Bilancia in modo intelligente ottimizzazione dei costi e affidabilità su Databricks
Approfondisci l'intersezione tra gestione finanziaria e cloud computing sulla Piattaforma di Data Intelligence Databricks
di Vuong Nguyen e Wasim Ahmad
La Databricks Data Intelligence Platform offre una flessibilità senza pari, consentendo agli utenti di accedere a risorse di calcolo scalabili orizzontalmente e quasi istantanee. Questa facilità di creazione può portare a costi cloud incontrollati se non gestiti correttamente.
Implementa l'Osservabilità per Tracciare e Addebitare i Costi
Come utilizzare efficacemente l'osservabilità per tracciare e addebitare i costi in Databricks
Quando si lavora con ecosistemi tecnici complessi, comprendere in modo proattivo gli elementi sconosciuti è fondamentale per mantenere la stabilità della piattaforma e controllare i costi. L'osservabilità fornisce un modo per analizzare e ottimizzare i sistemi in base ai dati che generano. Questo è diverso dal monitoraggio, che si concentra sull'identificazione di nuovi pattern piuttosto che sul tracciamento di problemi noti.
Funzionalità chiave per il tracciamento dei costi in Databricks
Tagging: Utilizza i tag per categorizzare risorse e addebiti. Ciò consente un'allocazione dei costi più granulare.
Tabelle di sistema: Sfrutta le tabelle di sistema per il tracciamento automatico dei costi e il chargeback. Strumenti di monitoraggio dei costi nativi del cloud: Utilizza questi strumenti per ottenere informazioni sui costi di tutte le risorse.
Cosa sono le Tabelle di Sistema e come utilizzarle
Databricks offre eccellenti capacità di osservabilità utilizzando tabelle di sistema. Le tabelle di sistema sono archivi analitici ospitati da Databricks dei dati operativi dell'account di un cliente presenti nel catalogo di sistema. Forniscono osservabilità storica sull'account e includono informazioni tabellari di facile consultazione sulla telemetria della piattaforma. Informazioni chiave come i dati di utilizzo della fatturazione sono disponibili nelle tabelle di sistema (attualmente include solo il prezzo di listino delle DBU), con ogni record di utilizzo che rappresenta un aggregato orario dell'utilizzo fatturabile di una risorsa.
Come abilitare le tabelle di sistema
Le tabelle di sistema sono gestite da Unity Catalog e richiedono un workspace abilitato per Unity Catalog per accedervi. Includono dati da tutti i workspace ma possono essere interrogati solo da workspace abilitati. L'abilitazione delle tabelle di sistema avviene a livello di schema: l'abilitazione di uno schema abilita tutte le sue tabelle. Gli amministratori devono abilitare manualmente i nuovi schemi utilizzando l'API.

Cosa sono i Tag di Databricks e come utilizzarli
Il tagging di Databricks ti consente di applicare attributi (coppie chiave-valore) alle risorse per una migliore organizzazione, ricerca e gestione. Per il tracciamento dei costi e il chargeback, i team possono taggare i loro job Databricks e il calcolo (Cluster, SQL warehouse), il che può aiutarli a tracciare l'utilizzo, i costi e attribuirli a team o unità specifiche.
Come applicare i tag
I tag possono essere applicati alle seguenti risorse Databricks per il tracciamento dell'utilizzo e dei costi:
- Calcolo Databricks
- Job Databricks
Una volta applicati questi tag, è possibile eseguire un'analisi dettagliata dei costi utilizzando le tabelle di sistema per l'utilizzo fatturabile.
