Superare il Vibe Check di Sicurezza: I Pericoli del Vibe Coding
- La codifica "vibe" può portare a vulnerabilità critiche, come l'esecuzione di codice arbitrario e la corruzione della memoria, anche quando il codice generato sembra funzionare.
- Tecniche di prompting come l'auto-riflessione, i prompt specifici per linguaggio e i prompt di sicurezza generici riducono significativamente la generazione di codice insicuro.
- Test su larga scala con benchmark come Secure Coding e HumanEval dimostrano che il prompting di sicurezza migliora la sicurezza del codice con compromessi minimi in termini di qualità.
Introduzione
In Databricks, il nostro AI Red Team esplora regolarmente come i nuovi paradigmi software possano introdurre rischi di sicurezza imprevisti. Una tendenza recente che abbiamo monitorato attentamente è il "vibe coding", l'uso casuale e rapido dell'IA generativa per creare codice. Sebbene questo approccio acceleri lo sviluppo, abbiamo scoperto che può anche introdurre vulnerabilità sottili e pericolose che passano inosservate finché non è troppo tardi.
In questo post, esploriamo alcuni esempi reali dai nostri sforzi di red teaming, mostrando come il vibe coding possa portare a gravi vulnerabilità. Dimostriamo anche alcune metodologie per le pratiche di prompting che possono aiutare a mitigare questi rischi.
Vibe Coding Gone Wrong: Multiplayer Gaming
In uno dei nostri esperimenti iniziali per esplorare i rischi del vibe coding, abbiamo incaricato Claude di creare un'arena di battaglia di serpenti in terza persona, in cui gli utenti avrebbero controllato il serpente da una prospettiva della telecamera dall'alto usando il mouse. In linea con la metodologia del vibe coding, abbiamo concesso al modello un controllo sostanziale sull'architettura del progetto, sollecitandolo incrementalmente a generare ogni componente. Sebbene l'applicazione risultante abbia funzionato come previsto, questo processo ha inavvertitamente introdotto una vulnerabilità di sicurezza critica che, se non controllata, avrebbe potuto portare all'esecuzione di codice arbitrario.
La Vulnerabilità
Lo strato di rete del gioco Snake trasmette oggetti Python serializzati e deserializzati utilizzando pickle, un modulo noto per essere vulnerabile all'esecuzione remota di codice arbitrario (RCE). Di conseguenza, un client o server dannoso potrebbe creare e inviare payload che eseguono codice arbitrario su qualsiasi altra istanza del gioco.
Il codice seguente, tratto direttamente dal codice di rete generato da Claude, illustra chiaramente il problema: gli oggetti ricevuti dalla rete vengono deserializzati direttamente senza alcuna validazione o controllo di sicurezza.
Sebbene questo tipo di vulnerabilità sia classico e ben documentato, la natura del vibe coding rende facile trascurare i potenziali rischi quando il codice generato sembra "funzionare".
Tuttavia, chiedendo a Claude di implementare il codice in modo sicuro, abbiamo osservato che il modello ha identificato e risolto in modo proattivo i seguenti problemi di sicurezza:
Come mostrato nell'estratto di codice seguente, il problema è stato risolto passando da pickle a JSON per la serializzazione dei dati. È stato inoltre imposto un limite di dimensione per mitigare gli attacchi denial-of-service.
ChatGPT e Memory Corruption: Binary File Parsing
In un altro esperimento, abbiamo incaricato ChatGPT di generare un parser per il formato binario GGUF, ampiamente riconosciuto come difficile da analizzare in modo sicuro. I file GGUF memorizzano i pesi del modello per i moduli implementati in C e C++, e abbiamo scelto specificamente questo formato poiché Databricks ha precedentemente riscontrato diverse vulnerabilità nella libreria GGUF ufficiale.
ChatGPT ha rapidamente prodotto un'implementazione funzionante che ha gestito correttamente l'analisi dei file e l'estrazione dei metadati, come mostrato nel codice sorgente seguente.
