Come MakeMyTrip ha ottenuto la personalizzazione in millisecondi su larga scala con Databricks
Scopri come la modalità in tempo reale fornisce raccomandazioni di viaggio istantanee e contesto per gli agenti AI
- Architettura di Streaming Unificata: MakeMyTrip ha superato i colli di bottiglia di latenza dell'ETL tradizionale adottando la modalità Real-Time (RTM) di Databricks, creando un'architettura Spark unificata senza la necessità di altri motori specializzati.
- Personalizzazione in Millisecondi: Elaborando ricerche di viaggiatori ad alto volume con un flusso di dati continuo, RTM ha consentito latenze P50 inferiori a 50 ms, determinando direttamente un aumento del 7% nei tassi di click-through degli utenti.
- Logica Unificata, Innovazione Più Rapida: Utilizzando un motore unificato, MakeMyTrip è in grado di passare senza problemi dall'elaborazione batch a quella in tempo reale senza riscrivere la logica di business. Ciò non solo elimina la complessità operativa, ma alimenta anche l'innovazione futura, rendendo facile fornire agli agenti di intelligenza artificiale generativa il contesto in tempo reale di cui hanno bisogno per un processo decisionale accurato.
Personalizzazione in tempo reale su larga scala
Ogni millisecondo conta quando i viaggiatori cercano hotel, voli o esperienze. In quanto agenzia di viaggi online più grande dell'India, MakeMyTrip compete sulla velocità in tempo reale e sulla pertinenza. Una delle sue funzionalità più importanti è "hotel cercati di recente": non appena gli utenti toccano la barra di ricerca, si aspettano un elenco in tempo reale e personalizzato dei loro interessi recenti, basato sulla loro interazione con il sistema.
Alla scala di MakeMyTrip, offrire tale esperienza richiede una latenza inferiore al secondo su una pipeline di produzione che serve milioni di utenti giornalieri, sia per le linee di business dei viaggi consumer che corporate. Implementando la Modalità Real-Time (RTM) di Databricks, il motore di esecuzione di nuova generazione in Apache Spark™ Structured Streaming, MakeMyTrip ha raggiunto con successo latenze a livello di millisecondi, mantenendo un'infrastruttura conveniente e riducendo la complessità ingegneristica.
La Sfida: Latenza ultra-bassa senza frammentazione architetturale
Il team dati di MakeMyTrip necessitava di una latenza inferiore al secondo per il flusso di lavoro "hotel cercati di recente" in tutte le linee di business. Alla loro scala, anche poche centinaia di millisecondi di ritardo creano attrito nel percorso utente, impattando direttamente i tassi di click-through.
La modalità micro-batch di Apache Spark introduceva limiti di latenza intrinseci che il team non poteva superare nonostante un'ampia ottimizzazione, fornendo costantemente una latenza da uno a due secondi, troppo lenta per le loro esigenze.
Successivamente, hanno valutato Apache Flink su circa 10 pipeline di streaming, che ha risolto i loro requisiti di latenza. Tuttavia, l'adozione di Apache Flink come secondo motore avrebbe introdotto significative sfide a lungo termine:
- Frammentazione architetturale: Mantenere motori separati per l'elaborazione in tempo reale e batch
- Logica di business duplicata: Le regole di business dovrebbero essere implementate e mantenute su due codebase
- Maggiore overhead operativo: Raddoppio dello sforzo di monitoraggio, debug e governance su più pipeline
- Rischi di coerenza: I risultati rischiano di divergere tra l'elaborazione batch e quella in tempo reale
- Costi infrastrutturali: Eseguire e ottimizzare due motori aumenta la spesa computazionale e l'onere di manutenzione
Perché la Modalità Real-Time: Latenza a millisecondi su un singolo stack Spark
Poiché MakeMyTrip non ha mai voluto un'architettura a doppio motore, Apache Flink non era un'opzione praticabile a lungo termine. Il team ha preso una decisione architetturale deliberata: aspettare che Apache Spark diventasse più veloce, piuttosto che frammentare lo stack. Pertanto, quando Apache Spark Structured Streaming ha introdotto RTM, MakeMyTrip è diventato il primo cliente ad adottarlo. RTM ha permesso loro di raggiungere latenze a livello di millisecondi su Apache Spark, soddisfacendo i requisiti in tempo reale senza introdurre un altro motore o dividere la piattaforma.
Mantenere due motori significa raddoppiare la complessità e il rischio di deriva della logica tra i calcoli batch e in tempo reale. Volevamo una singola fonte di verità, una pipeline basata su Spark, piuttosto che due motori da mantenere. La Modalità Real-Time ci ha fornito le prestazioni di cui avevamo bisogno con la semplicità che volevamo." —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
RTM fornisce un'elaborazione continua a bassa latenza attraverso tre innovazioni tecniche chiave che lavorano insieme per eliminare le fonti di latenza intrinseche nell'esecuzione micro-batch:
- Flusso dati continuo: I dati vengono elaborati man mano che arrivano invece di essere discretizzati in blocchi periodici.
