Mitigare il rischio di prompt injection per gli agenti AI su Databricks
di JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke e Jean Verrons
- Gli agenti di AI autonomi necessitano di dati sensibili, input non attendibili e azioni esterne per essere utili, ma la combinazione di tutti e tre crea catene di attacco sfruttabili.
- Il team di sicurezza di Databricks ha sviluppato una guida pratica per la messa in sicurezza degli agenti di AI su Databricks utilizzando la "Agents Rule of Two" di Meta, un framework per mitigare il rischio di prompt-injection.
- La guida illustra nove controlli specifici a più livelli su Databricks che riguardano l'accesso ai dati, la convalida degli input e le restrizioni in uscita per ridurre i rischi di prompt injection.
Panoramica
Da quando abbiamo rilasciato il Databricks AI Security Framework (DASF) nel 2024, il panorama delle minacce per AI è cambiato radicalmente. AI si è trasformata dal chatbot stereotipato in agenti in grado di ragionare, usare strumenti e intraprendere azioni per conto degli utenti con un intervento minimo o nullo. I team di sicurezza non devono più pensare solo agli utenti che interagiscono con i modelli, ma anche a uno sciame di agenti intelligenti che agiscono autonomamente, interagiscono con i servizi tramite MCP ed esplorano Internet per conto proprio.
L'iniezione di prompt era un rischio noto nell'era dell'inferenza, ma era in gran parte limitato alla richiesta e alla risposta dell'utente. Con agenti in grado di intraprendere azioni in modo autonomo, il rischio è aumentato in modo esponenziale.
Consideriamo un professionista dei dati che incarica il proprio agente AI di scrivere uno script che chiama un'API di terze parti. L'agente cerca la documentazione su Internet, scrive il codice e lo esegue. Ciò di cui l'utente non si rende conto è che la pagina della documentazione conteneva un prompt dannoso incorporato, che ordinava all'agente di esfiltrare le credenziali dall'ambiente compute dell'utente verso un webhook. Attacchi come questo sono ben documentati nella pratica. Tuttavia, esistono framework che ci aiutano a capire quando e perché hanno successo.
Una recente ricerca dei settori industriali, tra cui l'"Agents Rule of Two" di Meta e modelli simili come il "Lethal Trifecta" di Simon Willison, evidenzia le condizioni in cui gli attacchi di prompt injection hanno successo. Questi pattern sono strettamente allineati con i controlli definiti nel Databricks AI Security Framework (DASF), che fornisce un modello pratico per proteggere gli agenti di AI che operano su dati aziendali.
Entrambi arrivano alla stessa conclusione: un agente AI diventa vulnerabile alla prompt injection quando presenta tutte e tre le seguenti caratteristiche e, per mitigare il rischio, dovrebbe averne solo due:
- Accesso a sistemi sensibili o dati privati
- Esposizione a input non attendibili
- La capacità di cambiare stato o comunicare esternamente
In pratica, questi rischi corrispondono direttamente ai controlli di difesa approfondita definiti nel Databricks AI Security Framework (DASF), che organizza la sicurezza dell'IA attraverso l'accesso ai dati, l'interazione con i modelli e l'esecuzione operativa. Nelle sezioni seguenti, mostriamo come questi rischi possono essere mitigati utilizzando i controlli nativi sulla Databricks Platform.
Comprendere i rischi principali per gli agenti AI
Come accennato nella panoramica, il framework Agents Rule of Two di Meta aiuta a scomporre i pilastri fondamentali che rendono gli agenti di AI vulnerabili all'iniezione di prompt:
- Accesso a sistemi sensibili o dati privati: L'agente può leggere o interagire con dati sensibili dell'utente.
- Elaborare input non attendibili: l'agente può utilizzare contenuti forniti da fonti esterne o controllate da un utente malintenzionato.
- Modificare lo stato o comunicare esternamente: l'agente può intraprendere azioni al di fuori del suo ambiente locale, come effettuare richieste HTTP o modificare sistemi esterni.
Quando tutti e tre i pilastri sono presenti, il sistema ha già accesso a sistemi sensibili o dati privati (primo) e un utente malintenzionato può quindi iniettare istruzioni dannose tramite input non attendibili (secondo), inducendo l'agente a esfiltrare tali dati all'esterno (terzo). In questa sezione vedremo come ognuno di questi si applica nel contesto di Databricks.
Pilastro 1: accesso a sistemi sensibili o a dati privati
Perché un utente malintenzionato possa esfiltrare qualcosa di prezioso, l'agente deve prima potervi accedere. Questo è il primo pilastro della Regola dei Due degli Agenti e, in pratica, non è quasi mai facoltativo. Gli agenti sono più utili quando possono operare su dati reali e di alto valore. Sono sempre più utilizzati per attività come l'analisi del sentiment dei feedback dei clienti, la previsione della domanda, il rilevamento di frodi o l'assistenza per il codice. Per essere efficaci, a questi agenti viene deliberatamente concesso l'accesso a record dei clienti, cronologie delle transazioni, documenti proprietari o grandi codebase interne. In altre parole, proprio i dati che offrono alle organizzazioni un vantaggio competitivo sono anche quelli a cui gli utenti malintenzionati sono più interessati.
