PDF in Produzione: Annuncio dell'intelligenza documentale all'avanguardia su Databricks
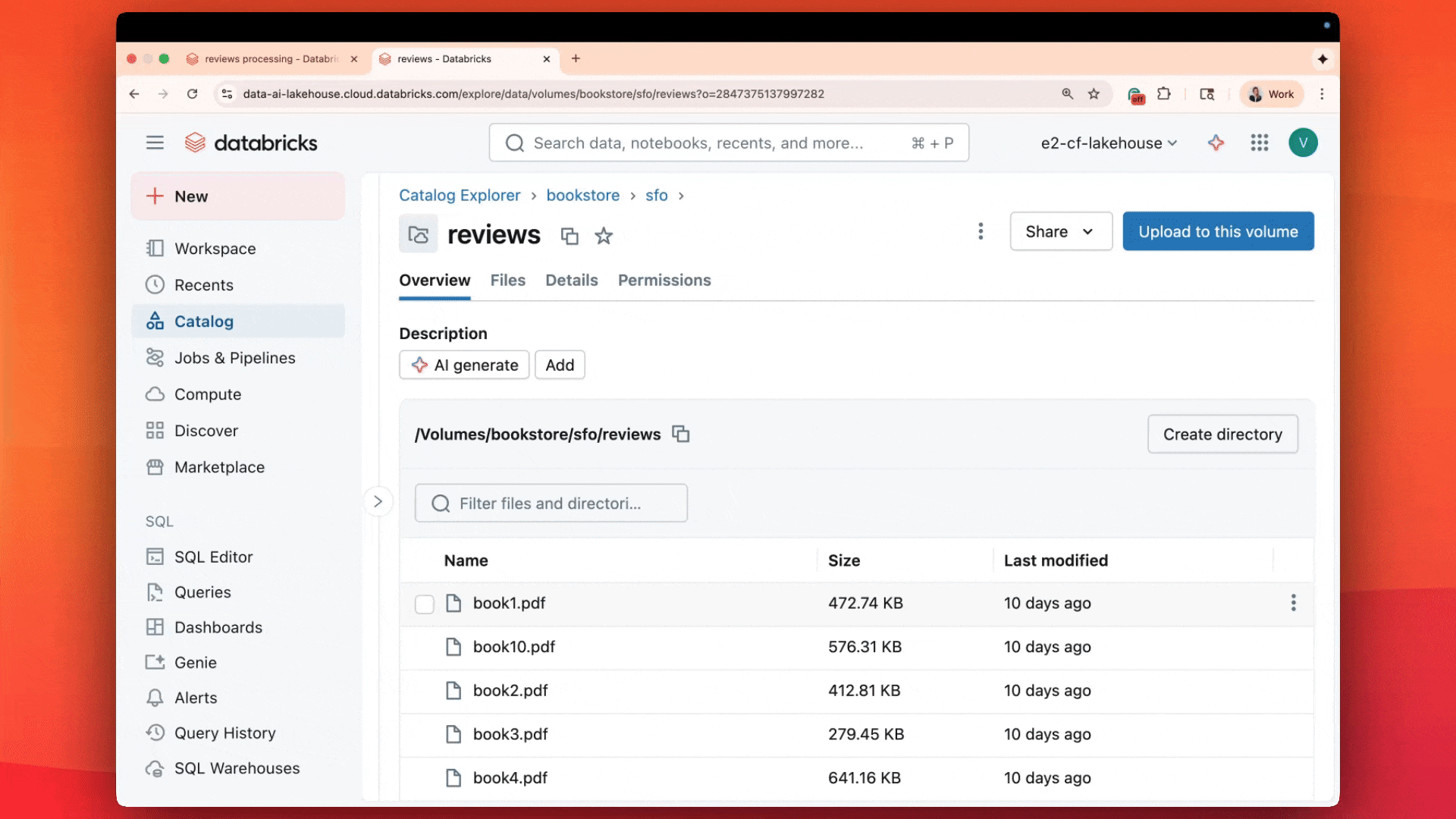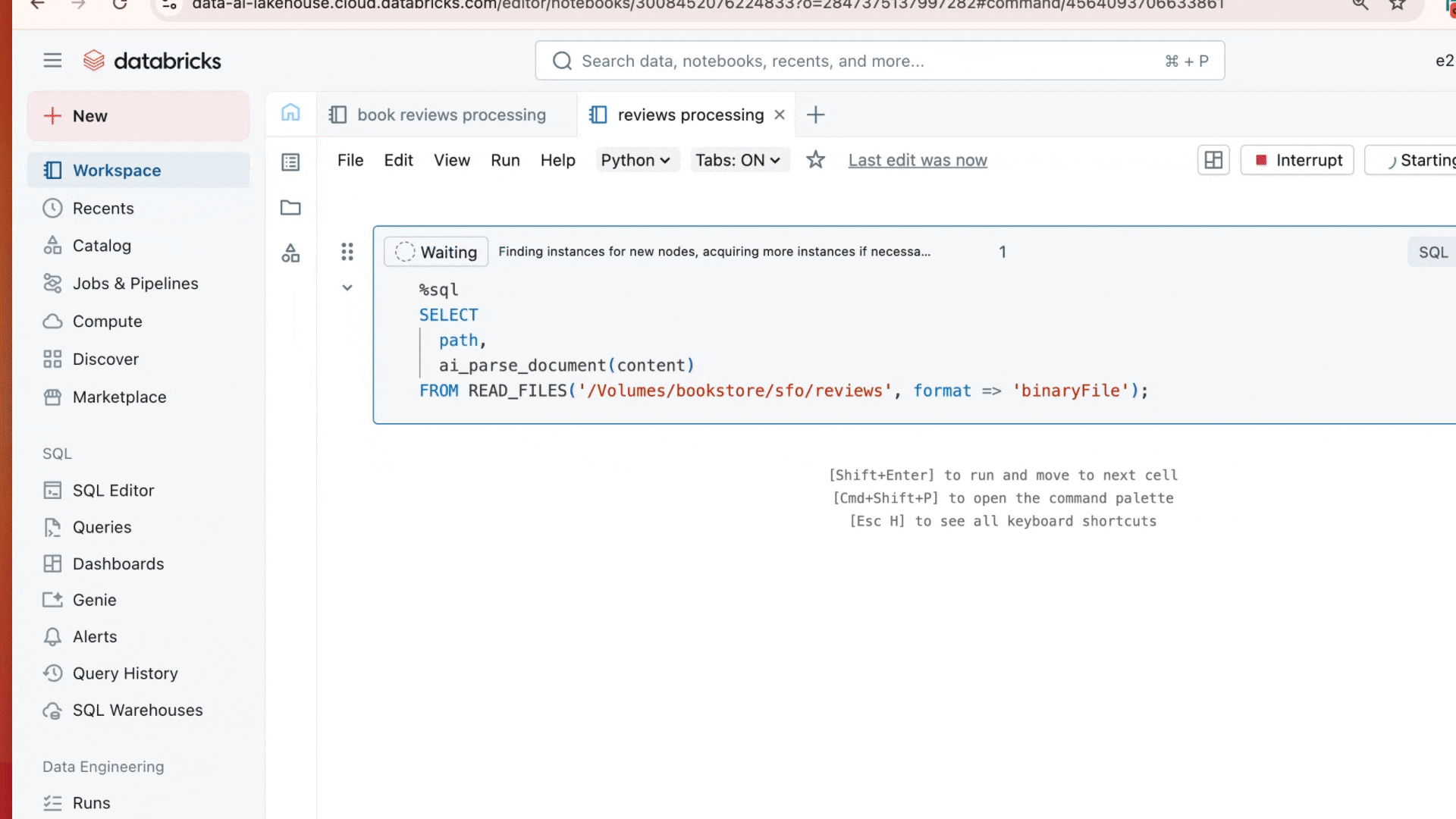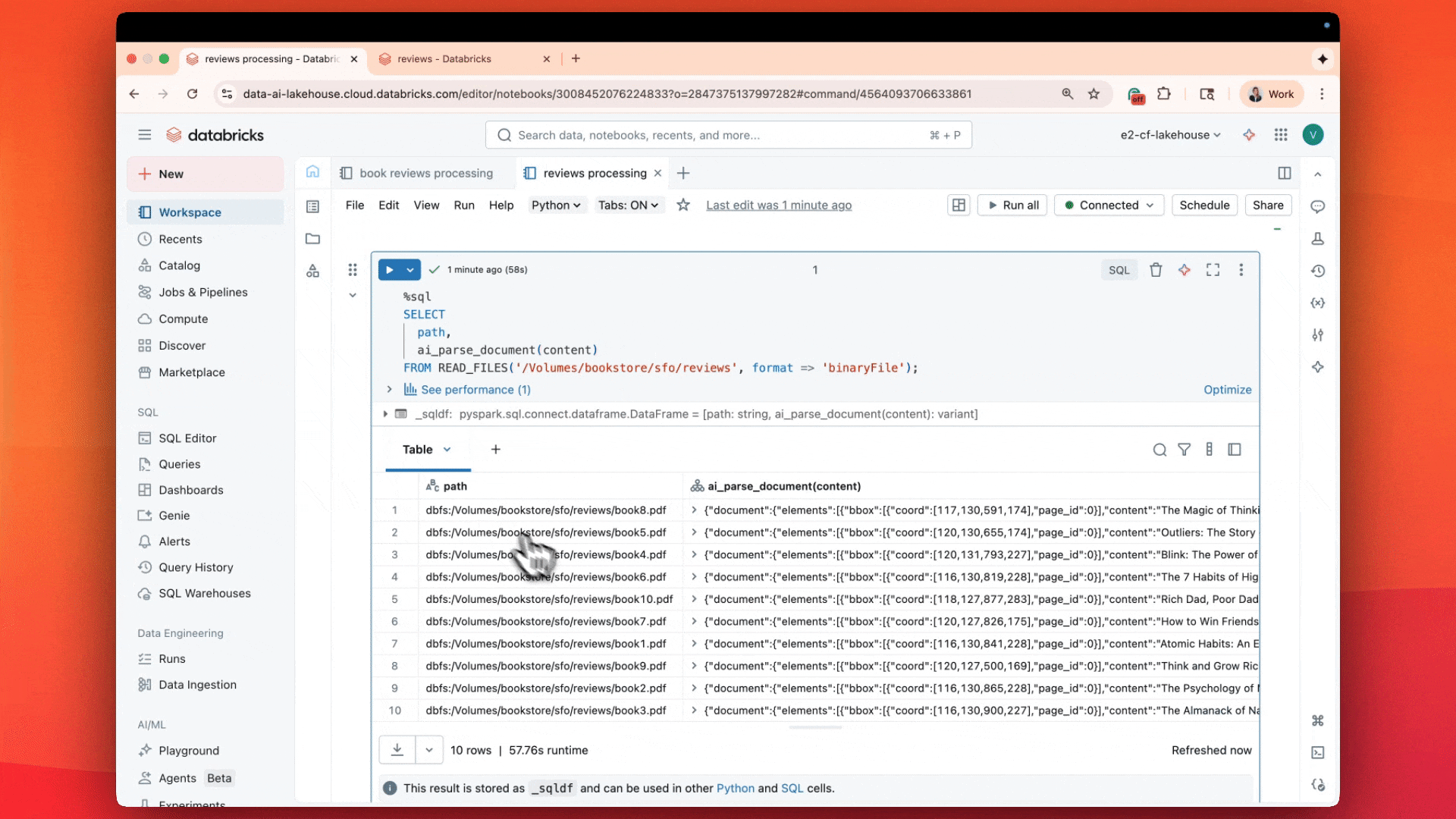