Superare la barriera dei microbatch: l'architettura della Mode in tempo reale di Apache Spark
Come abbiamo evoluto Spark per gestire ETL a throughput elevato e carichi di lavoro di streaming a bassissima latenza
- La Mode in tempo reale di Apache Structured Streaming unifica ETL a throughput elevato e carichi di lavoro operativi con latenza nell'ordine dei millisecondi in un unico motore.
- Approfondimento del modello di esecuzione ibrido, con descrizione dettagliata delle fasi di elaborazione concorrente e degli operatori non bloccanti che offrono latenze nell'ordine dei millisecondi.
- I clienti possono ora ottenere una reattività inferiore a 100 ms per applicazioni a latenza ultra-bassa, come il rilevamento di frodi in tempo reale.
Con il lancio della modalità in tempo reale (RTM) in Apache Spark 4.1, Structured Streaming ora offre una latenza a livello di millisecondi. In un recente post su un blog, abbiamo mostrato come RTM possa superare Flink per molti carichi di lavoro di feature engineering a bassa latenza (vedi sotto).
In questo blog, discuteremo le modifiche architetturali che hanno permesso a Structured Streaming di supportare sia carichi di lavoro ETL a throughput elevato sia carichi di lavoro a latenza ultra-bassa.
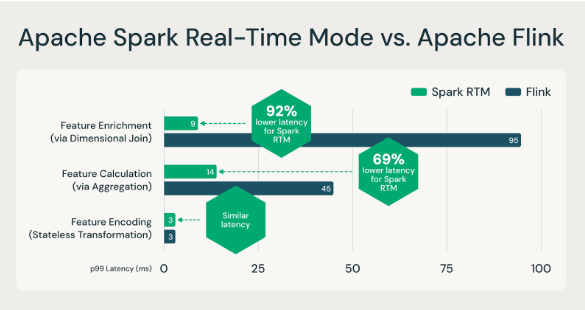
Apache Spark RTM è più veloce di Flink per i casi d'uso di feature ingegneria.
Il dilemma tra throughput e latenza
Fino ad ora, la scelta di un motore di streaming significava scendere a compromessi, scegliendo sistemi come Apache Spark per carichi di lavoro ETL ad alta throughput, o sistemi come Apache Flink per carichi di lavoro a bassa latenza. I due sistemi hanno semantica e caratteristiche prestazionali molto diverse. Tutto ciò cambia con RTM in Structured Streaming. Con l'introduzione di RTM, Apache Spark è ora in grado di gestire casi d'uso sia ad alto throughput che a latenza ultra-bassa. Ciò significa che ora è possibile scegliere un unico motore senza dover affrontare una nuova curva di apprendimento ed evitare di gestire due sistemi completamente diversi.
L'architettura a micro-batch offre un throughput elevato
Spark Structured Streaming utilizza un'architettura a micro-batch: il sistema di streaming riceve i dati in ingresso e li divide in batch discreti chiamati epoche, in base alla disponibilità dei dati e alle configurazioni della dimensione massima dei batch. Il motore Spark applica la logica di business attraverso trasformazioni come proiezione, filtro e aggregazione. I risultati vengono restituiti come un continuo Stream di batch. Structured Streaming eccelle nell'elaborazione a throughput elevato grazie a questa architettura a micro-batch: poiché più record vengono elaborati insieme, gli overhead fissi vengono ammortizzati e l'esecuzione vettorizzata può migliorare ulteriormente il throughput. Questi batch vengono eseguiti in parallelo, mantenendo al contempo un utilizzo elevato dell'hardware. La modalità a micro-batch alloca dinamicamente gli slot delle attività su più stream, il che contribuisce ulteriormente a un'elevata utilizzazione e a un alto throughput. L'innovazione fondamentale di Spark della tolleranza ai guasti basata sul lineage garantisce che questi stream vengano elaborati con solide garanzie exactly-once.
