Come Zalando ha costruito una base dati unificata per l'IA e l'analisi su Databricks
Zalando separa la creazione dei dati dal consumo, standardizza le definizioni delle metriche e abilita query affidabili in linguaggio naturale su dashboard e IA.
di Fabian Halkivaha, Mukrram Ur Rahman, Maria Vedenina e Timur Yüre
- Zalando ha costruito una base dati unificata su Databricks con Unity Catalog, Metric Views e Genie per governare i dati, standardizzare le metriche e abilitare l'analisi in linguaggio naturale.
- Hanno centralizzato la logica di business utilizzando Metric Views ("metriche come codice"), risolvendo le definizioni incoerenti delle metriche tra dashboard, SQL e pipeline.
- Basando Genie su questo livello semantico, Zalando fornisce query affidabili in linguaggio naturale, riducendo il tempo necessario per rispondere a nuove domande e migliorando la fiducia nei risultati.
In Zalando, una delle principali piattaforme online europee per la moda e lo stile di vita, orchestriamo un enorme ecosistema digitale che collega oltre 50 milioni di clienti attivi con più di 7.000 marchi e partner in tutta Europa. Ogni interazione del cliente (navigazione, ordine, reso, ecc.) genera un impulso di dati che guida il nostro processo decisionale, dalle raccomandazioni personalizzate all'ottimizzazione della logistica.
Operare su questa scala comporta una serie unica di sfide. Il nostro panorama di dati è vasto e complesso, alimentato da un'architettura di microservizi che trasmette terabyte di eventi nel nostro data lake centrale. Sebbene questa architettura ci abbia permesso di scalare rapidamente, ha anche reso la governance una sfida e ha offuscato la distinzione tra Dati Transazionali (operazioni commerciali quotidiane) e Dati Analitici (insight per il processo decisionale).
Per anni, abbiamo cercato un approccio distribuito per risolvere questo problema decentralizzando la proprietà, in modo che i team di dominio (come "Pagamenti" o "Logistica") potessero gestire i propri prodotti di dati. Una struttura di governance centralizzata è cruciale in questa configurazione per garantire un carico gestibile sui team e prevenire rischi aziendali. Inoltre, senza uno strato unificato per definire la verità, affrontiamo la sfida della divergenza delle metriche: Perché la dashboard del Marketing mostra un "Ricavo Netto" diverso dal report Finanziario? Poiché le metriche vivono in silos, è difficile governarle e garantire che siano individuabili e affidabili per il riutilizzo durante il loro ciclo di vita.
In questo post, condivideremo come Zalando sta raggiungendo questo obiettivo sfruttando l'intera piattaforma Databricks. Approfondiremo come stiamo costruendo uno Unified Semantic Layer che colma il divario tra Dati Transazionali e Dati Analitici. Nello specifico, tratteremo:
- Le Fondamenta: Come Unity Catalog abilita la governance federata e la condivisione sicura tra centinaia di team.
- Il Livello Semantico: Come Unity Catalog Business Semantics, potenziato da Metric Views, ci consente di definire la logica di business una volta e servirla ovunque.
- L'Analisi Potenziata da Conversational AI: Come sfruttiamo il livello semantico attraverso Genie, un'interfaccia potenziata da IA generativa che consente agli utenti di interrogare i dati utilizzando il linguaggio naturale senza bisogno di competenze SQL, aiutandoci a prendere decisioni più rapide e basate sui dati.
Le Fondamenta – Democratizzare la Governance con Unity Catalog
Per gestire efficacemente il nostro vasto panorama di dati, abbiamo deciso di abbandonare il controllo basato sulle risorse. In quel modello, ogni nuovo set di dati o consumatore richiedeva ruoli IAM personalizzati, policy del bucket S3 e gestione delle eccezioni. Ma abbiamo identificato delle sfide: i permessi erano frammentati su migliaia di risorse, ingombranti da rivedere e inclini alla deriva. Pertanto, siamo passati a un approccio di governance basato sull'identità. Le decisioni di accesso sono espresse come policy riutilizzabili legate a persone e gruppi. Vengono valutate in modo coerente tra i set di dati e applicate centralmente. Ciò rende l'accesso più facile da operare, controllare ed evolvere al cambiare dei team e dei dati. Abbiamo costruito queste fondamenta utilizzando Databricks Unity Catalog e implementato un framework di controllo degli accessi federato sopra di esso.