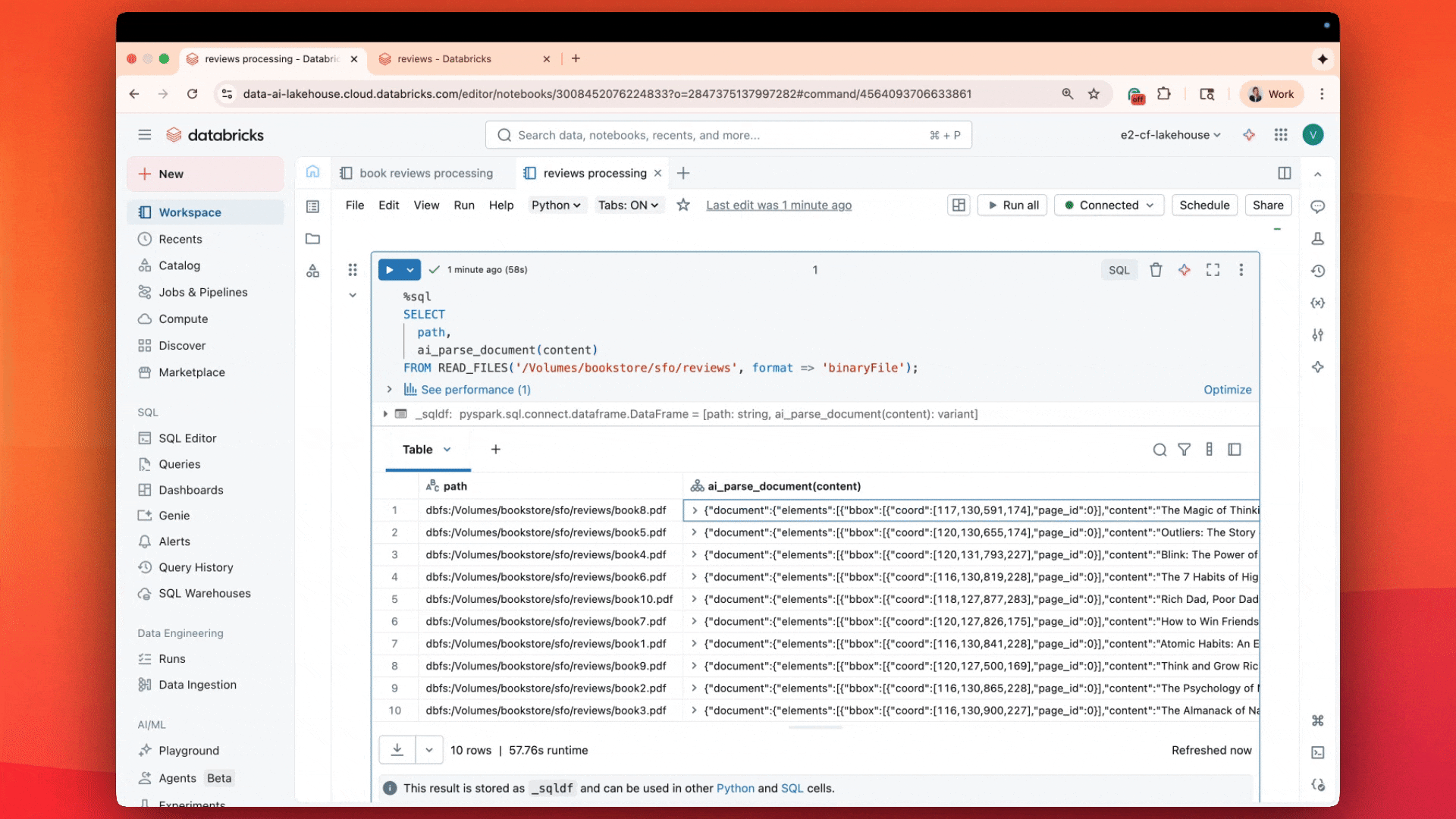
Con ai_parse_document, analizza e comprendi i PDF direttamente in SQL con qualità leader a un costo 3-5 volte inferiore
- Oggi introduciamo l'ultima novità di Agent Bricks: ai_parse_document (Anteprima Pubblica): basato sul nostro sistema agentico per la comprensione multimodale su larga scala.
- Sblocca l'80% dei tuoi dati aziendali con l'elaborazione intelligente di documenti all'avanguardia: elabora milioni di documenti complessi—tabelle, figure, diagrammi—con la potenza della ricerca AI innovativa in un'unica funzione SQL.