In quanto piattaforma unificata di dati e intelligence, Databricks è progettata per centralizzare ed elaborare i set di dati più preziosi di un'organizzazione. Le applicazioni e gli agenti in esecuzione sulla piattaforma operano, per loro natura, a stretto contatto con informazioni sensibili. Ciò significa che in molte implementazioni reali, si dovrebbe presumere che il primo pilastro dell'Agents Rule of Two sia presente, anziché trattarlo come una preoccupazione ipotetica.
Pilastro 2: Elaborare input non attendibili
Il secondo pilastro della Agents Rule of Two si concentra su come i dati non attendibili entrano nel sistema. Nel caso più semplice, questo rischio è evidente: un'interfaccia di chat LLM può accettare direttamente l'input dell'utente che contiene istruzioni dannose. Si tratta di una direct prompt injection, in cui l'aggressore fornisce il payload esplicitamente come parte dell'interazione.
Tuttavia, il rischio si estende oltre l'input diretto dell'utente. Gli agenti e le applicazioni basate su LLM spesso recuperano ed elaborano dati da fonti esterne come database, documenti, APIs o basi di conoscenza. In questi casi, le istruzioni dannose possono essere incorporate in contenuti altrimenti legittimi ed emergere solo quando l'agente legge o ragiona su tali dati. Questa è l'iniezione indiretta di prompt. La sfida è aggravata dal fatto che i moderni LLM sono progettati per interpretare un'ampia gamma di input, tra cui linguaggio naturale, dati strutturati, caratteri speciali, immagini e payload codificati. Questa diversità rende le istruzioni dannose difficili da rilevare utilizzando le tecniche tradizionali di convalida dell'input.
Sulla piattaforma Databricks, la diversità delle sorgenti di dati rende questo aspetto particolarmente rilevante. Una singola tabella di Unity Catalog potrebbe contenere record di transazioni da un sistema di gestione degli ordini, conversazioni di assistenza tra personale e clienti o feedback sui prodotti inviati tramite un modulo web. Quando a un agente viene dato accesso a tali dati, è importante porsi una domanda semplice ma fondamentale: una parte di questi dati potrebbe essere stata influenzata da un attore esterno?
Se la risposta è sì, il secondo pilastro della Regola dei Due degli Agenti è già in atto.
In pratica, questa valutazione è raramente semplice. Spesso richiede di risalire all'origine dei dati e di considerare punti di inserimento meno ovvi, come commenti, campi di testo libero, metadati o allegati, in cui potrebbero essere incorporate istruzioni dannose. Quelli che sembrano normali dati aziendali possono essere, dal punto di vista di un agente, istruzioni eseguibili.
Pilastro 3: Modificare lo stato o comunicare esternamente
L'ultimo pilastro della Regola dei Due degli Agenti si concentra su ciò che l'agente è effettivamente autorizzato a fare e, di conseguenza, su quanto può diventare ampio il raggio d'azione di un attacco. Nelle prime applicazioni LLM, il modello era di fatto di sola lettura. Un utente forniva un prompt, il modello generava una risposta e tale risposta veniva semplicemente visualizzata. Anche se un utente malintenzionato avesse influenzato l'output del modello, l'impatto era generalmente limitato al testo mostrato all'utente, poiché il modello non aveva la capacità di accedere a dati di runtime privati o di eseguire azioni.
Gli agenti moderni sono fondamentalmente diversi. Non si limitano più a produrre testo, ma possono anche cambiare stato tramite azioni come l'esecuzione di codice Python o di query SQL e comunicare esternamente chiamando APIs o interagendo con i sistemi tramite meccanismi come il Model Context Protocol (MCP).
Sulla piattaforma Databricks, gli agenti creati con funzionalità di AI possono essere facilmente collegati a server MCP, funzioni definite dall'utente o APIs esterne. Durante la fase di progettazione, è importante considerare non solo l'uso previsto di questi strumenti, ma anche il loro potenziale uso improprio. Se uno strumento consente all'agente di comunicare esternamente o di sovrascrivere le tabelle, l'ultimo pilastro della Regola dei Due degli agenti è attivo.
Come per gli altri pilastri, creare un quadro completo delle capacità dell'agente non è sempre semplice. Uno strumento che a prima vista sembra innocuo potrebbe comunque essere utilizzabile in modi inaspettati. Gli sviluppatori devono quindi pensare in termini di capacità effettive, ovvero ciò che l'agente potrebbe fare sotto influenza avversaria, e non solo le attività per cui è stato progettato.