Come identificare i costi utilizzando strumenti nativi del cloud
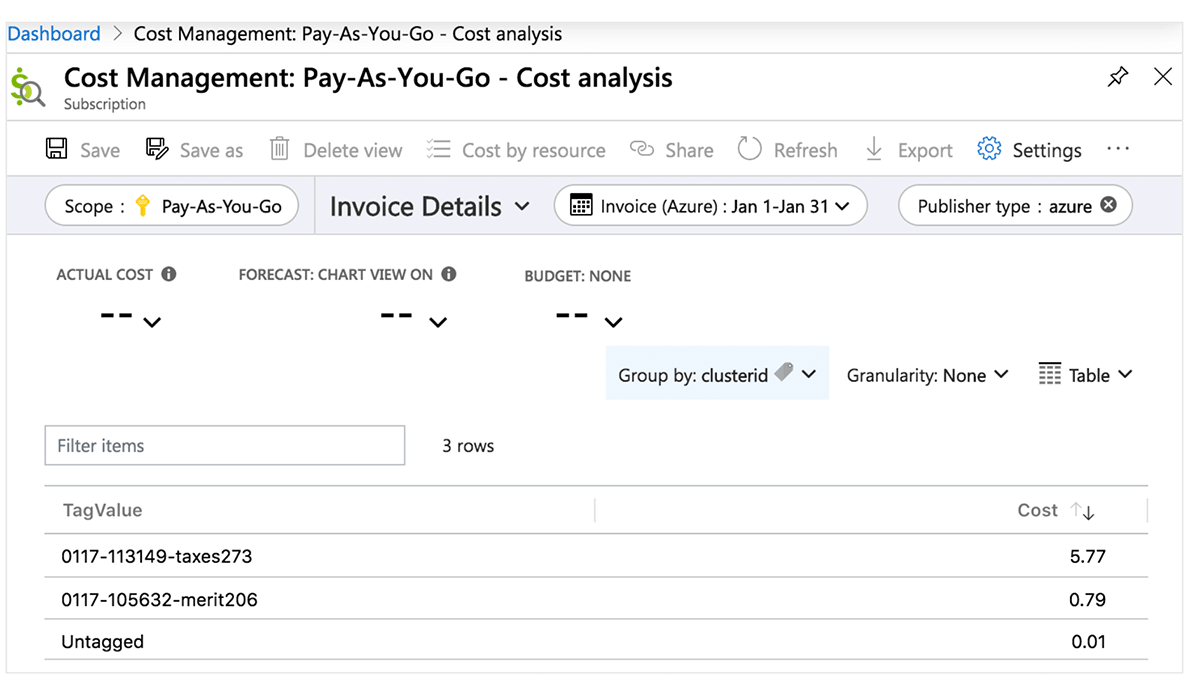
Per monitorare i costi e attribuire accuratamente l'utilizzo di Databricks alle unità di business e ai team della tua organizzazione (ad esempio, per il chargeback), puoi taggare i workspace (e i relativi gruppi di risorse gestiti) nonché le risorse di calcolo.
Centro Costi Azure
La seguente tabella illustra gli oggetti Azure Databricks a cui è possibile applicare i tag. Questi tag possono propagarsi a report di analisi dei costi dettagliati che puoi accedere nel portale e alla tabella di sistema per l'utilizzo fatturabile. Trova maggiori dettagli sulla propagazione dei tag e sulle limitazioni in Azure.
| Oggetto Azure Databricks | Interfaccia di Tagging (UI) | Interfaccia di Tagging (API) |
|---|---|---|
| Workspace | Portale Azure | API Risorse Azure |
| Pool | UI Pool nell'ambiente Databricks Azure | API Instance Pool |
| Calcolo All-purpose e Job | UI Calcolo nell'ambiente Databricks Azure | API Cluster |
| SQL Warehouse | UI SQL warehouse nell'ambiente Databricks Azure | API Warehouse |
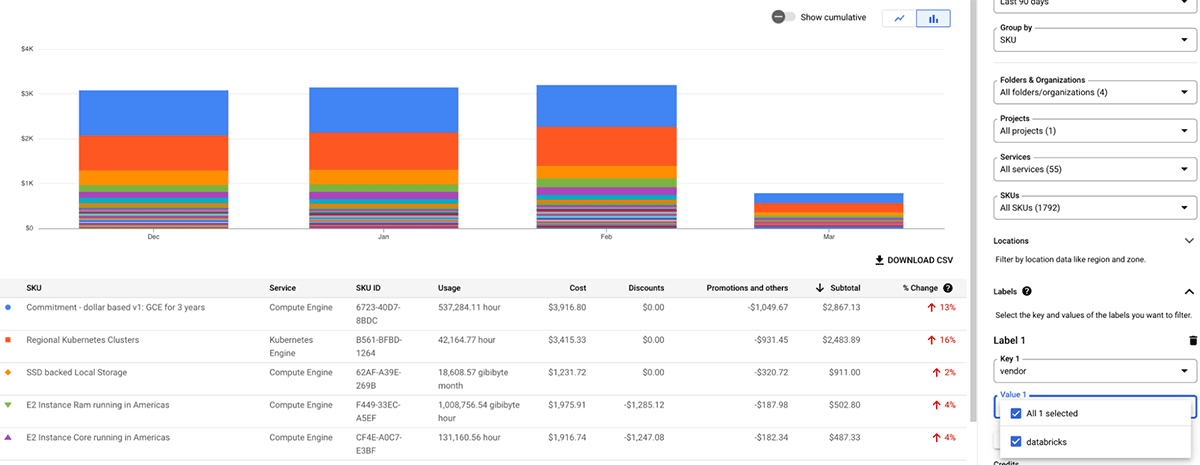
AWS Cost Explorer
La seguente tabella illustra gli Oggetti Databricks AWS a cui è possibile applicare i tag. Questi tag possono propagarsi sia ai log di utilizzo che alle istanze AWS EC2 e AWS EBS per l'analisi dei costi. Databricks consiglia di utilizzare le tabelle di sistema (Anteprima Pubblica) per visualizzare i dati di utilizzo fatturabile. Trova maggiori dettagli sulla propagazione dei tag e sulle limitazioni in AWS.
