Lakeflow Connect: Ingestione dati efficiente e semplice tramite il connettore SQL Server
Esplora il connettore SQL Server completamente gestito di Databricks Lakeflow Connect per semplificare l'ingestione e l'integrazione dei dati senza interruzioni con gli strumenti Databricks per l'elaborazione dei dati e l'analisi.
di Andrea Tardif, Prasanna Selvaraj, Hector Bustamante e Phanitha Kommareddi
- Le principali aziende tecnologiche affrontano sfide complesse nell'estrarre valore dai loro dati SQL Server per l'AI e l'analisi.
- Lakeflow Connect per SQL Server fornisce un'ingestione efficiente e incrementale sia per database on-premises che cloud.
- Questo blog esamina le considerazioni architetturali, i prerequisiti e le istruzioni passo-passo per l'ingestione dei dati di SQL Server nel tuo lakehouse.
Complessità nell'estrazione dei dati da SQL Server
Mentre le aziende digital native riconoscono il ruolo critico dell'IA nel promuovere l'innovazione, molte affrontano ancora sfide nel rendere i propri dati prontamente disponibili per utilizzi a valle, come lo sviluppo di machine learning e l'analisi avanzata. Per queste organizzazioni, supportare i team aziendali che si affidano a SQL Server significa disporre di risorse di data engineering e mantenere connettori personalizzati, preparare i dati per l'analisi e garantirne la disponibilità ai team di dati per lo sviluppo di modelli. Spesso, questi dati devono essere arricchiti con fonti aggiuntive e trasformati prima di poter informare decisioni basate sui dati.
Mantenere questi processi diventa rapidamente complesso e fragile, rallentando l'innovazione. Ecco perché Databricks ha sviluppato Lakeflow Connect, che include connettori dati integrati per database popolari, applicazioni aziendali e origini file. Questi connettori forniscono un'ingestione incrementale efficiente end-to-end, sono flessibili e facili da configurare, e sono completamente integrati con la Databricks Data Intelligence Platform per una governance, osservabilità e orchestrazione unificate. Il nuovo connettore Lakeflow per SQL Server è il primo connettore per database con una robusta integrazione sia per database on-premises che cloud per aiutare a derivare insight dai dati all'interno di Databricks.
In questo blog, esamineremo le considerazioni chiave su quando utilizzare Lakeflow Connect per SQL Server e spiegheremo come configurare il connettore per replicare i dati da un'istanza di Azure SQL Server. Successivamente, esamineremo un caso d'uso specifico, le best practice e come iniziare.
Considerazioni Architettoniche Chiave
Di seguito sono riportate le considerazioni chiave per decidere quando utilizzare il connettore SQL Server.
Compatibilità Regione e Funzionalità
Lakeflow Connect supporta una ampia gamma di varianti di database SQL Server, tra cui Microsoft Azure SQL Database, Amazon RDS per SQL Server, Microsoft SQL Server in esecuzione su Azure VM e Amazon EC2, e SQL Server on-premises accessibile tramite Azure ExpressRoute o AWS Direct Connect.
Poiché Lakeflow Connect viene eseguito su pipeline Serverless in background, è possibile sfruttare funzionalità integrate come l'osservabilità delle pipeline, l'alerting tramite log eventi e il monitoraggio del lakehouse. Se Serverless non è supportato nella tua regione, collabora con il tuo Databricks Account Team per presentare una richiesta che aiuti a dare priorità allo sviluppo o alla distribuzione in quella regione.
Lakeflow Connect è costruito sulla Data Intelligence Platform, che fornisce un'integrazione trasparente con Unity Catalog (UC) per riutilizzare permessi e controlli di accesso consolidati su nuove origini SQL Server per una governance unificata. Se le tue tabelle e viste Databricks sono su Hive, ti consigliamo di aggiornarle a UC per beneficiare di queste funzionalità (AWS | Azure | GCP)!
Requisiti Dati di Modifica
Lakeflow Connect può essere integrato con SQL Server con Microsoft change tracking (CT) o Microsoft Change Data Capture (CDC) abilitato per supportare un'ingestione incrementale ed efficiente.
CDC fornisce informazioni storiche sulle modifiche relative a operazioni di insert, update e delete, e quando i dati effettivi sono cambiati. Change tracking identifica quali righe sono state modificate in una tabella senza catturare le modifiche effettive dei dati. Scopri di più su CDC e sui benefici dell'utilizzo di CDC con SQL Server.
Databricks consiglia di utilizzare il change tracking per qualsiasi tabella con una chiave primaria per minimizzare il carico sul database di origine. Per le tabelle di origine senza chiave primaria, utilizzare CDC. Scopri di più su quando utilizzarlo qui.
Il connettore SQL Server cattura un caricamento iniziale dei dati storici alla prima esecuzione della pipeline di ingestione. Successivamente, il connettore traccia e ingerisce solo le modifiche apportate ai dati dall'ultima esecuzione, sfruttando le funzionalità CT/CDC di SQL Server per ottimizzare le operazioni e l'efficienza.
Governance e Sicurezza Reti Private
Quando viene stabilita una connessione con SQL Server utilizzando Lakeflow Connect:
- Il traffico tra l'interfaccia client e il piano di controllo è crittografato in transito utilizzando TLS 1.2 o versioni successive.
- Il volume di staging, dove i file raw vengono archiviati durante l'ingestione, è crittografato dal provider di archiviazione cloud sottostante.
- I dati a riposo sono protetti seguendo le best practice e gli standard di conformità.
- Quando configurato con endpoint privati, tutto il traffico dati rimane all'interno della rete privata del provider cloud, evitando Internet pubblico.
Una volta che i dati vengono ingeriti in Databricks, vengono crittografati come altri dataset all'interno di UC. Il gateway di ingestione che estrae snapshot, log delle modifiche e metadati dal database di origine atterra in un Volume UC, un'astrazione di storage ideale per registrare dataset non tabulari come file JSON. Questo Volume UC risiede all'interno dell'account di archiviazione cloud del cliente, all'interno delle sue Reti Virtuali o Virtual Private Cloud.
Inoltre, UC applica controlli di accesso granulari e mantiene audit trail per governare l'accesso a questi dati appena ingeriti. Le credenziali di servizio UC e le credenziali di archiviazione sono archiviate come oggetti securizzabili all'interno di UC, garantendo una gestione sicura e centralizzata dell'autenticazione. Queste credenziali non vengono mai esposte nei log né codificate nelle pipeline di ingestione SQL, fornendo una robusta protezione e controllo degli accessi.
Se la tua organizzazione soddisfa i criteri sopra indicati, considera Lakeflow Connect per SQL Server per semplificare l'ingestione dei dati in Databricks.
Riepilogo della Soluzione Tecnica
Successivamente, esamina i passaggi per configurare Lakeflow Connect per SQL Server e replicare i dati da un'istanza di Azure SQL Server.
Configura i Permessi di Unity Catalog
All'interno di Databricks, assicurati che il compute serverless sia abilitato per notebook, workflow e pipeline (AWS | Azure | GCP). Quindi, valida che l'utente o il principal del servizio che crea la pipeline di ingestione disponga delle seguenti autorizzazioni UC:
| Tipo di Permesso | Motivo | Documentazione |
| CREATE CONNECTION sul metastore | Lakeflow Connect deve stabilire una connessione sicura a SQL Server. | CREATE CONNECTION |
| USE CATALOG sul catalogo di destinazione | Richiesto in quanto fornisce l'accesso al catalogo in cui Lakeflow Connect depositerà le tabelle dati di SQL Server in UC. | USE CATALOG |
| USA SCHEMA, CREA TABELLA e CREA VOLUME su uno schema esistente o CREA SCHEMA sul catalogo di destinazione | Fornisce i diritti necessari per accedere agli schemi e creare posizioni di archiviazione per le tabelle di dati ingerite. | CONCEDI PRIVILEGI |
| Permessi illimitati per creare cluster o una policy di cluster personalizzata | Necessario per avviare le risorse di calcolo richieste per il processo di ingestion del gateway | GESTISCI POLICY DI CALCOLO |
Configura Azure SQL Server
Per utilizzare il connettore SQL Server, conferma che i seguenti requisiti siano soddisfatti:
- Conferma la versione di SQL
- SQL Server 2012 o una versione successiva deve essere abilitata per utilizzare il change tracking. Tuttavia, si consiglia 2016+. Rivedi i requisiti della versione SQL qui.
- Configura l'account di servizio del database dedicato all'ingestion di Databricks.
- Abilita change tracking o CDC integrato
- Devi avere SQL Server 2012 o una versione successiva per utilizzare CDC. Le versioni precedenti a SQL Server 2016 richiedono inoltre l'edizione Enterprise.
* Requisiti a partire da maggio 2025. Soggetti a modifiche.
Esempio: Ingestion da Azure SQL Server a Databricks
Successivamente, ingeriremo una tabella da un database Azure SQL Server a Databricks utilizzando Lakeflow Connect. In questo esempio, CDC e CT forniscono una panoramica di tutte le opzioni disponibili. Poiché la tabella in questo esempio ha una chiave primaria, CT avrebbe potuto essere la scelta principale. Tuttavia, poiché c'è solo una piccola tabella in questo esempio, non c'è preoccupazione per il sovraccarico di carico, quindi è stato incluso anche CDC. Si consiglia di rivedere quando utilizzare CDC, CT o entrambi per determinare quale sia il migliore per i tuoi dati e i requisiti di aggiornamento.
1. [Azure SQL Server] Verifica e Configura Azure SQL Server per CDC e CT
Inizia accedendo al portale Azure ed effettuando l'accesso con le tue credenziali dell'account Azure. Sul lato sinistro, fai clic su Tutti i servizi e cerca SQL Server. Trova e fai clic sul tuo server, quindi fai clic su ‘Query Editor’; in questo esempio, è stato selezionato sqlserver01.
Lo screenshot seguente mostra che il database SQL Server ha una tabella chiamata ‘drivers’.
