Migliorare il recupero e il RAG con il fine-tuning del modello di embedding
di Jacob Portes, Andrew Drozdov, Erica Ji Yuen, Vincent Chen, Sean Kulinski, Milo Cress, Colton Peltier, Sam Havens, Michael Carbin, Vitaliy Chiley e Connor Jennings
- Come il finetuning dei modelli di embedding migliora il recupero e l'accuratezza di RAG
- Principali guadagni di performance nei benchmark
- Come iniziare con il finetuning degli embedding su Databricks
Ottimizzazione dei modelli di embedding per un miglior recupero e RAG
In sintesi: L'ottimizzazione di un modello di embedding su dati specifici del dominio può migliorare significativamente la ricerca vettoriale e l'accuratezza della generazione aumentata dal recupero (RAG). Con Databricks, è facile ottimizzare, distribuire e valutare modelli di embedding per ottimizzare il recupero per il tuo caso d'uso specifico, sfruttando dati sintetici senza etichettatura manuale.
Perché è importante: Se il tuo sistema di ricerca vettoriale o RAG non restituisce i migliori risultati, l'ottimizzazione di un modello di embedding è un modo semplice ma potente per migliorare le prestazioni. Che tu abbia a che fare con documenti finanziari, basi di conoscenza o documentazione di codice interna, l'ottimizzazione può fornirti risultati di ricerca più pertinenti e migliori risposte LLM downstream.
Cosa abbiamo scoperto: Abbiamo ottimizzato e testato due modelli di embedding su tre set di dati aziendali e abbiamo osservato miglioramenti significativi nelle metriche di recupero (Recall@10) e nelle prestazioni RAG downstream. Ciò significa che l'ottimizzazione può cambiare le regole del gioco per l'accuratezza senza richiedere etichettatura manuale, sfruttando solo i tuoi dati esistenti.
Vuoi provare l'ottimizzazione degli embedding? Forniamo una soluzione di riferimento per aiutarti a iniziare. Databricks rendefacile la ricerca vettoriale, RAG, il reranking e l'ottimizzazione degli embedding. Contatta il tuo Databricks Account Executive o Solutions Architect per maggiori informazioni.
{kind=link}
Perché ottimizzare gli embedding?
I modelli di embedding alimentano i moderni sistemi di ricerca vettoriale e RAG. Un modello di embedding trasforma il testo in vettori, rendendo possibile trovare contenuti pertinenti in base al significato piuttosto che solo alle parole chiave. Tuttavia, i modelli pronti all'uso non sono sempre ottimizzati per il tuo dominio specifico, è qui che entra in gioco l'ottimizzazione.
L'ottimizzazione di un modello di embedding su dati specifici del dominio aiuta in diversi modi:
- Aumenta l'accuratezza del recupero: gli embedding personalizzati migliorano i risultati di ricerca allineandosi ai tuoi dati.
- Migliora le prestazioni RAG: un miglior recupero riduce le allucinazioni e consente risposte di IA generativa più fondate.
- Migliora costi e latenza: un modello ottimizzato più piccolo può talvolta superare alternative più grandi e costose.
In questo post del blog, dimostriamo che l'ottimizzazione di un modello di embedding è un modo efficace per migliorare le prestazioni di recupero e RAG per casi d'uso aziendali specifici per attività.
Risultati: l'ottimizzazione funziona
Abbiamo ottimizzato due modelli di embedding (gte-large-en-v1.5 e e5-mistral-7b-instruct) su dati sintetici e li abbiamo valutati su tre set di dati dal nostro Domain Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA e Databricks DocsQA). Li abbiamo quindi confrontati con text-embedding-3-large di OpenAI.
Punti chiave:
- L'ottimizzazione ha migliorato l'accuratezza del recupero su tutti i set di dati, superando spesso significativamente i modelli di base.
- Gli embedding ottimizzati hanno ottenuto risultati pari o migliori del reranking in molti casi, dimostrando che possono essere una solida soluzione autonoma.
- Un miglior recupero ha portato a migliori prestazioni RAG su FinanceBench, dimostrando benefici end-to-end.
