Dal monolito al Lakebase fino all'LTAP: ripensare il database a partire dallo storage
di Reynold Xin
- Quasi tutti i database tradizionali conservano il log write-ahead e i file di dati sul disco di una singola macchina, causa principale del rischio di perdita di dati, di repliche di lettura costose, di cloni ad alta disponibilità e di query analitiche che rallentano le transazioni.
- Lakebase rende stateless il compute di Postgres esternalizzando il log e i file di dati in servizi cloud indipendenti (SafeKeeper e PageServer), sbloccando storage illimitato, compute elastico, scritture durevoli, una HA più semplice e branching istantaneo, il tutto senza alcuna latenza aggiuntiva significativa.
- LTAP va oltre memorizzando i dati operativi una sola volta in formati colonnari aperti letti sia da Postgres che dai motori Lakehouse, in modo che l'analisi venga eseguita sugli stessi dati freschi appena scritti dalle transazioni, senza pipeline CDC, senza una seconda copia e senza rallentamenti per il carico di lavoro transazionale. A differenza di HTAP, che tenta di unificare entrambi i carichi di lavoro in un unico motore, LTAP si unifica a livello di storage e mantiene il motore migliore per ogni attività.
Quando ho iniziato il mio dottorato alla UC Berkeley 16 anni fa, il mio relatore mi disse: "I database OLTP sono un problema risolto. Funzionano. Concentrati sull'analisi dei dati." Eravamo solo all'inizio della possibilità di raccogliere molti più dati, strutturati e non strutturati, e di applicare il machine learning (che oggi chiamiamo "AI"). Così ho seguito il consiglio e mi sono unito ai miei cofondatori nel progetto di ricerca che è diventato Apache Spark, e in seguito abbiamo fondato Databricks.
Mentre sviluppavamo Databricks, abbiamo iniziato a usare vari database disponibili sul mercato e ci siamo resi conto che i database OLTP erano tutt'altro che un problema risolto: erano macchinosi, difficili da scalare e incredibilmente fragili. A un certo punto eravamo così frustrati che ci siamo chiesti come sarebbe stato un database OLTP se lo avessimo progettato oggi. Questa domanda ci ha portato a Lakebase, il nostro database Postgres serverless.
Questo post approfondisce l'architettura OLTP di Lakebase. Inizieremo dal livello di storage di un database monolitico tradizionale per capire da dove derivano i problemi, per poi vedere come Lakebase riorganizza questi stessi elementi in servizi indipendenti ed esternalizzati. Infine, passeremo a LTAP, dove questa stessa architettura consente di eseguire transazioni e analisi su un'unica copia dei dati, in tempo reale, senza i ritardi e i costi aggiuntivi di CDC o "mirroring".
Il database come monolite
