Come le tabelle di sistema di Databricks aiutano i data engineer a ottenere un'osservabilità avanzata
Le tabelle di sistema forniscono ai data engineer l'ampiezza e la profondità dei dati di cui hanno bisogno per monitorare con semplicità lo stato di salute delle loro pipeline di dati su larga scala, per carichi di lavoro più convenienti e affidabili.
- Scopri come le System Tables espongono la telemetria della piattaforma come tabelle interrogabili, includendo metadati e informazioni dettagliate sull'esecuzione per i processi e le pipeline di Lakeflow.
- Utilizza query di esempio per trasformare questa telemetria in informazioni dettagliate su opportunità di affidabilità, costo ed efficienza su larga scala per i Lakeflow jobs.
- Centralizza queste informazioni dettagliate in una vista operativa condivisa e quotidiana per i team di data ingegneria con il dashboard template di Lakeflow.
Il problema delle 3 del mattino
Sono le 3 del mattino e qualcosa si è rotto. La dashboard non è aggiornata, uno SLA non è stato rispettato e tutti si chiedono quale parte della piattaforma sia andata fuori fase. Forse un job è rimasto in esecuzione per ore senza timeout. Forse una pipeline ha aggiornato una tabella che nessuno leggeva da mesi. Forse un cluster è ancora su un vecchio runtime. Forse l'unica persona che conosce il proprietario del job è in vacanza.
Questi sono gli schemi che logorano i data team: compute sprecato da pipeline inutilizzate, lacune di affidabilità dovute a regole di controllo mancanti, problemi di igiene causati da runtime obsoleti e ritardi dovuti a responsabilità poco chiare. Si manifestano silenziosamente, crescono lentamente e poi, all'improvviso, diventano la causa dell'insonnia del tecnico reperibile.
Databricks System Tables forniscono un livello coerente per individuare precocemente questi problemi, esponendo in un unico posto metadati dei job, tempistiche delle attività, comportamento di esecuzione, cronologia della configurazione, lineage, indicatori di costo e proprietà.
Con le nuove tabelle di sistema per Lakeflow Jobs, ora hai accesso a schemi estesi che offrono dettagli di esecuzione più ricchi e segnali di metadati, consentendo un'osservabilità più avanzata.
Visibilità più approfondita e centralizzata su tutti i tuoi dati, semplificata con le System Tables.
Cosa sono le tabelle di sistema?
Le tabelle di sistema di Databricks sono un insieme di tabelle di sola lettura gestite da Databricks nel catalogo system che forniscono dati operativi e di osservabilità per il tuo account. Sono disponibili fin da subito e coprono una vasta gamma di dati, tra cui Job, pipeline, cluster, fatturazione, derivazione e altro ancora.
Categoria | Cosa traccia |
Job di Lakeflow | Configurazioni dei job, definizioni dei task, cronologie delle esecuzioni |
Lakeflow Spark Declarative Pipelines | Metadati della pipeline, cronologia degli aggiornamenti |
Fatturazione | Utilizzo, attribuzione dei costi per carico di lavoro |
Derivazione | Dipendenze di lettura/scrittura a livello di tabella |
Cluster | Configurazioni compute, utilizzo |
Perché le tabelle di sistema sono importanti per l'osservabilità
Le tabelle di sistema supportano l'analisi tra workspace all'interno di una regione, consentendo ai team di data engineering di analizzare facilmente qualsiasi comportamento del carico di lavoro e i pattern operativi su larga Scale da un'unica interfaccia interrogabile. Utilizzando queste tabelle, gli esperti di dati possono monitorare centralmente lo stato di salute di tutte le loro pipeline, individuare opportunità di risparmio sui costi e identificare rapidamente i fallimenti per una maggiore affidabilità.
Alcune Tabelle di sistema utilizzano la semantica SCD di tipo 2, conservando la cronologia completa delle modifiche tramite l'inserimento di una nuova riga per ogni aggiornamento. Ciò consente il controllo della configurazione e l'analisi storica dello stato della piattaforma nel tempo.
Tabelle di sistema di Lakeflow
Tabelle di sistema di Lakeflow conservano i dati degli ultimi 365 giorni e sono composte dalle seguenti tabelle.
Per un elenco completo delle System Tables e delle loro relazioni, fai riferimento alla documentazione.