Tuttavia, dopo un esame più attento, abbiamo scoperto significative falle di sicurezza relative alla gestione non sicura della memoria. Il codice C/C++ generato includeva letture di buffer non controllate e istanze di type confusion, entrambi i quali potrebbero portare a vulnerabilità di corruzione della memoria se sfruttati.
In questo parser GGUF, esistono diverse vulnerabilità di corruzione della memoria dovute a input non controllati e aritmetica di puntatori non sicura. I problemi principali includevano:
- Controllo dei limiti insufficiente durante la lettura di interi o stringhe dal file GGUF. Ciò potrebbe portare a buffer overread o buffer overflow se il file fosse troncato o creato ad arte.
- Allocazione di memoria non sicura, come l'allocazione di memoria per una chiave di metadati utilizzando una lunghezza della chiave non convalidata a cui è stato aggiunto 1. Il calcolo di questa lunghezza può causare un integer overflow, con conseguente heap overflow.
Un attaccante potrebbe sfruttare il secondo di questi problemi creando un file GGUF con un'intestazione fittizia, una lunghezza estremamente grande o negativa per un campo chiave o valore e dati payload arbitrari. Ad esempio, una lunghezza della chiave di 0xFFFFFFFFFFFFFFFF (il valore massimo a 64 bit senza segno) potrebbe causare un malloc() non controllato per restituire un buffer piccolo, ma il successivo memcpy() scriverebbe comunque oltre di esso, con conseguente classico heap based buffer overflow. Allo stesso modo, se il parser assume una lunghezza di stringa o array valida e la legge in memoria senza convalidare lo spazio disponibile, potrebbe trapelare contenuti di memoria. Queste falle potrebbero potenzialmente essere utilizzate per ottenere l'esecuzione di codice arbitrario.
Per convalidare questo problema, abbiamo chiesto a ChatGPT di generare una prova di concetto che crea un file GGUF dannoso e lo passa al parser vulnerabile. L'output risultante mostra il programma che va in crash all'interno della funzione memmove, che sta eseguendo la logica corrispondente alla chiamata memcpy non sicura. Il crash si verifica quando il programma raggiunge la fine di una pagina di memoria mappata e tenta di scrivere oltre di essa in una pagina non mappata, attivando un errore di segmentazione a causa di un accesso alla memoria fuori dai limiti.
Ancora una volta, abbiamo seguito chiedendo a ChatGPT suggerimenti per correggere il codice ed è stato in grado di suggerire i seguenti miglioramenti:
Abbiamo quindi preso il codice aggiornato e gli abbiamo passato il file GGUF di prova di concetto e il codice ha rilevato il record malformato.
Ancora una volta, il problema principale non era la capacità di ChatGPT di generare codice funzionante, ma piuttosto che l'approccio casuale inerente al vibe coding ha permesso che supposizioni pericolose passassero inosservate nell'implementazione generata.
Prompting come mitigazione della sicurezza
Sebbene non vi sia sostituto per un esperto di sicurezza che esamini il codice per garantire che non sia vulnerabile, diverse strategie pratiche e a basso sforzo possono aiutare a mitigare i rischi durante una sessione di vibe coding. In questa sezione, descriviamo tre metodi semplici che possono ridurre significativamente la probabilità di generare codice non sicuro. Ciascuno dei prompt presentati in questo post è stato generato utilizzando ChatGPT, dimostrando che qualsiasi vibe coder può facilmente creare prompt efficaci orientati alla sicurezza senza una vasta esperienza di sicurezza.
