Il nuovo modo per creare pipeline su Databricks: presentazione dell'IDE per l'ingegneria dei dati
Una nuova esperienza di sviluppo creata appositamente per la creazione di pipeline dichiarative Spark Lakeflow
di Adriana Ispas, Lennart Kats, Camiel Steenstra e Monica Alvarez Vicente
- Le pipeline dichiarative Spark dispongono ora di un'esperienza IDE dedicata nell'area di lavoro Databricks.
- Il nuovo IDE migliora la produttività e il debug con funzionalità come grafici delle dipendenze, anteprime e insight sull'esecuzione.
- L'IDE supporta sia l'onboarding rapido che i casi d'uso avanzati come l'integrazione Git, CI/CD e l'osservabilità.
Al Data + AI Summit di quest'anno, abbiamo presentato l'IDE per l'Ingegneria dei Dati: una nuova esperienza per sviluppatori creata appositamente per la scrittura di pipeline di dati direttamente all'interno di Databricks Workspace. Come nuova esperienza di sviluppo predefinita, l'IDE riflette il nostro approccio deciso all'ingegneria dei dati: dichiarativo per impostazione predefinita, modulare nella struttura, integrato con Git e assistito dall'IA.
In breve, l'IDE per l'Ingegneria dei Dati è tutto ciò di cui hai bisogno per scrivere e testare pipeline di dati, tutto in un unico posto.