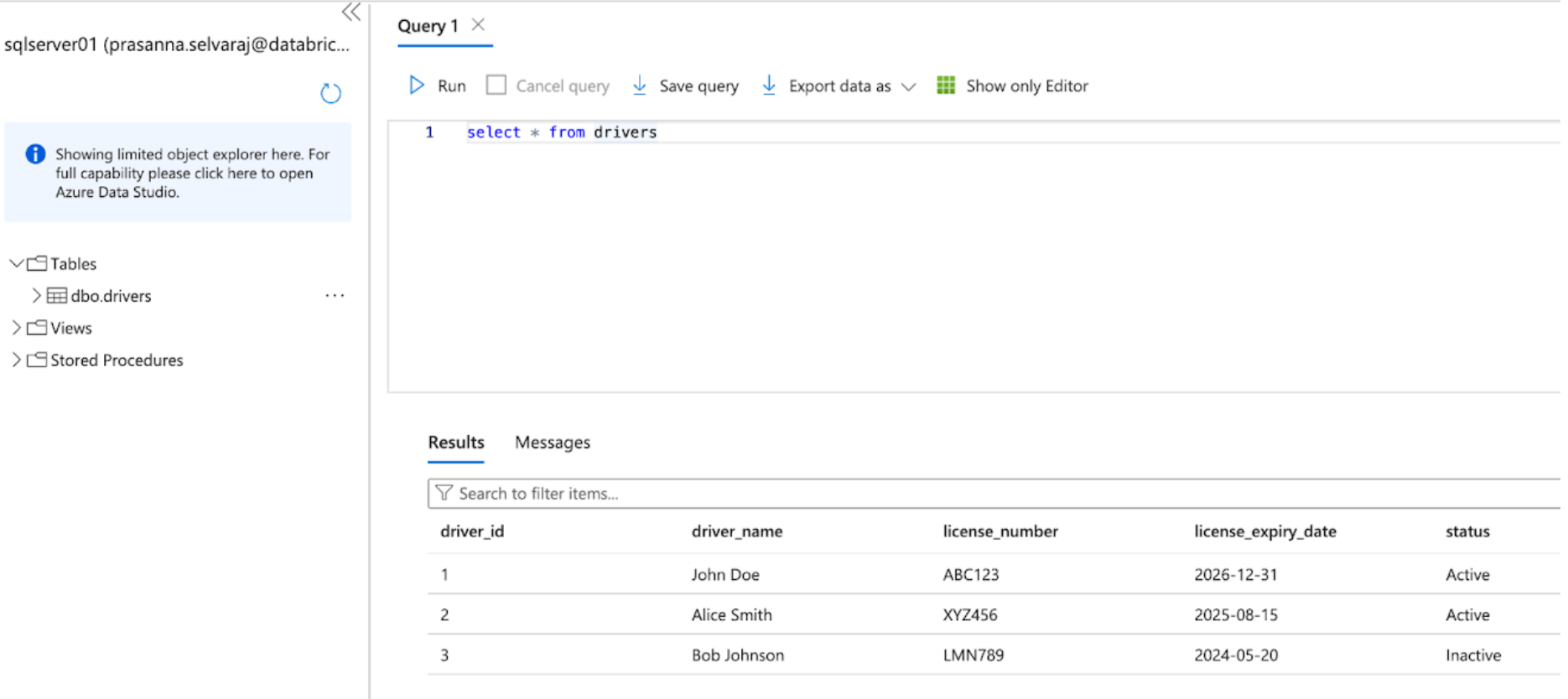
Prima di replicare i dati su Databricks, è necessario abilitare il change data capture, il change tracking o entrambi.
Per questo esempio, il seguente script viene eseguito sul database per abilitare CT:
Questo comando abilita il change tracking per il database con i seguenti parametri:
- CHANGE_RETENTION = 3 DAYS: Questo valore tiene traccia delle modifiche per 3 giorni (72 ore). Sarà necessario un aggiornamento completo se il tuo gateway è offline per un periodo superiore al tempo impostato. Si consiglia di aumentare questo valore se si prevedono interruzioni più lunghe.
- AUTO_CLEANUP = ON: Questa è l'impostazione predefinita. Per mantenere le prestazioni, rimuove automaticamente i dati di change tracking più vecchi del periodo di conservazione.
Quindi, il seguente script viene eseguito sul database per abilitare CDC:
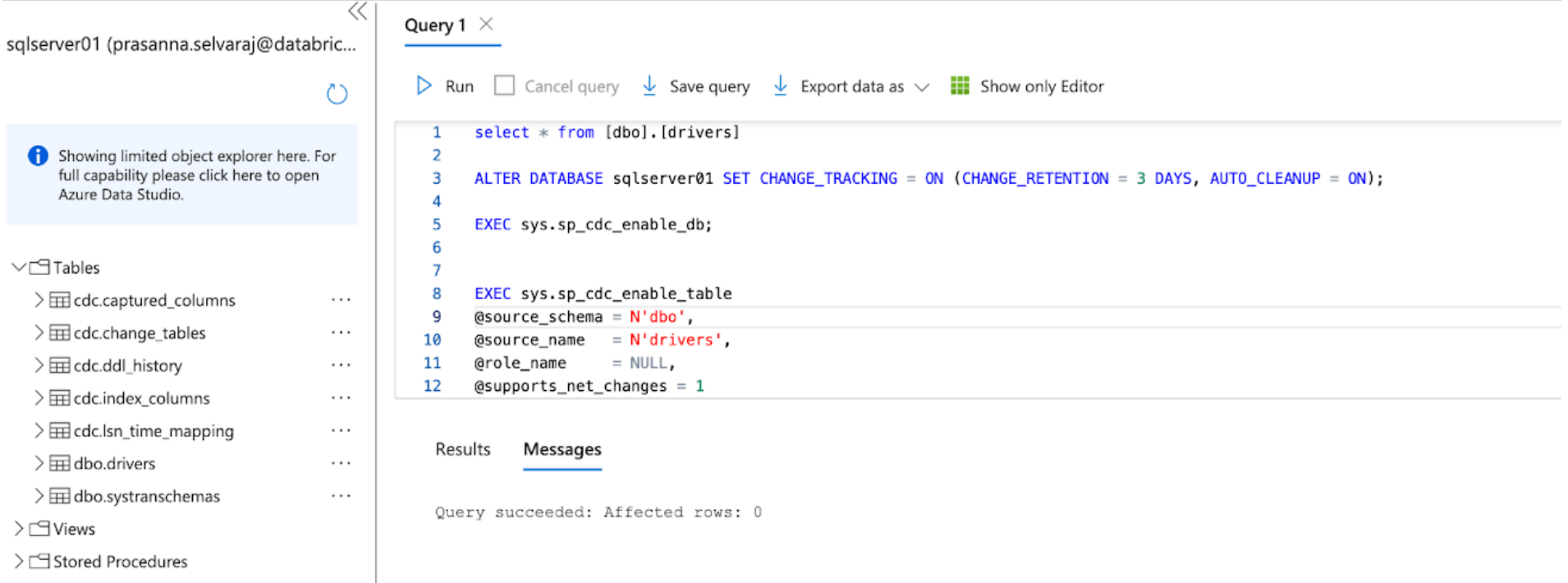
Quando entrambi gli script terminano l'esecuzione, rivedi la sezione delle tabelle sotto l'istanza di SQL Server in Azure e assicurati che tutte le tabelle CDC e CT siano state create.
2. [Databricks] Configura il connettore SQL Server in Lakeflow Connect
Nel passaggio successivo, verrà mostrata l'interfaccia utente di Databricks per configurare il connettore SQL Server. In alternativa, è possibile utilizzare Databricks Asset Bundles (DAB), un modo programmatico per gestire le pipeline di Lakeflow Connect come codice. Un esempio dello script DAB completo è nell'appendice seguente.
Una volta impostate tutte le autorizzazioni, come indicato nella sezione Prerequisiti di autorizzazione, sei pronto per ingerire i dati. Fai clic sul pulsante + Nuovo in alto a sinistra, quindi seleziona Aggiungi o carica dati.
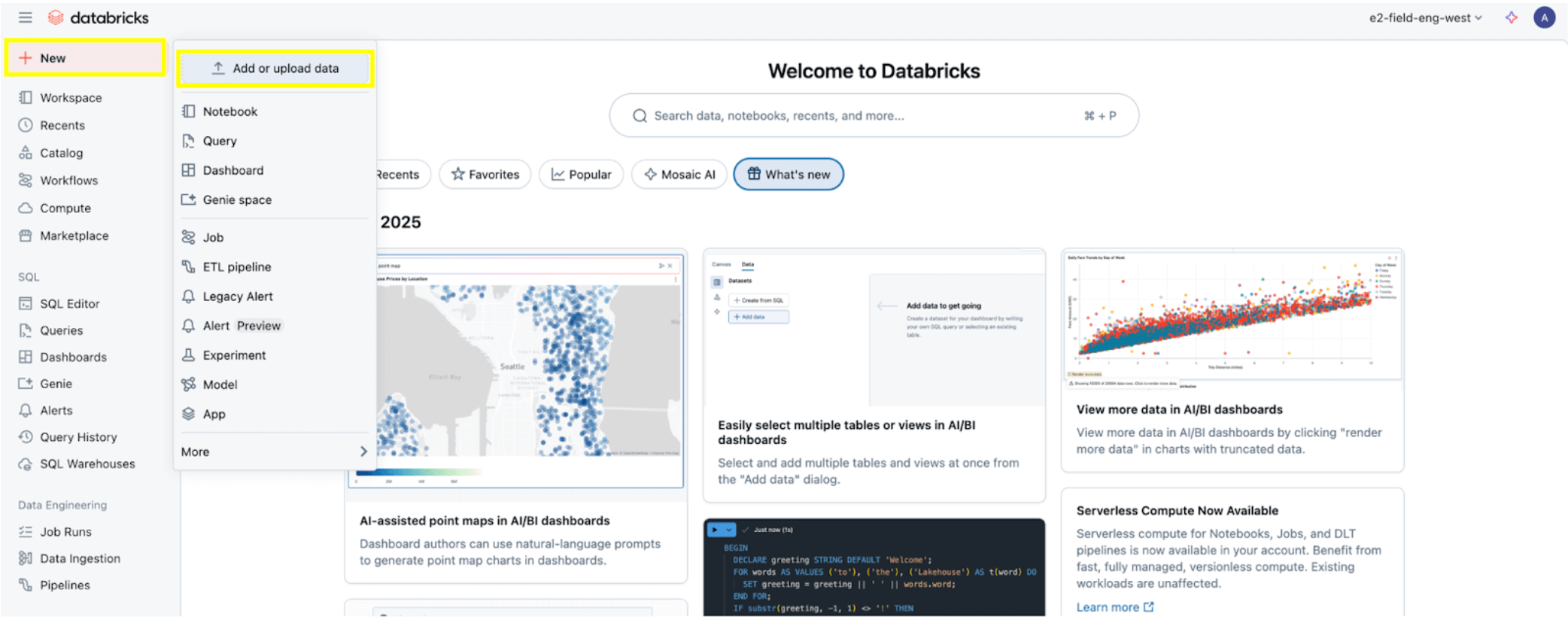
Quindi seleziona l'opzione SQL Server.