La stragrande maggioranza dei database in esecuzione oggi nel mondo è di tipo monolitico. Questo include MySQL, Postgres e il classico Oracle. Lakebase è basato su Postgres (che, guarda caso, è anch'esso nato a Berkeley), quindi useremo Postgres come esempio principale, ma la maggior parte dei database funziona in modo simile: si predispone una macchina che esegue il motore del database e lo storage. In questi sistemi di database, ci sono due elementi su disco che contano di più: il write ahead log (WAL) e i file di dati.
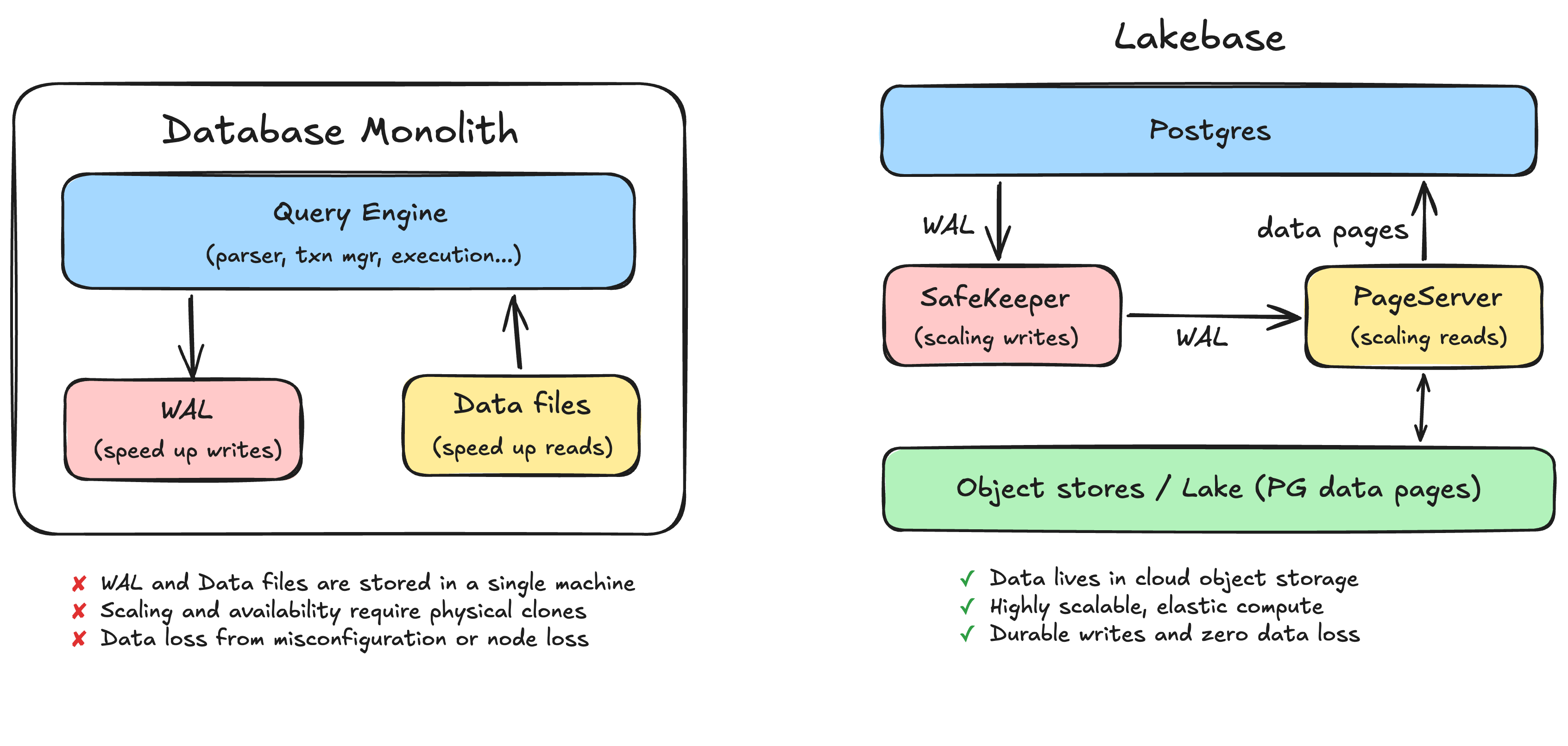
Quando si esegue il commit di una transazione, il database non riscrive immediatamente i file di dati. Sarebbe un processo lento, perché le righe interessate sono sparse all'interno del file in punti che richiedono I/O casuale. Al contrario, il database aggiunge prima una descrizione della modifica al WAL, che è un log sequenziale su disco. Una transazione viene considerata sottoposta a commit nel momento in cui tale voce di log viene scritta in modo permanente. Solo in un secondo momento, in modo asincrono, il database aggiorna i file di dati effettivi per riflettere la modifica.
Un modo semplice per vederla è questo: il WAL esiste per rendere veloci (e sicure) le scritture, mentre i file di dati esistono per rendere veloci le letture. Il log consente di eseguire il commit di una transazione con un'unica operazione di append sequenziale anziché con una serie di operazioni di I/O casuali sparse. I file di dati consentono di rispondere a una query leggendo direttamente lo stato corrente, invece di riprodurre l'intera cronologia del database dall'inizio dei tempi. (Se desideri comprendere tutti i complessi dettagli di questo design, leggi l'articolo ARIES di 69 pagine. Ti avvisiamo che si tratta di uno dei documenti più complessi dell'informatica.)
Sebbene questo design sia diventato la base di quasi tutti i database esistenti, l'architettura monolitica comporta anche molte sfide:
Perdita di dati dovuta a una configurazione errata. Un commit è permanente solo quanto lo è il flush su disco che lo supporta. Se il database, il sistema operativo o il livello di storage sono configurati in modo tale che una scrittura sul WAL venga confermata al client prima di essere stata effettivamente trasferita su un supporto permanente, il commit può andare perso in caso di interruzione di corrente o kernel panic. Queste impostazioni sono impercettibili, facili da sbagliare e l'errore è spesso silenzioso. Il sistema operativo potrebbe persino decidere di mentire sul completamento del flush!
Perdita di dati dovuta alla perdita di nodi. Anche con i flush configurati correttamente, il WAL e i file di dati risiedono su un'unica macchina. Se il disco di quella macchina smette di funzionare, anche i dati al suo interno andranno persi. Tieni presente che lo storage di rete o le tecniche di ridondanza come RAID-1/RAID-10 possono migliorare la durabilità, ma non risolvono radicalmente questo problema. Se il mount dello storage si interrompe, si interrompe anche l'accesso ai dati.
