Ingegneria delle prestazioni per l'inferenza LLM: best practice
di Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo e Daya Khudia
In questo post del blog, il team di ingegneri di MosaicML condivide le best practice su come sfruttare i popolari modelli linguistici di grandi dimensioni (LLM) open source per l'uso in produzione. Forniamo anche linee guida per la distribuzione di servizi di inferenza basati su questi modelli per aiutare gli utenti nella selezione dei modelli e dell'hardware di distribuzione. Abbiamo lavorato con diversi backend basati su PyTorch in produzione; queste linee guida derivano dalla nostra esperienza con FasterTransformers, vLLM, il prossimo TensorRT-LLM di NVIDIA e altri.
Comprendere la generazione di testo degli LLM
I modelli linguistici di grandi dimensioni (LLM) generano testo in un processo in due fasi: "prefill", in cui i token nel prompt di input vengono elaborati in parallelo, e "decoding", in cui il testo viene generato un 'token' alla volta in modo autoregressivo. Ogni token generato viene aggiunto all'input e reimmesso nel modello per generare il token successivo. La generazione si interrompe quando l'LLM restituisce un token speciale di arresto o quando viene soddisfatta una condizione definita dall'utente (ad esempio, è stato generato un numero massimo di token). Se desideri maggiori informazioni su come gli LLM utilizzano i blocchi decoder, consulta questo post del blog.
I token possono essere parole o sotto-parole; le regole esatte per la suddivisione del testo in token variano da modello a modello. Ad esempio, puoi confrontare come i modelli Llama tokenizzano il testo rispetto a come i modelli OpenAI tokenizzano il testo. Sebbene i provider di inferenza LLM parlino spesso di prestazioni in metriche basate sui token (ad esempio, token/secondo), questi numeri non sono sempre comparabili tra i diversi tipi di modelli date queste variazioni. Per un esempio concreto, il team di Anyscale ha scoperto che la tokenizzazione di Llama 2 è più lunga del 19% rispetto alla tokenizzazione di ChatGPT (ma ha comunque un costo complessivo molto inferiore). E i ricercatori di HuggingFace hanno anche scoperto che Llama 2 ha richiesto circa il 20% di token in più per l'addestramento sulla stessa quantità di testo di GPT-4.
Metriche importanti per il serving degli LLM
Quindi, come dovremmo pensare esattamente alla velocità di inferenza?
Il nostro team utilizza quattro metriche chiave per il serving degli LLM:
- Time To First Token (TTFT): Quanto velocemente gli utenti iniziano a vedere l'output del modello dopo aver inserito la loro query. Tempi di attesa brevi per una risposta sono essenziali nelle interazioni in tempo reale, ma meno importanti nei carichi di lavoro offline. Questa metrica è guidata dal tempo necessario per elaborare il prompt e quindi generare il primo token di output.
- Time Per Output Token (TPOT): Tempo per generare un token di output per ciascun utente che interroga il nostro sistema. Questa metrica corrisponde a come ciascun utente percepirà la "velocità" del modello. Ad esempio, un TPOT di 100 millisecondi/token corrisponderebbe a 10 token al secondo per utente, ovvero circa 450 parole al minuto, che è più veloce di quanto una persona tipica possa leggere.
- Latenza: Il tempo totale necessario al modello per generare la risposta completa per un utente. La latenza complessiva della risposta può essere calcolata utilizzando le due metriche precedenti: latenza = (TTFT) + (TPOT) * (il numero di token da generare).
- Throughput: Il numero di token di output al secondo che un server di inferenza può generare per tutti gli utenti e le richieste.
Il nostro obiettivo? Il tempo più veloce per il primo token, il throughput più elevato e il tempo più rapido per token di output. In altre parole, vogliamo che i nostri modelli generino testo il più velocemente possibile per il maggior numero di utenti che possiamo supportare.
In particolare, esiste un compromesso tra throughput e tempo per token di output: se elaboriamo 16 query utente contemporaneamente, avremo un throughput maggiore rispetto all'esecuzione sequenziale delle query, ma impiegheremo più tempo per generare token di output per ciascun utente.
Se hai obiettivi di latenza di inferenza complessiva, ecco alcune euristiche utili per valutare i modelli:
- La lunghezza dell'output domina la latenza complessiva della risposta: Per la latenza media, di solito puoi prendere la lunghezza prevista/massima dei token di output e moltiplicarla per un tempo medio complessivo per token di output per il modello.
- La lunghezza dell'input non è significativa per le prestazioni ma è importante per i requisiti hardware: L'aggiunta di 512 token di input aumenta la latenza meno della produzione di 8 token di output aggiuntivi nei modelli MPT. Tuttavia, la necessità di supportare input lunghi può rendere i modelli più difficili da servire. Ad esempio, consigliamo di utilizzare l'A100-80GB (o più recente) per servire MPT-7B con la sua lunghezza di contesto massima di 2048 token.
- La latenza complessiva scala in modo sub-lineare con la dimensione del modello: Sulla stessa hardware, i modelli più grandi sono più lenti, ma il rapporto di velocità non corrisponderà necessariamente al rapporto del numero di parametri. La latenza di MPT-30B è circa 2,5 volte quella di MPT-7B. La latenza di Llama2-70B è circa 2 volte quella di Llama2-13B.
Ci viene spesso chiesto dai potenziali clienti di fornire una latenza di inferenza media. Consigliamo che prima di ancorarti a specifici obiettivi di latenza ("abbiamo bisogno di meno di 20 ms per token"), dovresti dedicare del tempo alla caratterizzazione delle lunghezze di input previste e di output desiderate.
