Modelli LLM nel lakehouse: un balzo in avanti per il settore pubblico
di Tim Lortz, Parth Vakil e Lisa Sion

Negli ultimi mesi, l'interesse delle agenzie del settore pubblico per i Large Language Model (LLM) è salito alle stelle, poiché gli LLM stanno cambiando radicalmente le aspettative delle persone nelle loro interazioni con computer e dati. Dal punto di vista di Databricks, praticamente ogni cliente, effettivo e potenziale, del settore pubblico con cui interagiamo sente il dovere di integrare gli LLM nella propria missione. Ci chiedono spesso cosa siano gli LLM (come Dolly di Databricks), a cosa servano e in che modo Databricks Lakehouse supporterà le applicazioni basate su LLM. In questo post affronteremo queste domande nel contesto delle esigenze, delle opportunità e dei vincoli unici delle organizzazioni del settore pubblico. Ci concentreremo anche sui vantaggi di creare, possedere e curare il proprio LLM rispetto all'adozione di una tecnologia che richiede il Data Sharing con terze parti, come ChatGPT.
Cosa sono gli LLM?
Gli odierni LLM rappresentano l'ultima versione di una serie di innovazioni nell'elaborazione del linguaggio naturale, iniziata all'incirca nel 2017 con l'ascesa dell'architettura del modello transformer. Questi modelli basati su transformer possiedono da tempo capacità sorprendenti di comprendere il linguaggio umano abbastanza bene da svolgere attività come l'identificazione del sentiment, l'estrazione di nomi di persone, luoghi e cose e la traduzione di documenti da una lingua all'altra. Sono anche in grado di generare testo interessante da un prompt, con vari gradi di qualità e precisione. Più di recente, ricercatori e sviluppatori hanno scoperto che modelli linguistici molto grandi, "pre-addestrati" su fonti di testo molto grandi e diversificate, possono essere sottoposti a "fine-tuning" per seguire varie istruzioni umane e generare informazioni utili.
In precedenza, la prassi migliore consisteva nell'addestrare modelli separati per ogni attività linguistica. Il processo di addestramento del modello richiedeva risorse: dati curati, compute (solitamente una o più GPU) e competenze avanzate di Data Science e sviluppo software. Sebbene tali modelli possano essere molto accurati, esistono chiaramente limiti di risorse, sia in termini di calcolo che di impegno umano, nell'ampliare il loro utilizzo. Con la rapida ascesa di ChatGPT, ora vediamo che un singolo LLM, con la giusta quantità di contesto e il prompt corretto, può essere utilizzato per eseguire molte attività diverse, a volte con una precisione migliore rispetto a un modello più specializzato. E la capacità degli LLM di generare nuovo testo, l'"IA generativa", è sia affascinante che estremamente utile.
Per cosa possono essere utilizzati gli LLM nel Settore Pubblico?
Le organizzazioni del settore privato hanno segnalato incredibili vantaggi derivanti dagli LLM, come la generazione e la migrazione del codice, la categorizzazione e le risposte automatizzate al feedback dei clienti, i chatbot per i call center, la generazione di report e molto altro. Essendo un microcosmo di molti diversi settori industriali, le agenzie del Settore Pubblico hanno le stesse opportunità offerte dagli LLM, oltre ad altre esigenze specifiche. I casi d'uso comuni nel Settore Pubblico includono:
- Assistenza per la conformità normativa. Grazie alla sua capacità di interpretare ed elaborare il testo, un LLM può assistere nel determinare i requisiti di conformità analizzando documenti normativi, testi legali e la giurisprudenza pertinente. Può aiutare gli enti governativi e le aziende a comprendere le implicazioni delle normative e a garantire il rispetto della legge.
- Assistente per l'addestramento e l'istruzione. Scale e accelera l'apprendimento per gli studenti fungendo da istruttore virtuale, rispondendo alle domande, spiegando concetti complessi, recuperando parti pertinenti delle registrazioni delle lezioni o consigliando le offerte del catalogo dei corsi.