| Oggetto Databricks AWS | Interfaccia di Tagging (UI) | Interfaccia di Tagging (API) |
|---|---|---|
| Workspace | N/A | API Account |
| Pool | UI Pool nell'ambiente Databricks | API Instance Pool |
| Calcolo All-purpose e Job | UI Calcolo nell'ambiente Databricks | API Cluster |
| SQL Warehouse | UI SQL warehouse nell'ambiente Databricks | API Warehouse |
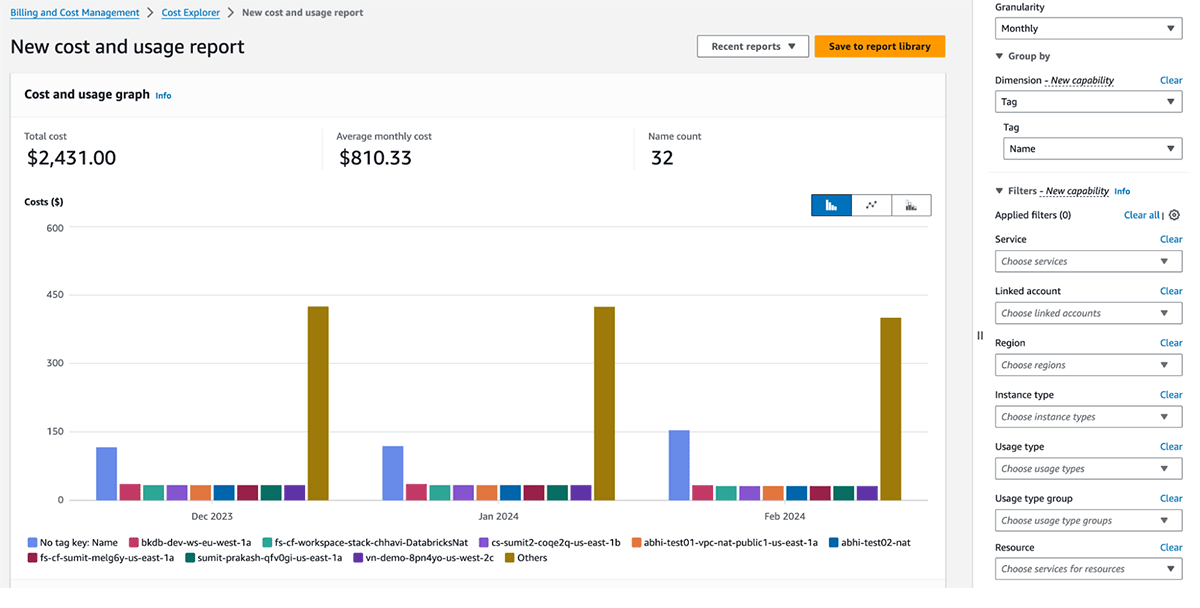
Gestione costi e fatturazione GCP
La seguente tabella illustra gli oggetti Databricks GCP a cui è possibile applicare tag. Questi tag/etichette possono essere applicati alle risorse di calcolo. Trova maggiori dettagli sulla propagazione dei tag/etichette e sulle limitazioni in GCP.
