Avere il quadro completo: unificare i costi di Databricks e dell'infrastruttura cloud
Scopri come automatizzare dashboard dei costi unificate che i team FinOps e Platform vogliono davvero usare.
- La nuova Cloud Infra Cost Field Solution (disponibile per AWS e Azure) dimostra come inserire, arricchire, unire e visualizzare i dati di Databricks e i relativi dati sui costi del cloud per visualizzare i costi totali a livello di account, cluster e persino di tag.
- L'implementazione della Field Solution fornisce ai team FinOps e di piattaforma un'unica e affidabile vista del TCO, consentendo loro di analizzare nel dettaglio i costi completi per workspace, carico di lavoro e business unit per allineare l'utilizzo con i budget, eliminando la riconciliazione manuale e trasformando il reporting dei costi in una funzionalità operativa sempre attiva.
- Aziende come General Motors hanno adottato questo approccio per sviluppare una comprensione olistica dei loro costi di Databricks, assicurando che siano visibili e ben compresi.
Comprensione del TCO su Databricks
Comprendere il valore dei propri investimenti in AI e dati è fondamentale; eppure, oltre il 52% delle aziende non riesce a misurare rigorosamente il ritorno sull'investimento (ROI) [Futurum]. La visibilità completa del ROI richiede di collegare l'utilizzo della piattaforma e l'infrastruttura cloud in un quadro finanziario chiaro. Spesso i dati sono disponibili ma frammentati, poiché le odierne piattaforme dati devono supportare una gamma crescente di architetture di storage e compute.
Su Databricks, i clienti gestiscono ambienti multicloud, multi-carico di lavoro e multi-team. In questi ambienti, avere una visione coerente e completa dei costi è essenziale per prendere decisioni informate.
Alla base della visibilità dei costi su piattaforme come Databricks c'è il concetto di costo totale di proprietà (TCO).
Sulle piattaforme dati multicloud, come Databricks, il TCO è costituito da due componenti principali:
- Costi della piattaforma, come il calcolo e lo storage gestito, sono costi sostenuti attraverso l'uso diretto dei prodotti Databricks.
- I costi dell'infrastruttura cloud, come macchine virtuali, archiviazione e costi di rete, sono costi sostenuti attraverso l'utilizzo sottostante dei servizi cloud necessari per supportare Databricks.
La comprensione del TCO è semplificata quando si utilizzano prodotti serverless. Poiché il compute è gestito da Databricks, i costi dell'infrastruttura cloud sono inclusi nei costi di Databricks, offrendo una visibilità centralizzata dei costi direttamente nelle tabelle di sistema di Databricks (anche se i costi di archiviazione rimarranno a carico del provider di servizi cloud).
Comprendere il TCO per i prodotti di compute classica, tuttavia, è più complesso. Qui, i clienti gestiscono il compute direttamente con il provider cloud, il che significa che sia i costi della piattaforma Databricks che i costi dell'infrastruttura cloud devono essere riconciliati. In questi casi, ci sono due distinte sorgenti di dati da analizzare:
- Le tabelle di sistema (AWS | AZURE | GCP) in Databricks forniscono metadati operativi a livello di workload e informazioni sull'utilizzo di Databricks.
- I report sui costi del provider di servizi cloud dettaglieranno i costi dell'infrastruttura cloud, inclusi gli sconti.
Insieme, queste origini costituiscono la vista completa del TCO. Man mano che l'ambiente si espande su più cluster, Job e account cloud, la comprensione di questi set di dati diventa una parte fondamentale dell'osservabilità dei costi e della governance finanziaria.
La complessità del TCO
La complessità di misurare il TCO di Databricks è aggravata dai diversi modi in cui i provider cloud espongono e riportano i dati sui costi. Capire come unire questi set di dati con le tabelle di sistema per produrre KPI di costo accurati richiede una conoscenza approfondita dei meccanismi di fatturazione cloud, conoscenza che molti amministratori di piattaforma focalizzati su Databricks potrebbero non avere. Qui, analizziamo nel dettaglio la misurazione del TCO per Azure Databricks e Databricks su AWS.
Azure Databricks: sfruttare i dati di fatturazione di prima parte
Poiché Azure Databricks è un servizio proprietario all'interno dell'ecosistema Microsoft Azure, gli addebiti relativi a Databricks vengono visualizzati direttamente in Azure Cost Management insieme ad altri servizi Azure, includendo anche i tag specifici di Databricks. I costi di Databricks vengono visualizzati nell'interfaccia utente di analisi dei costi di Azure e come dati di gestione dei costi.
Tuttavia, i dati di Azure Cost Management non conterranno i metadati più approfonditi a livello di carico di lavoro e le metriche sulle prestazioni presenti nelle tabelle di sistema di Databricks. Pertanto, molte organizzazioni cercano di importare le esportazioni di fatturazione di Azure in Databricks.
Tuttavia, unire completamente queste due sorgenti di dati richiede molto tempo e una profonda conoscenza del dominio, uno sforzo che la maggior parte dei clienti semplicemente non ha il tempo di definire, mantenere e replicare. A ciò contribuiscono diverse sfide:
- L'infrastruttura deve essere configurata per l'esportazione automatizzata dei costi in ADLS, a cui è quindi possibile fare riferimento ed eseguire query direttamente in Databricks.