- Qualità e costi leader: Abbiamo sviluppato un sistema di intelligenza documentale competitivo per qualità con le migliori offerte dei concorrenti a un costo 3-5 volte inferiore.
- Integrazione completa della piattaforma: Elaborazione incrementale automatica con Spark Declarative Pipelines, governance con Unity Catalog e uso senza interruzioni tra Agent Bricks, AI Search e AIBI.
Durante la Settimana degli Agenti stiamo espandendo Agent Bricks, la piattaforma Databricks per la creazione di agenti AI governati e pronti per la produzione che ragionano accuratamente sui tuoi dati. Una delle maggiori sfide che le aziende affrontano quando scalano gli agenti è l'accesso ai dati non strutturati. Quasi l'80% della conoscenza aziendale è intrappolata in PDF, report e diagrammi che gli agenti non possono leggere, comprendere o elaborare. Questi documenti contengono un contesto critico, eppure la maggior parte degli agenti AI non poteva leggerli, fino ad ora.
Gli strumenti di parsing esistenti si fermano all'estrazione del testo. Perdono layout, elementi visivi e relazioni che portano significato nei documenti reali. I team impiegano mesi a scrivere codice personalizzato fragile che fallisce ancora sui dati del mondo reale. ai_parse_document elimina questa complessità. Porta la comprensione completa dei documenti direttamente nella Piattaforma di Intelligenza dei Dati Databricks, dando a ogni agente accesso alla piena fedeltà del tuo contesto aziendale, in modo accurato, sicuro e scalabile.
Con un singolo comando SQL, le organizzazioni possono trasformare i documenti in dati strutturati, governati e interrogabili:
Il risultato non è solo il testo del PDF, ma anche informazioni sul layout, tabelle analizzate, riquadri di delimitazione, figure e immagini con didascalie: una descrizione completa del documento, come informazione strutturata.
"L'ai_parse_document di Databricks riduce l'overhead di configurazione, consentendo agli scienziati dei dati di dedicare meno tempo alla configurazione e più tempo allo sviluppo di soluzioni complesse incentrate sul cliente."—Meiling He, Sr. Data Science Manager, Rockwell Automation
Prestazioni-Prezzo allo Stato dell'Arte
Se confrontato con altri sistemi di parsing allo stato dell'arte e modelli linguistici visivi (VLM), ai_parse_document ha la massima qualità per la sua categoria di prezzo, misurata sia da un benchmark esterno comune (OmniOCR) sia dal nostro benchmark interno privato (vedi Figure sotto). Il benchmark interno è più allineato alla distribuzione dei documenti che abbiamo visto dai clienti e anche improbabile che faccia parte dei dati di addestramento di qualsiasi modello. Nelle prossime settimane, rilasceremo anche le nostre nuove etichette OmniOCR, che correggono alcuni errori di etichettatura e introducono riquadri di delimitazione e informazioni gerarchiche.