I grafici di utilizzo fatturabile di Databricks nella console dell'account possono aggregare l'utilizzo per singoli tag. Anche i report CSV sull'utilizzo fatturabile scaricati dalla stessa pagina includono tag predefiniti e personalizzati. I tag si propagano anche alle etichette GKE e GCE.
| Oggetto Databricks GCP | Interfaccia di Tagging (UI) | Interfaccia di Tagging (API) |
|---|---|---|
| Pool | UI Pool nell'ambiente Databricks | API Instance Pool |
| Calcolo per tutti gli scopi e per i processi | Interfaccia utente di calcolo nell'area di lavoro Databricks | API Cluster |
| SQL Warehouse | Interfaccia utente di SQL warehouse nell'area di lavoro Databricks | API Warehouse |
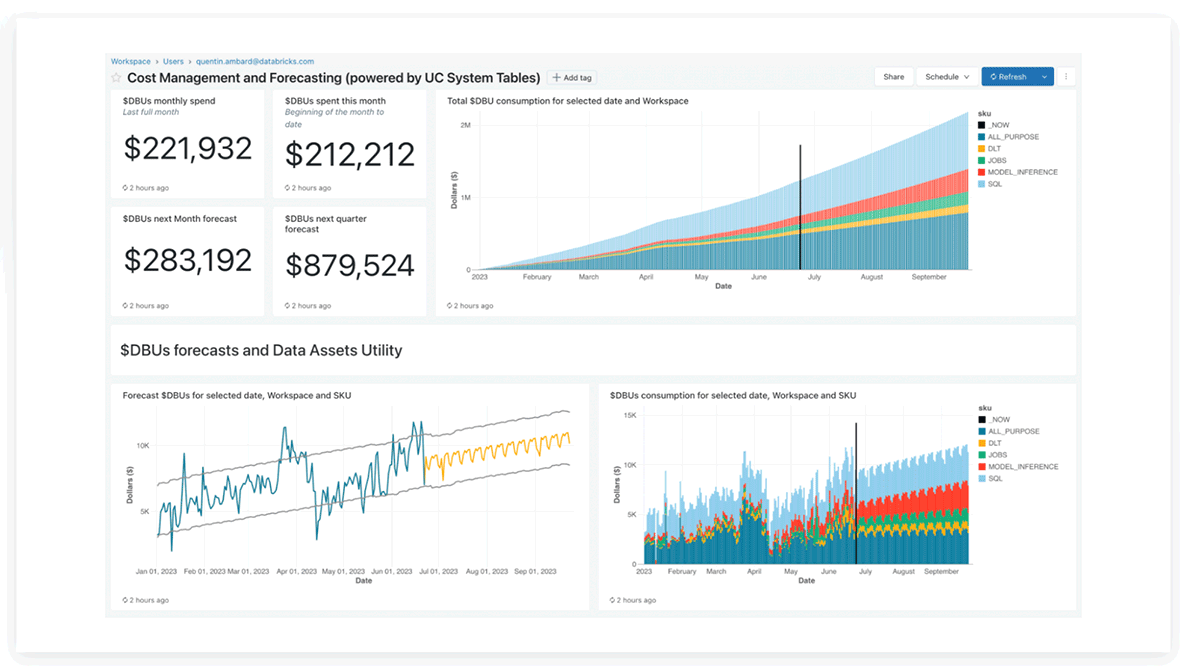
Dashboard di Lakeview per le tabelle di sistema Databricks
Il team di prodotto Databricks ha fornito dashboard Lakeview preconfigurate per l'analisi dei costi e la previsione utilizzando le tabelle di sistema, che i clienti possono anche personalizzare.
