Mode in tempo reale: streaming a bassissima latenza su Spark API senza un secondo motore
Elabora dati in streaming in millisecondi su Apache Spark, senza l'overhead di Apache Flink.
- Unificazione: scopri come la Modalità in tempo reale (RTM) in Apache Spark unifica l'addestramento offline e l'ingegneria delle funzionalità online a bassissima latenza in un unico motore ad alte prestazioni.
- Prestazioni: scopri la riprogettazione dell'architettura che consente una bassissima latenza in Spark, con un'analisi delle prestazioni che confronta Apache Spark RTM con Apache Flink.
- Semplicità & Adozione: RTM offre molti vantaggi operativi, tra cui una migrazione semplificata, un'API unificata per prevenire il "logic drift", e casi d'uso di clienti reali.
Da tempo, Apache Spark Structured Streaming alimenta pipeline di dati mission-critical su larga Scale, dallo streaming ETL alle analitiche e al machine learning. Tuttavia, con l'evoluzione dei casi d'uso operativi, i team hanno iniziato a chiedere qualcosa in più: latenze inferiori al secondo per applicazioni come il rilevamento di frodi, la personalizzazione, il rilevamento di anomalie, gli avvisi e il reporting in tempo reale.
Storicamente, per soddisfare questi requisiti di latenza ultra-bassa era necessario introdurre sistemi specializzati accanto a Spark. Con l'introduzione della Mode in Spark Structured Streaming in tempo reale, questo compromesso non è più necessario. In questo blog, esploriamo come Spark semplifichi l'architettura di streaming in tempo reale per casi d'uso comuni come l'ingegneria delle funzionalità, elimini la complessità operativa di lunga data e offra prestazioni leader del settore.
Lo streaming in tempo reale non richiede più l'esecuzione di più sistemi eterogenei.
La capacità di elaborare i dati e di agire su di essi in tempo reale è oggi un requisito fondamentale. Le applicazioni moderne, in particolare gli agenti IA, si basano su un continuo stream di contesto aggiornato per poter funzionare. Se i dati sottostanti sono incompleti o in ritardo, l'esperienza utente ne risente. Le prestazioni in tempo reale non sono necessarie solo per i casi d'uso tradizionali come il rilevamento delle frodi, ma per ogni interazione comune in cui un utente si aspetta risposte precise e aggiornate. In questo ambiente, la latenza ha un impatto diretto su ricavi, fiducia dei clienti e vantaggio competitivo.
Storicamente, i team di dati che sviluppano applicazioni di streaming in tempo reale hanno dovuto gestire due stack di elaborazione dati distinti: Apache Spark™ per le analitiche su larga scala e sistemi specializzati come Apache Flink® o Kafka Streams per applicazioni sensibili alla latenza con risposte inferiori al secondo. Questa frammentazione richiede ai team di mantenere codebase duplicate, gestire modelli di governance separati e assumere talenti specializzati per ottimizzare e mantenere infrastrutture specifiche per ogni motore.
Lanciata in anteprima pubblica ad agosto 2025, la Modalità in tempo reale (RTM) per Apache Spark Structured Streaming è progettata per eliminare questo attrito. Evolvendo radicalmente il motore di esecuzione di Spark, abbiamo eliminato la necessità di un secondo sistema. Questo cambiamento consente agli ingegneri di gestire l'intero spettro di casi d'uso, dall'ETL ad alta throughput alle app in tempo reale a bassa latenza, utilizzando la stessa Spark API che già conoscono. Ciò significa meno tempo per la gestione dell'infrastruttura e più tempo per concentrarsi sul caso d'uso aziendale.
