Come creare Spazi Genie pronti per la produzione e creare fiducia lungo il percorso
Un percorso per la creazione di uno spazio Genie partendo da zero fino a renderlo pronto per la produzione, migliorandone l'accuratezza attraverso la valutazione di benchmark e l'ottimizzazione sistematica.
di Pulkit Pareek e Eric Lind
- Sfrutta i benchmark per misurare oggettivamente la prontezza del tuo spazio Genie, anziché soggettivamente.
- Segui un esempio end-to-end dello sviluppo di uno spazio Genie pronto per la produzione, che illustra molti scenari comuni di risoluzione dei problemi.
- Aumenta la fiducia degli utenti finali condividendo i risultati finali di accuratezza sulle domande che necessitano di una risposta corretta.
La sfida della fiducia nell'analitica self-service
Genie è una funzionalità di Databricks che consente ai team aziendali di interagire con i propri dati utilizzando il linguaggio naturale. Utilizza l'IA generativa personalizzata in base alla terminologia e ai dati della tua organizzazione, con la possibilità di monitorare e perfezionarne le prestazioni attraverso il feedback degli utenti.
Una sfida comune a qualsiasi strumento di analitiche del linguaggio naturale è creare fiducia con gli utenti finali. Consideriamo Sarah, un'esperta di marketing che sta provando Genie per la prima volta invece delle sue dashboard.
Sarah: "Qual è stata la nostra percentuale di clic nello scorso trimestre?"
Genie: 8,5%
Il pensiero di Sarah: Aspetta, mi ricordo che abbiamo festeggiato quando abbiamo raggiunto il 6% lo scorso trimestre...
Questa è una domanda di cui Sarah conosce la risposta, ma per cui non visualizza il risultato corretto. Forse la query generata includeva campagne diverse o utilizzava una definizione di calendario standard per "ultimo trimestre", quando invece avrebbe dovuto utilizzare il calendario fiscale dell'azienda. Ma Sarah non sa cosa c'è che non va. Il momento di incertezza ha introdotto un dubbio. Senza una valutazione adeguata delle risposte, questo dubbio sull'usabilità può aumentare. Gli utenti tornano a richiedere il supporto degli analisti, il che interrompe altri progetti e aumenta i costi e il time-to-value per generare un singolo approfondimento. L'investimento nel self-service rimane sottoutilizzato.
La domanda non è solo se il tuo spazio Genie sia in grado di generare SQL. Il punto è se i tuoi utenti si fidano abbastanza dei risultati da prendere decisioni basate su di essi.
Per creare questo rapporto di fiducia è necessario passare da una valutazione soggettiva ("sembra che funzioni") a una convalida misurabile ("lo abbiamo testato sistematicamente"). Dimostreremo come la funzionalità di benchmark integrata di Genie trasforma un'implementazione di base in un sistema pronto per la produzione su cui gli utenti fanno affidamento per le decisioni critiche. I benchmark forniscono un metodo basato sui dati per valutare la qualità del tuo spazio Genie e ti aiutano a colmare le lacune durante la sua cura.
In questo blog ti guideremo attraverso un esempio di percorso end-to-end per la creazione di uno Genie space con benchmark per sviluppare un sistema affidabile.
I dati: analisi della campagna di marketing
Il nostro team di marketing deve analizzare le prestazioni delle campagne su quattro set di dati interconnessi.
- Clienti potenziali - Informazioni sull'azienda, inclusi settore e località
- Contatti - Informazioni sul destinatario, inclusi reparto e tipo di dispositivo
- Campagne - Dettagli della campagna, inclusi budget, template e date
- Eventi - Tracciamento degli eventi email (invii, aperture, clic, segnalazioni di spam)
Il flusso di lavoro: identificare le aziende target (prospect) → trovare i contatti presso tali aziende → inviare campagne di marketing → monitorare la risposta dei destinatari a tali campagne (eventi).
Alcune domande di esempio a cui gli utenti dovevano rispondere sono:
- "Quali campagne hanno prodotto il ROI migliore per settore industriale?"
- "Qual è il nostro rischio di conformità per i diversi tipi di campagna?"
- "In che modo i pattern di engagement (CTR) variano in base al dispositivo e al reparto?"