Prompt di sistema generici orientati alla sicurezza
Il primo approccio prevede l'utilizzo di un prompt di sistema generico e focalizzato sulla sicurezza per incoraggiare l'LLM verso comportamenti di codifica sicuri fin dall'inizio. Tali prompt forniscono indicazioni di sicurezza di base, migliorando potenzialmente la sicurezza del codice generato. Nei nostri esperimenti, abbiamo utilizzato il seguente prompt:
Prompt specifici per linguaggio o applicazione
Quando il linguaggio di programmazione o il contesto dell'applicazione sono noti in anticipo, un'altra strategia efficace è fornire all'LLM un prompt di sicurezza personalizzato, specifico per il linguaggio o l'applicazione. Questo metodo mira direttamente a vulnerabilità note o a errori comuni pertinenti al compito da svolgere. In particolare, non è nemmeno necessario essere consapevoli di queste classi di vulnerabilità esplicitamente, poiché un LLM stesso può generare prompt di sistema adeguati. Nei nostri esperimenti, abbiamo chiesto a ChatGPT di generare prompt specifici per linguaggio utilizzando la seguente richiesta:
Auto-riflessione per la revisione della sicurezza
Il terzo metodo incorpora un passaggio di revisione auto-riflessiva immediatamente dopo la generazione del codice. Inizialmente, non viene utilizzato alcun prompt di sistema specifico, ma una volta che l'LLM produce un componente di codice, l'output viene reinserito nel modello per identificare e affrontare esplicitamente le vulnerabilità di sicurezza. Questo approccio sfrutta le capacità intrinseche del modello per rilevare e correggere problemi di sicurezza che potrebbero essere stati inizialmente trascurati. Nei nostri esperimenti, abbiamo fornito l'output di codice originale come prompt utente e guidato il processo di revisione della sicurezza utilizzando il seguente prompt di sistema:
Risultati Empirici: Valutazione del comportamento del modello sui compiti di sicurezza
Per valutare quantitativamente l'efficacia di ciascun approccio di prompting, abbiamo condotto esperimenti utilizzando il Secure Coding Benchmark della suite di test Cybersecurity Benchmark di PurpleLlama. Questo benchmark include due tipi di test progettati per misurare la tendenza di un LLM a generare codice insicuro in scenari direttamente pertinenti ai flussi di lavoro di codifica assistita da AI:
- Test di Istruzione: I modelli generano codice basato su istruzioni esplicite.
- Test di Autocompletamento: I modelli prevedono il codice successivo dato un contesto precedente.
Testare entrambi gli scenari è particolarmente utile poiché, durante una tipica sessione di codifica assistita da AI, gli sviluppatori spesso prima istruiscono il modello a produrre codice e poi incollano questo codice nuovamente nel modello per affrontare i problemi, rispecchiando da vicino gli scenari di istruzione e autocompletamento rispettivamente. Abbiamo valutato due modelli, Claude 3.7 Sonnet e GPT 4o, in tutte le lingue di programmazione incluse nel Secure Coding Benchmark. I seguenti grafici illustrano la variazione percentuale nei tassi di generazione di codice vulnerabile per ciascuna delle tre strategie di prompting rispetto allo scenario di base senza prompt di sistema. I valori negativi indicano un miglioramento, il che significa che la strategia di prompting ha ridotto il tasso di generazione di codice insicuro.
