Polari contro panda
Confronta l'elaborazione parallela ad alte prestazioni di Polars con la versatile API di Pandas per la manipolazione dei dati basata su DataFrame
- Comprendere le differenze tra Polars e Pandas per le operazioni DataFrame e i flussi di lavoro di analisi dei dati
- Scoprire come Polars utilizza l'elaborazione parallela basata su Rust e la valutazione lazy per prestazioni superiori su set di dati di grandi dimensioni
- Scoprire quando scegliere l'ampio ecosistema e la flessibilità di Pandas rispetto alla velocità e all'efficienza della memoria di Polars
Introduzione: comprendere le opzioni della libreria DataFrame
I DataFrame sono strutture di dati bidimensionali, solitamente tabelle, simili a fogli di calcolo, che consentono di archiviare e manipolare dati tabulari in righe di osservazioni e colonne di variabili, nonché di estrarre informazioni preziose dal set di dati fornito. Le librerie DataFrame sono toolkit software che forniscono una struttura simile a un foglio di calcolo per lavorare con i dati nel codice. Le librerie DataFrame sono un elemento essenziale di una piattaforma di analisi dei dati perché forniscono l'astrazione principale che rende i dati facili da caricare, manipolare, analizzare e interpretare, collegando l'archiviazione di dati grezzi e gli strumenti di analitiche di livello superiore, machine learning e visualizzazione.
Polars e pandas sono le principali librerie DataFrame di Python per l'analisi e la manipolazione dei dati, ma sono ottimizzate per casi d'uso e scale di lavoro diversi.
pandas è una libreria open-source scritta per il linguaggio di programmazione Python che mette a disposizione strutture di dati e strumenti di analisi dei dati veloci e adattabili. È la libreria DataFrame più utilizzata in Python. È maturo, ricco di funzionalità e dispone di un vasto ecosistema con numerose integrazioni. Pandas vanta un'ampia documentazione, il supporto della community e librerie di plotting mature. È apprezzato per i set di dati di piccole e medie dimensioni e per l'analisi esplorativa.
Polars è una libreria DataFrame colonnare veloce, basata su Rust, con un'API Python. È progettata per la velocità, con parallelismo integrato ed "esecuzione lazy" (non eseguita immediatamente) per carichi di lavoro più grandi della memoria.
A seconda dei tuoi requisiti di elaborazione dei dati, Pandas funziona bene per la data science su set di dati fino a qualche milione di righe. Se ti occupi di ETL, analitiche o lavori su tabelle di grandi dimensioni, Polars è generalmente più efficiente.
Quando usare pandas per il tuo flusso di lavoro
Pandas dà il meglio di sé quando la flessibilità, la velocità di iterazione e la compatibilità con l'ecosistema contano più delle Scale estreme. È la libreria DataFrame standard di fatto. Dà priorità alla flessibilità e offre integrazioni profonde con Scikit-learn. NumPy, Matplotlib, statsmodels e molti strumenti di machine learning.
Funziona con codebase legacy ed è familiare ai team di elaborazione dati che lo utilizzano per l'analisi interattiva e il lavoro di esplorazione dei dati in cui la flessibilità è l'aspetto più importante. Il suo formato basato su righe è ideale per set di dati di piccole e medie dimensioni per analisi ad hoc, flussi di lavoro basati su notebook e prototipazione rapida.
Con pandas, puoi eseguire qualsiasi funzione Python, mentre Polars scoraggia vivamente l'esecuzione arbitraria di codice Python. Con pandas, le modifiche sul posto e l'editing passo-passo sono la norma, consentendo agli utenti di mutare lo stato nel tempo. Con Polars, i DataFrame sono di fatto immutabili.
Si può eseguire l'interfaccia pandas API su Apache Spark 3.2. Ciò permette di distribuire uniformemente i carichi di lavoro di pandas, assicurando che tutto avvenga nel modo corretto.
Per l'analisi esplorativa dei dati, pandas offre attività operative veloci e interattive, semplici operazioni di sezionamento/filtraggio/raggruppamento e ispezioni visive rapide. Viene spesso utilizzato per la convalida/il controllo dei dati e la pulizia dei dati grezzi da valori mancanti, formati incoerenti, duplicati o tipi di dati misti.