- "Quali Template hanno le prestazioni migliori per specifici segmenti di prospect?"
Queste domande richiedono l'unione di tabelle, il calcolo di metriche specifiche del dominio e l'applicazione di conoscenze del dominio su ciò che rende una campagna "di successo" o "ad alto rischio". È fondamentale rispondere correttamente, perché da queste risposte dipendono direttamente l'allocazione del budget, la strategia della campagna e le decisioni sulla conformità. Iniziamo!
Il percorso: dallo sviluppo della baseline alla produzione
Non bisogna aspettarsi che l'aggiunta aneddotica di tabelle e di una manciata di prompt di testo produca uno spazio Genie sufficientemente accurato per gli utenti finali. Una conoscenza approfondita delle esigenze degli utenti finali, unita alla conoscenza dei set di dati e delle funzionalità della piattaforma Databricks, porterà ai risultati desiderati.
In questo esempio end-to-end, valutiamo l'accuratezza del nostro Genie space tramite benchmark, diagnostichiamo le lacune di contesto che causano risposte errate e implementiamo le correzioni. Considera questo framework per approcciare lo sviluppo e le valutazioni di Genie.
- Definisci la tua suite di benchmark (punta a 10-20 domande rappresentative). Queste domande dovrebbero essere definite da esperti in materia e dagli utenti finali che utilizzeranno Genie per le analitiche. Idealmente, queste domande vengono create prima di qualsiasi sviluppo effettivo del tuo spazio Genie.
- Stabilisci la tua precisione di riferimento. Esegui tutte le domande di benchmark nel tuo spazio con solo gli oggetti dati di base aggiunti allo spazio Genie. Documenta l'accuratezza, quali domande vengono superate, quali no e perché.
- Ottimizza sistematicamente. Implementa una serie di modifiche (ad es. aggiungendo le descrizioni delle colonne). Riesegui tutte le domande di benchmark. Misura l'impatto, i miglioramenti e continua lo sviluppo iterativo seguendo le best practice pubblicate.
- Misura e comunica. L'esecuzione dei benchmark fornisce criteri di valutazione oggettivi che dimostrano come lo spazio Genie soddisfi sufficientemente le aspettative, aumentando la fiducia di utenti e stakeholder.
Abbiamo creato una suite di 13 domande di benchmark che rappresentano ciò che gli utenti finali cercano nei nostri dati di marketing. Ogni domanda di benchmark è una domanda realistica in un inglese semplice, abbinata a una query SQL convalidata che risponde a tale domanda.
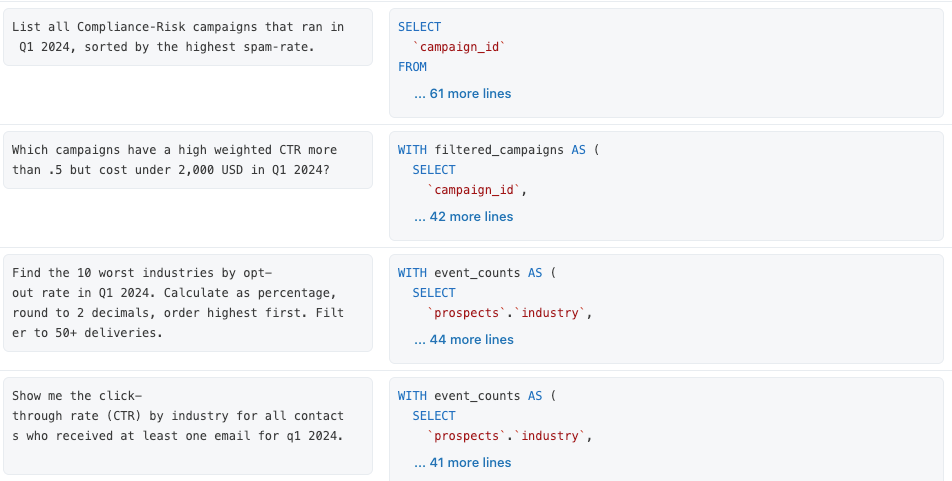
Genie non include queste query SQL di benchmark come contesto esistente, per scelta progettuale. Vengono utilizzati esclusivamente per la valutazione. È nostro compito fornire il contesto giusto in modo che sia possibile rispondere correttamente a tali domande. Iniziamo!
