Presentazione di AI Runtime: GPU NVIDIA Serverless e Scalabili su Databricks per Training e Finetuning
Addestra gli ultimi LLM con GPU NVIDIA H100 istantaneamente disponibili connesse al tuo Lakehouse
di Tejas Sundaresan, Jianwei Xie, Bandish Shah e Hanlin Tang
- Con AI Runtime, Databricks ora supporta le GPU NVIDIA in Serverless Compute, consentendo l'accesso on-demand a NVIDIA A10 e H100 scalabili senza overhead infrastrutturale.
- Addestra modelli di computer vision, LLM, sistemi di raccomandazione basati sul deep learning e altri modelli con il nostro runtime dedicato per l'addestramento distribuito – tutto pronto all'uso.
- AI Runtime è integrato con il caricamento dati ad alta velocità dai dati di Lakehouse, l'orchestrazione del workflow con Lakeflow e la governance con Unity Catalog.
Le GPU sono alla base dei carichi di lavoro AI più avanzati di oggi, dalla previsione e raccomandazione ai modelli fondazionali multimodali. Tuttavia, i team incontrano difficoltà nell'approvvigionamento e nella gestione dell'infrastruttura GPU, nella configurazione di ambienti di training distribuiti e nel debug dei colli di bottiglia nel caricamento dei dati. I ricercatori di deep learning preferiscono concentrarsi sulla modellazione, non sulla risoluzione dei problemi dell'infrastruttura.
Siamo entusiasti di annunciare l'anteprima pubblica di AI Runtime (AIR), un nuovo stack di training che abilita il training distribuito GPU on-demand su A10 e H100. AI Runtime contiene tutta la tecnologia utilizzata per il training su larga scala di LLM