L'Architettura
Abbiamo progettato un pattern a doppio catalogo che separa rigorosamente la creazione dei dati dal loro consumo, garantendo che l'agilità non vada a scapito del controllo:
- Cataloghi Privati per l'Autonomia: Ogni team di dominio crea il proprio Catalogo Privato utilizzando una soluzione interna self-service. All'interno di questo ambiente privato, il team può creare schemi, ingerire dati grezzi e costruire tabelle al proprio ritmo senza attendere l'approvazione centrale. Questo funge da loro "fabbrica", ottimizzata per lo sviluppo e l'iterazione senza restrizioni. L'unica limitazione che affrontano è che tutti gli oggetti creati qui sono accessibili esclusivamente dal team stesso, più un numero limitato di collaboratori correlati. Ciò significa che i casi d'uso costruiti su questi cataloghi non sono destinati all'uso a livello aziendale.
- Il Catalogo Condiviso Centrale per la Governance: Per i casi d'uso in cui vari team in tutta l'azienda devono utilizzare questi set di dati, abbiamo introdotto un catalogo condiviso centrale. Questo funge da "showroom" aziendale. Tutti i dati condivisi in tutta l'organizzazione devono essere esposti qui tramite Dynamic Views, dove ricadono sotto una rigorosa governance centrale. Nel momento in cui i dati arrivano qui, sono immediatamente individuabili tramite Unity Catalog.
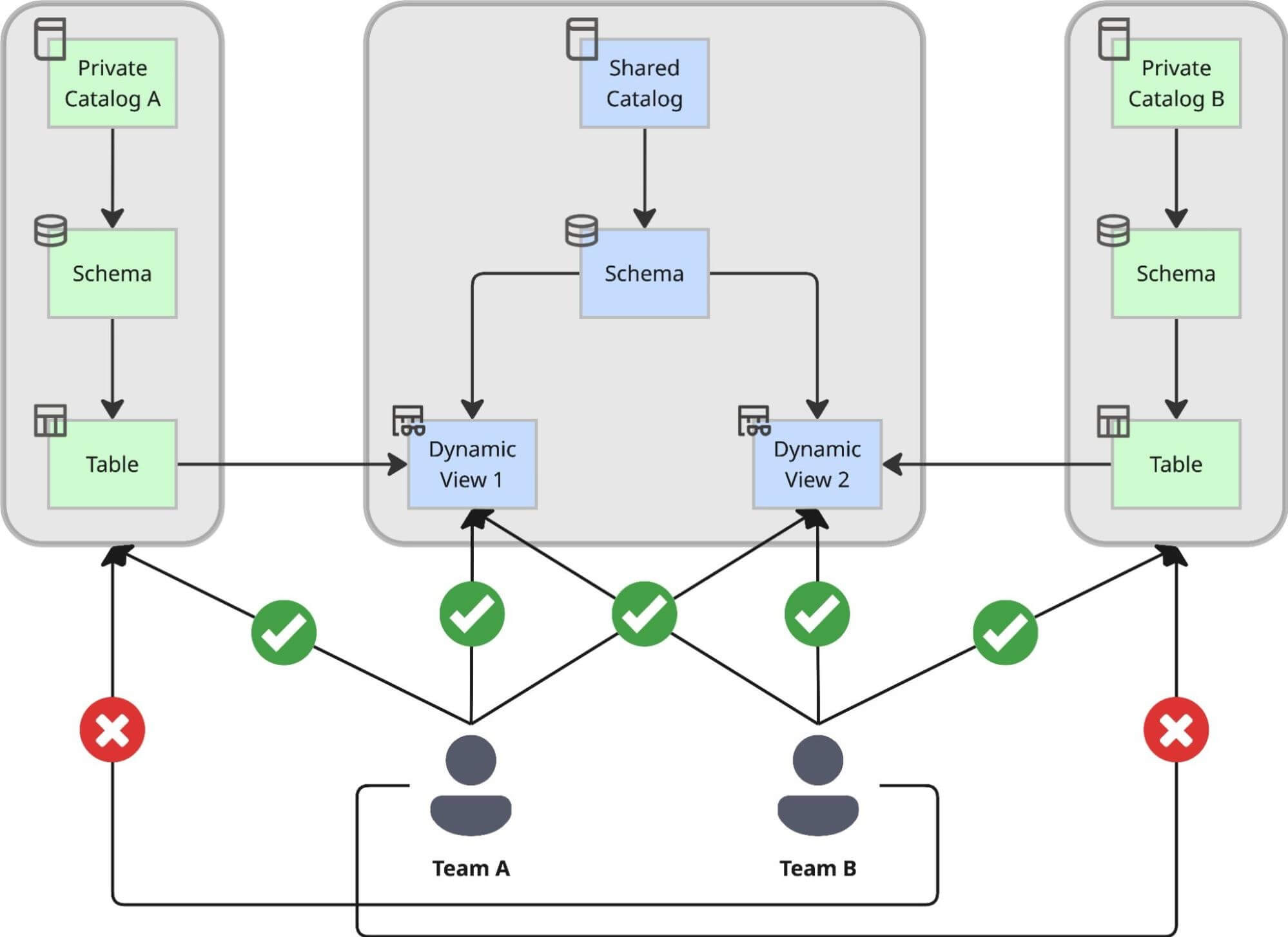
Perché le Dynamic Views? Controllo Centralizzato e Auditabilità
Abbiamo preso una decisione strategica di esporre i dati nel catalogo condiviso esclusivamente tramite Dynamic Views, piuttosto che puntatori diretti a tabelle. Questo approccio ci consente di applicare un processo di accesso centralizzato in grado di gestire complesse regole di conformità.