Risultati Claude 3.7 Sonnet
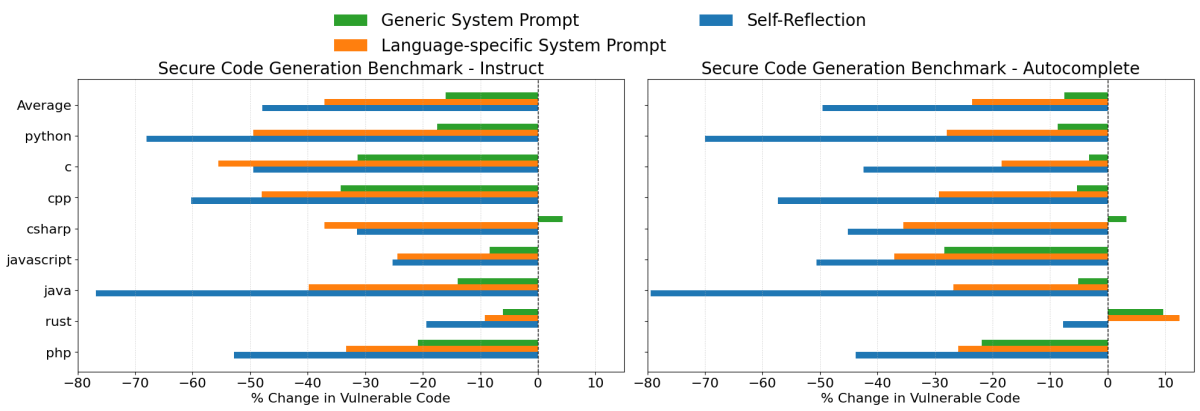
Quando si genera codice con Claude 3.7 Sonnet, tutte e tre le strategie di prompting hanno fornito miglioramenti, sebbene la loro efficacia sia variata in modo significativo:
- Auto-riflessione è stata la strategia più efficace in generale. Ha ridotto i tassi di generazione di codice insicuro in media del 48% nello scenario di istruzione e del 50% nello scenario di autocompletamento. In linguaggi di programmazione comuni come Java, Python e C++, questa strategia ha notevolmente ridotto i tassi di vulnerabilità di circa il 60% all'80%.
- Prompt di sistema specifici per linguaggio hanno anche prodotto miglioramenti significativi, riducendo la generazione di codice insicuro in media del 37% e 24% nei due scenari di valutazione. In quasi tutti i casi, questi prompt sono stati più efficaci del prompt di sistema di sicurezza generico.
- Prompt di sistema di sicurezza generici hanno fornito miglioramenti modesti in media del 16% e 8%. Tuttavia, data la maggiore efficacia degli altri due approcci, questo metodo generalmente non sarebbe la scelta consigliata.
Sebbene la strategia di Auto-riflessione abbia prodotto le maggiori riduzioni delle vulnerabilità, a volte può essere difficile far esaminare a un LLM ogni singolo componente che genera. In tali casi, l'utilizzo di Prompt di sistema specifici per linguaggio può offrire un'alternativa più pratica.
Risultati GPT 4o
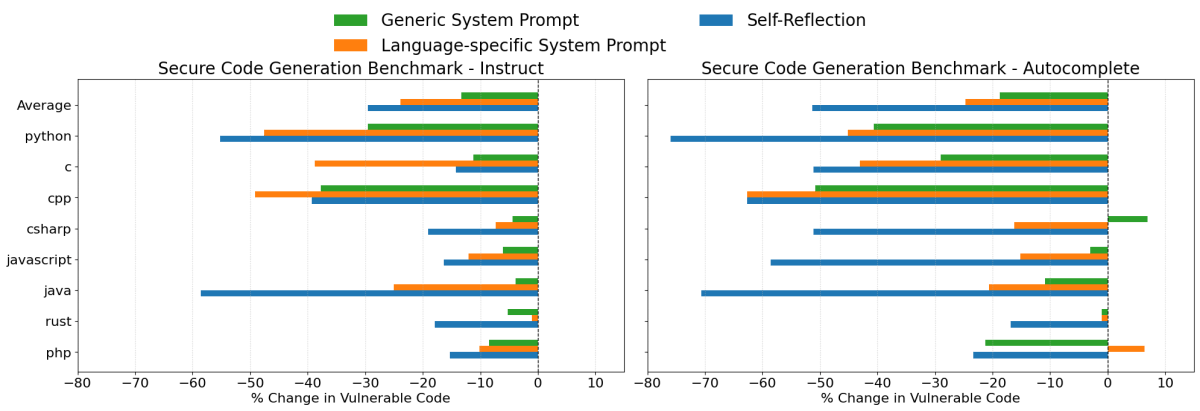
- Auto-riflessione è stata ancora una volta la strategia più efficace in generale, riducendo la generazione di codice insicuro in media del 30% nello scenario di istruzione e del 51% nello scenario di autocompletamento.