Tabelle di osservabilità dei job (Disponibilità generale)
system.lakeflow.jobs: metadati SCD2 per i job, incluse configurazione e tag. Utile per l'inventario, la governance e l'analisi della deviazione della configurazione.system.lakeflow.job_tasks: tabella SCD2 che descrive tutte le attività dei job, le loro definizioni e le dipendenze. Utile per comprendere le strutture delle attività su Scale.system.lakeflow.job_run_timeline– Timeline immutabile delle esecuzioni dei job con stato, compute e tempistiche. Ideale per l'analisi dei trend di SLA e delle prestazioni.system.lakeflow.job_task_run_timeline– Sequenza temporale delle esecuzioni delle singole attività all'interno di ogni job. Aiuta a individuare i colli di bottiglia e i problemi a livello di attività.
Tabelle di osservabilità delle pipeline (Anteprima pubblica)
system.lakeflow.pipelines– Tabella di metadati SCD2 per le pipeline SDP, che consente la visibilità delle pipeline tra aree di lavoro e il tracciamento delle modifiche.system.lakeflow.pipeline_update_timeline: log di esecuzione immutabili per gli aggiornamenti delle pipeline, a supporto del debug e dell'ottimizzazione storica.
Le tabelle di sistema di Lakeflow hanno registrato una rapida crescita di popolarità, con decine di milioni di query eseguite ogni singolo giorno, segnando un aumento di 17 volte su base annua. Questo picco sottolinea il valore che i data engineer traggono dalle tabelle di sistema di Lakeflow, che sono diventate un componente cruciale dell'osservabilità quotidiana per molti clienti di Databricks Lakeflow.
Esaminiamo ora i casi d'uso resi possibili dalle tabelle di sistema dei processi, recentemente ampliate e ora disponibili a livello generale.
Tabelle di sistema in pratica: stato di salute operativo per Lakeflow Jobs
In qualità di data engineer in un team di piattaforma centrale, hai la responsabilità di gestire centinaia di processi per più team. Il tuo obiettivo è mantenere la piattaforma dati economica, affidabile e performante, garantendo al contempo che i team seguano le best practice operative e di governance.
A tale scopo, hai iniziato a eseguire l'audit dei tuoi processi e delle tue pipeline di Lakeflow in base a quattro obiettivi principali:
- Ottimizza i costi: Identifica i job pianificati che aggiornano set di dati mai utilizzati a valle.
- Garantire l'affidabilità: applica timeout e soglie di esecuzione per evitare job fuori controllo e violazioni degli SLA.
- Mantenere l'igiene: verificare la coerenza delle versioni di runtime e degli standard di configurazione.
- Assegna responsabilità: identifica i proprietari dei job per semplificare i follow-up e la risoluzione dei problemi.
Pattern 1: trovare i processi che producono dati non utilizzati
Il problema: I job pianificati vengono eseguiti regolarmente, aggiornando tabelle che nessun consumer a valle legge mai. Spesso si tratta del modo più semplice per risparmiare sui costi, se si riesce a individuarli.
L'approccio: unire le tabelle Lakeflow Jobs con le tabelle di lineage e di fatturazione per identificare i producer senza consumer, classificati in base al costo.
Cosa fare dopo: esamina i principali responsabili con i rispettivi proprietari. Alcuni potrebbero essere sospesi immediatamente in tutta sicurezza. Per altri potrebbe essere necessario un piano di deprecazione se dei sistemi esterni ne dipendono al di fuori di Databricks.
Pattern 2: ricerca di processi senza timeout o soglie di durata
Il problema: I job senza timeout possono essere eseguiti a tempo indeterminato. Un task bloccato consuma compute per ore, o addirittura giorni, prima che qualcuno se ne accorga. Oltre ad aumentare i costi, questo può causare anche violazioni degli SLA, quindi è necessario individuare tempestivamente gli sforamenti e intervenire prima che le scadenze o i processi a valle ne risentano.
L'approccio: Eseguire una query sulle configurazioni dei job attuali per le impostazioni di timeout e threshold di durata mancanti.
Operazioni successive: esegui un confronto incrociato con i runtime cronologici da job_run_timeline per impostare threshold realistiche. Un job che in genere viene eseguito in 20 minuti potrebbe richiedere un timeout di 1 ora e una threshold di durata di 30 minuti. Un job che varia ampiamente potrebbe richiedere prima un'analisi.