- Riassumere e rispondere a domande da documenti tecnici. Forse il caso d'uso più diffuso relativo agli LLM nel Settore Pubblico è l'estrazione di conoscenza da migliaia o milioni di documenti, inclusi PDF ed email, in un formato che faciliti la rapida individuazione di contenuti pertinenti in base a criteri di ricerca, per poi utilizzare tali contenuti per generare riepiloghi o report.
- Intelligence open source. Gli LLM possono potenziare notevolmente l'analisi di Open Source Intelligence (OSINT) da parte della Comunità di Intelligence, elaborando e analizzando enormi quantità di informazioni multilingue pubblicamente disponibili. Gli LLM possono estrarre entità chiave, relazioni, sentiment e comprensione contestuale da diverse fonti come social media, articoli di notizie e report, per poi riassumere e organizzare in modo efficiente queste informazioni, aiutando gli analisti a comprendere rapidamente ed estrarre approfondimenti da grandi volumi di dati OSINT.
- Modernizzazione delle codebase legacy. Le agenzie governative continuano a spostare i carichi di lavoro dei dati da mainframe, data warehouse on-premise e software di analitiche proprietari. Fornendo assistenti alla codifica a sviluppatori e analisti per suggerire codice durante la programmazione, o addestrando LLM personalizzati per gestire la conversione di codice in blocco, il ritmo della migrazione può accelerare, mentre i professionisti acquisiscono agevolmente le competenze software pertinenti.
- Risorse umane. In qualità di più grande datore di lavoro della nazione, il governo federale affronta sfide uniche nell'assunzione e nel garantire la soddisfazione dei dipendenti. Sfruttare gli LLM nel campo delle risorse umane può aiutare ad affrontare queste sfide automatizzando lo screening dei curriculum, abbinando i candidati alle descrizioni dei job e analizzando il feedback dei dipendenti per migliorare i processi di assunzione e aumentare il coinvolgimento della forza lavoro. Inoltre, gli LLM possono aiutare a garantire la conformità alle policy HR, a sostenere le iniziative di diversità e inclusione e a fornire consigli personalizzati per l'onboarding e lo sviluppo di carriera.
In che modo Databricks supporterà le esigenze delle organizzazioni del settore pubblico in un mondo basato sugli LLM?
Sebbene siano certamente potenti, gli LLM introducono anche una nuova serie di sfide, amplificate da alcuni dei vincoli operativi tipici delle organizzazioni del settore pubblico. Analizziamone alcune e allineiamole con le funzionalità di Databricks Lakehouse:
Sfida n. 1: Sovranità e governance dei dati
Questo modello presenta un problema:
La maggior parte delle organizzazioni del settore pubblico dispone di rigidi controlli normativi sui propri dati. Questi controlli esistono per motivi di privacy, sicurezza e, in alcuni casi, per la necessità di preservare la segretezza. Anche il semplice compito di porre a un LLM una domanda o una serie di domande potrebbe rivelare informazioni proprietarie. Inoltre, la maggior parte delle agenzie federali avrà la necessità di perfezionare gli LLM per soddisfare i loro requisiti specifici. Per questi motivi, è logico presumere che le agenzie del settore pubblico saranno limitate nell'uso di modelli pubblici. È probabile che richiedano che i modelli vengano perfezionati in un ambiente che ne garantisca la riservatezza e la sicurezza e che anche le interazioni con i modelli tramite vari metodi di prompting siano riservate.
Soluzioni Databricks
Databricks Lakehouse Platform dispone degli strumenti necessari per sviluppare e distribuire applicazioni LLM end-to-end. (Maggiori dettagli in seguito.) Inoltre, Databricks possiede le certificazioni necessarie per elaborare i dati per la stragrande maggioranza delle organizzazioni del settore pubblico statunitense. Databricks è un partner affidabile e competente per le organizzazioni che desiderano sfruttare il pieno potenziale degli LLM senza i rischi derivanti dall'utilizzo di LLM proprietari as-a-service come ChatGPT o Bard.