Iterazione 0: stabilire la baseline
Abbiamo intenzionalmente iniziato con nomi di tabella scadenti come cmp e proc_delta, e nomi di colonna come uid_seq (per campaign_id), label_txt (per campaign_name), num_val (per cost) e proc_ts (per event_date). Questo punto di partenza rispecchia ciò che molte organizzazioni affrontano realmente: dati modellati per convenzioni tecniche piuttosto che per un significato aziendale.
Le tabelle da sole, inoltre, non forniscono alcun contesto su come calcolare KPI e metriche specifici del dominio. Genie sa come sfruttare centinaia di funzioni SQL integrate, ma ha comunque bisogno delle colonne e della logica giuste da utilizzare come input. Cosa succede quindi quando Genie non ha abbastanza contesto?
Analisi dei benchmark: Genie non è riuscito a rispondere correttamente a nessuna delle nostre 13 domande di benchmark. Non perché l'IA non fosse abbastanza potente, ma perché mancava di qualsiasi contesto pertinente, come mostrato di seguito.

Approfondimento: ogni domanda posta dagli utenti finali si basa sulla produzione da parte di Genie di una query SQL a partire dagli oggetti di dati forniti. Convenzioni di denominazione dei dati di scarsa qualità influenzeranno quindi ogni singola query generata. Non è possibile trascurare la qualità dei dati di base e aspettarsi di creare un rapporto di fiducia con gli utenti finali! Genie non genera una query SQL per ogni domanda. Lo fa solo quando ha abbastanza contesto. Questo è un comportamento previsto per prevenire allucinazioni e risposte fuorvianti.
Azione successiva: I punteggi di benchmark iniziali bassi indicano che dovresti prima concentrarti sulla pulizia degli oggetti di Unity Catalog, quindi inizieremo da lì.
Iterazione 1: significati ambigui delle colonne
Abbiamo migliorato i nomi delle tabelle in campaigns, events, contacts e prospects e aggiunto descrizioni chiare delle tabelle in Unity Catalog.

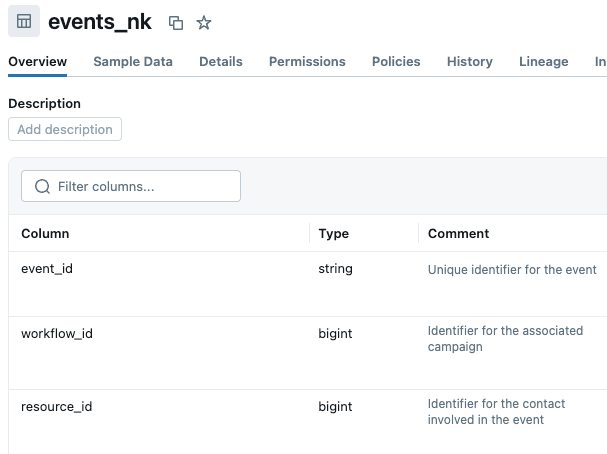
Tuttavia, abbiamo riscontrato un'altra sfida correlata: nomi di colonna o commenti fuorvianti che suggeriscono relazioni inesistenti.
Ad esempio, colonne come workflow_id, resource_id e owner_id esistono in più tabelle. Sembra che dovrebbero collegare le tabelle tra loro, ma non è così. La tabella events utilizza workflow_id come chiave esterna per le campagne (non una tabella di flusso di lavoro separata) e resource_id come chiave esterna per i contatti (non una tabella di risorse separata). Nel frattempo, la tabella campaigns ha una propria colonna workflow_id che non è assolutamente correlata. Se i nomi e le descrizioni di queste colonne non sono annotati in modo appropriato, ciò può portare a un uso impreciso di tali attributi. Abbiamo aggiornato le descrizioni delle colonne in Unity Catalog per esplicitare lo scopo di ciascuna di quelle colonne ambigue. Nota: se non riesci a modificare i metadati in UC, puoi aggiungere le descrizioni di tabelle e colonne nel knowledge store dello spazio Genie.
