Un framework per previsioni multi-modello su Databricks
di Ryuta Yoshimatsu , Puneet Jain, Tristan Nixon, Sathish Gangichetty, Michael Shtelma e Bryan Smith
Introduzione
La previsione delle serie temporali costituisce la base per la gestione dell'inventario e della domanda nella maggior parte delle aziende. Utilizzando i dati dei periodi passati insieme alle condizioni previste, le aziende possono prevedere ricavi e unità vendute, consentendo loro di allocare le risorse per soddisfare la domanda prevista. Data la natura fondamentale di questo lavoro, le aziende esplorano costantemente modi per migliorare l'accuratezza delle previsioni, permettendo loro di impiegare le risorse giuste nel posto giusto al momento giusto, minimizzando al contempo gli impegni di capitale.
La sfida per la maggior parte delle organizzazioni è l'ampia gamma di tecniche di previsione a loro disposizione. Tecniche statistiche classiche, modelli additivi generalizzati, approcci basati su machine learning e deep learning e ora transformer generativi pre-addestrati forniscono alle organizzazioni un numero schiacciante di scelte, alcune delle quali funzionano meglio in alcuni scenari rispetto ad altri.
Sebbene la maggior parte dei creatori di modelli affermi di aver migliorato l'accuratezza delle previsioni rispetto ai set di dati di base, la realtà è che la conoscenza del dominio e i requisiti aziendali restringono tipicamente il numero di scelte di modelli a pochi, e solo l'applicazione pratica e la valutazione sui set di dati di un'organizzazione possono determinare quale funziona meglio. E ciò che è "meglio" spesso varia da unità di previsione a unità di previsione e persino nel tempo, costringendo le organizzazioni a eseguire valutazioni comparative continue tra le tecniche per determinare cosa funziona meglio al momento.
In questo blog, introdurremo il framework Many Model Forecasting (MMF) per la valutazione comparativa dei modelli di previsione. MMF consente agli utenti di addestrare e prevedere utilizzando più modelli di previsione su larga scala, da centinaia di migliaia a molti milioni di serie temporali alla loro massima granularità. Con il supporto per la preparazione dei dati, il backtesting, la convalida incrociata, lo scoring e il deployment, il framework consente ai team di previsione di implementare una soluzione completa di generazione di previsioni utilizzando modelli classici e all'avanguardia, con un'enfasi sulla configurazione rispetto alla codifica, riducendo al minimo lo sforzo necessario per introdurre nuovi modelli e capacità nei loro processi. Abbiamo riscontrato in numerose implementazioni di clienti che questo framework:
- Riduce il time to market: Con molti modelli consolidati e all'avanguardia già integrati, gli utenti possono valutare e distribuire rapidamente le soluzioni.
- Migliora l'accuratezza delle previsioni: Attraverso una valutazione approfondita e una selezione granulare dei modelli, MMF consente alle organizzazioni di scoprire in modo efficiente approcci di previsione che forniscono una maggiore precisione.
- Abilita la prontezza alla produzione: Aderendo alle best practice di MLOps, MMF si integra nativamente con Databricks, garantendo un deployment senza interruzioni.
Accedi a oltre 40 modelli utilizzando il framework
Il framework Many Model Forecasting (MMF) viene distribuito come repository Github con codice sorgente completamente accessibile, trasparente e commentato. Le organizzazioni possono utilizzare il framework così com'è o estenderlo per aggiungere funzionalità necessarie alla loro specifica organizzazione.
MMF include il supporto integrato per oltre 40 modelli attraverso l'integrazione di alcune delle librerie open source di previsione più popolari disponibili oggi, tra cui statsforecast, neuralforecast, sktime, r fable, chronos, moirai e moment. E mentre i nostri clienti esplorano modelli più recenti, intendiamo supportarne ancora di più.
Con questi modelli già integrati nel framework, gli utenti possono eliminare lo sviluppo ridondante della preparazione dei dati e dell'addestramento del modello specifico per ciascun modello e concentrarsi invece sulla valutazione e sul deployment, accelerando significativamente il time to market. Questo è particolarmente vantaggioso per team di data scientist e ingegneri di machine learning con risorse limitate e stakeholder aziendali desiderosi di risultati.
Utilizzando MMF, i team di previsione possono valutare più modelli contemporaneamente, consentendo sia alla logica integrata che a quella personalizzata di selezionare il modello migliore per ciascuna serie temporale e migliorando l'accuratezza complessiva della soluzione di previsione. Distribuito su un cluster Databricks, MMF sfrutta tutte le risorse messe a sua disposizione per accelerare l'addestramento e la valutazione dei modelli attraverso il parallelismo automatizzato. I team configurano semplicemente le risorse che desiderano utilizzare per l'esercizio di previsione e MMF si occupa del resto.