Sfide nell'inferenza LLM
L'ottimizzazione dell'inferenza LLM beneficia di tecniche generali come:
- Operator Fusion: La combinazione di diversi operatori adiacenti spesso si traduce in una migliore latenza.
- Quantizzazione: Attivazioni e pesi vengono compressi per utilizzare un numero inferiore di bit.
- Compressione: Sparsità o Distillazione.
- Parallelizzazione: Parallelismo tensoriale su più dispositivi o parallelismo pipeline per modelli più grandi.
Oltre a questi metodi, ci sono molte ottimizzazioni importanti specifiche per i Transformer. Un esempio lampante è la cache KV (key-value). Il meccanismo di Attention nei modelli basati su Transformer solo decoder è computazionalmente inefficiente. Ogni token presta attenzione a tutti i token visti in precedenza e quindi ricalcola molti degli stessi valori man mano che ogni nuovo token viene generato. Ad esempio, durante la generazione del N-esimo token, l'(N-1)-esimo token presta attenzione agli N-2, N-3... token 1. Allo stesso modo, durante la generazione dell'(N+1)-esimo token, l'attenzione per l'N-esimo token deve nuovamente esaminare gli N-1, N-2, N-3... token 1. La cache KV, ovvero il salvataggio delle chiavi/valori intermedi per i layer di attenzione, viene utilizzata per preservare questi risultati per un riutilizzo successivo, evitando calcoli ripetuti.
La larghezza di banda della memoria è fondamentale
Le computazioni negli LLM sono dominate principalmente da operazioni di moltiplicazione matrice-matrice; queste operazioni con dimensioni ridotte sono tipicamente limitate dalla larghezza di banda della memoria sulla maggior parte dell'hardware. Durante la generazione di token in modo autoregressivo, una delle dimensioni della matrice di attivazione (definita dalla dimensione del batch e dal numero di token nella sequenza) è piccola a piccole dimensioni del batch. Pertanto, la velocità dipende da quanto rapidamente possiamo caricare i parametri del modello dalla memoria GPU alle cache/registri locali, piuttosto che da quanto rapidamente possiamo calcolare sui dati caricati. La larghezza di banda della memoria disponibile e raggiunta nell'hardware di inferenza è un predittore migliore della velocità di generazione dei token rispetto alle loro prestazioni di calcolo di picco.
L'utilizzo dell'hardware di inferenza è molto importante in termini di costi di serving. Le GPU sono costose e dobbiamo farle svolgere il maggior lavoro possibile. I servizi di inferenza condivisi promettono di mantenere bassi i costi combinando i carichi di lavoro di molti utenti, colmando le lacune individuali e raggruppando le richieste sovrapposte. Per modelli di grandi dimensioni come Llama2-70B, otteniamo buoni costi/prestazioni solo a grandi dimensioni del batch. Avere un sistema di serving di inferenza in grado di operare a grandi dimensioni del batch è fondamentale per l'efficienza dei costi. Tuttavia, un batch di grandi dimensioni significa una cache KV più grande, e ciò a sua volta aumenta il numero di GPU richieste per servire il modello. C'è un tira e molla qui e gli operatori di servizi condivisi devono fare alcuni compromessi sui costi e implementare ottimizzazioni di sistema.
Model Bandwidth Utilization (MBU)
Quanto è ottimizzato un server di inferenza LLM?
Come spiegato brevemente in precedenza, l'inferenza per gli LLM a piccole dimensioni del batch, specialmente al momento del decoding, è limitata dalla velocità con cui possiamo caricare i parametri del modello dalla memoria del dispositivo alle unità di calcolo. La larghezza di banda della memoria detta la velocità con cui avviene il movimento dei dati. Per misurare l'utilizzo dell'hardware sottostante, introduciamo una nuova metrica chiamata Model Bandwidth Utilization (MBU). L'MBU è definita come (larghezza di banda della memoria raggiunta) / (larghezza di banda della memoria di picco) dove la larghezza di banda della memoria raggiunta è ((dimensione totale dei parametri del modello + dimensione della cache KV) / TPOT).
Ad esempio, se un modello da 7 miliardi di parametri in esecuzione con precisione a 16 bit ha un TPOT pari a 14 ms, significa che sta spostando 14 GB di parametri in 14 ms, traducendosi in un utilizzo della larghezza di banda di 1 TB/sec. Se la larghezza di banda di picco della macchina è 2 TB/sec, stiamo operando con un MBU del 50%. Per semplicità, questo esempio ignora la dimensione della cache KV, che è piccola per dimensioni di batch ridotte e lunghezze di sequenza inferiori. Valori MBU vicini al 100% implicano che il sistema di inferenza sta utilizzando efficacemente la larghezza di banda di memoria disponibile. L'MBU è anche utile per confrontare diversi sistemi di inferenza (hardware + software) in modo normalizzato. L'MBU è complementare alla metrica Model Flops Utilization (MFU; introdotta nel paper PaLM PaLM), che è importante in scenari limitati dal calcolo.
La Figura 1 mostra una rappresentazione grafica dell'MBU in un grafico simile a un modello roofline. La linea inclinata continua della regione ombreggiata in arancione mostra il throughput massimo possibile se la larghezza di banda della memoria è completamente satura al 100%. Tuttavia, in realtà, per batch size ridotti (punto bianco), le prestazioni osservate sono inferiori al massimo – quanto inferiori è una misura dell'MBU. Per batch size elevati (regione gialla), il sistema è limitato dal calcolo e il throughput raggiunto come frazione del throughput massimo possibile viene misurato come Model Flops Utilization (MFU).
