Ti presentiamo KARL: un agente più veloce per la conoscenza aziendale, potenziato da RL personalizzato
Apprendimento per rinforzo per agenti aziendali
Per il report tecnico completo, fai clic qui. Se ti interessa provare l'RL personalizzato di Databricks sul tuo agente aziendale, fai clic qui.
Il miglioramento delle capacità di ragionamento dei modelli attuali ha portato a un'esplosione di agenti implementati per il lavoro di conoscenza, come la scrittura di codice, la formulazione di domande sui dati aziendali e l'automazione dei flussi di lavoro comuni. Sebbene i modelli utilizzati nelle attività aziendali siano molto potenti, sono anche estremamente costosi e i costi di inferenza hanno iniziato a crescere in modo insostenibile per molti casi d'uso. In questo post e nel relativo report tecnico, descriviamo la nostra esperienza nell'utilizzo dell'apprendimento per rinforzo (RL) per creare modelli personalizzati per alimentare casi d'uso che sono una parte fondamentale del nostro prodotto Agent Bricks. Questo esempio dimostra che, a costi relativamente bassi, è possibile creare modelli personalizzati che dominano nettamente i modelli di frontiera su tutte e tre le dimensioni critiche: costo di inferenza, latenza e qualità. I nostri risultati sono coerenti con altre osservazioni del settore, come il modello Composer di Cursor, in cui la personalizzazione basata su RL è stata in grado di migliorare drasticamente sia la velocità che la qualità rispetto alle alternative.
KARL: un agente di conoscenza più veloce, più potente e più economico per gli utenti di Databricks
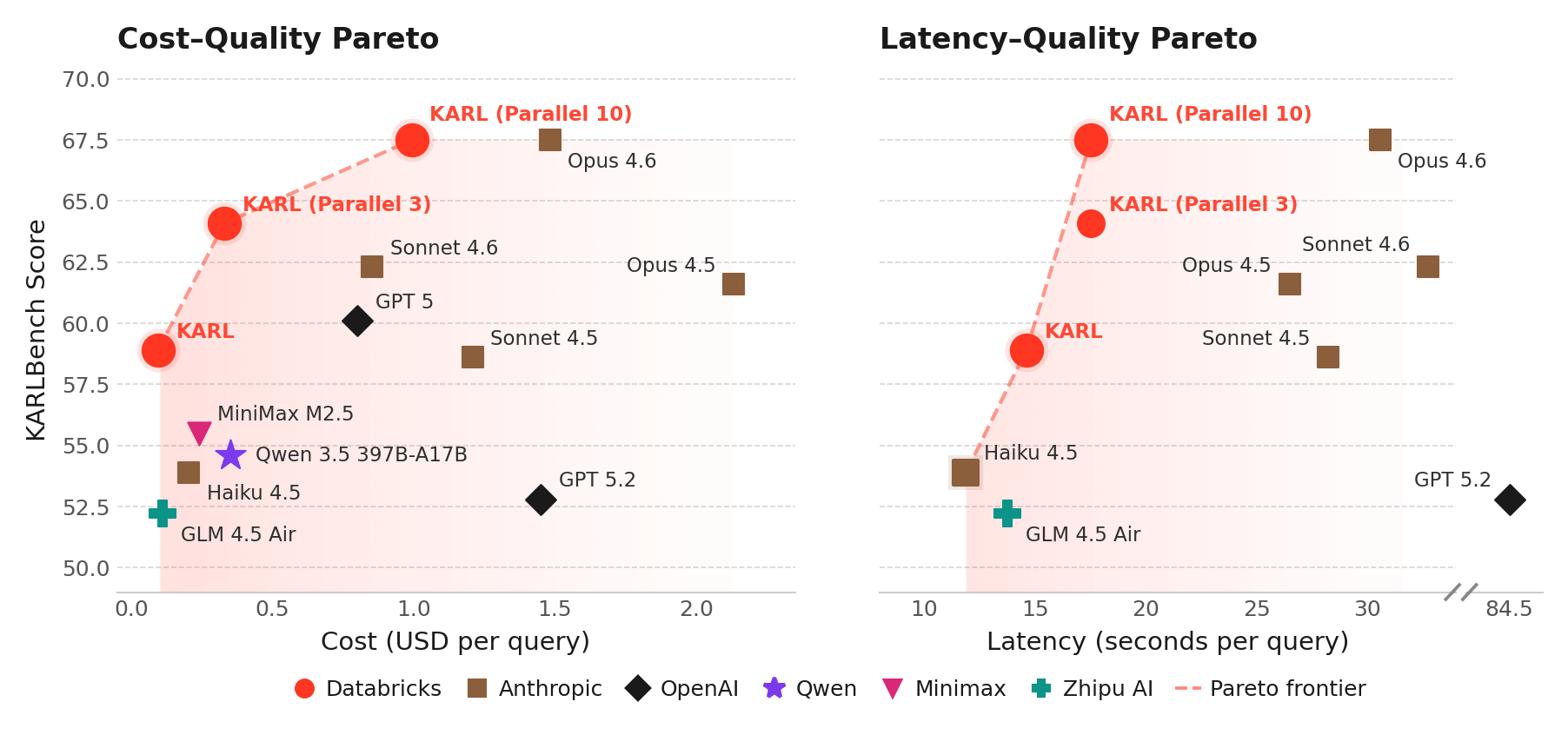
Il modello che abbiamo addestrato, che chiamiamo KARL, affronta una capacità aziendale critica, il ragionamento fondato: rispondere a domande cercando documenti, ricercando fatti, confrontando le informazioni e ragionando su dozzine o centinaia di passaggi. Il ragionamento fondato è richiesto per diversi prodotti Databricks, come Agent Bricks Knowledge Assistant. A differenza della matematica e della programmazione, le attività di ragionamento fondato sono difficili da verificare, poiché spesso non esiste un'unica risposta corretta. In situazioni come questa, guidare l'apprendimento per rinforzo verso una buona soluzione è particolarmente difficile.