Con questa nuova esperienza di sviluppo disponibile in Anteprima Pubblica, vorremmo utilizzare questo blog per spiegare perché le pipeline dichiarative beneficiano di un'esperienza IDE dedicata ed evidenziare le funzionalità chiave che rendono lo sviluppo delle pipeline più veloce, organizzato e facile da debuggare.
L'ingegneria dei dati dichiarativa ottiene un'esperienza sviluppatore dedicata
Le pipeline dichiarative semplificano l'ingegneria dei dati permettendoti di dichiarare cosa vuoi ottenere invece di scrivere istruzioni dettagliate passo dopo passo su come costruirla. Sebbene la programmazione dichiarativa sia un approccio estremamente potente per la creazione di pipeline di dati, lavorare con dataset multipli e gestire l'intero ciclo di vita dello sviluppo può diventare difficile da gestire senza strumenti dedicati.
Ecco perché abbiamo creato un'esperienza IDE completa per le pipeline dichiarative direttamente in Databricks Workspace. Disponibile come nuovo editor per Lakeflow Spark Declarative Pipelines, ti consente di dichiarare dataset e vincoli di qualità nei file, organizzarli in cartelle e visualizzare le connessioni tramite un grafo di dipendenze generato automaticamente visualizzato accanto al tuo codice. L'editor valuta i tuoi file per determinare il piano di esecuzione più efficiente e ti consente di iterare rapidamente rieseguendo singoli file, un set di dataset modificati o l'intera pipeline.
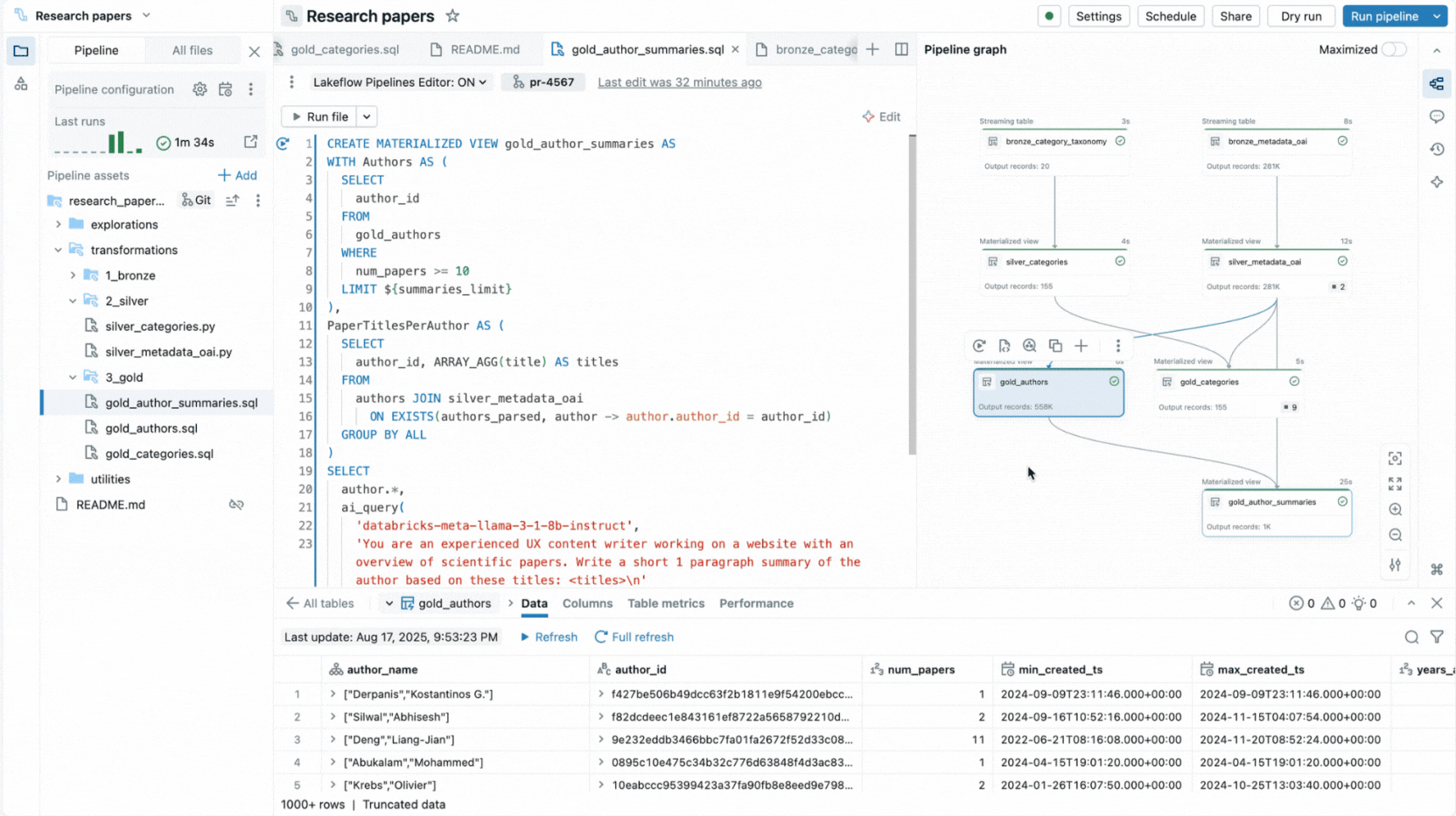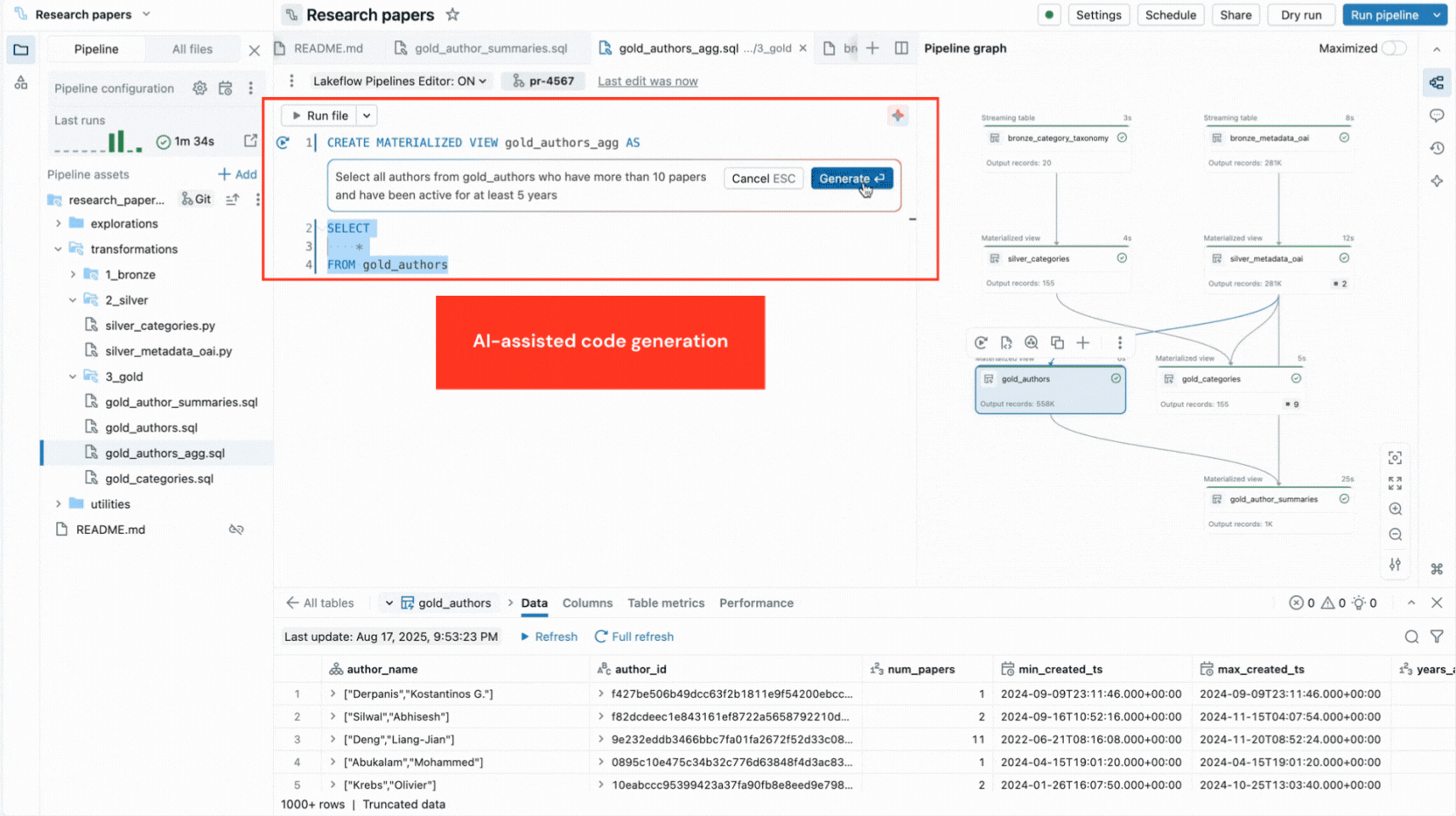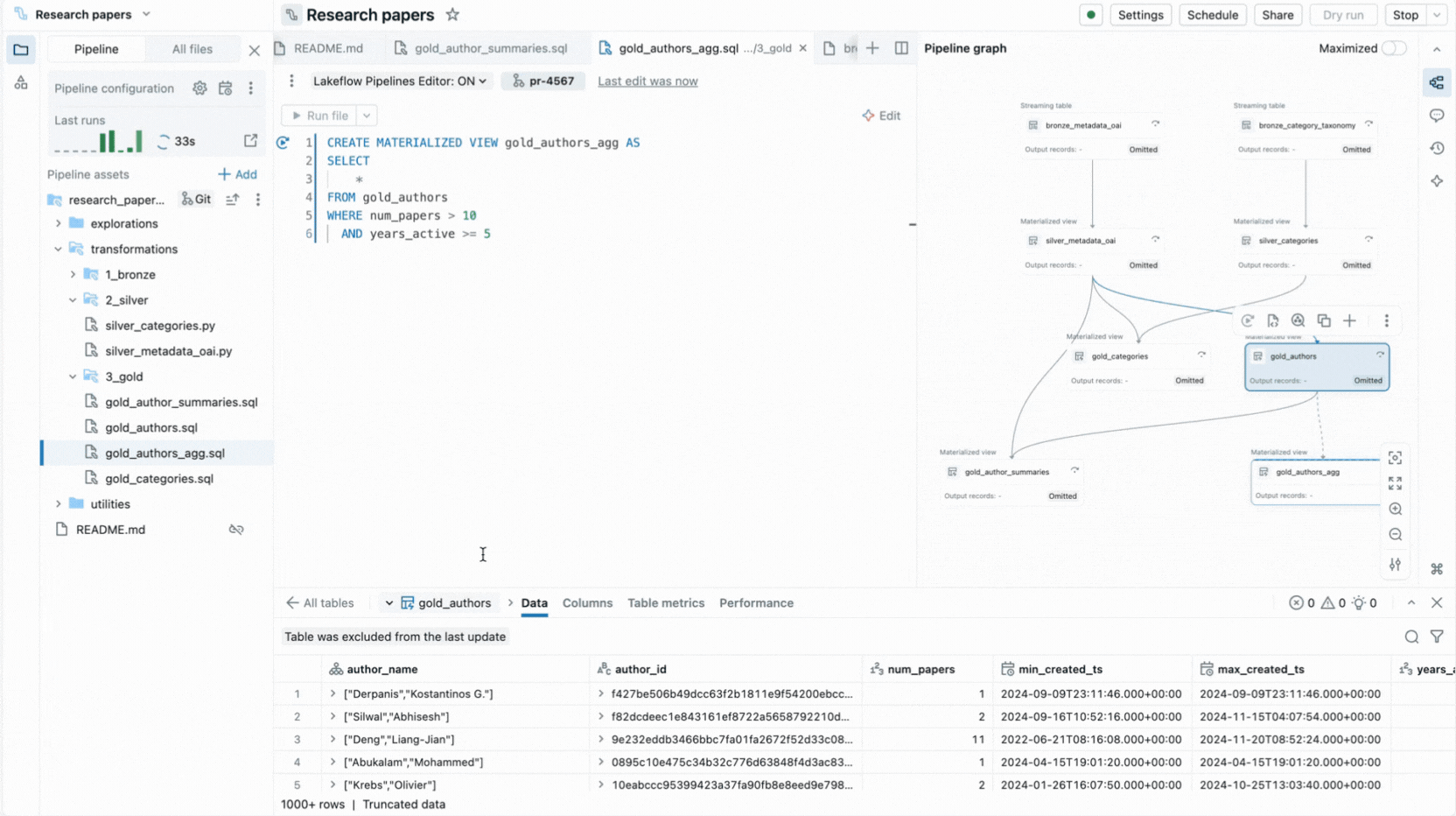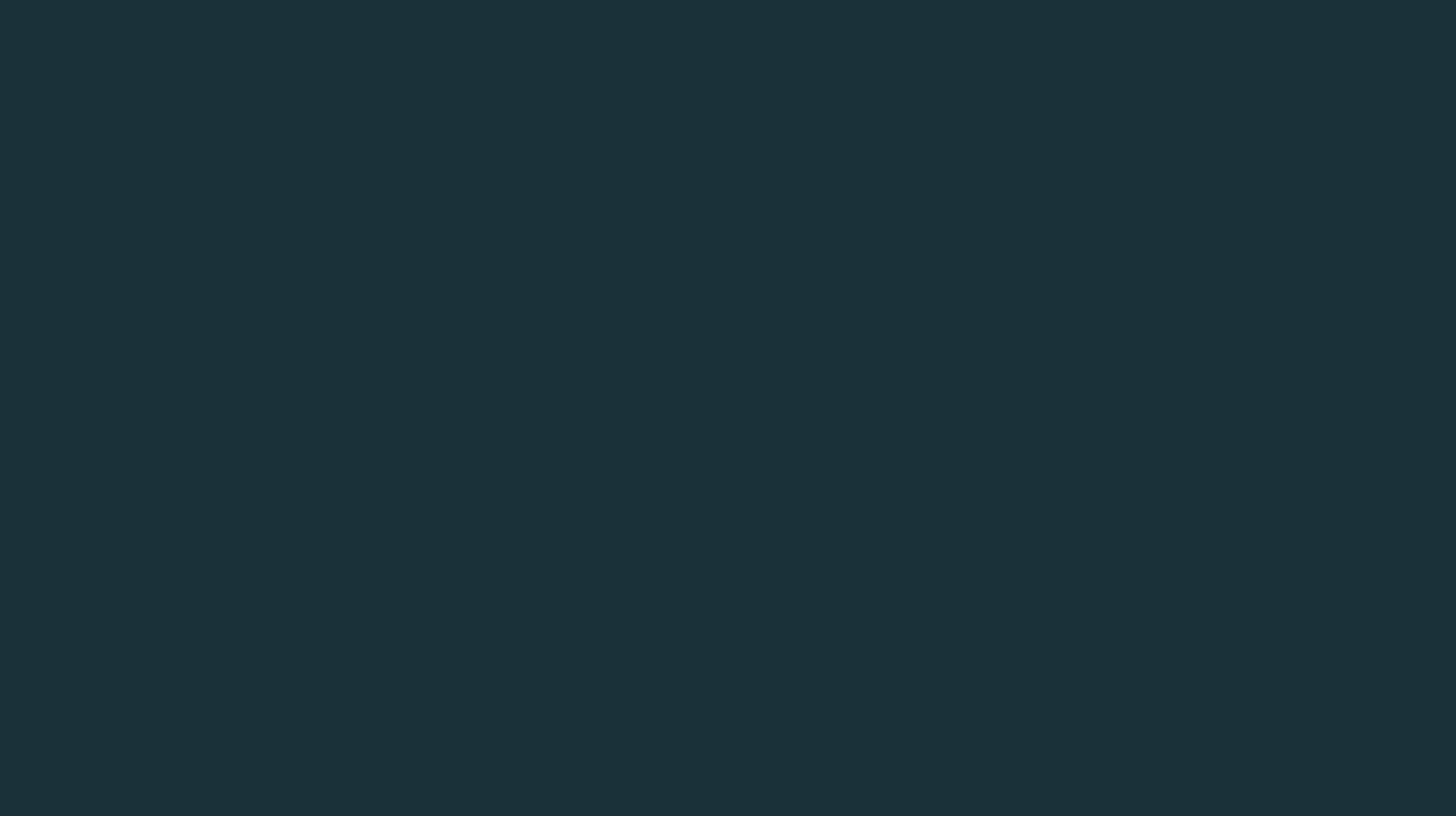
L'editor fornisce anche insight sull'esecuzione, anteprime dei dati integrate e include strumenti di debug per aiutarti a ottimizzare il tuo codice. Si integra inoltre con il controllo di versione e l'esecuzione pianificata con Lakeflow Jobs. Pertanto, puoi eseguire tutte le attività relative alla tua pipeline da un'unica interfaccia.
Consolidando tutte queste funzionalità in un'unica interfaccia simile a un IDE, l'editor abilita le pratiche e la produttività che gli ingegneri dei dati si aspettano da un IDE moderno, pur rimanendo fedele al paradigma dichiarativo.
Il video incorporato di seguito mostra queste funzionalità in azione, con ulteriori dettagli trattati nelle sezioni seguenti.