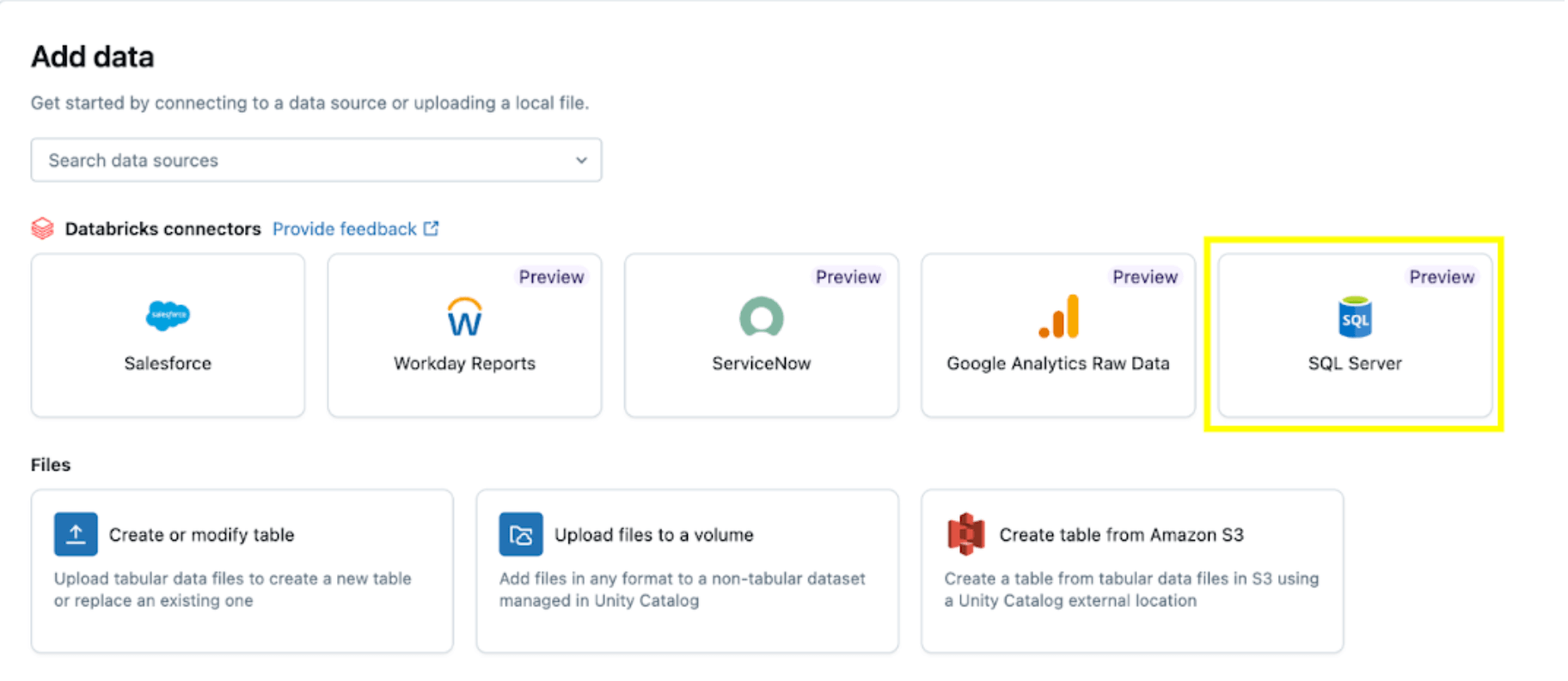
Il connettore SQL Server è configurato in diversi passaggi.
1. Configura il gateway di ingestion (AWS | Azure | GCP). In questo passaggio, fornisci un nome per la pipeline del gateway di ingestion e un catalogo e uno schema per la posizione del volume UC per estrarre snapshot e dati in continua modifica dal database di origine.
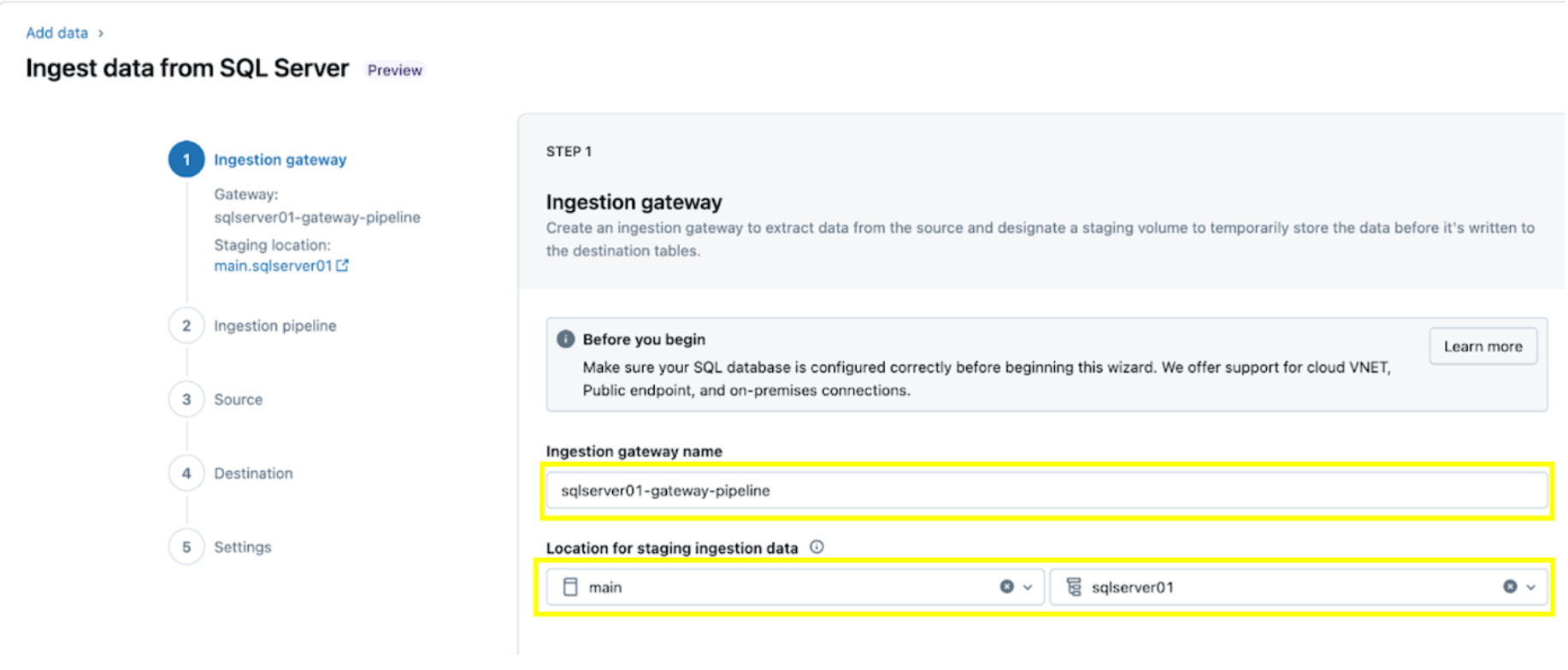
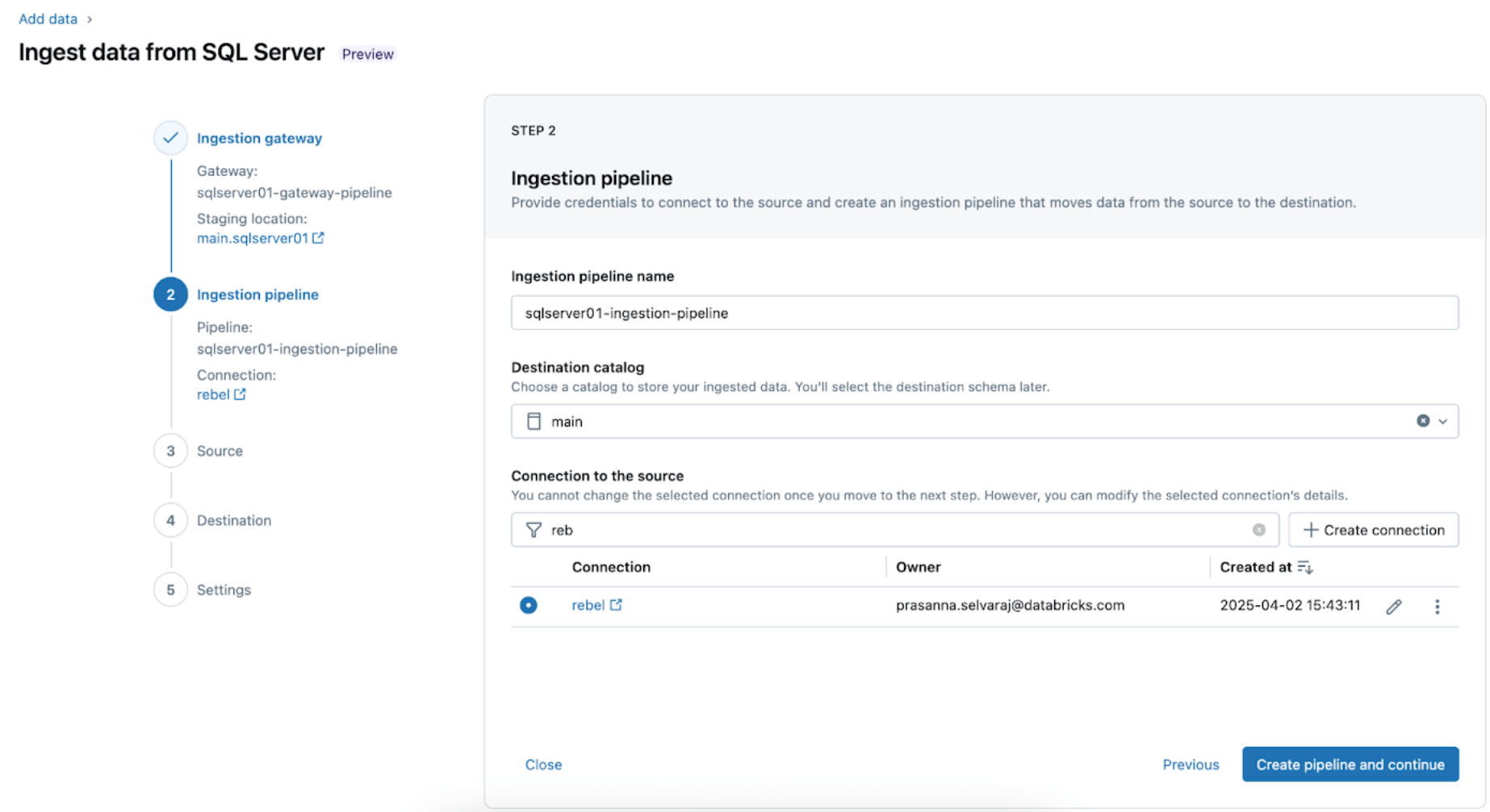
2. Configura la pipeline di ingestion. Questa replica la sorgente dati CDC/CT e gli eventi di evoluzione dello schema. È necessaria una connessione SQL Server, che viene creata tramite l'interfaccia utente seguendo questi passaggi o con il seguente codice SQL:
Per questo esempio, denomina la connessione SQL Server rebel come mostrato.
