Presentazione di Apache Spark 4.0
Ora disponibile in Databricks Runtime 17.0
di Wenchen Fan, Serge Rielau, Herman van Hövell, Hyukjin Kwon, Allison Wang, Anish Shrigondekar, Daniel Tenedorio, Martin Grund, DB Tsai, Xiao Li e Reynold Xin
Free Edition ha sostituito Community Edition, offrendo funzionalità avanzate senza costi. Inizia a usare Free Edition oggi stesso.
Apache Spark 4.0 segna una pietra miliare importante nell'evoluzione del motore di analisi Spark. Questa release porta significativi progressi su tutta la linea: dai miglioramenti del linguaggio SQL e della connettività estesa, alle nuove capacità Python, ai miglioramenti dello streaming e a una migliore usabilità. Spark 4.0 è progettato per essere più potente, conforme agli standard ANSI e facile da usare che mai, mantenendo al contempo la compatibilità con i carichi di lavoro Spark esistenti. In questo post, spieghiamo le caratteristiche chiave e i miglioramenti introdotti in Spark 4.0 e come elevano la tua esperienza di elaborazione di big data.
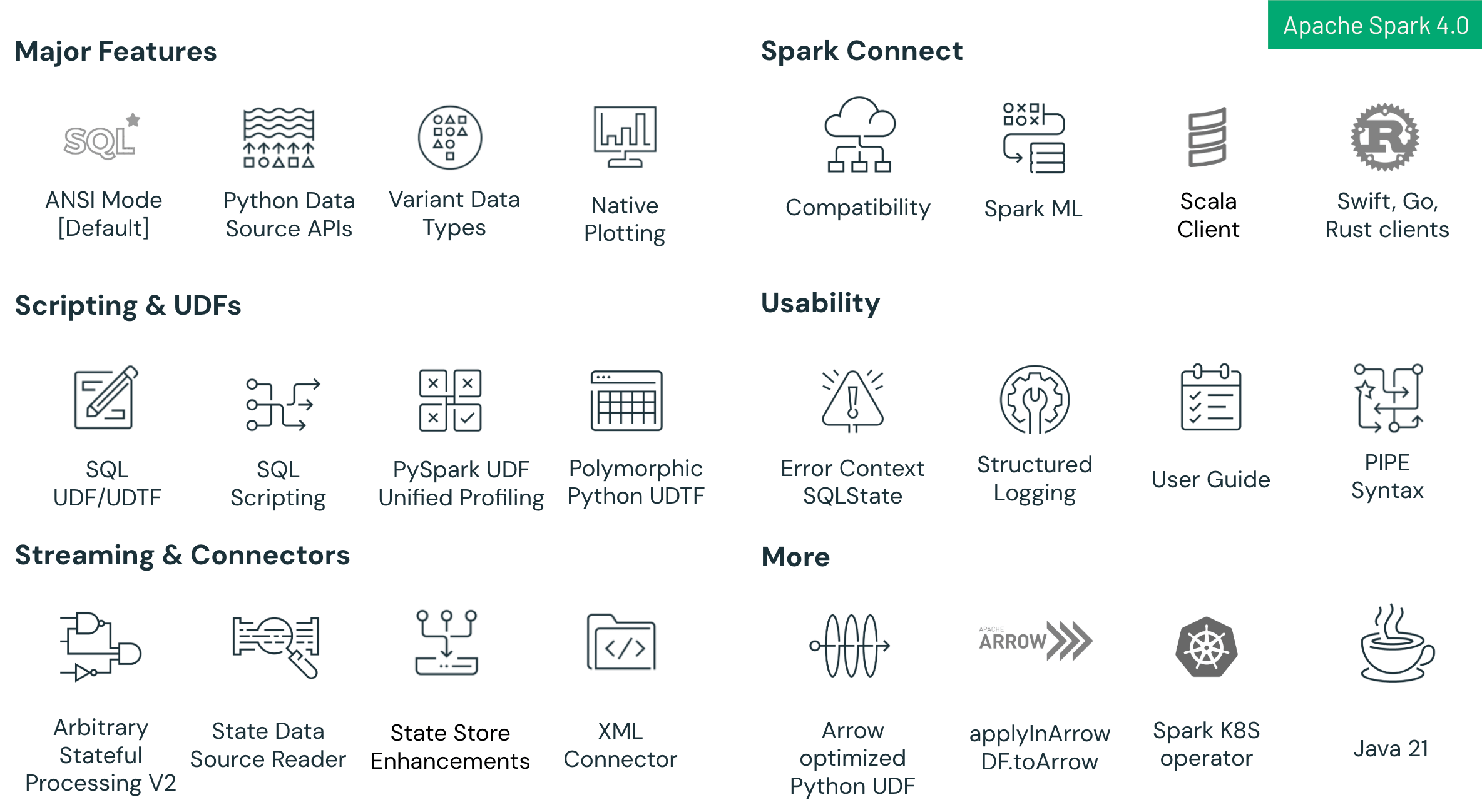
Principali novità in Spark 4.0 includono:
- Miglioramenti del linguaggio SQL: Nuove funzionalità tra cui scripting SQL con variabili di sessione e flusso di controllo, funzioni definite dall'utente (UDF) SQL riutilizzabili e una sintassi PIPE intuitiva per semplificare e ottimizzare flussi di lavoro analitici complessi.