come MPT e DBRX. Anche in Beta, diverse centinaia di clienti, tra cui Rivian, Factset e YipitData, hanno utilizzato AIR per addestrare e distribuire modelli di deep learning in produzione. I casi d'uso spaziano dai modelli di computer vision ai sistemi di raccomandazione fino agli LLM finetuned per attività agenti. Il nostro team Databricks AI Research ha utilizzato AIR per il reinforcement learning di modelli come nel nostro recente paper KARL.
Con AI Runtime, gli utenti Databricks hanno ora:
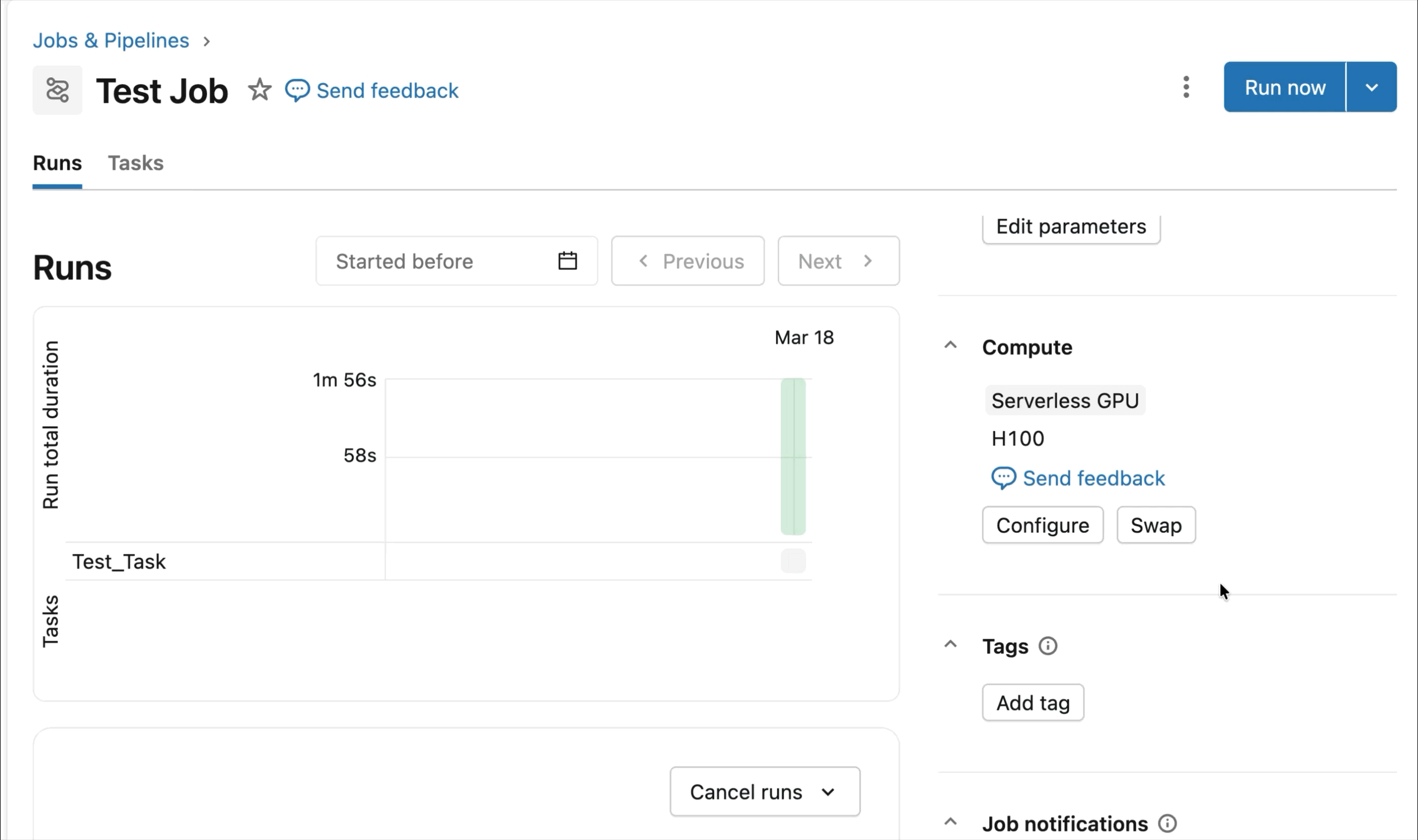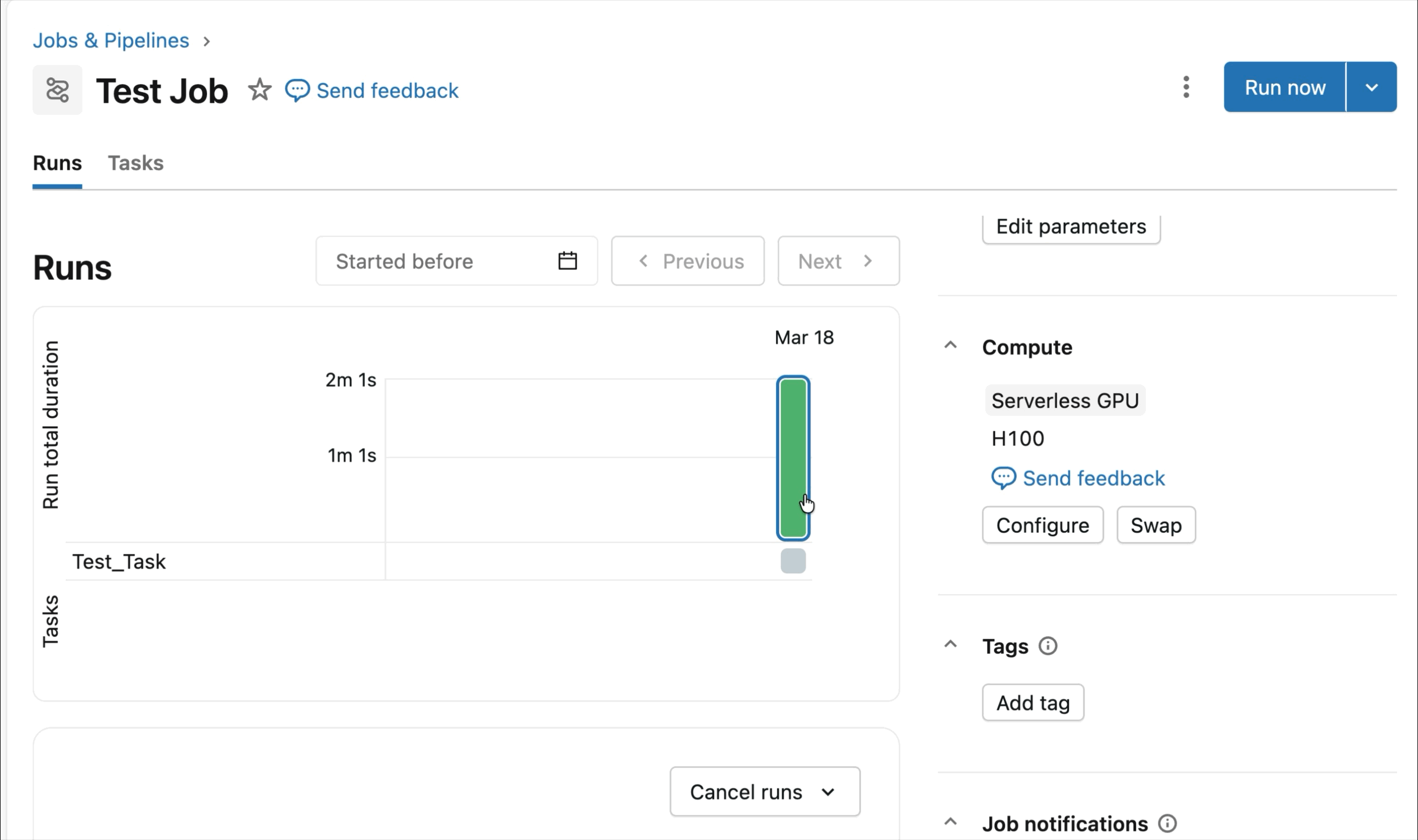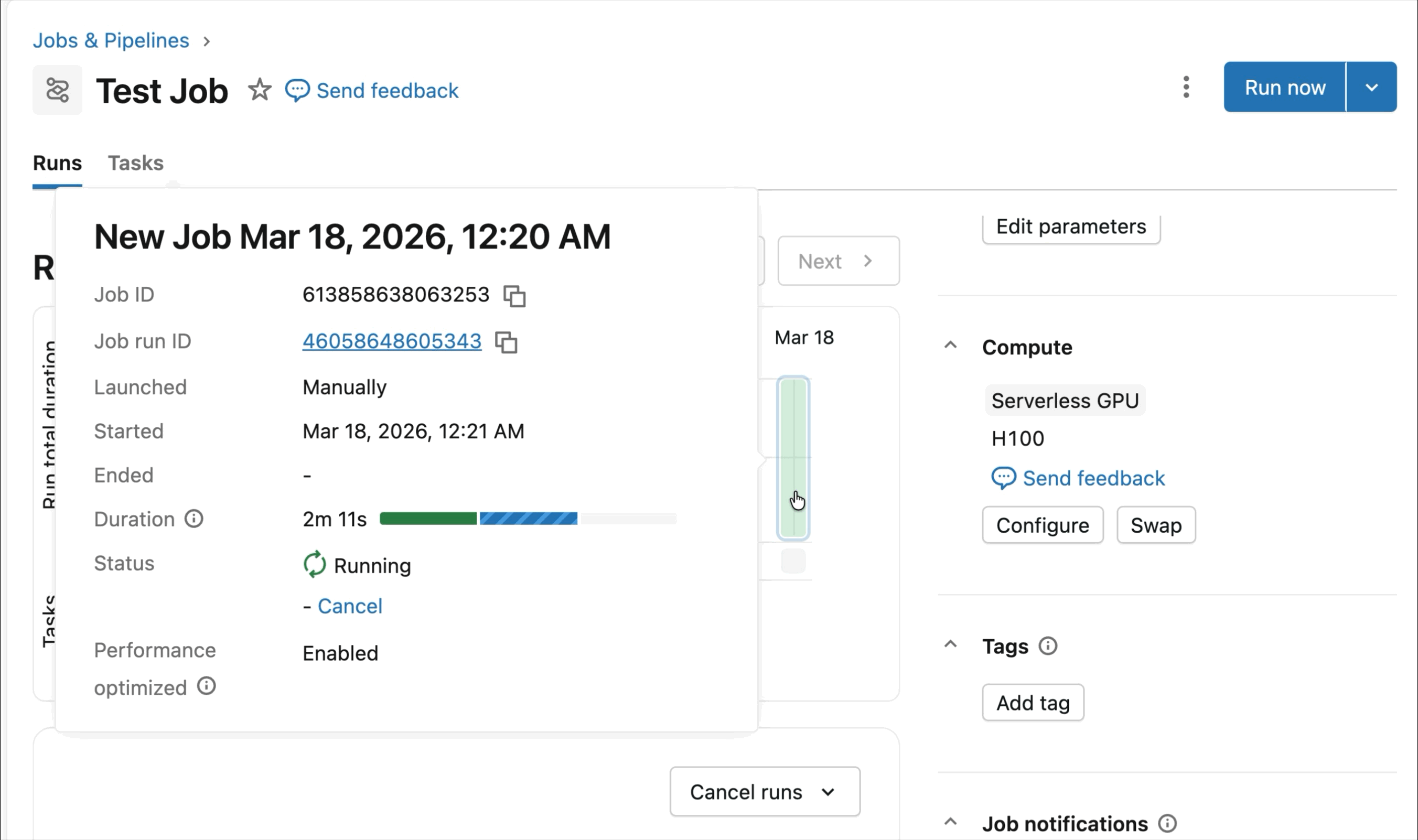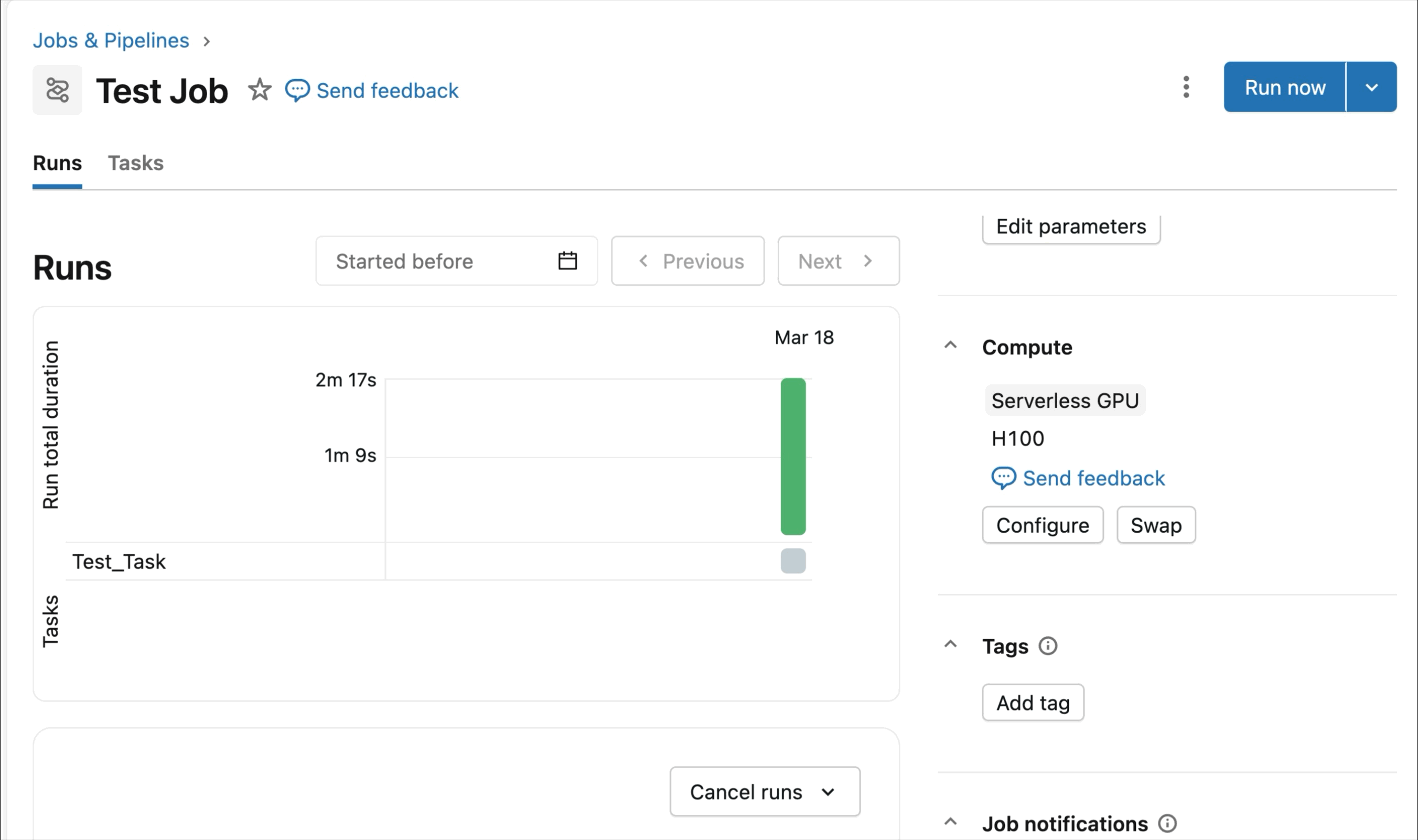