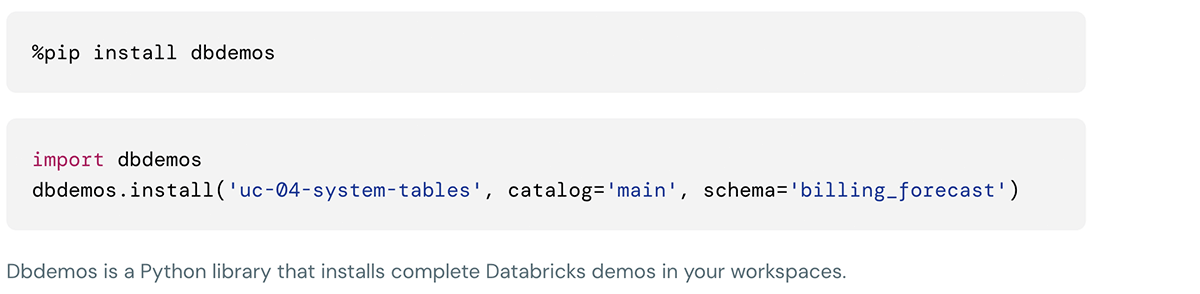
Questa demo può essere installata utilizzando i seguenti comandi nella cella dei notebook Databricks:
Migliori pratiche per massimizzare il valore
Quando si eseguono carichi di lavoro su Databricks, la scelta della configurazione di calcolo corretta migliorerà significativamente le metriche di costo/prestazioni. Di seguito sono riportate alcune tecniche pratiche di ottimizzazione dei costi:
Utilizzare il tipo di calcolo giusto per il lavoro giusto
Per i carichi di lavoro SQL interattivi, SQL warehouse è il motore più conveniente. Ancora più efficiente potrebbe essere il calcolo Serverless, che offre un tempo di avvio molto rapido per i SQL warehouse e consente un tempo di auto-terminazione più breve.
Per i carichi di lavoro non interattivi, i cluster di processi (Jobs) costano significativamente meno dei cluster per tutti gli scopi. I flussi di lavoro multi-task (Multitask workflows) possono riutilizzare le risorse di calcolo per tutti i task, riducendo ulteriormente i costi.
Scegliere il tipo di istanza corretto
L'utilizzo dell'ultima generazione di tipi di istanze cloud porterà quasi sempre benefici in termini di prestazioni, poiché sono dotate delle migliori prestazioni e delle funzionalità più recenti. Su AWS, le istanze Amazon EC2 basate su Graviton2 possono offrire prestazioni prezzo fino a 3 volte migliori rispetto alle istanze Amazon EC2 comparabili.
In base ai tuoi carichi di lavoro, è anche importante scegliere la famiglia di istanze corretta. Alcune semplici regole generali sono:
- Ottimizzate per la memoria per carichi di lavoro ML, shuffle e spill intensivi
- Ottimizzate per il calcolo per carichi di lavoro Structured Streaming, processi di manutenzione (ad es. Optimize & Vacuum)
- Ottimizzate per lo storage per carichi di lavoro che beneficiano della cache, ad es. analisi dati ad hoc e interattive
- Ottimizzate per GPU per carichi di lavoro ML e DL specifici
- Uso generale in assenza di requisiti specifici
Scegliere il Runtime corretto
L'ultimo Databricks Runtime (DBR) di solito offre prestazioni migliorate e sarà quasi sempre più veloce di quello precedente.
Photon è un motore di query vettorializzato nativo di Databricks ad alte prestazioni che esegue i tuoi carichi di lavoro SQL e le chiamate alle API DataFrame più velocemente per ridurre il costo totale per carico di lavoro. Per questi carichi di lavoro, l'abilitazione di Photon potrebbe portare significativi risparmi sui costi.
Sfruttare l'Autoscaling nel Calcolo Databricks
Databricks fornisce una funzionalità unica di autoscaling dei cluster che semplifica il raggiungimento di un elevato utilizzo del cluster perché non è necessario fornire il cluster per adattarlo a un carico di lavoro. Questo è particolarmente utile per carichi di lavoro interattivi o carichi di lavoro batch con carico di dati variabile. Tuttavia, l'autoscaling classico non funziona con i carichi di lavoro Structured Streaming, motivo per cui abbiamo sviluppato l'Autoscaling Avanzato (Enhanced Autoscaling) in Delta Live Tables per gestire i carichi di lavoro in streaming che sono picchi e imprevedibili.