- Miglioramenti di Spark Connect: Spark Connect, la nuova architettura client-server di Spark, raggiunge ora un'elevata parità di funzionalità con Spark Classic in Spark 4.0. Questa release aggiunge una compatibilità migliorata tra Python e Scala, supporto multilingua (con nuovi client per Go, Swift e Rust) e un percorso di migrazione più semplice tramite la nuova impostazione spark.api.mode. Gli sviluppatori possono passare senza problemi da Spark Classic a Spark Connect per beneficiare di un'architettura più modulare, scalabile e flessibile.
- Miglioramenti di affidabilità e produttività: La modalità SQL ANSI abilitata per impostazione predefinita garantisce una maggiore integrità dei dati e una migliore interoperabilità, completata dal tipo di dati VARIANT per la gestione efficiente di dati JSON semi-strutturati e dal logging JSON strutturato per una migliore osservabilità e una risoluzione dei problemi più semplice.
- Avanzamenti dell'API Python: Plotting nativo basato su Plotly direttamente su DataFrame PySpark, un'API Python Data Source che abilita connettori batch e streaming Python personalizzati, e UDTF Python polimorfiche per il supporto di schemi dinamici e una maggiore flessibilità.
- Avanzamenti dello Structured Streaming: Nuova API Arbitrary Stateful Processing chiamata transformWithState in Scala, Java e Python per una logica stateful personalizzata robusta e tollerante ai guasti, miglioramenti dell'usabilità dello state store e una nuova State Store Data Source per una migliore debuggabilità e osservabilità.
Nelle sezioni seguenti, condividiamo maggiori dettagli su queste entusiasmanti funzionalità e, alla fine, forniamo collegamenti agli sforzi JIRA pertinenti e ai post di blog approfonditi per coloro che desiderano saperne di più. Spark 4.0 rappresenta una piattaforma robusta e pronta per il futuro per l'elaborazione di dati su larga scala, combinando la familiarità di Spark con nuove funzionalità che soddisfano le moderne esigenze di ingegneria dei dati.
Principali miglioramenti di Spark Connect
Uno degli aggiornamenti più entusiasmanti in Spark 4.0 è il miglioramento generale di Spark Connect, in particolare il client Scala. Con Spark 4, tutte le funzionalità di Spark SQL offrono una compatibilità quasi completa tra Spark Connect e la modalità di esecuzione Classic, con solo piccole differenze residue. Spark Connect è la nuova architettura client-server per Spark che disaccoppia l'applicazione utente dal cluster Spark e, in 4.0, è più capace che mai:
- Compatibilità migliorata: Un risultato importante per Spark Connect in Spark 4 è la compatibilità migliorata delle API Python e Scala, che rende il passaggio tra l'uso di Spark Classic e Spark Connect senza interruzioni. Ciò significa che per la maggior parte dei casi d'uso, tutto ciò che devi fare è abilitare Spark Connect per le tue applicazioni impostando
spark.api.modesuconnect. Si consiglia di iniziare a sviluppare nuovi job e applicazioni con Spark Connect abilitato in modo da poter beneficiare al massimo del potente motore di ottimizzazione ed esecuzione delle query di Spark. - Supporto multilingua: Spark Connect in 4.0 supporta un'ampia gamma di linguaggi e ambienti. I client Python e Scala sono completamente supportati e sono disponibili nuovi client di connessione supportati dalla community per Go, Swift e Rust. Questo supporto poliglotta significa che gli sviluppatori possono utilizzare Spark nella lingua di loro scelta, anche al di fuori dell'ecosistema JVM, tramite l'API Connect. Ad esempio, un'applicazione di ingegneria dati Rust o un servizio Go possono ora connettersi direttamente a un cluster Spark ed eseguire query DataFrame, espandendo la portata di Spark oltre la sua base di utenti tradizionale.