La scalabilità delle letture richiede un clone fisico. Quando una singola macchina non è più in grado di gestire il traffico, la soluzione standard consiste nell'aggiungere una replica di lettura. Tuttavia, una replica di lettura è una copia fisica completa dell'intero database, che riceve in streaming il WAL dal database primario e lo riproduce. Predisporne una significa copiare l'intero set di dati e poi rimettersi in pari con il log. Per un database di grandi dimensioni, questa non è un'operazione rapida e potrebbe persino causare il downtime del database.
Anche l'alta disponibilità richiede un clone fisico. Sopravvivere alla perdita del nodo primario significa eseguire almeno un nodo di standby aggiuntivo, che è a sua volta una copia fisica completa del database mantenuta sincronizzata tramite il WAL. In questo modo si paga almeno il doppio dell'infrastruttura, si attende molto tempo per mettere online un nodo di standby e si deve configurare la replica sincrona per evitare di perdere dati in caso di guasto del primario. (In pratica, molti consigliano 3 o più nodi.)
L'analisi dei dati compete con il traffico transazionale. Una query analitica complessa viene eseguita sulle stesse risorse hardware del carico di lavoro transazionale sensibile alla latenza. Una singola query di reportistica di grandi dimensioni o una pulizia GDPR possono rallentare le query OLTP principali. È possibile eseguire le query analitiche su una replica separata, ma si finisce per pagare per tale replica senza comunque ottenere prestazioni ottimali a causa della natura orientata alle righe dello storage OLTP (l'analisi dei dati richiede uno storage orientato alle colonne per garantire prestazioni elevate).
Quasi tutti questi problemi riconducono alla stessa causa principale dell'architettura monolitica: il WAL e i file di dati sono memorizzati all'interno di un'unica macchina. La durabilità è legata al disco di quella macchina. La scalabilità e la disponibilità richiedono la clonazione fisica di tale macchina. I carichi di lavoro interferiscono tra loro perché condividono la stessa macchina.
Architettura di Lakebase
Se oggi si dovesse riprogettare un database OLTP, si partirebbe dai componenti del cloud moderno: uno storage a oggetti cloud economico e altamente durevole abbinato a risorse di calcolo elastiche. Questo è il percorso intrapreso dal team di Neon e la base di ciò che è diventato Lakebase.
La mossa fondamentale consiste nel rendere stateless le istanze di calcolo di Postgres. Per farlo, esternalizziamo il WAL e i file di dati presenti sui dischi locali in servizi dedicati e scalabili in modo indipendente. Il livello di calcolo diventa un motore Postgres stateless che può essere avviato, arrestato e replicato liberamente, poiché non possiede più i dati.
Vediamo come questi due servizi di storage possono collaborare per risolvere le sfide sopra menzionate senza compromettere le prestazioni.
Scalabilità delle scritture: il WAL diventa SafeKeeper
In un monolite, una scrittura viene resa permanente eseguendone il flush sul disco locale. In Lakebase, il WAL viene esternalizzato in un servizio di storage distribuito chiamato SafeKeeper. Invece di affidarsi al flush su disco per la durabilità, un commit viene reso permanente replicando il record di log su un quorum di nodi SafeKeeper tramite una replica di rete basata su Paxos. Non esiste più un disco il cui guasto possa causare la perdita dei dati, né un flush configurato in modo errato che comprometta silenziosamente la garanzia di durabilità.
A questo punto è naturale chiedersi: lo spostamento dei commit dal WAL su disco locale al WAL su SafeKeeper aumenta la latenza di scrittura a causa del passaggio di rete aggiuntivo? La risposta è no. Per qualsiasi implementazione Postgres seria che si preoccupi di durabilità e disponibilità, sarebbe comunque necessario configurare la replica sincrona, che richiede un passaggio di rete aggiuntivo; pertanto, l'esternalizzazione del WAL in SafeKeeper non comporta alcun sovraccarico aggiuntivo. In effetti, a causa del funzionamento interno di Postgres, la combinazione di SafeKeeper e PageServer può portare a un throughput di scrittura 5 volte superiore e a una latenza di lettura 2 volte inferiore.
Scalabilità delle letture: i file di dati diventano PageServer
I file di dati si spostano in un altro servizio di storage distribuito chiamato PageServer. Il WAL viene trasmesso in streaming da SafeKeeper a PageServer, e quest'ultimo applica in modo asincrono tali modifiche alla propria versione dei dati, materializzando le pagine in uno storage a oggetti cloud a basso costo (il lake). Si può pensare a PageServer come a una cache write-through per lo storage a oggetti sottostante.