Per le analitiche aziendali e la reportistica, in cui i team di dati devono generare metriche su una scala temporale definita, pandas semplifica l'operazione di groupby e aggregazione con un facile rimodellamento e produce output direttamente in formato CSV/Excel.
Quando i team di data science preparano i dati per i modelli di ML, pandas facilita la sperimentazione con la creazione naturale di feature basate su colonne e una stretta integrazione con scikit-learn. Viene spesso utilizzato per la prototipazione rapida e le prove di concetto prima di scrivere la logica in SQL, Spark o pipeline di produzione.
Anche i team finanziari e aziendali non tecnici utilizzano pandas per automatizzare i flussi di lavoro basati su Excel.
Maggiori informazioni:
Lavorare con i DataFrame di pandas
Impara l'analisi dei dati con pandas
Quando usare Polars nel tuo flusso di lavoro
Polars eccelle quando prestazioni, scalabilità e affidabilità sono più importanti della flessibilità ad hoc. Grazie al suo motore Rust, al multithreading, al modello di memoria colonnare e al motore di esecuzione lazy, Polars può gestire carichi di lavoro ETL sorprendentemente grandi su una singola macchina dove l'efficienza della memoria è fondamentale. L'esecuzione lazy significa che le attività operative non vengono eseguite immediatamente, ma vengono registrate, ottimizzate ed eseguite solo quando l'output viene richiesto esplicitamente. Ciò può comportare enormi guadagni in termini di prestazioni perché crea un unico piano di esecuzione ottimizzato invece di eseguire ogni attività operativa passo dopo passo. Le trasformazioni dei dati vengono pianificate prima ed eseguite in seguito, consentendo al sistema di ottimizzare l'intera pipeline per la massima velocità ed efficienza.
Per le pipeline di dati di produzione che richiedono prestazioni elevate e costanti e flussi di lavoro in cui la velocità è fondamentale, Polars è multithreading per impostazione predefinita per sfruttare tutti i core della CPU disponibili ed elaborare ogni blocco del DataFrame su un thread diverso. Questo lo rende notevolmente più veloce delle tradizionali librerie DataFrame single-thread come pandas.
Quando si eseguono join su decine di milioni di righe, ad esempio unendo log di clickstream con metadati utente, i join di Polars sono multithread e i dati colonnari riducono la copia non necessaria di memoria.
Per scenari di utilizzo che coinvolgono set di dati di grandi dimensioni, trasformazioni complesse o pipeline a più fasi, Polars beneficia dell'elaborazione parallela, in cui ogni riga può essere elaborata in modo indipendente, suddividendo le operazioni di join su più core ed eseguendo il partizionamento hash in parallelo. Per pipeline di query a più fasi con molte trasformazioni, Polars può ottimizzare ed eseguire l'intera pipeline in parallelo. L'utilizzo dello streaming parallelo e della valutazione lazy consente a Polars di elaborare set di dati più grandi della RAM. L'elaborazione parallela e la valutazione lazy aiutano anche le attività operative di scansione di file di grandi dimensioni (file CSV/Parquet).
Polars ottiene anche importanti vantaggi in termini di prestazioni utilizzando l'archiviazione colonnare basata su Apache Arrow per l'ottimizzazione delle query. Nell'archiviazione colonnare, i dati vengono archiviati colonna per colonna, non riga per riga. Ciò consente a Polars di leggere solo le colonne necessarie, riducendo al minimo l'I/O del disco e l'accesso alla memoria e rendendolo più efficiente per l'elaborazione analitica. Può operare direttamente sui buffer di memoria continui di Apache Arrow senza copiare i dati.
Se ti occupi di ingegneria delle feature ed esplorazione di ML su set di dati estremamente grandi, di unire tabelle dei fatti di grandi dimensioni, di eseguire aggregazioni pesanti e analitiche OLAP, di carichi di lavoro di serie temporali, di scansioni massive di file, di elaborazione di dati più grandi della memoria e di elaborazione batch con SLA rigidi, Polars potrebbe essere la scelta migliore.
