Migliorare le prestazioni di Text2SQL con facilità su Databricks
di Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta e Sam Shah
Vuoi portare il tuo LLM tra i primi 10 di Spider, un benchmark ampiamente utilizzato per i task text-to-SQL? Spider valuta quanto bene gli LLM possono convertire query di testo in codice SQL.
Per chi non ha familiarità con il text-to-SQL, la sua importanza risiede nel trasformare il modo in cui le aziende interagiscono con i propri dati. Invece di fare affidamento su esperti SQL per scrivere query, le persone possono semplicemente porre domande sui propri dati in linguaggio naturale e ricevere risposte precise. Questo democratizza l'accesso ai dati, migliora la business intelligence e consente un processo decisionale più informato.
Il benchmark Spider è uno standard ampiamente riconosciuto per la valutazione delle prestazioni dei sistemi text-to-SQL. Sfida gli LLM a tradurre query in linguaggio naturale in istruzioni SQL precise, richiedendo una profonda comprensione degli schemi del database e la capacità di generare codice SQL sintatticamente e semanticamente corretto.
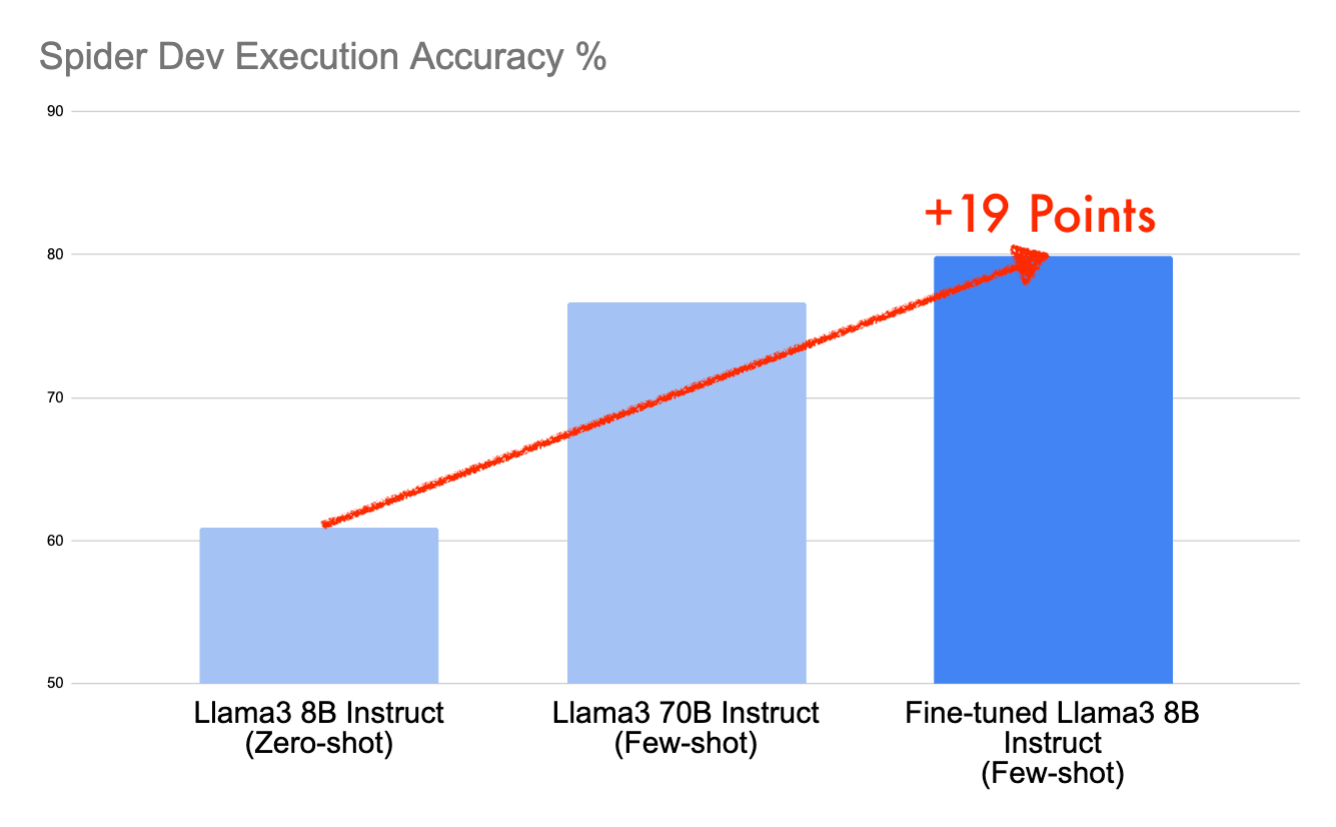
In questo post, approfondiremo come abbiamo ottenuto punteggi del 79,9% sul set di dati di sviluppo Spider e del 78,9% sul set di dati di test in meno di un giorno di lavoro utilizzando il modello open-source Llama3 8B Instruct – un notevole miglioramento di 19 punti rispetto al baseline. Questa performance ci collocherebbe in una posizione nella top 10 della classifica Spider, ora congelata, grazie a un prompting strategico e al fine-tuning su Databricks.