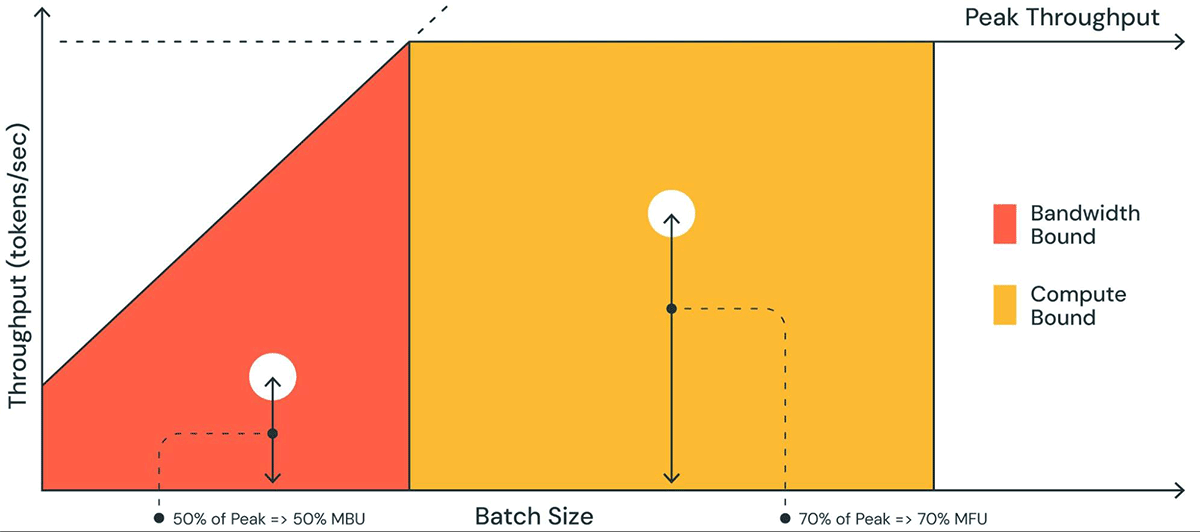
MBU e MFU determinano quanto spazio aggiuntivo è disponibile per aumentare la velocità di inferenza su una data configurazione hardware. La Figura 2 mostra l'MBU misurato per diversi gradi di parallelismo tensoriale con il nostro server di inferenza basato su TensorRT-LLM. L'utilizzo massimo della larghezza di banda della memoria si ottiene quando si trasferiscono blocchi di memoria grandi e contigui. Quando modelli più piccoli come MPT-7B vengono distribuiti su più GPU, osserviamo un MBU inferiore poiché spostiamo blocchi di memoria più piccoli su ciascuna GPU.
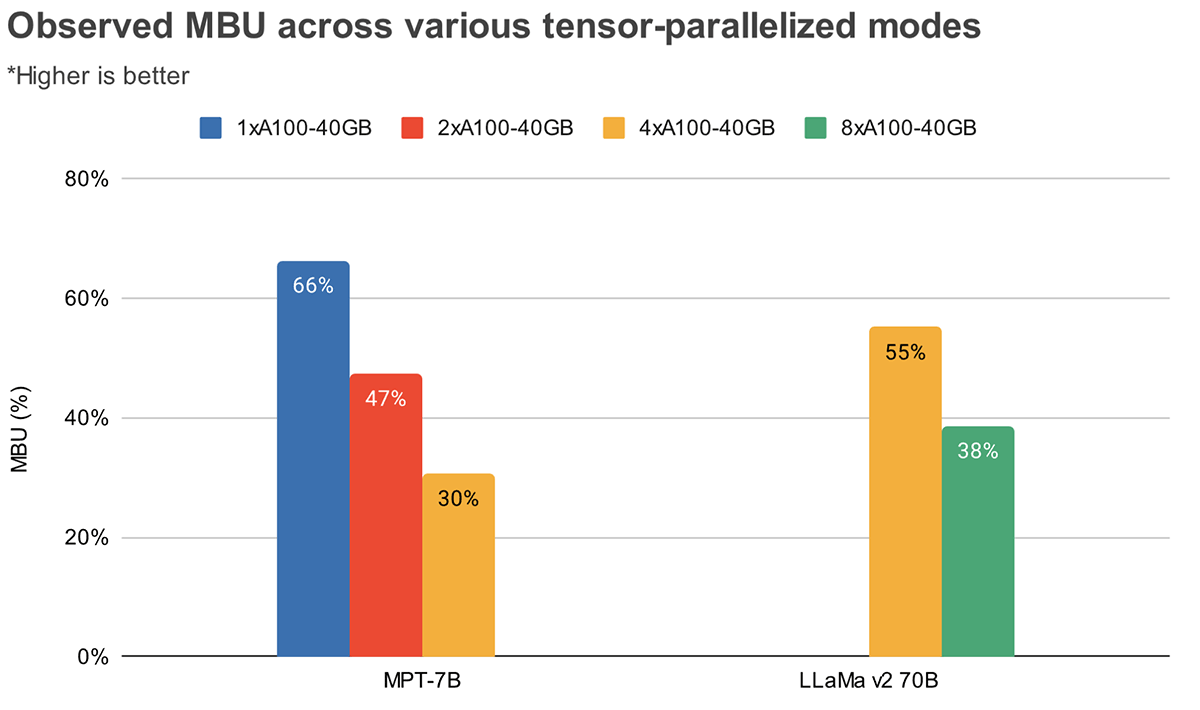
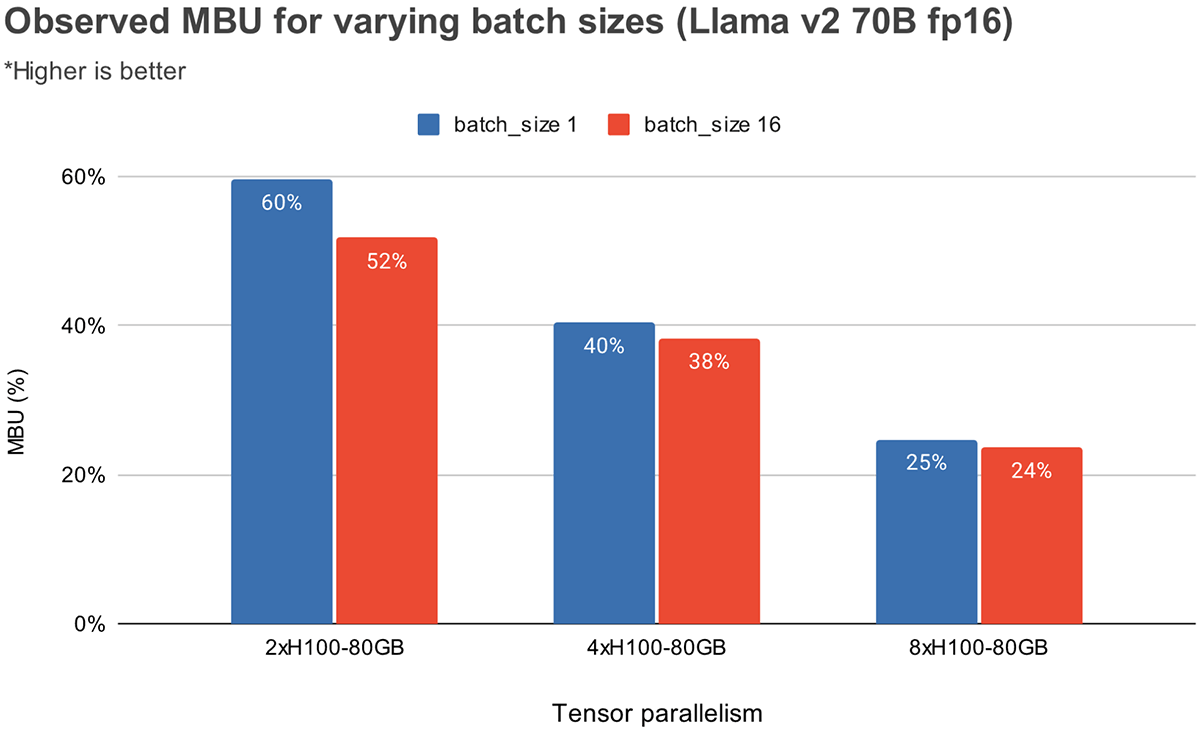
La Figura 3 mostra l'MBU osservato empiricamente per diversi gradi di parallelismo tensoriale e batch size sulle GPU NVIDIA H100. L'MBU diminuisce all'aumentare del batch size. Tuttavia, quando si scalano le GPU, la diminuzione relativa dell'MBU è meno significativa. Vale anche la pena notare che la scelta di hardware con maggiore larghezza di banda di memoria può migliorare le prestazioni con meno GPU. Con un batch size di 1, possiamo ottenere un MBU più elevato del 60% su 2xH100-80GB rispetto al 55% su 4xA100-40GB GPU (Figura 2).
Risultati del Benchmarking
Latenza
Abbiamo misurato il tempo per il primo token (TTFT) e il tempo per token di output (TPOT) attraverso diversi gradi di parallelismo tensoriale per i modelli MPT-7B e Llama2-70B. Man mano che i prompt di input si allungano, il tempo per generare il primo token inizia a consumare una parte sostanziale della latenza totale. Il parallelismo tensoriale su più GPU aiuta a ridurre questa latenza.
A differenza dell'addestramento del modello, scalare a più GPU offre rendimenti decrescenti significativi per la latenza di inferenza. Ad esempio, per Llama2-70B, passare da 4x a 8x GPU riduce la latenza solo di 0,7x con batch size ridotti. Una ragione di ciò è che un parallelismo maggiore ha un MBU inferiore (come discusso in precedenza). Un'altra ragione è che il parallelismo tensoriale introduce un overhead di comunicazione tra i nodi GPU.