"Il nuovo editor riunisce tutto in un unico posto: codice, grafo della pipeline, risultati, configurazione e troubleshooting. Niente più salti tra schede del browser o perdita di contesto. Lo sviluppo risulta più focalizzato ed efficiente. Posso vedere direttamente l'impatto di ogni modifica al codice. Un clic mi porta alla riga di errore esatta, il che rende il debug più veloce. Tutto è collegato: codice ai dati; codice alle tabelle; tabelle al codice. Passare da una pipeline all'altra è facile e funzionalità come le cartelle di utilità auto-configurate rimuovono la complessità. Questo è il modo in cui dovrebbe funzionare lo sviluppo delle pipeline."—Chris Sharratt, Data Engineer, Rolls-Royce
"Secondo me, il nuovo Editor Pipeline è un enorme miglioramento. Trovo molto più facile gestire strutture di cartelle complesse e passare da un file all'altro grazie all'esperienza multi-scheda. La vista DAG integrata mi aiuta davvero a tenere sotto controllo pipeline intricate e la gestione avanzata degli errori è rivoluzionaria: mi aiuta a individuare rapidamente i problemi e semplifica il mio flusso di lavoro di sviluppo."—Matt Adams, Senior Data Platforms Developer, PacificSource Health Plans
Facilità di avvio
Abbiamo progettato l'editor in modo che anche gli utenti nuovi al paradigma dichiarativo possano creare rapidamente la loro prima pipeline.