Oltre a Databricks, nel settore si sta assistendo a un numero crescente di prove che gli LLM open-source, se utilizzati in modo appropriato, possono fornire risultati che si avvicinano alla parità con i principali LLM proprietari. L'evidenza è più forte nei casi d'uso in cui gli LLM proprietari devono comprendere contesti sfumati o istruzioni su cui non sono stati precedentemente addestrati. In questi casi, gli LLM open source possono ricevere prompt o essere sottoposti a fine-tuning su dati specifici dell'organizzazione per fornire risultati sorprendenti. Con questa architettura della soluzione, le organizzazioni possono ottenere risultati di livello mondiale con compute e sviluppo contenuti, senza che i dati varchino mai i confini autorizzati. Per le organizzazioni del settore pubblico, ciò rappresenta un vantaggio significativo che non può essere trascurato.
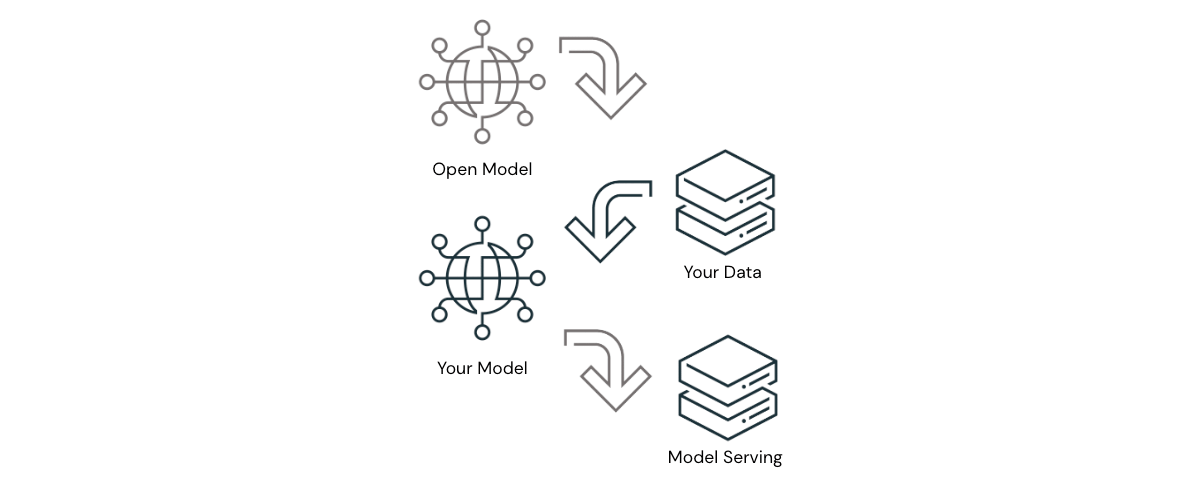
La fiducia di Databricks nella potenza degli LLM open source è rafforzata dal rilascio di Dolly 2.0, il primo LLM open source in grado di seguire le istruzioni, messo a punto su un set di dati di istruzioni generato dall'uomo e concesso in licenza per la ricerca e l'uso commerciale. Al rilascio di Dolly è seguita un'ondata di altri capaci LLM open source, alcuni dei quali hanno prestazioni davvero impressionanti. Databricks si impegna a fornire alle organizzazioni del settore pubblico una piattaforma per creare applicazioni con l'LLM di loro scelta, open source o commerciale, e siamo entusiasti di ciò che ci riserva il futuro.