| Tempo per il primo token (ms) | ||||
|---|---|---|---|---|
| Modello | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0.73x) | 26 (0.56x) | - |
| Llama2-70B | Non entra | 154 (1x) | 114 (0.74x) | |
Tabella 1: Tempo per il primo token date richieste di input di lunghezza 512 token con batch size di 1. Modelli più grandi come Llama2 70B necessitano di almeno 4x A100-40B GPU per entrare in memoria
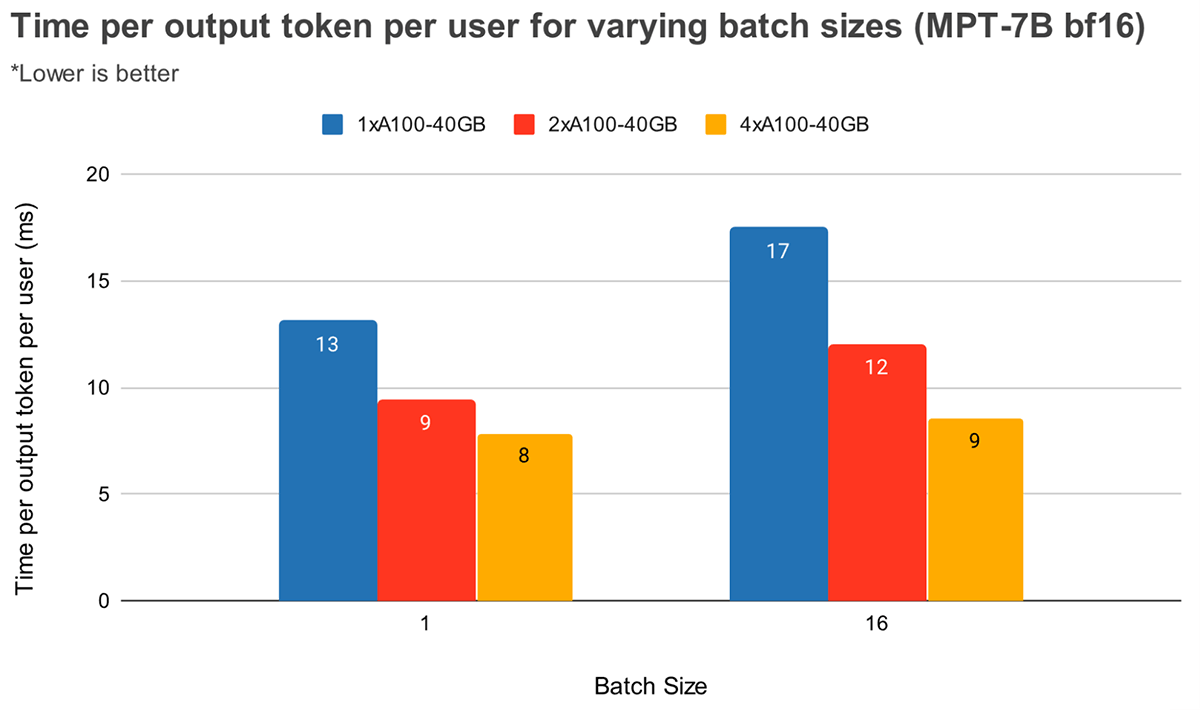
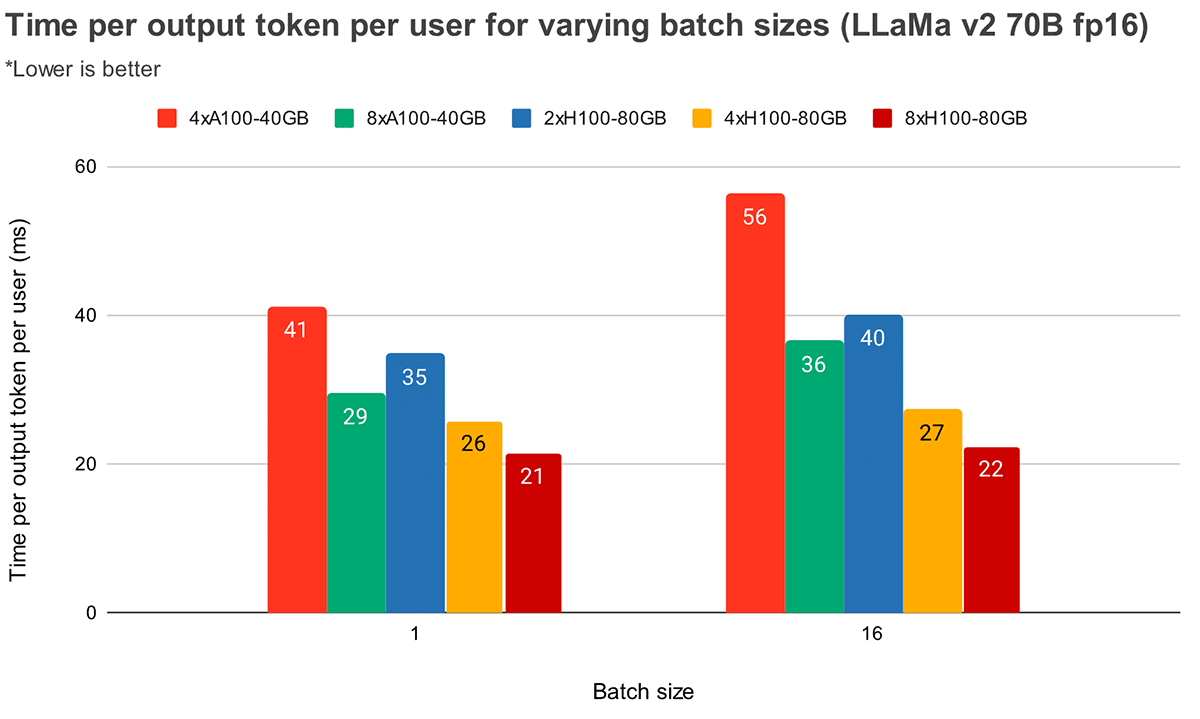
Con batch size maggiori, un parallelismo tensoriale più elevato porta a una diminuzione relativa più significativa della latenza per token. La Figura 4 mostra come varia il tempo per token di output per MPT-7B. Con un batch size di 1, passare da 2x a 4x riduce la latenza per token solo del ~12%. Con un batch size di 16, la latenza con 4x è inferiore del 33% rispetto a 2x. Ciò è in linea con la nostra osservazione precedente che la diminuzione relativa dell'MBU è minore a gradi di parallelismo tensoriale più elevati per batch size 16 rispetto al batch size 1.
La Figura 5 mostra risultati simili per Llama2-70B, eccetto che il miglioramento relativo tra 4x e 8x è meno pronunciato. Confrontiamo anche lo scaling delle GPU su due hardware diversi. Poiché H100-80GB ha una larghezza di banda di memoria per GPU 2,15 volte superiore rispetto ad A100-40GB, possiamo vedere che la latenza è inferiore del 36% con batch size 1 e inferiore del 52% con batch size 16 per sistemi 4x.
Throughput
Possiamo scambiare throughput e tempo per token raggruppando le richieste. Raggruppare le query durante la valutazione della GPU aumenta il throughput rispetto all'elaborazione sequenziale delle query, ma ogni query impiegherà più tempo per essere completata (ignorando gli effetti di accodamento).
