Patching a Zero-Downtime in Lakebase Parte 1: Prewarming
La prima di diverse funzionalità che rendono invisibili i riavvii del calcolo
di Hans Norheim
- La manutenzione pianificata causa più interruzioni dei guasti non pianificati per la maggior parte dei database, poiché le patch avvengono più frequentemente dei guasti hardware. L'obiettivo è rendere gli aggiornamenti di versione e le patch di sicurezza completamente impercettibili.
- Il problema principale dei riavvii del database è che le cache in memoria vengono cancellate, causando un degrado della produttività fino al 70% mentre i dati vengono ricaricati dallo storage. Sotto carico di lavoro elevato, questo può trasformarsi da un problema di prestazioni a un problema di disponibilità.
- Lakebase affronta questo problema avviando un nuovo nodo di calcolo in background prima di un riavvio pianificato, pre-riscaldando la sua cache utilizzando l'elenco delle pagine della primaria attuale e lo stream WAL, quindi promuovendolo a primaria senza costi aggiuntivi o overhead di replica.
Garantire che i database dei clienti siano sempre disponibili è una delle cose più importanti che facciamo in Lakebase. Abbiamo progettato il sistema con ridondanza a ogni livello, effettuando automaticamente il failover e il recupero del tuo database in caso di guasti hardware o software.
In un sistema su larga scala, tali guasti non pianificati sono un'aspettativa statistica, ma per un singolo database non sono così frequenti. Per un singolo database, la manutenzione pianificata tende a causare più interruzioni del carico di lavoro. Dopotutto, un tipico database viene aggiornato più frequentemente di quanto subisca un guasto hardware.
Oggi, quasi tutti i provider di database operano con finestre di manutenzione: periodi in cui il tuo database interrompe tutte le connessioni attive e viene aggiornato e riavviato in un processo che può richiedere da pochi secondi a minuti. Sebbene Lakebase ti consenta di programmare gli aggiornamenti in un momento ottimale per te, si tratta comunque di una breve interruzione quando si verifica.
Pensiamo di poter fare di meglio. Questo post del blog è il primo di una serie su come stiamo sfruttando l'architettura lakebase per eliminare completamente l'impatto della manutenzione pianificata. Il nostro obiettivo: rendere gli aggiornamenti di versione e le patch di sicurezza completamente impercettibili.
In questo post, tratteremo il prewarming: una tecnica che previene qualsiasi degrado delle prestazioni che segue un riavvio del database. Nei post futuri, discuteremo i miglioramenti al processo di failover stesso e ottimizzazioni aggiuntive che ci avvicinano al vero patching a zero downtime.
Il Problema dei Riavvii a Freddo
La sfida nel riavviare PostgreSQL è che le cache in memoria (in particolare la buffer cache e la local file cache) vengono perse. Anche se il database torna online molto rapidamente (1 secondo @ P99), il carico di lavoro potrebbe subire un rallentamento nei primi minuti dopo il riavvio – abbiamo visto una riduzione di circa il 70% nel pgbench TPS. Ciò è dovuto a un basso rapporto di cache hit mentre i dati vengono letti nuovamente dallo storage e la cache si riscalda. Sebbene questo possa sembrare solo un problema di prestazioni, può essere un problema di disponibilità se il rallentamento è così grave che il database non riesce a tenere il passo con il carico di lavoro e si verificano timeout.
Esistono tecniche per affrontare questo problema in Postgres: pg_prewarm può essere utilizzato per riscaldare le buffer cache. Tuttavia, questo viene eseguito dopo un riavvio, quando il carico di lavoro è già compromesso. Lo streaming di replica può essere utilizzato per impostare una replica, che può essere pre-riscaldata prima di effettuare il failover su di essa (promuovendola a primaria). Tuttavia, ciò richiede la creazione di una replica completa e un'attenta orchestrazione del pre-riscaldamento prima del failover.
Prewarming sull'Architettura Lakebase
Nell'architettura lakebase, combiniamo nodi di calcolo stateless ed elastici con storage disaggregato e condiviso. I nodi di calcolo impiegano cache locali per offrire prestazioni massime senza sacrificare le proprietà serverless. Sebbene la cache affronti gli stessi problemi di cold-start descritti sopra, abbiamo più opzioni con l'architettura Lakebase.
Poiché le repliche di calcolo Postgres di Lakebase sono stateless, possiamo avviarle e arrestarle su richiesta. Sfruttiamo questo e lo combiniamo con il pre-riscaldamento automatico sui riavvii pianificati per minimizzare l'impatto delle prestazioni sul carico di lavoro. Ecco come funziona:
- Diventa disponibile una nuova versione dell'immagine di calcolo Postgres di Lakebase. Ricevi una notifica e puoi programmare il riavvio per un momento che ti sia comodo.