Questo è simile alla relazione tra WAL e file di dati del monolito, con la differenza che le due metà ora risiedono in servizi separati e scalabili in modo indipendente, connessi tramite la rete anziché trovarsi sullo stesso disco. Quando viene richiesta una pagina dal PageServer, e se il PageServer non dispone ancora dell'ultima versione (ricorda che le modifiche vengono scritte prima sul SafeKeeper prima di arrivare al PageServer), il PageServer applica i log del SafeKeeper per ricostruire lo stato più recente.
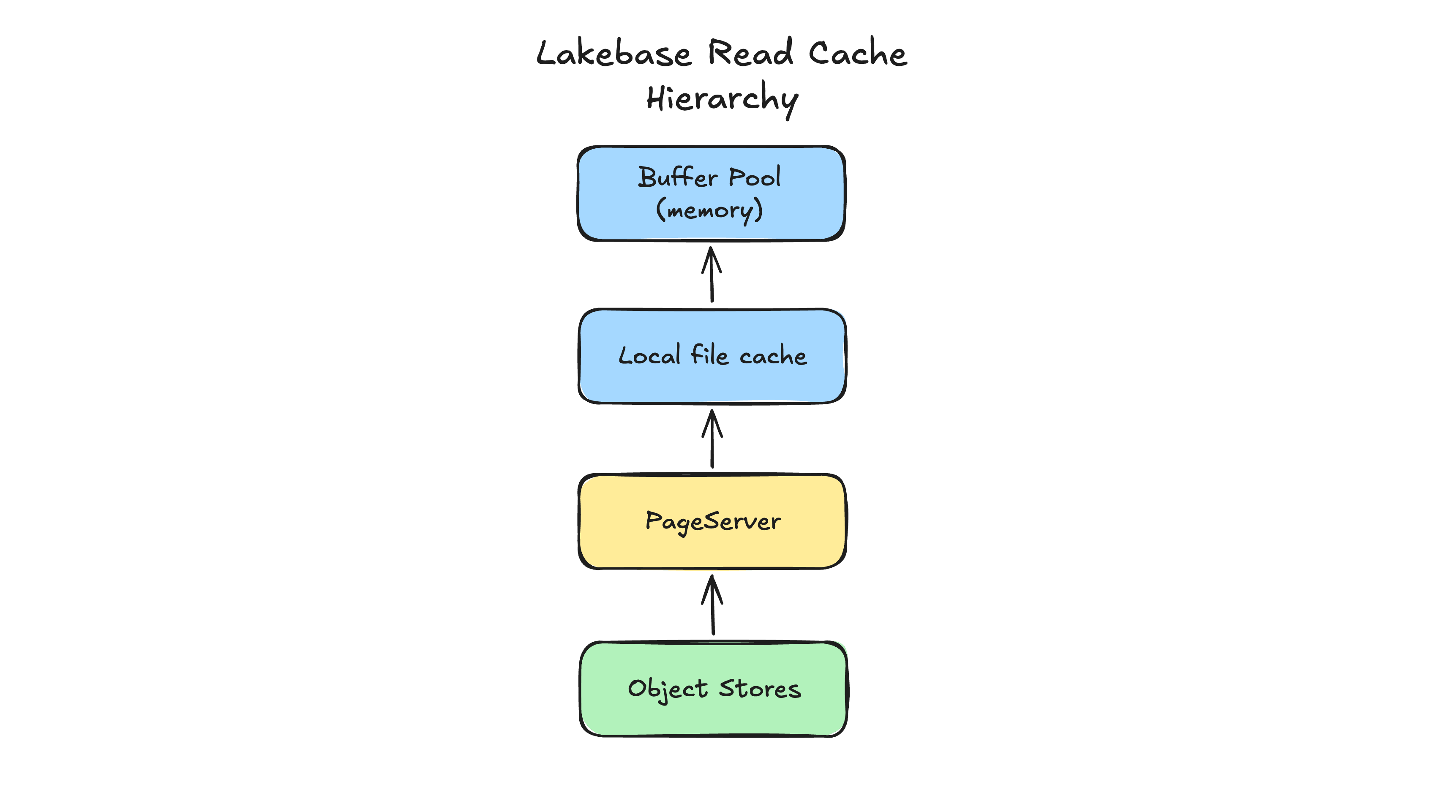
Una domanda simile: lo spostamento dei file di dati dai dischi locali al PageServer aumenta la latenza di lettura a causa del passaggio di rete aggiuntivo? La risposta è no, all'atto pratico. Il sistema è progettato per isolare e ridurre al minimo l'impatto della latenza attraverso un caching aggressivo e multilivello. Per recuperare una pagina, Postgres consulta prima il suo buffer pool, che si trova nella memoria locale del nodo. Quando la pagina non è presente, consulta una cache del disco locale. Deve rivolgersi al PageServer solo in caso di cache miss. Poiché un nodo di calcolo può essere configurato con capacità di memoria locale e di disco identiche a quelle di una configurazione monolitica, il tasso di cache hit locale rimane invariato. Per la stragrande maggioranza delle operazioni, la latenza di lettura è indistinguibile da quella di un monolito, ma si ottiene il vantaggio di uno storage disaccoppiato e virtualmente infinito.