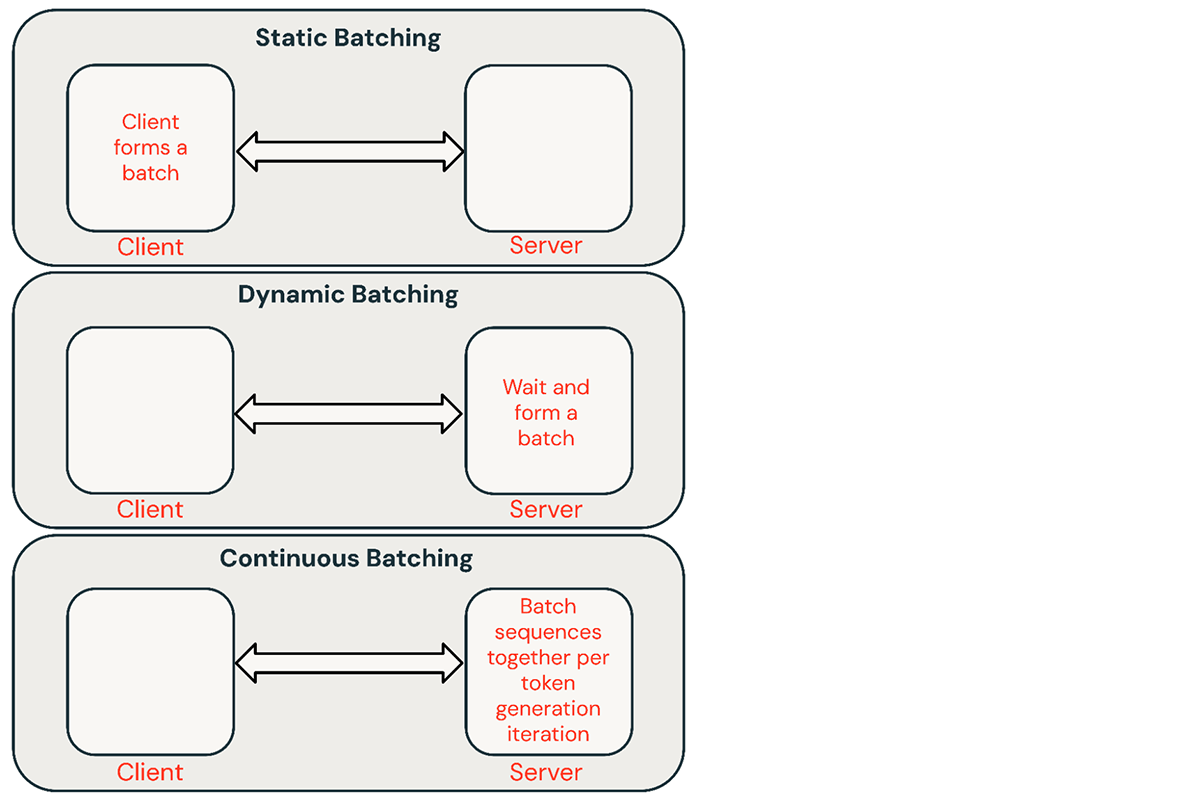
Esistono alcune tecniche comuni per il batching delle richieste di inferenza:
- Batching statico: Il client raggruppa più prompt in richieste e una risposta viene restituita dopo che tutte le sequenze nel batch sono state completate. I nostri server di inferenza supportano questo ma non lo richiedono.
- Batching dinamico: I prompt vengono raggruppati al volo all'interno del server. Tipicamente, questo metodo funziona peggio del batching statico ma può avvicinarsi all'ottimale se le risposte sono brevi o di lunghezza uniforme. Non funziona bene quando le richieste hanno parametri diversi.
- Batching continuo: L'idea di raggruppare le richieste man mano che arrivano è stata introdotta in questo eccellente paper questo ed è attualmente il metodo SOTA. Invece di attendere il completamento di tutte le sequenze in un batch, raggruppa le sequenze a livello di iterazione. Può ottenere un throughput 10x-20x migliore rispetto al batching dinamico.
Il batching continuo è solitamente l'approccio migliore per i servizi condivisi, ma ci sono situazioni in cui gli altri due potrebbero essere migliori. In ambienti con basso QPS, il batching dinamico può superare il batching continuo. A volte è più facile implementare ottimizzazioni GPU di basso livello in un framework di batching più semplice. Per i carichi di lavoro di inferenza batch offline, il batching statico può evitare un overhead significativo e ottenere un throughput migliore.
Batch Size
L'efficacia del batching dipende fortemente dallo stream di richieste. Possiamo però ottenere un limite superiore alle sue prestazioni confrontando il batching statico con richieste uniformi.
| Dimensione del batch | |||||||
|---|---|---|---|---|---|---|---|
| Hardware | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | Errore OOM (Out of Memory) | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
Tabella 2: Throughput di picco MPT-7B (richieste/sec) con batching statico e un backend basato su FasterTransformers. Richieste: 512 token di input e 64 di output. Per input più grandi, il limite OOM si verificherà con dimensioni di batch inferiori.
Compromesso latenza
La latenza delle richieste aumenta con la dimensione del batch. Con una singola GPU NVIDIA A100, ad esempio, se massimizziamo il throughput con una dimensione del batch di 64, la latenza aumenta di 4 volte mentre il throughput aumenta di 14 volte. I servizi di inferenza condivisi solitamente scelgono una dimensione del batch bilanciata. Gli utenti che ospitano i propri modelli dovrebbero decidere il compromesso latenza/throughput appropriato per le loro applicazioni. In alcune applicazioni, come i chatbot, la bassa latenza per risposte rapide è la priorità principale. In altre applicazioni, come l'elaborazione in batch di PDF non strutturati, potremmo voler sacrificare la latenza per elaborare un singolo documento al fine di elaborarli tutti rapidamente in parallelo.