- Poco prima dell'orario programmato, il nostro piano di controllo avvia in background un nuovo calcolo Postgres. Non lo vedi e non ti viene addebitato alcun costo. Il carico di lavoro della primaria attuale non viene influenzato.
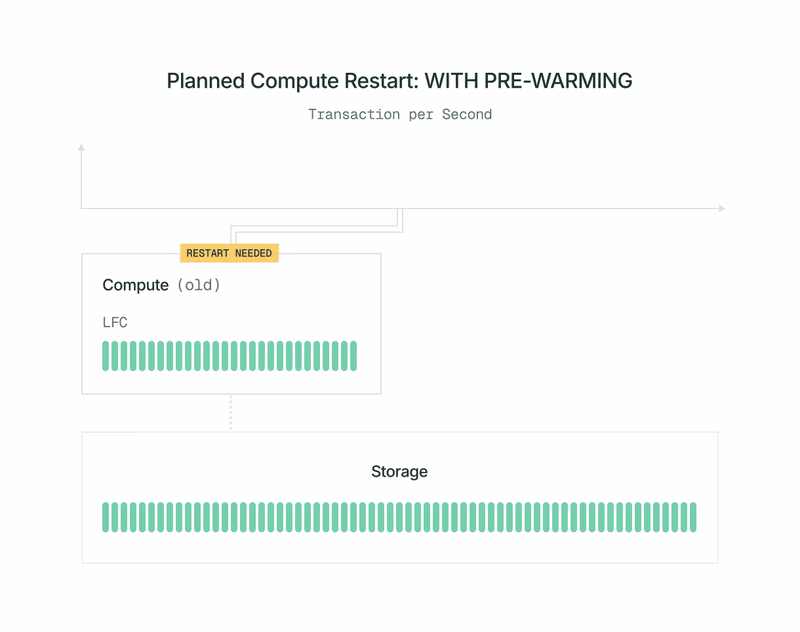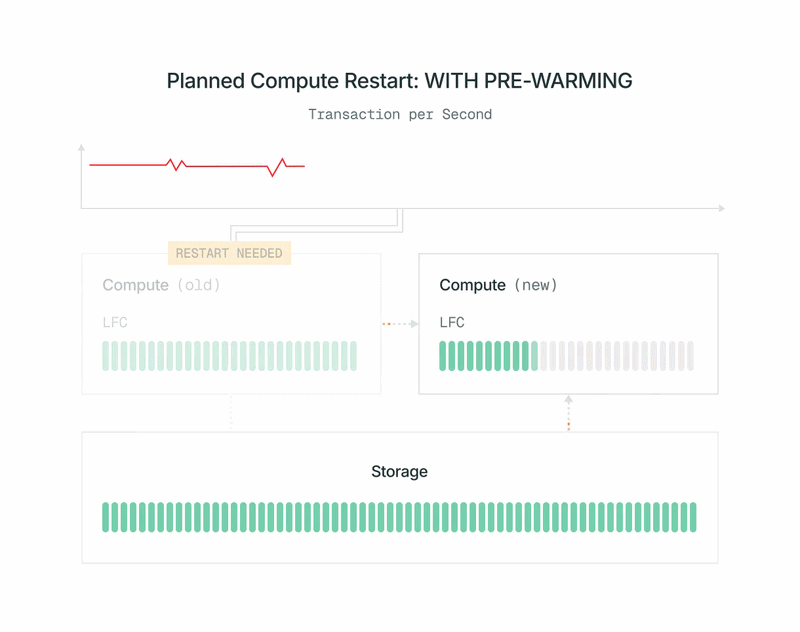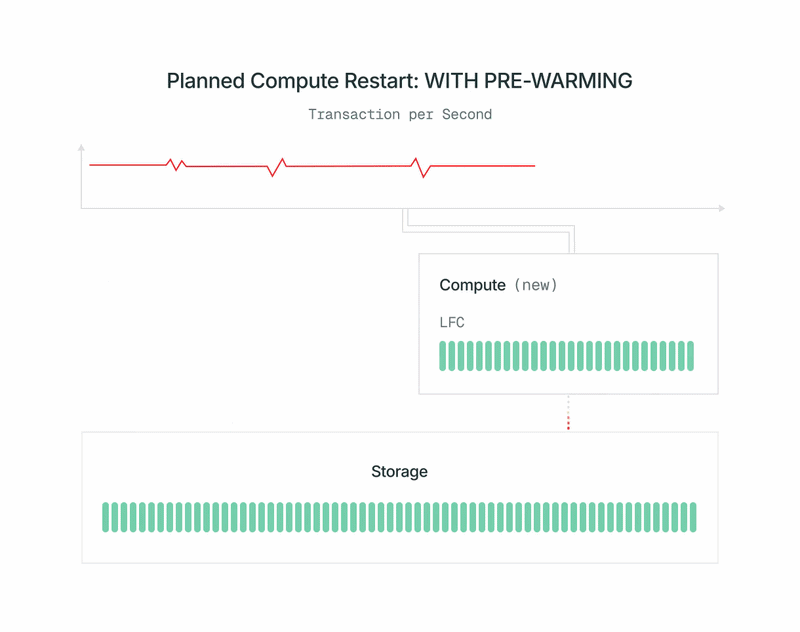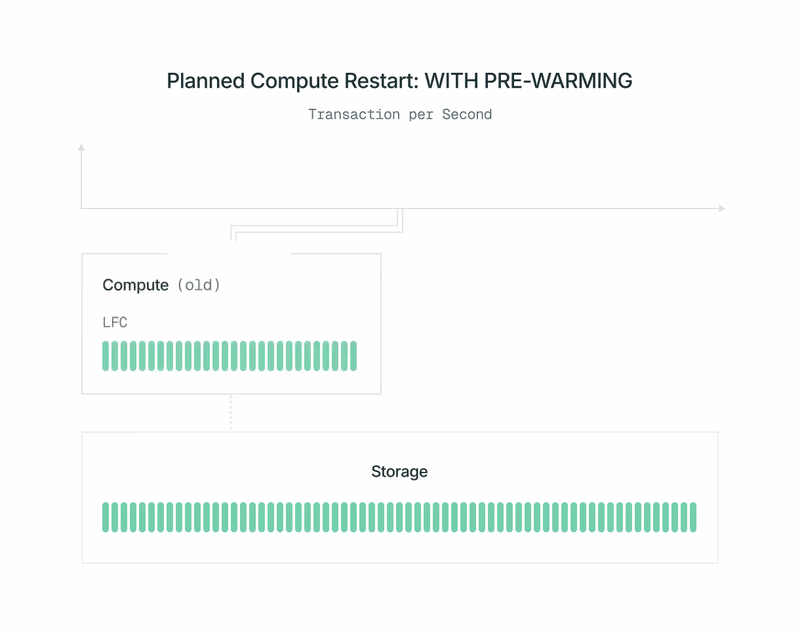
- Un elenco di pagine nella cache della primaria attuale viene inviato al nuovo calcolo. Il nuovo calcolo carica quelle pagine nella cache dal nostro livello di storage condiviso senza influire sulla primaria.
- Il nuovo calcolo si sottoscrive al WAL (write-ahead log) per mantenere aggiornata la sua cache. Per efficienza, a differenza di una normale replica Postgres, può ignorare tutti i record WAL che non influiscono sulla sua cache. Ottiene il WAL dai nostri Safekeepers, senza aggiungere ulteriore carico al calcolo primario.
- Al completamento del pre-riscaldamento, arrestiamo rapidamente la vecchia primaria, promuoviamo il nuovo calcolo a primaria e lo inseriamo. La promozione utilizza il pg_promote standard da OSS Postgres e non riavvia il server del database.
Prima:

Dopo:
Con l'architettura lakebase, ottieni questo senza costi aggiuntivi, senza pagare per repliche aggiuntive. Ad oggi, tutti i riavvii pianificati degli endpoint di lettura/scrittura vengono eseguiti in questo modo senza che tu debba fare nulla. Presto estenderemo questa funzionalità anche agli endpoint di sola lettura.
Risultati
Per misurare l'impatto delle cache fredde, abbiamo eseguito pgbench da 10 GB (fattore di scala 670) su un database riavviandolo – prima con il pre-riscaldamento abilitato, poi senza pre-riscaldamento. Il primo grafico mostra un carico di lavoro di sola lettura (pgbench “select only”), mentre il secondo mostra un carico di lavoro di lettura/scrittura (pgbench “simple update”).


In entrambi i casi, vediamo che la produttività recupera quasi istantaneamente con il pre-riscaldamento. Senza pre-riscaldamento, il recupero è molto più lento mentre la cache fredda si riscalda. La differenza è più marcata per il carico di lavoro di sola lettura perché il pre-riscaldamento migliora il rapporto di cache hit, il che aiuta le letture proporzionalmente più delle scritture.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.