Cosa sblocca questa soluzione
Una volta che il WAL risiede nel SafeKeeper e i file di dati nel PageServer, una lunga serie di funzionalità che erano difficili o impossibili nel monolito diventano conseguenze naturali dell'architettura. Le seguenti sono già ampiamente disponibili come parte del prodotto Lakebase sia su Databricks che su Neon:
Ancora Postgres. Si tratta del vero Postgres, quindi il protocollo di rete, SQL, i driver e le estensioni funzionano tutti così come sono.
Storage illimitato. I dati risiedono nello storage di oggetti cloud anziché su un disco locale allocato. Non dovrai più dimensionare una macchina in base a un limite di capacità. Lo storage è, all'atto pratico, infinito.
Calcolo serverless ed elastico. Poiché il calcolo è stateless, può scalare istantaneamente sotto carico e ridursi fino a zero quando è inattivo. Smetterai di pagare per una macchina di grandi dimensioni che rimane in attesa del traffico.
Scritture durevoli e nessuna perdita di dati. Un commit è durevole una volta replicato sui nodi SafeKeeper tramite Paxos, non quando un singolo disco locale dichiara di averlo scaricato. La perdita di un singolo nodo non comporta la perdita dei dati sottoposti a commit.
HA più semplice. Nel monolito, HA significava mantenere un secondo clone fisico completo, pagare il doppio e rischiare comunque la perdita di dati al momento del passaggio. Qui, lo stato durevole risiede già in un livello di storage replicato indipendente da qualsiasi singola istanza di calcolo. Il failover non significa più promuovere una copia fisica separata del database sperando che l'ultimo segmento del log sia stato trasferito.
Branching, clonazione e ripristino istantanei. Questo è il mio preferito. Per il codice, la creazione di un branch è una copia completamente isolata dell'intera codebase creata in meno di un secondo, e lo facciamo decine di volte al giorno senza pensarci. Per un database monolitico, la clonazione significa copiare fisicamente l'intero set di dati, il che è lento, costoso e rischioso per il sistema di produzione. Quando i dati risiedono in un livello di storage esternalizzato e dotato di versioning, un branch o un clone è un'operazione sui metadati anziché una copia fisica. Puoi creare il branch di un database di produzione di grandi dimensioni in pochi secondi, eseguire un esperimento o una migrazione rischiosa sul branch e poi eliminarlo. Il ripristino a un momento specifico nel tempo funziona allo stesso modo. Finalmente il database si muove alla velocità del tuo codice.
La separazione tra calcolo e storage non è di per sé una novità. Il post precedente ha analizzato i database cloud di seconda generazione che lo facevano già. Tuttavia, la chiave di Lakebase è che memorizziamo i dati operativi su storage di oggetti standard in un formato aperto. In questo modo, offriamo ad altri motori l'opportunità di leggerli direttamente, il che porta a LTAP.
LTAP: un'unica copia per transazioni e analytics
Finora abbiamo parlato solo di come migliorare un singolo database operativo: renderlo più durevole, più elastico, più economico da gestire, più veloce da ramificare. Ma una volta che i dati risiedono in un livello di storage esternalizzato, diventa possibile qualcosa di più interessante. Possiamo smettere di considerare il database transazionale e il sistema analitico come due mondi separati.
Torniamo per un momento al PageServer. Questo riceve già il flusso di modifiche dal WAL e materializza in modo asincrono le pagine nello storage di oggetti. Quella fase di materializzazione, il momento in cui i dati atterrano nel lake, si rivela essere esattamente il posto giusto per risolvere un problema molto più vecchio...
Anche con un Lakebase, i dati nello storage di oggetti venivano comunque scritti nel formato di pagina nativo di Postgres, disposti riga per riga. Questo formato è ottimo per le transazioni e scarso per l'analisi, quindi qualsiasi motore analitico che volesse leggerlo doveva pagare un costo di conversione a ogni lettura o, più comunemente, affidarsi a una copia separata dei dati mantenuta sincronizzata da una pipeline. La pipeline può essere fragile e le due copie dei dati possono diventare un incubo di governance con autorizzazioni divergenti.