La Figura 7 mostra la curva throughput vs latenza per il modello 7B. Ogni linea su questa curva si ottiene aumentando la dimensione del batch da 1 a 256. Questo è utile per determinare quanto possiamo aumentare la dimensione del batch, soggetti a diversi vincoli di latenza. Ricordando il nostro grafico roofline sopra, troviamo che queste misurazioni sono coerenti con ciò che ci aspetteremmo. Dopo una certa dimensione del batch, ovvero quando passiamo al regime bound dal punto di vista computazionale, ogni raddoppio della dimensione del batch aumenta solo la latenza senza aumentare il throughput.
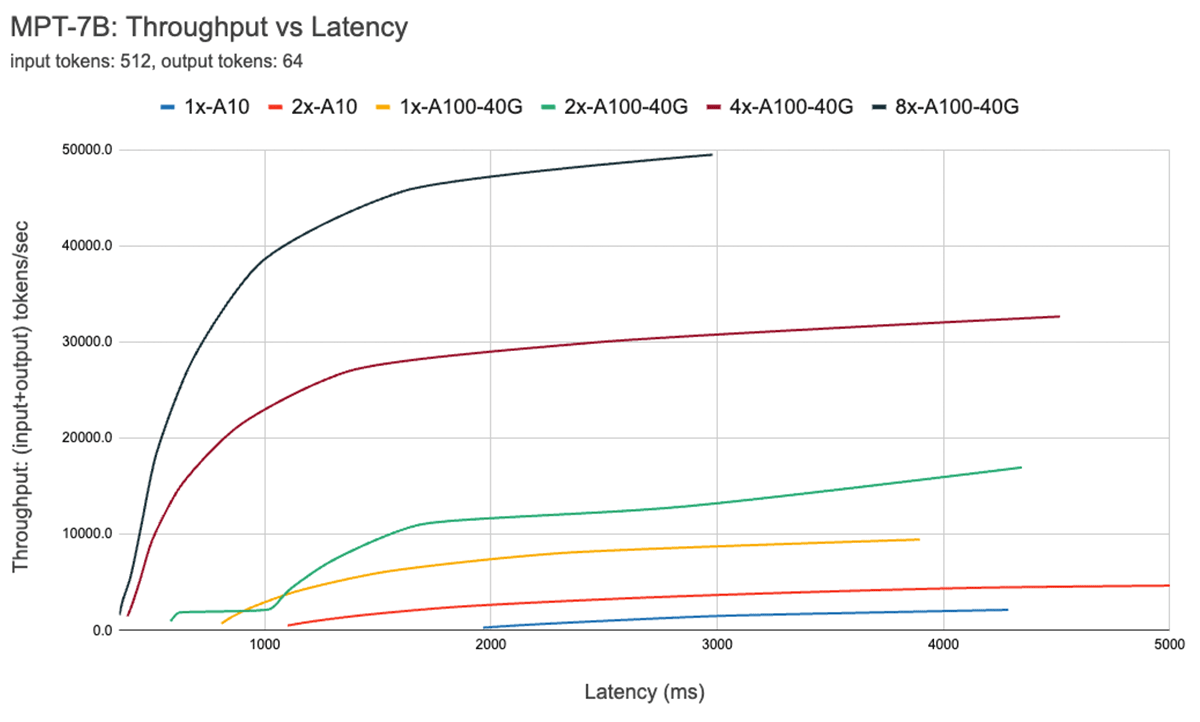
Quando si utilizza il parallelismo, è importante comprendere i dettagli hardware di basso livello. Ad esempio, non tutte le istanze 8xA100 sono uguali tra i diversi cloud. Alcuni server hanno connessioni ad alta larghezza di banda tra tutte le GPU, altri accoppiano le GPU e hanno connessioni a larghezza di banda inferiore tra le coppie. Questo potrebbe introdurre colli di bottiglia, facendo deviare le prestazioni reali in modo significativo dalle curve sopra.
Caso di studio di ottimizzazione: Quantizzazione
La quantizzazione è una tecnica comune utilizzata per ridurre i requisiti hardware per l'inferenza LLM. Ridurre la precisione dei pesi e delle attivazioni del modello durante l'inferenza può ridurre drasticamente i requisiti hardware. Ad esempio, passare da pesi a 16 bit a pesi a 8 bit può dimezzare il numero di GPU richieste in ambienti con memoria limitata (ad es. Llama2-70B su A100). Scendere a pesi a 4 bit rende possibile eseguire l'inferenza su hardware consumer (ad es. Llama2-70B su Macbook).
Nella nostra esperienza, la quantizzazione dovrebbe essere implementata con cautela. Tecniche di quantizzazione naive possono portare a un sostanziale degrado della qualità del modello. L'impatto della quantizzazione varia anche tra architetture (ad es. MPT vs Llama) e dimensioni dei modelli. Esploreremo questo in modo più dettagliato in un futuro post del blog.
Quando si sperimentano tecniche come la quantizzazione, si consiglia di utilizzare un benchmark di qualità LLM come il Mosaic Eval Gauntlet per valutare la qualità del sistema di inferenza, non solo la qualità del modello isolato. Inoltre, è importante esplorare ottimizzazioni di sistema più approfondite. In particolare, la quantizzazione può rendere le cache KV molto più efficienti.