Utilizzando le Dynamic Views come livello di servizio, abbiamo ottenuto:
- Regole di Processo Personalizzate per il GDPR: Inseriamo logica personalizzata direttamente nella definizione della vista utilizzando funzioni come is_account_group_member(). Ciò garantisce un robusto controllo degli accessi verificando se gli utenti soddisfano i requisiti antitrust e sono autorizzati ad accedere a dati sensibili (come l'email).
- Accesso Insider Conforme per Impostazione Predefinita: Grazie a un processo di classificazione automatizzato, ogni colonna viene classificata. Tutte le colonne non sensibili sono accessibili a un'ampia varietà di utenti per impostazione predefinita, il che accelera la democratizzazione dei dati e il processo decisionale.
- Auditabilità Completa: Poiché tutti gli accessi tra team passano attraverso queste viste gestite centralmente, manteniamo una traccia di audit completa delle decisioni di accesso. Sappiamo esattamente quale policy ha concesso a un utente l'accesso a una specifica riga o colonna.
- Insight Affidabili: Per prevenire la generazione di dati errati o numeri fuorvianti dovuti ad aggregazioni parziali, qualsiasi query che tenti di accedere a una colonna sensibile senza la necessaria autorizzazione specifica fallirà esplicitamente con un errore di permesso negato.
Governance as Code: Il Flusso di Condivisione
Per mantenere questo processo efficiente, abbiamo automatizzato il flusso di condivisione utilizzando un approccio GitOps:
- Pull Request per Condividere: Quando un team è pronto a condividere un set di dati dal proprio catalogo privato al catalogo condiviso, non apre un ticket. Apre una Pull Request (PR) in un repository centrale con un file di configurazione che punta alla loro tabella di origine.
- Regole di Approvazione: La Pull Request viene controllata per i criteri di condivisione, l'unicità e altri importanti fattori decisionali.
- Validazione e Provisioning Automatizzati: Una volta che la PR viene approvata e unita, il nostro servizio di piattaforma genera automaticamente la corrispondente Dynamic View nel catalogo condiviso centrale e classifica automaticamente le colonne.
Questa configurazione ci consente di mantenere l'agilità dei team distribuiti, applicando al contempo uno standard di governance centralizzato e completamente verificabile che mantiene i nostri dati facilmente individuabili, sicuri e conformi.
Il Livello Semantico – Definire "La Verità" con Metric Views
Con le solide fondamenta che abbiamo stabilito per l'accesso ai dati, ora ci concentriamo sulla garanzia di un'interpretazione coerente dei dati.
Stiamo centralizzando attivamente la logica di business che in precedenza era frammentata in tutto lo stack di dati:
- Strumenti BI: Definizioni delle metriche incorporate in singole dashboard
- Script SQL: Logica duplicata in notebook e pipeline
- Tabelle Materializzate: Metriche precalcolate legate a casi d'uso specifici
Stiamo unificando migliaia di definizioni di metriche in un unico livello governato. Ciò ci consente di rompere il "logic lock-in": la definizione di "Net Merchandise Value" (NMV) in uno strumento di dashboarding diventa completamente accessibile a uno scienziato di dati che lavora in un notebook o a un bot AI che risponde alla domanda di un utente.
