LogSentinel: come Databricks utilizza Databricks per il rilevamento e la governance delle PII basati su LLM
Un approfondimento su LogSentinel: come sfruttiamo internamente gli LLM per automatizzare il rilevamento e la governance dei dati PII
- Utilizziamo gli LLM su Databricks per rilevare e classificare automaticamente i dati sensibili in log e database.
- Il nostro sistema LogSentinel applica una classificazione gerarchica, basata sulla residenza e multi-modello per un'etichettatura precisa, tecniche che vengono integrate direttamente nel prodotto Data Classification.
- Grazie alla pre-etichettatura delle colonne e al rilevamento continuo del drift delle etichette, LogSentinel consente un rilevamento PII affidabile, l'applicazione automatizzata delle policy e flussi di lavoro di conformità molto più rapidi su larga scala.
Databricks opera su una scala in cui i nostri log e set di dati interni cambiano costantemente: gli schemi si evolvono, compaiono nuove colonne e la semantica dei dati subisce delle derive. Questo blog illustra come utilizziamo internamente Databricks in Databricks per mantenere i dati PII e altri dati sensibili correttamente etichettati man mano che la nostra piattaforma cambia.
Per fare questo, abbiamo creato LogSentinel, un sistema di classificazione dei dati basato su LLM su Databricks che tiene traccia dell'evoluzione di uno schema, rileva il drift dell'etichettatura e fornisce etichette di alta qualità ai nostri controlli di governance e sicurezza. Usiamo MLflow per tracciare gli esperimenti e monitorare le prestazioni nel tempo e stiamo integrando le migliori idee di LogSentinel nel prodotto Databricks Data Classification, in modo che i clienti possano beneficiare dello stesso approccio.
Perché questo sistema è importante
Questo sistema è progettato per agire su tre leve di business concrete per i team che si occupano di piattaforma, dati e sicurezza:
- Cicli di conformità più brevi: le attività di revisione ricorrenti che in precedenza richiedevano settimane di lavoro da parte degli analisti vengono ora completate in poche ore perché le colonne sono pre-etichettate e pre-classificate prima dell'esame umano.
- Minore rischio operativo: il sistema rileva continuamente il drift dell'etichettatura e le modifiche dello schema, quindi è meno probabile che i campi sensibili passino inosservati con tag errati o mancanti.
- Applicazione più rigorosa delle policy: etichette affidabili ora guidano direttamente le regole di mascheramento, controllo degli accessi, conservazione e residenza dei dati, trasformando quella che era una "governance basata sul massimo impegno" in una policy eseguibile.
In pratica, i team possono inserire nuove tabelle in una pipeline standard, monitorare le metriche di drift e le eccezioni e fare affidamento sul sistema per applicare i vincoli relativi a PII e residenza dei dati senza creare un classificatore su misura per ogni dominio.