Prestazioni di recupero
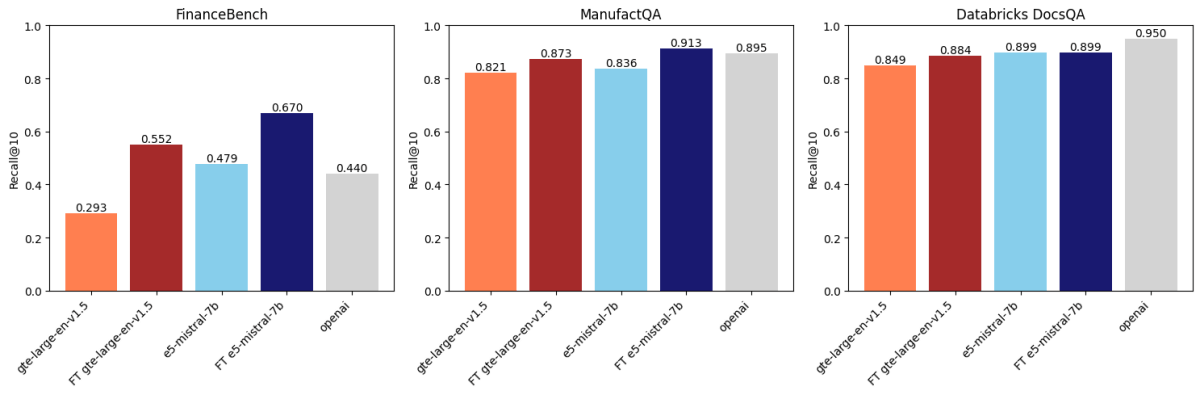
Dopo aver confrontato tre set di dati, abbiamo scoperto che l'ottimizzazione degli embedding migliora l'accuratezza su due di questi set di dati. La Figura 1 mostra che per FinanceBench e ManufactQA, gli embedding ottimizzati hanno superato le loro versioni di base, superando talvolta anche il modello API di OpenAI (grigio chiaro). Per Databricks DocsQA, tuttavia, l'accuratezza di text-embedding-3-large di OpenAI supera tutti i modelli ottimizzati. È possibile che ciò sia dovuto al fatto che il modello è stato addestrato sulla documentazione pubblica di Databricks. Ciò dimostra che, sebbene l'ottimizzazione possa essere efficace, dipende fortemente dal set di dati di addestramento e dall'attività di valutazione.
Ottimizzazione vs. Reranking
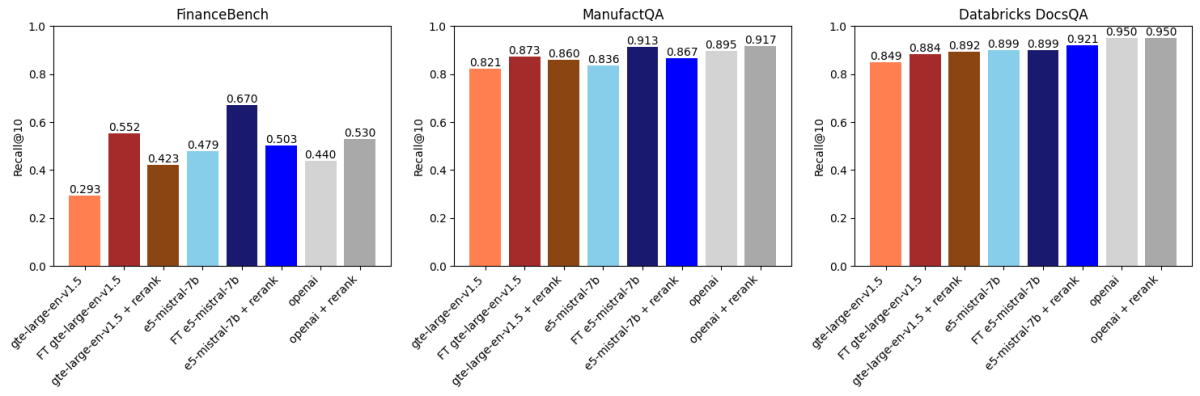
Abbiamo quindi confrontato i risultati precedenti con il reranking basato su API utilizzando voyageai/rerank-1 (Figura 2). Un reranker in genere prende i primi k risultati recuperati da un modello di embedding, riordina questi risultati in base alla pertinenza rispetto alla query di ricerca e quindi restituisce i primi k riordinati (nel nostro caso k=30 seguito da k=10). Questo funziona perché i reranker sono solitamente modelli più grandi e potenti rispetto ai modelli di embedding e modellano anche l'interazione tra la query e il documento in modo più espressivo.