Per raggiungere questo obiettivo, adottiamo le Databricks Metric Views come nostro livello semantico unificato. Questo disaccoppia in modo decisivo la definizione di una metrica dal suo utilizzo, garantendo che gli utenti ricevano esattamente lo stesso risultato calcolato, sia che interroghino tramite un editor SQL, una dashboard o un agente AI. In pratica, ciò garantisce che sia gli utenti tecnici che quelli non tecnici utilizzino le stesse definizioni di metrica.
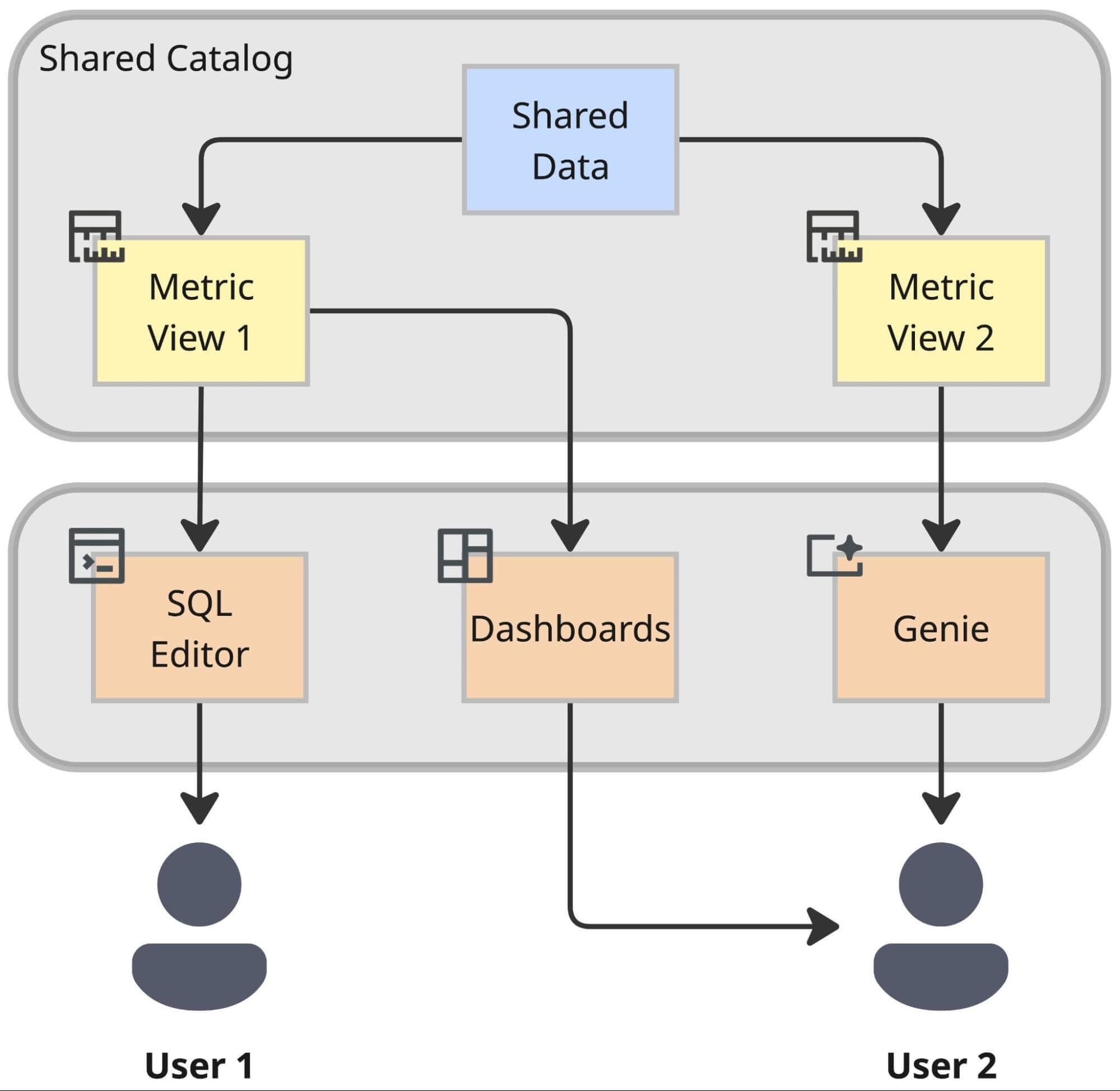
Metrica come Codice: Il Ciclo di Vita della Metrica
Implementiamo un rigoroso approccio "Metric as Code" al nostro livello semantico, proprio come utilizziamo GitOps per la condivisione dei dati in Unity Catalog. Garantiamo la coerenza tra tutti i team centralizzando e standardizzando ogni definizione di KPI.