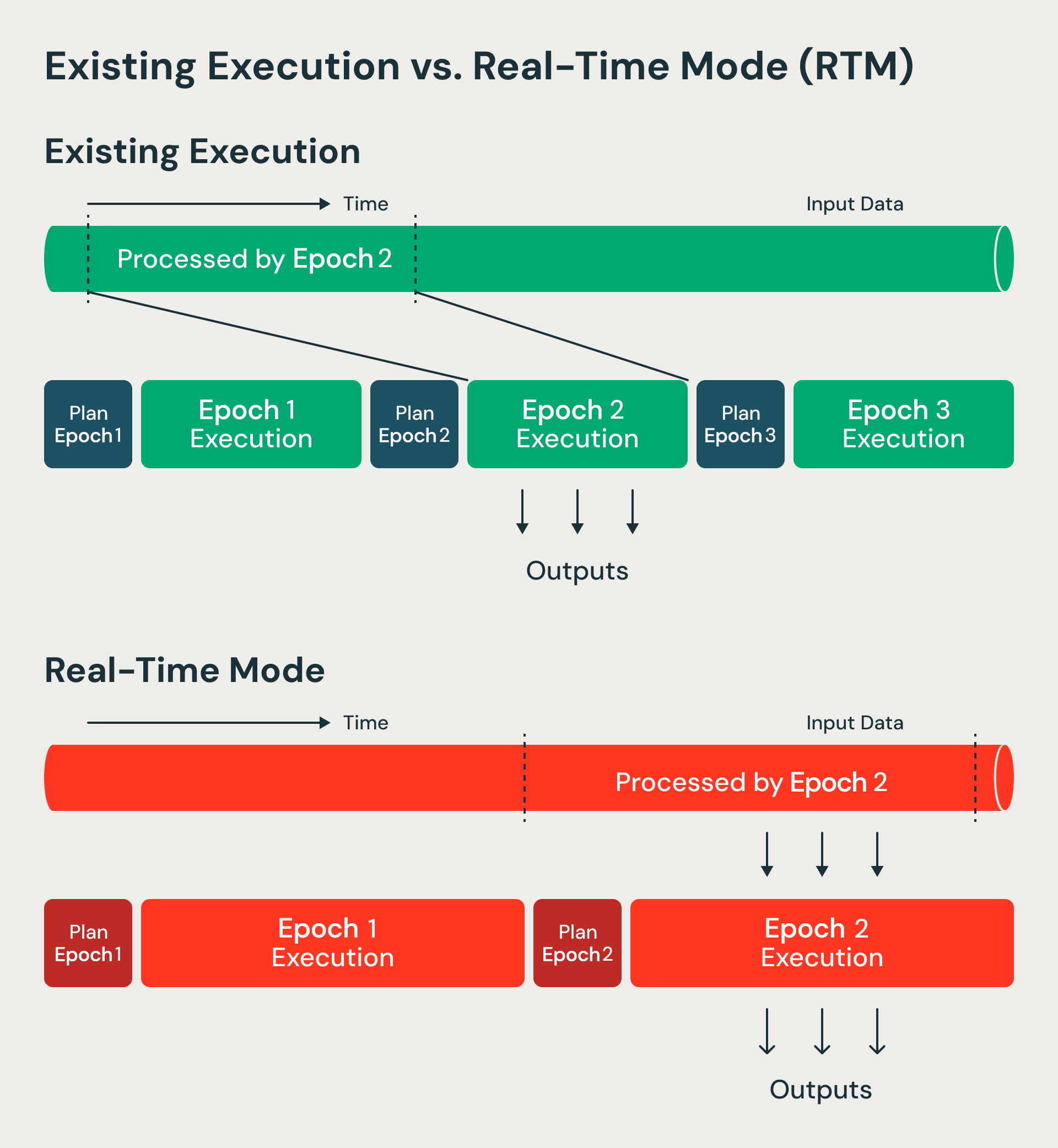
La modalità RTM elabora i dati in modo non bloccante rispetto alla modalità microbatch.
Infilare l'ago della bassa latenza
Sebbene Structured Streaming sia molto efficace nella gestione di carichi di lavoro di ETL e acquisizione a livello di secondi, molti casi d'uso operativi richiedono una latenza a livello di millisecondi. Il rilevamento di frodi nelle transazioni finanziarie, gli approfondimenti in tempo reale nel settore industriale dei viaggi o l'analisi dei dati di telemetria dei veicoli connessi sono tutti esempi in cui i clienti necessitano di risposte in millisecondi.
Sfida architetturale: perché i batch più piccoli non funzionano
La soluzione più ovvia potrebbe sembrare semplice: basta ridurre la dimensione dei batch. Se elaboriamo un record alla volta, dovremmo ottenere prestazioni in tempo reale. Sfortunatamente, non è così semplice.