- Configurazione guidata consente ai nuovi utenti di iniziare con codice di esempio, mentre gli utenti esistenti possono configurare impostazioni avanzate, come pipeline con CI/CD integrato tramite Databricks Asset Bundles.
- Strutture di cartelle suggerite forniscono un punto di partenza per organizzare gli asset senza imporre convenzioni rigide, in modo che i team possano anche implementare i propri schemi organizzativi consolidati. Ad esempio, puoi raggruppare le trasformazioni in cartelle per ogni fase del Medallion, con un dataset per file.
- Impostazioni predefinite consentono agli utenti di scrivere ed eseguire il loro primo codice senza un pesante overhead di configurazione iniziale e di regolare le impostazioni in seguito, una volta definito il loro carico di lavoro end-to-end.
Queste funzionalità aiutano gli utenti a diventare rapidamente produttivi e a trasformare il loro lavoro in pipeline pronte per la produzione.
Efficienza nel ciclo di sviluppo interno
La creazione di pipeline è un processo iterativo. L'editor semplifica questo processo con funzionalità che facilitano la scrittura e rendono più veloce il test e l'affinamento della logica:
- Generazione di codice basata sull'IA e modelli di codice velocizzano le definizioni dei dataset e i vincoli di qualità dei dati, ed eliminano i passaggi ripetitivi.