Come accennato in precedenza, nella generazione di token autoregressiva, le chiavi/valori (KV) passati dai layer di attenzione vengono memorizzati nella cache invece di ricalcolarli ad ogni passaggio. La dimensione della cache KV varia in base al numero di sequenze elaborate contemporaneamente e alla lunghezza di queste sequenze. Inoltre, durante ogni iterazione della generazione del token successivo, nuovi elementi KV vengono aggiunti alla cache esistente, rendendola più grande man mano che vengono generati nuovi token. Pertanto, una gestione efficace della memoria della cache KV durante l'aggiunta di questi nuovi valori è fondamentale per buone prestazioni di inferenza. I modelli Llama2 utilizzano una variante dell'attenzione chiamata Grouped Query Attention (GQA). Si noti che quando il numero di head KV è 1, GQA è uguale a Multi-Query-Attention (MQA). GQA aiuta a ridurre la dimensione della cache KV condividendo Chiavi/Valori. La formula per calcolare la dimensione della cache KV è
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (K e V) * 2 (byte per Float16) * n_kv_heads
La Tabella 3 mostra la dimensione della cache KV GQA calcolata a diverse dimensioni del batch con una lunghezza di sequenza di 1024 token. La dimensione dei parametri per i modelli Llama, in confronto, è di 140 GB (Float16) per il modello 70B. La quantizzazione della cache KV è un'altra tecnica (oltre a GQA/MQA) per ridurre la dimensione della cache KV, e stiamo valutando attivamente il suo impatto sulla qualità della generazione.
| Dimensione Batch | Memoria Cache KV GQA (FP16) | Memoria Cache KV GQA (Int8) |
|---|---|---|
| 1 | .312 GiB | .156 GiB |
| 16 | 5 GiB | 2.5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
Tabella 3: Dimensione cache KV per Llama-2-70B a una lunghezza di sequenza di 1024
Come accennato in precedenza, la generazione di token con LLM a basse dimensioni del batch è un problema bound dalla larghezza di banda della memoria della GPU, ovvero la velocità di generazione dipende dalla rapidità con cui i parametri del modello possono essere spostati dalla memoria della GPU alle cache on-chip. La conversione dei pesi del modello da FP16 (2 byte) a INT8 (1 byte) o INT4 (0,5 byte) richiede lo spostamento di meno dati e quindi accelera la generazione dei token. Tuttavia, la quantizzazione può influire negativamente sulla qualità della generazione del modello. Stiamo attualmente valutando l'impatto sulla qualità del modello utilizzando Model Gauntlet e prevediamo di pubblicare presto un post di follow-up al riguardo.
Conclusioni e risultati chiave
Ciascuno dei fattori che abbiamo delineato sopra influenza il modo in cui costruiamo e distribuiamo i modelli. Utilizziamo questi risultati per prendere decisioni basate sui dati che tengono conto del tipo di hardware, dello stack software, dell'architettura del modello e dei modelli di utilizzo tipici. Ecco alcune raccomandazioni tratte dalla nostra esperienza.
Identifica il tuo obiettivo di ottimizzazione: Ti interessa le prestazioni interattive? Massimizzare il throughput? Minimizzare i costi? Ci sono compromessi prevedibili qui.
Presta attenzione ai componenti della latenza: Per le applicazioni interattive, il tempo per il primo token determina la reattività del tuo servizio e il tempo per token di output determina la sua velocità.
La larghezza di banda della memoria è fondamentale: La generazione del primo token è tipicamente un'operazione bound dal calcolo, mentre la decodifica successiva è un'operazione bound dalla memoria. Poiché l'inferenza LLM opera spesso in contesti bound dalla memoria, MBU è una metrica utile da ottimizzare e può essere utilizzata per confrontare l'efficienza dei sistemi di inferenza.
Il batching è fondamentale: l'elaborazione di più richieste in parallelo è fondamentale per ottenere un throughput elevato e per utilizzare efficacemente le GPU costose. Per i servizi online condivisi il batching continuo è indispensabile, mentre i carichi di lavoro di inferenza batch offline possono ottenere un throughput elevato con tecniche di batching più semplici.
Ottimizzazioni approfondite: le tecniche standard di ottimizzazione dell'inferenza sono importanti (ad es. fusione di operatori, quantizzazione dei pesi) per gli LLM, ma è importante esplorare ottimizzazioni di sistema più approfondite, specialmente quelle che migliorano l'utilizzo della memoria. Un esempio è la quantizzazione della cache KV.
Configurazioni hardware: il tipo di modello e il carico di lavoro previsto devono essere utilizzati per decidere l'hardware di deployment. Ad esempio, quando si scala a più GPU, l'MBU diminuisce molto più rapidamente per i modelli più piccoli, come MPT-7B, rispetto ai modelli più grandi, come Llama2-70B. Le prestazioni tendono anche a scalare in modo sub-lineare con gradi più elevati di parallelismo tensoriale. Detto questo, un alto grado di parallelismo tensoriale potrebbe ancora avere senso per i modelli più piccoli se il traffico è elevato o se gli utenti sono disposti a pagare un sovrapprezzo per una latenza extra bassa.
Decisioni basate sui dati: comprendere la teoria è importante, ma raccomandiamo di misurare sempre le prestazioni end-to-end del server. Ci sono molte ragioni per cui un deployment di inferenza può avere prestazioni inferiori alle attese. L'MBU potrebbe essere inaspettatamente basso a causa di inefficienze software. Oppure le differenze hardware tra i provider cloud potrebbero portare a sorprese (abbiamo osservato una differenza di latenza 2x tra server 8xA100 di due provider cloud).
Per iniziare con l'inferenza LLM, prova Databricks Model Serving. Dai un'occhiata alla documentazione per saperne di più.
Vedi tutti i precedenti blog di MosaicML
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.