Funzionalità del linguaggio SQL
Spark 4.0 aggiunge nuove funzionalità per semplificare l'analisi dei dati:
- Funzioni definite dall'utente (UDF) SQL – Spark 4.0 introduce le UDF SQL, che consentono agli utenti di definire funzioni personalizzate riutilizzabili direttamente in SQL. Queste funzioni semplificano la logica complessa, migliorano la manutenibilità e si integrano perfettamente con l'ottimizzatore di query di Spark, migliorando le prestazioni delle query rispetto alle tradizionali UDF basate su codice. Le UDF SQL supportano definizioni temporanee e permanenti, rendendo facile per i team condividere logica comune tra più query e applicazioni. [Leggi il post del blog]
- Sintassi PIPE SQL – Spark 4.0 introduce una nuova sintassi PIPE, che consente agli utenti di concatenare operazioni SQL utilizzando l'operatore |>. Questo approccio in stile funzionale migliora la leggibilità e la manutenibilità delle query consentendo un flusso lineare di trasformazioni. La sintassi PIPE è completamente compatibile con SQL esistente, consentendo un'adozione graduale e l'integrazione nei flussi di lavoro correnti. [Leggi il post del blog]
- Collation sensibili al linguaggio, accenti e maiuscole/minuscole - Spark 4.0 introduce una nuova proprietà COLLATE per i tipi STRING. È possibile scegliere tra molte collation sensibili al linguaggio e alla regione per controllare come Spark determina l'ordinamento e i confronti. È inoltre possibile decidere se le collation devono essere insensibili agli accenti, alle maiuscole/minuscole e agli spazi finali. [Leggi il post del blog]
- Variabili di sessione - Spark 4.0 introduce variabili locali di sessione, che possono essere utilizzate per conservare e gestire lo stato all'interno di una sessione senza utilizzare variabili del linguaggio host. [Leggi il post del blog]
- Marcatori di parametro - Spark 4.0 introduce marcatori di parametro in stile nominato (":var") e non nominato ("?"). Questa funzionalità consente di parametrizzare le query e passare in modo sicuro i valori tramite l'API spark.sql(). Ciò mitiga il rischio di SQL injection. [Vedi la documentazione]
- Scripting SQL: Scrivere flussi di lavoro SQL multi-step è più facile in Spark 4.0 grazie alle nuove funzionalità di scripting SQL. Ora è possibile eseguire script SQL multi-istruzione con funzionalità come variabili locali e flusso di controllo. Questo miglioramento consente agli ingegneri dei dati di spostare parti della logica ETL in SQL puro, con Spark 4.0 che supporta costrutti che in precedenza erano possibili solo tramite linguaggi esterni o stored procedure. Questa funzionalità sarà presto ulteriormente migliorata dalla gestione delle condizioni di errore. [Leggi il post del blog]
Integrità dei dati e produttività degli sviluppatori
Spark 4.0 introduce diversi aggiornamenti che rendono la piattaforma più affidabile, conforme agli standard e facile da usare. Questi miglioramenti semplificano sia i flussi di lavoro di sviluppo che quelli di produzione, garantendo una maggiore qualità dei dati e una risoluzione dei problemi più rapida.