- Link interno: Apache Spark (ancora: elaborazione distribuita dei dati)
- Link interno: pipeline di dati (ancoraggio: creazione di pipeline di dati scalabili)
Rappresentazione e architettura dei dati
I modelli di rappresentazione dei dati e le architetture di pandas e Polars differiscono di proposito. L'archiviazione basata su righe utilizzata da pandas memorizza righe complete in modo continuo nella memoria, mentre l'archiviazione colonnare presente in Polars memorizza ogni colonna in modo contiguo. Ciascun metodo può influire sulle prestazioni, a seconda dei tipi di query eseguite.
Per le query analitiche, l'archiviazione colonnare in genere offre prestazioni migliori perché la query deve toccare solo le colonne necessarie, mentre gli archivi di righe devono leggere righe complete.
Le colonne hanno tipi uniformi, il che porta a rapporti di compressione migliori, e la vettorizzazione consente un'elaborazione batch veloce.
Per le query transazionali, come i carichi di lavoro OLTP, è preferibile l'archiviazione basata su righe, poiché un'intera riga viene archiviata insieme, quindi il recupero di un record completo richiede una singola lettura e l'aggiornamento di una riga modifica una sola regione compatta di memoria.
I grafici sottostanti mostrano i rapporti di prestazione medi che confrontano le librerie DataFrame basate su righe e su colonne (in questo caso, Koalas e Dask).
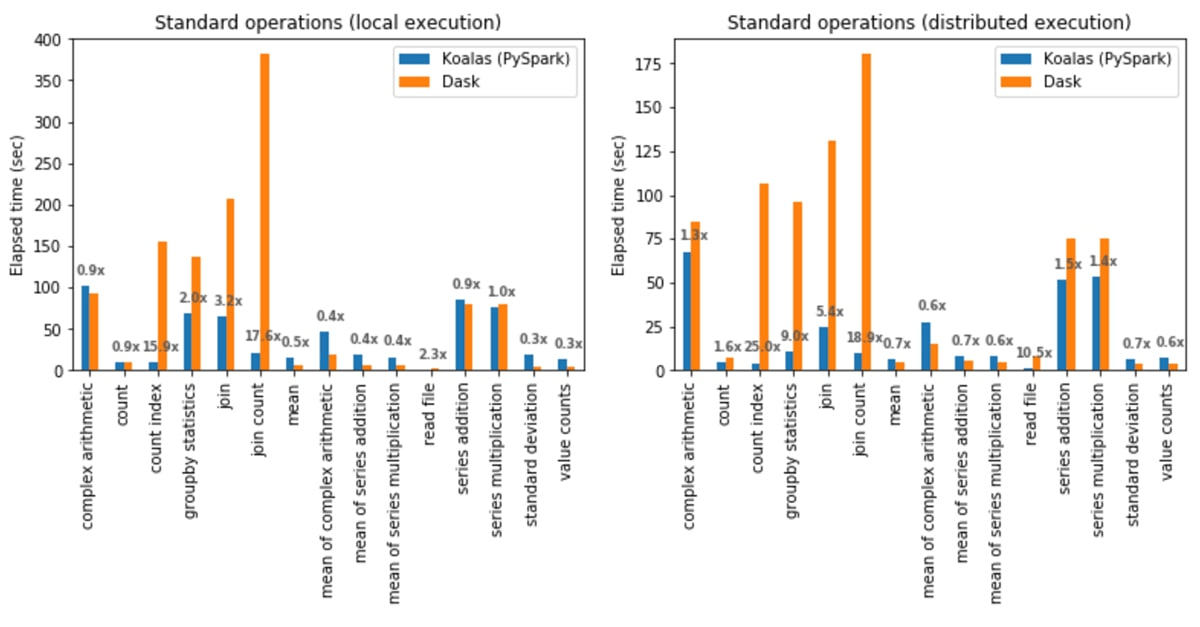
Il formato colonnare di Polars consente aggregazioni più veloci. Poiché ogni colonna è memorizzata in modo contiguo in memoria, può eseguire lo stream di una singola colonna senza analizzare dati non correlati e parallelizza le aggregazioni tra i core della CPU. Per i set di dati di grandi dimensioni, l'archiviazione colonnare riduce la pressione sulla RAM perché legge solo le colonne necessarie per la query.