- GPU NVIDIA serverless e on-demand: Configura semplicemente il tuo notebook in 2-3 clic e ottieni un rapido collegamento alle GPU A10 e H100 Serverless per iniziare il training – non è necessario alcun cluster. Paga solo per le GPU che utilizzi, senza preoccuparti dell'utilizzo del tempo di inattività.
- Strumenti di orchestrazione robusti: Utilizza tutta la potenza della suite di orchestrazione di Databricks con Lakeflow Jobs e supporto DABs per carichi di lavoro GPU di lunga durata
- Training distribuito ottimizzato: AIR include miglioramenti delle prestazioni per il training distribuito GPU, come RDMA e caricamento dati ad alte prestazioni
- Governance e osservabilità centralizzate: esegui, osserva e governa i carichi di lavoro GPU esattamente dove risiedono i tuoi dati, con gestione degli esperimenti integrata tramite MLflow, gestione degli accessi con Unity Catalog e debug assistito da agenti
GPU NVIDIA H100 e A10 on-demand nei notebook
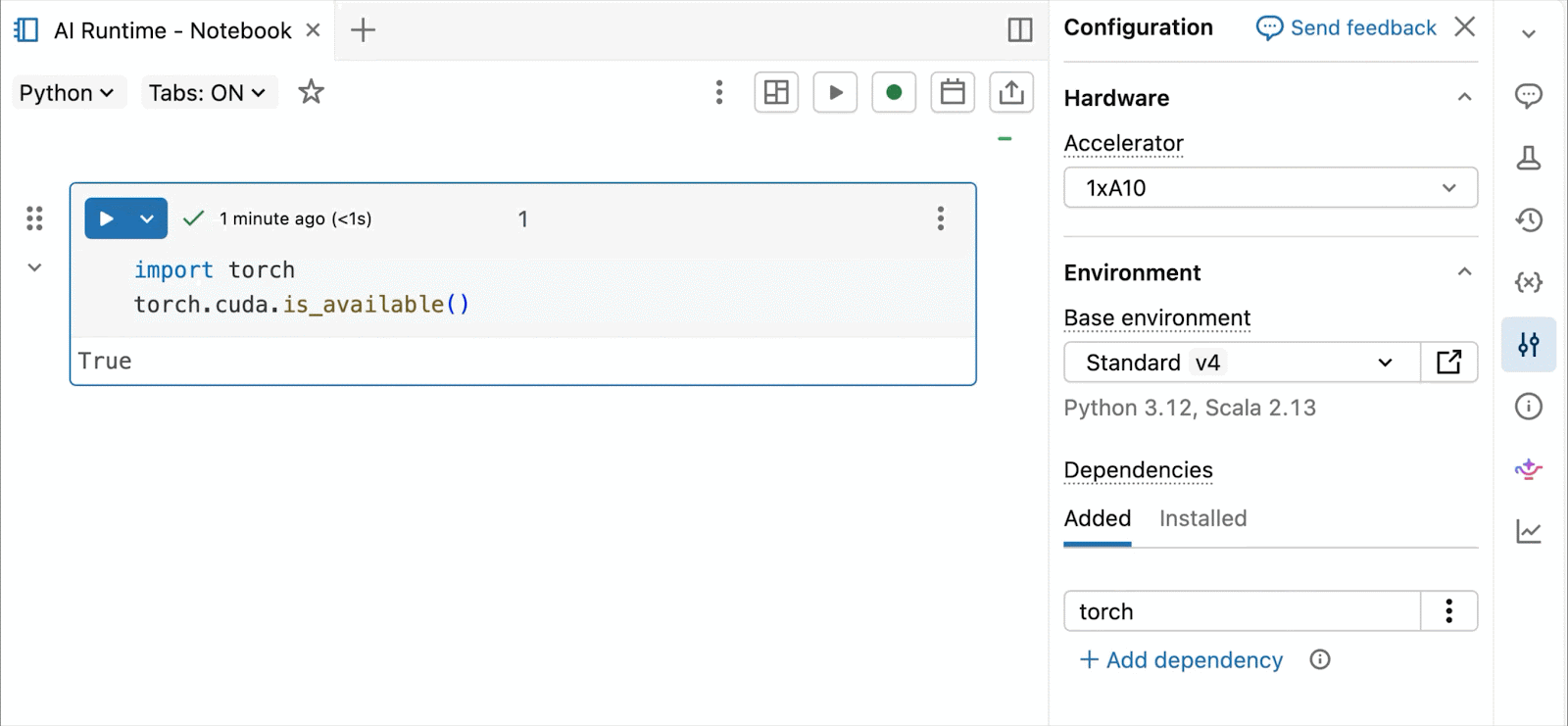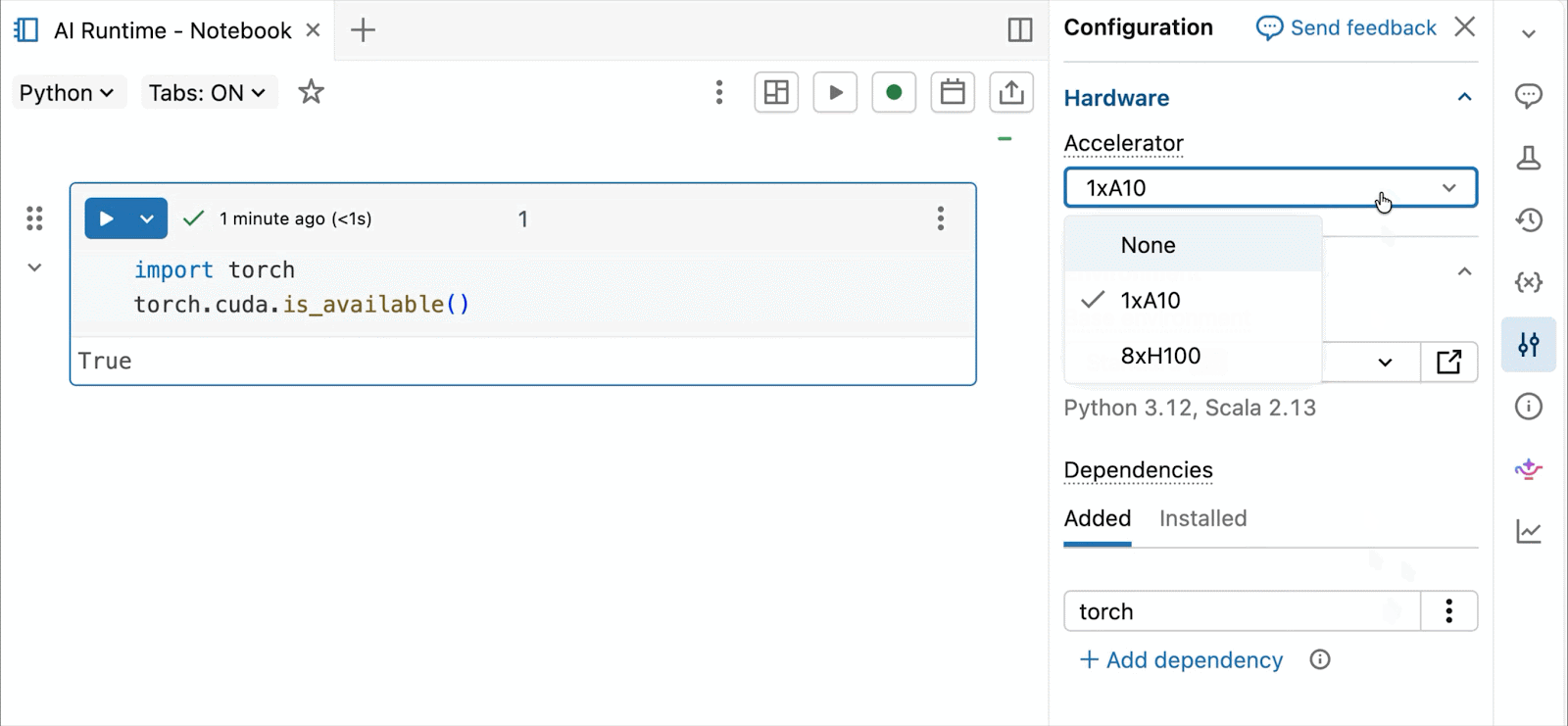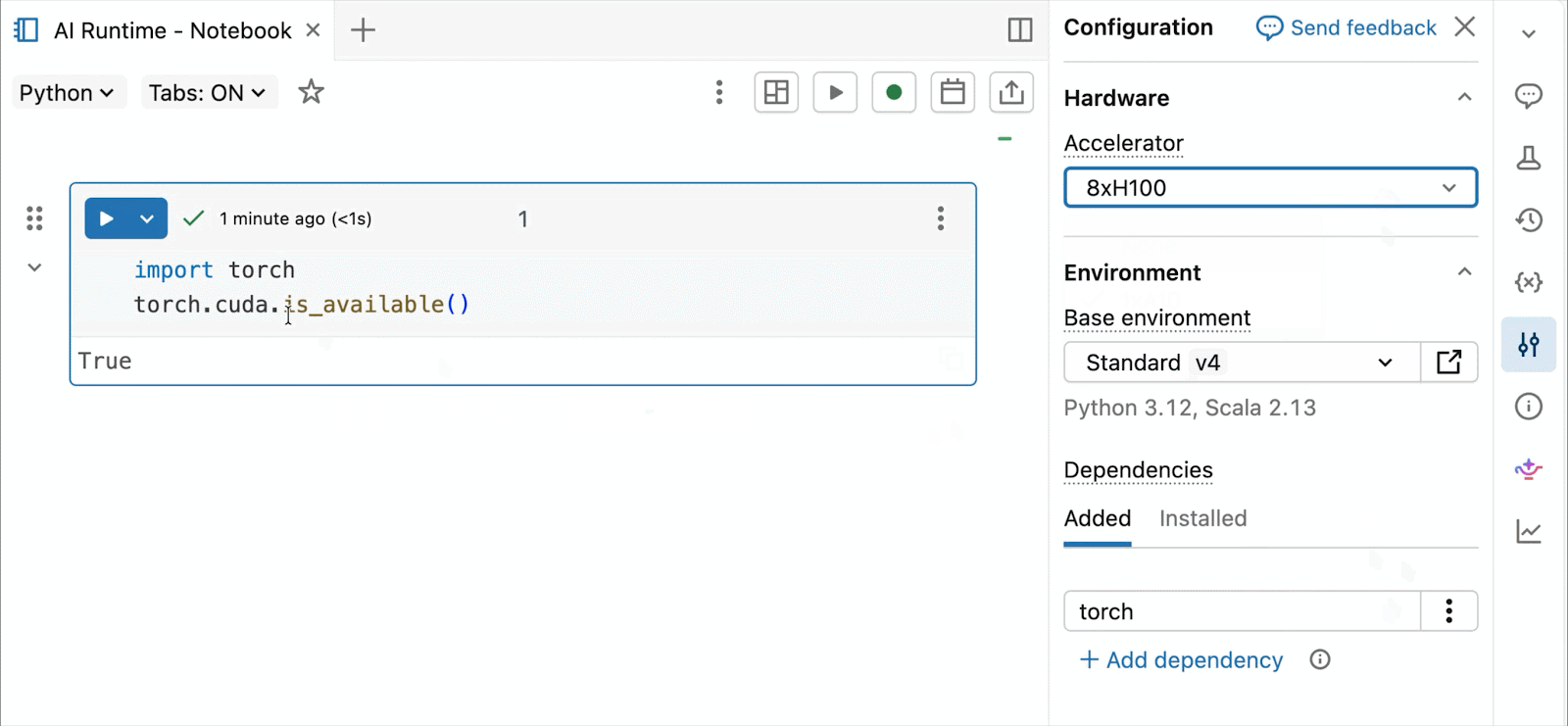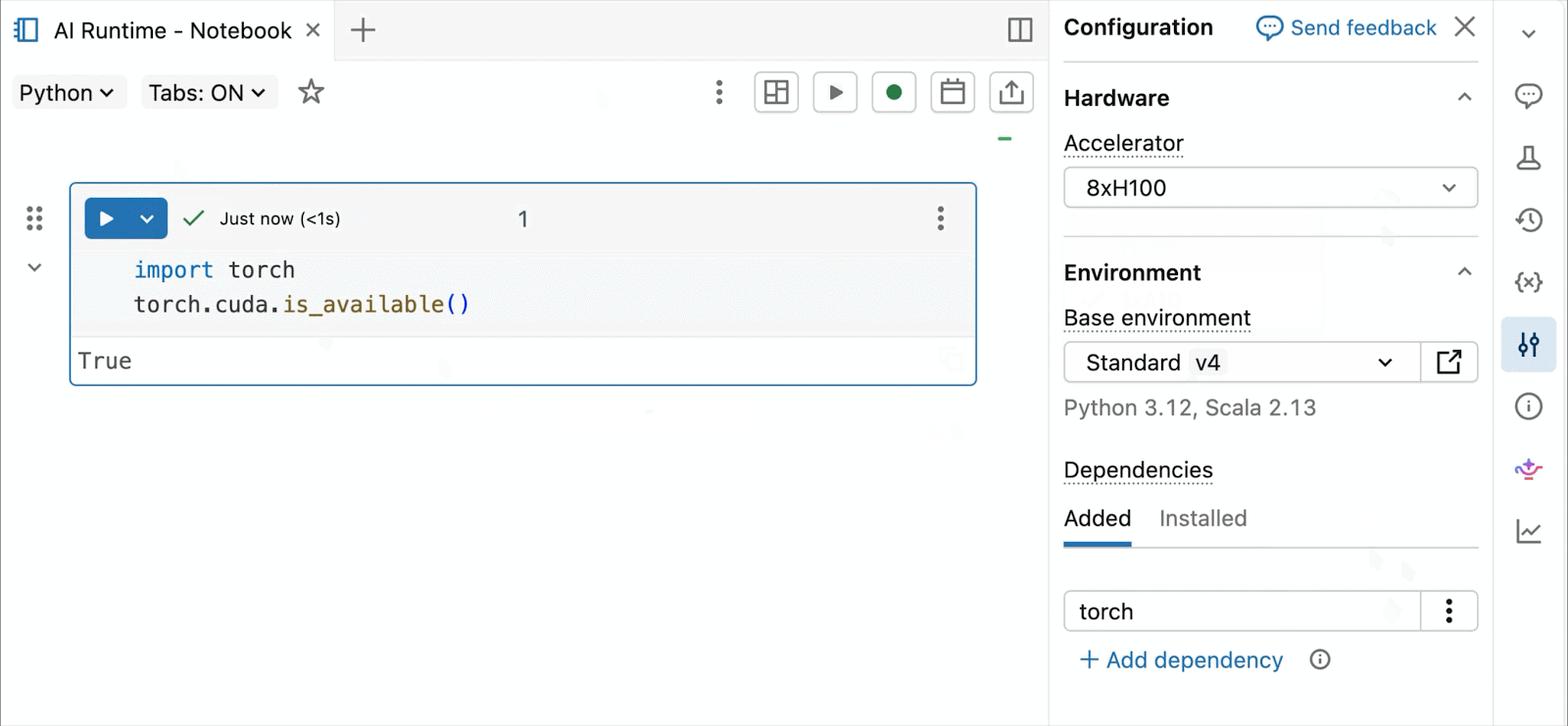
Per lo sviluppo interattivo e il debug, connettiti alle GPU A10 e H100 on-demand nei Databricks Notebooks con pochi clic. Da lì, sfrutta tutte le ergonomie per sviluppatori per cui Databricks è conosciuta, dalla gestione dell'ambiente per i pacchetti Python comuni all'authoring e al debug basati su agenti con Genie Code. Monta facilmente i dati dal Lakehouse per addestrare modelli di deep learning, o addirittura invoca una flotta di CPU remote per carichi di lavoro di elaborazione dati Spark dal tuo notebook con GPU per preparare i tuoi dati.