Mettendo tutto insieme
Presi singolarmente, ciascuno dei tre pilastri può sembrare gestibile. La prompt injection è meno preoccupante se l'agente non può accedere a dati sensibili. L'accesso a dati sensibili è meno rischioso se l'agente non ha la capacità di agire su di essi. E gli strumenti potenti sono meno pericolosi se l'agente elabora solo input attendibili. Il rischio diventa significativo quando questi fattori convergono. In tali condizioni, un malintenzionato può influenzare il comportamento dell'agente in modi che vanno oltre l'uso previsto, trasformando quella che sembra un'interazione di routine in un incidente di sicurezza con conseguenze nel mondo reale.
Da un punto di vista difensivo, questo ci fornisce un principio di progettazione pratico: cercare di separare i tre pilastri. Nella maggior parte delle applicazioni di AI del mondo reale, è difficile rimuovere completamente un singolo elemento. Gli agenti hanno bisogno di dati per essere utili, devono elaborare input diversi e spesso necessitano di strumenti per automatizzare le attività. Tuttavia, esistono modi concreti per contenere il rischio associato a ciascun pilastro.
Su molte piattaforme di IA, questi rischi vengono affrontati attraverso un mosaico di strumenti che spaziano dai sistemi di identità, ai controlli di rete, ai gateway dei modelli e alle soluzioni di governance dei dati. Databricks adotta un approccio diverso. Poiché dati, modelli di AI e applicazioni vengono eseguiti su una piattaforma unificata governata da Unity Catalog e Agent Bricks, le organizzazioni possono applicare controlli a più livelli sull'intero sistema di AI, dall'accesso ai dati all'interazione con i modelli e all'esecuzione in fase di runtime, senza introdurre ulteriori silos di sicurezza.
La piattaforma Databricks fornisce controlli a ciascuno di questi livelli, che esploreremo nelle sezioni seguenti utilizzando un esempio reale, il nostro nuovo agente AI: Social Gauge.
Controlli per i rischi di prompt injection sugli agenti di AI per pilastro
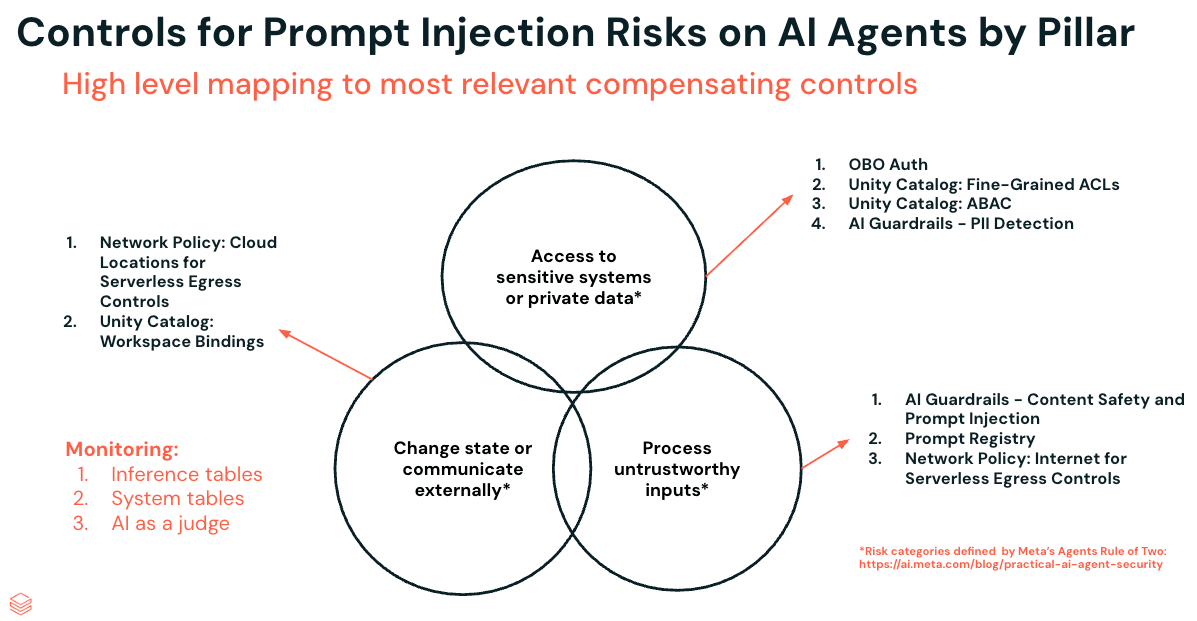
Il modo più efficace per mitigare la prompt injection è rimuovere completamente uno dei tre pilastri, e questo rimane vero. Ma in pratica, la maggior parte degli agenti ha bisogno di un certo grado di tutti e tre: accesso a dati sensibili, esposizione a input esterni e capacità di agire. Quindi, invece di rimuovere un pilastro, l'obiettivo diventa rafforzare ognuno di essi per ridurre la superficie di attacco.