- Pianificazione della pipeline: Le fasi vengono eseguite simultaneamente senza blocchi, consentendo ai task downstream di elaborare i dati immediatamente senza attendere il completamento delle fasi upstream.
- Shuffle in streaming: I dati vengono passati tra i task immediatamente, bypassando i colli di bottiglia di latenza degli shuffle tradizionali basati su disco.
Insieme, queste innovazioni consentono ad Apache Spark di raggiungere pipeline su scala millisecondo che in precedenza erano possibili solo con motori specializzati. Per saperne di più sul fondamento tecnico di RTM, leggi questo blog, “Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode."
L'Architettura: Una Pipeline Unificata in Tempo Reale
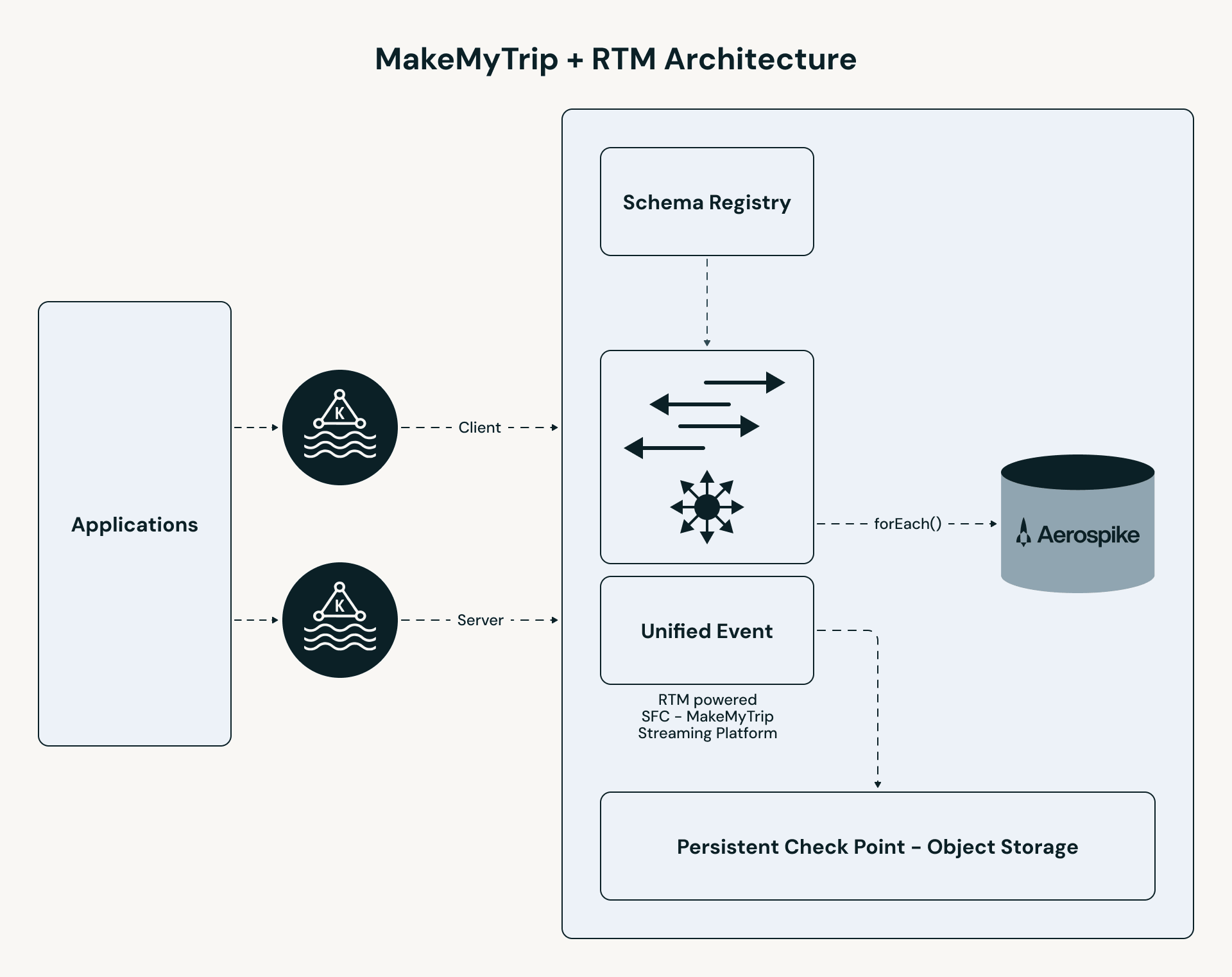
La pipeline di MakeMyTrip segue un percorso ad alte prestazioni:
- Ingestione unificata: Gli argomenti clickstream B2C e B2B vengono uniti in un singolo stream. Tutta la logica di personalizzazione — arricchimento, lookup stateful ed elaborazione eventi — viene applicata in modo coerente su entrambi i segmenti di utenti.