Pattern 3: rileva le versioni di runtime legacy
Il problema: I runtime deprecati sono privi di patch di sicurezza e miglioramenti delle prestazioni e soggetti a imminenti scadenze di fine del ciclo di vita (EOL). Tuttavia, con centinaia di Job, tenere traccia di chi utilizza ancora le versioni precedenti è un'operazione noiosa.
L'approccio: Eseguire query sulle configurazioni delle attività dei job per le versioni di runtime e segnalare tutto ciò che è al di sotto della threshold.
Passaggi successivi: Assegna la priorità agli aggiornamenti in base alle scadenze EOL. Condividi questo elenco con i proprietari dei job e monitora i progressi nelle query di follow-up.
Schema 4: identificare i proprietari dei job per la risoluzione
Il problema: Quando un job fallisce o non è configurato correttamente, è necessario sapere chi contattare per risolvere il problema.
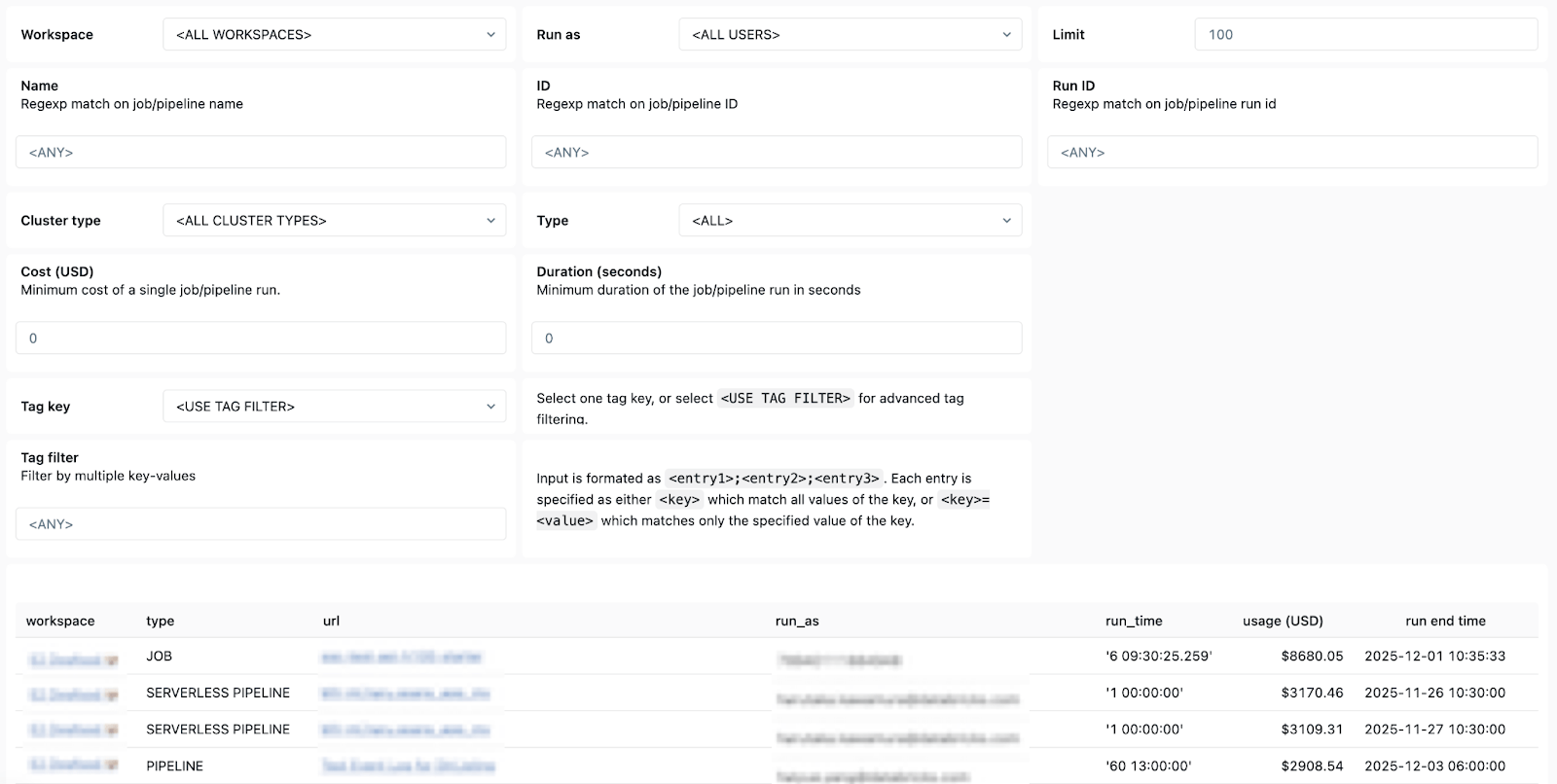
L'approccio: Eseguire query sulle tabelle di sistema per identificare facilmente i proprietari dei job per ogni azione da intraprendere.