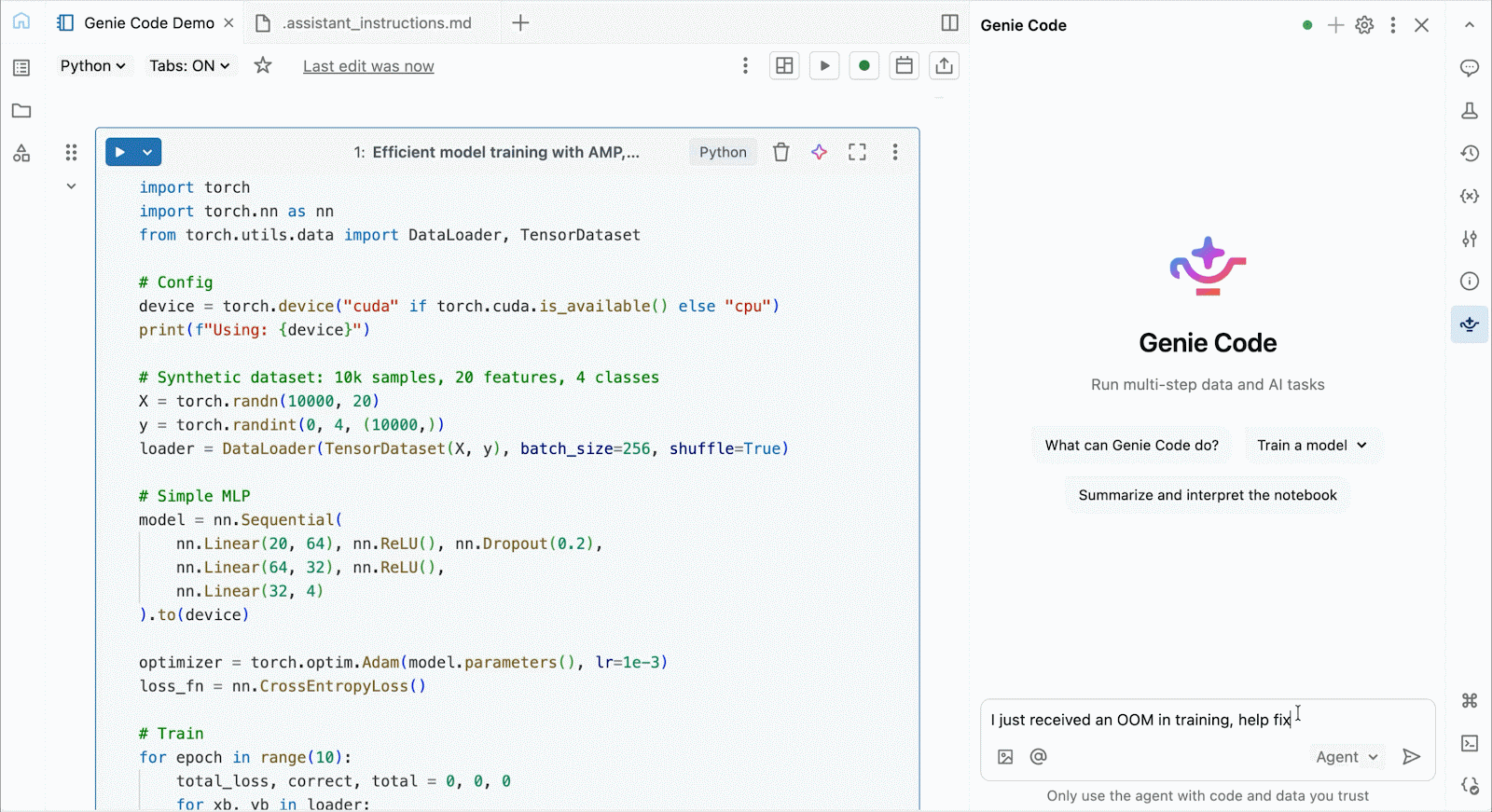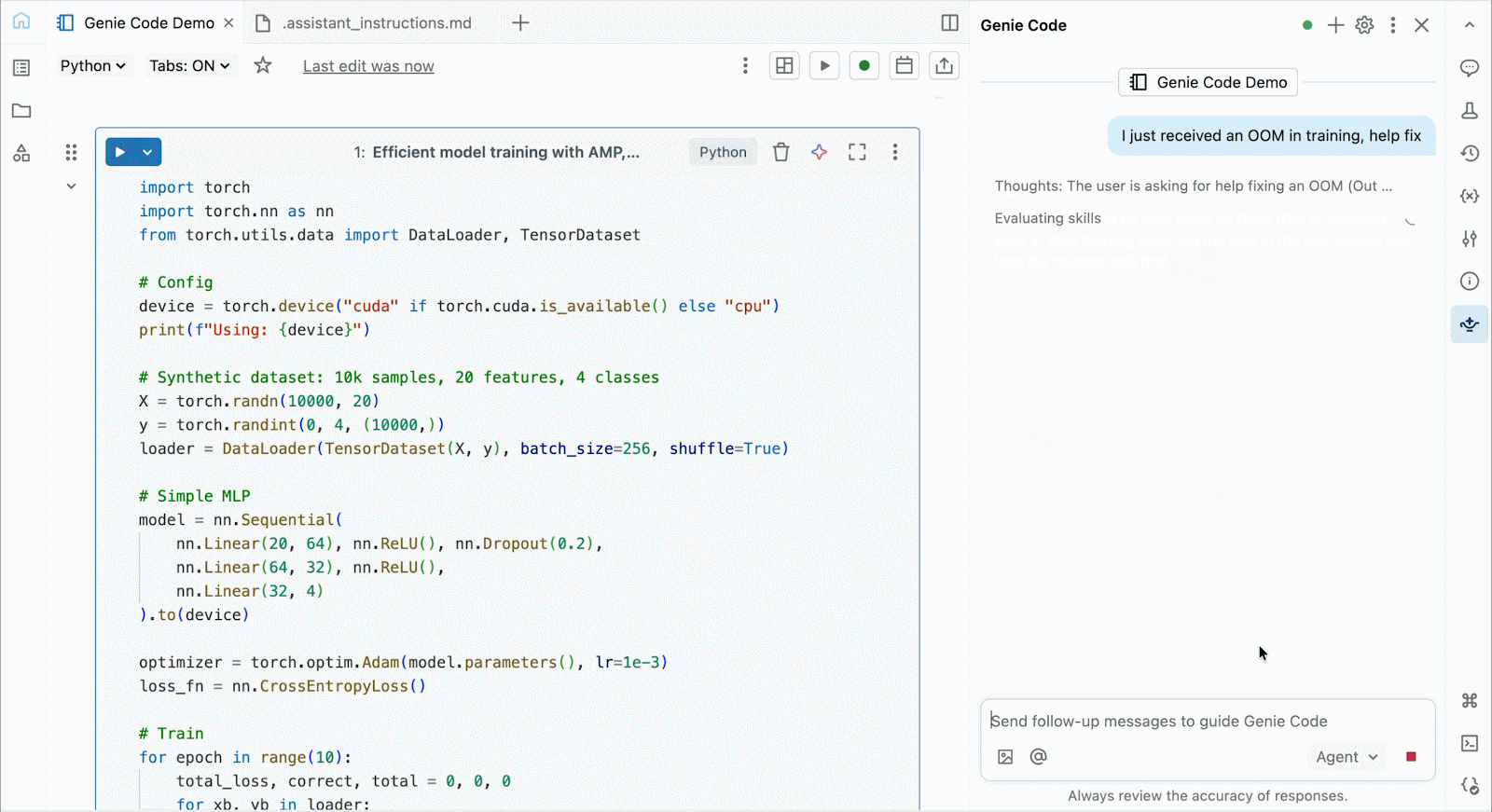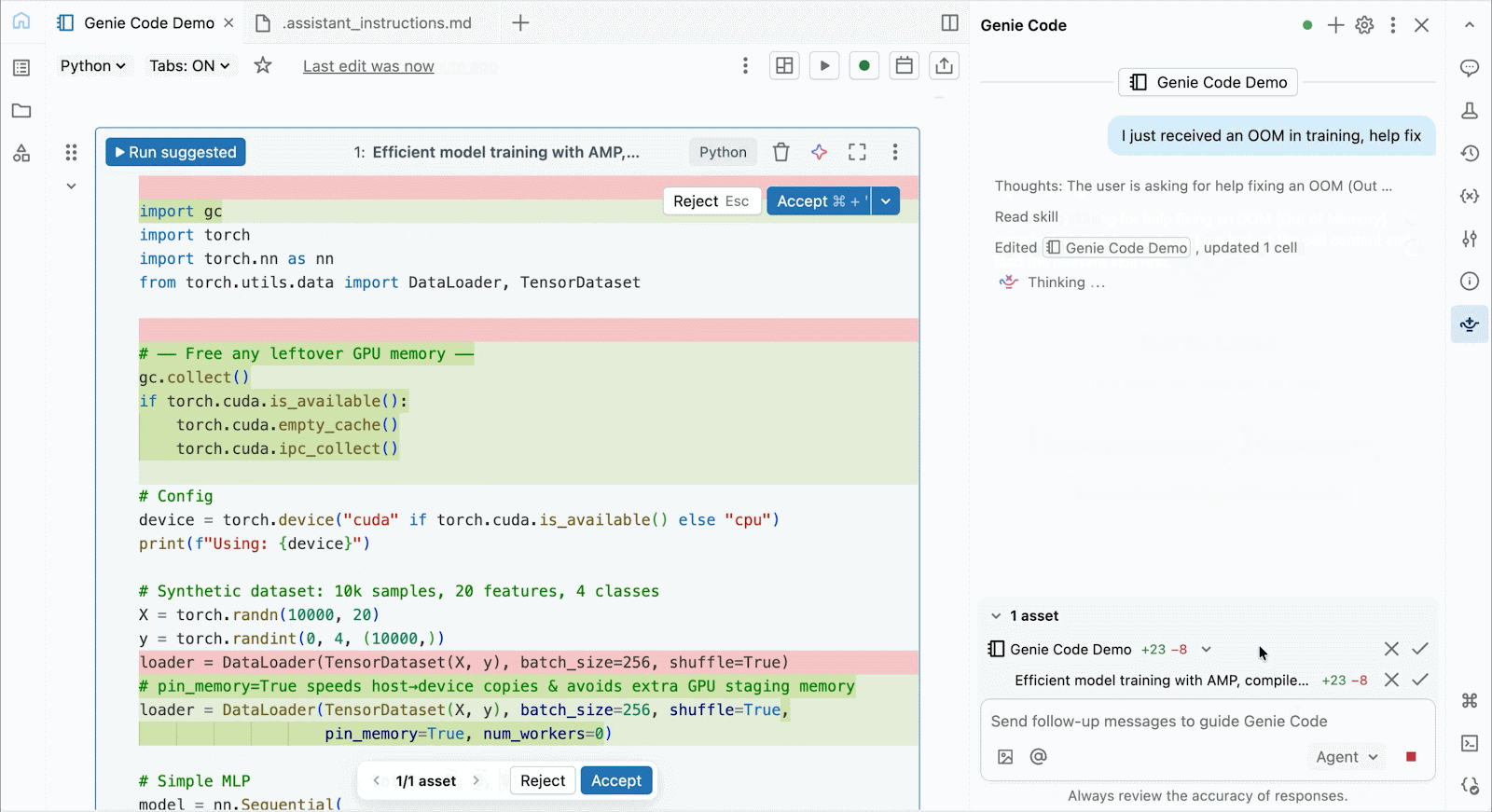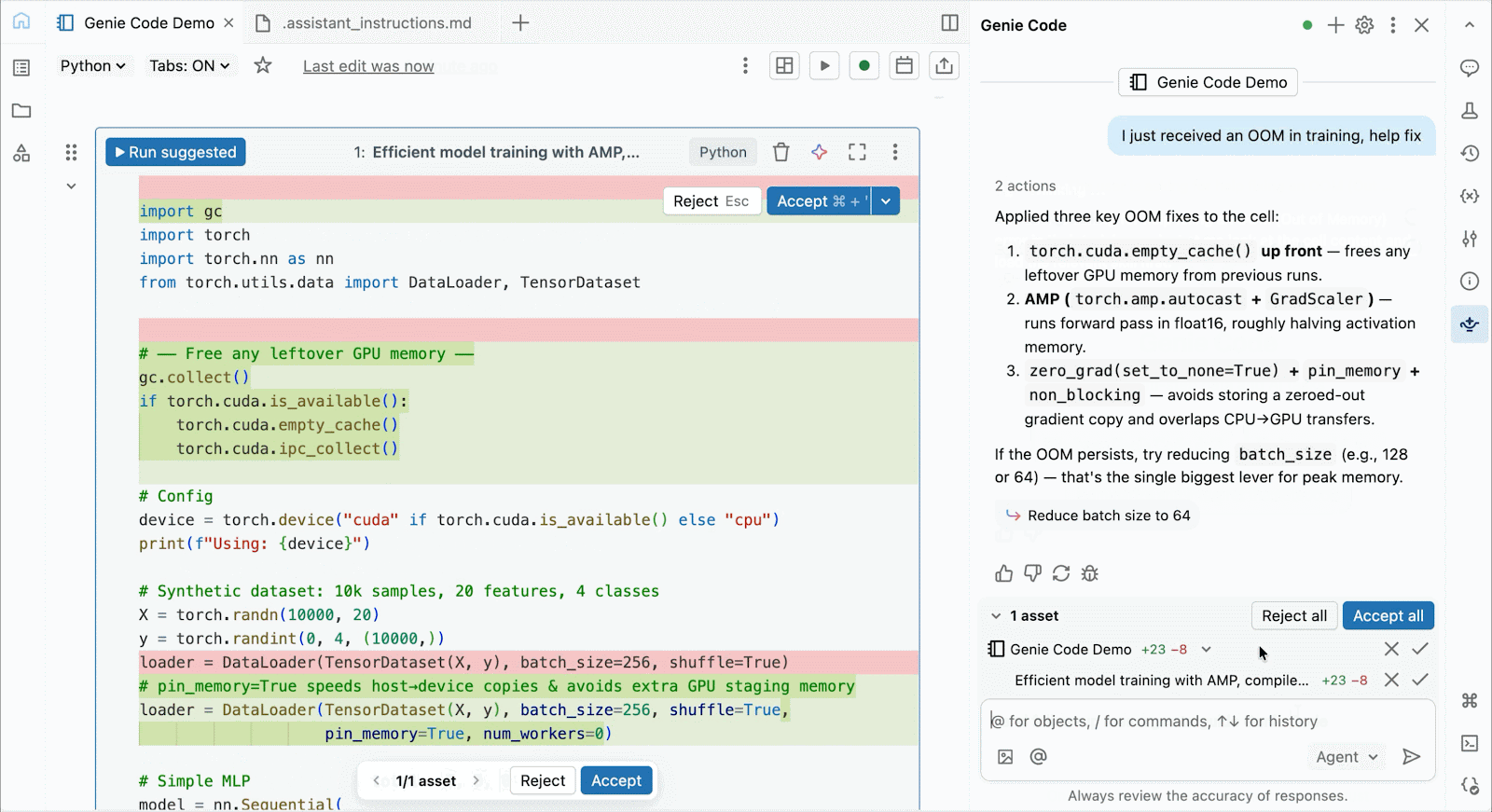
Usa Genie Code per risolvere colli di bottiglia nelle prestazioni, sperimentare nuove architetture o eseguire il debug di bug complessi relativi alla convergenza del modello o a errori criptici del framework.