- I dati sui costi di Azure vengono aggregati e aggiornati quotidianamente, a differenza delle tabelle di sistema, il cui aggiornamento è nell'ordine di ore; i dati devono essere attentamente deduplicati e i timestamp abbinati.
- L'unione delle due origini richiede l'analisi dei dati dei tag di Azure ad alta cardinalità e l'identificazione della chiave di join corretta (ad esempio, ClusterId).
Databricks su AWS: allineamento dei costi del Marketplace e dell'infrastruttura
Su AWS, sebbene i costi di Databricks siano visibili nel Cost and Usage Report (CUR) e in AWS Cost Explorer, questi sono rappresentati a un livello più aggregato, a livello di SKU, a differenza di Azure. Inoltre, i costi di Databricks vengono visualizzati nel CUR solo se Databricks viene acquistato tramite l'AWS Marketplace; altrimenti, il CUR rifletterà solo i costi dell'infrastruttura AWS.
In questo caso, capire come analizzare congiuntamente l'AWS CUR e le tabelle di sistema è ancora più fondamentale per i clienti con ambienti AWS. Ciò consente ai team di analizzare la spesa per l'infrastruttura, l'utilizzo delle DBU e gli sconti insieme al contesto a livello di cluster e di carico di lavoro, creando una visione più completa del TCO tra account e aree geografiche AWS.
Tuttavia, anche l'unione di AWS CUR con le tabelle di sistema può essere impegnativa. I punti critici più comuni includono:
- L'infrastruttura deve supportare la rielaborazione ricorrente del CUR, poiché AWS aggiorna e sostituisce i dati sui costi più volte al giorno (senza una chiave primaria) per il mese corrente e per qualsiasi periodo di fatturazione precedente che presenti modifiche.
- I dati sui costi di AWS coprono più tipi di voci e campi di costo, e richiedono attenzione per selezionare il costo effettivo corretto per tipo di utilizzo (On-Demand, Savings Plan, Reserved Instances) prima dell'aggregazione.
- L'unione dei dati CUR con i metadati di Databricks richiede un'attribuzione attenta, poiché la cardinalità può essere diversa; ad esempio, i cluster all-purpose condivisi sono rappresentati come una singola riga di utilizzo AWS, ma possono essere mappati a più Job nelle tabelle di sistema.
Semplificazione dei calcoli del TCO di Databricks
Negli ambienti Databricks su scala di produzione, le domande sui costi vanno rapidamente oltre la spesa complessiva. I team desiderano comprendere i costi nel loro contesto, ovvero come l'utilizzo dell'infrastruttura e della piattaforma si collega ai workload e alle decisioni reali. Le domande più comuni includono:
- Come si confronta il costo totale di un job serverless rispetto a quello di un job classico?
- Quali cluster, Job e warehouse sono i maggiori consumatori di VM gestite dal cloud?
- Come cambiano i trend dei costi man mano che i carichi di lavoro scalano, si spostano o si consolidano?
Per rispondere a queste domande è necessario unire i dati finanziari dei provider di servizi cloud con i metadati operativi di Databricks. Tuttavia, come descritto sopra, per raggiungere questo obiettivo i team devono mantenere pipeline personalizzate e una base di conoscenza dettagliata della fatturazione del cloud e di Databricks.
Per rispondere a questa esigenza, Databricks presenta la Cloud Infra Cost Field Solution, una soluzione open-source che automatizza l'acquisizione e l'analisi unificata dei dati sull'infrastruttura cloud e sull'utilizzo di Databricks, all'interno della Databricks Platform.
Fornendo una base unificata per l'analisi del TCO negli ambienti di compute serverless e classici di Databricks, la Field Solution aiuta le organizzazioni a ottenere una maggiore visibilità dei costi e a comprendere i compromessi architetturali. I team di ingegneria possono monitorare la spesa e gli sconti del cloud, mentre i team finanziari possono identificare il contesto aziendale e la proprietà dei principali fattori di costo.
Nella prossima sezione, illustreremo come funziona la soluzione e come ottenere start.
Analisi dettagliata della soluzione tecnica
Sebbene i componenti possano avere nomi diversi, la Cloud Infra Cost Field Solution per i clienti Azure e AWS condivide gli stessi principi e può essere suddivisa nei seguenti componenti:
- Esporta i dati su costi e utilizzo nello spazio di archiviazione cloud
- Acquisire e modellare i dati in Databricks utilizzando le Lakeflow Spark Declarative Pipelines
- Visualizza il TCO completo (costi di Databricks e del provider cloud correlato) con le dashboard AI/BI
Sia le Field soluzioni per AWS che per Azure sono eccellenti per le organizzazioni che operano all'interno di un unico cloud, ma possono anche essere combinate per i clienti Databricks multicloud utilizzando Delta Sharing.