La nostra architettura gestisce l'intero ciclo di vita di una metrica:
- Definizione in YAML: Le metriche sono definite nel codice (file YAML) archiviati in un repository centrale. Questo cattura non solo la logica di aggregazione (ad es. SUM(amount)) e le relazioni tra tabelle, fatti e metriche, ma anche metadati critici come proprietà, descrizione e formattazione.
- Validazione Automatica: Prima che una metrica possa essere unita alla produzione, la nostra pipeline CI/CD esegue una suite di controlli automatici. Questi includono:
- Unicità: Garanzia che non esista già una metrica con lo stesso nome o definizione.
- Conformità: Applicazione delle convenzioni di denominazione (ad es. snake_case) per garantire la reperibilità.
- Proprietà: Verifica che un ID team valido sia associato alla metrica per la responsabilità.
- Umano nel ciclo: Attraverso il principio delle 4 occhi, ogni Pull Request viene revisionato da esperti di dominio.
- Ambienti di Sviluppo Individuali: Per consentire ai team di iterare rapidamente pur testando in un ambiente molto vicino alla produzione, ogni Pull Request distribuisce le Metric Views in un ambiente di test separato. Questa configurazione rende possibile verificare immediatamente le implicazioni della modifica.
Costruire uno Schema a Stella per il Lakehouse
Sotto il cofano, ci affidiamo a principi consolidati di modellazione dimensionale. Ogni Metric View nel nostro ambiente di produzione funge da interfaccia standard, mappando tipicamente 1-a-1 con le nostre tabelle Fatto, ereditando attributi dalle tabelle Dimensione conformate.
Questa configurazione è cruciale per la nostra scala. Imponendo che le Metric Views siano costruite sopra i dati attendibili nel nostro Catalogo Condiviso (dalla Sezione 1), garantiamo che il livello semantico erediti tutti i benefici di sicurezza e conformità della piattaforma sottostante. Un utente che interroga una vista metrica è ancora soggetto alla stessa sicurezza a livello di riga e colonna, e alle regole di accesso che abbiamo definito nel livello Unity Catalog. Miglioreremo ulteriormente questa configurazione entro la fine dell'anno con un ulteriore livello di autorizzazione tramite le Metric Views, in modo che gli utenti non necessitino più di accesso ai dati grezzi, ma solo di accesso a livello di metrica e dimensione.
Il Risultato: Interoperabilità
Il vantaggio di questa architettura è l'interoperabilità. Estraendo la logica di business dagli strumenti BI proprietari e inserendola nel livello semantico del Lakehouse, ci prepariamo per il futuro. Una metrica definita una volta in questo livello diventa istantaneamente disponibile per:
- Databricks Dashboards per la reportistica standard.
- Genie per l'analisi basata sull'AI in un'interfaccia conversazionale che utilizza il linguaggio naturale.
- Strumenti e Applicazioni Esterni tramite connettori standardizzati.
Questa centralizzazione è la chiave per il nostro prossimo passo importante: consentire al business di "parlare" con i propri dati.
L'Analisi Conversazionale Potenziata dall'AI
Le dashboard sono essenziali per rispondere a domande quotidiane e ricorrenti. Tuttavia, la velocità del business spesso supera la capacità della reportistica standard di catturare tutto. Ad esempio, un Category Manager potrebbe aver bisogno di sapere: "Quali marchi di sneaker hanno avuto un alto tasso di click-through ma non sono rientrati nella top 10 per numero di articoli venduti in Germania la scorsa settimana?" Rispondere a domande nuove come questa, non affrontate dai report standard esistenti, richiedeva frequentemente la creazione di una nuova dashboard. Anche con strumenti self-service, persisteva un significativo ritardo nel "tempo per l'insight". Gli utenti dovevano trovare il dataset giusto, configurare i widget e applicare i filtri prima di poter ottenere una risposta. Ciò spesso si traduceva in dashboard una tantum, contribuendo alla proliferazione delle dashboard e alla riduzione della reperibilità.
Per ottimizzare l'esperienza utente, abbiamo valutato diverse soluzioni "Talk-to-Data" che offrono interfacce conversazionali basate su LLM, spesso definite chatbot AI. Genie ha ottenuto i migliori risultati perché è basato su un livello semantico unificato, mentre le soluzioni senza questo livello faticavano a generare SQL accurato per logiche di business complesse.