Lakeflow per carichi di lavoro pronti per la produzione
AI Runtime è una piattaforma di livello enterprise per il calcolo accelerato. Sviluppa il tuo codice di deep learning in notebook interattivi, quindi utilizza tutta la potenza di Lakeflow per inviare e orchestrare job su compute GPU. Sia i notebook che i repository di codice personalizzato possono essere eseguiti da Lakeflow per job pianificati o di lunga durata. Per esigenze di produzione come CI/CD (continuous integration e continuous deployment), AI Runtime è pienamente compatibile con i nostri Declarative Automation Bundles (DABs).
Con la nostra integrazione Lakeflow, i clienti possono mantenere il training e il fine-tuning dei modelli strettamente sincronizzati con le pipeline di dati upstream e i sistemi di produzione downstream.
“L'AI Runtime di Databricks ha semplificato notevolmente il processo di training di un modello personalizzato Text To Formula (TTF). Senza configurazione dell'infrastruttura o ritardi, è stato facile scegliere il giusto compute in base alla dimensione del prompt e alla generazione di token di output. Questo ci ha permesso di muoverci rapidamente, mantenere i nostri flussi di lavoro Lakehouse e fornire un modello di alta qualità con governance completa, riducendo il tempo di configurazione, training e distribuzione del nostro modello da giorni a ore.”—Nikhil Sunderraj Principal Machine Learning Engineer, FactSet Research Systems, Inc.
Runtime ottimizzato per il deep learning distribuito
I carichi di lavoro di training distribuiti possono essere difficili da preparare, debuggare e osservare. Dalla risoluzione dei problemi di configurazione RDMA al tracciamento della telemetria da più GPU alla corretta configurazione del software, gli utenti possono facilmente trascurare dettagli critici che rallentano drasticamente il training del modello.
Invece, AI Runtime è ottimizzato per l'intero ciclo di vita del deep learning ed è progettato per farti risparmiare tempo. Le dipendenze chiave come PyTorch e CUDA sono preinstallate, insieme a un supporto ottimizzato per framework di training distribuiti come Ray, Hugging Face Transformers, Composer e altre librerie, in modo da poter iniziare subito il training senza gestire gli ambienti. I clienti sono anche invitati a portare le proprie librerie, da Unsloth a TorchRec a cicli di training personalizzati.

SDK e strumenti di osservabilità integrati semplificano la gestione dei carichi di lavoro di training distribuiti. MLFlow abilita una profonda osservabilità dei carichi di lavoro GPU, con tracciamento automatico dell'utilizzo della GPU e degli esperimenti di training. Sia che tu stia facendo fine-tuning di modelli fondazionali o addestrando modelli di previsione e personalizzazione, il runtime è ottimizzato per accelerare i flussi di lavoro di training con una configurazione minima.
L'anteprima pubblica di AI Runtime di oggi supporta il training distribuito su 8x H100 in un singolo nodo, con supporto multi-nodo attualmente in anteprima privata.
“L'AI Runtime di Databricks ci consente di eseguire in modo efficiente carichi di lavoro LLM (fine-tuning e inferenza) senza overhead infrastrutturale, direttamente nel nostro lakehouse. Questa integrazione trasparente semplifica le nostre pipeline e garantisce un uso efficiente delle GPU, permettendoci di fornire insight AI di alta qualità ai nostri clienti e di concentrarci sull'innovazione, non sull'infrastruttura.”—Lucas Froguel, Senior AI Platform Engineer, YipitData
Governance e osservabilità centralizzate dei dati
AI Runtime si integra nativamente con il Databricks Lakehouse, consentendoti di eseguire e governare carichi di lavoro GPU dove risiedono i tuoi dati. Ciò elimina flussi di lavoro frammentati e semplifica il percorso dalla sperimentazione alla produzione.
- Governance centralizzata con Unity Catalog: Applica controlli di accesso, lineage e policy di governance coerenti sia ai dati che ai carichi di lavoro AI, consentendo un uso sicuro e conforme delle risorse GPU.
- Osservabilità unificata: Traccia e monitora tutti i carichi di lavoro, CPU e GPU, in un unico posto utilizzando tabelle di sistema native per audit unificato, tracciamento dell'utilizzo e insight operativi.
I tuoi carichi di lavoro AI vengono eseguiti interamente all'interno del perimetro dei dati della tua azienda, offrendo una solida governance e sicurezza senza sacrificare la flessibilità per la sperimentazione e la scalabilità.
“Sfruttare il supporto GPU serverless di Databricks all'interno del nostro Lakehouse ci consente di addestrare in modo efficiente modelli audio e multimodali avanzati senza overhead infrastrutturale. Questa integrazione trasparente semplifica i flussi di lavoro e fornisce un uso efficiente delle risorse GPU, garantendo la fornitura di sistemi ad alte prestazioni e consentendoci di concentrarci sull'innovazione.”—Arjuna Siva, VP of Infotainment & Connectivity, Rivian and Volkswagen Group Technologies
Integrazione dell'innovazione GPU di prossima generazione da NVIDIA
La domanda di calcolo accelerato continua a crescere per i carichi di lavoro AI e i sistemi agenti. AI Runtime consente a più clienti Databricks di sfruttare l'hardware NVIDIA per accelerare i propri carichi di lavoro AI e portare avanti il proprio business. Siamo entusiasti di continuare la nostra collaborazione con NVIDIA per portare ai nostri clienti le ultime tecnologie NVIDIA, come la RTX PRO 4500 Blackwell Server Edition, annunciata al GTC 2026.
"Man mano che l'adozione dell'AI accelera in tutti i settori, le organizzazioni necessitano di un'infrastruttura scalabile e ad alte prestazioni per alimentare i propri carichi di lavoro di dati e AI. Le tecnologie NVIDIA portano prestazioni accelerate all'offerta AI Runtime per la Databricks Lakehouse Platform."—Pat Lee, Vice President, Strategic Partnerships presso NVIDIA.
Inizia oggi stesso con AI Runtime
Per aiutarti a iniziare, abbiamo preparato diversi notebook di esempio e guide introduttive:
- Consulta la nostra documentazione per istruzioni dettagliate sull'impostazione e sull'uso quotidiano.
- Modelli di esempio per l'addestramento di sistemi di raccomandazione, modelli ML classici, fine-tuning di LLM e altro ancora!
- Guida alla migrazione dai carichi di lavoro GPU di Classic Compute a Serverless.
Contatta il tuo team di account per saperne di più o se hai domande!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.