Ogni micro-batch in Structured Streaming comporta costi fissi che dominano il tempo di esecuzione durante l'elaborazione di piccole quantità di dati. Il sistema scrive i file di log in un'archiviazione a oggetti durevole prima e dopo l'esecuzione di ogni micro-batch. Inoltre, anche gli aggiornamenti di stato per ogni query stateful devono essere caricati nell'archiviazione a oggetti alla fine di un micro-batch. Si tratta di passaggi critici per garantire la semantica di coerenza, ma possono aggiungere centinaia di millisecondi, se non secondi, al tempo di esecuzione. Anche se nascondiamo alcune di queste latenze, la latenza della pianificazione di ogni batch, l'overhead di pianificazione logica e fisica, la serializzazione dei task e lo scheduling sono difficili da ridurre. Come si può immaginare, la riduzione delle dimensioni dei batch raggiunge rapidamente i suoi limiti. La figura seguente mostra che quando i micro-batch diventano troppo piccoli (la barra più a sinistra), i costi fissi di elaborazione dei micro-batch dominano l'esecuzione e aumentano la latenza end-to-end.
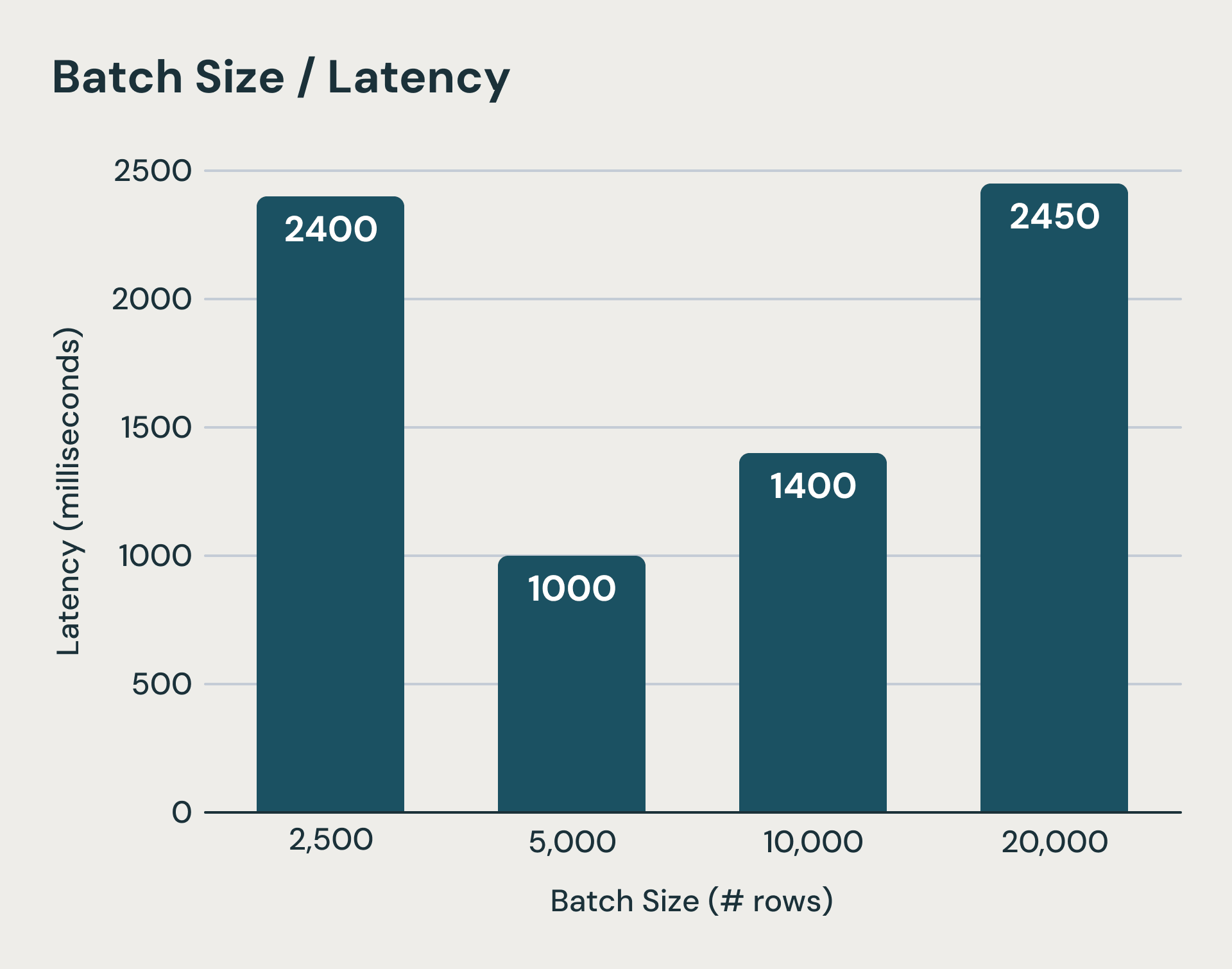
Oltre una certa threshold, batch inferiori possono aumentare la latenza a causa degli overhead fissi
Questo ci ha posto di fronte a una sfida architetturale: vogliamo mantenere i vantaggi in termini di costi e tolleranza ai guasti dell'architettura a micro-batch, ottenendo al contempo la bassa latenza che ci si aspetta da modelli che elaborano un record alla volta (come Apache Storm e Apache Flink). La nostra intuizione chiave è che possiamo far evolvere l'architettura a micro-batch per supportare carichi di lavoro in tempo reale. Abbiamo continuato a utilizzare molte delle funzionalità principali dell'architettura a micro-batch, come il checkpointing per la tolleranza ai guasti. Tuttavia, abbiamo eliminato i passaggi in cui i dati attendevano, causando un'elevata latenza. Illustriamo queste modifiche di seguito.