Il layout colonnare in Polars consente l'esecuzione vettorizzata tramite Apache Arrow, abilitando la Data Sharing a zero copie. Polars può eseguire il filtraggio e lo slicing senza copiare i buffer di dati sottostanti.
Il modello di archiviazione basato su righe utilizzato da pandas significa che ogni riga di un DataFrame viene archiviata come una raccolta di oggetti Python raggruppati insieme. Questo modello è ottimizzato per le attività operative che recuperano o modificano record completi. Può recuperare tutti i dati di un record in un'unica ricerca, rendendolo più adatto a molte piccole attività operative con carichi di lavoro misti piuttosto che a grandi vettori. Supporta tipi di dati eterogenei come oggetti Python, stringhe, numeri, elenchi e dati nidificati. Tale flessibilità è utile per dati disordinati del mondo reale, JSON all'interno di record CSV e set di feature di tipo misto.
Per le query che richiedono l'accesso a molte o a tutte le colonne per una singola riga, come il recupero di record a livello di utente e la serializzazione di dati a livello di riga per le API, pandas non ha bisogno di ricostruire la riga accedendo a più buffer di colonna. È anche più veloce per i carichi di lavoro con mutazioni frequenti, perché consente la mutazione sul posto delle celle del DataFrame.
Quando i dati si adattano comodamente alla memoria, pandas è molto comodo e offre prestazioni abbastanza veloci per set di dati di piccole e medie dimensioni.
Prestazioni: valutazione della velocità e dell'uso delle risorse
Polars è generalmente più veloce e più efficiente in termini di risorse rispetto a pandas, soprattutto per il lavoro di tipo data engineering e all'aumentare dei dati e della complessità. Polars è colonnare, multi-thread per impostazione predefinita e può eseguire piani di query lazy/ottimizzati. Pandas è per lo più single-thread per le operazioni su DataFrame e utilizza la valutazione eager, in cui ogni riga viene eseguita immediatamente e materializza DataFrame intermedi. Pandas può essere più veloce su dati di piccole dimensioni e per alcune semplici operazioni vettorizzate, ed è più flessibile, ma questa flessibilità può avere un costo in termini di CPU/memoria.
Il Graph seguente mostra come il numero di thread può influire sulle prestazioni.