Analizzeremo nove controlli distribuiti su tutti e tre i pilastri utilizzando un esempio pratico: Social Gauge, un agente integrato in un'app Databricks che estrae dati dai social media e da fonti di notizie, per poi combinarli con i record dei clienti esistenti gestiti da Unity Catalog. Si pensi ai team di marketing che effettuano il monitoraggio del sentiment sui lanci di prodotti, ai team finanziari che consolidano la copertura trimestrale o alle redazioni che effettuano il monitoraggio delle agenzie di stampa. Per questa guida pratica, ci concentreremo su un cliente del settore retail che utilizza Social Gauge per monitorare il sentiment degli utenti riguardo a nuovi prodotti.
Dato questo contesto, mentre esaminiamo ciascuno dei tre pilastri, tenete a mente il seguente scenario di attacco:
- Social Gauge ha accesso a dati finanziari sensibili oltre a quanto necessario per l'uso previsto.
- Viene acquisito un post sui social media contenente una "prompt injection" che incorpora istruzioni dannose.
- Tali istruzioni indicano all'agente di recuperare i dati finanziari fuori ambito ed esfiltrarli all'esterno o modificarli all'interno di uno schema interno per influenzare le decisioni a valle.
I controlli che trattiamo in ogni sezione sono progettati per interrompere, mitigare o monitorare questa catena di attacco in diverse fasi.
Pilastro 1: accesso a sistemi sensibili o a dati privati - Controlli
Questo pilastro è quasi inevitabile. Gli agenti sono utili proprio perché operano su dati reali. Social Gauge deve eseguire query su record dei clienti tramite Unity Catalog per rispondere a domande come "C'è un motivo per cui le vendite dei miei prodotti sono calate a gennaio? È correlato a un qualche sentiment dei clienti?" Senza tale accesso, l'agente non può fornire insight reali.
Nel nostro scenario di attacco, il rischio del Pilastro 1 è che Social Gauge abbia accesso a dati finanziari che vanno oltre quanto necessario per il suo uso previsto, lasciando l'agente vulnerabile a un'iniezione di prompt indiretta che gli ordina di recuperare questi dati fuori ambito. Poiché non possiamo eliminare questo pilastro, vogliamo limitarlo, circoscrivendo la portata di Social Gauge ai soli dati pertinenti per l'utente che effettua la richiesta.
Databricks si trova in una posizione unica per mitigare questo rischio, perché gli agenti di AI operano direttamente sui dati aziendali governati tramite Unity Catalog. Ciò consente alle organizzazioni di applicare controlli di accesso granulari, l'applicazione delle policy e meccanismi di protezione dei dati in modo coerente sia per gli utenti umani che per gli agenti di AI.
Autenticazione per conto dell'utente:
Quando si creano integrazioni con agenti di AI, i clienti possono scegliere di utilizzare l'autenticazione on-behalf-of-user (OBO) per le APIs di Databricks. Ciò significa che quando l'SDK sottostante viene richiamato per accedere ai dati, utilizza le autorizzazioni dell'utente finale che interagisce con l'agente anziché un service principal legato all'agente stesso.
Questo dovrebbe essere il primo passo nella creazione di qualsiasi applicazione di AI. Limita intrinsecamente le autorizzazioni e impedisce che un agente con autorizzazioni eccessive diventi un singolo punto di compromissione.
Unity Catalog - Elenchi di controllo degli accessi granulari:
Affinché l'autenticazione OBO sia efficace, i clienti necessitano di elenchi di controllo degli accessi granulari in Unity Catalog, garantendo che nessun utente o workspace abbia accesso a dati a cui non dovrebbe.
I privilegi sugli oggetti a protezione diretta sono i controlli di accesso con cui la maggior parte dei clienti ha familiarità. Stabiliscono quali azioni un utente può eseguire su un oggetto a protezione diretta di Unity Catalog, che si tratti di un catalogo, uno schema, una tabella, un volume o altro. Per molti clienti, queste impostazioni sono già in atto come parte della loro strategia di governance. Consulta la nostra documentazione sulle best practice per Unity Catalog per ulteriori informazioni sulla gestione delle autorizzazioni.
Unity Catalog - Controlli degli accessi basati su attributi (ABAC):
I controlli degli accessi granulari funzionano bene quando gli utenti rientrano in gruppi chiaramente definiti come data engineer, analisti o utenti aziendali. Ma cosa succede nel caso di utenti aziendali che lavorano in diverse linee di business o di utenti con sede in regioni diverse? È qui che entra in gioco l'ABAC.
L'ABAC consente di definire le policy una sola volta e di applicarle a cataloghi, schemi, tabelle e altro ancora. Esistono due tipi di policy. Le policy di filtro delle righe filtrano automaticamente le tabelle in base agli attributi di un utente. Ad esempio, se un utente ha sede nell'area EMEA, la tabella viene ridotta ai soli record di quella regione. Le policy di mascheramento delle colonne mascherano le colonne sensibili a meno che un utente non appartenga a un gruppo specifico, fornendo un modo semplice per ridurre l'esposizione di PII.