- Modalità SQL ANSI: Uno dei cambiamenti più significativi in Spark 4.0 è l'abilitazione della modalità SQL ANSI per impostazione predefinita, allineando Spark più strettamente alle semantiche SQL standard. Questa modifica garantisce una gestione dei dati più rigorosa fornendo messaggi di errore espliciti per le operazioni che in precedenza comportavano troncamenti silenziosi o valori null, come overflow numerici o divisione per zero. Inoltre, l'adesione agli standard SQL ANSI migliora notevolmente l'interoperabilità, semplificando la migrazione dei carichi di lavoro SQL da altri sistemi e riducendo la necessità di estese riscritture di query e riqualificazione dei team. Nel complesso, questo progresso promuove flussi di lavoro di dati più chiari, affidabili e portabili. [Vedi la documentazione]
- Nuovo tipo di dati VARIANT: Apache Spark 4.0 introduce il nuovo tipo di dati VARIANT, progettato specificamente per dati semi-strutturati. Questo tipo di dati consente di archiviare strutture complesse simili a JSON o mappe all'interno di una singola colonna, mantenendo la capacità di interrogare in modo efficiente i campi nidificati. Questa potente funzionalità offre una notevole flessibilità dello schema, semplificando l'ingestione e la gestione di dati che non sono conformi a schemi predefiniti. Inoltre, l'indicizzazione e l'analisi integrate di Spark per i campi JSON migliorano le prestazioni delle query, facilitando ricerche e trasformazioni rapide. Riducendo al minimo la necessità di ripetuti passaggi di evoluzione dello schema, VARIANT semplifica le pipeline ETL, con conseguenti flussi di lavoro di elaborazione dati più snelli. [Leggi il post del blog]
- Logging strutturato: Spark 4.0 introduce un nuovo framework di logging strutturato che semplifica il debug e il monitoraggio. Abilitando
spark.log.structuredLogging.enabled=true,Spark scrive i log come righe JSON, ogni voce include campi strutturati come timestamp, livello di log, messaggio e contesto completo Mapped Diagnostic Context (MDC). Questo formato moderno semplifica l'integrazione con strumenti di osservabilità come Spark SQL, ELK e Splunk, rendendo i log molto più facili da analizzare, cercare e interpretare. [Scopri di più]
Avanzamenti dell'API Python
Gli utenti Python hanno molto da festeggiare in Spark 4.0. Questa release rende Spark più "Pythonic" e migliora le prestazioni dei carichi di lavoro PySpark:
- Supporto nativo per il plotting: L'esplorazione dei dati in PySpark è appena diventata più semplice: Spark 4.0 aggiunge funzionalità di plotting native ai DataFrame PySpark. Ora puoi chiamare un metodo .plot() o utilizzare un'API associata su un DataFrame per generare grafici direttamente dai dati Spark, senza dover raccogliere manualmente i dati in pandas. Sotto il cofano, Spark utilizza Plotly come backend di visualizzazione predefinito per il rendering dei grafici. Ciò significa che tipi di grafici comuni come istogrammi e grafici a dispersione possono essere creati con una sola riga di codice su un DataFrame PySpark, e Spark gestirà il recupero di un campione o di un aggregato dei dati da visualizzare in un notebook o in un'interfaccia grafica. Supportando il plotting nativo, Spark 4.0 semplifica l'analisi esplorativa dei dati: puoi visualizzare distribuzioni e tendenze dal tuo set di dati senza lasciare il contesto Spark o scrivere codice matplotlib/plotly separato. Questa funzionalità è un vantaggio per la produttività degli scienziati dei dati che utilizzano PySpark per l'EDA.
- API Python per origini dati: Spark 4.0 introduce una nuova API Python per origini dati che consente agli sviluppatori di implementare origini dati personalizzate per batch e streaming interamente in Python. In precedenza, la scrittura di un connettore per un nuovo formato di file, database o stream di dati richiedeva spesso conoscenze di Java/Scala. Ora, puoi creare lettori e scrittori in Python, il che apre Spark a una comunità più ampia di sviluppatori. Ad esempio, se hai un formato di dati personalizzato o un'API che ha solo un client Python, puoi incapsularlo come origine/sink di DataFrame Spark utilizzando questa API. Questa funzionalità migliora notevolmente l'estensibilità per PySpark sia in contesti batch che di streaming. Vedi il post di approfondimento su PySpark per un esempio di implementazione di una semplice origine dati personalizzata in Python o consulta un esempio qui. [Leggi il post del blog]