Prompting Zero-Shot per le Prestazioni Baseline
Iniziamo valutando le prestazioni di Meta Llama 3 8B Instruct sul set di dati di sviluppo Spider utilizzando un formato di prompt molto semplice composto dalle istruzioni CREATE TABLE che hanno creato le tabelle e da una domanda a cui vorremmo rispondere utilizzando tali tabelle:
Questo tipo di prompt è spesso definito "zero-shot" perché non ci sono altri esempi nel prompt. Per la prima domanda nel set di dati di sviluppo Spider, questo formato di prompt produce:
L'esecuzione del benchmark Spider sul set di dati di sviluppo utilizzando questo formato produce un punteggio complessivo di 60,9 se misurato tramite accuratezza di esecuzione e greedy decoding. Ciò significa che nel 60,9% dei casi il modello produce SQL che, una volta eseguito, produce gli stessi risultati di una query "gold" che rappresenta la soluzione corretta.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot | 78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Con il punteggio baseline stabilito, prima ancora di entrare nel fine-tuning, proviamo diverse strategie di prompting per cercare di aumentare il punteggio del modello base sul set di dati di sviluppo Spider.
Prompting con Righe di Esempio
Uno degli svantaggi del primo prompt che abbiamo utilizzato è che non include alcuna informazione sui dati nelle colonne oltre al tipo di dato. Un paper sulla valutazione delle capacità text-to-SQL dei modelli con Spider ha rilevato che l'aggiunta di righe di esempio al prompt ha portato a un punteggio più alto, quindi proviamo questo.
Possiamo aggiornare il formato del prompt sopra in modo che le istruzioni create table includano anche le prime righe di ogni tabella. Per la stessa domanda di prima, ora abbiamo un prompt aggiornato:
Includere righe di esempio per ogni tabella aumenta il punteggio complessivo di circa 6 punti percentuali a 67,0:
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot with sample rows | 80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
Prompting Few-Shot
Il prompting few-shot è una strategia ben nota utilizzata con gli LLM in cui possiamo migliorare le prestazioni su un task come la generazione di SQL corretto includendo alcuni esempi che dimostrano il task da eseguire. Con un prompt zero-shot abbiamo fornito gli schemi e poi posto una domanda. Con un prompt few-shot forniamo alcuni schemi, una domanda, il SQL che risponde a quella domanda, e poi ripetiamo quella sequenza un paio di volte prima di arrivare alla domanda effettiva che vogliamo porre. Questo generalmente si traduce in prestazioni migliori rispetto a un prompt zero-shot.
Una buona fonte di esempi che dimostrano il task di generazione SQL è in realtà il set di dati di addestramento Spider stesso. Possiamo prendere un campione casuale di alcune domande da questo dataset con le relative tabelle e costruire un prompt few-shot che dimostri il SQL che può rispondere a ciascuna di queste domande. Poiché stiamo ora utilizzando righe di esempio come nel prompt precedente, dovremmo anche assicurarci che uno di questi esempi includa anche righe di esempio per dimostrarne l'utilizzo.
Un altro miglioramento che possiamo apportare al precedente prompt zero-shot è includere anche un "system prompt" all'inizio. I system prompt sono tipicamente utilizzati per fornire indicazioni dettagliate al modello che delineano il task da eseguire. Mentre un utente può porre più domande nel corso di una chat con un modello, il system prompt viene fornito solo una volta prima che l'utente ponga una domanda, stabilendo essenzialmente le aspettative su come il "sistema" dovrebbe comportarsi durante la chat.