{kind=link}
Quello che abbiamo scoperto è:
- L'ottimizzazione di gte-large-en-v1.5 ha superato il reranking su FinanceBench e ManufactQA.
- text-embedding-3-large di OpenAI ha beneficiato del reranking, ma i miglioramenti sono stati marginali su alcuni set di dati.
- Per Databricks DocsQA, il reranking ha avuto un impatto minore, ma l'ottimizzazione ha comunque portato miglioramenti, dimostrando la natura dipendente dal set di dati di questi metodi.
I reranker solitamente comportano latenza e costi di inferenza aggiuntivi per query rispetto ai modelli di embedding. Tuttavia, possono essere utilizzati con database vettoriali esistenti e in alcuni casi possono essere più convenienti rispetto al re-embedding dei dati con un modello di embedding più recente. La scelta se utilizzare un reranker dipende dal tuo dominio e dai tuoi requisiti di latenza/costo.
L'ottimizzazione migliora le prestazioni RAG
Per FinanceBench, un miglior recupero si è tradotto direttamente in migliore accuratezza RAG se combinato con GPT-4o (vedi Appendice). Tuttavia, in domini in cui il recupero era già forte, come Databricks DocsQA, l'ottimizzazione non ha aggiunto molto, evidenziando che l'ottimizzazione funziona meglio quando il recupero è un collo di bottiglia evidente.
Come abbiamo ottimizzato e valutato i modelli di embedding
Ecco alcuni dettagli più tecnici sulla generazione di dati sintetici, l'ottimizzazione e la valutazione.
Modelli di embedding
Abbiamo ottimizzato due modelli di embedding open-source:
- gte-large-en-v1.5 è un popolare modello di embedding basato su BERT Large (434 milioni di parametri, 1,75 GB). Abbiamo scelto di eseguire esperimenti su questo modello a causa delle sue dimensioni modeste e della licenza aperta. Questo modello di embedding è anche attualmente supportato sulla Databricks Foundation Model API.
- e5-mistral-7b-instruct appartiene a una classe più recente di modelli di embedding costruiti su LLM potenti (in questo caso Mistral-7b-instruct-v0.1). Sebbene e5-mistral-7b-instruct sia migliore nei benchmark di embedding standard come MTEB ed è in grado di gestire prompt più lunghi e sfumati, è molto più grande di gte-large-en-v1.5 (poiché ha 7 miliardi di parametri) ed è leggermente più lento e costoso da servire.
Li abbiamo quindi confrontati con text-embedding-3-large di OpenAI.
Set di dati di valutazione
Abbiamo valutato tutti i modelli sui seguenti set di dati dalla nostra Domain Intelligence Benchmark Suite (DIBS): FinanceBench, ManufactQA e Databricks DocsQA.
| Set di dati | Descrizione | # Query | # Corpus |
|---|---|---|---|
| FinanceBench | Domande relative a documenti SEC 10-K generate da esperti umani. Il recupero avviene su singole pagine da un sovrainsieme di 360 depositi SEC 10-K. | 150 | 53.399 |
| ManufactQA | Domande e risposte campionate da forum pubblici di un produttore di dispositivi elettronici. | 6.787 | 6.787 |
| Databricks DocsQA | Domande basate sulla documentazione Databricks pubblicamente disponibile, generate da esperti Databricks. | 139 | 7.561 |
Riportiamo recall@10 come metrica di recupero principale; questa misura se il documento corretto è tra i primi 10 documenti recuperati.
Lo standard di riferimento per la qualità dei modelli di embedding è il benchmark MTEB, che include task di recupero come BEIR e molti altri task non di recupero. Mentre modelli come gte-large-en-v1.5 e e5-mistral-7b-instruct ottengono buoni risultati su MTEB, eravamo curiosi di vedere come si comportassero nei nostri task aziendali interni.