Di recente abbiamo annunciato LTAP, ovvero Lake Transactional/Analytical Processing, che elimina il problema delle due copie dei dati. L'idea chiave è unificare i due mondi a livello di storage anziché a livello di motore. Non cerchiamo di creare un unico motore che sia in qualche modo eccellente sia per le transazioni che per l'analisi. Manteniamo lo strumento migliore per ogni compito: Postgres, con semantica ACID completa per le transazioni, e i motori Lakehouse per l'analisi. Ciò che cambia sono i dati sottostanti. Invece di due copie in due formati, c'è un'unica copia durevole, in formati colonnari aperti come Delta e Iceberg, memorizzati come Parquet, che entrambi i lati leggono (e con vari livelli di cache per prestazioni migliori).
Materializzazione in formato colonnare
Nota: questa sezione richiede una maggiore conoscenza interna di Postgres rispetto ad altre sezioni.
Mentre il PageServer materializza le pagine nello storage di oggetti, esegue la transcodifica dei dati di Postgres da un formato a righe al layout colonnare di Parquet man mano che atterrano nel lake. Preserviamo l'esatta rappresentazione Postgres di ogni valore, fino ai singoli bit, in modo che qualsiasi motore compatibile con Postgres possa reinterpretarlo senza perdere informazioni. Questo approccio è diverso da quello basato su CDC, poiché CDC invia un flusso di eventi di modifica logica in uno schema esterno e tralascia la semantica fisica e transazionale di Postgres; qui invece la manteniamo. Con un motore iperottimizzato, la CPU libera nel livello PageServer esegue la transcodifica da riga a colonna come parte della materializzazione dei dati nello storage di oggetti, senza quindi gravare sul calcolo di Postgres che gestisce le transazioni. Per servire le letture transazionali in modo efficiente, il PageServer materializza comunque le tradizionali pagine basate su righe in una cache locale, ma si tratta esclusivamente di una cache prestazionale. Lo store durevole sottostante rimane unificato nel lake, accessibile da entrambi i lati.
Preservare la semantica di Postgres in formato colonnare si riduce a due cose: il sistema di tipi e il multi-versioning.
Sistema di tipi. La maggior parte dei tipi Postgres si mappa direttamente sui tipi Parquet nativi. La manciata di valori senza una controparte colonnare senza perdita di dati, ad esempio NaN e ±Infinity, i tipi NUMERIC oltre l'intervallo decimale, i tipi esotici o di estensione, non vengono scartati o forzati. Vengono trasportati insieme alle colonne originali in un campo di overflow strutturato all'interno della stessa tabella, contenente il testo canonico di Postgres per tali valori. Questo campo è direttamente interrogabile da qualsiasi motore ed è sufficiente per ricostruire esattamente i byte Postgres originali durante il percorso inverso.
Multi-versioning. In Postgres, viene conservata ogni versione di riga che una transazione potrebbe osservare, il che è esattamente ciò che rende possibili l'isolamento degli snapshot e il PITR. Al contrario, i formati di tabella aperti espongono snapshot coerenti a livello di tabella senza versioni di riga intermedie. Otteniamo i vantaggi di entrambi gli approcci separando la durevolezza dalla visibilità. Ogni riga materializzata in formato colonnare porta con sei il proprio indirizzo heap fisico (blocco e offset), in modo che le pagine heap rimangano completamente ricostruibili. La classica pagina heap di Postgres diventa una cache che accelera le letture puntuali, mentre la fonte di verità durevole risiede nei file colonnari nello storage di oggetti. Gli indici di Postgres non vengono transcodificati in colonne; vengono serviti e ricostruiti da quel livello di cache calda. Le versioni di riga intermedie vengono conservate per preservare la semantica MVCC e il PITR di Postgres, ma non sono visibili ai lettori Iceberg/Delta e vengono infine eliminate tramite garbage collection. Il risultato netto: i motori analitici vedono tabelle pulite e coerenti con gli snapshot, mentre il sistema Postgres sottostante vede ancora una cronologia delle versioni completa e navigabile nel tempo.
C'è anche un piacevole effetto collaterale. I dati colonnari si comprimono molto meglio dei dati riga, spesso di oltre dieci volte, quindi la conversione in storage colonnare riduce sostanzialmente il volume di dati che attraversa la rete tra il livello di caching e l'object store, al punto che spesso è trascurabile. Il formato che rende veloce l'analisi rende anche più economico il percorso di storage. Sfruttiamo questo aspetto anche per scrivere contemporaneamente sia in formato riga che in formato colonnare negli object store per la verifica dei dati durante la fase di rollout transitorio di LTAP (poiché vogliamo essere estremamente attenti alle modifiche dello storage).