Azure Databricks Field Solution
La Cloud Infra Cost Field Solution per Azure Databricks è costituita dai seguenti componenti di architettura:
Architettura della soluzione Azure Databricks
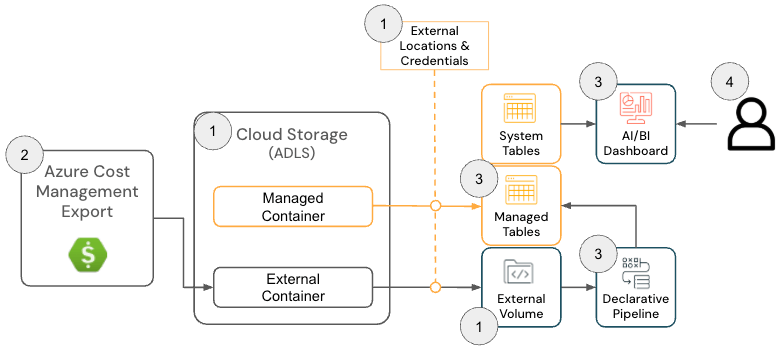
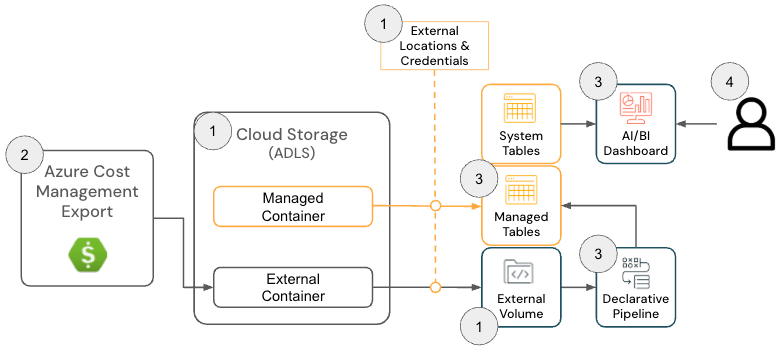{kind=link}
Per distribuire questa soluzione, gli amministratori devono disporre delle seguenti autorizzazioni su Azure e Databricks:
- azure
- Autorizzazioni per creare un'esportazione dei costi di Azure
- Autorizzazioni per creare le seguenti risorse all'interno di un gruppo di risorse:
- databricks
- Autorizzazione a creare le seguenti risorse:
- Credenziale archiviazione
- Posizione esterna
- Autorizzazione a creare le seguenti risorse:
Il repository GitHub fornisce istruzioni di configurazione più dettagliate; tuttavia, a livello generale, la soluzione per Azure Databricks prevede i seguenti passaggi:
- [Terraform] Eseguire il deployment di Terraform per configurare i componenti dipendenti, tra cui un account di archiviazione, una posizione esterna e un volume
- Lo scopo di questo passaggio è configurare una posizione in cui vengono esportati i dati di fatturazione di Azure in modo che possano essere letti da Databricks. Questo passaggio è facoltativo se esiste già un Volume, poiché la posizione di esportazione di Azure Cost Management può essere configurata nel passaggio successivo.
[Azure] Configura Esportazione di Gestione costi di Azure per esportare i dati di fatturazione di Azure nell'account di archiviazione e conferma che l'esportazione dei dati sta avvenendo correttamente
- Lo scopo di questo passaggio è utilizzare la funzionalità di esportazione di Azure Cost Management per rendere disponibili i dati di fatturazione di Azure in un formato di facile utilizzo (ad es. Parquet).
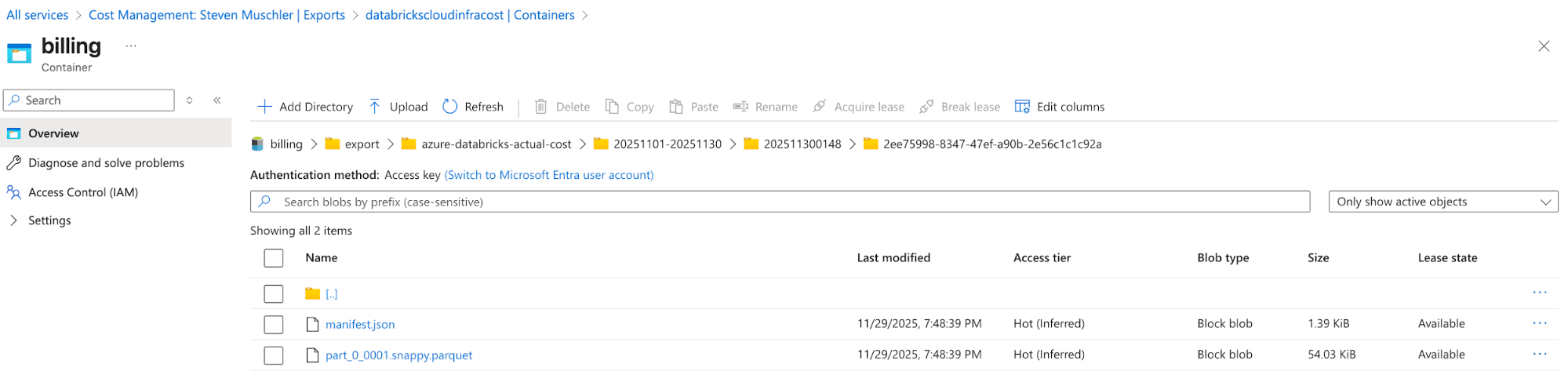
Account di archiviazione con l'esportazione di Azure Cost Management configurata
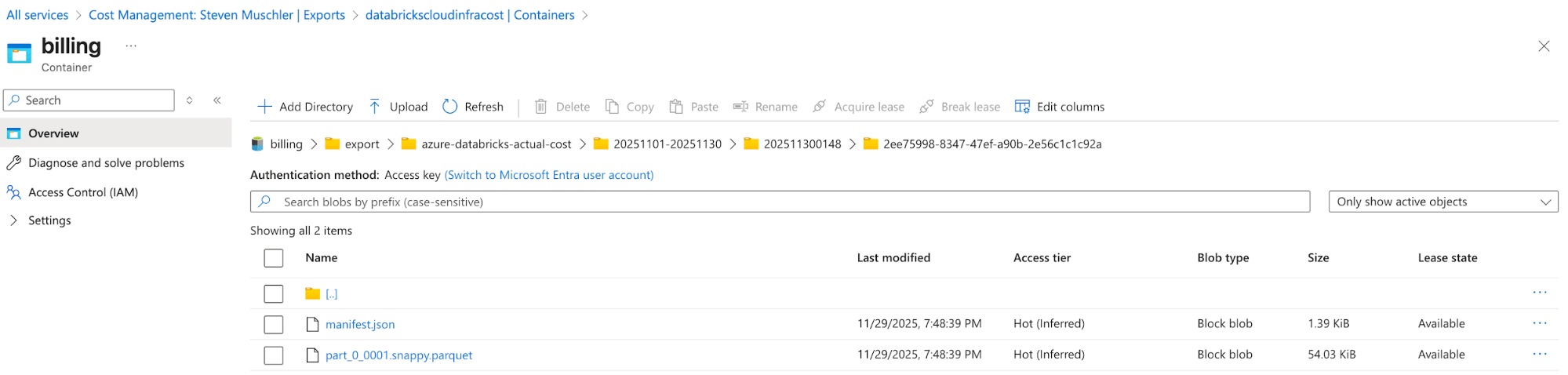
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Configurazione del Databricks Asset Bundle (DAB) per eseguire il deployment di un Lakeflow Job, una pipeline dichiarativa Spark e una dashboard di AI/BI
- Lo scopo di questo passaggio è l'inserimento e la modellazione dei dati di fatturazione di Azure per la visualizzazione tramite una AI/BI dashboard.
- [Databricks] Convalidare i dati nella dashboard di AI/BI e convalidare il Lakeflow Job
- Questo passaggio finale è dove si realizza il valore. I clienti ora dispongono di un processo automatizzato che consente loro di visualizzare il TCO della loro architettura Lakehouse!
{kind=link}
Dashboard di AI/BI che mostra il TCO di Azure Databricks