 Qualità rispetto al costo per un'imminente versione del sistema di intelligenza documentale Databricks di ai_parse_document, rispetto ad altri sistemi leader e VLM su OmniOCR, un benchmark esterno comune. I prezzi possono variare a seconda della complessità del documento e riflettono gli sconti promozionali.">
Qualità rispetto al costo per un'imminente versione del sistema di intelligenza documentale Databricks di ai_parse_document, rispetto ad altri sistemi leader e VLM su OmniOCR, un benchmark esterno comune. I prezzi possono variare a seconda della complessità del documento e riflettono gli sconti promozionali.">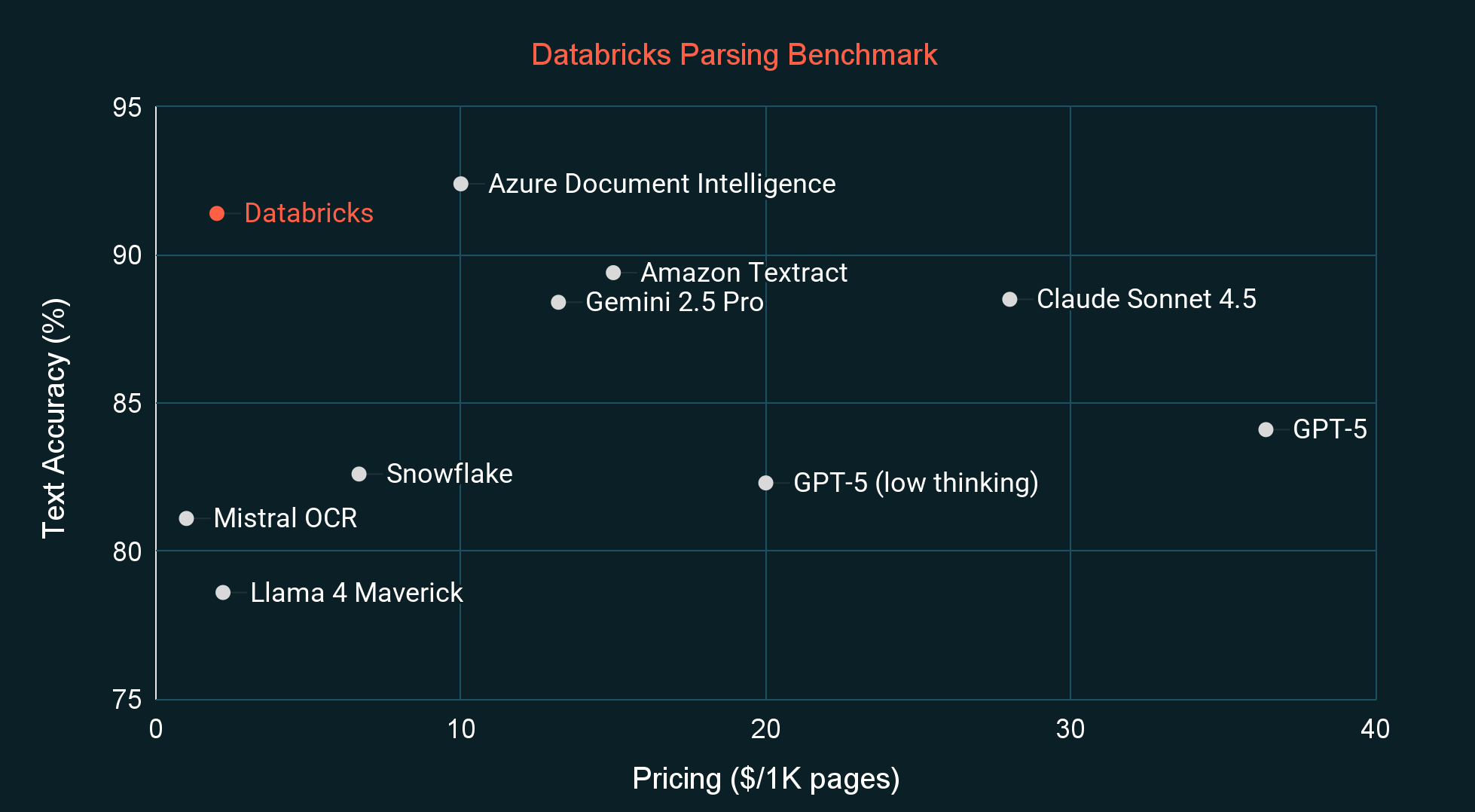 Qualità rispetto al costo per un'imminente versione del sistema di intelligenza documentale Databricks di ai_parse_document, rispetto ad altri sistemi leader e VLM su un benchmark interno di parsing PDF che riflette meglio la distribuzione di immagini e layout che osserviamo nelle aziende. I prezzi possono variare a seconda della complessità del documento e riflettono gli sconti promozionali.">
Qualità rispetto al costo per un'imminente versione del sistema di intelligenza documentale Databricks di ai_parse_document, rispetto ad altri sistemi leader e VLM su un benchmark interno di parsing PDF che riflette meglio la distribuzione di immagini e layout che osserviamo nelle aziende. I prezzi possono variare a seconda della complessità del documento e riflettono gli sconti promozionali.">Come Funziona
ai_parse_document acquisisce tabelle, figure e diagrammi con descrizioni generate dall'IA e metadati spaziali, archiviando i risultati in Unity Catalog. I tuoi documenti ora si comportano come tabelle: ricercabili tramite AI Search e utilizzabili nei flussi di lavoro di Agent Bricks.