Leggere i dati più recenti senza influire su Postgres
Una grande sfida è la freschezza dei dati. Se l'analisi legge da una copia nel lake, come fa a vedere i dati di cui è stato fatto il commit un momento fa e che non sono ancora stati materializzati nell'object store? Questa è la domanda che fa fallire la maggior parte dei progetti basati sul "basta puntare l'analisi verso il lake", quindi vale la pena esaminare come risponde LTAP.
Quando si avvia una query analitica (ad esempio dal prodotto Lakehouse//RT che abbiamo appena annunciato), questa chiede innanzitutto a Postgres l'LSN corrente, ovvero il numero di sequenza del log che indica l'esatta posizione nel WAL da cui leggere. Si tratta di una ricerca di metadati economica. Con quell'LSN, il motore analitico legge la stragrande maggioranza dei dati, compreso tutto ciò che è già stato materializzato fino a quel momento, direttamente dall'object storage. L'unica cosa rimasta è il piccolo insieme di modifiche molto recenti che non sono ancora state materializzate nel lake, che recupera dal PageServer e unisce sopra.
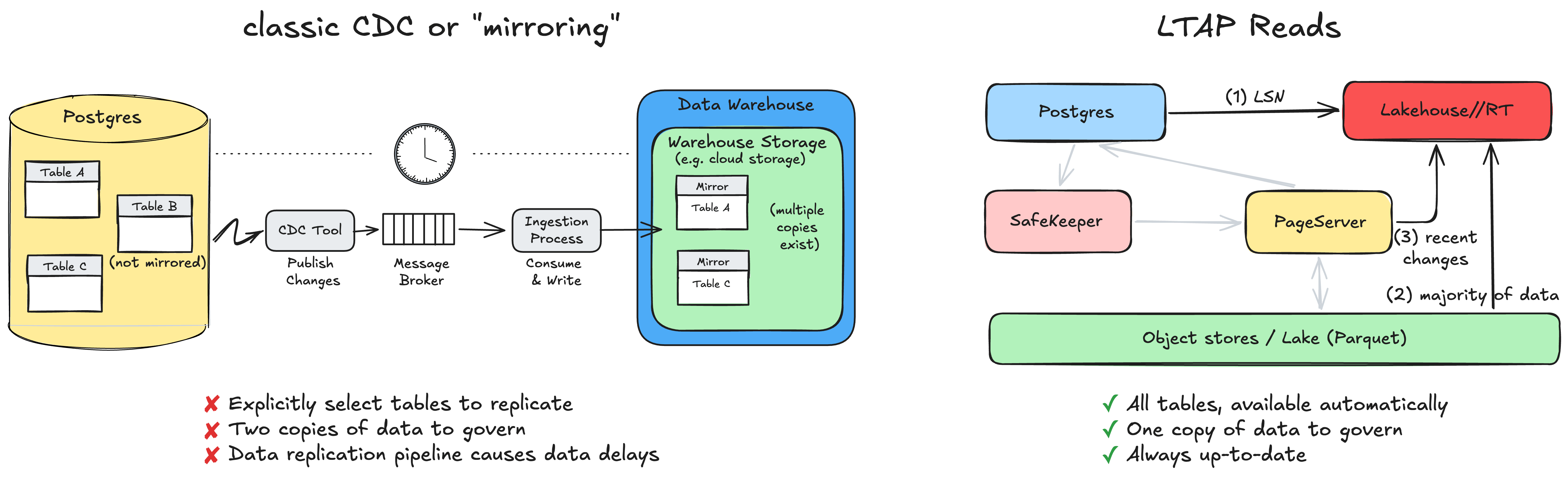
Il risultato è una lettura coerente e completamente aggiornata dei dati a partire da quell'LSN. Quasi tutto il lavoro ricade su un object storage economico e scalabile. E, cosa fondamentale, Postgres stesso non gestisce alcuno dei flussi di lettura analitici, se non restituendo un singolo numero (LSN). Il carico di lavoro transazionale non rallenta perché qualcuno ha avviato una query analitica di grandi dimensioni.
C'è un'ottimizzazione pratica che vale la pena menzionare: per le tabelle molto piccole, quelle che contengono una manciata di righe, non ci preoccupiamo di convertirle in formato colonnare e di creare i relativi metadati Iceberg. La gestione costerebbe più di quanto farebbe risparmiare, e una tabella così piccola non ha alcun effetto misurabile sulle prestazioni analitiche, indipendentemente da come è strutturata. Queste tabelle sono ancora presenti e interrogabili come parte della singola copia.
Ogni tabella, automaticamente
A causa dell'importanza di questo problema, sul mercato si è fatto un gran parlare dell'integrazione di OLTP e analisi. Un approccio classico è il CDC, che replica efficacemente i dati dallo storage OLTP in un livello di storage analitico separato. Potresti aver sentito parlare di altri nomi come “mirroring”, “zero CDC” o “zero ETL”.