Concentrati sugli output dei modelli e sulle valutazioni comparative
La chiave di MMF è la standardizzazione degli output dei modelli. Durante l'esecuzione delle previsioni, MMF genera due tabelle UC: evaluation_output e scoring_output. La tabella evaluation_output (Figura 1) memorizza tutti i risultati di valutazione di ogni periodo di backtesting, attraverso tutte le serie temporali e i modelli, fornendo una panoramica completa delle prestazioni di ciascun modello. Ciò include le previsioni insieme ai valori effettivi, consentendo agli utenti di costruire metriche personalizzate che si allineano alle esigenze aziendali specifiche. Sebbene MMF offra diverse metriche pronte all'uso, come MAE, MSE, RMSE, MAPE e SMAPE, la flessibilità di creare metriche personalizzate facilita una valutazione dettagliata e la selezione o l'ensembling dei modelli, garantendo risultati di previsione ottimali.
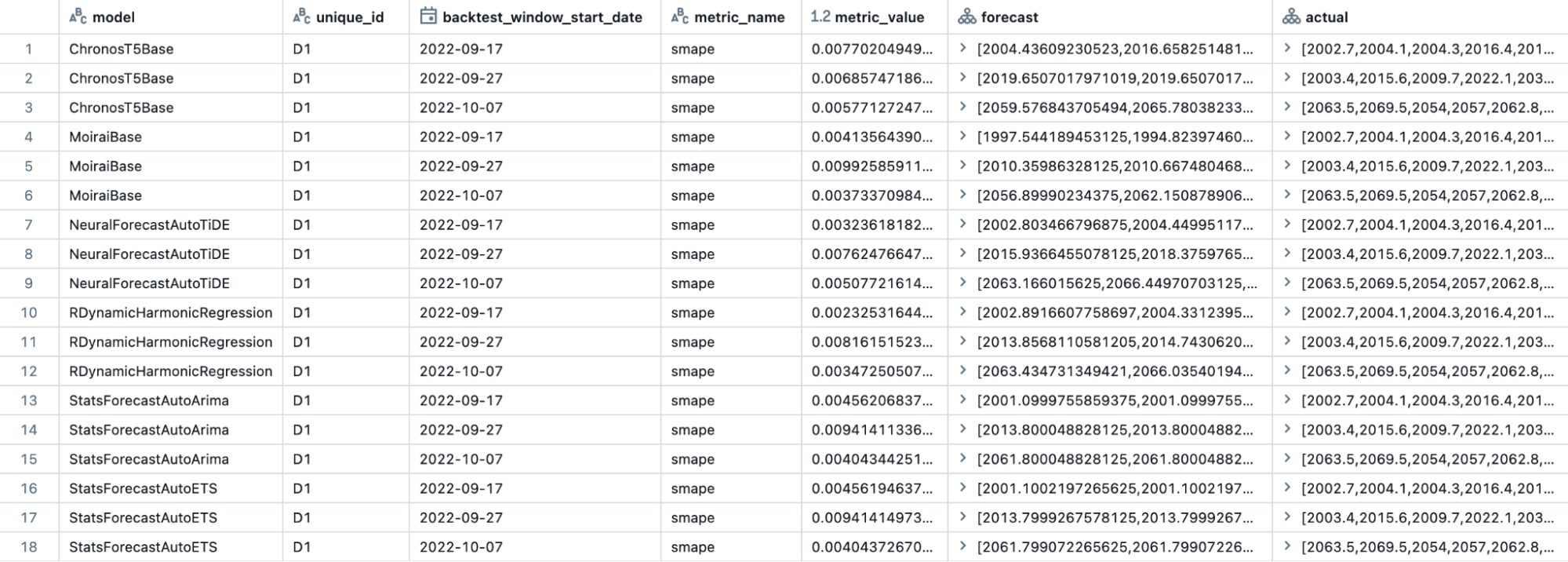
La seconda tabella, scoring_output (Figura 2), contiene le previsioni per ciascuna serie temporale da ciascun modello. Utilizzando i risultati completi di valutazione memorizzati nella tabella evaluation_output, è possibile selezionare le previsioni dal modello più performante o da una combinazione di modelli. Scegliendo le previsioni finali da un pool di modelli concorrenti o da un ensemble di modelli selezionati, è possibile ottenere una precisione e una stabilità superiori rispetto all'affidarsi a un singolo modello, migliorando così l'accuratezza e la stabilità complessiva della soluzione di previsione su larga scala.

Semplifica la gestione dei modelli tramite l'automazione
Costruito sulla piattaforma Databricks, MMF si integra perfettamente con le sue capacità Databricks, fornendo il logging automatizzato di parametri, metriche aggregate e modelli (per modelli globali e foundation) a MLflow (Figura 3). Protetti come parte di Unity Catalog di Databricks, i team di previsione possono impiegare controlli di accesso granulari e una gestione adeguata dei loro modelli, non solo dei loro output.