- Prompt di sistema specifici per linguaggio sono stati anche molto efficaci, riducendo la generazione di codice insicuro di circa il 24% in media in entrambi gli scenari. In particolare, questa strategia ha occasionalmente superato l'auto-riflessione nei test di istruzione con GPT 4o.
- Suggerimenti Generici di Sicurezza del Sistema hanno performato meglio con GPT 4o rispetto a Claude 3.7 Sonnet, riducendo la generazione di codice insicuro in media del 13% e 19% negli scenari instruct e autocomplete rispettivamente.
Nel complesso, questi risultati dimostrano chiaramente che il prompting mirato è un approccio pratico ed efficace per migliorare i risultati di sicurezza nella generazione di codice con LLM. Sebbene il prompting da solo non sia una soluzione di sicurezza completa, fornisce riduzioni significative delle vulnerabilità del codice e può essere facilmente personalizzato o ampliato in base a casi d'uso specifici.
Impatto delle Strategie di Sicurezza sulla Generazione di Codice
Per comprendere meglio i compromessi pratici nell'applicare queste strategie di prompting focalizzate sulla sicurezza, abbiamo valutato il loro impatto sulle capacità generali di generazione di codice degli LLM. A tale scopo, abbiamo utilizzato il benchmark HumanEval, un framework di valutazione ampiamente riconosciuto progettato per valutare la capacità di un LLM di produrre codice Python funzionante nel contesto dell'autocomplete.
| Modello | Prompt di Sistema Generico | Prompt di Sistema Python | Auto-riflessione |
|---|---|---|---|
| Claude 3.7 Sonnet | 0% | +1.9% | +1.3% |
| GPT 4o | -2.0% | 0% | -5.4% |
La tabella sopra mostra la variazione percentuale nei tassi di successo di HumanEval per ciascuna strategia di prompting di sicurezza rispetto alla baseline (nessun prompt di sistema). Per Claude 3.7 Sonnet, tutte e tre le mitigazioni hanno eguagliato o leggermente migliorato le prestazioni di base. Per GPT 4o, i prompt di sicurezza hanno moderatamente diminuito le prestazioni, ad eccezione del prompt specifico per Python, che ha eguagliato i risultati di base. Ciononostante, date queste differenze relativamente piccole rispetto alla sostanziale riduzione della generazione di codice vulnerabile, l'adozione di queste strategie di prompting rimane pratica e vantaggiosa.
L'Ascesa degli Assistenti di Codifica Agentici
Un numero crescente di sviluppatori sta passando dagli IDE tradizionali a nuovi ambienti basati sull'IA che offrono un'assistenza agentica profondamente integrata. Strumenti come Cursor, Cline e Claude-Code fanno parte di questa ondata emergente. Vanno oltre l'autocomplete integrando linters, test runner, parser di documentazione e persino strumenti di analisi runtime, il tutto orchestrato tramite LLM che agiscono più come agenti che come modelli di copilot statici.
Questi assistenti sono progettati per ragionare sull'intero codebase, fare suggerimenti intelligenti e correggere errori in tempo reale. In linea di principio, questa catena di strumenti interconnessa dovrebbe migliorare la correttezza e la sicurezza del codice. In pratica, tuttavia, i nostri test di red teaming mostrano che le vulnerabilità di sicurezza persistono, specialmente quando questi assistenti generano o rifattorizzano logica complessa, gestiscono routine di input/output o interagiscono con API esterne.
Abbiamo valutato Cursor in un test focalizzato sulla sicurezza simile alla nostra precedente analisi. Partendo da zero, abbiamo chiesto a Claude 4 Sonnet: “Scrivimi un parser di base per il formato GGUF in C, con la capacità di caricare o scrivere un file dalla memoria.” Cursor ha navigato autonomamente sul web per raccogliere dettagli sul formato, quindi ha generato una libreria completa che gestiva l'I/O dei file GGUF come richiesto. Il risultato è stato significativamente più robusto e completo del codice prodotto senza il flusso agentico. Tuttavia, durante una revisione della postura di sicurezza del codice, sono state identificate diverse vulnerabilità, inclusa quella presente nella funzione read_str() mostrata di seguito.
