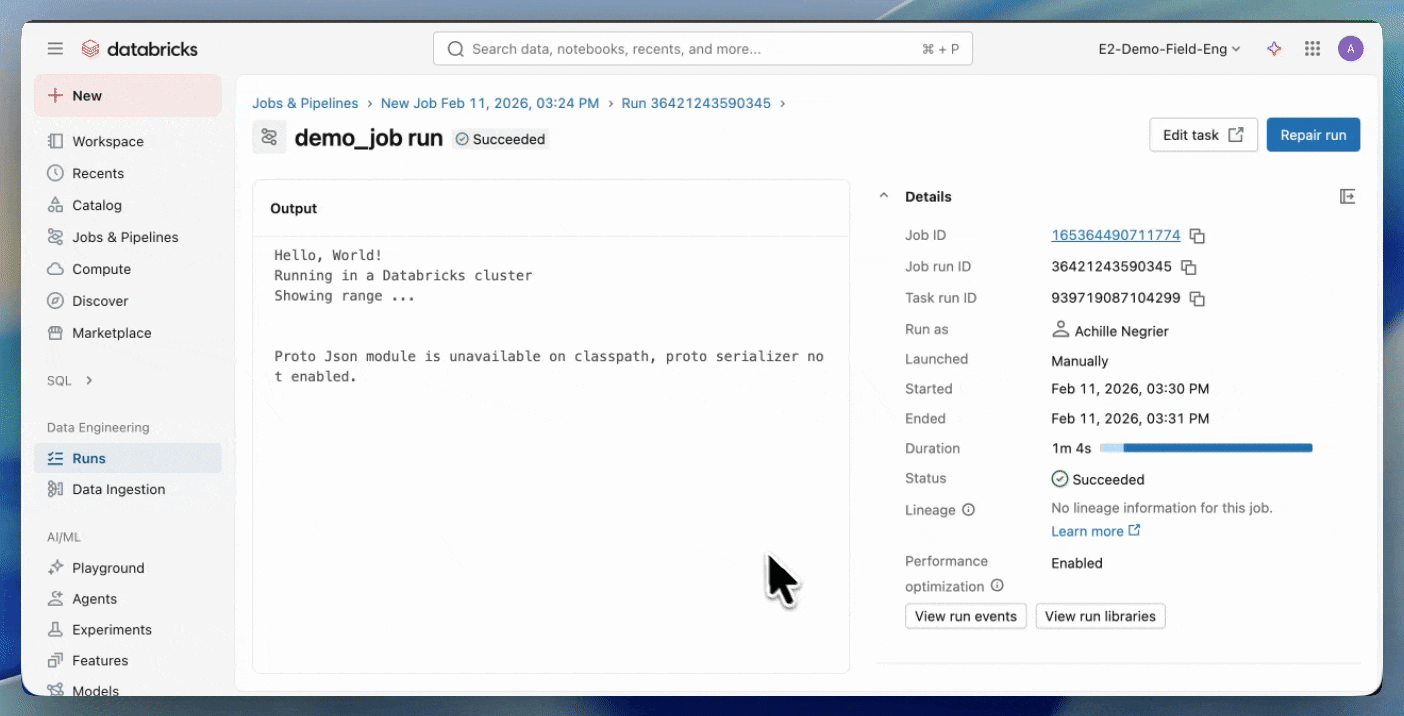
Passaggio 2: Crea un processo Serverless
- Carica il tuo JAR in un volume di Unity Catalog o in una cartella dell'area di lavoro UC.
- Crea un nuovo processo utilizzando un'attività JAR e seleziona Serverless come calcolo.
Inizia con i JAR Serverless.
Per iniziare rapidamente, segui il tutorial sullo sviluppo e distribuzione di processi Scala utilizzando il modello Databricks Asset Bundle. Per un tutorial sulla compilazione manuale di un JAR, consulta Esegui codice Scala su Serverless compute.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.