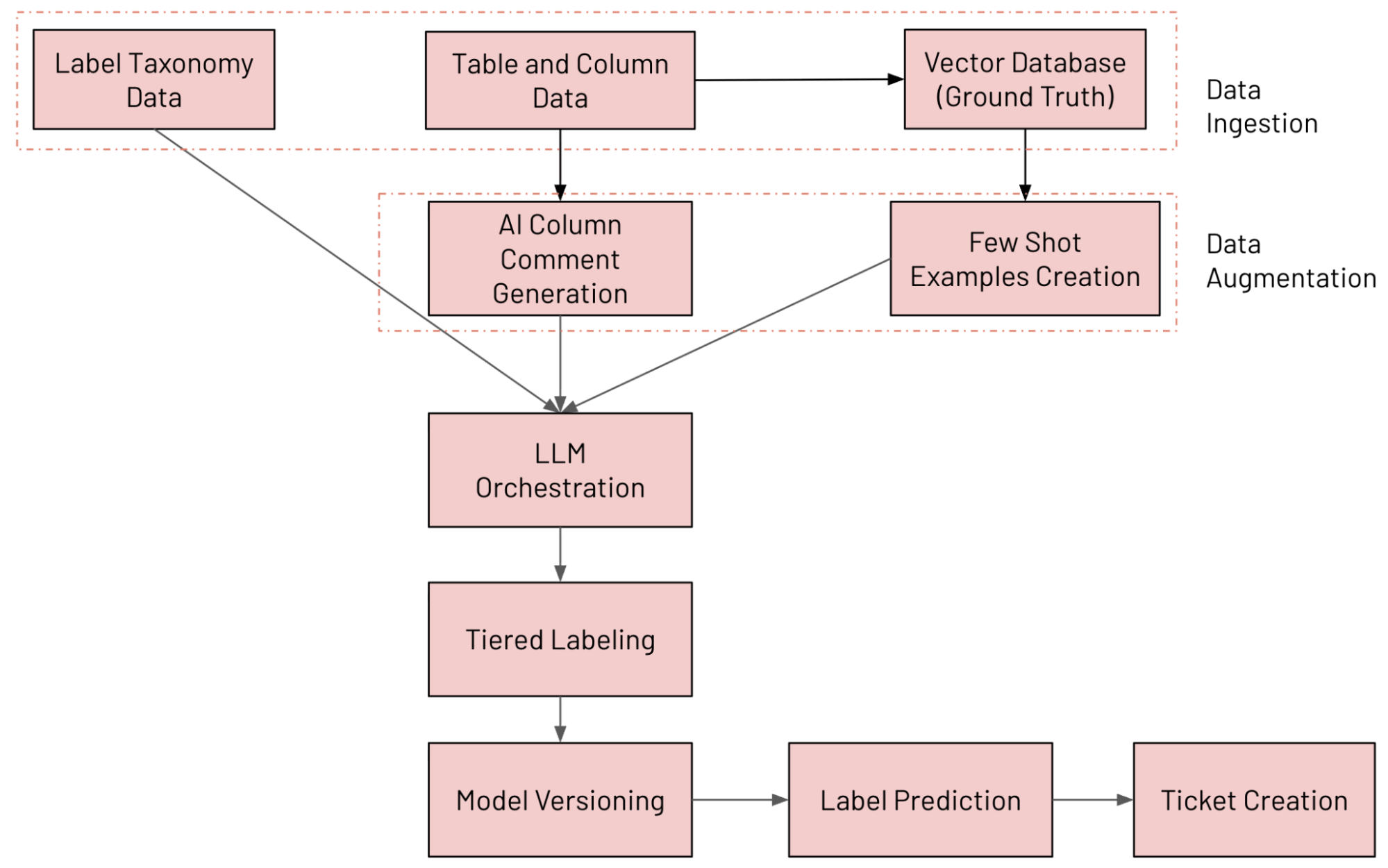
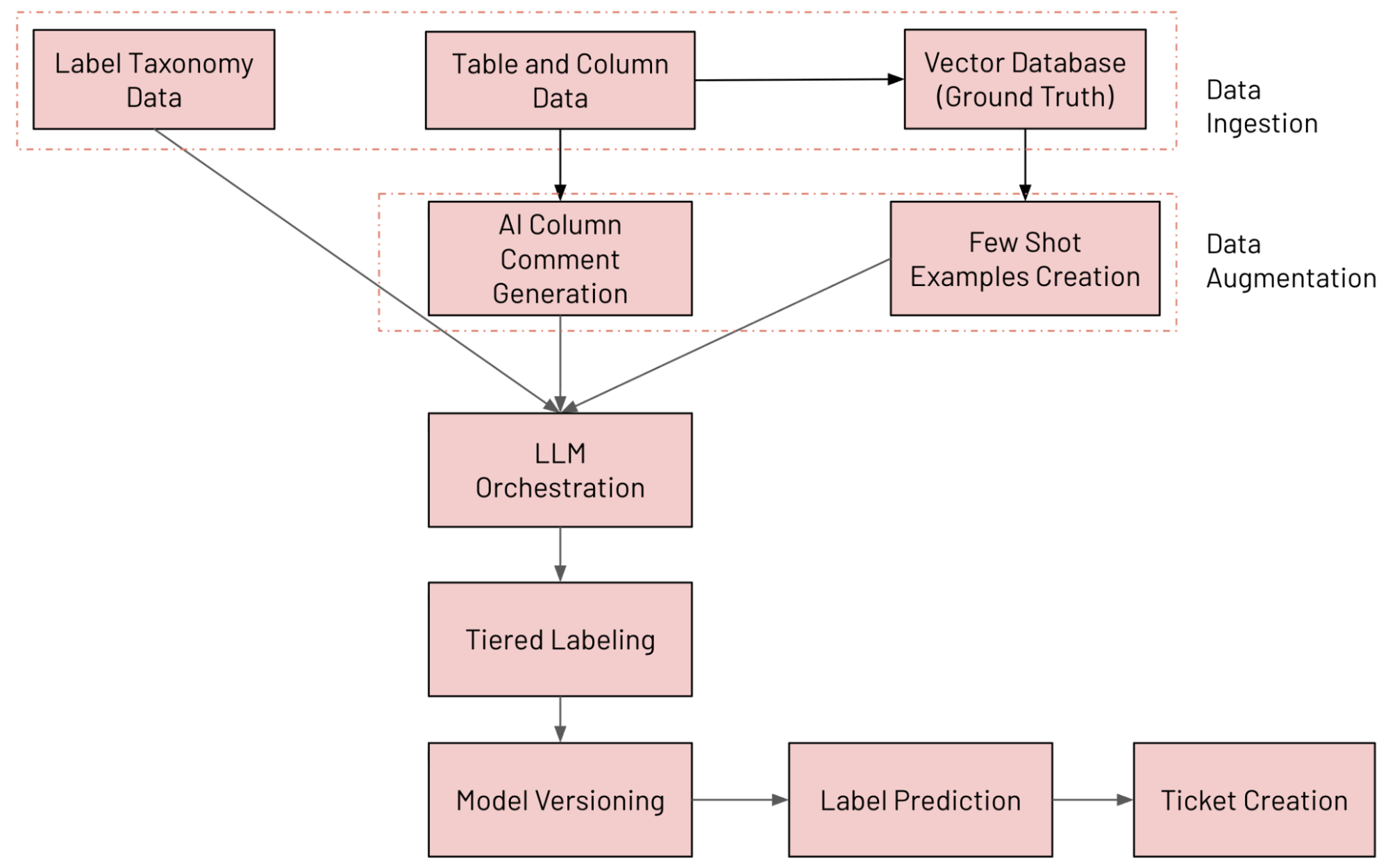
Architettura del sistema in sintesi
Abbiamo creato un sistema di classificazione delle colonne basato su LLM su Databricks che annota continuamente le tabelle utilizzando la nostra tassonomia interna dei dati, rileva il drift delle etichette e apre ticket di correzione quando rileva un problema. I vari componenti del sistema sono illustrati di seguito (monitorati e valutati con MLFlow):
- Ingestione dei dati: ingestione di varie sorgenti di dati (tra cui i dati delle colonne di Unity Catalog, i dati sulla tassonomia delle etichette e i dati di ground truth)
- Data Augmentation: aumento dei dati tramite Databricks AI Search e generazione di commenti tramite IA
- Orchestrazione LLM
- Sistema di etichettatura a più livelli
- Versionamento dei modelli: esecuzione di più modelli in parallelo
- Previsione dell'etichetta: previsione dell'etichetta finale con l'approccio Mixture of Experts (MoE)
- Creazione di ticket: rilevamento delle violazioni e generazione di ticket JIRA
Il flusso di lavoro end-to-end è mostrato nella figura seguente
{kind=link}
Acquisizione di dati
Per ogni tipo di log o set di dati da annotare, campioniamo casualmente i valori di ogni colonna e inviamo al sistema i seguenti metadati: nome della tabella, nome della colonna, tipo, commento esistente e un piccolo campione di valori. Per ridurre i costi degli LLM e migliorare il throughput, più colonne della stessa tabella vengono raggruppate in batch in un'unica richiesta.