Sfida n. 2: Complessità architetturale
Questo modello presenta un problema:
La modernizzazione del patrimonio di dati continua a essere una priorità per la maggior parte dei leader tecnici nel settore pubblico. Sono ormai lontani i tempi dei data warehouse on-premise, solitamente sostituiti da data warehouse o lakehouse in cloud. Le organizzazioni che non sono ancora migrate al cloud, o che hanno optato per un data warehouse in cloud, ora si trovano di fronte a un altro punto di svolta: come adottare gli LLM in un'architettura che non è in grado di supportarli? Dato l'enorme potenziale degli LLM di avere un impatto sulle missioni delle agenzie e sui dipendenti pubblici che le realizzano, è fondamentale stabilire un'architettura a prova di futuro. Entra nel lakehouse.
Soluzioni Databricks
Databricks è da tempo una piattaforma valida per i carichi di lavoro di machine learning (ML) e intelligenza artificiale (AI). I clienti utilizzano da anni LLM di livello produttivo e i loro predecessori su Databricks, sfruttando funzionalità quali:
- Compute scalabile per la pre-elaborazione di dati non strutturati come testo, immagini e audio
- Accesso alla suite completa di librerie ML/AI open-source
- Un ambiente di sviluppo notebook nativo e il migliore della categoria, con un eccellente supporto anche per l'integrazione con gli IDE
- Funzionalità di governance dei dati tramite Unity Catalog che garantiscono controlli di accesso adeguati a
- Dati strutturati (database e tabelle)
- Dati non strutturati (file, immagini, documenti)
- Modelli (LLM o di altro tipo)
- Opzioni di compute su GPU per l'addestramento e le previsioni dei modelli di ML, ora un prerequisito per lavorare con gli LLM basati su transformer
- Gestione end-to-end del ciclo di vita dei modelli con MLflow e Unity Catalog. I modelli sono trattati come elementi di prima classe, con lineage ai dati di origine e agli eventi di addestramento, e possono essere distribuiti in modalità batch o in tempo reale
- Capacità di erogazione dei modelli, che diventano sempre più critiche man mano che le organizzazioni eseguono il fine-tuning, ospitano e distribuiscono i propri LLM
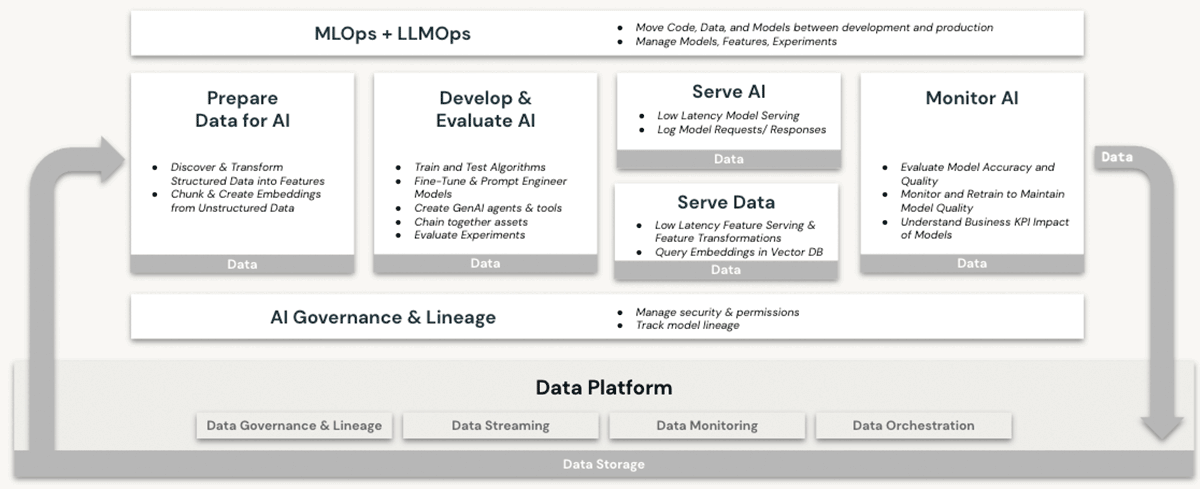
Nessuna di queste funzionalità è offerta in un data warehouse, nemmeno in cloud. Per utilizzare gli LLM in combinazione con un data warehouse, un'organizzazione dovrebbe procurarsi altri servizi software per tutti gli aspetti dei processi di addestramento e deployment del modello e inviare dati avanti e indietro tra questi servizi. Solo l'architettura Databricks Lakehouse offre la semplicità, a livello di architettura, di eseguire tutte le attività operative LLM su un'unica piattaforma, sfruttando appieno i vantaggi illustrati nella nostra precedente discussione sulla sovranità dei dati.