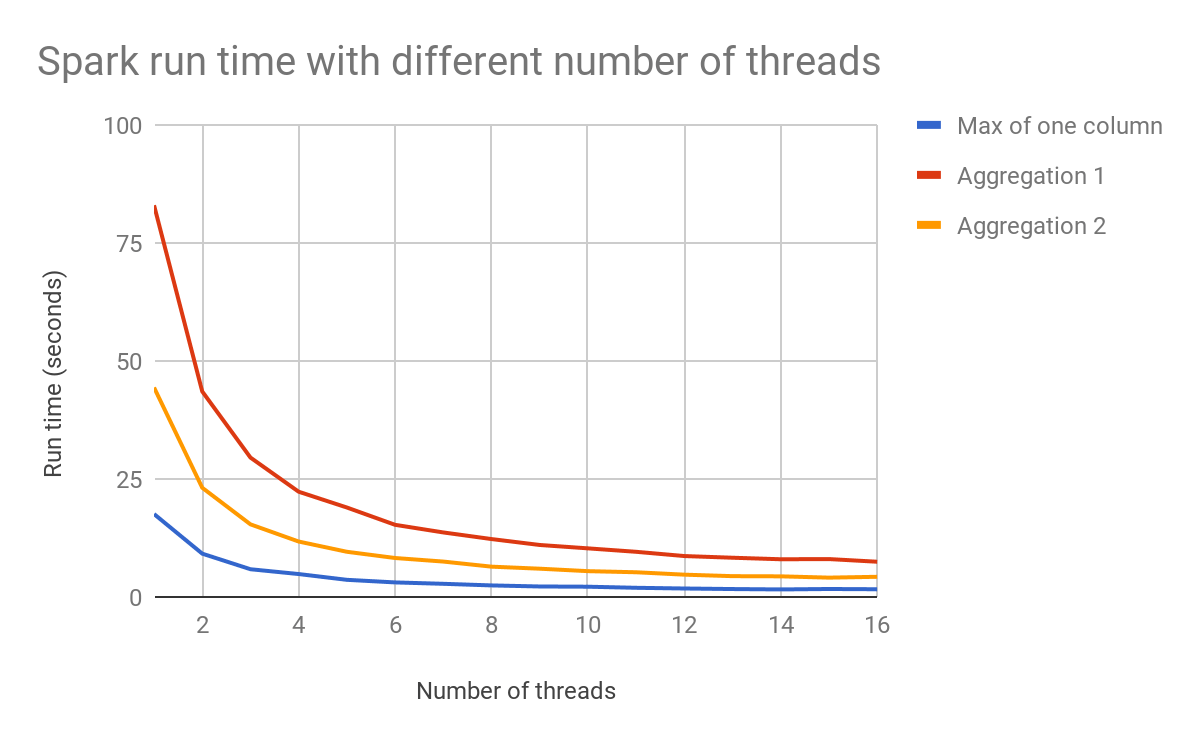
Con la pianificazione delle query e l'ottimizzatore di LazyFrame di Polars, il codice crea prima un piano di query, poi Polars lo ottimizza e lo esegue quando glielo si comanda. Questo da solo spiega gran parte del vantaggio di Polars in termini di velocità e utilizzo della memoria.
In pandas, la valutazione eager significa che esegue il compute immediatamente, creando un oggetto intermedio in memoria e passandolo poi al passaggio successivo; di conseguenza le prestazioni calano a causa dei passaggi multipli sui dati (spesso creando più intermedi di dimensioni complete). Poiché pandas non può vedere l'intera pipeline, non può eseguire un'ottimizzazione globale. Tuttavia, pandas dà il meglio di sé quando i dati rientrano agevolmente nella memoria, quando le operazioni sono piccole e interattive e quando si desidera un feedback immediato dopo ogni riga. Come regola generale, scegli pandas quando:
- stai facendo una rapida EDA
- i set di dati sono di piccole/medie dimensioni
- desideri un'ispezione e un debug passo dopo passo
- la tua logica è Python altamente personalizzato (riga per riga)
Scegli Polars quando:
- stai eseguendo pipeline ETL/analitiche ripetibili
- i set di dati sono grandi o ampi
- leggi spesso file Parquet/Arrow
- se per te sono importanti la velocità, la memoria e un numero inferiore di copie intermedie
A causa delle loro differenze filosofiche (pandas creato per la flessibilità e Polars per la velocità), le due librerie gestiscono i dati mancanti e i valori nulli in modo diverso, il che può anche influire sulle prestazioni.
Pandas può trattare diversi valori come “mancanti”, il che lo rende flessibile ma a volte incoerente e può rallentare le attività operative a causa della gestione degli oggetti Python. Polars utilizza “null” come unico valore mancante per tutti i tipi di dati per avvicinarsi alla semantica di SQL, il che è più veloce e più efficiente in termini di memoria su larga scala.
Come si vede nel Graph sottostante, che mostra i confronti dei tempi di esecuzione per flussi di lavoro rappresentativi, quando pandas è costretto a eseguire un'esecuzione a livello di Python (per riga) su set di dati di grandi dimensioni, crea molte copie intermedie e le attività operative rallentano.