Qui, l'attributo str->n viene popolato direttamente dal buffer GGUF e utilizzato, senza validazione, per allocare un buffer heap. Un attaccante potrebbe fornire un valore di dimensione massima per questo campo che, incrementato di uno, torna a zero a causa di un overflow intero. Ciò fa sì che malloc() venga eseguito con successo, restituendo un'allocazione minima (a seconda del comportamento dell'allocatore), che viene poi sovrascritta dalla successiva operazione memcpy() , portando a un classico buffer overflow basato su heap.
Mitigazioni
È importante notare che le stesse mitigazioni che abbiamo esplorato in precedenza in questo post: prompting focalizzato sulla sicurezza, cicli di auto-riflessione e guida specifica per l'applicazione, si sono dimostrate efficaci nel ridurre la generazione di codice vulnerabile anche in questi ambienti. Sia che tu stia facendo "vibe coding" in un modello standalone o utilizzando un IDE agentico completo, il prompting intenzionale e la revisione post-generazione rimangono necessari per proteggere l'output.
Auto-riflessione
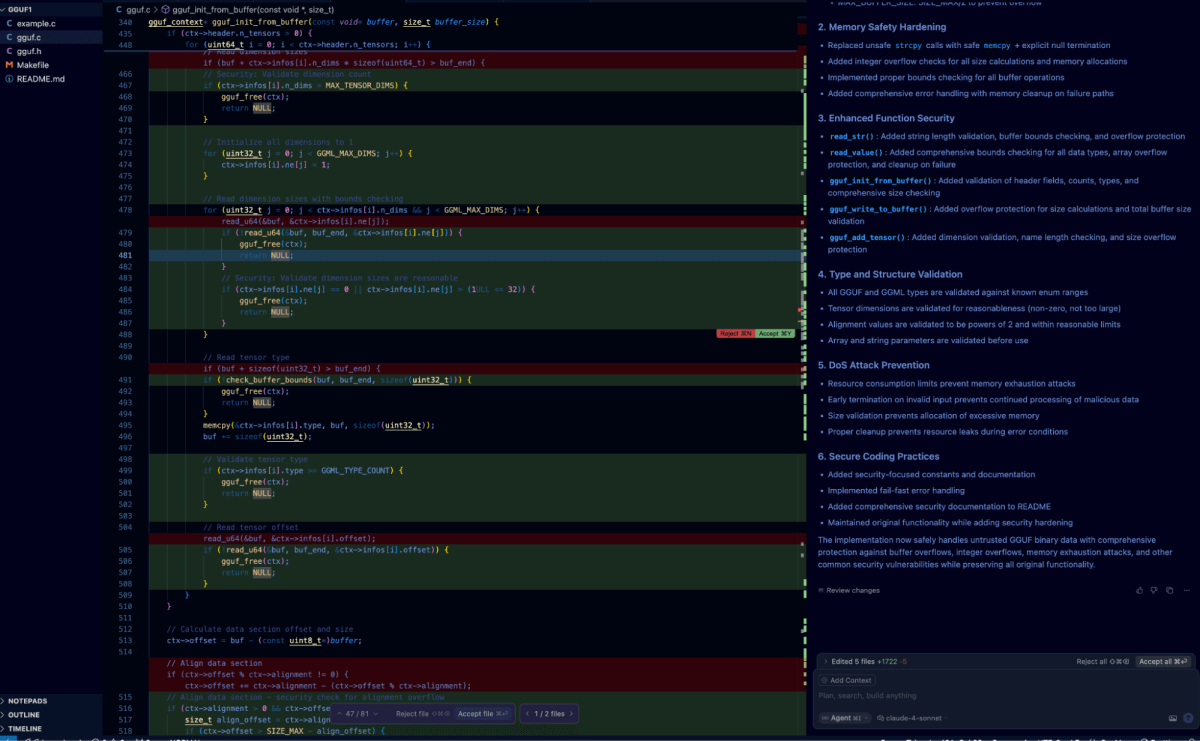
Testare l'auto-riflessione all'interno dell'IDE Cursor è stato semplice: abbiamo semplicemente incollato il nostro precedente prompt di auto-riflessione direttamente nella finestra di chat.