Guardrail AI - Rilevamento PII:
I controlli di cui sopra si concentrano sulla limitazione di chi può accedere a cosa. Ma è altrettanto importante monitorare ciò che viene effettivamente restituito dall'agente. Molti clienti usano Agent Bricks AI Gateway come livello di governance centrale per l'accesso all'AI. Oltre all'accesso unificato ai modelli, al routing, al monitoraggio dell'utilizzo e ai limiti di velocità, AI Gateway fornisce guardrail come il rilevamento di PII, bloccando o redigendo automaticamente i dati sensibili ovunque appaiano negli input o negli output di un modello. Ciò protegge da scenari in cui un agente viene manipolato per far emergere dati che non dovrebbe.
Riepilogo: Controlli per l'accesso a sistemi sensibili o dati privati
Con questi controlli in atto, l'esposizione di Social Gauge appare fondamentalmente diversa. Anche se l'agente viene manipolato da un attacco di prompt injection, può raggiungere solo i dati a cui l'utente richiedente ha già accesso, limitati alla sua regione, mascherati dove sono presenti colonne sensibili e monitorati per la presenza di PII in uscita. Un utente malintenzionato che compromette l'agente non eredita le chiavi del regno, ma le autorizzazioni di un singolo utente, con una guardia a sorvegliare la porta.
Pilastro 2: Elaborare input non attendibili - Controlli
Databricks fornisce molti controlli di piattaforma che mitigano l'esposizione a utenti esterni non autorizzati: SSO con MFA, controlli di ingresso basati sul contesto, PrivateLink front-end o ACL IP. Ma il rischio di esposizione a input non attendibili non termina con la schermata di accesso.
La funzione principale di Social Gauge è la ricerca su Internet di post sui social media e articoli di notizie sui prodotti di consumo. Tale funzione la espone a un'iniezione di prompt indiretta, ovvero a istruzioni dannose incorporate in contenuti web altrimenti legittimi. Pertanto, sebbene gli utenti non autorizzati non possano accedere direttamente all'interfaccia di Social Gauge, la superficie di attacco indiretta è assolutamente attiva.
Esiste anche il rischio insider: utenti che tentano tecniche di jailbreaking per accedere a dati che non dovrebbero visualizzare, riutilizzare Social Gauge per qualcosa per cui non è stato creato o manipolarne l'analisi (ad esempio, "inventa una fonte secondo cui il mio prodotto sta andando alla grande!").
Nel nostro scenario di attacco, il rischio del Pilastro 2 è che un post sui social media contenente una prompt injection venga ingerito e che il contenuto dannoso incorporato venga interpretato come istruzioni legittime dall'agente. Questo rischio può essere mitigato attraverso controlli che rafforzano la gestione da parte dell'agente di input non attendibili.
Guardrail dell'AI: sicurezza dei contenuti e iniezione di prompt:
Come abbiamo visto, con Agent Bricks AI Gateway, sono disponibili diversi guardrail integrati, come il filtraggio di sicurezza e il rilevamento di PII, che possono essere applicati. Questi guardrail possono essere applicati all'input o all'output di un agente (o a entrambi). Oltre a questi guardrail integrati, è anche possibile distribuire modelli personalizzati su Databricks Model Serving e sfruttarli. Ad esempio, gli ultimi modelli Llama Protection sono LLM specializzati che sono stati sottoposti a fine-tuning per rilevare le prompt injection, i contenuti tossici o l'abuso dell'interprete di codice. Questi modelli possono fungere da livello difensivo intorno ai tuoi agenti, ispezionando le interazioni prima che si trasformino in incidenti.