La nostra tassonomia è definita utilizzando i Protocol Buffer e attualmente include più di 100 etichette di dati gerarchiche, con la possibilità di aggiungere estensioni personalizzate quando i team necessitano di categorie aggiuntive. Ciò fornisce ai responsabili della governance e della piattaforma un accordo condiviso sul significato di "PII" e "sensibile" che va oltre una manciata di espressioni regolari.
Aumento dei dati
Due strategie di potenziamento migliorano significativamente la qualità della classificazione:
- Generazione di commenti per le colonne tramite IA: quando mancano i commenti, usiamo i commenti generati dall'IA di Databricks per sintetizzare descrizioni concise e leggibili dall'uomo che aiutano sia l'LLM sia i futuri fruitori delle tabelle.
- Generazione di esempi few-shot: manteniamo un set di dati ground truth e usiamo sia esempi statici sia esempi dinamici recuperati tramite AI Search; per ogni colonna, creiamo un embedding a partire da nome, tipo, commento e contesto, quindi recuperiamo le prime K colonne etichettate simili da includere nel prompt.
Il prompting statico è ideale nelle fasi iniziali o quando i dati etichettati sono limitati, garantendo coerenza e riproducibilità. Il prompting dinamico è più efficace nei sistemi maturi, utilizzando la ricerca vettoriale per estrarre esempi simili e adattarsi a nuovi schemi e domini di dati in set di dati ampi e diversificati.
Orchestrazione LLM
Al centro del sistema c'è un livello di orchestrazione leggero che gestisce le chiamate LLM su scala di produzione.
Le funzionalità principali includono:
- Routing multi-modello tra LLM ospitati internamente (ad esempio, modelli basati su Llama, Claude e GPT) con fallback automatico quando un modello non è disponibile.
- Logica di riprova per errori temporanei e limiti di frequenza con backoff esponenziale.
- Hook di validazione che rilevano etichette vuote, non valide o allucinate e rieseguono tali casi con modelli di backup.
- Elaborazione batch che annota più colonne contemporaneamente per ottimizzare l'utilizzo dei token senza perdere il contesto.
Sistema di etichettatura a più livelli
Prevediamo tre tipi di etichette per colonna:
- Etichette granulari, selezionate da un set di oltre 100 opzioni dettagliate che supportano il mascheramento, l'oscuramento e controlli di accesso rigorosi.
- Etichette gerarchiche, che aggregano etichette granulari correlate in categorie più ampie adatte al monitoraggio e alla reportistica.
- Etichette di residenza, che indicano se i dati devono rimanere all'interno della regione o possono essere spostati tra regioni, alimentando direttamente le policy di spostamento dei dati.
Per mantenere le previsioni coerenti e ridurre le allucinazioni, utilizziamo un flusso a due fasi: una fase di classificazione generale assegna una categoria di alto livello, quindi una fase di affinamento sceglie l'etichetta esatta all'interno di quella categoria. Questo rispecchia il modo in cui un revisore umano deciderebbe prima “questi sono dati del workspace” e poi sceglierebbe l'etichetta specifica dell'identificatore del workspace.
Controllo delle versioni del modello e previsione delle etichette
Invece di affidarsi a una singola configurazione "migliore", ogni impostazione del modello viene trattata come un esperto che compete per etichettare una colonna.
Più versioni del modello vengono eseguite in parallelo con differenze in:
- Scelte LLM primarie e di fallback.
- Uso di commenti generati rispetto a metadati grezzi.
- Strategia di prompting (few-shot statico o dinamico).
- Granularità delle etichette e sottoinsiemi di tassonomia.
Ogni esperto produce un'etichetta e un punteggio di confidenza compreso tra 0 e 100. Il sistema seleziona quindi l'etichetta dall'esperto con la confidenza più alta, un approccio in stile Mixture-of-Experts che migliora l'accuratezza e riduce l'impatto di previsioni errate occasionali da parte di una singola configurazione.