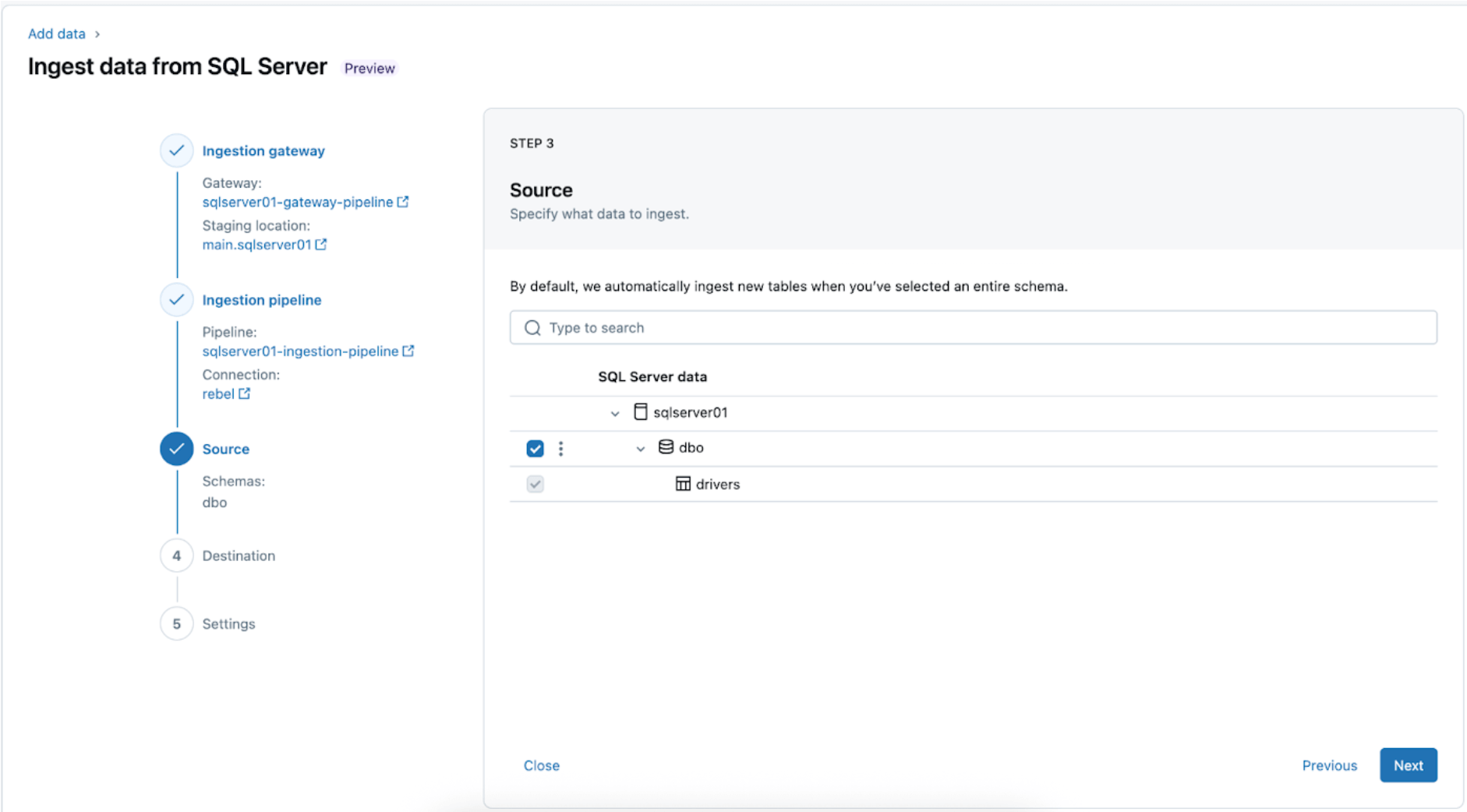
3. Selezione delle tabelle SQL Server per la replica. Seleziona l'intero schema da ingerire in Databricks invece di scegliere tabelle individuali da ingerire.
L'intero schema può essere ingerito in Databricks durante l'esplorazione iniziale o le migrazioni. Se lo schema è di grandi dimensioni o supera il numero consentito di tabelle per pipeline (vedere i limiti del connettore), Databricks consiglia di suddividere l'ingestione in più pipeline per mantenere prestazioni ottimali. Per flussi di lavoro specifici del caso d'uso, come un singolo modello ML, dashboard o report, è generalmente più efficiente ingerire tabelle individuali su misura per tale esigenza specifica, piuttosto che l'intero schema.
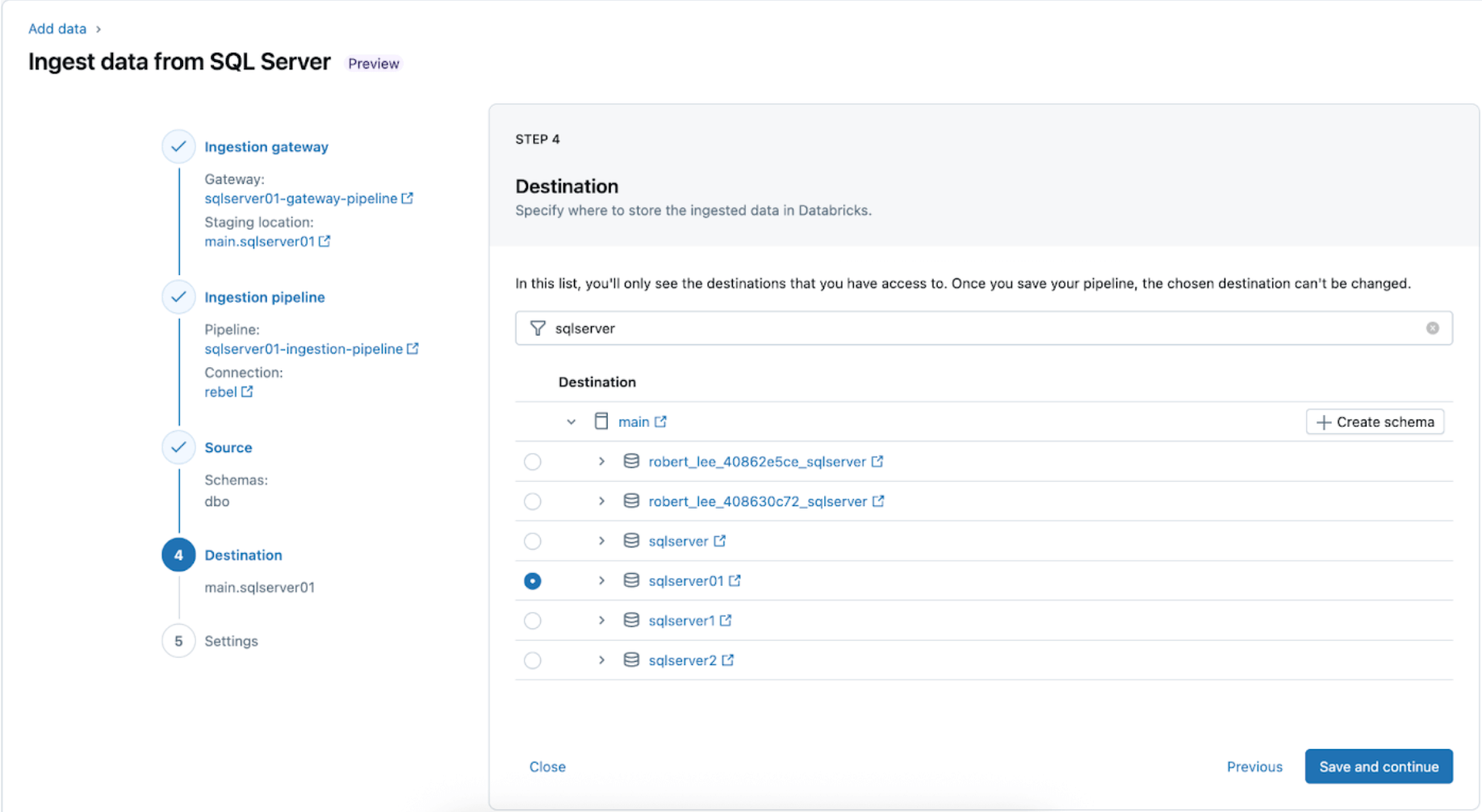
4. Configura la destinazione in cui le tabelle SQL Server verranno replicate all'interno di UC. Seleziona il catalogo main e lo schema sqlserver01 per far atterrare i dati in UC.