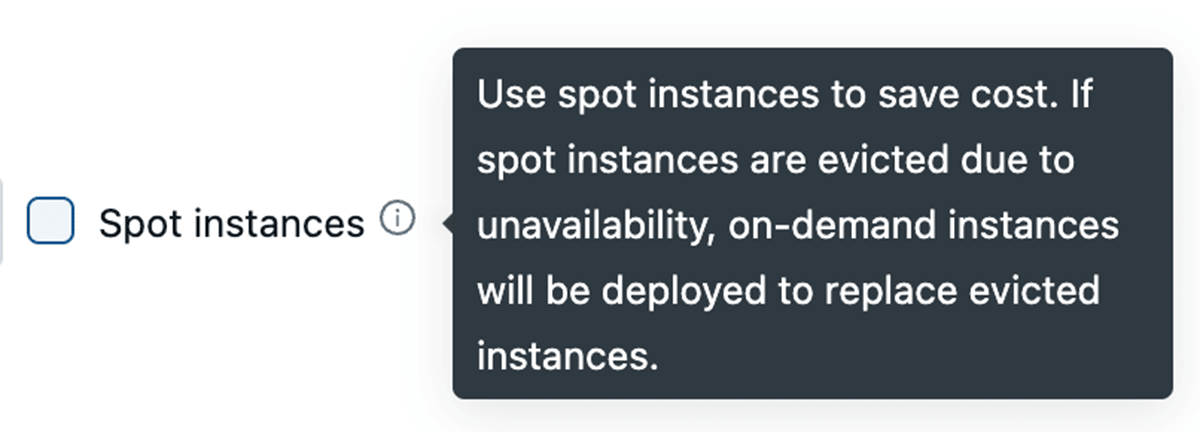
Sfruttare le Istanze Spot
Tutti i principali provider cloud offrono istanze spot che consentono di accedere alla capacità inutilizzata nei loro data center per un costo fino al 90% inferiore rispetto alle normali istanze On-Demand. Databricks consente di sfruttare queste istanze spot, con la possibilità di tornare automaticamente alle istanze On-Demand in caso di terminazione per ridurre al minimo le interruzioni. Per la stabilità del cluster, si consiglia di utilizzare nodi driver On-Demand.
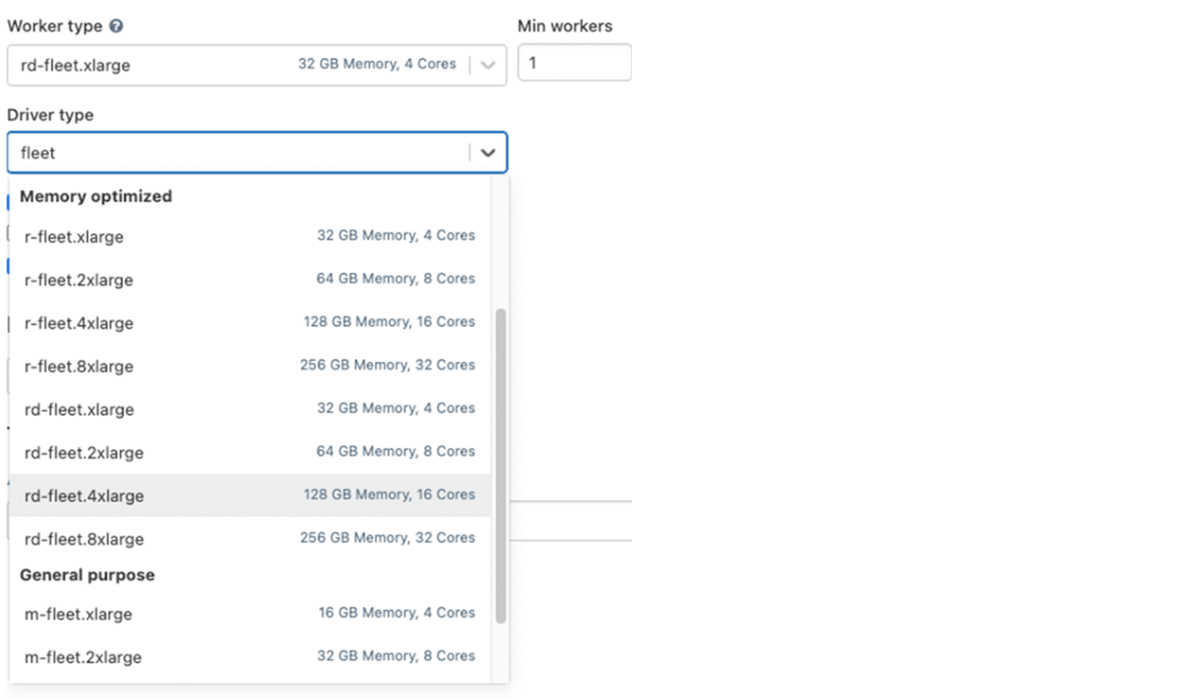
Sfruttare il tipo di istanza Fleet (su AWS)
Sotto il cofano, quando un cluster utilizza uno di questi tipi di istanza fleet, Databricks selezionerà i tipi di istanza fisica AWS corrispondenti con il miglior prezzo e disponibilità da utilizzare nel tuo cluster.