Nel CDC o “mirroring”, poiché la pipeline di replica dei dati ha un costo, non può essere applicata a tutte le tabelle. Dovresti selezionare esplicitamente le tabelle che ti interessano e questa replica comporta in genere un ritardo.
Con LTAP non c'è nulla da attivare. Una tabella esistente si trova, per costruzione, già nel lake ed è già interrogabile. Non esiste un elenco di tabelle replicate o specchiate, perché non c'è alcuna replica. Esiste un'unica copia governata dei dati in formati aperti, senza alcuna pipeline ETL da creare, monitorare o riparare (sia da parte dei nostri clienti che nostra). I motori transazionali e analitici scalano in modo indipendente, ciascuno dimensionato per il proprio carico di lavoro. E poiché non c'è spostamento di dati né una seconda copia, le due viste non possono mai divergere: l'analisi legge sempre gli stessi dati appena scritti dall'applicazione.
Per dare un'altra occhiata a come funziona LTAP, guarda questa demo del Data and AI Summit.
E l'HTAP?
Se conosci il settore, avrai già notato che LTAP è un gioco di parole deliberato su HTAP: hybrid transactional/analytical processing. L'HTAP è stato il "sacro graal" dell'ingegneria dei database, concentrandosi sulla creazione di un unico motore in grado di gestire carichi di lavoro sia transazionali che analitici.
In pratica, non è mai esistito un singolo sistema di database HTAP ampiamente adottato. Come mai? A mio parere, i sistemi HTAP risentono di uno o più dei seguenti problemi:
Set di funzionalità incompleto. Progettare da zero un nuovo motore proprietario per svolgere un singolo compito è un investimento pluriennale. Cercare di creare un unico motore in grado di svolgere il lavoro di più motori moltiplica l'investimento necessario per raggiungere il set di funzionalità che gli ingegneri danno per scontato in un database maturo. Questi sistemi spesso sono in ritardo su aspetti che si presume siano sempre presenti, dall'ampiezza del supporto SQL (ad esempio, il supporto delle chiavi esterne) alla maturità dell'ottimizzatore di query.
Nessun ecosistema. Postgres e Spark si trovano ciascuno al centro di un vasto ecosistema: driver, estensioni, strumenti e decenni di conoscenze operative accumulate. Un motore completamente nuovo parte al di fuori di tutto questo, e un motore è utile solo quanto l'ecosistema su cui un team può effettivamente costruire.
Nessun isolamento delle prestazioni. Molti sistemi HTAP eseguono transazioni e analisi sullo stesso hardware, quindi i due carichi di lavoro competono per la stessa CPU e memoria. Questo è lo stesso fallimento da cui siamo partiti con il monolito, con una query analitica che priva di risorse il carico di lavoro transazionale.
Tutti e tre i problemi risalgono alla stessa decisione di unificare i due carichi di lavoro in un unico motore. Lakebase e LTAP aggirano queste sfide unificandosi a livello di storage, utilizzando al contempo motori di calcolo diversi per i differenti carichi di lavoro, sfruttando appieno i loro set di funzionalità e il supporto dell'ecosistema, con un isolamento completo delle prestazioni.
Considerazioni finali
Quando l'anno scorso abbiamo proposto per la prima volta l'architettura Lakebase, sapevamo già che avrebbe sbloccato storage illimitato, calcolo elastico, scritture durevoli, HA più semplice e branching istantaneo, in base a quanto visto con la piattaforma Neon. Questi vantaggi sono arrivati quasi meccanicamente una volta che il WAL ha iniziato a risiedere nel SafeKeeper e i file di dati nel PageServer.
L'idea di LTAP è nata in un secondo momento, dopo che i team di Neon e Databricks si sono uniti per risolvere il problema decennale di eseguire analisi sui dati transazionali più freschi. Man mano che risolveremo gli ultimi dettagli di LTAP e lo distribuiremo nei prossimi mesi, tutte le tue tabelle Lakebase saranno semplicemente disponibili per l'analisi con prestazioni elevate tanto quanto i dati del Lakehouse.
Ciò che mi entusiasma di più è quello che ci aspetta. Sebbene LTAP sia un passo successivo naturale, lo stesso design apre anche molte opportunità di ottimizzazione per separare altre pesanti operazioni di manutenzione dai carichi di lavoro transazionali principali. Abbiamo appena iniziato a esplorare ciò che questa architettura rende possibile e non vediamo l'ora di condividere le prossime novità.
Ringraziamenti: vorrei ringraziare il team di Lakebase per aver reso reale tutto ciò di cui abbiamo parlato in questo blog, per averlo revisionato e per avermi aiutato a mantenere l'accuratezza dei dettagli tecnici.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.