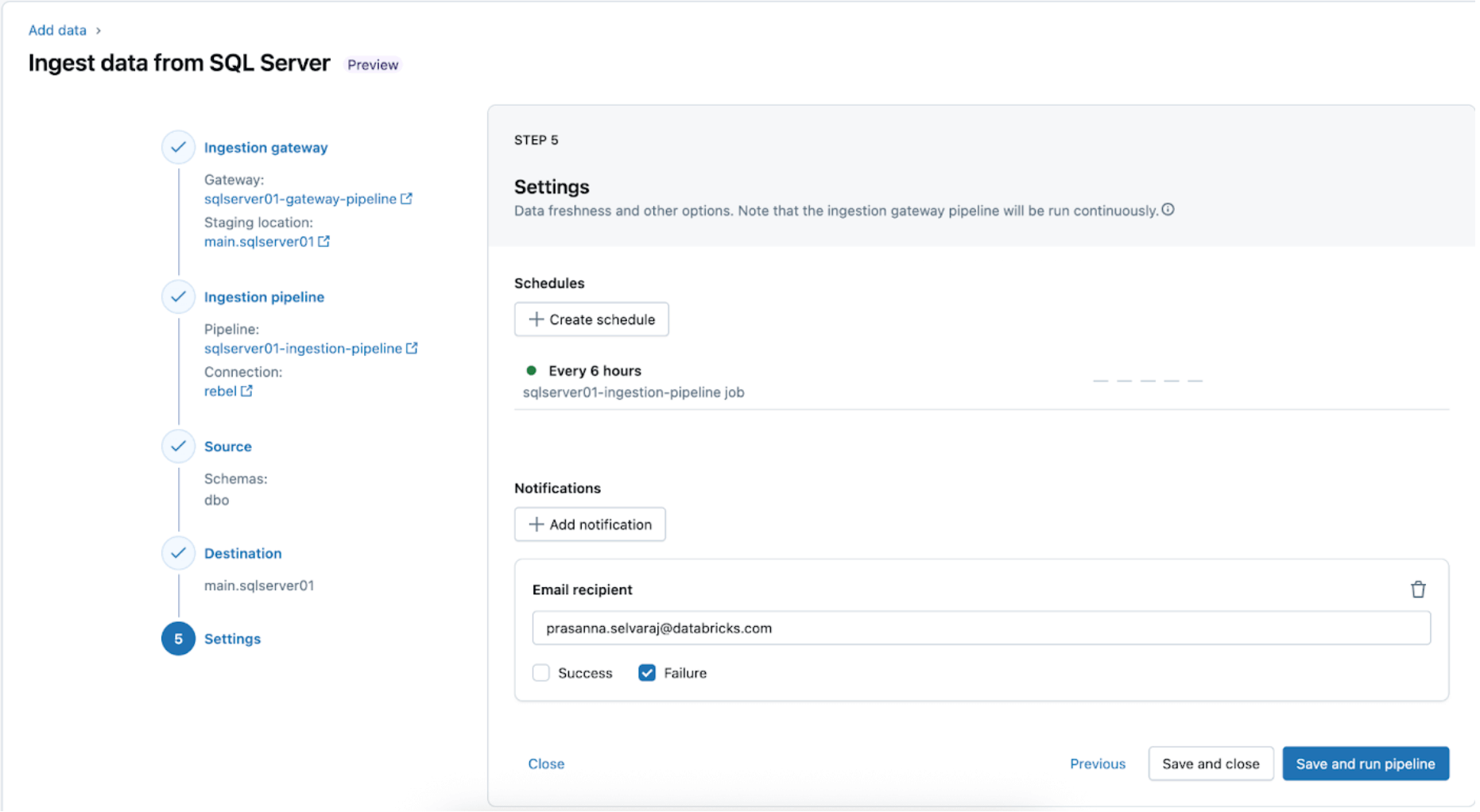
5. Configura pianificazioni e notifiche (AWS | Azure | GCP). Questo passaggio finale aiuterà a determinare la frequenza di esecuzione della pipeline e dove inviare i messaggi di successo o fallimento. Imposta la pipeline in modo che venga eseguita ogni 6 ore e notifichi all'utente solo i fallimenti della pipeline. Questo intervallo può essere configurato per soddisfare le esigenze del tuo carico di lavoro.
La pipeline di ingestione può essere attivata con una pianificazione personalizzata. Lakeflow Connect creerà automaticamente un job dedicato per ogni trigger di pipeline pianificato. La pipeline di ingestione è un'attività all'interno del job. Facoltativamente, è possibile aggiungere altre attività prima o dopo l'attività di ingestione per qualsiasi elaborazione downstream.
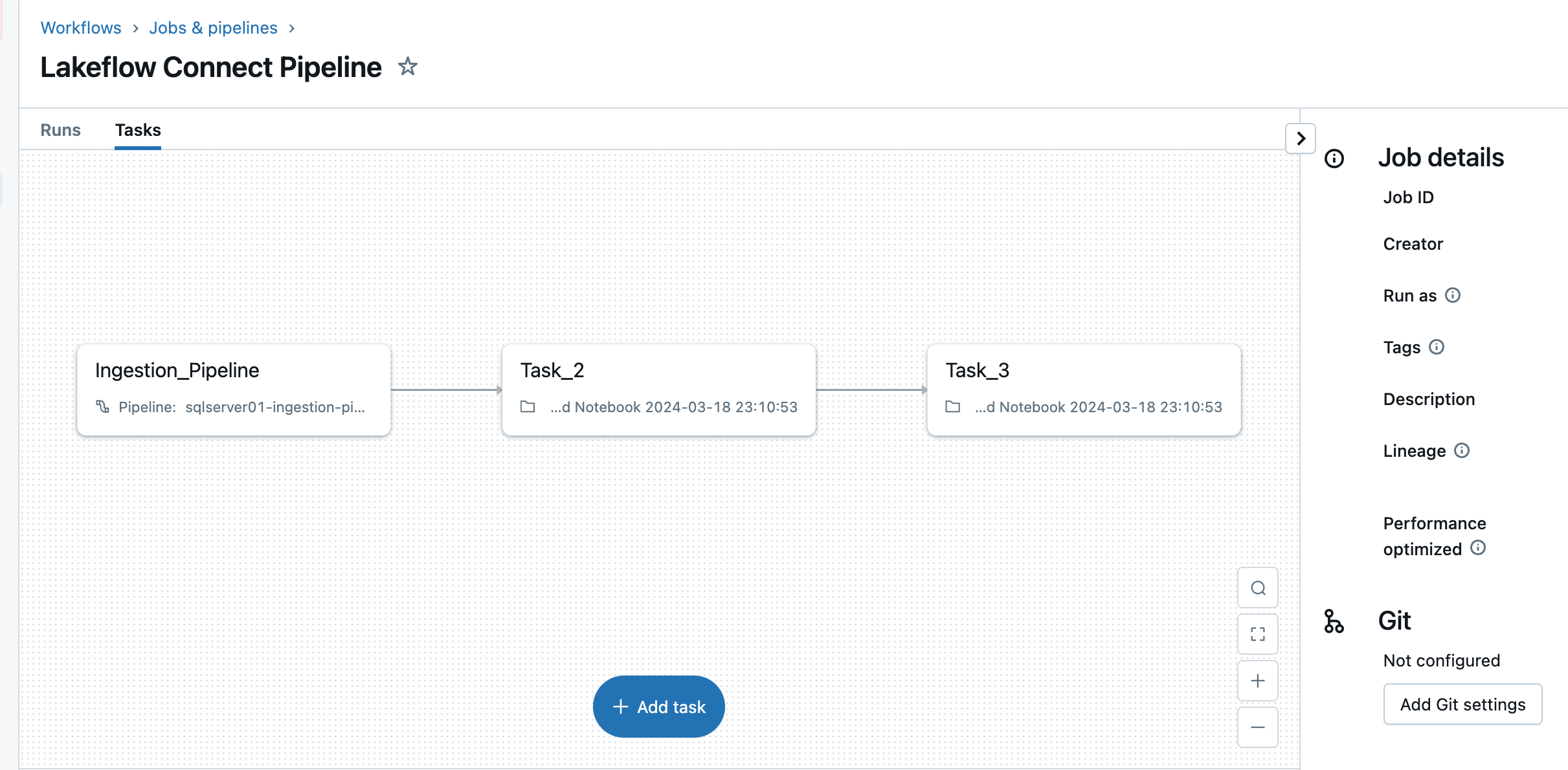
Dopo questo passaggio, la pipeline di ingestione viene salvata e attivata, avviando un caricamento completo dei dati da SQL Server a Databricks.