Questo è il motivo per cui l'introduzione delle Metric Views si è rivelata fondamentale per l'analisi conversazionale potenziata dall'AI come Genie. Indirizzando Genie verso le Metric Views pre-stabilite (come dettagliato nella Sezione 2), abbiamo ottenuto una svolta critica: risposte coerenti e affidabili basate su definizioni di business governate.
Perché Metric Views aumenta drasticamente l'accuratezza dell'AI
La più grande barriera all'adozione dell'AI nell'analisi è la fiducia. Se un LLM genera una query SQL errata (allucinazione), i numeri saranno sbagliati e gli utenti perderanno fiducia.
Genie risolve questo problema lavorando con il nostro livello semantico nelle Metric Views.
- Nessuna Indovinazione: Quando un utente chiede "NMV" (Net Merchandise Value), Genie non cerca di calcolarlo dalle tabelle grezze. Riconosce "NMV" come una metrica governata nella nostra vista metrica e interroga semplicemente la logica predefinita. Pertanto, la vista metrica riduce la complessità della generazione di un'istruzione SQL, portando a una maggiore accuratezza.
- Consapevole del Contesto: Abbiamo investito molto nell'arricchimento dei metadati del nostro Unity Catalog, aggiungendo descrizioni, sinonimi e query di esempio. Genie utilizza questo contesto per capire che quando un utente dice "Cancellazioni", intende specificamente ordini cancellati prima della spedizione, corrispondendo alla nostra definizione interna.
Potenziare la Prima Linea
Abbiamo testato Genie con team non tecnici, come Merchandiser, Acquirenti e Analisti dei Prezzi, che storicamente si affidavano a esportazioni Excel o strumenti BI. Il feedback è stato immediato: gli utenti potevano ottenere risposte rapide a domande granulari (ad es. performance di mercato specifiche abbinate a un tipo di dispositivo specifico) senza dover conoscere una singola riga di SQL o dedicare tempo alla creazione di una vista di report personalizzata.
L'introduzione della nuova Modalità Agente ha notevolmente migliorato l'esperienza utente. La Modalità Agente analizza automaticamente i dati per individuare la causa principale dei risultati dell'analisi, consentendo agli utenti di chiedere semplicemente "perché" è successo qualcosa. In Zalando, ciò potrebbe ridurre il tempo di preparazione per le nostre riunioni periodiche sulle performance—dove vengono prese decisioni di gestione critiche—da diverse ore a pochi minuti.
Tuttavia, con le sue ampie funzionalità, Genie può anche diventare costoso se non configurato correttamente, ad esempio su tabelle e viste non aggregate. Ecco perché è fondamentale curare attentamente i dati e il contesto utilizzati da Genie. Inoltre, riconosciamo il potenziale per ulteriori miglioramenti, come il vantaggio di introdurre il controllo completo della versione di Genie e abilitare aggiornamenti programmatici alle configurazioni di Genie, su cui Databricks sta già lavorando e che è attualmente già parzialmente supportato.Scaling Genie per l'adozione aziendale
Non stiamo trattando Genie solo come un esperimento in sandbox; lo stiamo integrando nelle nostre operazioni aziendali. Le nostre aree di interesse per lo scaling includono:
- Stabilire la Governance: Gli spazi Genie curati saranno supportati da Metric Views governate e correttamente mantenute.
- Garantire l'Affidabilità dei Dati: Stiamo collaborando con i team proprietari dei dati per stabilire spazi Genie curati. Questi spazi offriranno rappresentazioni analitiche dei loro dati tramite Metric Views, garantendo che la qualità dei dati sia mantenuta dai proprietari dei dati stessi.
- Integrazione con Agent Bricks o utilizzo di Genies in Databricks One: Abbiamo in programma di orchestrare questi spazi Genie curati utilizzando Agent Bricks o utilizzando Genies all'interno di Databricks One. Questo approccio garantisce agli utenti un punto di ingresso unico e unificato per tutte le loro richieste di dati.
Combinando la governance di Unity Catalog, la standardizzazione della logica di business tramite Metric Views e l'intelligenza di Genie, stiamo costruendo una cultura dei dati in cui "chiedere ai dati" è facile come chiedere a un collega.
Grazie a Merve Karali, Tobias Efinger e Roberto Bruno Martins per aver contribuito a questo post.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.