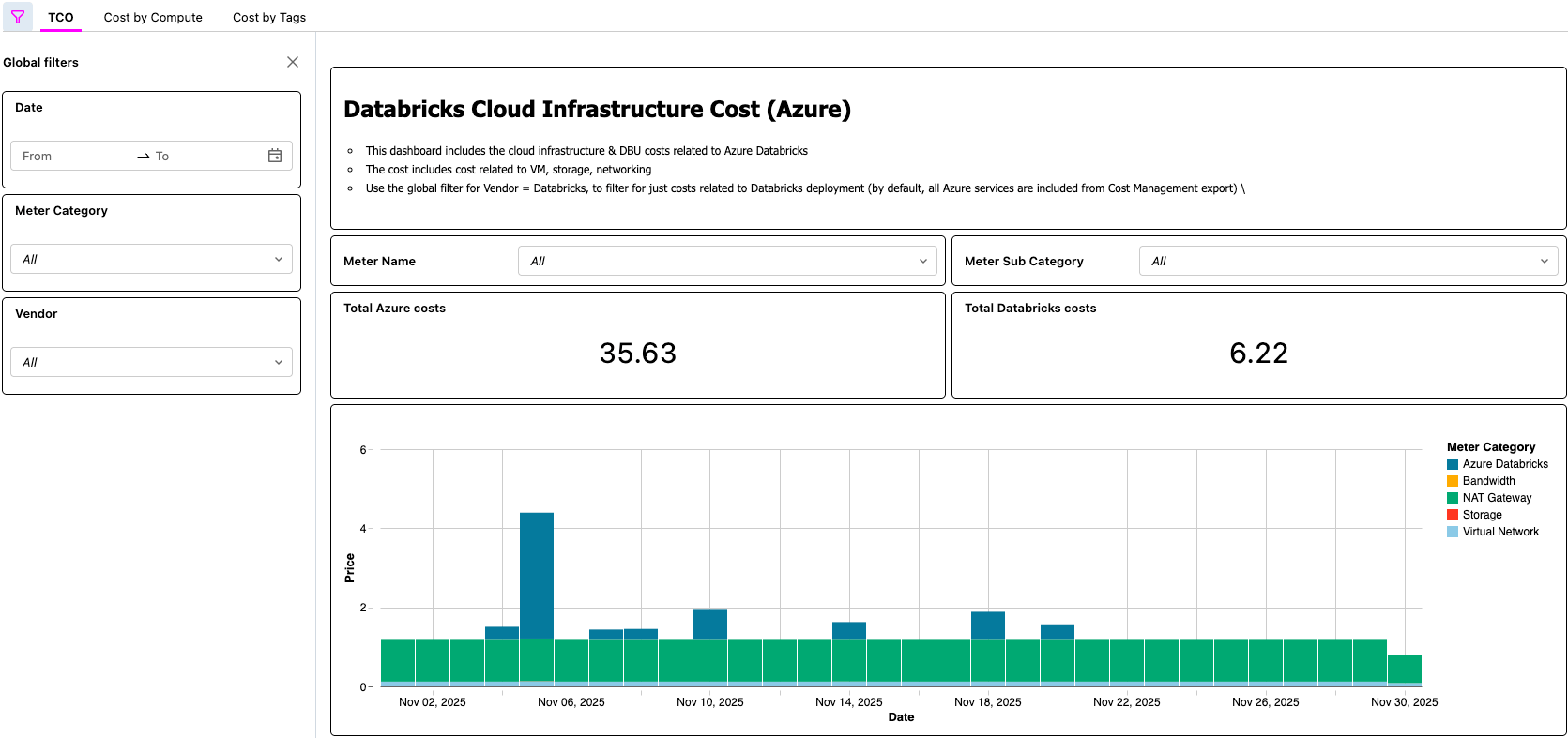
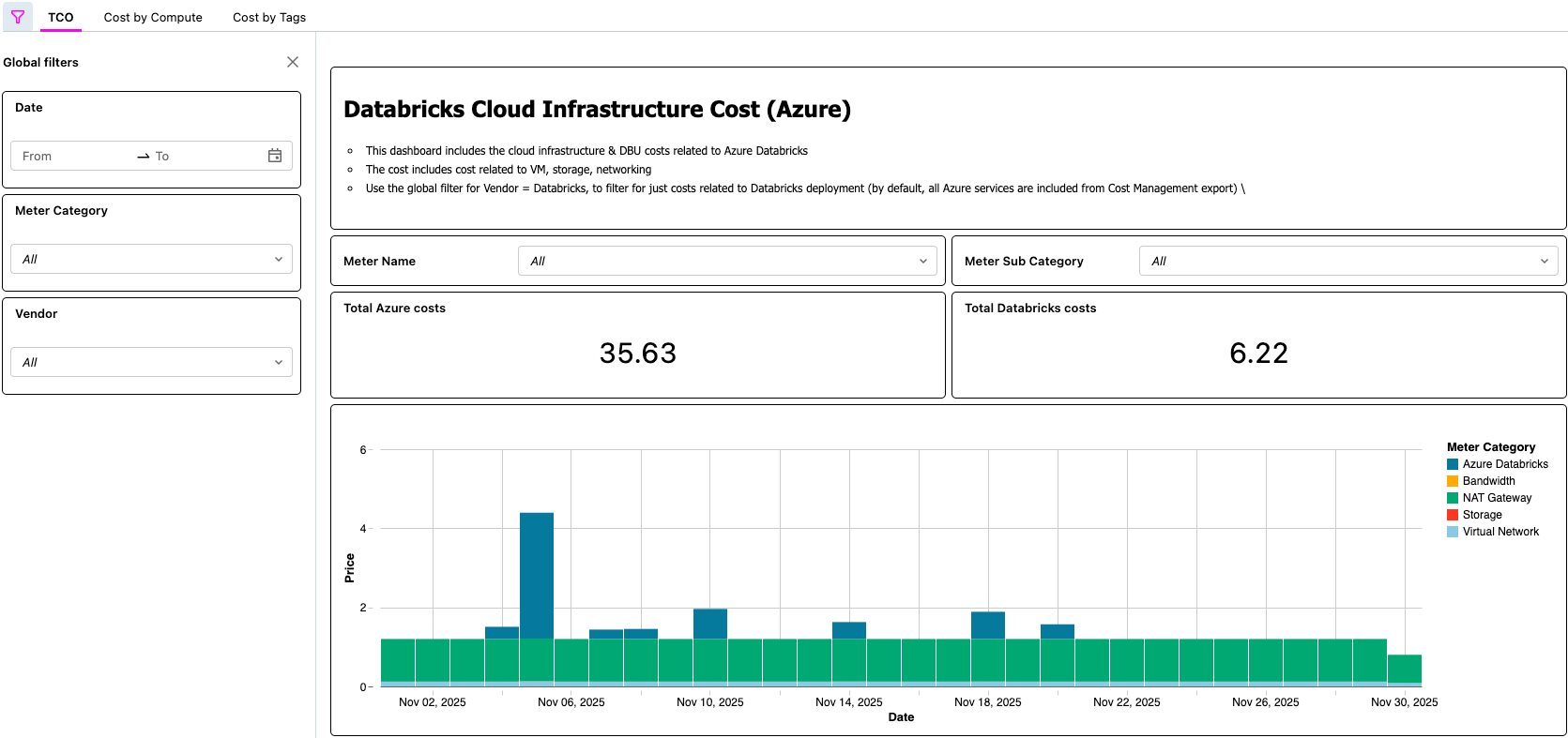{kind=link}
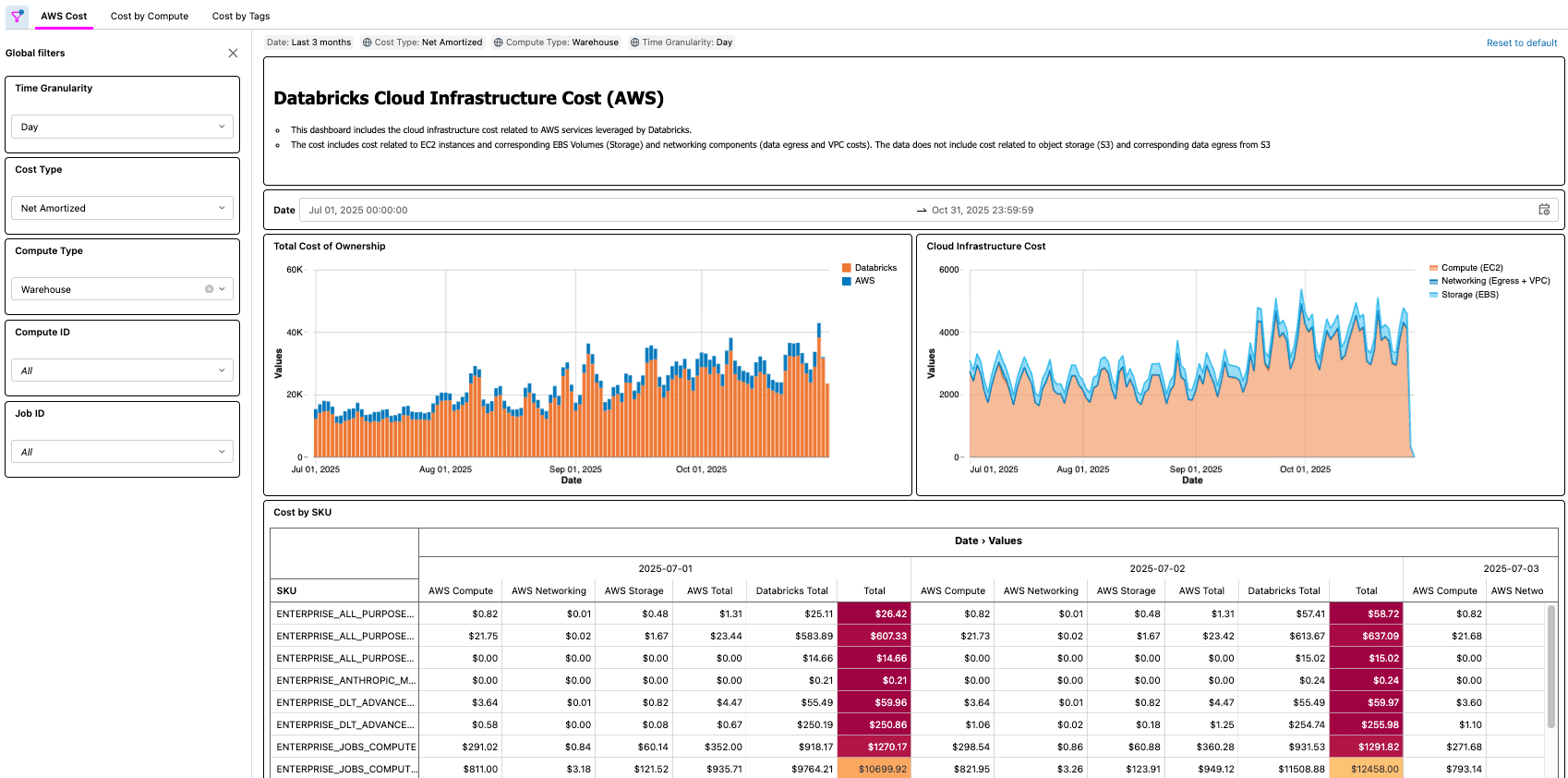
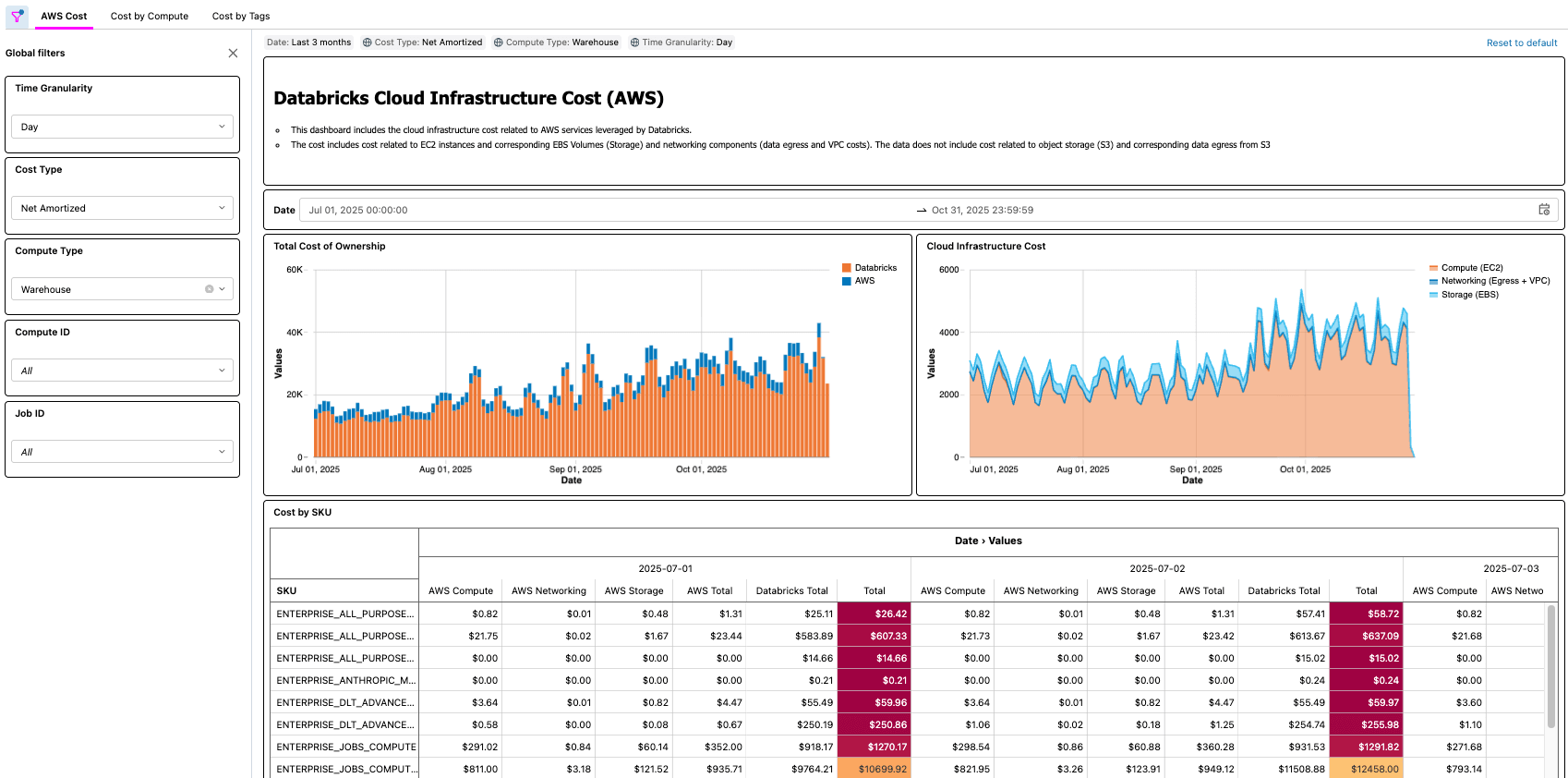
Soluzione Databricks su AWS
La soluzione per Databricks su AWS è costituita da diversi componenti dell'architettura che operano insieme per inserire i dati del report su costi & utilizzo (CUR) 2.0 di AWS e renderli persistenti in Databricks utilizzando l'architettura medallion.
Per eseguire il deployment di questa soluzione, le seguenti autorizzazioni e configurazioni devono essere attive in AWS e Databricks:
- aws
- Autorizzazioni per creare un CUR
- Autorizzazioni per creare un bucket Amazon S3 (o autorizzazioni per distribuire il CUR in un bucket esistente)
- Nota: la soluzione richiede AWS CUR 2.0. Se si dispone ancora di un'esportazione CUR 1.0, la documentazione di AWS fornisce i passaggi necessari per l'aggiornamento.