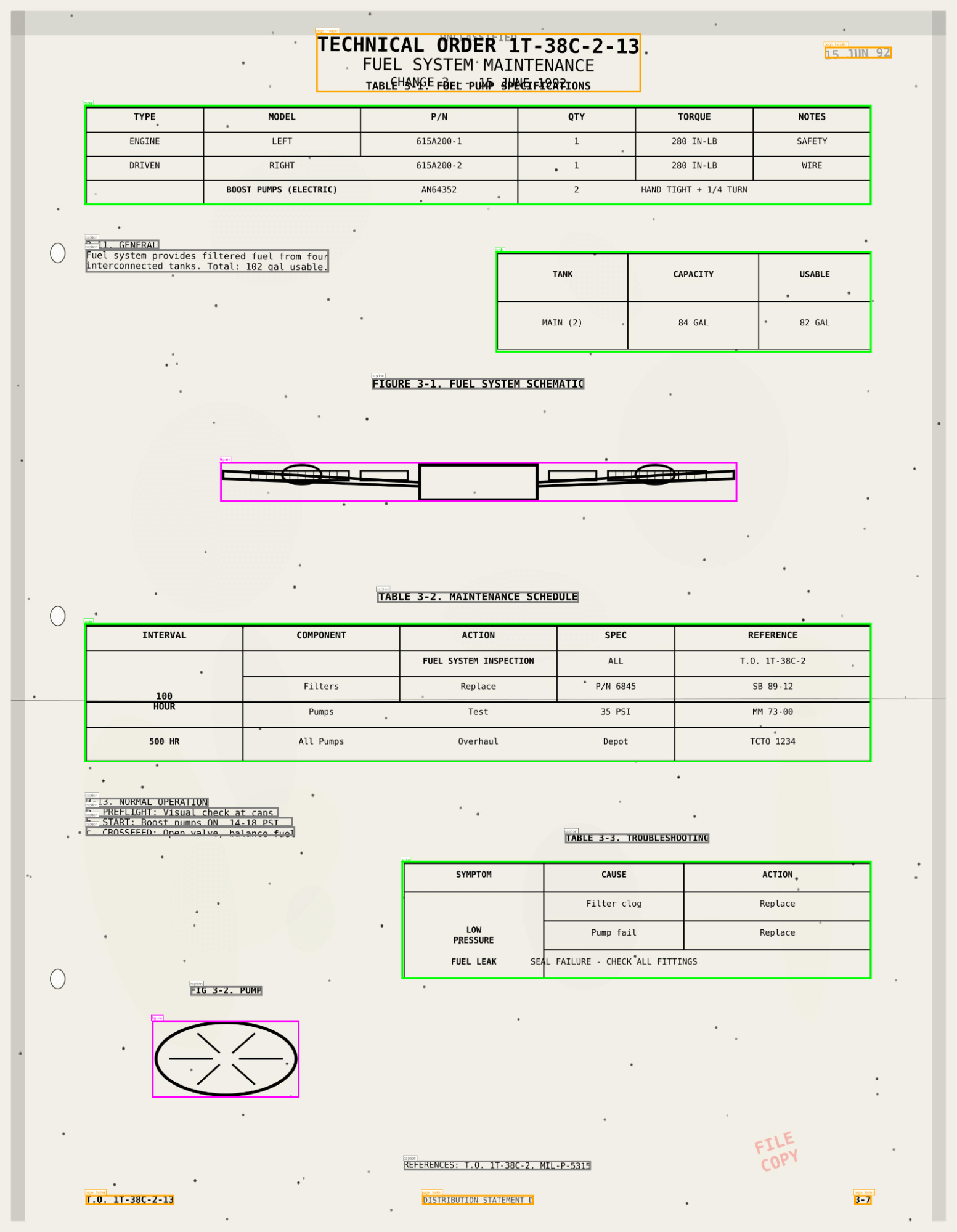 Screenshot che mostrano ai_parse_document che rileva riquadri di delimitazione con figure e tabelle complesse, mostrando le descrizioni delle figure">
Screenshot che mostrano ai_parse_document che rileva riquadri di delimitazione con figure e tabelle complesse, mostrando le descrizioni delle figure">“Estrarre tabelle, testo e metadati da PDF o immagini era un processo complesso e ricco di codice. Databricks lo ha condensato in una singola funzione SQL, ai_parse_document, semplificando radicalmente l'elaborazione di dati non strutturati su larga scala e mettendola nelle mani di ogni team di dati, non solo degli scienziati dei dati.”—Rajesh Balakrishnan, Principal Data Scientist, TE Connectivity
Con una singola istruzione SQL, i clienti stanno già elaborando milioni di documenti in parallelo:
Ogni risultato include:
- Tabelle preservate esattamente come appaiono, comprese celle unite e strutture nidificate.