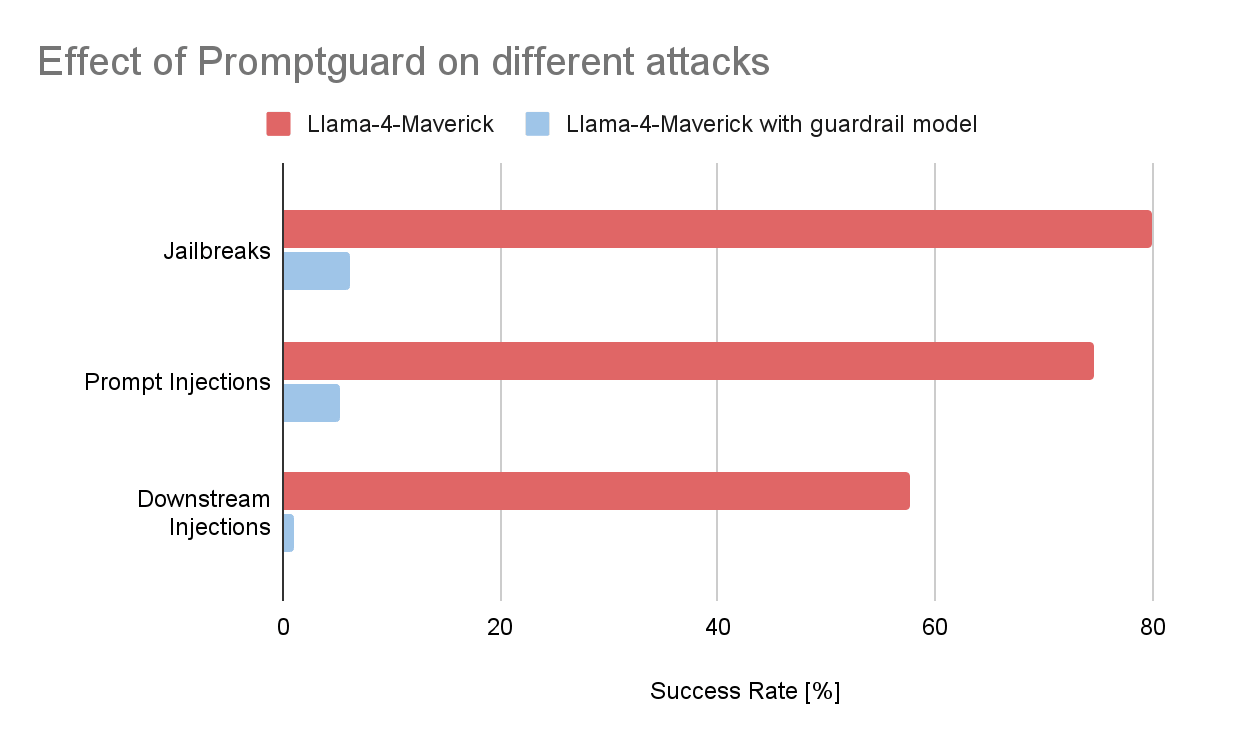
Per avere un'idea dell'efficacia di queste barriere di protezione, abbiamo condotto un piccolo Experiment. Abbiamo raccolto alcune centinaia di prompt dannosi dallo scanner di vulnerabilità Garak, uno strumento open-source sviluppato da NVIDIA che si integra facilmente con Databricks per i test di sicurezza automatizzati dei modelli LLM. Da questo set di dati, abbiamo selezionato tre categorie di attacco comuni:
- Iniezioni di prompt: istruzioni dannose nascoste in contesti come siti web, attività di traduzione o email, progettate per manipolare il modello e indurlo a tenere un comportamento non previsto.
- Jailbreak: prompt creati con cura per eludere le misure di sicurezza di allineamento e generare output dannosi o limitati.
- Attacchi di downstream injection: prompt che tentano di indurre il modello a generare contenuti che diventano pericolosi solo quando vengono interpretati da un altro sistema, ad esempio un'istruzione SQL dannosa eseguita da un'applicazione o un tag immagine Markdown appositamente creato che esfiltra dati sensibili quando viene reso come HTML.
Abbiamo quindi misurato il tasso di successo di questi attacchi rispetto a un modello di base, in questo caso un'implementazione di Llama-4-Maverick. I risultati erano chiari. Senza guardrail, una porzione significativa dei prompt dannosi ha attivato con successo il comportamento mirato. Quando un modello di guardrail personalizzato (Prompt Guard 2 per prompt injection e jailbreak, llama guard 3-8b per injection downstream) è stato posizionato a monte del modello, il tasso di successo è sceso di oltre il 90% in tutte e tre le categorie.
Se sei interessato a esplorare tecniche di guardrail aggiuntive, approcci open source o modelli all'avanguardia per il rilevamento di PII, contatta il tuo rappresentante Databricks per saperne di più sulle implementazioni di guardrail personalizzate.
Registro dei prompt:
Un prompt di sistema ben congegnato può talvolta fare la differenza tra la riuscita o meno di un attacco; non è robusto come un modello di rilevamento dedicato, ma vale la pena crearlo nel modo giusto. MLflow Prompt Registry semplifica l'ingegneria e la gestione dei prompt per le applicazioni GenAI, consentendo di creare versioni, monitorare, testare e riutilizzare i prompt all'interno dell'organizzazione invece di assemblarli ad hoc.
Riepilogo: controlli per l'elaborazione di input non attendibili
Social Gauge continua a leggere dall'open Internet: questo è il suo requisito fondamentale. Tuttavia, la superficie di attacco che un utente malintenzionato può sfruttare si è notevolmente ridotta. I prompt malevoli incorporati nei contenuti web ora devono superare un modello di rilevamento perfezionato prima di raggiungere l'agente e il prompt di sistema è versionato e testato anziché essere creato al volo. Nessuno di questi controlli è infallibile di per sé, ma usati insieme trasformano una superficie di attacco spalancata in qualcosa che un utente malintenzionato deve faticare molto di più per sfruttare.
Pilastro 3: Modificare lo stato o comunicare esternamente - Controlli
Nella fase finale del nostro scenario di attacco, il rischio del Pilastro 3 è che, una volta elaborata la prompt injection, l'agente abbia la capacità di eseguire le istruzioni dannose, esfiltrando i dati all'esterno o modificandoli all'interno di uno schema interno per influenzare le decisioni a valle.