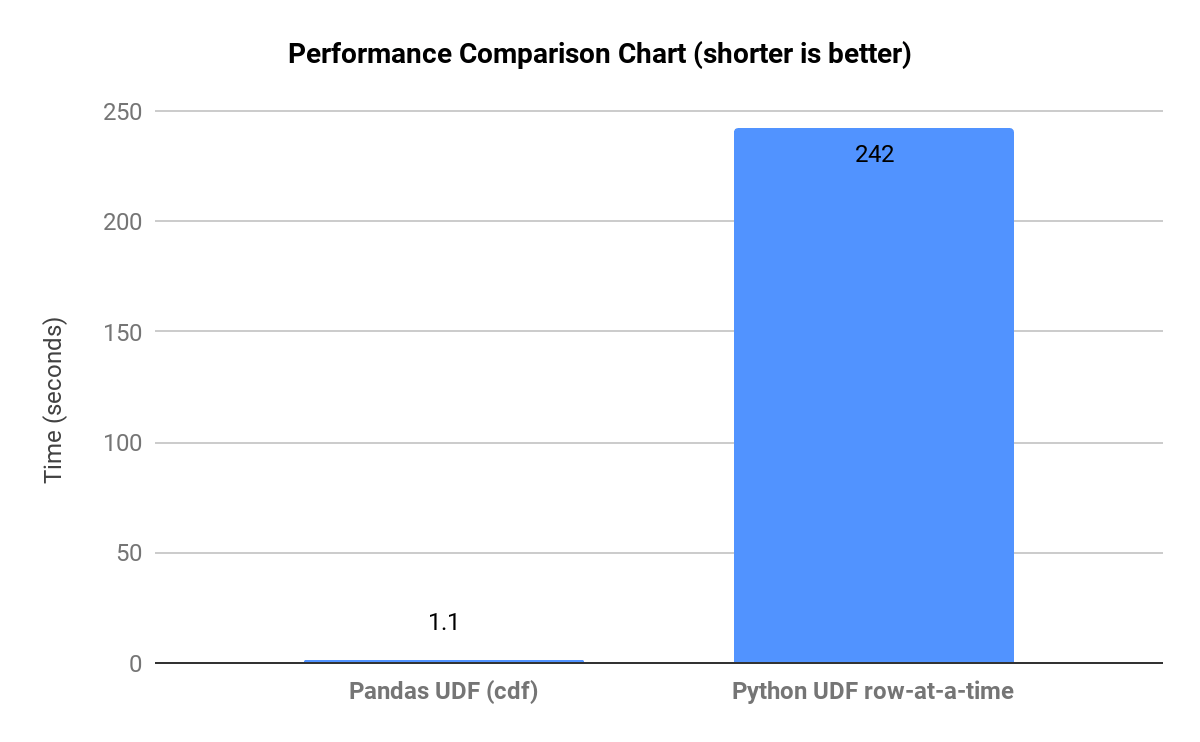
Anche Polars può presentare colli di bottiglia nelle prestazioni quando interrompe la vettorizzazione e impedisce l'ottimizzazione delle query o quando la modalità lazy non viene utilizzata per pipeline di grandi dimensioni. L'ottimizzazione di Polars può anche andare in crisi con join many-to-many molto grandi.
Il Graph sottostante mostra l'aumento lineare del consumo di memoria di pandas con la dimensione dei dati.
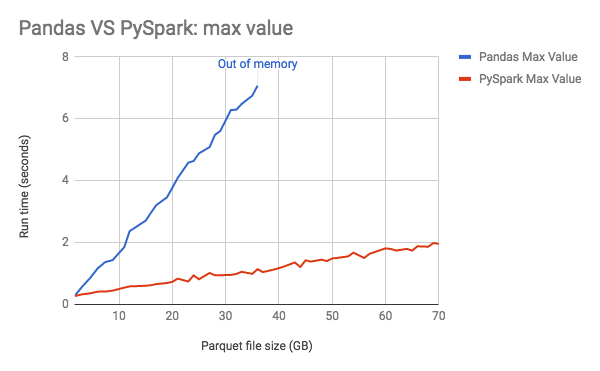
Guida alle prestazioni:
- Se il tuo carico di lavoro consiste in operazioni di groupby/join/scan su file Parquet di grandi dimensioni, in genere Polars è la scelta vincente.
- Se il tuo flusso di lavoro è un'EDA interattiva con molta logica Python personalizzata, pandas è spesso più pratico.