Con queste strategie in mente, possiamo costruire un prompt few-shot che inizia anche con un messaggio di sistema rappresentato da un grande blocco di commenti SQL in cima, seguito da tre esempi:
Questo nuovo prompt ha portato a un punteggio di 70,8, che rappresenta un ulteriore miglioramento di 3,8 punti percentuali rispetto al nostro punteggio precedente. Abbiamo aumentato il punteggio di quasi 10 punti percentuali rispetto a dove avevamo iniziato, solo attraverso semplici strategie di prompting.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows | 83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
Probabilmente stiamo raggiungendo il punto di rendimenti decrescenti dal tweaking del nostro prompt. Effettuiamo il fine-tuning del modello per vedere quali ulteriori guadagni si possono ottenere.
Fine-Tuning con LoRA
Se stiamo effettuando il fine-tuning del modello, la prima domanda è quali dati di addestramento utilizzare. Spider include un set di dati di addestramento, quindi questo sembra un buon punto di partenza. Per effettuare il fine-tuning del modello utilizzeremo QLoRA in modo da poter addestrare efficientemente il modello su un singolo cluster GPU Databricks A100 da 80GB, come Standard_NC24ads_A100_v4 in Databricks. Questo può essere completato in circa quattro ore utilizzando i 7k record nel set di dati di addestramento Spider. Abbiamo discusso in precedenza il fine-tuning con LoRA in un post del blog precedente. I lettori interessati possono fare riferimento a quel post per maggiori dettagli. Possiamo seguire ricette di addestramento standard utilizzando le librerie trl, peft e bitsandbytes.
Anche se stiamo ottenendo i record di addestramento da Spider, dobbiamo comunque formattarli in modo che il modello possa imparare da essi. L'obiettivo è mappare ogni record, composto dallo schema (con righe di esempio), dalla domanda e dalla query SQL in una singola stringa di testo. Iniziamo eseguendo alcune elaborazioni sul set di dati grezzo di Spider. Dai dati grezzi produciamo un set di dati in cui ogni record è composto da tre campi: schema_with_rows, question e query. Il campo schema_with_rows è derivato dalle tabelle corrispondenti alla domanda, seguendo la formattazione dell'istruzione CREATE TABLE e le righe utilizzate nel prompt few-shot precedente.
Successivamente carichiamo il tokenizer:
Definiremo una funzione di mappatura che convertirà ogni record dal nostro set di dati di addestramento Spider elaborato in una stringa di testo. Possiamo utilizzare apply_chat_template dal tokenizer per formattare comodamente il testo nel formato chat previsto dal modello Instruct. Sebbene questo non sia esattamente lo stesso formato che stiamo utilizzando per il nostro prompt few-shot, il modello generalizza abbastanza bene da funzionare anche se la formattazione boilerplate dei prompt è leggermente diversa.
Per SYSTEM_PROMPT utilizziamo lo stesso prompt di sistema utilizzato nel prompt few-shot precedente. Per USER_MESSAGE_FORMAT utilizziamo analogamente:
Con questa funzione definita, tutto ciò che resta è trasformare il set di dati Spider elaborato con essa e salvarlo come file JSONL.
Ora siamo pronti per l'addestramento. Poche ore dopo abbiamo un Llama3 8B Instruct fine-tuned. Rieseguendo il nostro prompt few-shot su questo nuovo modello si è ottenuto un punteggio di 79.9, che rappresenta un ulteriore miglioramento di 9 punti percentuali rispetto al nostro punteggio precedente. Abbiamo ora aumentato il punteggio totale di circa 19 punti percentuali rispetto al nostro semplice baseline zero-shot.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows (Fine-tuned Llama3 8B Instruct) |
91.1 | 85.9 | 72.4 | 54.8 | 79.9 |
| Few-shot with sample rows (Llama3 8B Instruct) |
83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
| Zero-shot with sample rows (Llama3 8B Instruct) |
80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
| Zero-shot (Llama3 8B Instruct) |
78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Potresti chiederti ora come il modello Llama3 8B Instruct e la sua versione fine-tuned si confrontino con un modello più grande come Llama3 70B Instruct. Abbiamo ripetuto il processo di valutazione utilizzando il modello 70B off-the-shelf sul set di dati dev con otto GPU A100 da 40 GB e registrato i risultati qui sotto.
| Few-shot with sample rows (Llama3 70B Instruct) |
89.5 | 83.0 | 64.9 | 53.0 | 76.7 |
| Zero-shot with sample rows (Llama3 70B Instruct) |
83.1 | 81.8 | 59.2 | 36.7 | 71.1 |
| Zero-shot (Llama3 70B Instruct) |
82.3 | 80.5 | 57.5 | 31.9 | 69.2 |
Come previsto, confrontando i modelli off-the-shelf, il modello 70B batte il modello 8B se misurato utilizzando lo stesso formato di prompt. Ma ciò che sorprende è che il modello Llama3 8B Instruct fine-tuned ottiene un punteggio superiore al modello Llama3 70B Instruct di 3 punti percentuali. Quando ci si concentra su attività specifiche come il text-to-SQL, il fine-tuning può portare a modelli piccoli che sono comparabili in termini di prestazioni con modelli di dimensioni molto maggiori.