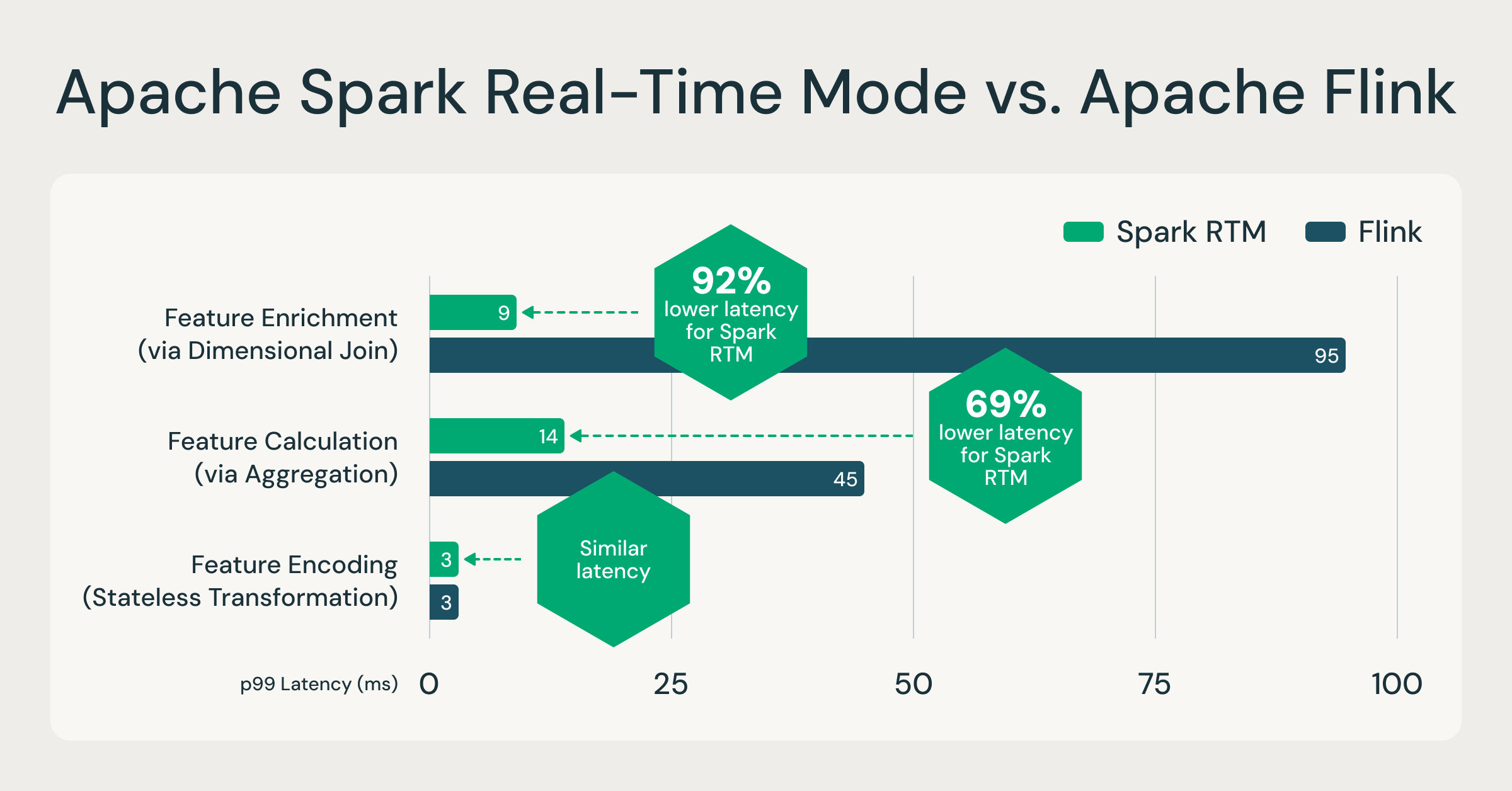
Spark ora può elaborare gli eventi in millisecondi; fino al 92% più veloce di Flink
La Mode in tempo reale (RTM) ha introdotto un nuovo motore di esecuzione ottimizzato che consente a Spark di offrire latenze costanti inferiori al secondo. Per valutare le prestazioni, abbiamo condotto un confronto diretto tra Spark RTM e Apache Flink. Il test si è basato su carichi di lavoro di calcolo delle feature in tempo reale che vediamo comunemente in produzione. Questi modelli di calcolo delle feature sono rappresentativi della maggior parte dei casi d'uso ETL a bassa latenza, come il rilevamento delle frodi, la personalizzazione e le analitiche operative.
Abbiamo valutato tre pattern di feature comuni:
- Codifica delle feature (trasformazione stateless): troncamento delle righe di input e codifica
- Arricchimento delle feature (tramite join): unione di uno stream con una tabella statica
- Calcolo delle feature (tramite aggregazione): aggregazione GroupBy + Count
I risultati dimostrano che l'architettura evoluta di Spark offre un profilo di latenza paragonabile a quello di framework di streaming specializzati.
Queste prestazioni sono rese possibili da tre innovazioni tecniche chiave in RTM:
- Flusso di dati continuo: i dati vengono elaborati man mano che arrivano anziché in blocchi periodici e discretizzati.
- Pianificazione della pipeline: gli stage vengono eseguiti simultaneamente senza blocchi, consentendo ai task downstream di elaborare immediatamente i dati senza attendere il completamento degli stage upstream.
- Shuffle in streaming: i dati vengono passati immediatamente tra le attività, aggirando i colli di bottiglia della latenza dei tradizionali shuffle basati su disco.
Insieme, trasformano Spark in un motore ad alte prestazioni e a bassa latenza in grado di gestire i casi d'uso operativi più esigenti.
I team gestiscono meno infrastruttura e operano più velocemente con Spark.
Sebbene la velocità pura sia essenziale, il vero valore della modalità in tempo reale risiede nella sua capacità di eliminare la complessità operativa che in genere ostacola la creazione di pipeline a bassissima latenza. Spark RTM semplifica notevolmente la tua architettura attraverso tre vantaggi principali. Per rendere questo concetto concreto, li descriviamo nel contesto delle applicazioni di machine learning in tempo reale.
