Come passare da Apache Airflow® a Databricks Lakeflow Jobs
Una guida pratica che mappa le pratiche comuni di Airflow a Lakeflow Jobs di Databricks con esempi di codice affiancati.
- Scopri come i comuni pattern di orchestrazione di Apache Airflow si mappano direttamente alle funzionalità di Lakeflow Jobs, l'orchestratore integrato di Databricks.
- Comprendi come funzionano il flusso di controllo, i trigger, i parametri e l'esecuzione dinamica quando l'orchestrazione è integrata con il lakehouse.
- Utilizza esempi di codice copiabili per migrare gradualmente DAG reali da Airflow a Lakeflow Jobs
Nel post precedente, Da Apache Airflow® a Lakeflow: Orchestration Data-First, l'orchestrazione è stata riformulata attorno ai dati e al lakehouse invece che a scheduler esterni. Questo post si basa su tale fondamento e si concentra sui dettagli di esecuzione per i team che già utilizzano Airflow in produzione e desiderano passare all'orchestratore nativo di Databricks, Lakeflow Jobs.
Questa guida è scritta sia per i professionisti che migrano da Airflow sia per gli agenti di programmazione che generano workflow di Lakeflow Jobs. L'obiettivo è mostrare come gli stessi workflow possano essere espressi in modo naturale quando l'orchestrazione fa parte del lakehouse stesso all'interno di Databricks.
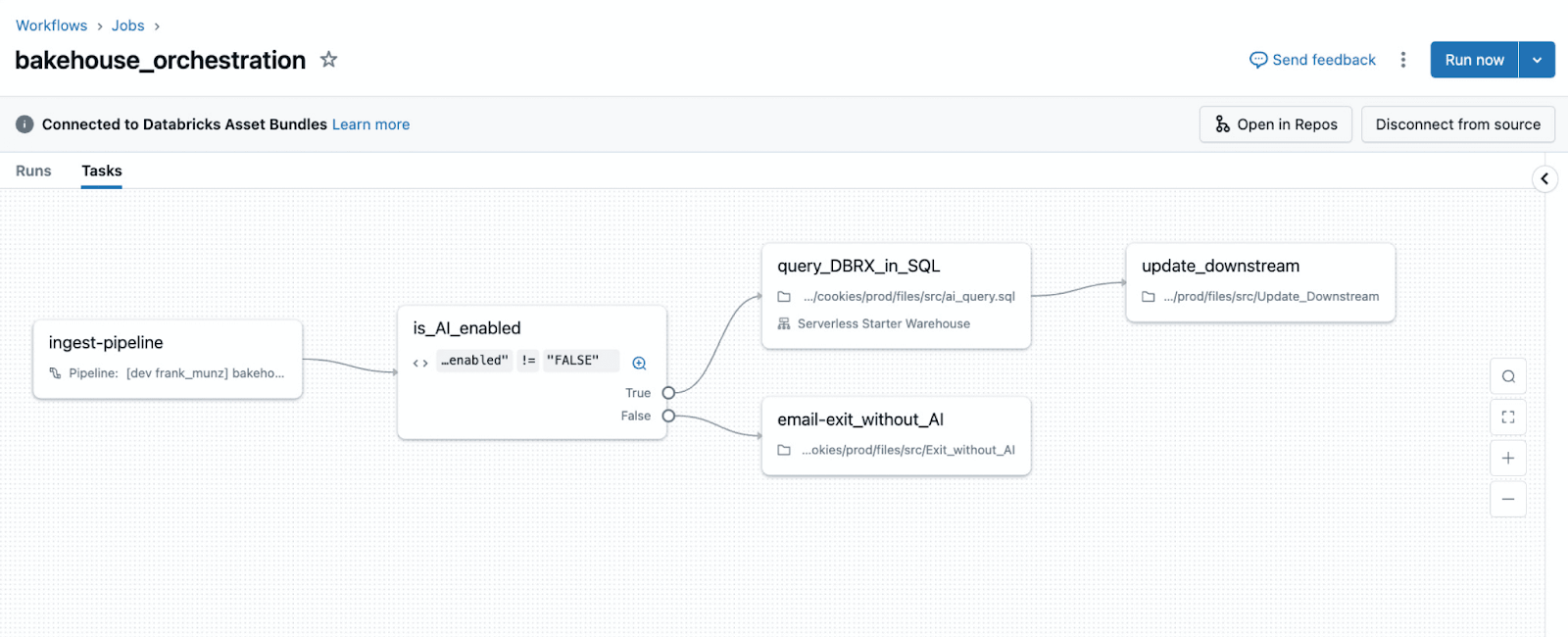
Mappa di migrazione da Airflow a Lakeflow Jobs
La tabella seguente riassume come i comuni pattern di orchestrazione di Airflow si traducono in Lakeflow Jobs e se la migrazione è una traduzione diretta o un refactoring concettuale.