Deploy to a Model Serving Endpoint
Llama3 è supportato da Databricks Model Serving, quindi potremmo persino distribuire il nostro modello Llama3 fine-tuned a un endpoint e utilizzarlo per alimentare applicazioni. Tutto ciò che dobbiamo fare è registrare il modello fine-tuned in Unity Catalog e quindi creare un endpoint utilizzando l'interfaccia utente. Una volta distribuito, possiamo interrogarlo utilizzando librerie comuni.
Wrapping Up
Abbiamo iniziato il nostro percorso con Llama3 8B Instruct sul set di dati dev di Spider utilizzando un prompt zero-shot, ottenendo un punteggio modesto di 60.9. Migliorando questo con un prompt few-shot — completo di messaggi di sistema, esempi multipli e righe di esempio — abbiamo aumentato il nostro punteggio a 70.8. Ulteriori guadagni sono derivati dal fine-tuning del modello sul set di dati di addestramento Spider, portandoci a un impressionante 79.9 su Spider dev e 78.9 su Spider test. Questo aumento significativo di 19 punti rispetto al nostro punto di partenza e un vantaggio di 3 punti sul Llama3 70B Instruct di base non solo dimostra la potenza del nostro modello, ma ci assicurerebbe anche un posto ambito tra i primi 10 risultati su Spider.
Scopri di più su come sfruttare la potenza degli LLM open source e della Data Intelligence Platform registrandoti a Data+AI Summit.
Appendix
Evaluation Setup
La generazione è stata eseguita utilizzando vLLM, greedy decoding (temperatura 0), due GPU A100 da 80 GB e 1024 token massimi di nuova generazione. Per valutare le generazioni abbiamo utilizzato la suite di test dal repository taoyds/test-suite-sql-eval su Github.
Training Setup
Ecco i dettagli specifici sulla configurazione del fine-tuning:
| Base Model | Llama3 8B Instruct |
| GPUs | Single A100 80GB |
| Max Steps | 100 |
| Spider train dataset records | 7000 |
| Lora R | 16 |
| Lora Alpha | 32 |
| Lora Dropout | 0.1 |
| Learning Rate | 1.5e-4 |
| Learning Rate Scheduler | Constant |
| Gradient Accumulation Steps | 8 |
| Gradient Checkpointing | True |
| Train Batch Size | 12 |
| LoRA Target Modules | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Modello di risposta del Data Collator | <|start_header_id|>assistant<|end_header_id|> |
Esempio di prompt zero-shot
Questo è il primo record dal set di dati dev che abbiamo utilizzato per la valutazione, formattato come un prompt zero-shot che include gli schemi delle tabelle. Le tabelle a cui si riferisce la domanda sono rappresentate utilizzando le istruzioni CREATE TABLE che le hanno create.
Esempio di prompt zero-shot con righe di esempio
Questo è il primo record dal set di dati dev che abbiamo utilizzato per la valutazione, formattato come un prompt zero-shot che include gli schemi delle tabelle e righe di esempio. Le tabelle a cui si riferisce la domanda sono rappresentate utilizzando le istruzioni CREATE TABLE che le hanno create. Le righe sono state selezionate utilizzando "SELECT * {table_name} LIMIT 3" da ogni tabella, con i nomi delle colonne che appaiono come intestazione.
Esempio di prompt few-shot con righe di esempio
Questo è il primo record dal set di dati dev che abbiamo utilizzato per la valutazione, formattato come un prompt few-shot che include gli schemi delle tabelle e righe di esempio. Le tabelle a cui si riferisce la domanda sono rappresentate utilizzando le istruzioni CREATE TABLE che le hanno create. Le righe sono state selezionate utilizzando "SELECT * {table_name} LIMIT 3" da ogni tabella, con i nomi delle colonne che appaiono come intestazione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.