Come l'architettura lakebase garantisce scritture Postgres 5 volte più veloci
Risolvere il collo di bottiglia strutturale delle prestazioni in Postgres gestito
di David Wein e Vlad Lazar
- Lakebase ora offre un throughput fino a 5 volte più veloce per i carichi di lavoro OLTP ad alta intensità di scrittura, un problema comune per le applicazioni Postgres su larga scala.
- L'architettura lakebase ci consente di scaricare attività critiche di ripristino da crash dal livello di calcolo all'archiviazione distribuita.
- Il campionamento in produzione mostra miglioramenti del throughput di scrittura di 4,5 volte su istanze di calcolo con 32 vCPU e una riduzione del 94% del traffico WAL, il tutto riducendo la latenza di coda di lettura di 2 volte senza compromettere la durabilità.
In una lakebase, il calcolo e lo storage sono separati per design. Sebbene questa separazione sia stata originariamente concepita per la flessibilità operativa, inclusi scaling, branching e ripristino istantaneo, essa sblocca anche un'enorme frontiera di prestazioni.
Disaccoppiando questi livelli, possiamo scaricare il lavoro dal tuo calcolo Postgres al nostro storage distribuito in modi strutturalmente impossibili nelle distribuzioni Postgres tradizionali e monolitiche. In questo post, esploreremo come abbiamo sfruttato questo vantaggio architetturale per eliminare un collo di bottiglia decennale di Postgres, migliorando il throughput di scrittura di Postgres di 5 volte, riducendo al contempo le latenze di coda di lettura di 2 volte e il traffico WAL del 94%.
Il costo nascosto della durabilità tradizionale di Postgres
Per capire come abbiamo ottenuto un miglioramento di 5 volte nelle prestazioni di Postgres gestito, dobbiamo esaminare come Postgres tradizionale gestisce la durabilità.
In Postgres, ogni modifica al database viene prima salvata in un log sequenziale (il Write-Ahead Log, o WAL) per garantire che i dati non vengano persi in caso di crash. Per mantenere rapidi i tempi di ripristino da crash, Postgres esegue periodicamente un evento di pulizia in background chiamato "checkpoint". A differenza di uno snapshot, un checkpoint è semplicemente un marcatore di tappa nel log. Durante un checkpoint, Postgres prende tutti i dati modificati attualmente in memoria (gestiti in blocchi da 8KB chiamati "pagine") e li scarica sul disco principale, fino a un punto specifico nel log. Se si verifica un crash, Postgres ripristina i tuoi dati partendo da quel marcatore di checkpoint e riproducendo i recenti log WAL sul disco.
Tuttavia, c'è un rischio: se il server si blocca esattamente mentre sta salvando una pagina da 8KB sul disco, la pagina potrebbe essere scritta solo parzialmente, risultando in una "pagina strappata" corrotta. Se Postgres tenta di riprodurre un piccolo aggiornamento del log su una pagina strappata, i dati vengono irrimediabilmente rovinati. Per risolvere questo problema, Postgres deve assicurarsi di non fare mai affidamento su un disco corrotto per il ripristino.
Lo fa utilizzando una "Full Page Write" (FPW). La primissima volta che una pagina viene modificata dopo un marcatore di checkpoint, Postgres non si limita a registrare la piccola modifica; copia l'intera pagina da 8KB nel WAL. Se si verifica un crash e la pagina del disco è strappata, Postgres ignora il disco rovinato, prende il backup intatto da 8KB dal WAL e lo usa come punto di partenza perfetto per riprodurre il resto dei log. Sebbene ciò garantisca la sicurezza assoluta, è costoso: nelle applicazioni con molte scritture, la registrazione di intere pagine da 8KB può gonfiare il volume del log fino a 15 volte, diventando spesso il più grande collo di bottiglia delle prestazioni del sistema.
La soluzione lakebase: eliminare il rischio di pagine strappate
Nell'architettura lakebase, il tuo calcolo è stateless. Non si affida a una directory di dati locale. Invece, trasmette il WAL a un quorum di safekeepers basato su Paxos.
Poiché non esiste una pagina su disco locale da strappare, la modalità di errore che FPW era stata progettata per prevenire semplicemente non esiste. Tuttavia, disattivare ingenuamente FPW crea un problema secondario: le prestazioni di lettura. Senza quelle immagini periodiche di pagina intera nel log, il livello di storage dovrebbe riprodurre una catena infinitamente lunga di piccole delta per ricostruire una pagina per una richiesta di lettura. Quella che una volta era una riproduzione limitata O(frequenza di checkpoint) diventa una catena illimitata, portando a un picco nella latenza di lettura e nel consumo di risorse.
Innovazione: pushdown della generazione di immagini allo storage distribuito
Abbiamo risolto questo problema spostando l'intelligenza dal nodo di calcolo al livello di storage. Chiamiamo questo processo pushdown della generazione di immagini.
Quando il calcolo Postgres richiede una pagina dallo storage, il pageserver (un componente del sistema di storage distribuito Lakebase) la ricostruisce trovando l'immagine materializzata più recente di quella pagina e riproducendo eventuali delta WAL su di essa. Le immagini di pagina intera che il calcolo usava incorporare nel WAL fungevano anche da punti di reset periodici in quella catena di delta, mantenendo naturalmente la catena ragionevolmente limitata e le letture veloci. Per un trattamento più approfondito di questo meccanismo, vedi Deep dive into Neon storage engine.
Con le scritture di pagina intera disabilitate, quei punti di reset scompaiono. Senza intelligenza aggiuntiva nel sistema di storage distribuito, una pagina frequentemente aggiornata potrebbe accumulare una lunga catena di piccole delta senza un'immagine intermedia. Il risultato sarebbe un aumento indesiderabile della latenza di lettura e del consumo di risorse, poiché il pageserver riprodurrebbe l'intera catena per servire una lettura, aumentando la latenza e il consumo di risorse.
Per evitare questo problema, abbiamo spostato la responsabilità della generazione delle immagini dal flusso WAL del calcolo al livello di storage, preservando il comportamento di lettura limitato dello storage e eliminando al contempo l'overhead del WAL sul calcolo. Il pageserver ora genera immagini di pagina intera quando una pagina ha accumulato più record delta di una soglia configurata senza un'immagine intermedia. Questo è un approccio naturalmente migliore perché la decisione di generare una nuova immagine si basa sul numero effettivo di modifiche a una pagina piuttosto che sul processo di checkpoint di Postgres non correlato.
Ecco perché questo è significativamente migliore per le prestazioni:
- Efficienza della rete: Il calcolo invia solo i delta compatti, che sono le modifiche effettive, portando a una riduzione del traffico del 94% nei nostri benchmark.
- Scalabilità: Il lavoro viene spostato dal singolo writer Postgres al livello di storage distribuito e scalabile indipendentemente. La generazione di immagini per un branch di progetto è ora condivisa tra più pageserver in background.
- Letture ottimali: La generazione delle immagini si basa ora sulle modifiche effettive a una pagina piuttosto che sul processo di checkpoint di Postgres non correlato.
Quantificare l'impatto: dal laboratorio alla produzione
Abbiamo testato questa ottimizzazione utilizzando HammerDB TPROC-C (un benchmark OLTP derivato da TPC-C) e abbiamo validato i risultati su carichi di lavoro di produzione reali.
1. Scaling del calcolo serverless
Il throughput è misurato in nuovi ordini al minuto (NOPM). I guadagni scalano drasticamente con la dimensione dell'istanza di calcolo:
Dimensione del calcolo | Prima (NOPM) | Dopo (NOPM) | Guadagno di throughput |
4-vCPU | 78,876 | 94,891 | 20% |
16-vCPU | 95,832 | 269,189 | 2.8x |
32-vCPU | 95,686 | 439,300 | 4.5x+ |