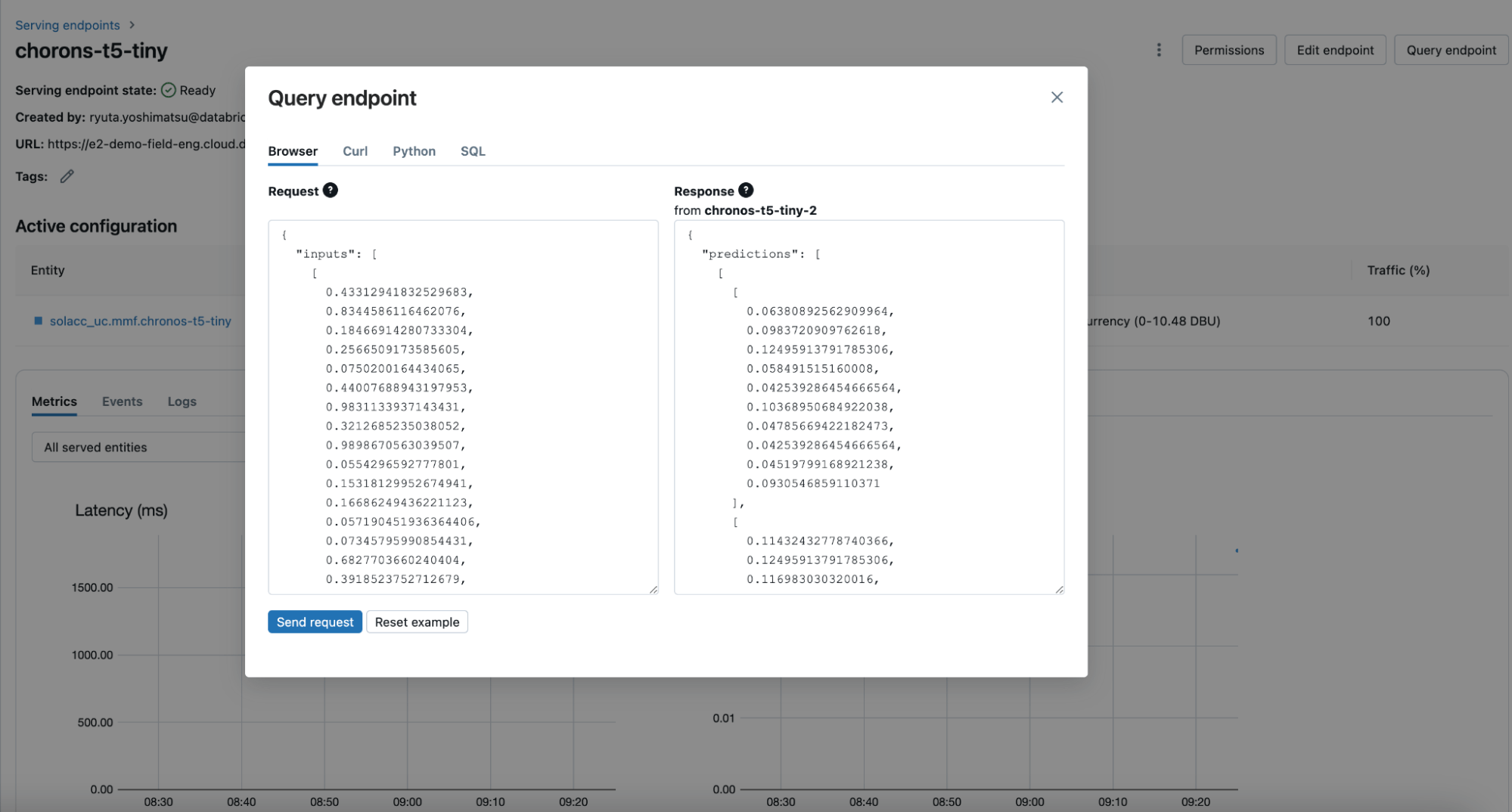
Se un team ha bisogno di riutilizzare un modello (come è comune negli scenari di machine learning), può semplicemente caricarlo sul proprio cluster utilizzando il metodo load_model di MLflow o distribuirlo dietro un endpoint in tempo reale utilizzando Databricks Model Serving di Databricks (Figura 4). Con i modelli foundation di serie temporali ospitati in Model Serving, è possibile generare previsioni multi-step in avanti in qualsiasi momento, a condizione che venga fornita la cronologia alla risoluzione corretta. Questa capacità migliora significativamente le applicazioni di previsione on-demand, monitoraggio in tempo reale e tracciamento.
Inizia subito
In Databricks, la generazione di previsioni è uno dei casi d'uso più popolari per i clienti. La natura fondamentale delle previsioni per così tanti processi aziendali significa che le organizzazioni cercano costantemente miglioramenti nell'accuratezza delle previsioni.
Con questo framework, speriamo di fornire ai team di previsione un accesso semplice alla funzionalità più scalabile, robusta ed estesa necessaria per supportare il loro lavoro. Attraverso MMF, i team possono ora concentrarsi sulla generazione di risultati e meno su tutto il lavoro di sviluppo richiesto per valutare nuovi approcci e portarli alla prontezza di produzione.
Ringraziamenti
Ringraziamo i team dietro statsforecast e neuralforecast (Nixtla), r fable, sktime, chronos, moirai, moment e timesfm per i loro contributi alle community open source, che ci hanno fornito l'accesso ai loro strumenti eccezionali.
Dai un'occhiata al repository MMF e ai notebook di esempio che mostrano come le organizzazioni possono iniziare a utilizzarlo nel loro ambiente Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.