La nostra soluzione: un modello di esecuzione ibrido
Ecco come abbiamo migliorato la latenza di Structured Streaming:
1. Epoche di durata più lunga con flusso di dati continuo
La modalità a micro-batch elabora batch di dati chiamati epoche. I confini dell'epoca vengono decisi in anticipo utilizzando offset di start e fine. La modalità in tempo reale, invece, elabora epoche di durata più lunga ma modifica il modo in cui i dati fluiscono all'interno di ogni epoca. I dati ora scorrono in stream continuo attraverso diverse fasi e operatori senza blocchi. Poiché le epoche hanno una durata maggiore, gli overhead di checkpointing e delle barriere vengono ammortizzati. Ai confini dell'epoca, utilizziamo ancora le barriere per la gestione del ripristino e la riprogrammazione delle attività, mantenendo i vantaggi che rendono le architetture a micro-batch resilienti ed efficienti. Abbiamo essenzialmente evoluto il micro-batch in Structured Streaming in un intervallo di checkpoint.
2. Fasi di elaborazione simultanee
Nell'architettura di Structured Streaming, le fasi di elaborazione venivano eseguite in sequenza: i riduttori attendevano il completamento dei mappatori, creando ritardi non necessari. Abbiamo reso queste fasi simultanee nella modalità in tempo reale. Ora il driver di Spark richiede gli offset di origine e pianifica i mapper, ma i reducer possono iniziare a elaborare i file di shuffle non appena diventano disponibili, invece di attendere il completamento di tutti i mapper. Questa modifica riduce drasticamente la latenza end-to-end. La figura RTM sottostante mostra che le due fasi vengono eseguite contemporaneamente e che la fase 2 inizia a elaborare le righe non appena vengono elaborate dalla fase 1.
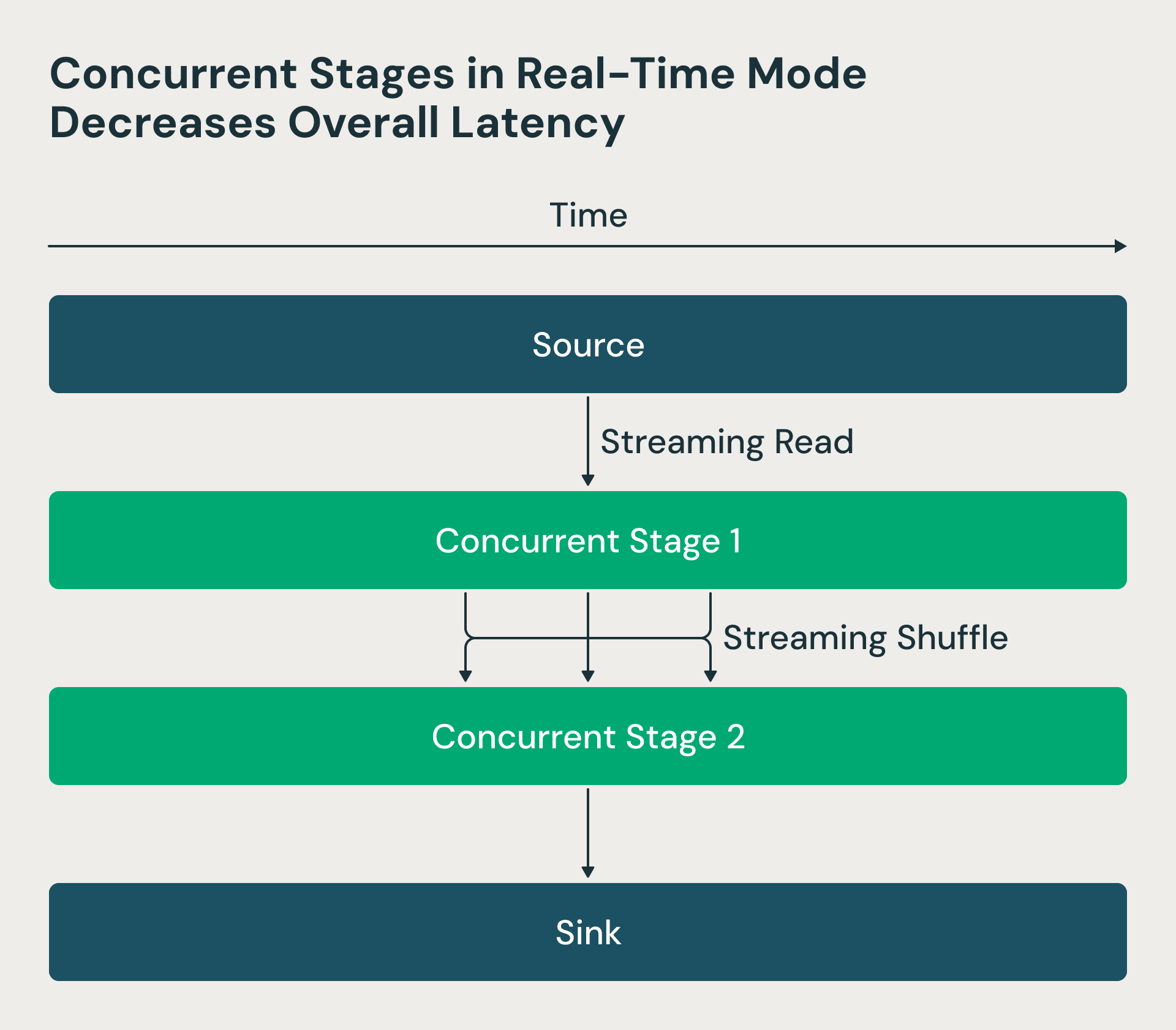
La modalità in tempo reale utilizza fasi concorrenti che riducono la latenza
3. Operatori non bloccanti