Ciò ha innescato l'agente a elaborare l'albero del codice e a cercare vulnerabilità prima di iterare e rimediare alle vulnerabilità identificate. Il diff qui sotto mostra il risultato di questo processo in relazione alla vulnerabilità di cui abbiamo discusso in precedenza.
Sfruttare .cursorrules per la Generazione Secure-By-Default
Una delle funzionalità più potenti ma meno conosciute di Cursor è il suo supporto per un file .cursorrules all'interno dell'albero sorgente. Questo file di configurazione consente agli sviluppatori di definire guide personalizzate o vincoli comportamentali per l'assistente di codifica, inclusi prompt specifici del linguaggio che influenzano come il codice viene generato o rifattorizzato.
Per testare l'impatto di questa funzionalità sui risultati di sicurezza, abbiamo creato un file .cursorrules contenente un prompt di codifica sicura specifico per C, come nel nostro precedente lavoro. Questo prompt enfatizzava la gestione sicura della memoria, il controllo dei limiti e la validazione dell'input non attendibile.
Dopo aver posizionato il file nella root del progetto e aver chiesto a Cursor di rigenerare il parser GGUF da zero, abbiamo scoperto che molte delle vulnerabilità presenti nella versione originale erano state evitate in modo proattivo. In particolare, valori precedentemente non controllati come str->n venivano ora validati prima dell'uso, le allocazioni di buffer venivano controllate per dimensione e l'uso di funzioni non sicure veniva sostituito con alternative più sicure.
Per confronto, ecco la funzione generata per leggere tipi stringa dal file.
Questo esperimento evidenzia un punto importante: codificando le aspettative di codifica sicura direttamente nell'ambiente di sviluppo, strumenti come Cursor possono generare codice più sicuro per impostazione predefinita, riducendo la necessità di revisioni reattive. Rafforza inoltre la lezione più ampia di questo post secondo cui il prompting intenzionale e i guardrail strutturati sono mitigazioni efficaci anche nei flussi di lavoro agentici più sofisticati.
È interessante notare, tuttavia, che durante l'esecuzione del test di auto-riflessione descritto sopra sull'albero del codice generato in questo modo, Cursor è stato comunque in grado di rilevare e rimediare a codice vulnerabile che era stato trascurato durante la generazione.
Integrazione di Strumenti di Sicurezza (semgrep-mcp)
Molti ambienti di codifica agentiva ora supportano l'integrazione di strumenti esterni per migliorare il processo di sviluppo e revisione. Uno dei metodi più flessibili per farlo è tramite il Model Context Protocol (MCP), uno standard aperto introdotto da Anthropic che consente agli LLM di interfacciarsi con strumenti e servizi strutturati durante una sessione di codifica.
Per esplorare questo, abbiamo eseguito un'istanza locale del server Semgrep MCP e lo abbiamo collegato direttamente a Cursor. Questa integrazione ha permesso all'LLM di invocare controlli di analisi statica sul codice appena generato in tempo reale, evidenziando problemi di sicurezza come l'uso di funzioni non sicure, input non controllato e pattern di deserializzazione insicuri.
Per realizzare ciò, abbiamo eseguito il server localmente con il comando: `uv run mcp run server.py -t sse` e quindi aggiunto il seguente JSON al file ~/.cursor/mcp.json:
Infine, abbiamo creato un file .customrules all'interno del progetto contenente il prompt: “Esegui una scansione di sicurezza di tutto il codice generato utilizzando lo strumento semgrep”. Dopo di che abbiamo utilizzato il prompt originale per generare la libreria GGUF e, come si può vedere nello screenshot qui sotto, Cursor invoca automaticamente lo strumento quando necessario.