- databricks
- Autorizzazione a creare le seguenti risorse:
- Credenziale archiviazione
- Posizione esterna
- Autorizzazione a creare le seguenti risorse:
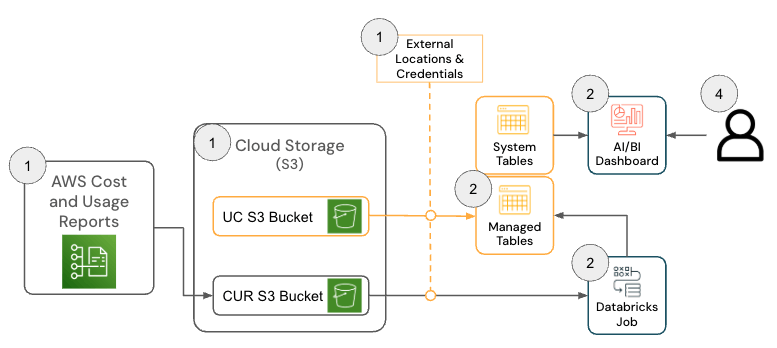
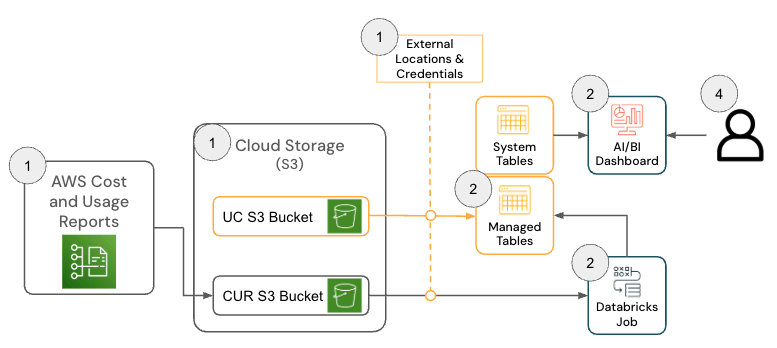{kind=link}
Il repository GitHub fornisce istruzioni di configurazione più dettagliate; tuttavia, a livello generale, la soluzione per AWS Databricks prevede i seguenti passaggi.
- [AWS] Configurazione del Report sui costi e sull'utilizzo (CUR) 2.0 di AWS
- Lo scopo di questo passaggio è sfruttare la funzionalità AWS CUR in modo che i dati di fatturazione di AWS siano disponibili in un formato di facile utilizzo.
- [Databricks] Configurazione del Databricks Asset Bundle (DAB)
- Lo scopo di questo passaggio è inserire e modellare i dati di fatturazione AWS in modo che possano essere visualizzati utilizzando una dashboard di AI/BI.