- UDTF Python polimorfiche: Basandosi sulla capacità UDTF SQL, PySpark ora supporta le User-Defined Table Functions in Python, incluse le UDTF polimorfiche che possono restituire forme di schema diverse a seconda dell'input. Puoi creare una classe Python come UDTF utilizzando un decoratore che produce un iteratore di righe di output e registrarla in modo che possa essere richiamata da Spark SQL o dall'API DataFrame. Un aspetto potente sono le UDTF con schema dinamico: la tua UDTF può definire un metodo analyze() per produrre uno schema al volo in base ai parametri, come la lettura di un file di configurazione per determinare le colonne di output. Questo comportamento polimorfico rende le UDTF estremamente flessibili, consentendo scenari come l'elaborazione di uno schema JSON variabile o la suddivisione di un input in un set variabile di output. Le UDTF PySpark consentono efficacemente alla logica Python di produrre un risultato di tabella completo per ogni invocazione, il tutto all'interno del motore di esecuzione Spark. [Vedi la documentazione]
Miglioramenti dello streaming
Apache Spark 4.0 continua a perfezionare Structured Streaming per migliorare prestazioni, usabilità e osservabilità:
- Elaborazione stateful arbitraria v2: Spark 4.0 introduce un nuovo operatore di elaborazione stateful arbitraria chiamato transformWithState. TransformWithState consente di creare pipeline operative complesse con supporto per la definizione di logica orientata agli oggetti, tipi composti, supporto per timer e TTL, supporto per la gestione dello stato iniziale, evoluzione dello schema dello stato e una serie di altre funzionalità. Questa nuova API è disponibile in Scala, Java e Python e fornisce integrazioni native con altre importanti funzionalità come il lettore di origini dati di stato, la gestione dei metadati dell'operatore, ecc. [Leggi il post del blog]
- Origine dati di stato - Reader: Spark 4.0 aggiunge la capacità di interrogare lo stato dello streaming come una tabella. Questa nuova origine dati di archiviazione dello stato espone lo stato interno utilizzato nelle aggregazioni di streaming stateful (come contatori, finestre di sessione, ecc.), join, ecc. come un DataFrame leggibile. Con opzioni aggiuntive, questa funzionalità consente inoltre agli utenti di monitorare le modifiche dello stato su base per aggiornamento per una visibilità granulare. Questa funzionalità aiuta anche a comprendere quale stato sta elaborando il tuo job di streaming e può ulteriormente assistere nella risoluzione dei problemi e nel monitoraggio della logica stateful dei tuoi stream, nonché nel rilevamento di eventuali corruzioni sottostanti o violazioni degli invarianti. [Leggi il post del blog]
- Miglioramenti dello State Store: Spark 4.0 aggiunge anche numerosi miglioramenti allo state store, come una migliore gestione del riutilizzo dei file Static Sorted Table (SST), miglioramenti nella gestione degli snapshot e della manutenzione, un formato di checkpoint dello stato rielaborato e ulteriori miglioramenti delle prestazioni. Insieme a ciò, sono state apportate numerose modifiche relative a un logging e una classificazione degli errori migliorati per un monitoraggio e una debuggabilità più semplici.
Ringraziamenti
Spark 4.0 è un enorme passo avanti per il progetto Apache Spark, con ottimizzazioni e nuove funzionalità che toccano ogni livello, dai miglioramenti del core alle API più ricche. In questa release, la community ha chiuso più di 5000 problemi JIRA e circa 400 contributori individuali, da sviluppatori indipendenti a organizzazioni come Databricks, Apple, Linkedin, Intel, OpenAI, eBay, Netease, Baidu, hanno guidato questi miglioramenti.
Estendiamo i nostri più sinceri ringraziamenti a ogni contributore, sia che tu abbia segnalato un ticket, revisionato codice, migliorato la documentazione o condiviso feedback nelle mailing list. Oltre ai principali miglioramenti di SQL, Python e streaming, Spark 4.0 offre anche il supporto per Java 21, l'operatore Spark K8S, connettori XML, supporto Spark ML su Connect e profilazione unificata delle UDF PySpark. Per l'elenco completo delle modifiche e tutti gli altri affinamenti a livello di motore, consulta le note di rilascio ufficiali di Spark 4.0.
Ottenere Spark 4.0: È completamente open source, scaricalo da spark.apache.org. Molte delle sue funzionalità erano già disponibili in Databricks Runtime 15.x e 16.x, e ora sono incluse di serie con Runtime 17.0. Per esplorare Spark 4.0 in un ambiente gestito, iscriviti alla Community Edition o avvia una prova, scegli "17.0" quando avvii il tuo cluster e potrai eseguire Spark 4.0 in pochi minuti.
Se ti sei perso il nostro meetup su Spark 4.0 dove abbiamo discusso queste funzionalità, puoi visualizzare le registrazioni qui. Inoltre, resta sintonizzato per futuri meetup di approfondimento su queste funzionalità di Spark 4.0.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.