Su un calcolo a 32 vCPU, il miglioramento ha superato il 450%.
Con le immagini di pagina intera generate sul calcolo, ogni transazione genera in media 58Kb di WAL. Con la generazione di immagini spinta verso il basso, questo valore scende a meno di 4Kb – una riduzione del 94%. Il miglioramento del throughput ne consegue direttamente: meno WAL significa meno contesa sul percorso di scrittura, meno larghezza di banda di rete consumata e meno lavoro per il livello di storage da ingerire.

Rimuovendo il collo di bottiglia FPW di Postgres, abbiamo permesso al throughput di scalare linearmente con le risorse di calcolo. Questo è qualcosa che Postgres monolitico fatica a fare sotto un carico di scrittura pesante.
2. Validazione in produzione nel mondo reale
In un ambiente di produzione per un progetto di alto profilo a 56 vCPU, l'abilitazione del pushdown delle immagini ha ridotto la generazione di WAL a regime da 30 MB/s a solo 1 MB/s.

Questa diminuzione del volume è correlata direttamente a un aumento del throughput delle transazioni durante i picchi giornalieri.
Questo non ha solo aiutato le scritture. Ottimizzando le catene delta, il numero di record WAL che devono essere applicati per ogni lettura è diminuito significativamente. Abbiamo riscontrato una diminuzione delle latenze di lettura p99 dal 30% al 50% e delle latenze p50 di circa il 30%.

Allargando la prospettiva, a livello regionale, dopo l'abilitazione abbiamo visto la quantità totale di WAL generata dai calcoli diminuire fino a 4 volte. La latenza p99 delle letture dal motore di storage è migliorata fino a 3 volte ed è diventata molto più stabile.