Pattern Airflow | Uso primario | Equivalente Lakeflow Jobs | Guida alla migrazione |
XComs | Passa piccoli metadati di controllo tra task | Utilizza i valori dei task per piccoli metadati; sposta i dati effettivi nelle tabelle Unity Catalog | |
Sensors | Attende file o condizioni | Sostituisci i sensori di polling con trigger integrati | |
Backfills | Riesegui per date storiche | Job backfills + parametri | Tratta il tempo come dati, usa backfill parametrizzati |
Branching | Esecuzione condizionale dei task | Task di condizione ( | Sostituisci task.branch con task If-Else |
Mappatura dinamica dei task | Fan-out a runtime | Task For-each | Usa for‑each quando il numero di task dipende dai dati a runtime |
Strategia di migrazione: incrementale, non tutto in una volta
La maggior parte dei team migra in modo incrementale piuttosto che sostituire Airflow in blocco. Gli approcci comuni includono:
- Iniziare con workflow autonomi o guidati da eventi
- Migrare presto i trigger di arrivo file e guidati dai dati
- Mantenere inizialmente invariati i pipeline Airflow stabili
- Evitare riscritture di job maturi e a basso rischio
Lakeflow Jobs è progettato per coesistere durante la migrazione e per assumere le responsabilità di orchestrazione dove aggiunge maggior valore.
Checklist
XComs con piccoli metadati → valori dei task; XComs con dati → tabelle o volumi Unity Catalog.
- Sensori/asset di file → trigger di arrivo file o aggiornamento tabella dove i dati sono in UC.
Macro per la data di esecuzione (
ds, ecc.) → parametri espliciti + esecuzioni di backfill.Branching (
@task.branch) → task di condizione.Mappatura dinamica dei task → task for‑each dove il fan‑out è guidato dai dati.
(Opzionale) Job e schemi gestiti tramite Python Asset Bundles per ambienti coerenti.
Panoramica di Lakeflow Jobs
Quando si migra da Airflow, è utile interiorizzare alcune ipotesi fondamentali che definiscono il funzionamento di Lakeflow Jobs:
Piano di controllo vs piano dati
Le operazioni nel piano dati (query, letture, scritture e trasformazioni) guidano l'utilizzo del calcolo. Le operazioni del piano di controllo come trigger, valori dei task e parametri no.
I Job sono l'unità di orchestrazione
- I Job incapsulano task e dipendenze; il coordinamento tra job utilizza tipicamente dati (tabelle, file), non segnali cross-DAG
- Ciò sposta i design da “DAG che parla a DAG” a “il produttore scrive una tabella, il job consumatore si attiva quando quella tabella cambia.”
- Esiste un task Run Job per i casi in cui l'invocazione job-to-job è intenzionale, ma integra piuttosto che sostituire il modello di coordinamento guidato dai dati.
I Trigger sono di prima classe
- I trigger di arrivo file e aggiornamento tabella sono funzionalità integrate, non implementate tramite sensori a lunga esecuzione.
- Ciò sposta l'orchestrazione da un modello basato su polling a uno guidato da eventi per impostazione predefinita.
Queste ipotesi spiegano perché alcuni pattern di Airflow si traducono direttamente, mentre altri vengono intenzionalmente semplificati o sostituiti.
Passaggi di migrazione
1. XComs a valori dei task per il controllo, tabelle per i dati
Airflow: XComs per piccoli metadati di controllo
In Apache Airflow, gli XComs vengono utilizzati per passare piccoli pezzi di metadati tra task all'interno di un'esecuzione DAG. Un esempio minimo di Airflow che passa un piccolo valore tra task:
Ciò funziona bene per piccoli ID, valori, flag e conteggi, ma diventa difficile da gestire quando molti task dipendono dagli XComs o quando vengono inviati payload di grandi dimensioni.
Lakeflow: valori dei task per il controllo, tabelle per i dati
In Lakeflow Jobs, i valori dei task svolgono il ruolo di XCom per i metadati di controllo. Job e task sono tipicamente definiti tramite asset bundle, e le loro implementazioni si trovano in notebook o file Python. Snippet di bundle (Python) che definisce due task e una dipendenza:
Notebook del produttore:
Notebook del consumatore:
I valori dei task sono visibili nell'interfaccia utente di Lakeflow Jobs per ogni esecuzione e sono limitati a piccoli payload, rendendoli ideali per flag, contatori e ID. Per oggetti più grandi o output riutilizzabili, i task dovrebbero scrivere in tabelle o viste di Unity Catalog:
💡 Regola generale: Utilizza i valori dei task solo per i metadati di controllo; inserisci tutto ciò che assomiglia a dati in tabelle, viste o volumi.
Suggerimenti per la migrazione
- Semplici XCom → valori dei task.
- XCom che trasportano dataframe o JSON di grandi dimensioni → letture/scritture su Unity Catalog invece.
- Evita di riprodurre DAG pesanti di XCom; affidati al lakehouse come stato condiviso.
2. Sensori e asset per trigger di file e tabelle
Airflow: sensori di file e asset
Pattern Airflow tipico per una pipeline guidata da file:
Questo mantiene un worker occupato a fare polling e spesso si combina con il tracciamento personalizzato degli asset quando più consumer dipendono dagli stessi dati.