- Elaborazione RTM: Il motore Apache Spark utilizza la pianificazione concorrente e lo shuffle in streaming per elaborare eventi in millisecondi.
- Arricchimento stateful: La pipeline esegue un lookup a bassa latenza in Aerospike per recuperare gli "Ultimi N" hotel per ciascun utente.
- Servizio istantaneo: I risultati vengono inviati a una cache UI (Redis), consentendo all'app di servire risultati personalizzati in meno di 50 ms.
Configurazione di RTM: una singola riga di codice
Utilizzare RTM nella propria query di streaming non richiede la riscrittura della logica di business o la ristrutturazione delle pipeline. L'unica modifica al codice necessaria è impostare il tipo di trigger su RealTimeTrigger, come mostrato nel seguente snippet di codice:
L'unica considerazione infrastrutturale: gli slot dei task del cluster devono essere maggiori o uguali al numero totale di task attivi nelle fasi di sorgente e shuffle. Il team di MakeMyTrip ha analizzato le loro partizioni Kafka, le partizioni shuffle e la complessità della pipeline in anticipo per garantire una concorrenza sufficiente prima di andare in produzione.
Co-sviluppo di RTM per la Produzione
In quanto primo adottatore di RTM, MakeMyTrip ha lavorato direttamente con l'ingegneria Databricks per portare la pipeline alla prontezza produttiva. Diverse funzionalità hanno richiesto una stretta collaborazione tra i due team per costruire, ottimizzare e validare.
- Stream Union: Unire B2C e B2B in un'unica Pipeline
MakeMyTrip necessitava di unificare due stream Kafka separati — clickstream consumer B2C e viaggi corporate B2B — in un'unica pipeline RTM in modo che la stessa logica di personalizzazione potesse essere applicata in modo coerente su entrambi i segmenti di utenti. Dopo un mese di stretta collaborazione con l'ingegneria Databricks, la funzionalità è stata creata e rilasciata. Il risultato è stata un'unica pipeline in cui tutta la logica di business risiede in un unico posto, senza rischio di divergenza tra i segmenti di utenti. - Task Multiplexing: Più Partizioni, Meno Core
Il modello predefinito di RTM assegna uno slot/core per partizione Kafka. Con 64 partizioni nella configurazione di produzione di MakeMyTrip, ciò si traduce in 64 slot/core, proibitivo in termini di costi alla loro scala. Per affrontare questo problema, il team Databricks ha introdotto l'opzione MaxPartitions per Kafka, che consente a più partizioni di essere gestite da un singolo core. Ciò ha fornito a MakeMyTrip la leva necessaria per ridurre i costi infrastrutturali senza compromettere il throughput. - Pipeline Hardening: Checkpointing, Backpressure e Fault Tolerance
Il team ha affrontato una serie di sfide operative specifiche per carichi di lavoro a basso throughput e alta latenza: ottimizzazione della frequenza e della conservazione del checkpoint, gestione dei timeout e gestione della backpressure durante i picchi di volume di clickstream. Scalando a 64 partizioni Kafka, abilitando la backpressure e limitando il MaxRatePerPartition a 500 eventi, il team ha ottimizzato throughput e stabilità. Attraverso questa ottimizzazione iterativa delle configurazioni batch, del partizionamento e del comportamento di retry, sono arrivati a una pipeline stabile e di livello produttivo che serve milioni di utenti al giorno.
Risultati
RTM ha consentito la personalizzazione istantanea e una migliore reattività, un maggiore coinvolgimento misurato tramite tassi di click-through e una semplicità operativa di un singolo motore unificato. Le metriche chiave sono mostrate di seguito.
Apache Spark come motore in tempo reale
Il deployment di MakeMyTrip dimostra che RTM su Spark offre la latenza estremamente bassa richiesta dalle tue applicazioni in tempo reale. Poiché RTM è basato sugli stessi familiari API Spark, puoi usare la stessa logica di business sia per pipeline batch che in tempo reale. Non avrai più bisogno di mantenere una seconda piattaforma o un codebase separato per l'elaborazione in tempo reale, ma potrai semplicemente abilitare RTM su Spark con una singola riga di codice.
La modalità in tempo reale ci ha permesso di comprimere la nostra infrastruttura e offrire esperienze in tempo reale senza gestire più motori di streaming. Mentre ci muoviamo nell'era degli agenti AI, guidarli efficacemente richiede la costruzione di un contesto in tempo reale da flussi di dati. Stiamo sperimentando con Spark RTM per fornire ai nostri agenti il contesto più ricco e recente necessario per prendere le migliori decisioni possibili. —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Iniziare con la modalità in tempo reale
Per saperne di più sulla modalità in tempo reale, guarda questo video on-demand su come iniziare o consulta la documentazione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.