Dati di Addestramento
Abbiamo addestrato modelli separati su dati sintetici su misura per ciascuno dei benchmark sopra indicati:
| Set di Addestramento | Descrizione | # Campioni Unici |
|---|---|---|
| Synthetic FinanceBench | Query generate da 2.400 documenti SEC 10-K | ~6.000 |
| Synthetic Databricks Docs QA | Query generate dalla documentazione pubblica Databricks. | 8.727 |
| ManufactQA | Query generate da PDF di produzione elettronica | 14.220 |
Per generare il set di addestramento per ciascun dominio, abbiamo preso documenti esistenti e generato query di esempio basate sul contenuto di ciascun documento utilizzando LLM come Llama 3 405B. Le query sintetiche sono state quindi filtrate per qualità da un LLM-as-a-judge (GPT4o). Le query filtrate e i relativi documenti sono stati quindi utilizzati come coppie contrastive per il finetuning. Abbiamo utilizzato negativi in-batch per l'addestramento contrastivo, ma l'aggiunta di negativi difficili potrebbe migliorare ulteriormente le prestazioni (vedi Appendice).
Ottimizzazione degli Iperparametri
Abbiamo eseguito sweep su:
- Tasso di apprendimento, dimensione del batch, temperatura softmax
- Conteggio epoche (testate 1-3 epoche)
- Variazioni del prompt di query (ad es. "Query:" vs. prompt basati su istruzioni)
- Strategia di pooling (mean pooling vs. last token pooling)
Tutto il finetuning è stato eseguito utilizzando le librerie open source mosaicml/composer, mosaicml/llm-foundry e mosaicml/streaming sulla piattaforma Databricks.
Come Migliorare AI Search e RAG su Databricks
Il finetuning è solo un approccio per migliorare le prestazioni di vector search e RAG; elenchiamo alcuni approcci aggiuntivi di seguito.
Per un Migliore Recupero:
- Utilizza un modello di embedding migliore: Molti utenti lavorano inconsapevolmente con embedding obsoleti. Sostituire semplicemente un modello con prestazioni superiori può portare a guadagni immediati. Controlla la classifica MTEB per i modelli migliori.
- Prova la ricerca ibrida: Combina embedding densi con la ricerca basata su parole chiave per una maggiore precisione. Databricks AI Search lo rende facile con una soluzione con un clic.
- Usa un reranker: Un reranker può perfezionare i risultati riordinandoli in base alla pertinenza. Databricks lo fornisce come funzionalità integrata (attualmente in Private Preview). Contatta il tuo Account Executive per provarlo.
Per un Migliore RAG:
- Ottimizza i tuoi prompt: Piccole modifiche nei prompt degli LLM possono migliorare notevolmente le risposte. DSPy può aiutare ad automatizzare questo processo (vedi Costruisci app genAI utilizzando DSPy su Databricks).
- Aggiorna il tuo LLM: Se il recupero è forte ma le risposte sono deboli, considera l'utilizzo di un modello generativo migliore.
- Finetune un LLM: Se il tuo dominio è unico e hai dati sufficienti, il finetuning di un modello come Llama 3 può migliorare ulteriormente la qualità del RAG. Vedi Databricks Model Training: Fine-Tune Your LLM on Databricks for Specialized Tasks and Knowledge per maggiori dettagli.
Inizia con il Finetuning su Databricks
Il finetuning degli embedding può essere una vittoria facile per migliorare il recupero e il RAG nei tuoi sistemi AI. Su Databricks, puoi:
- Finetune e servi modelli di embedding su infrastruttura scalabile.
- Utilizza strumenti integrati per vector search, reranking e RAG.
- Testa rapidamente diversi modelli per trovare quello che funziona meglio per il tuo caso d'uso.
Pronto a provare? Abbiamo creato una soluzione di riferimento per semplificare il finetuning: contatta il tuo Databricks Account Executive o Solutions Architect per ottenere l'accesso.
Appendice
Tabella 1: Confronto tra gte-large-en-v1.5, e5-mistral-7b-instruct e text-embedding-3-large. Stessi dati della Figura 1.
Generazione di Dati di Addestramento Sintetici
Per tutti i dataset, le query nel set di addestramento non erano le stesse delle query nel set di test. Tuttavia, nel caso di Databricks DocsQA (ma non per FinanceBench o ManufactQA), i documenti utilizzati per generare query sintetiche erano gli stessi documenti utilizzati nel set di valutazione. Il focus del nostro studio è migliorare il recupero su task e domini specifici (al contrario di un modello di embedding generalizzabile zero-shot); vediamo quindi questo come un approccio valido per determinati casi d'uso di produzione. Per FinanceBench e ManufactQA, i documenti utilizzati per generare dati sintetici non si sovrapponevano al corpus utilizzato per la valutazione.