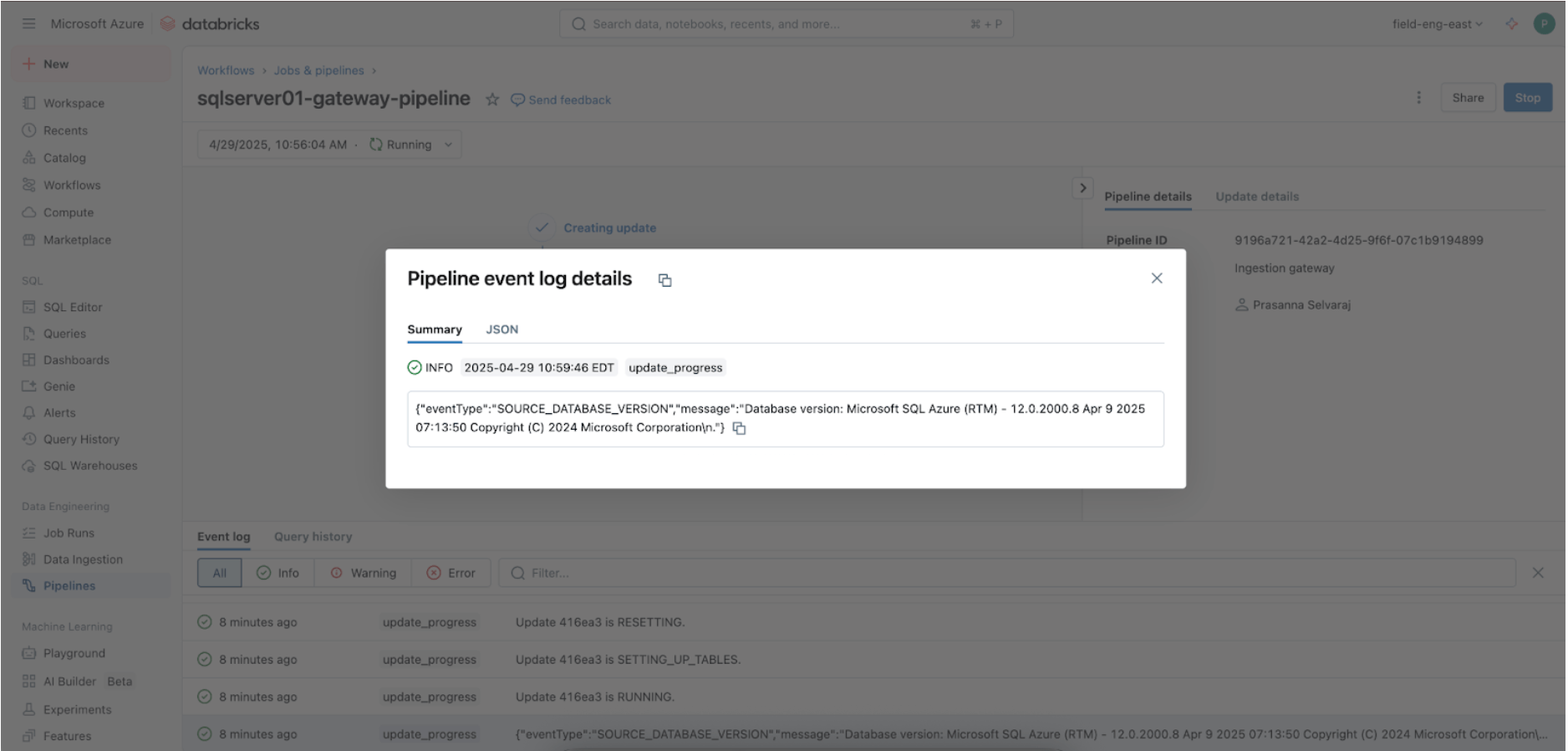
3. [Databricks] Validazione delle Esecuzioni Riuscite delle Pipeline Gateway e di Ingestione
Naviga nel menu Pipeline per verificare se la pipeline di ingestione del gateway è in esecuzione. Una volta completata, cerca 'update_progress' nell'interfaccia del log degli eventi della pipeline nel pannello inferiore per assicurarti che il gateway ingerisca correttamente i dati di origine.
Per controllare lo stato della sincronizzazione, naviga nel menu pipeline. Lo screenshot seguente mostra che la pipeline di ingestione ha eseguito tre operazioni di inserimento e aggiornamento (UPSERT).
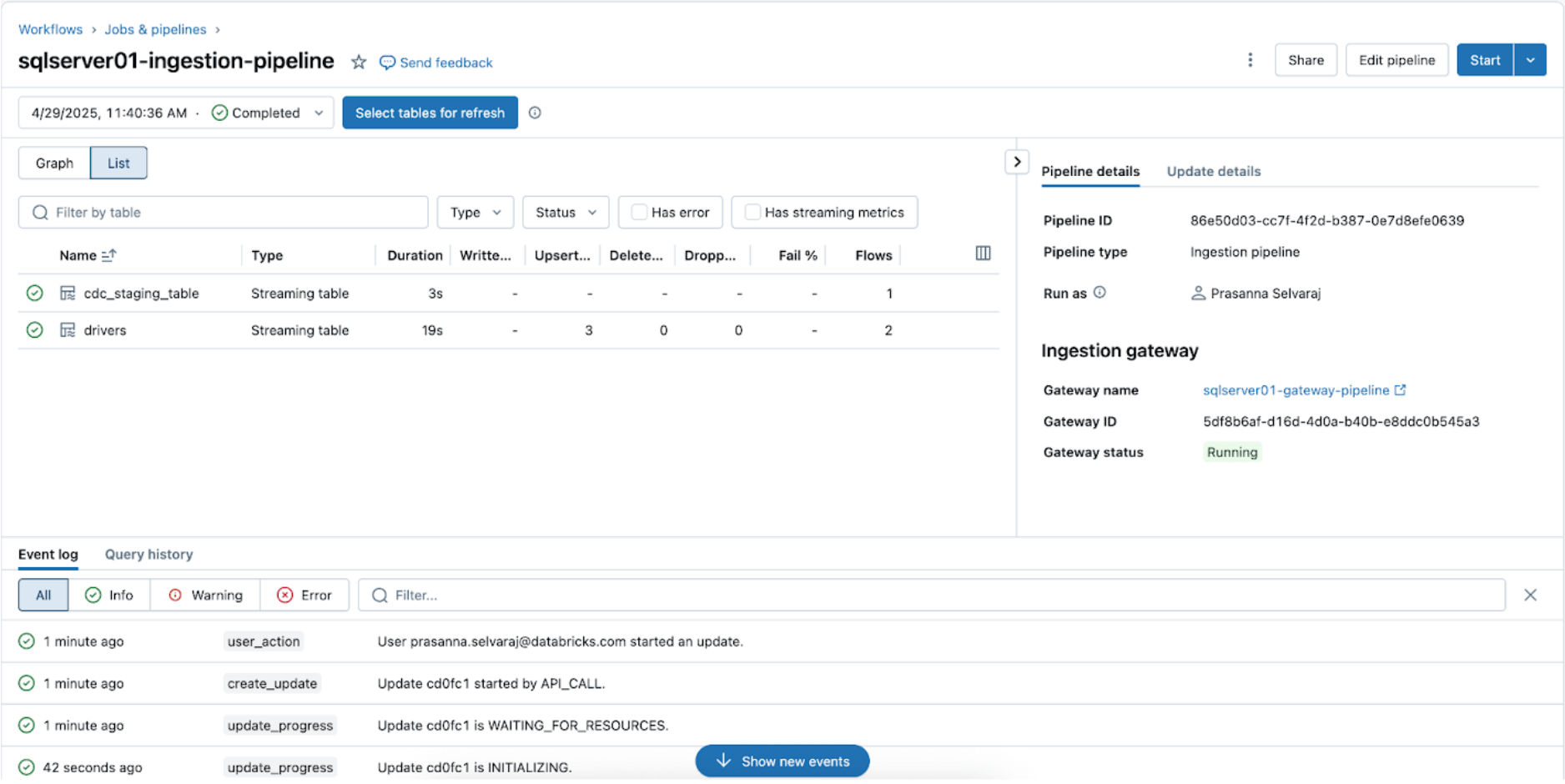
Naviga nel catalogo di destinazione, main, e nello schema, sqlserver01, per visualizzare la tabella replicata, come mostrato di seguito.

4. [Databricks] Test CDC ed Evoluzione dello Schema
Successivamente, verifica un evento CDC eseguendo operazioni di inserimento, aggiornamento ed eliminazione nella tabella di origine. Lo screenshot del SQL Server di Azure sottostante raffigura i tre eventi.
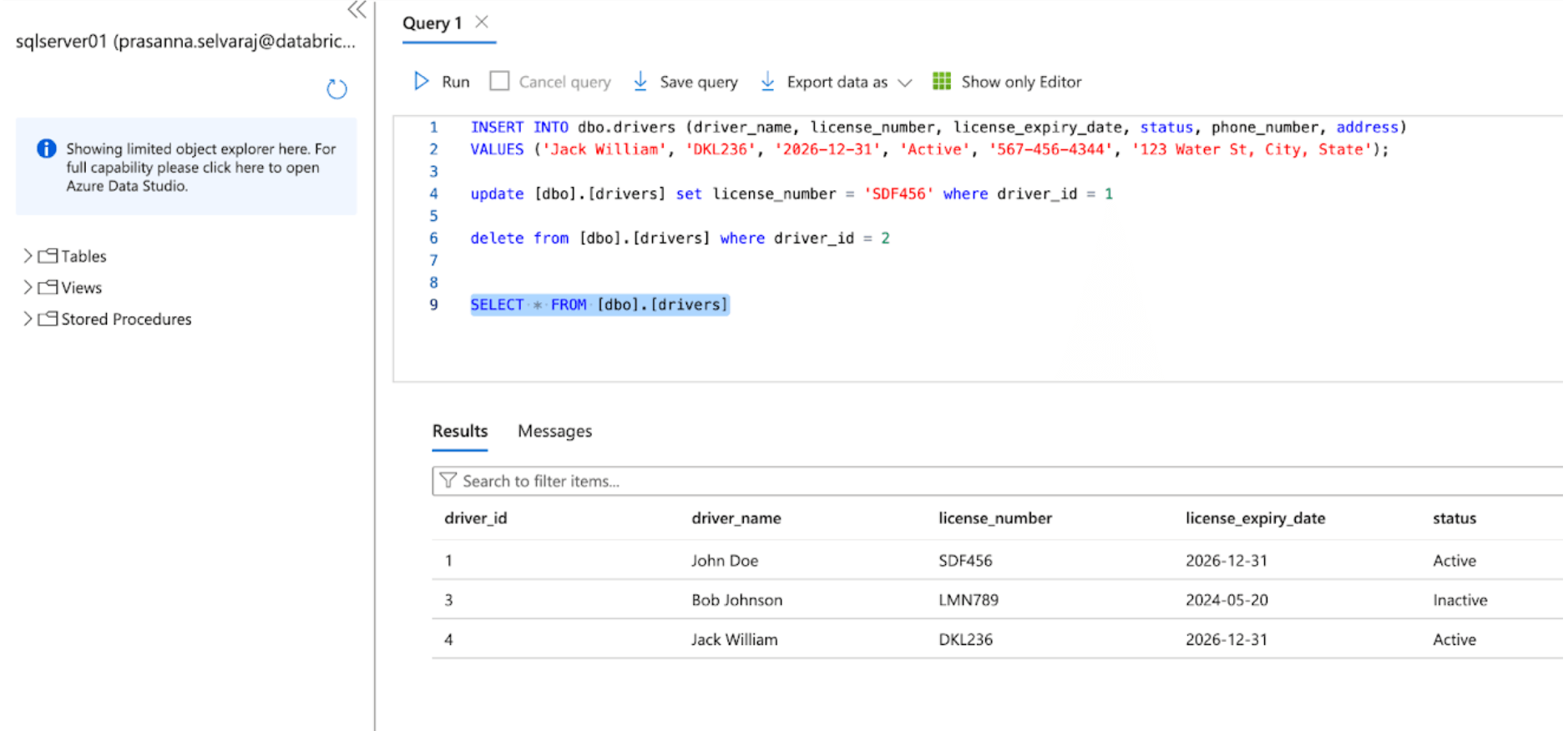
Una volta attivata la pipeline e completata, interroga la tabella delta sotto lo schema di destinazione e verifica le modifiche.