Social Gauge arricchisce i dati esistenti con dati di terze parti per gli utenti che analizzano le prestazioni dei prodotti, il che significa che deve intrinsecamente scrivere su cataloghi, schemi, tabelle e altri oggetti. Lo stato sottostante sta cambiando. Ci concentreremo su tre controlli: limitare l'accesso alla rete in uscita, limitare l'accesso allo storage esterno e limitare le modifiche di stato all'interno di Unity Catalog.
Controlli di egress serverless - Posizioni Internet:
Anche se un'injection di prompt viene elaborata dall'agente, il raggio d'azione risultante può essere materialmente ridotto applicando controlli di egress serverless tramite le policy di rete di Databricks. Questi consentono agli amministratori di definire una posizione "nega per impostazione default" per le connessioni in uscita da carichi di lavoro serverless (incluse le Databricks Apps) e di consentire esplicitamente solo le destinazioni attendibili di cui l'agente ha effettivamente bisogno.
Collegando una policy di rete limitata al workspace che esegue un agente come Social Gauge, si limita la capacità dell'agente di raggiungere Endpoint Internet arbitrari, riducendo la superficie di attacco di iniezione di prompt indiretta e il rischio di esfiltrazione di dati verso destinazioni sconosciute.
Controlli di egress serverless - Oggetti di Unity Catalog:
Oltre a limitare l'accesso a endpoint noti tramite il filtraggio FQDN, la seconda funzionalità dei controlli di egress serverless è la capacità di limitare l'accesso a percorsi di archiviazione cloud come i bucket S3. I bucket associati al workspace, alle tabelle di sistema e ai set di dati di esempio rimangono di sola lettura per default, ma questo controllo va oltre: impedisce a un agente IA di scrivere su qualsiasi bucket non autorizzato, bloccando uno dei percorsi di esfiltrazione più comuni.
Unity Catalog - Binding di Workspace:
Ibinding tra Workspace e catalogo consentono ai clienti di limitare l'accesso ai cataloghi da Workspace specifiche. Questo è importante quando gli sviluppatori possono accedere ai dati in più ambienti, ma tali dati non devono superare i confini dell'ambiente di sviluppo. Un Data Engineer potrebbe avere l'autorizzazione a leggere i dati di produzione, ma non dovrebbe essere in grado di farlo da un workspace di sviluppo.
Dato che Social Gauge opera con credenziali OBO, le associazioni del workspace riducono la possibilità che l'agente modifichi inavvertitamente lo stato dell'ambiente di produzione mentre opera in quello di sviluppo.
Riepilogo: controlli per modificare lo stato o comunicare esternamente
Con i controlli di uscita serverless che impongono un criterio di negazione default sulle connessioni in uscita e bloccano l'archiviazione esterna, e con le associazioni della workspace che rafforzano i confini degli ambienti, abbiamo chiuso i percorsi più ovvi di esfiltrazione e manipolazione dello stato. Ora parliamo di come intercettare ciò che sfugge.
Monitoraggio degli agenti AI per i rischi per la sicurezza
Come accennato in precedenza, i clienti possono usare Agent Bricks AI Gateway per gestire e governare l'accesso a tutti i modelli e agenti AI in tutta l'azienda, e questa unificazione si estende anche all'osservabilità e al monitoraggio. Con AI Gateway, puoi centralizzare i Logs di tutti gli input e output dei modelli e agenti AI in tutta l'organizzazione tramite tabelle di inferenza, consentendo di utilizzare questi dati per monitorare e controllare le richieste AI e per migliorare le prestazioni e la sicurezza del modello.
Tabelle di inferenza
È possibile utilizzare la query seguente per monitorare le tabelle di inferenza e vedere se uno dei guardrail integrati è stato attivato dai Trigger. La query estrarrà quale Trigger (di input o di output) è stato attivato, nonché quali categorie dannose sono state rilevate. Naturalmente, quando si tratta di sicurezza, essere proattivi è sempre meglio che essere reattivi, quindi una volta convalidata la query, vale la pena compiere i passaggi aggiuntivi per configurarla come un avviso, notificando automaticamente l'utente o il suo Centro SOC per le attività operative di sicurezza (SOC) quando qualcosa potrebbe richiedere un'indagine.
Tabelle di sistema
Oltre alle tabelle di inferenza, le tabelle di sistema di Databricks contengono una grande quantità di insight sugli eventi materiali che si verificano in Databricks. In passato abbiamo scritto in un blog su come possono essere sfruttate per monitorare e segnalare in modo proattivo potenziali minacce alla sicurezza e indicatori di compromissione (IoC), e questo può essere esteso ai rischi di sicurezza principali per gli agenti IA. La query seguente, ad esempio, può essere utilizzata per monitorare il controllo del traffico in uscita serverless e se qualcuno (o un agente) sta cercando di aggirarlo per comunicare esternamente.