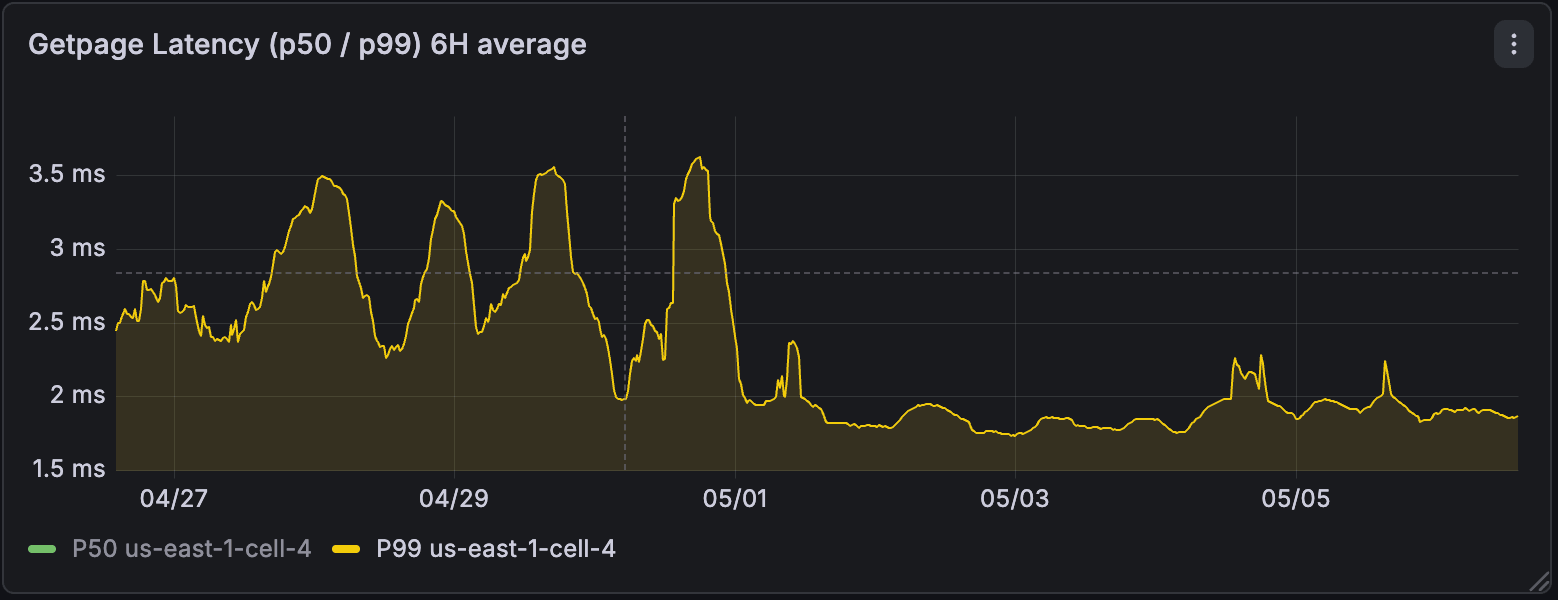
3. Tabelle sincronizzate Lakebase
Per le tabelle sincronizzate ad alta intensità di dati, l'impatto è stato immediato. Un cliente ha visto il throughput di ingestione passare da 17.000 righe al secondo a 62.000 righe al secondo, un aumento di 3 volte, semplicemente abilitando il pushdown delle immagini.
Implementazione senza interruzioni: prestazioni senza interruzioni
Dalla fine di marzo, abbiamo implementato questa soluzione su tutta la nostra flotta. Ora è attiva per tutti i database Lakebase Serverless e Neon a livello globale.
La modifica è stata applicata ai calcoli in esecuzione tramite il nostro piano di controllo e il sistema di storage, che hanno coordinato la transizione automaticamente. Ciò è stato ottenuto utilizzando il meccanismo di record WAL XLOG_FPW_CHANGE di Postgres esistente, il che significa che non sono stati necessari riavvii o interruzioni per i nostri clienti.
Cosa c'è dopo per le prestazioni di Postgres gestito?
L'architettura Lakebase è stata costruita per la flessibilità, ma è stata progettata per le prestazioni. Il pushdown delle scritture di pagina intera fa parte di uno sforzo sistematico per raccogliere i benefici della separazione tra storage e calcolo.
Proprio come abbiamo introdotto il pre-riscaldamento della cache per il patching a tempo di inattività zero, stiamo continuando a spostare le attività più impegnative dalle vostre transazioni al nostro stack di storage in background scalabile. La "tassa" di scrittura di Postgres è ufficialmente un ricordo del passato.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.