Politica del Cluster (Cluster Policy)
L'uso efficace delle politiche dei cluster consente agli amministratori di imporre restrizioni specifiche sui costi per gli utenti finali:
- Abilitare l'auto-terminazione del cluster con un valore ragionevole (ad esempio, 1 ora) per evitare di pagare per i tempi di inattività.
- Garantire che possano essere selezionate solo istanze VM convenienti
- Imporre tag obbligatori per l'addebito dei costi
- Controllare il profilo di costo complessivo limitando il costo massimo per cluster, ad esempio il numero massimo di DBU all'ora o le risorse di calcolo massime per utente
Ottimizzazione dei costi basata sull'IA
La Piattaforma di Intelligenza dei Dati Databricks integra funzionalità AI avanzate che ottimizzano le prestazioni, riducono i costi, migliorano la governance e semplificano lo sviluppo di applicazioni AI enterprise. Predictive I/O e Liquid Clustering migliorano la velocità delle query e l'utilizzo delle risorse, mentre la gestione intelligente dei carichi di lavoro ottimizza l'autoscaling per l'efficienza dei costi. Nel complesso, la piattaforma Databricks offre una suite completa di strumenti AI per aumentare la produttività e i risparmi sui costi, consentendo al contempo soluzioni innovative per casi d'uso specifici del settore.
Liquid Clustering
Il liquid clustering di Delta Lake sostituisce il partizionamento delle tabelle e ZORDER per semplificare le decisioni sul layout dei dati e ottimizzare le prestazioni delle query. Liquid clustering offre la flessibilità di ridefinire le chiavi di clustering senza riscrivere i dati esistenti, consentendo al layout dei dati di evolvere nel tempo insieme alle esigenze analitiche.
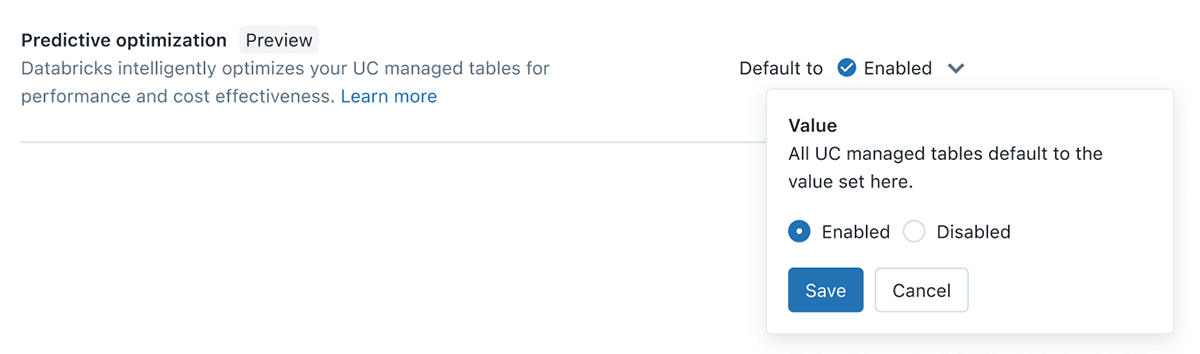
Ottimizzazione Predittiva (Predictive Optimization)
I data engineer sul lakehouse avranno familiarità con la necessità di ottimizzare e svuotare regolarmente le loro tabelle (OPTIMIZE & VACUUM), tuttavia ciò crea sfide continue per identificare le tabelle giuste, la pianificazione appropriata e la dimensione di calcolo giusta per l'esecuzione di questi processi. Con Predictive Optimization, sfruttiamo Unity Catalog e Lakehouse AI per determinare le migliori ottimizzazioni da eseguire sui tuoi dati, e quindi eseguiamo tali operazioni su un'infrastruttura serverless dedicata. Tutto ciò avviene automaticamente, garantendo le migliori prestazioni senza sprechi di calcolo o sforzi di ottimizzazione manuale.