- Figure e diagrammi descritti automaticamente con didascalie generate dall'IA.
- Metadati spaziali e riquadri di delimitazione per citazioni e validazione.
- Output di immagini opzionali archiviati nei volumi di Unity Catalog per la ricerca multimodale o la visualizzazione.
Poiché tutto rimane all'interno di Databricks, mantieni coerenza nella governance, nella lineage e nell'osservabilità.
Sostituisci il tuo stack di parser esterni con una singola funzione SQL che funziona come qualsiasi altra operazione Databricks. Mentre i team tipicamente esportano documenti in servizi OCR, API di rilevamento del layout e strumenti di didascalie di figure, ai_parse_document li elabora senza lasciare il tuo ambiente Databricks:
“ai_parse_document rende RAG veloce e semplice su Databricks abilitando il parsing parallelo dei documenti direttamente all'interno delle tabelle Delta che stai già utilizzando”—Hunter Johnson, Lead Data Scientist, Emerson Electric Co.
Da Parsing all'Azione con Agent Bricks
Una volta effettuato il parsing, i dati del documento fluiscono naturalmente nel resto dell'ecosistema Agent Bricks
Insieme, queste funzionalità rendono i dati non strutturati una parte completamente integrata della piattaforma Agent Bricks.
Costruito per Scala e Affidabilità di Produzione
Molte aziende hanno milioni di documenti non strutturati da analizzare, alcune ne ricevono persino milioni al giorno. È fondamentale disporre di una soluzione in grado di scalare in modo affidabile per elaborare questi dati senza impiegare giorni. Databricks integra ai_parse_document con Spark Declarative Pipelines, fornendo un'elaborazione automatica e incrementale dei documenti su larga scala. Quando arrivano nuovi documenti, sia da SharePoint, S3 o ADLS, vengono analizzati automaticamente. Lakeflow gestisce i tentativi, il checkpointing e lo scaling, quindi non è mai necessario rielaborare dati esistenti o scrivere codice di orchestrazione personalizzato.
Tutto è governato tramite Unity Catalog, consentendo di gestire permessi, controllare accessi e tracciare la lineage per i contenuti analizzati esattamente come si fa per i dati strutturati.
Sblocca dati non strutturati con Agent Bricks
ai_parse_document è l'ultima aggiunta alle Funzioni AI di Agent Bricks, che si affianca a funzionalità come ai_extract, ai_classify, ai_summarize e ai_query. Insieme, queste funzioni consentono a ogni team di ragionare su tutti i dati aziendali direttamente all'interno della piattaforma Databricks. Combinando l'intelligenza documentale con la governance, l'osservabilità e l'orchestrazione integrate, Databricks consente alle aziende di creare agenti AI che comprendono veramente il contesto aziendale e agiscono su di esso con sicurezza.
Pronto a sbloccare il valore nei tuoi dati non strutturati?
- Leggi la documentazione per iniziare a usare ai_parse_document oggi
- Costruisci pipeline incrementali per documenti con la nostra soluzione di riferimento
Autori della ricerca (contributo paritario): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.