- Esecuzione selettiva ti consente di eseguire una singola tabella, tutte le tabelle in un file o l'intera pipeline.
- Grafo di pipeline interattivo fornisce una panoramica delle dipendenze dei dataset e offre azioni rapide come anteprime dei dati, riesecuzioni, navigazione al codice o aggiunta di nuovi dataset con boilerplate generato automaticamente.
- Anteprime dei dati integrate ti consentono di ispezionare i dati delle tabelle senza lasciare l'editor.
- Errori contestuali appaiono accanto al codice pertinente, con correzioni suggerite da Databricks Assistant.
- Pannelli di insight sull'esecuzione visualizzano metriche dei dataset, aspettative, prestazioni delle query, con accesso ai profili delle query per l'ottimizzazione delle prestazioni.
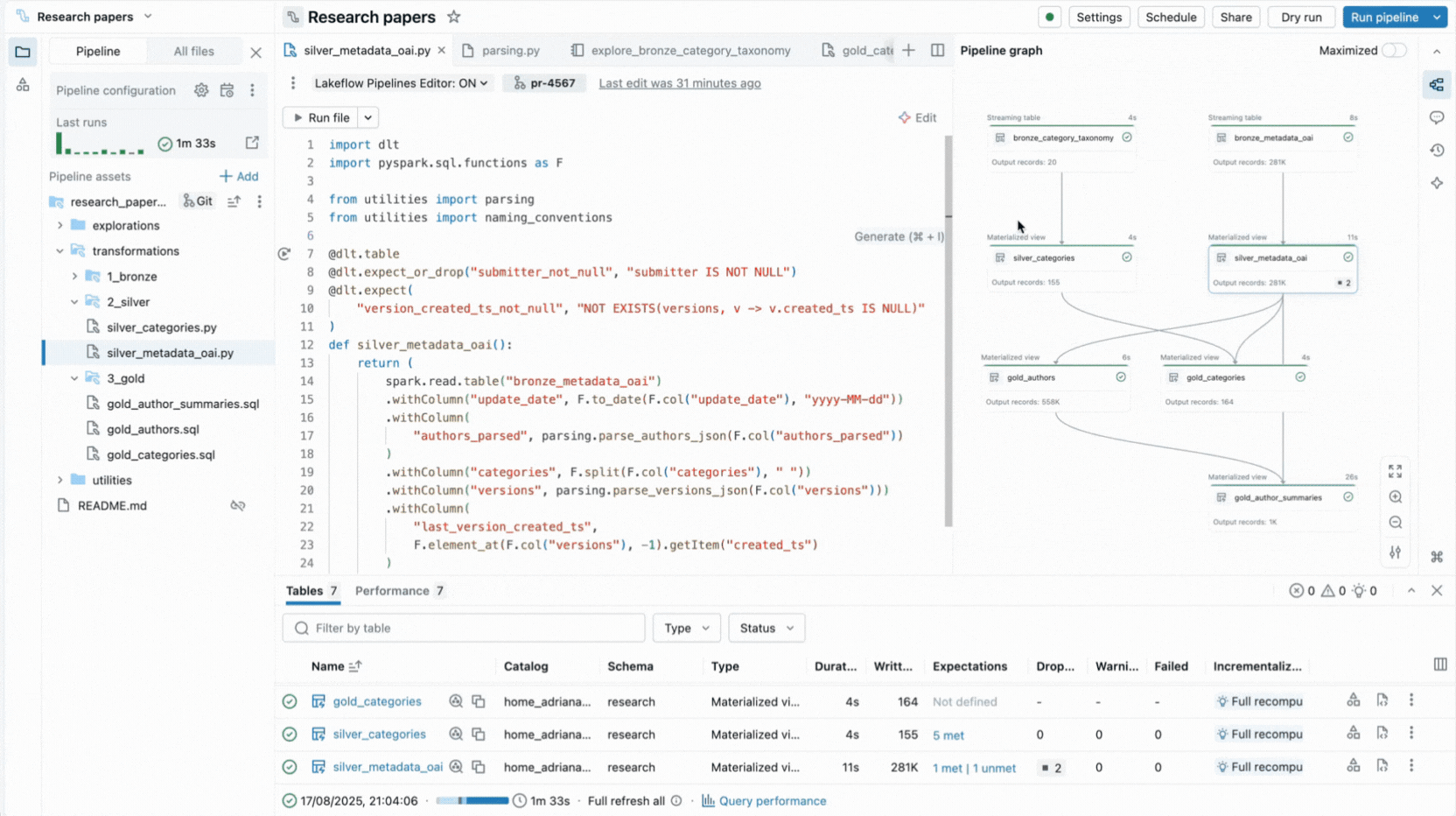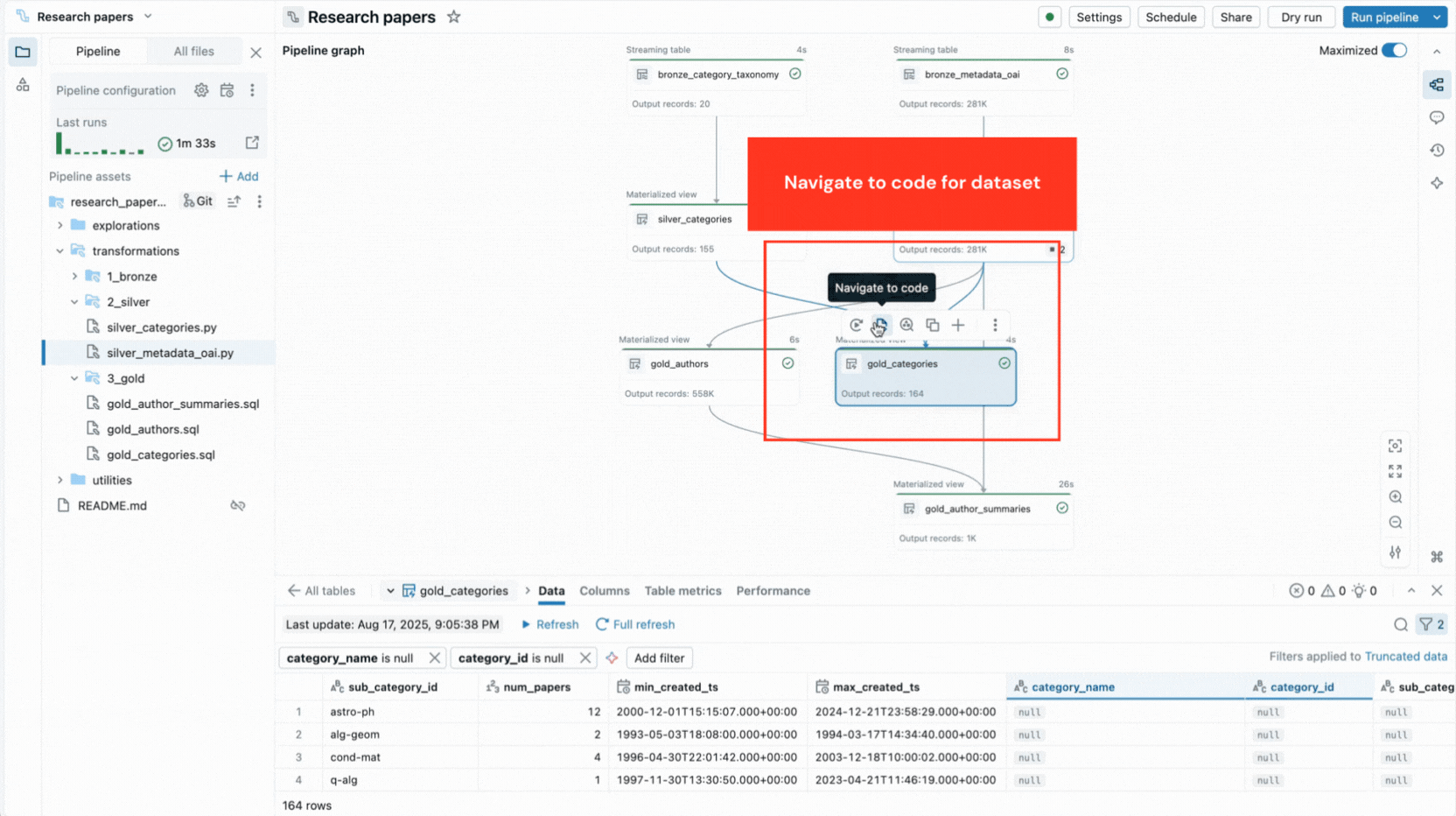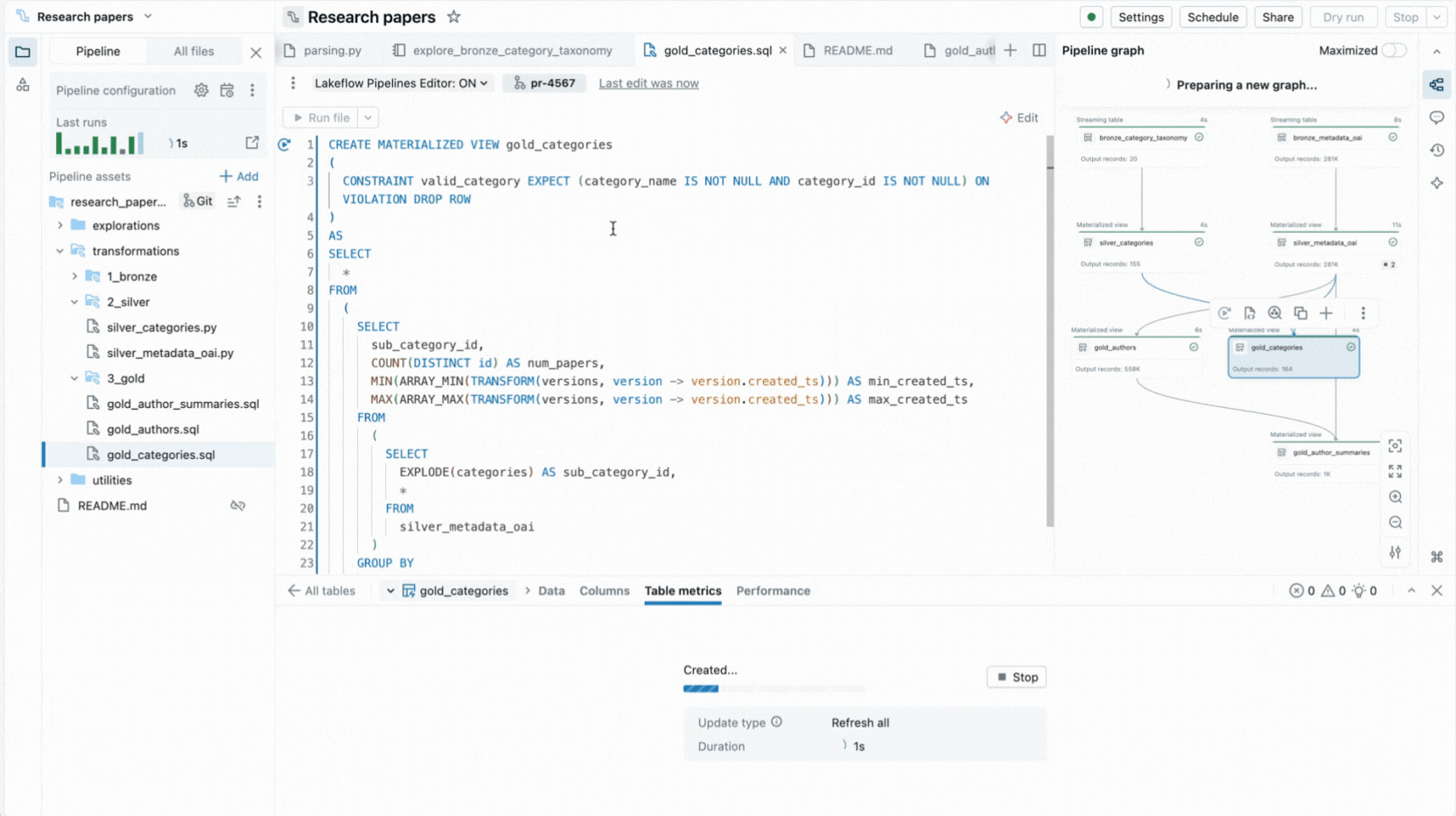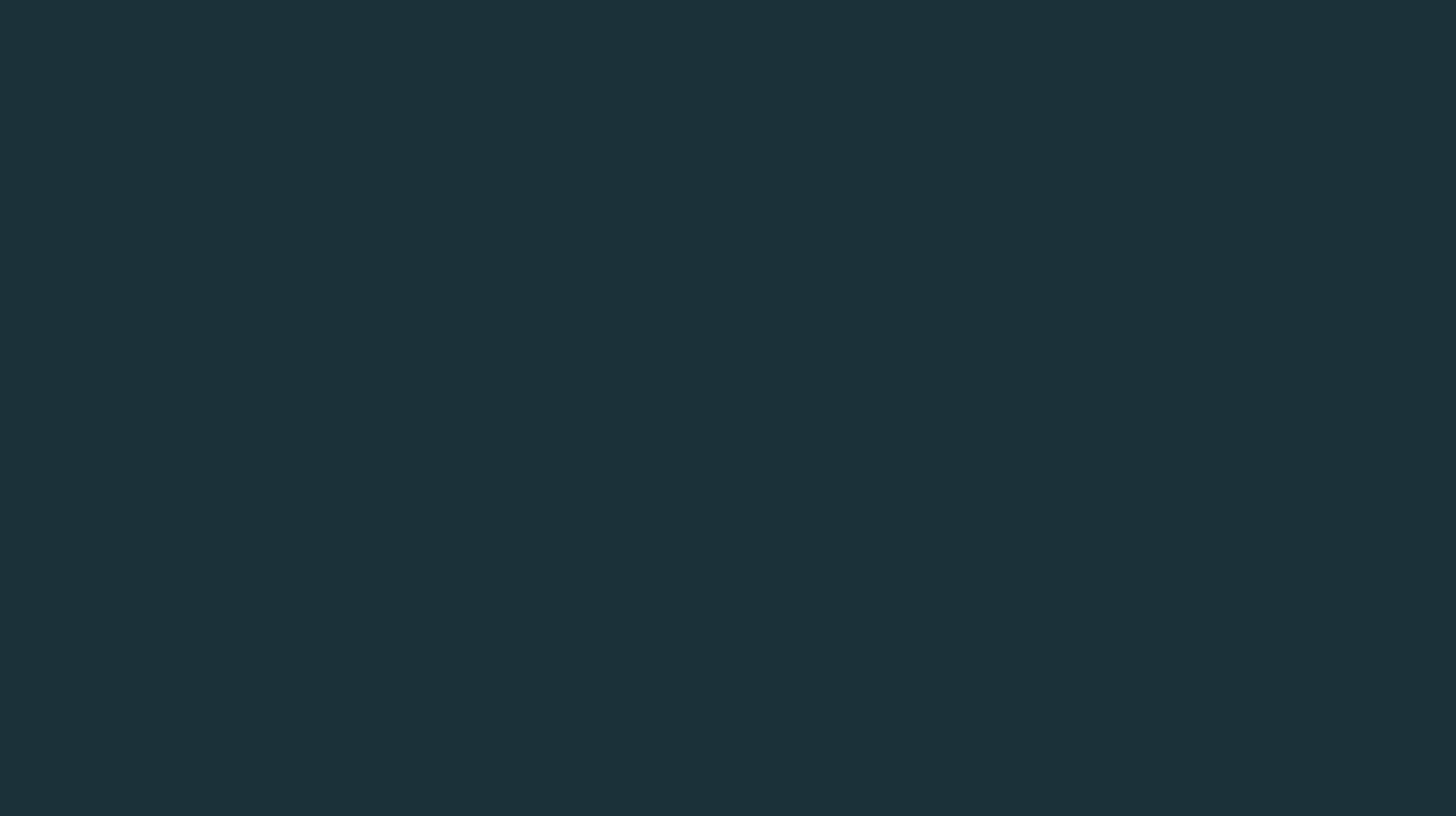
Queste funzionalità riducono il cambio di contesto e mantengono gli sviluppatori concentrati sulla creazione della logica della pipeline.
Un'unica interfaccia per tutte le attività