Operazioni successive: contatta i proprietari dei processi per assegnare la proprietà dei problemi che richiedono un intervento.
Insieme, questi pattern ti aiutano a ottimizzare i costi, a mantenere i dati aggiornati, ad applicare meccanismi di protezione per l'affidabilità e ad assegnare una chiara proprietà per la risoluzione. Costituiscono le fondamenta per l'osservabilità operativa.
Mettere tutto insieme: operazionalizzare le informazioni dettagliate con le dashboard
Eseguire queste query ad hoc è utile. Ma per le attività operative quotidiane, vuoi una vista condivisa che tutto il team possa consultare.
La dashboard di Lakeflow mi offre una panoramica dei Job in tutti i miei Workspace, non solo a livello di costi, ma anche per l'integrità e le attività operative delle pipeline: tracciamento della spesa, identificazione delle pipeline obsolete, monitoraggio degli errori e individuazione di opportunità di ottimizzazione. - Zoe Van Noppen, Data Solution Architect, Cubigo
Per iniziare, importa la dashboard nel tuo workspace. Per istruzioni dettagliate, fai riferimento alla documentazione ufficiale.
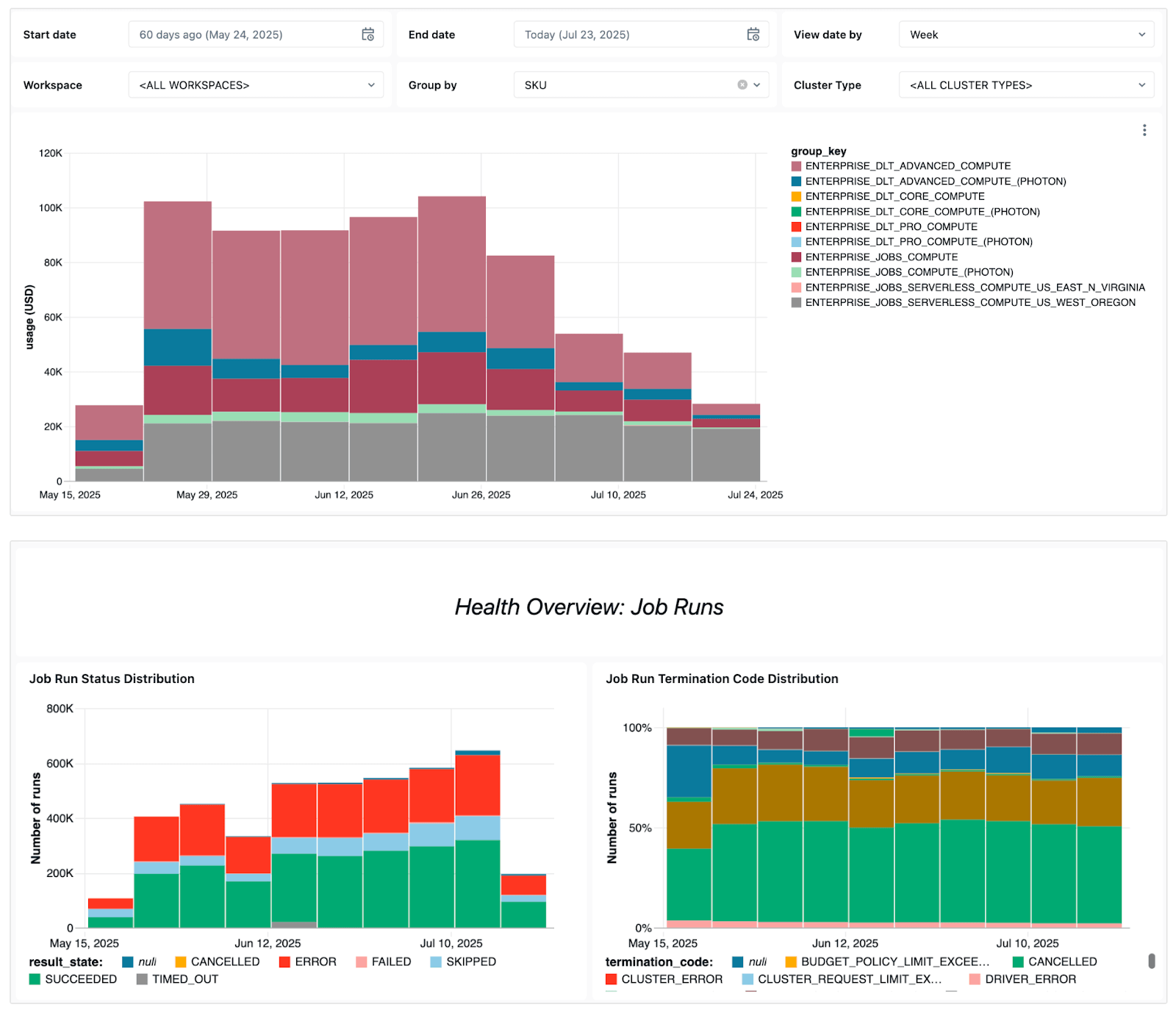
La dashboard mostra diversi segnali operativi chiave, tra cui:
- Andamento degli errori - per consentirti di vedere quali job falliscono più spesso, le tendenze generali degli errori e i messaggi di errore comuni.
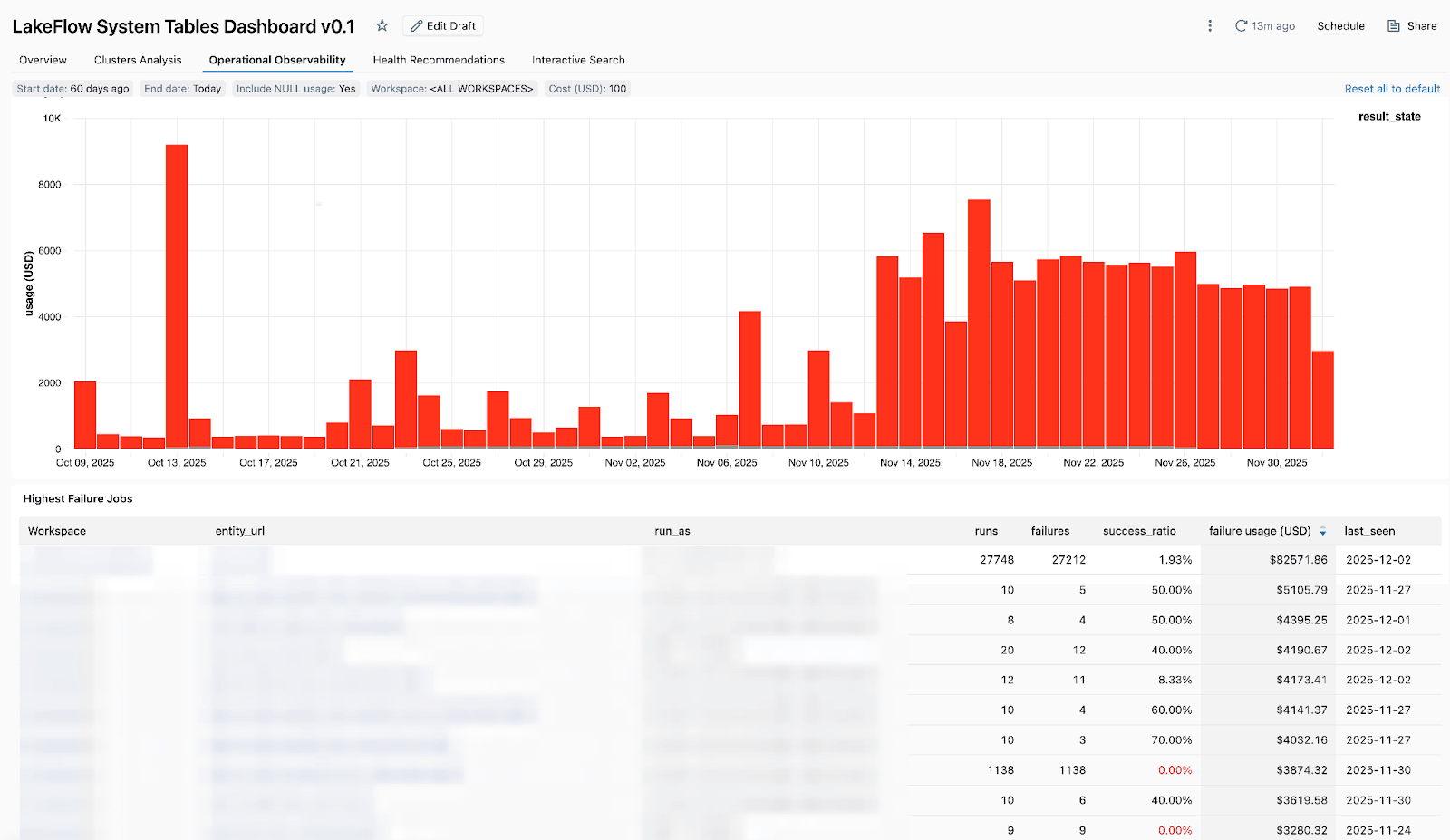
- Job a costo elevato: per poter identificare i job e le singole esecuzioni di job più costosi degli ultimi 30 giorni o nel tempo. La tabella seguente è ordinata in base