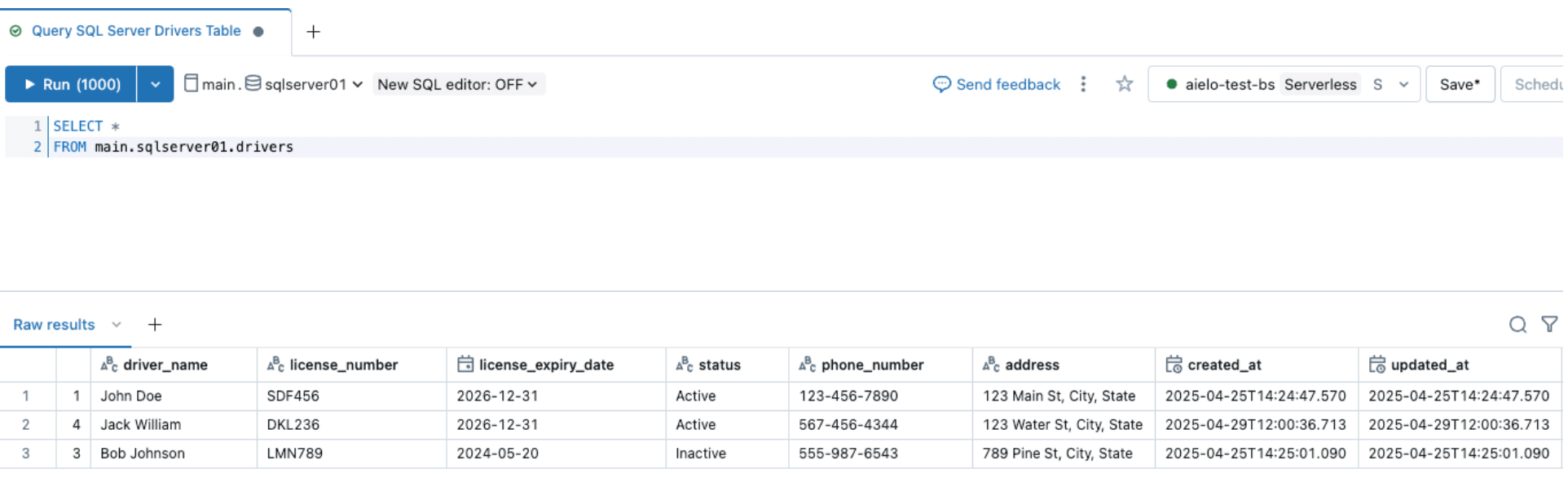
Allo stesso modo, eseguiamo un evento di evoluzione dello schema e aggiungiamo una colonna alla tabella di origine SQL Server, come mostrato di seguito

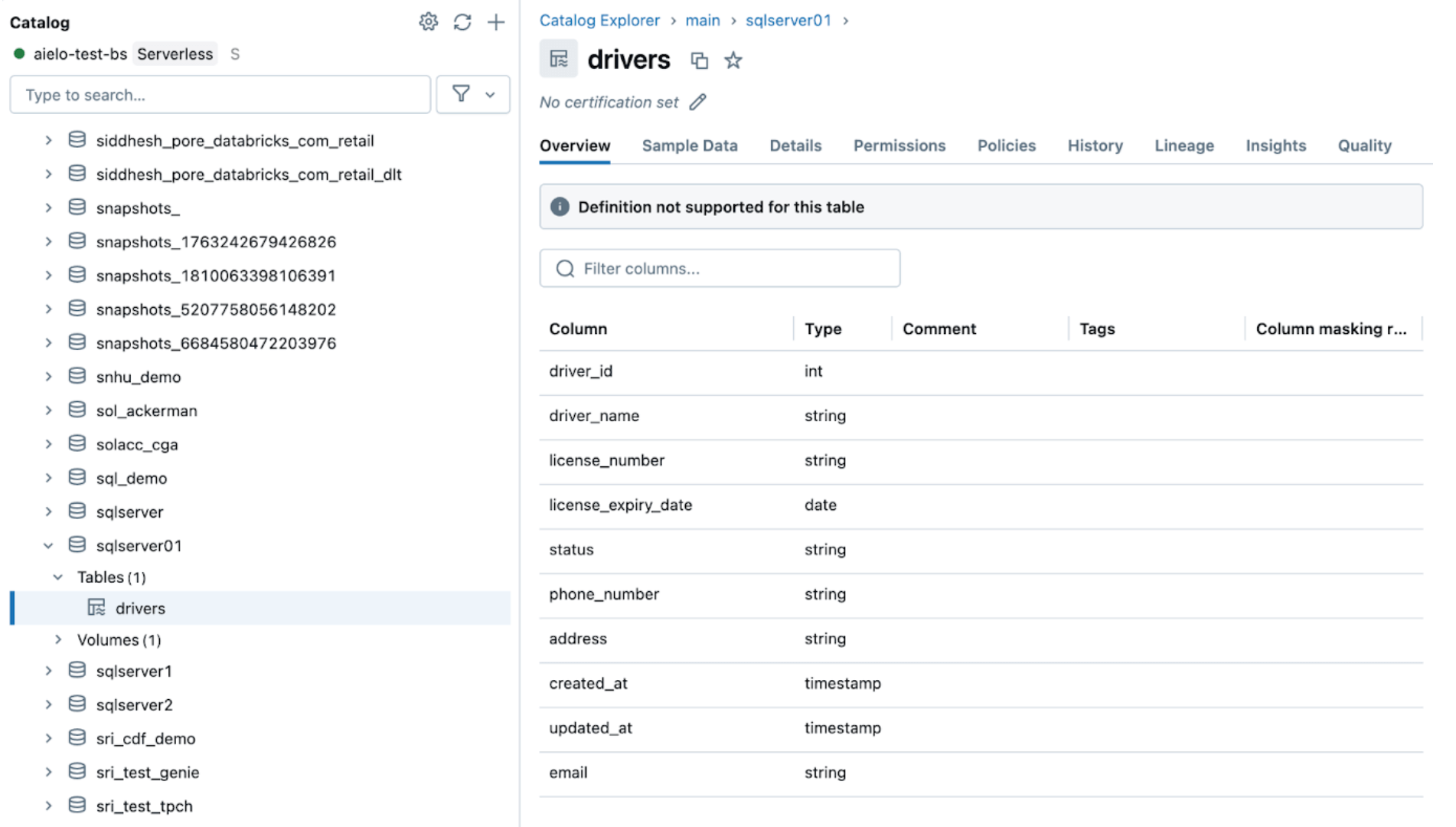
Dopo aver modificato le origini, attiva la pipeline di ingestione facendo clic sul pulsante di avvio nell'interfaccia utente di Databricks DLT. Una volta completata la pipeline, verifica le modifiche navigando nella tabella di destinazione, come mostrato di seguito. La nuova colonna email verrà aggiunta alla fine della tabella drivers.
5. [Databricks] Monitoraggio Continuo delle Pipeline
Una volta che le pipeline di ingestione e gateway sono in esecuzione con successo, è fondamentale monitorarne lo stato di salute e il comportamento. L'interfaccia utente della pipeline fornisce controlli sulla qualità dei dati, stato di avanzamento della pipeline e informazioni sulla data lineage. Per visualizzare le voci del log degli eventi nell'interfaccia utente della pipeline, individua il riquadro inferiore sotto il DAG della pipeline, come mostrato di seguito.