Abbiamo ristrutturato operatori chiave come lo shuffle, che erano stati progettati per l'esecuzione in batch con un buffering sostanziale. Nella modalità batch, un'aggregazione group-by memorizzerebbe nel buffer tutti i record, eseguirebbe la pre-aggregazione e restituirebbe i risultati solo alla fine. Per l'elaborazione in tempo reale, abbiamo modificato questi operatori per ridurre al minimo il buffering e produrre risultati in modo continuo, consentendo ai dati di fluire attraverso la pipeline senza attese non necessarie.
Riepilogo
Utilizzando epoche di durata più lunga con un flusso di dati continuo, fasi di elaborazione simultanee e operatori non bloccanti, abbiamo generalizzato il motore Apache Spark Structured Streaming per gestire casi d'uso di streaming sia ad alto throughput che a latenza ultra-bassa. Questo approccio ibrido ora elimina la necessità di scegliere tra motori di streaming. Gli utenti devono solo imparare a usare Apache Spark e non è necessario imparare a usare un altro framework dedicato allo streaming a latenza ultra-bassa.
La modalità in tempo reale è già in produzione presso Databricks e viene utilizzata da diversi clienti, da società finanziarie all'avanguardia a siti di viaggi. I nostri clienti sono in grado di ottenere una latenza di millisecondi per i loro casi d'uso.
Sebbene questo sia un importante passo avanti nelle capacità di Spark, continuiamo ad aggiungere nuove funzionalità di streaming. Se la tua organizzazione cerca soluzioni per carichi di lavoro in tempo reale, prova Apache Spark Structured Streaming!
Esplora le risorse tecniche
Per approfondire l'ingegneria alla base di RTM, guarda questa sessione on-demand tenuta dai nostri esperti in materia. Illustreranno la progettazione e l'implementazione della Mode in tempo reale.
Oppure consulta la guida tecnica al Mode in tempo reale per scoprire come iniziare. Troverai tutto il necessario per abilitare l'elaborazione in tempo reale per i tuoi carichi di lavoro di streaming.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.