Utilizzando l'RL, le tecniche e l'infrastruttura sviluppata in Databricks, KARL eguaglia le prestazioni dei modelli proprietari più potenti del mondo a una frazione del costo di servizio e della latenza, anche su nuove attività di ragionamento fondato che non aveva mai visto. (Vedi il report tecnico per tutti i dettagli.) Ci siamo riusciti con poche migliaia di ore di addestramento su GPU e dati interamente sintetici.
Nei test interni con utenti umani, KARL ha fornito risposte migliori e più complete rispetto ai nostri prodotti esistenti e ai più recenti modelli di frontiera. I risultati di questa ricerca vengono integrati negli agenti Databricks che usi oggi, come Agent Bricks, basando le risposte sui tuoi dati non strutturati e strutturati nel Databricks Lakehouse.
Una pipeline di RL riutilizzabile per i clienti di Databricks
Siamo entusiasti di annunciare che le stesse pipeline di RL e la stessa infrastruttura che abbiamo usato per creare KARL (e altri agenti di cui parleremo presto) sono ora disponibili per i clienti di Databricks che cercano di migliorare le prestazioni dei modelli e ridurre i costi per i loro carichi di lavoro agentici ad alto volume. Quasi tutte le attività aziendali del mondo reale sono difficili da verificare, quindi KARL apre la strada, non solo a un'esperienza migliore per gli utenti di Databricks, ma anche alla creazione da parte dei nostri clienti di modelli di RL personalizzati per i loro agenti più diffusi. La nostra anteprima privata dell'RL personalizzato, supportata da AI Runtime, ti consente di utilizzare l'infrastruttura di KARL per creare una versione più efficiente e specifica per il dominio del tuo agente. Se hai un agente di IA che sta scalando rapidamente e ti interessa ottimizzarlo con l'RL, registrati qui per esprimere il tuo interesse per questa anteprima.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.