ai job a più alto costo nel periodo selezionato e ne mostra l'andamento dei costi nel tempo.
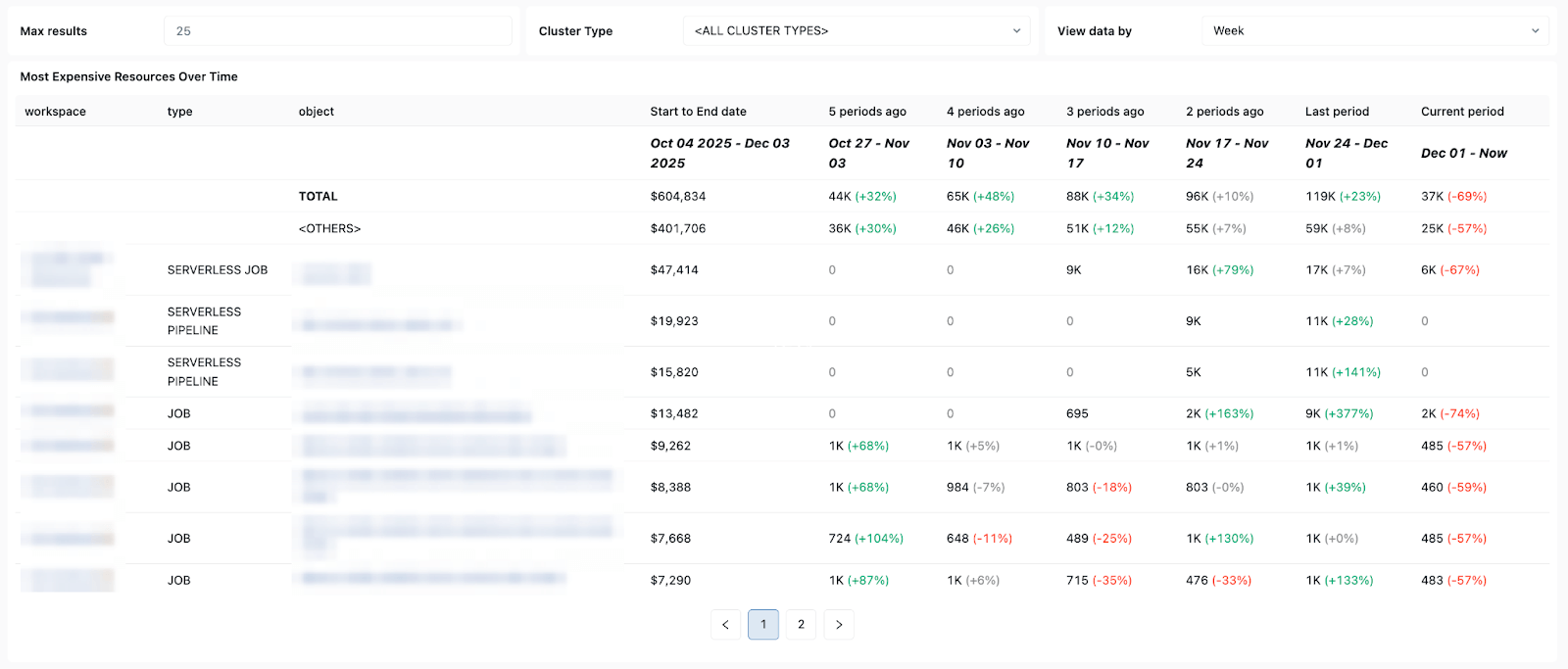
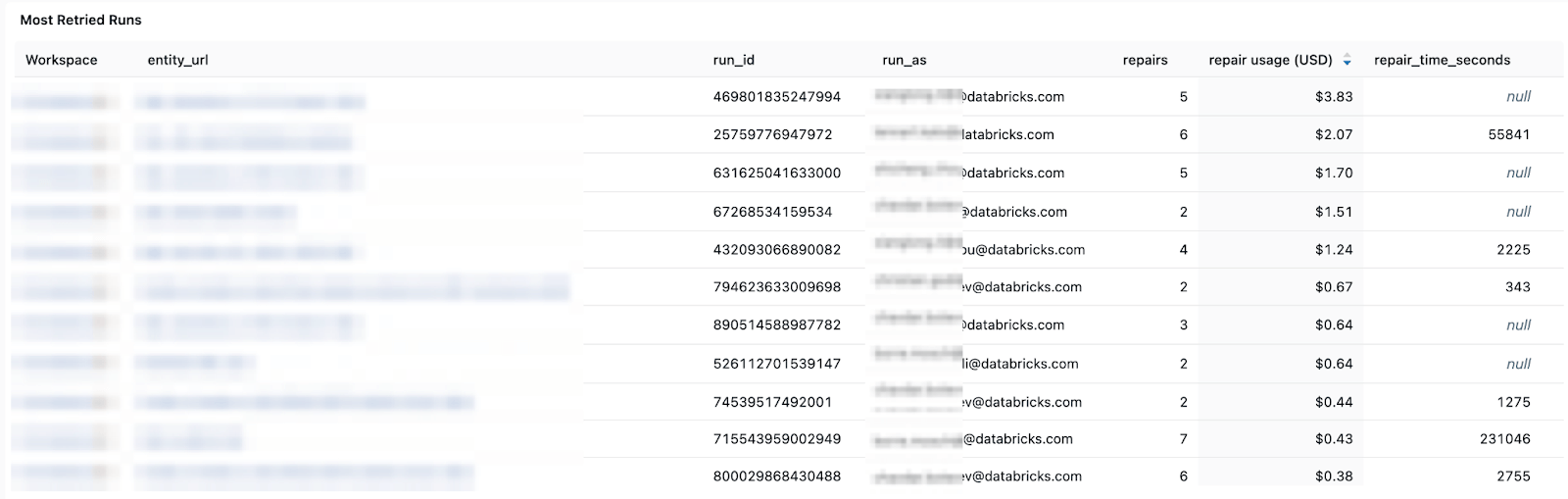
Schemi di costi e tentativi - per aiutarti a monitorare le tendenze dei costi e l'impatto dei tentativi o delle esecuzioni di riparazione sulla spesa totale.
- Approfondimenti sulla configurazione - consentono di verificare l'efficienza dei cluster, le regole sullo stato di salute, i timeout e le versioni di runtime per una corretta prassi operativa.