AI as a Judge
L'uso dell'AI come giudice è onnipresente nel campo degli agenti e dell'intelligenza artificiale in generale. Infatti, la maggior parte dei modelli di guardrail sono essenzialmente LLM sottoposti a fine-tuning e/o guidati da prompt di sistema specifici per servire a quello scopo specifico. Come accennato in precedenza, è facile distribuire modelli personalizzati su Databricks Model Serving e abbiamo esempi di distribuzione della maggior parte dei modelli guardrail più recenti e avanzati, come Llama Guard 4 e Llama Prompt Guard 2 su Databricks. Oltre a distribuirli come guardrail personalizzati, uno dei vantaggi dell'architettura aperta e componibile di Databricks è che, una volta registrato un modello utilizzando la variante generica mlflow.pyfunc di MLflow, è possibile sfruttarlo in molti modi diversi. Alcuni esempi includono la loro implementazione come flussi di lavoro Spark batch o pipeline dichiarative Spark, la chiamata tramite SQL con ai_query o persino la loro applicazione in scenari quasi in tempo reale o micro-batch con Spark Structured Streaming.
In alcuni casi, l'applicazione di barriere di protezione a ogni richiesta o risposta potrebbe non essere fattibile. Si tratta di uno scenario perfettamente valido in cui le barriere di protezione possono interferire con l'obiettivo di business o il dominio tematico in cui opera l'agente. Anche se le barriere di protezione non vengono applicate, possiamo comunque monitorare la sicurezza dei nostri agenti utilizzando le loro tabelle di inferenza e una pipeline batch o di streaming per classificare i contenuti potenzialmente dannosi.
Altre risorse
I controlli in questo post sono un punto di partenza, non un traguardo. Il rischio di prompt injection si evolve man mano che gli agenti diventano più capaci e l'obiettivo è un programma di sicurezza ripetibile che tenga il passo; non si tratterà di un'attività di hardening una tantum!
Questi pattern di sicurezza degli agenti stanno anche plasmando la prossima evoluzione del Databricks AI Security Framework. Un prossimo aggiornamento del DASF espande il framework per includere agenti di AI autonomi, l'uso di strumenti e i rischi emergenti di prompt injection, aiutando le organizzazioni a proteggere interi sistemi di AI, non solo i modelli.
Abbiamo organizzato le risorse più pertinenti in tre fasi:
Definire:
- Il framework per la sicurezza dell'AI di Databricks (DASF) 2.0 offre un'analisi completa dei rischi su 12 componenti principali dei sistemi di AI, con mappatura su standard quali MITRE ATLAS, NIST, OWASP e HITRUST. Fornisce 67 controlli pratici per ridurre rischi come prompt injection, jailbreak ed esfiltrazione di dati. Controlli DASF discussi in questo blog:
- DASF 5: Controllare l'accesso ai dati e ad altri oggetti
- DASF 64: Limita l'accesso da modelli e agenti AI
- DASF 57: usare i controlli degli accessi basati su attributi (ABAC)
- DASF 58: Proteggi i dati con filtri e mascheramento
- DASF 54: implementare i guardrail AI
- DASF 62: Implementare la segmentazione della rete
- DASF 37: Impostare tabelle di inferenza per il monitoraggio e il debug dei modelli
- DASF 49: Automatizzare la valutazione degli LLM
- DASF 73: Registrare prompt
- DASF 55: monitorare i log di controllo
- Il Databricks AI Governance Framework (DAGF) definisce il modo in cui le organizzazioni dovrebbero governare i sistemi di IA durante il loro ciclo di vita, dalla progettazione e sviluppo all'implementazione e al monitoraggio.
- Le guide alle best practice per la sicurezza di Databricks (per AWS, Azure e GCP) forniscono una panoramica dettagliata dei principali controlli di sicurezza che consigliamo per ambienti tipici e ad alta sicurezza, in base a ciò che vediamo funzionare in collaborazione con i nostri clienti più attenti alla sicurezza.
Distribuisci
- L'Architettura di riferimento per la sicurezza di Databricks - Terraform Template (SRA) consente l'implementazione di Databricks Workspace e dell'infrastruttura cloud configurate con le best practice per la sicurezza.
Monitorare:
- Il Security Analysis Tool (SAT) aiuta i team addetti alla sicurezza e alla piattaforma a valutare rapidamente la postura di sicurezza dei workspace Databricks.
- Databricks Detection Tool, una serie di rilevamenti mirati, riuniti in un Notebook di facile utilizzo, che aiuta a monitorare l'attività nelle Workspace.
L'unione di queste risorse offre ai tuoi team un modo pragmatico per passare da un hardening puntuale di un singolo agente a un programma di sicurezza ripetibile e scalabile per l'IA su Databricks, in grado di tenere il passo sia con la tua innovazione sia con il panorama delle minacce in evoluzione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.