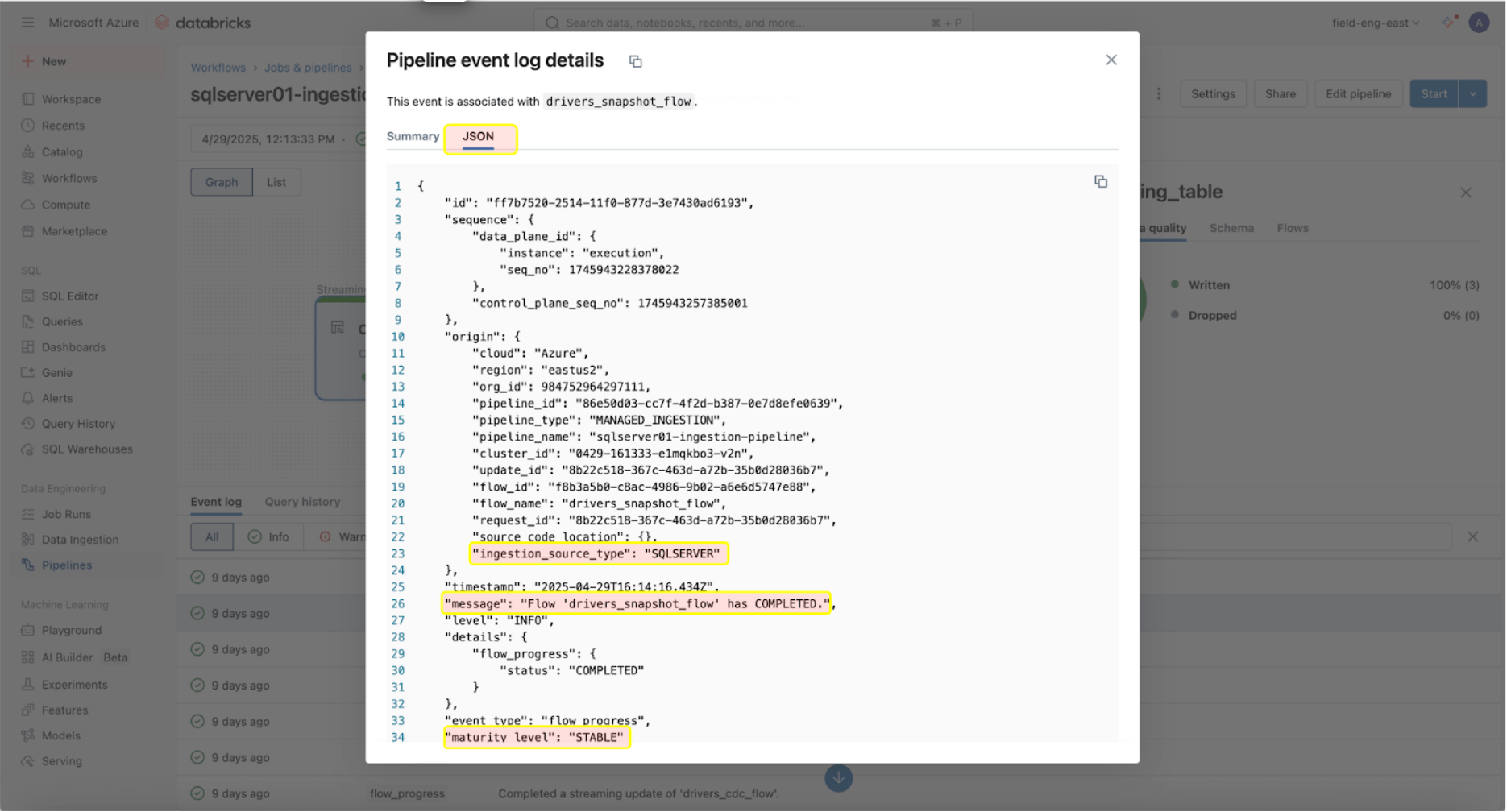
La voce del log degli eventi sopra mostra che il flusso ‘drives_snapshot_flow’ è stato ingerito da SQL Server ed è stato completato. Il livello di maturità STABLE indica che lo schema è stabile e non è cambiato. Ulteriori informazioni sullo schema del log degli eventi sono disponibili qui.
Esempio nel mondo reale
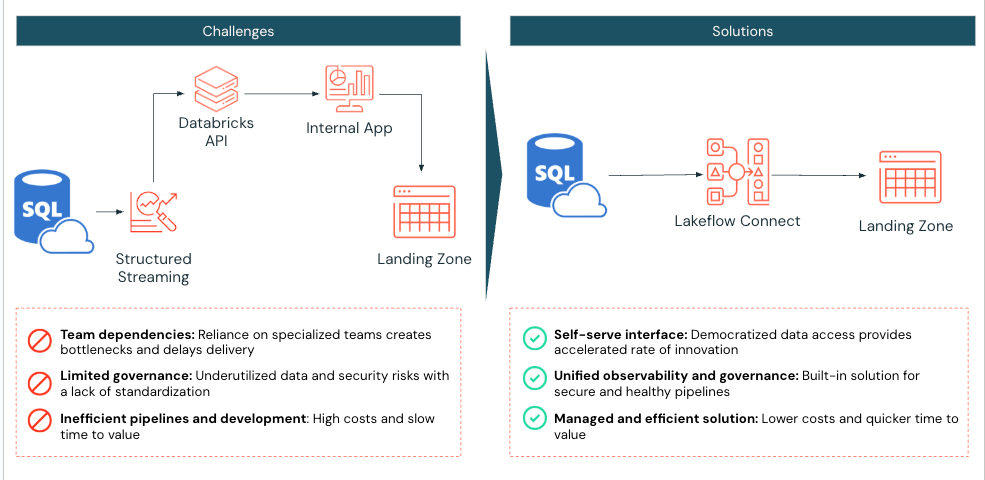
Un laboratorio diagnostico medico su larga scala che utilizzava Databricks ha affrontato sfide nell'ingestione efficiente dei dati da SQL Server nel proprio lakehouse. Prima di implementare Lakeflow Connect, il laboratorio utilizzava notebook Databricks Spark per estrarre due tabelle da Azure SQL Server in Databricks. La loro applicazione interagiva quindi con l'API Databricks per gestire l'esecuzione di compute e job.
Il laboratorio diagnostico medico ha implementato Lakeflow Connect per SQL Server, riconoscendo che questo processo poteva essere semplificato. Una volta abilitata, l'implementazione è stata completata in un solo giorno, consentendo al laboratorio diagnostico medico di sfruttare gli strumenti integrati di Databricks per l'osservabilità con aggiornamenti incrementali giornalieri dell'ingestione.
Considerazioni operative
Una volta che il connettore SQL Server ha stabilito con successo una connessione al tuo Azure SQL Database, il passo successivo è pianificare in modo efficiente le tue pipeline di dati per ottimizzare le prestazioni e l'utilizzo delle risorse. Inoltre, è essenziale seguire le best practice per la configurazione programmatica delle pipeline per garantire scalabilità e coerenza tra gli ambienti.
Orchestrazione della pipeline
Non c'è limite alla frequenza con cui la pipeline di ingestione può essere pianificata. Tuttavia, per ridurre al minimo i costi e garantire la coerenza nelle esecuzioni delle pipeline senza sovrapposizioni, Databricks consiglia un intervallo di almeno 5 minuti tra le esecuzioni di ingestione. Ciò consente l'introduzione di nuovi dati alla sorgente tenendo conto delle risorse computazionali e del tempo di avvio.
La pipeline di ingestione può essere configurata come un task all'interno di un job. Quando i carichi di lavoro downstream dipendono dall'arrivo di dati freschi, le dipendenze dei task possono essere impostate per garantire che l'esecuzione della pipeline di ingestione venga completata prima dell'esecuzione dei task downstream.
Inoltre, se la pipeline è ancora in esecuzione quando viene pianificato il prossimo aggiornamento, la pipeline di ingestione si comporterà in modo simile a un job e salterà l'aggiornamento fino al successivo, supponendo che l'aggiornamento in corso venga completato in tempo.
Osservabilità e monitoraggio dei costi
Lakeflow Connect opera su un modello di prezzi basato sul compute, garantendo efficienza e scalabilità per varie esigenze di integrazione dati. La pipeline di ingestione opera su compute serverless, che consente flessibilità nello scaling in base alla domanda e semplifica la gestione eliminando la necessità per gli utenti di configurare e gestire l'infrastruttura sottostante.
Tuttavia, è importante notare che mentre la pipeline di ingestione può essere eseguita su compute serverless, il gateway di ingestione per i connettori di database opera attualmente su compute classico per semplificare le connessioni alla sorgente del database. Di conseguenza, gli utenti potrebbero vedere una combinazione di addebiti DLT DBU classici e serverless riflessi nella loro fatturazione.
Il modo più semplice per tracciare e monitorare l'utilizzo di Lakeflow Connect è tramite le tabelle di sistema. Di seguito è riportato un esempio di query per visualizzare l'utilizzo di una particolare pipeline Lakeflow Connect:

La documentazione ufficiale sui prezzi di Lakeflow Connect (AWS | Azure | GCP) fornisce informazioni dettagliate sulle tariffe. Potrebbero essere applicati costi aggiuntivi, come le commissioni di uscita serverless (prezzi). I costi di uscita dal provider cloud per il compute classico sono disponibili qui (AWS | Azure | GCP).
Best Practice e Punti Chiave
A maggio 2025, di seguito sono riportate alcune delle best practice e delle considerazioni da seguire durante l'implementazione di questo connettore SQL Server:
- Configura ogni Ingestion Gateway per autenticarsi con un utente o un'entità con accesso solo al database sorgente replicato.
- Assicurati che all'utente vengano concesse le autorizzazioni necessarie per creare connessioni in UC e ingerire i dati.
- Utilizza i DAB per configurare in modo affidabile le pipeline di ingestione di Lakeflow Connect, garantendo ripetibilità e coerenza nella gestione dell'infrastruttura.
- Per le tabelle sorgente con chiavi primarie, abilita il Change Tracking per ottenere un overhead inferiore e prestazioni migliorate.
- Per le tabelle sorgente senza chiave primaria, abilita il CDC grazie alla sua capacità di catturare le modifiche a livello di colonna, anche senza identificatori di riga univoci.
Lakeflow Connect per SQL Server fornisce un'integrazione completamente gestita e integrata sia per database on-premises che cloud per un'ingestione incrementale ed efficiente in Databricks.
Passi Successivi e Risorse Aggiuntive
Prova oggi stesso il connettore SQL Server per risolvere le tue sfide di ingestione dati. Segui i passaggi delineati in questo blog o consulta la documentazione. Scopri di più su Lakeflow Connect sulla pagina del prodotto, visualizza un tour del prodotto o visualizza una demo del connettore Salesforce per aiutare a prevedere il churn dei clienti.
I Delivery Solutions Architect (DSA) di Databricks accelerano le iniziative Data e AI nelle organizzazioni. Forniscono leadership architetturale, ottimizzano le piattaforme per costi e prestazioni, migliorano l'esperienza degli sviluppatori e guidano l'esecuzione efficace dei progetti. I DSA colmano il divario tra l'implementazione iniziale e le soluzioni di livello di produzione, lavorando a stretto contatto con vari team, tra cui data engineering, technical lead, dirigenti e altri stakeholder per garantire soluzioni su misura e un valore più rapido. Per beneficiare di un piano di esecuzione personalizzato, guida strategica e supporto durante il tuo percorso di dati e AI da parte di un DSA, contatta il tuo Databricks Account Team.
Appendice
In questo passaggio facoltativo, per gestire le pipeline Lakeflow Connect come codice utilizzando DAB, è sufficiente aggiungere due file al bundle esistente:
- Un file di workflow che controlla la frequenza di ingestione dei dati (resources/sqlserver.yml).
- Un file di definizione della pipeline (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml:
resources/sqlserver_job.yml:
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.