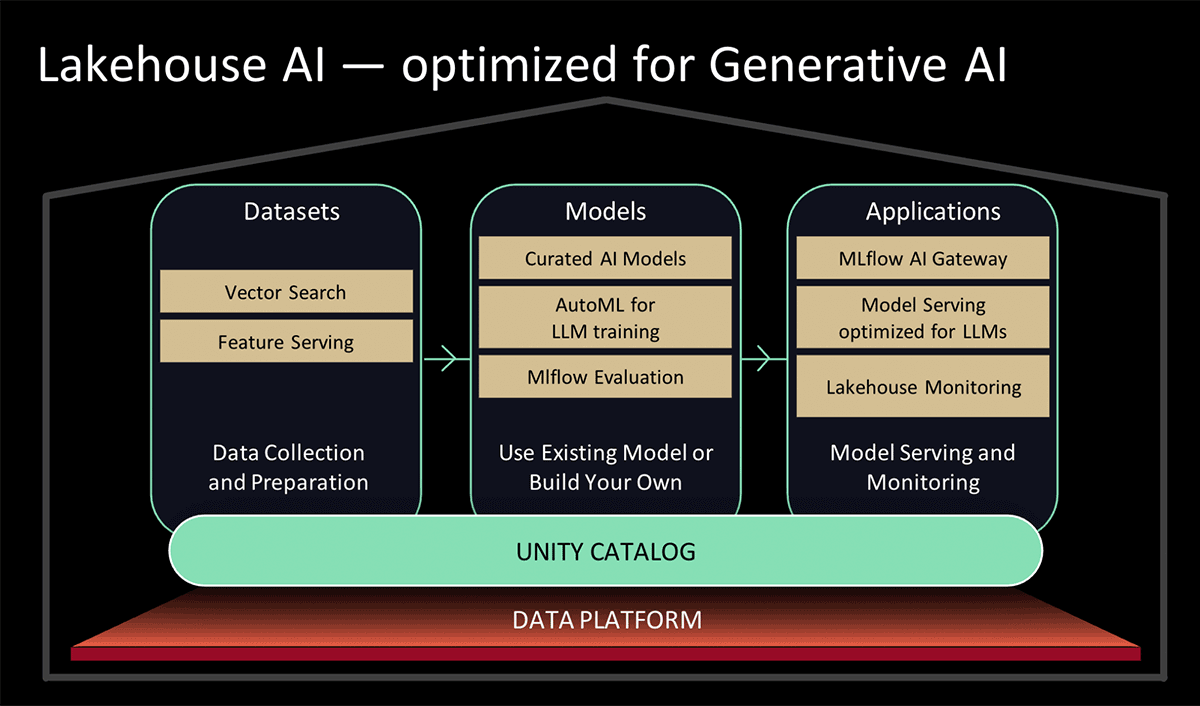
Al Data and AI Summit 2023, Databricks ha presentato Lakehouse AI, che aggiunge diverse nuove importanti funzionalità relative agli LLM che semplificano notevolmente l'architettura per MLOps, tra cui:
- Ricerca vettoriale per l'indicizzazione. Un database vettoriale ospitato da Databricks aiuta i team a indicizzare rapidamente i dati delle loro organizzazioni come vettori di embedding e a eseguire ricerche di somiglianza vettoriale a bassa latenza in implementazioni in tempo reale.