- [Databricks] Rivedi la dashboard e convalida il processo Lakeflow
- Questo passaggio finale è dove si realizza il valore. I clienti ora dispongono di un processo automatizzato che mette a loro disposizione il TCO della loro architettura lakehouse!
{kind=link}
Scenari reali
Come dimostrato con entrambe le soluzioni Azure e AWS, una soluzione come questa consente molti esempi reali, come ad esempio:
- Identificazione e calcolo del risparmio totale sui costi dopo l'ottimizzazione di un job con un basso utilizzo di CPU e/o memoria
- Identificazione di carichi di lavoro in esecuzione su tipi di VM che non hanno una prenotazione
- Identificazione di carichi di lavoro con costi di rete e/o di archiviazione locale anormalmente elevati
Come esempio pratico, un professionista FinOps di una grande organizzazione con migliaia di carichi di lavoro potrebbe avere il compito di trovare le ottimizzazioni più semplici da implementare, cercando carichi di lavoro che hanno un certo costo, ma che hanno anche un basso utilizzo della CPU e/o della memoria. Poiché le informazioni sul TCO dell'organizzazione sono ora disponibili tramite la Cloud Infra Cost Field Solution, l'utente può quindi unire tali dati alla tabella di sistema Node Timeline (AWS, AZURE, GCP) per rendere visibili queste informazioni e quantificare con precisione i risparmi sui costi una volta completate le ottimizzazioni. Le domande più importanti dipenderanno dalle esigenze aziendali di ciascun cliente. Ad esempio, General Motors utilizza questo tipo di soluzione per rispondere a molte delle domande precedenti e ad altre ancora, per assicurarsi di ottenere il massimo valore dalla propria architettura lakehouse.
Punti chiave
Dopo l'implementazione della Cloud Infra Cost Field Solution, le organizzazioni ottengono una visione unica e affidabile del TCO che combina la spesa di Databricks e dell'infrastruttura cloud correlata, eliminando la necessità di una riconciliazione manuale dei costi tra le piattaforme. Esempi di domande a cui è possibile rispondere utilizzando la soluzione:
- Qual è la ripartizione dei costi per il mio utilizzo di Databricks tra il provider di servizi cloud e Databricks?
- Qual è il costo totale per l'esecuzione di un carico di lavoro, inclusi i costi di VM, archiviazione locale e rete?
- Qual è la differenza nel costo totale di un carico di lavoro quando viene eseguito in modalità serverless rispetto a quando viene eseguito su un compute classico
I team della piattaforma e FinOps possono analizzare nel dettaglio i costi completi per workspace, carico di lavoro e business unit direttamente in Databricks, rendendo molto più semplice allineare l'utilizzo con i budget, i modelli di responsabilità e le pratiche FinOps. Poiché tutti i dati sottostanti sono disponibili come tabelle governate, i team possono creare le proprie applicazioni per i costi — dashboard, app interne o utilizzare assistenti IA integrati come Databricks Genie— accelerando la generazione di informazioni dettagliate e trasformando FinOps da un'attività di reporting periodico a una funzionalità operativa sempre attiva.
Passaggi successivi e risorse
Distribuisci oggi la Cloud Infra Cost Field Solution da GitHub (link qui, disponibile su AWS e Azure) e ottieni la piena visibilità sulla tua spesa totale per Databricks. Con una visibilità completa, puoi ottimizzare i costi di Databricks, anche prendendo in considerazione il serverless per la gestione automatizzata dell'infrastruttura.
La dashboard e la pipeline create come parte di questa soluzione offrono un modo rapido ed efficace per iniziare ad analizzare la spesa di Databricks insieme al resto dei costi dell'infrastruttura. Tuttavia, ogni organizzazione alloca e interpreta gli addebiti in modo diverso, quindi potresti voler personalizzare ulteriormente i modelli e le trasformazioni in base alle tue esigenze. Le estensioni comuni includono l'unione dei dati sui costi dell'infrastruttura con tabelle di sistema Databricks aggiuntive (AWS | AZURE | GCP) per migliorare l'accuratezza dell'attribuzione, la creazione di una logica per separare o riallocare i costi condivisi delle VM quando si utilizzano pool di istanze, la modellazione delle prenotazioni di VM in modo diverso o l'integrazione di dati storici per supportare l'analisi dell'andamento dei costi a lungo termine. Come per qualsiasi modello di costo di un hyperscaler, esiste un ampio margine per personalizzare le pipeline oltre l'implementazione predefinita per allinearle al reporting interno, alle strategie di tagging e ai requisiti FinOps.
I Delivery Solutions Architect (DSA) di Databricks accelerano le iniziative di dati e IA nelle organizzazioni. Forniscono leadership architetturale, ottimizzano le piattaforme per costi e prestazioni, migliorano l'esperienza degli sviluppatori e guidano l'esecuzione di successo dei progetti. I DSA colmano il divario tra l'implementazione iniziale e le soluzioni pronte per la produzione, lavorando a stretto contatto con vari team, tra cui ingegneria dei dati, technical lead, dirigenti e altri stakeholder, per garantire soluzioni su misura e un più rapido time-to-value. Per beneficiare di un piano di esecuzione personalizzato, della guida strategica e del supporto da parte di un DSA durante il tuo percorso con i dati e l'AI, contatta il tuo Account Team di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.