Minimizzare il "logic drift" tra addestramento e inferenza: l'ML in tempo reale, come il rilevamento delle frodi, richiede un passaggio senza interruzioni tra l'elaborazione batch ad alta velocità (per l'addestramento del modello) e lo streaming a bassa latenza (per l'inferenza in tempo reale). Spark è la scelta preferita dei data scientist per l'addestramento dei modelli e forzare un passaggio da Spark a Flink per l'inferenza creerebbe un divario nella logica di business. Si finisce per avere una versione della logica in Spark per l'addestramento e una codebase completamente diversa in Flink per la produzione. Questa replica della logica di business può essere soggetta a errori e porta al "logic drift", in cui il modello viene addestrato su una realtà ma effettua lo scoring su un'altra. Con Spark RTM, il codice di trasformazione rimane identico, consentendo di mettere in produzione le funzionalità più velocemente e con grande precisione.
Aggiornamento on-demand con una modifica al codice di una sola riga: i requisiti di business sono raramente statici. Una pipeline di feature che oggi inizia con un SLA di 1 minuto potrebbe richiedere una latenza inferiore al secondo domani, con l'evolversi delle esigenze di attualità del modello. Viceversa, per molti casi d'uso, "andare più lentamente" (ad esempio, con batch giornalieri o orari) è significativamente più conveniente quando non è richiesto un aggiornamento immediato. Spark offre lo spazio per crescere e scalare insieme al tuo prodotto. Consente di modificare facilmente la strategia di feature ingegneria con una modifica al codice di una sola riga. Ad esempio, è possibile impostare il trigger su AvailableNow per eseguire una pipeline con una pianificazione giornaliera o oraria. Quando le esigenze di business cambiano, è possibile passare a uno streaming continuo a bassissima latenza semplicemente passando alla modalità in tempo reale: .trigger(RealTimeTrigger.apply()). Al contrario, in Flink, raggiungere questo obiettivo è un processo manuale. Spesso richiede di ottimizzare il parallelismo e orchestrare l'arresto e il riavvio delle risorse compute solo per adattarsi a una nuova frequenza di elaborazione.
Accelera lo sviluppo: RTM è basato sulla stessa Spark API che il tuo team conosce già. Ciò elimina le difficoltà legate alla manutenzione di più sistemi, consentendoti di procedere più velocemente creando e scalando applicazioni in tempo reale in un unico ambiente coerente.
I clienti eseguono diverse applicazioni in tempo reale su Spark.
Gli early adopter utilizzano RTM per alimentare una serie di applicazioni a bassa latenza in vari settori industriali.
Rilevamento delle frodi: una piattaforma leader di asset digitale calcola feature di rischio dinamiche come i controlli di velocità e i pattern di spesa aggregati dagli stream di Kafka, aggiornando il proprio negozio di funzionalità online in meno di 200 millisecondi per bloccare le transazioni fraudolente nel punto vendita.
Esperienze personalizzate: una piattaforma di e-commerce compute le feature di intent in tempo reale in base alla sessione corrente di un utente, consentendo ai modelli di refresh i consigli nel momento in cui un utente interagisce con un prodotto.
Monitoraggio IoT: un'azienda di trasporti e logistica acquisisce dati di telemetria in tempo reale per il rilevamento di anomalie, passando da un processo decisionale reattivo a uno proattivo in pochi millisecondi.
DraftKings, uno dei maggiori servizi di scommesse sportive e fantasy sport del Nord America, utilizza RTM per alimentare il calcolo delle feature per i suoi modelli di rilevamento delle frodi.
“Nelle scommesse sportive dal vivo, il rilevamento delle frodi richiede una velocità estrema. L'introduzione della Modalità in tempo reale insieme all'API transformWithState in Spark Structured Streaming è stata una vera rivoluzione per noi. Abbiamo ottenuto miglioramenti sostanziali sia nella latenza che nella progettazione delle pipeline e, per la prima volta, abbiamo creato pipeline di feature unificate per l'addestramento ML e l'inferenza online, raggiungendo latenze bassissime che prima non erano possibili.” —Maria Marinova, Sr. Lead Software Engineer, DraftKings
Inizia a sviluppare con la Modalità in tempo reale di Spark.
L'era della scelta tra "facile" e "veloce" è finita. Perché gestire due motori, due modelli di sicurezza e due set di competenze specializzate quando ora un unico motore fa tutto? RTM offre la velocità al di sotto del secondo richiesta dalle tue applicazioni in tempo reale, con la semplicità architetturale che il tuo team merita. Eliminando la "tassa operativa", puoi finalmente concentrarti sulla creazione di valore invece che sulla gestione dell'infrastruttura.
Pronto a eliminare la complessità del tuo stack in tempo reale?
- Approfondisci i dettagli: esplora la documentazione di RTM per comprendere le specifiche tecniche complete, le origini e i sink supportati e le query di esempio. Troverai tutto ciò di cui hai bisogno per abilitare il nuovo trigger e configurare i tuoi carichi di lavoro di streaming.
- Guardalo in azione: per approfondire l'ingegneria alla base di RTM, guarda questa sessione di approfondimento tecnico, che illustra la progettazione e l'implementazione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.