- Lakehouse Monitoring Il primo servizio unificato di monitoraggio di dati e IA che consente agli utenti di monitorare simultaneamente la qualità sia dei dati che degli asset di IA.
- Funzione AI. Gli analisti di dati e i Data Engineer ora possono utilizzare gli LLM e altri modelli di machine learning all'interno di una query SQL interattiva o di una pipeline ETL SQL/Spark.
- Governance unificata di dati e AI. Miglioramenti a Unity Catalog per fornire governance completa e tracciamento del lineage di dati e asset di IA in un'unica esperienza unificata.
- MLflow AI Gateway Il gateway IA di MLflow, parte di MLflow 2.5, è un gateway API a livello di workspace che consente alle organizzazioni di creare e condividere route, che possono quindi essere configurate con vari limiti di velocità, caching, attribuzione dei costi, ecc. per gestire i costi e l'utilizzo.
- MLflow 2.4. Questa release offre un set completo di strumenti LLMOps per la valutazione dei modelli
Sfida n. 3: Divario di competenze
Questo modello presenta un problema:
Negli ultimi anni, le agenzie governative hanno dovuto far fronte a una persistente "fuga di cervelli", in particolare in ruoli che si sovrappongono a tendenze tecnologiche in voga come la sicurezza informatica, il cloud computing e l'ML/AI. L'attuale intensa attenzione sugli LLM sta guidando una domanda ancora maggiore di professionisti di talento nel campo dell'ML/AI. Inevitabilmente, il fascino e i vantaggi che derivano da un impiego nel settore big tech e delle startup aggraveranno la carenza di talenti nel settore pubblico. I leader di governo devono avere accesso a piattaforme e partnership che li aiutino ad adottare facilmente gli LLM e a rendere i propri dipendenti autonomi nell'utilizzarli.
Soluzioni Databricks
Databricks è impegnata a rilasciare funzionalità che semplificano ed espandono le capacità esistenti per lavorare con gli LLM nella piattaforma lakehouse. Tra questi:
- Modelli semplificati per l'utilizzo di LLM pre-addestrati di Hugging Face per task di inferenza nelle pipeline di dati, o per il loro fine-tuning per prestazioni migliori sui propri dati in Databricks.
- Semplificazione del processo e miglioramento delle prestazioni del caricamento dei dati da Apache Spark a Hugging Face per i processi di addestramento o fine-tuning dei modelli.
- Acceleratori di soluzioni LLM specifici per settore, che mostrano modelli di implementazione ripetibili per ottenere rapidi risultati, come le analitiche del servizio clienti e la scoperta del prodotto
- La release 2.3 di MLflow, che offre in particolare il supporto LLM nativo:
- Tre nuovissimi "model flavor": Hugging Face Transformers, funzioni OpenAI e LangChain.
- Notevole miglioramento della velocità di download e upload dei modelli da e verso i servizi cloud, grazie al download e all'upload multi-part per i file dei modelli.
- Una funzione Databricks SQL integrata che consente agli utenti di accedere agli LLM direttamente da SQL. Questa funzionalità può aggirare i lunghi e complessi processi di sviluppo di modelli linguistici, consentendo agli analisti di creare semplicemente prompt LLM efficaci
- Come annunciato al Data & AI Summit 2023,
- Aggiunte al servizio AutoML basato su interfaccia utente di Databricks che eseguirà il fine-tuning degli LLM per la classificazione del testo e i modelli di embedding; e
- Modelli curati, supportati da un Model Serving ottimizzato per prestazioni elevate. Anziché dedicare tempo alla ricerca dei migliori modelli di AI generativa open-source per il tuo caso d'uso, puoi fare affidamento sui modelli curati dagli esperti di Databricks per i casi d'uso più comuni.