Analisi dei benchmark: le query semplici a tabella singola hanno iniziato a funzionare grazie a nomi e descrizioni chiari. Domande come "Conta eventi per tipo nel 2023" e "Quali campagne sono iniziate negli ultimi tre mesi?" ora ricevevano risposte corrette. Tuttavia, qualsiasi query che richiedeva join tra tabelle falliva: Genie non era ancora in grado di determinare correttamente quali colonne rappresentassero le relazioni.
Approfondimento: le convenzioni di denominazione chiare sono d'aiuto, ma senza definizioni esplicite delle relazioni, Genie deve indovinare quali colonne collegano le tabelle. Quando più colonne hanno nomi come workflow_id o resource_id, queste supposizioni possono portare a risultati imprecisi. Metadati adeguati fungono da base, ma le relazioni devono essere definite esplicitamente.
Azione successiva: definisci le relazioni di join tra i tuoi oggetti di dati. Nomi di colonna come id o resource_id compaiono di continuo. Chariamo esattamente quali di quelle colonne fanno riferimento ad altri oggetti di tabella.
Iterazione 2: Modello di dati ambiguo
Il modo migliore per chiarire quali colonne Genie dovrebbe utilizzare per unire le tabelle è attraverso l'uso di chiavi primarie ed esterne. Abbiamo aggiunto vincoli di chiave primaria ed esterna in Unity Catalog, indicando esplicitamente a Genie come si collegano le tabelle: campaigns.campaign_id si collega a events.campaign_id, che si collega a contacts.contact_id, che si collega a prospects.prospect_id. Ciò elimina le congetture e determina come vengono creati di default i join multi-tabella. Nota: se non riesci a modificare le relazioni in UC o se la relazione tra tabelle è complessa (ad es. più condizioni di JOIN), puoi definirle nel knowledge store dello spazio Genie.
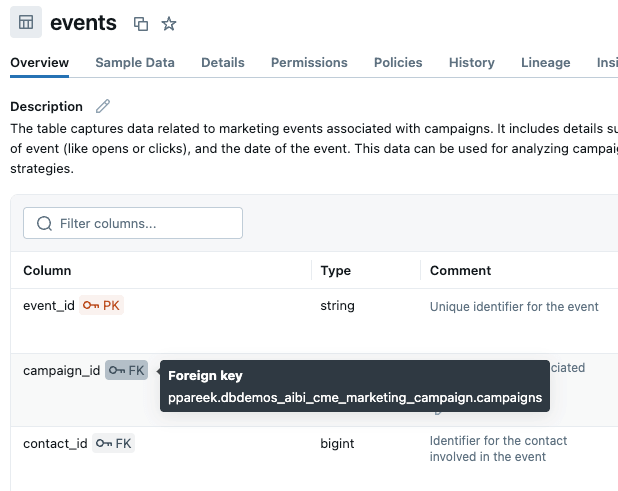
In alternativa, potremmo considerare la creazione di una vista metrica che può includere i dettagli di join esplicitamente nella definizione dell'oggetto. Ne parleremo più avanti.
Analisi benchmark: Progresso costante. Le domande che richiedevano join su più tabelle hanno iniziato a funzionare: "Mostra i costi delle campagne per settori industriali per il primo trimestre 2024" e "Quali campagne hanno avuto più di 1.000 eventi a gennaio?" ora hanno avuto successo.
Approfondimento: le relazioni consentono le query complesse su più tabelle che forniscono un valore aziendale reale. Genie genera SQL strutturato correttamente ed esegue correttamente operazioni semplici come la somma dei costi e il conteggio degli eventi.
Azione: dei restanti benchmark errati, molti includono riferimenti a valori che gli utenti intendono sfruttare come filtri di dati. Il modo in cui gli utenti finali pongono le domande non corrisponde direttamente ai valori presenti nel set di dati.
Iterazione 3: comprensione dei valori dei dati
Uno spazio Genie dovrebbe essere curato per rispondere a domande specifiche del dominio. Tuttavia, le persone non sempre parlano usando la stessa identica terminologia con cui appaiono i nostri dati. Gli utenti potrebbero dire "aziende di bioingegneria" ma il valore dei dati è "biotecnologia".
L'abilitazione di dizionari di valori e del campionamento dei dati consente una ricerca più rapida e precisa dei valori così come esistono nei dati, anziché fare in modo che Genie utilizzi solo il valore esatto richiesto dall'utente finale.