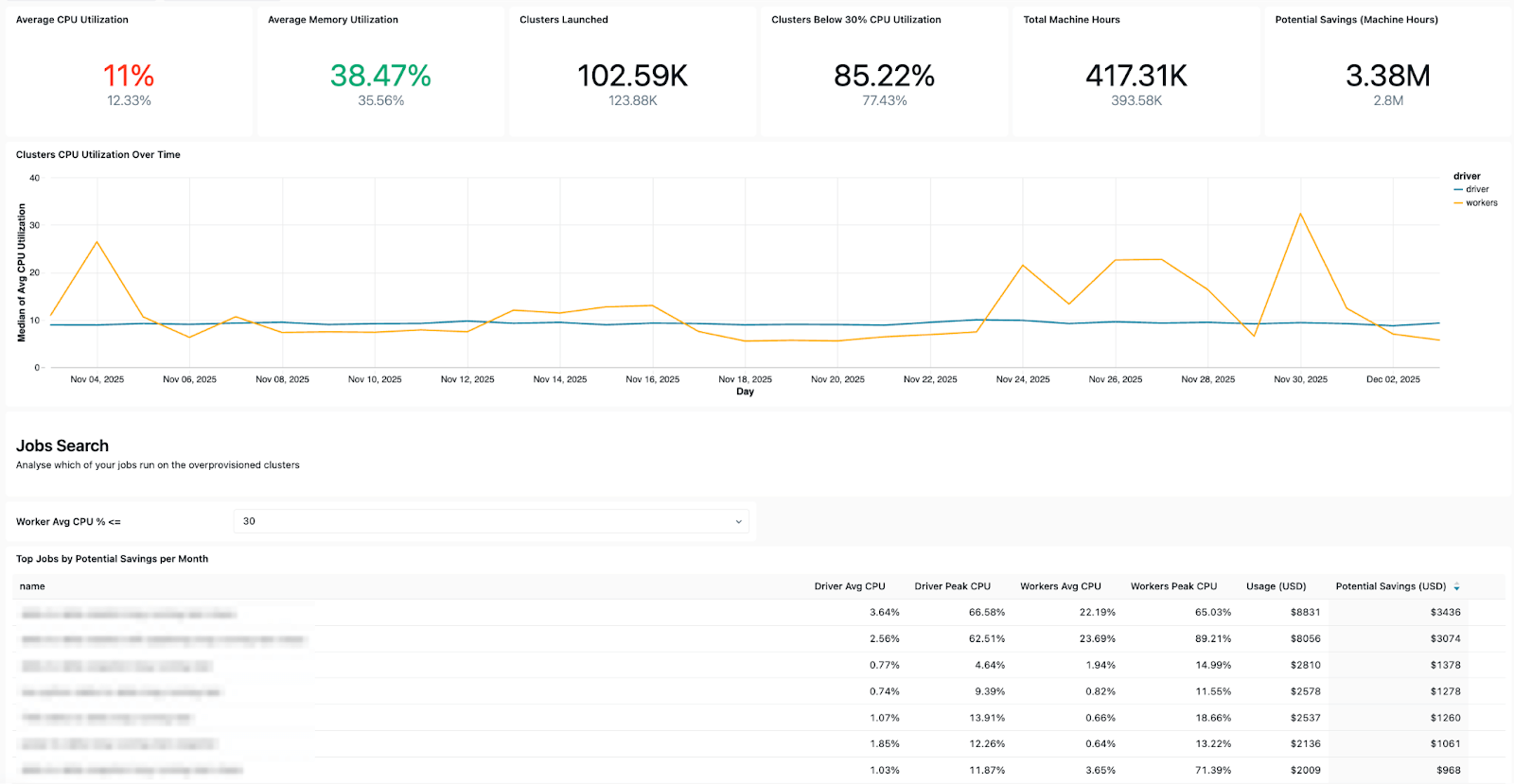
- Dettagli sulla proprietà, per trovare facilmente gli utenti "run-as" e i creatori di job e sapere chi contattare.
In breve, le tabelle di sistema di Databricks semplificano il monitoraggio, l'audit e la risoluzione dei problemi dei Job di Lakeflow in modo efficiente, su vasta Scale e tra Workspace diverse. Grazie a visualizzazioni chiare, semplici e accessibili dei tuoi Job e delle tue pipeline disponibili nel modello di template, ogni Data Engineer che utilizza Lakeflow può ottenere un'osservabilità avanzata e garantire costantemente pipeline pronte per la produzione, convenienti e affidabili.
Le tabelle di sistema trasformano i dati di telemetria della piattaforma in un asset interrogabile. Invece di unire i segnali provenienti da cinque strumenti diversi, scrivi SQL su uno schema unificato e ottieni risposte in pochi secondi.
Il tuo io delle 3 del mattino ti ringrazierà.
Per ulteriori informazioni sulle tabelle di sistema, consulta le seguenti risorse:
Non conosci Databricks? Prova Databricks gratuitamente oggi stesso!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.