Vista Materializzata con Aggiornamento Incrementale
In Databricks, Materialized Views (MVs) sono tabelle gestite da Unity Catalog che consentono agli utenti di pre-calcolare i risultati basati sull'ultima versione dei dati nelle tabelle di origine. Costruite su Delta Live Tables & serverless, le MV riducono la latenza delle query pre-calcolando query altrimenti lente e calcoli usati frequentemente. Quando possibile, i risultati vengono aggiornati in modo incrementale, ma i risultati sono identici a quelli che verrebbero forniti da un ricalcolo completo. Ciò riduce i costi computazionali ed evita la necessità di mantenere cluster separati
Funzionalità serverless per casi d'uso di Model Serving & Gen AI
Per supportare meglio i casi d'uso di model serving e Gen AI, Databricks ha introdotto diverse funzionalità sulla nostra infrastruttura serverless che scala automaticamente in base ai tuoi flussi di lavoro senza la necessità di configurare istanze e tipi di server.
- AI Search: Indice vettoriale che può essere sincronizzato da qualsiasi Delta Table con 1 clic - non sono necessarie pipeline di ingestion/sync dati complesse e personalizzate.
- Online Tables: Tabelle completamente serverless che scalano automaticamente la capacità di throughput con il carico delle richieste e forniscono accesso a bassa latenza e alto throughput ai dati di qualsiasi scala
- Model Serving: servizio altamente disponibile e a bassa latenza per il deployment di modelli. Il servizio scala automaticamente verso l'alto o verso il basso per soddisfare le variazioni della domanda, risparmiando sui costi dell'infrastruttura e ottimizzando le prestazioni di latenza
Predictive I/O per aggiornamenti ed eliminazioni
Con queste funzionalità basate sull'AI, Databricks SQL può ora analizzare i pattern storici di lettura e scrittura per costruire in modo intelligente indici e ottimizzare i carichi di lavoro. Predictive I/O è una raccolta di ottimizzazioni Databricks che migliorano le prestazioni per le interazioni con i dati. Le funzionalità di Predictive I/O sono raggruppate nelle seguenti categorie:
- Le letture accelerate riducono il tempo necessario per scansionare e leggere i dati. Utilizza tecniche di deep learning per raggiungere questo obiettivo. Maggiori dettagli sono disponibili in questa documentazione
- Gli aggiornamenti accelerati riducono la quantità di dati che devono essere riscritti durante aggiornamenti, eliminazioni e merge. Predictive I/O sfrutta i deletion vectors per accelerare gli aggiornamenti riducendo la frequenza di riscrittura completa dei file durante la modifica dei dati sulle tabelle Delta. Predictive I/O ottimizza le operazioni
DELETE,MERGEeUPDATE. Maggiori dettagli sono disponibili in questa documentazione
Predictive I/O è esclusivo del motore Photon su Databricks.
Gestione intelligente dei carichi di lavoro (IWM)
Uno dei principali problemi degli amministratori di piattaforme tecniche è la gestione di diversi warehouse per carichi di lavoro piccoli e grandi e assicurarsi che il codice sia ottimizzato e messo a punto per essere eseguito in modo ottimale e sfruttare appieno la capacità dell'infrastruttura di calcolo. IWM è una suite di funzionalità che aiuta con le sfide sopra menzionate e aiuta a eseguire questi carichi di lavoro più velocemente mantenendo i costi bassi. Raggiunge questo obiettivo analizzando pattern in tempo reale e garantendo che i carichi di lavoro abbiano la quantità ottimale di calcolo per eseguire le istruzioni SQL in ingresso senza interrompere le query già in esecuzione.
La giusta base FinOps - tramite tagging, policy e reporting - è cruciale per la trasparenza e il ROI della tua Piattaforma di Intelligenza dei Dati. Ti aiuta a realizzare valore di business più velocemente e a costruire un'azienda di maggior successo.
Utilizza serverless e DatabricksIQ per una configurazione rapida, efficienza dei costi e ottimizzazioni automatiche che si adattano ai tuoi pattern di carico di lavoro. Ciò porta a un TCO inferiore, una maggiore affidabilità e operazioni più semplici ed economiche.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.