I valori di esempio e i dizionari di valori sono ora attivati per impostazione predefinita, ma vale la pena controllare due volte che le colonne giuste comunemente utilizzate per il filtraggio siano abilitate e dispongano di dizionari di valori personalizzati quando necessario.
Analisi di benchmark: oltre il 50% delle domande di benchmark ora ottiene risposte corrette. Le domande che includono valori di categoria specifici come “biotecnologia” hanno iniziato a identificare correttamente tali filtri. La sfida ora è implementare metriche e aggregazioni personalizzate. Ad esempio, Genie fornisce una migliore ipotesi su come calcolare il CTR in base al rilevamento del valore “click” e alla sua comprensione delle metriche basate su tassi. Ma non è abbastanza sicuro per generare semplicemente le query:
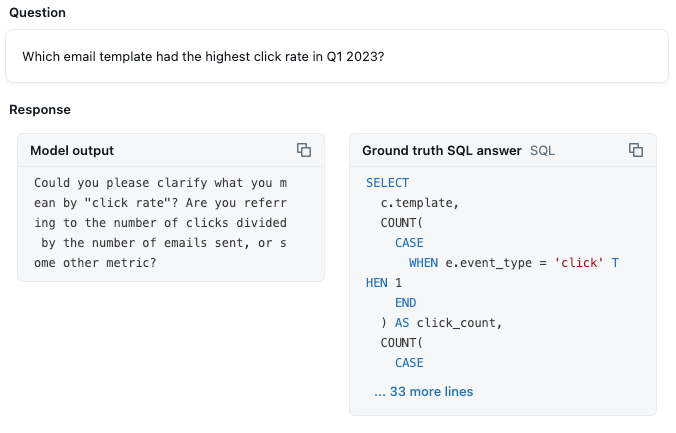
Questa è una metrica che vogliamo sia calcolata correttamente il 100% delle volte, quindi dobbiamo chiarire quel dettaglio per Genie.
Approfondimento: il campionamento dei valori migliora la generazione SQL di Genie fornendo l'accesso a valori di dati reali. Quando gli utenti pongono domande colloquiali con errori di ortografia o terminologia diversa, il campionamento dei valori aiuta Genie a far corrispondere i prompt ai valori di dati effettivi nelle tabelle.
Azione successiva: il problema più comune ora è che Genie non genera ancora l'SQL corretto per le nostre metriche personalizzate. Definiamo in modo esplicito le nostre metriche per ottenere risultati più accurati.
Iterazione 4: Definizione di metriche personalizzate
A questo punto, Genie ha il contesto per gli attributi di dati categorici presenti nei dati, può filtrare in base ai nostri valori di dati ed eseguire aggregazioni semplici da funzioni SQL standard (ad es. “conteggio eventi per tipo” utilizza COUNT()). Per fare più chiarezza su come Genie dovrebbe calcolare le nostre metriche, abbiamo aggiunto query SQL di esempio al nostro genie space. Questo esempio mostra la definizione di metrica corretta per il CTR:
Nota: si consiglia di lasciare commenti nelle query SQL, poiché forniscono un contesto pertinente insieme al codice.
Analisi di benchmark: questo ha prodotto il più grande miglioramento singolo in termini di accuratezza finora. Considera che il nostro obiettivo è rendere Genie in grado di rispondere a domande a un livello molto dettagliato per un pubblico definito. È previsto che la maggior parte delle domande degli utenti finali si baserà su metriche personalizzate, come CTR, tassi di spam, metriche di engagement, ecc. Ancora più importante, anche le varianti di queste domande hanno funzionato. Genie ha imparato la definizione della nostra metrica e la applicherà a qualsiasi query futura.
Approfondimento: le query di esempio insegnano una logica di business che i soli metadati non possono trasmettere. Una query di esempio ben congegnata spesso risolve simultaneamente un'intera categoria di lacune nei benchmark. Questo ha fornito più valore di qualsiasi altro singolo passaggio di iterazione finora.