Benchmarking
Per comprendere le differenze di prestazioni, di seguito sono riportati alcuni approcci di benchmarking che è possibile implementare:
Ad-hoc rapido
- Utilizzare
time.perf_counter()per il wall time - Ripeti più volte
- Segnala
mediana/p95
Microbenchmark ripetibili (per un team / PR)
- Utilizzare
pytest-benchmarkoasv - Eseguire su una macchina stabile (o un runner CI bloccato)
- Salva i risultati tra i commit
Benchmarking simile alla produzione (il più significativo)
- Forma e dimensioni del set di dati reale
- Esecuzioni con cache fredda e calda a confronto
- Misurazione dei tempi della pipeline end-to-end
- Tracciamento di memoria e CPU
Per rendere i confronti equi, utilizza lo stesso formato di input, abbina i tipi di dati, utilizza gli stessi raggruppamenti, chiavi, output e controlla il threading (comportamento predefinito o confronto diretto a core singolo).
- Quando le differenze di prestazioni contano di più per casi d'uso specifici
- Miglioramenti medi del tempo effettivo con Polars su set di dati di grandi dimensioni
Gestione dei dati mancanti e dei tipi di dati
Il modo in cui una libreria DataFrame gestisce i dati mancanti e i tipi di dati influisce su correttezza, qualità dei dati, prestazioni e facilità d'uso. Pandas offre una gestione flessibile ma a volte incoerente dei dati mancanti e dei dtype, mentre Polars impone un unico modello null con una tipizzazione forte, il che porta a un comportamento più sicuro, più veloce e più prevedibile, soprattutto su larga scala.
Il modello dei dati mancanti per pandas tratta diversi valori (NaN (float), None, NaT (datetime), pd.NA (scalare nullo)) come valori mancanti. Ciò favorisce la flessibilità, ma può essere incoerente quando tipi di dati diversi gestiscono i dati mancanti in modo diverso. Quando si riempiono i valori mancanti, pandas potrebbe modificare il tipo di dati in modo imprevisto. La semantica ambigua dei valori nulli rende più difficile per pandas rilevare problemi di qualità dei dati.
Polars utilizza un unico valore mancante (null) e adotta lo stesso comportamento per tutti i tipi di dati, i quali ammettono valori null per default. Questo in genere produce un comportamento prevedibile e prestazioni migliori. Quando si riempiono i valori mancanti, Polars è esplicito e preserva il tipo di dato. La gestione coerente dei valori null di Polars di solito comporta meno errori di qualità dei dati.
Ci sono anche considerazioni da fare su come i diversi modelli di memoria influenzano le conversioni dei tipi di dati e l'interoperabilità. pandas storicamente si appoggia a NumPy (orientato alle righe, oggetti Python che possono contenere tipi di dati misti) mentre Polaris è colonnare nativo Arrow, il che lo rende più semplice da integrare nel resto dello stack di dati Python.
Ecco alcune best practice per mantenere l'integrità dei dati durante l'utilizzo di entrambe le librerie DataFrame:
- Per entrambe le librerie…
Imponi l'univocità e i vincoli chiave del database, come l'univocità della chiave primaria, la validità della chiave esterna e i conteggi/le partizioni di righe previsti. Convalida i join per evitare le esplosioni silenziose di righe. Usa trasformazioni coerenti e deterministiche: sono molto più facili da testare e riprodurre. Archivia i dati “source-of-truth” in Parquet con uno schema stabile per preservare i tipi. E non aspettare la fine per eseguire la convalida. Esegui la convalida nei punti chiave, come dopo l'acquisizione, dopo le trasformazioni principali e dopo la pubblicazione.
- Con pandas…
Imposta esplicitamente i tipi di dati al momento della lettura, ove possibile, e preferisci i tipi di dati che ammettono valori nulli come Int64, boolean, string o datetime64[ns] in modo che pandas non ripieghi su object. Normalizza presto i valori mancanti e fai attenzione a problemi silenti come NaN == Naan. Evita l'indicizzazione a catena e le operazioni per riga per la logica principale.
- Con Polars...
Definisci lo schema e i tipi di dati in modo esplicito e affidati alla tipizzazione rigorosa di Polars. Usa null in modo coerente e preferisci la gestione dei valori null basata su espressioni.
Transizioni di sintassi e API
- Differenze principali dell'API: concatenamento di Polars e operazioni di pandas
- Con Polars, in genere si costruisce un'unica pipeline concatenata basata su espressioni e, in modalità lazy, Polars può ottimizzare l'intera catena. In pandas, spesso si scrive una sequenza di istruzioni che mutano con il metodo eager (passo dopo passo).