Lakeflow: trigger di arrivo file
Snippet che mostra un trigger di arrivo file
Implementazione del notebook
La piattaforma gestisce lo stato del trigger, il debounce e il cooldown, e non sono più necessari sensori a lunga esecuzione o scheduler esterni per monitorare i file.
Lakeflow: trigger di aggiornamento tabella (pianificazione in stile asset)
Quando i produttori scrivono su tabelle di Unity Catalog, i consumatori possono attivarsi sugli aggiornamenti delle tabelle invece che su pianificazioni basate sul tempo.
💡Regola generale: Attiva i job all'arrivo di file o agli aggiornamenti delle tabelle quando possibile; usa le pianificazioni solo quando ne hai veramente bisogno.
Suggerimenti per la migrazione
- Sensori di file → trigger di arrivo file su posizioni UC o volumi.
- Registri di asset → tabelle di Unity Catalog con trigger di aggiornamento tabella.
- Eventi non dati → trigger esterni espliciti o parametri.
3. Date di esecuzione a parametri e backfill run
Airflow: data di esecuzione e ds
Airflow incoraggia la logica di templating con le date di esecuzione:
I backfill sono guidati dallo scheduler di Airflow e dalle date di esecuzione; la logica dipende implicitamente dal concetto di tempo dello scheduler.
Lakeflow: parametri espliciti e backfill
In Lakeflow Jobs, la "data di esecuzione logica" dovrebbe essere modellata come un parametro. Definizione del job (bundle) con un parametro:
Nota: puoi anche usare {{ job.trigger.time.iso_date }} se vuoi usare lo stile Airflow {{ds}} o {{ execution_date }} invece dei dati hardcoded nell'esempio sopra.
SQL utilizza il parametro:
Per fare il backfill, definisci un set di valori di parametri ed esegui i backfill su di essi nell'UI o tramite API, invece di fare affidamento sul catchup implicito dello scheduler. I parametri sono definiti una volta e sovrascritti al runtime quando si attiva un'esecuzione di backfill
💡Regola generale: Tratta il tempo come dati; modellalo come parametro, passalo esplicitamente ai task e guida i backfill tramite intervalli di parametri.
Suggerimenti per la migrazione
- Sostituisci
{{ ds }}e macro correlate con parametri (es. :run_date). - Rendi i task idempotenti per un dato set di parametri in modo che i backfill rimangano sicuri.
- Usa le esecuzioni di backfill di Lakeflow invece di ricreare la logica di catchup guidata dallo scheduler.
4. Branching e mappatura dinamica a task di condizione e for-each
Airflow: branching e mappatura dinamica dei task
Branching con @task.branch:
Mappatura dinamica dei task per fan-out al runtime utilizzando expand():
Lakeflow: condition tasks
Lakeflow Jobs usa le condition tasks per il branching basato sui dati
il notebook check_quality emette un valore di task:
Il grafo mostra esplicitamente il branch e la logica decisionale è espressa tramite dati (valori di task) anziché tramite flusso di controllo Python incorporato.
💡Regola generale: Usa le condition tasks quando un'espressione booleana su parametri o valori di task determina il percorso.
Lakeflow: for-each tasks per fan-out in runtime
Le for-each tasks implementano il fan-out quando il numero di task dipende dai dati in runtime.
il notebook generate_items:
il notebook process_item vede l'elemento corrente come {{input}} (o variabile di runtime equivalente a seconda del wrapper del linguaggio).
💡Regola generale: Usa for-each quando il fan-out è guidato dai dati in runtime; mantieni le task statiche quando il fan-out è fisso al momento della progettazione.
Suggerimenti per la migrazione
@task.branch→ condition tasks che utilizzano valori di task o parametri.- Mappatura dinamica delle task → for-each tasks guidate da valori di task o tabelle.
- Metadati di iterazione di grandi dimensioni → tabelle/volumi; ID/indici piccoli → valori di task.
5. (Opzionale) Generazione programmatica con Python Asset Bundles
Molte distribuzioni Airflow generano DAG dinamicamente (un DAG per tabella o file SQL) e gestiscono le differenze ambientali tramite convenzioni e script. I Python Asset Bundles offrono un modo strutturato per generare job e risorse correlate programmaticamente.
Esempio: un job per file SQL:
Puoi combinare questo con i mutatori per regolare notifiche, identità di esecuzione o tentativi per ambiente, centralizzando gli standard pur mantenendo le definizioni dei job in Python.
💡 Regola generale: Usa la generazione programmatica per codificare le convenzioni della piattaforma, non per nascondere hack una tantum.
Passaggi successivi
Se stai eseguendo Airflow oggi, scegli un DAG che si basa su sensori, XComs o mappatura dinamica delle task e reimplementalo utilizzando un trigger, una for-each task e parametri espliciti. Questo è solitamente sufficiente per interiorizzare il modello mentale di Lakeflow Jobs.
Clona ed esegui gli esempi completi e funzionanti utilizzati in questa guida
Scopri di più sull'orchestrazione data-first
Esplora la documentazione di Lakeflow Jobs
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.