Azione successiva: Restano solo alcune domande errate nel benchmark. A un'analisi più attenta, notiamo che i restanti benchmark non vanno a buon fine per due motivi:
- Gli utenti pongono domande su attributi di dati che non esistono direttamente nei dati. Ad esempio, “quante campagne hanno generato un CTR elevato nell'ultimo trimestre?” Genie non sa cosa intende un utente per CTR "alto" perché non esiste un attributo di dati corrispondente.
- Queste tabelle di dati includono record che dovremmo escludere. Ad esempio, abbiamo molte campagne di test che non sono destinate ai clienti. Dobbiamo escluderle dai nostri KPI.
Iterazione 5: documentazione delle regole specifiche del dominio
Queste lacune rimanenti sono frammenti di contesto che si applicano globalmente al modo in cui tutte le nostre query dovrebbero essere create e si riferiscono a valori che non esistono direttamente nei nostri dati.
Prendiamo il primo esempio sull'CTR elevato o qualcosa di simile come le campagne ad alto costo. Non è sempre facile e neppure consigliato aggiungere dati specifici del dominio alle nostre tabelle, per diversi motivi:
- Apportare modifiche, come l'aggiunta di un campo
campaign_cost_segmentation(alto, medio, basso), alle tabelle di dati richiederà tempo e avrà un impatto su altri processi, poiché gli schemi delle tabelle e le pipeline di dati dovranno essere tutti modificati. - Per i calcoli aggregati come il CTR, man mano che arrivano nuovi dati, i valori del CTR cambieranno. In ogni caso, non dovremmo pre-calcolare questo valore; vogliamo che il calcolo venga eseguito on-the-fly mentre specifichiamo i filtri, come i periodi di tempo e le campagne.
Quindi possiamo usare un'istruzione testuale in Genie per eseguire per noi questa segmentazione specifica del dominio.

Allo stesso modo, possiamo specificare come Genie dovrebbe sempre scrivere le query per allinearle alle aspettative di business. Ciò può includere elementi come calendari personalizzati, filtri globali obbligatori, ecc. Ad esempio, i dati di questa campagna includono campagne di test che dovrebbero essere escluse dai nostri calcoli dei KPI.


Analisi di benchmark: accuratezza del benchmark del 100%! I casi limite e le domande basate su soglie hanno iniziato a funzionare in modo coerente. Le domande su "campagne ad alto rendimento" o "campagne a rischio di conformità" ora applicano correttamente le nostre definizioni aziendali.
Approfondimento: le istruzioni testuali sono un modo semplice ed efficace per colmare eventuali lacune rimaste dai passaggi precedenti, per garantire che vengano generate le query corrette per gli utenti finali. Tuttavia, non dovrebbe essere il primo né l'unico posto a cui affidarsi per l'iniezione di contesto.
Nota: in alcuni casi potrebbe non essere possibile raggiungere il 100% di accuratezza. Ad esempio, a volte le domande di benchmark richiedono query molto complesse o più prompt per generare la risposta corretta. Se non riesci a creare facilmente una singola query SQL di esempio, annota semplicemente questa lacuna quando condividi i risultati della valutazione del benchmark con altri. In genere ci si aspetta che i benchmark di Genie siano superiori all'80% prima di passare al test di accettazione utente (UAT).
Azione successiva: ora che Genie ha raggiunto il livello di accuratezza previsto per le nostre domande di benchmark, passeremo all'UAT e raccoglieremo ulteriori feedback dagli utenti finali!
(Facoltativo) Iterazione 6: Pre-calcolo di metriche complesse
Per la nostra iterazione finale, abbiamo creato una vista personalizzata che predefinisce le metriche di marketing chiave e applica le classificazioni aziendali. Creare una vista o una vista metrica può essere più semplice nei casi in cui tutti i set di dati rientrano in un unico modello di dati e si dispone di decine di metriche personalizzate. È più semplice inserire tutti questi elementi nella definizione di un oggetto dati piuttosto che scrivere una query SQL di esempio per ciascuno di essi specifica per lo spazio Genie.
Risultato del benchmark: abbiamo comunque ottenuto un'accuratezza del benchmark del 100% sfruttando le viste invece delle sole tabelle di base, poiché il contenuto dei metadati è rimasto lo stesso.
Approfondimento: invece di spiegare calcoli complessi attraverso esempi o istruzioni, è possibile incapsularli in una vista o in una vista metrica, definendo un'unica fonte di verità.