Lo sviluppo di pipeline comporta più della semplice scrittura di codice. La nuova esperienza per sviluppatori porta tutte le attività correlate su un'unica interfaccia, dalla modularizzazione del codice per la manutenibilità all'impostazione dell'automazione e dell'osservabilità:
- Organizza codice adiacente, come notebook esplorativi o moduli Python riutilizzabili, in cartelle dedicate, modifica file in schede multiple ed eseguili separatamente dalla logica della pipeline. Questo mantiene il codice correlato facilmente reperibile e la tua pipeline ordinata.
- Controllo di versione integrato tramite cartelle Git consente un lavoro sicuro e isolato, revisioni del codice e pull request verso repository condivisi.
- CI/CD con supporto Databricks Asset Bundles per le pipeline collega lo sviluppo del ciclo interno al deployment. Gli amministratori dei dati possono imporre test e automatizzare la promozione in produzione utilizzando modelli e file di configurazione, il tutto senza aggiungere complessità al flusso di lavoro di un data practitioner.
- Automazione e osservabilità integrate consentono l'esecuzione pianificata delle pipeline e forniscono un rapido accesso alle esecuzioni passate per il monitoraggio e il troubleshooting.
Unificando queste funzionalità, l'editor semplifica sia lo sviluppo quotidiano che le operazioni a lungo termine delle pipeline.