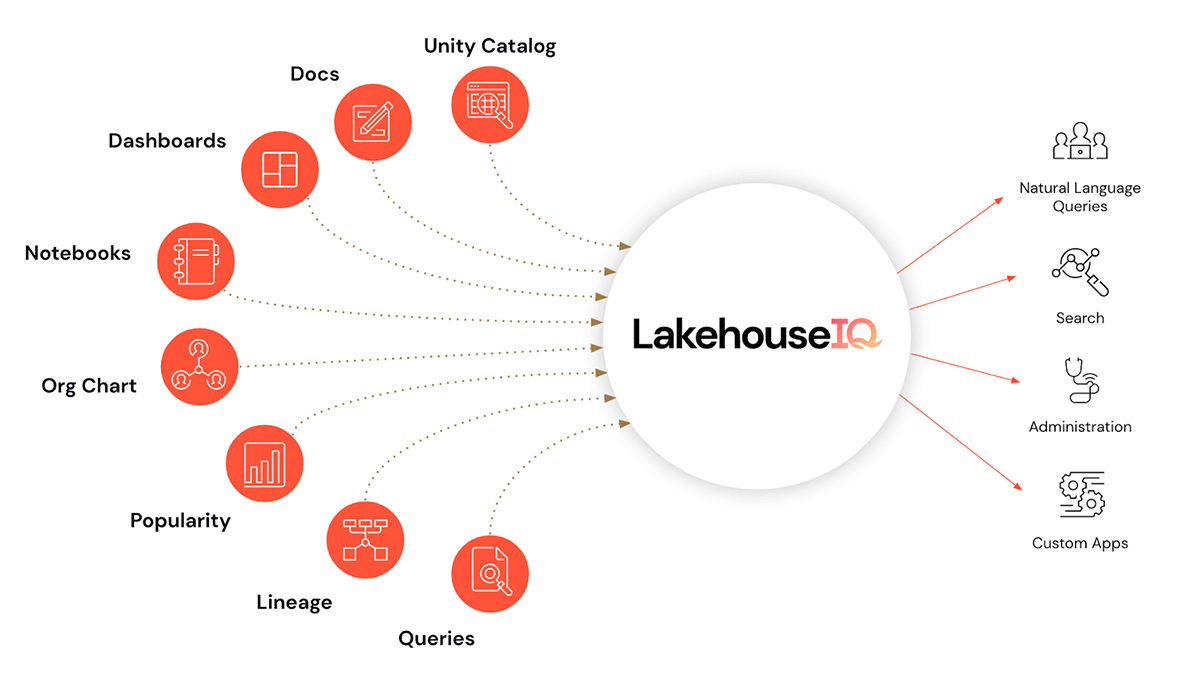
- E, ciliegina sulla torta, LakehouseIQ, un motore di conoscenza che apprende le sfumature uniche del tuo business e dei tuoi dati per consentire l'accesso in linguaggio naturale ad essi per un'ampia gamma di casi d'uso.
Oltre a rendere gli LLM facili da usare in Databricks, stiamo anche introducendo programmi di addestramento e abilitazione per gli LLM per aiutare le organizzazioni a migliorare la loro competenza sugli LLM. Questi vengono forniti a un livello accessibile per gli utenti del settore pubblico di Databricks.
- In partnership con EdX per offrire corsi online tenuti da esperti, specificamente incentrati sulla creazione e l'utilizzo di modelli linguistici nelle applicazioni moderne
Conclusioni e prossimi passi
Abbondano le opportunità di sfruttare gli LLM per accelerare i casi d'uso del settore pubblico. Un valore immenso rimane sepolto nei dati legacy, in attesa di essere scoperto e applicato ai problemi attuali. Scopri di più su come Databricks può aiutarti ad adottare gli LLM per la tua missione partecipando al nostro webinar Large Language Models in the Public Sector il 2 agosto a mezzogiorno (EDT). Inoltre, consulta le iscrizioni all'anteprima delle funzionalità elencate nell'annuncio Lakehouse AI e scopri per quali la tua organizzazione è idonea.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.