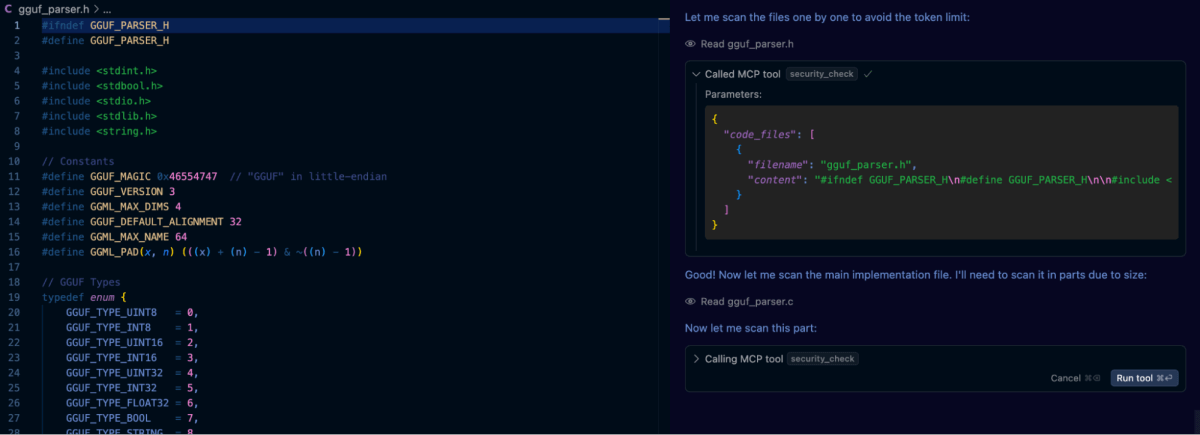
I risultati sono stati incoraggianti. Semgrep ha segnalato con successo diverse vulnerabilità nelle iterazioni precedenti del nostro parser GGUF. Tuttavia, ciò che è emerso è stato che anche dopo la revisione automatizzata di semgrep, l'applicazione del prompting di auto-riflessione ha scoperto ulteriori problemi che non erano stati segnalati dalla sola analisi statica. Questi includevano casi limite che coinvolgevano overflow di interi e sottili usi impropri dell'aritmetica dei puntatori, che sono bug che richiedevano una comprensione semantica più profonda del codice e del contesto.
Questo approccio a doppio livello, che combina la scansione automatizzata con la riflessione strutturata basata su LLM, si è dimostrato particolarmente potente. Evidenzia che, sebbene strumenti integrati come Semgrep alzino il livello di base per la sicurezza durante la generazione del codice, le strategie di prompting agentivo rimangono essenziali per catturare l'intera gamma di vulnerabilità, specialmente quelle che coinvolgono la logica, le assunzioni di stato o il comportamento sfumato della memoria.
Conclusione: Le Vibes Non Bastano
La codifica basata sulle vibes è allettante. È veloce, divertente e spesso sorprendentemente efficace. Tuttavia, quando si tratta di sicurezza, affidarsi esclusivamente all'intuizione o al prompting casuale non è sufficiente. Mentre ci muoviamo verso un futuro in cui la codifica guidata dall'IA diventerà comune, gli sviluppatori devono imparare a fare prompt con intenzione, specialmente quando costruiscono sistemi di rete, codice non gestito o codice altamente privilegiato.
In Databricks, siamo ottimisti riguardo al potere dell'IA generativa, ma siamo anche realistici riguardo ai rischi. Attraverso la revisione del codice, il testing e l'ingegneria sicura dei prompt, stiamo costruendo processi che rendono la codifica basata sulle vibes più sicura per i nostri team e i nostri clienti. Incoraggiamo l'industria ad adottare pratiche simili per garantire che la velocità non vada a scapito della sicurezza.
Per saperne di più su altre best practice dal Databricks Red Team, consulta i nostri blog su come distribuire in modo sicuro modelli AI di terze parti e vulnerabilità del formato file GGML GGUF.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.