Cosa abbiamo imparato: l'impatto dello sviluppo guidato dai benchmark
Non esiste una soluzione magica per configurare uno spazio Genie che risolva tutto. L'accuratezza pronta per la produzione si ottiene in genere solo quando si dispone di dati di alta qualità, metadati arricchiti in modo appropriato, una logica delle metriche definita e un contesto specifico del dominio inserito nello spazio. Nel nostro esempio end-to-end, abbiamo riscontrato problemi comuni che riguardavano tutte queste aree.
I benchmark sono fondamentali per valutare se il tuo spazio soddisfa le aspettative ed è pronto per il feedback degli utenti. Ha anche guidato i nostri sforzi di sviluppo per colmare le lacune nell'interpretazione delle domande da parte di Genie. In revisione:
- Iterazioni 1-3 - 54% di precisione dei benchmark. Queste iterazioni si sono concentrate sul far comprendere più chiaramente a Genie i nostri dati e metadati. L'implementazione di nomi di tabella, descrizioni di tabella, descrizioni di colonna, chiavi di join e l'abilitazione di valori di esempio appropriati sono tutti passaggi fondamentali per qualsiasi Genie space. Con queste funzionalità, Genie dovrebbe essere in grado di identificare correttamente la tabella, le colonne e le condizioni di join giuste che influiscono su qualsiasi query generata. Può anche eseguire semplici aggregazioni e filtraggio. Genie è stato in grado di rispondere correttamente a più della metà delle nostre domande di benchmark specifiche del dominio solo con questa conoscenza di base.
- Iterazione 4 - accuratezza del benchmark del 77%. Questa iterazione si è concentrata sul chiarire le definizioni delle nostre metriche personalizzate. Ad esempio, il CTR non fa parte di ogni domanda di benchmark, ma è un esempio di metrica non standard (ad es. sum(), avg(), ecc.) che deve essere calcolata correttamente ogni volta.
- Iterazione 5: accuratezza del benchmark del 100%. Questa iterazione ha dimostrato l'uso di istruzioni testuali per colmare le lacune rimanenti nelle imprecisioni. Queste istruzioni includevano scenari comuni, come l'inclusione di filtri globali sui dati per uso analitico, definizioni specifiche del dominio (ad es. cosa costituisce una campagna ad altocoinvolgimento) e informazioni sui calendari fiscali specificati.
Seguendo un approccio sistematico di valutazione del nostro Genie space, abbiamo individuato un comportamento imprevisto delle query in modo proattivo, invece di venirne a conoscenza da Sarah in modo reattivo. Abbiamo trasformato la valutazione soggettiva ("sembra funzionare") in una misurazione oggettiva ("abbiamo convalidato il suo funzionamento per 13 scenari rappresentativi che coprono i nostri principali casi d'uso come inizialmente definiti dagli utenti finali").
Il percorso da seguire
Per creare fiducia nelle analitiche self-service non è necessario raggiungere la perfezione fin dal primo giorno. Si tratta piuttosto di un miglioramento sistematico con una convalida misurabile. L'importante è individuare i problemi prima che lo facciano gli utenti.
La funzionalità Benchmark fornisce il livello di misurazione che rende tutto ciò realizzabile. Trasforma l'approccio iterativo consigliato dalla documentazione di Databricks in un processo quantificabile e che crea fiducia. Riepiloghiamo questo processo di sviluppo sistematico basato su benchmark:
- Crea domande di benchmark (obiettivo: 10-15) che rappresentino le domande realistiche dei tuoi utenti.
- Testa il tuo spazio per stabilire l'accuratezza di base
- Apporta miglioramenti alla configurazione seguendo l'approccio iterativo che Databricks consiglia nelle nostre best practice
- Riesegui tutti i benchmark dopo ogni modifica per misurare l'impatto e identificare le lacune nel contesto derivanti da domande errate. Documenta l'avanzamento della precisione per aumentare la fiducia degli stakeholder.
Parti da solide basi di Unity Catalog. Aggiungi il contesto di business. Testa in modo esaustivo tramite benchmark. Misura ogni modifica. Crea fiducia attraverso l'accuratezza convalidata.
Tu e i tuoi utenti finali ne trarrete vantaggio!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.