Esistono vari modi per selezionare passaggi negativi per l'addestramento contrastivo. Possono essere selezionati casualmente o predefiniti. Nel primo caso, i passaggi negativi vengono selezionati all'interno del batch di addestramento; questi sono spesso definiti "in-batch negatives" o “soft negatives”. Nel secondo caso, l'utente pre-seleziona esempi di testo semanticamente difficili, cioè potenzialmente correlati alla query ma leggermente errati o irrilevanti. Questo secondo caso è talvolta chiamato "hard negatives". In questo lavoro, abbiamo semplicemente utilizzato in-batch negatives; la letteratura indica che l'uso di hard negatives porterebbe probabilmente a risultati ancora migliori.
Dettagli di Finetuning
Per tutti gli esperimenti di finetuning, la lunghezza massima della sequenza è impostata a 2048. Abbiamo quindi valutato tutti i checkpoint. Per tutto il benchmarking, i documenti del corpus sono stati troncati a 2048 token (non suddivisi in chunk), il che è stato un vincolo ragionevole per i nostri dataset specifici. Abbiamo scelto i baseline più forti su ciascun benchmark dopo aver eseguito una scansione dei prompt delle query e della strategia di pooling.
Migliorare le Prestazioni di RAG
Un sistema RAG è composto sia da un retriever che da un modello generativo. Il retriever seleziona un set di documenti pertinenti a una particolare query, e poi li passa al modello generativo. Abbiamo selezionato i migliori modelli gte-large-en-v1.5 finetuned e li abbiamo utilizzati per il primo stadio di recupero di un semplice sistema RAG (seguendo l'approccio generale descritto in Long Context RAG Performance of LLMs e The Long Context RAG Capabilities of OpenAI o1 and Google Gemini). In particolare, abbiamo recuperato k=10 documenti ciascuno con una lunghezza massima di 512 token e utilizzato GPT4o come LLM generativo. L'accuratezza finale è stata valutata utilizzando un LLM-as-a-judge (GPT4o).
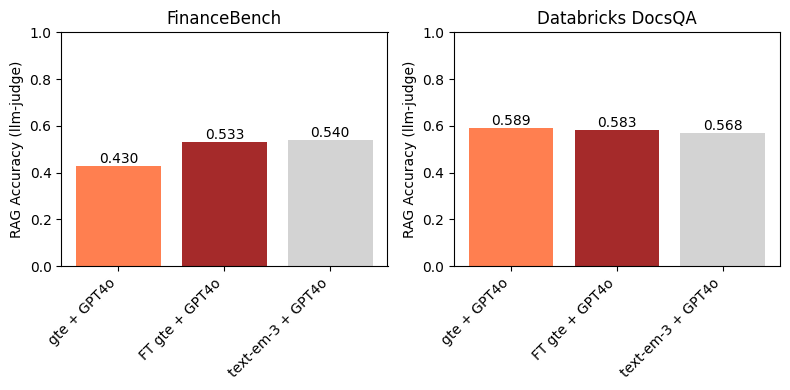
Su FinanceBench, la Figura 3 mostra che l'utilizzo di un modello di embedding finetuned porta a un miglioramento dell'accuratezza RAG downstream. Inoltre, è competitivo con text-embedding-3-large. Questo è previsto, poiché il finetuning di gte ha portato a un grande miglioramento in Recall@10 rispetto al baseline gte (Figura 1). Questo esempio evidenzia l'efficacia del finetuning del modello di embedding su domini e dataset specifici.
Sul dataset Databricks DocsQA, non riscontriamo miglioramenti quando utilizziamo il modello gte finetuned rispetto al baseline gte. Questo è in qualche modo previsto, poiché i margini tra i modelli baseline e finetuned nelle Figure 1 e 2 sono piccoli. Interessante notare che, anche se text-embedding-3-large ha un Recall@10 (leggermente) superiore a qualsiasi modello gte, non porta a un'accuratezza RAG downstream più elevata. Come mostrato nella Figura 1, tutti i modelli di embedding avevano un Recall@10 relativamente alto sul dataset Databricks DocsQA; questo indica che il recupero probabilmente non è il collo di bottiglia per RAG, e che il finetuning di un modello di embedding su questo dataset non è necessariamente l'approccio più fruttuoso.
Vorremmo ringraziare Quinn Leng e Matei Zaharia per il feedback su questo blogpost.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.