Dai un'occhiata al video qui sotto per maggiori dettagli su tutte queste funzionalità in azione.
Cosa c'è di nuovo
Non ci fermiamo qui. Ecco un'anteprima di ciò che stiamo esplorando attualmente:
- Supporto nativo per i test dei dati in Lakeflow Spark Declarative Pipelines e test runner nell'editor
- Generazione di test assistita dall'IA per velocizzare la validazione
- Esperienza agentiva per Lakeflow Spark Declarative Pipelines.
Facci sapere cos'altro vorresti vedere: il tuo feedback guida ciò che costruiamo.
Inizia oggi stesso con la nuova esperienza per sviluppatori
L'IDE per l'ingegneria dei dati è disponibile in tutti i cloud. Per abilitarlo, apri un file associato a una pipeline esistente, fai clic sul banner ‘Lakeflow Pipelines Editor: OFF’ e attivalo. Puoi anche abilitarlo durante la creazione della pipeline con un interruttore simile, o dalla pagina Impostazioni utente.
Scopri di più utilizzando queste risorse:
- Dai un'occhiata alla documentazione.
- Guarda la presentazione Authoring Data Pipelines With the New Editor al Data + AI Summit 2025.
- Dai un'occhiata a Lakeflow in Production: CI/CD, Testing and Monitoring at Scale al Data + AI Summit 2025.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.