Questo design rende sicura l'Experiment: è possibile introdurre nuovi modelli o strategie di prompt, eseguirli insieme a quelli esistenti e valutarli sia in base alle metriche che al volume di ticket downstream prima che diventino l'impostazione predefinita.
Creazione di ticket
La pipeline confronta continuamente le annotazioni dello schema corrente con le previsioni dell'LLM per far emergere deviazioni significative.
I casi tipici includono:
- Nuove colonne aggiunte senza alcuna annotazione.
- Annotazioni esistenti che non corrispondono più al contenuto della colonna.
- Colonne contenenti valori sensibili che sono state etichettate come idonee per lo spostamento tra regioni.
Quando il sistema rileva una violazione, crea una voce di policy e apre un ticket JIRA per il team proprietario con il contesto relativo a tabella, colonna, etichetta proposta e livello di confidenza. Questo trasforma i problemi di classificazione dei dati in un flusso di lavoro continuo che i team possono monitorare e risolvere allo stesso modo in cui monitorano altri incidenti di produzione.
Impatto e valutazione
Il sistema è stato valutato su 2.258 campioni etichettati, di cui 1.010 contenevano PII e 1.248 erano non PII. Su questo set di dati, ha raggiunto fino al 92% di precisione e al 95% di richiamo per il rilevamento di PII.
Cosa ancora più importante per gli stakeholder, il deployment ha prodotto i risultati operativi necessari:
- L'impegno per la revisione manuale si è ridotto da settimane a ore per ogni ciclo di audit su larga scala perché i revisori partono da etichette suggerite di alta qualità anziché da schemi grezzi.
- Il drift dell'etichettatura viene ora rilevato continuamente man mano che gli schemi si evolvono, anziché essere scoperta durante una revisione annuale.
- Gli avvisi relativi a dati sensibili etichettati erroneamente come sicuri sono più mirati, così i team di sicurezza possono agire rapidamente invece di analizzare i numerosi avvisi degli scanner basati su regole.
- Le policy di mascheramento e residenza vengono applicate su larga scala utilizzando la stessa tassonomia di etichette che alimenta le analitiche e la reportistica.
Precision e recall fungono da guardrail, ma il sistema è ottimizzato in base a risultati quali il tempo di revisione, la latenza di rilevamento del drift e il volume di ticket utilizzabili prodotti a settimana.
Conclusione
Combinando l'etichettatura basata sulla tassonomia e un framework di valutazione in stile MoE, abbiamo abilitato i flussi di lavoro di ingegneria e governance esistenti in Databricks, con esperimenti e distribuzioni gestiti tramite MLflow. Mantiene le etichette aggiornate al variare degli schemi, rende le revisioni di conformità più rapide e mirate e fornisce gli hook di applicazione necessari per applicare le regole di mascheramento e di residenza in modo coerente su tutta la piattaforma.
La parte più entusiasmante di questo lavoro è l'integrazione dei nostri risultati interni direttamente nel prodotto Data Classification. Man mano che rendiamo operative e convalidiamo queste tecniche all'interno di LogSentinel, le integriamo direttamente nella classificazione dei dati di Databricks.
Lo stesso schema (ingerire metadati e campioni, aumentare il contesto, orchestrare più LLM e fornire le previsioni ai sistemi di policy e di ticketing) può essere riutilizzato ovunque sia richiesta una comprensione affidabile e in evoluzione dei dati. Integrando queste informazioni dettagliate nella nostra offerta di prodotti di base, consentiamo a ogni organizzazione di sfruttare la propria data intelligence per la conformità e la governance con la stessa precisione e scalabilità che usiamo in Databricks.
Ringraziamenti
Questo progetto è stato reso possibile grazie alla collaborazione tra diversi team di ingegneria. Un ringraziamento a Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Sun, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava per il loro supporto e i loro contributi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.