- Esempi di codice affiancati: filtraggio, raggruppamento, aggregazioni
- Filtraggio e selezione (concatenamento)
- pandas
- Filtraggio e selezione (concatenamento)
result = pdf[pdf["country"] == "US"][["user_id", "revenue"]]
- Polars
result = (
pldf
.filter(pl.col("country") == "US")
.select(["user_id", "revenue"])
)
- Raggruppamento e aggregazione:
- pandas
rev_by_user = (
pdf
.groupby("user_id", as_index=False)["revenue"]
.sum()
)
- Polars
rev_by_user = (
pldf
.group_by("user_id")
.agg(pl.col("revenue").sum())
)
Fondamenti della sintassi di Polars:
Ci sono due concetti fondamentali per l'apprendimento di Polars: le espressioni e l'esecuzione lazy vs eager. Polars è costruito attorno alle espressioni, un calcolo per colonna (simile a SQL) che descrive ciò che si desidera calcolare e un motore che decide come calcolarlo in modo efficiente. Le espressioni non vengono eseguite immediatamente. Sono elementi costitutivi nella modalità di funzionamento "lazy", in cui le attività operative costruiscono un piano di query e le esecuzioni avvengono solo al momento della chiamata.
Al contrario, in modalità eager (comportamento di pandas), le attività operative vengono eseguite immediatamente, il che la rende ideale per l'esplorazione e il debug, ma rallenta per le pipeline su larga scala. Polars può offrire l'esecuzione eager per l'interattività e l'esecuzione lazy per pipeline ottimizzate su larga scala.
Conversione del codice Pandas esistente in Polars
La conversione solitamente significa:
- sostituisci l'indicizzazione per righe/colonne
df[...]con.filter()/.select() - sostituire l'assegnazione in-place con
.with_columns() - sostituisci
.apply()con espressioni native (ove possibile) - Considera la modalità lazy per ETL basati su file
Esempio di conversione:
Pandas originale:
df = pd.read_parquet("events.parquet")
df = df[df["country"] == "US"][["user_id", "revenue", "ts"]]
df["revenue"] = df["revenue"].fillna(0)
df["day"] = pd.to_datetime(df["ts"]).dt.date
)
out = (
df.groupby(["user_id", "day"], as_index=False)
.agg(total_revenue=("revenue", "sum"))
Polars lazy ottimizzato:
import polars as pl
out = (
pl.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id", "revenue", "ts"])
.with_columns([
pl.col("revenue").fill_null(0),
pl.col("ts").dt.date().alias("day"),
])
.group_by(["user_id", "day"])
.agg(pl.col("revenue").sum().alias("total_revenue"))
.collect()
)
Quando un team cambia libreria di dati (ad esempio, passando da pandas a Polars o aggiungendo Polars a pandas), la curva di apprendimento riguarda meno la sintassi e più la mentalità, i flussi di lavoro e la gestione del rischio. La mentalità di pandas è imperativa: procedere passo dopo passo, apportare modifiche man mano e ispezionare dopo ogni riga. La mentalità di Polars è dichiarativa, basata su espressioni, in cui si creano trasformazioni come pipeline con dati immutabili e si utilizza una pianificazione delle query simile a quella di SQL.
La sfida di apprendimento è iniziare a pensare per colonne e in modo dichiarativo, piuttosto che riga per riga. Le abitudini di debug e ispezione devono cambiare: bisogna pensare in termini di trasformazioni, non di stati.
Con Polars, la rigidezza dei tipi di dati può sembrare ostile quando impone la coerenza dello schema e fallisce rapidamente in caso di problemi con i tipi di dati, ma questi fallimenti prevengono bug silenziosi sulla qualità dei dati. La sfida è trattare gli errori sui tipi di dati come segnali sulla qualità dei dati, non come fastidi.
I team potrebbero anche percepire lacune negli strumenti quando passano a Polars, poiché quasi tutti gli strumenti dati di Python accettano pandas ed esiste un vasto ecosistema pandas con documentazione. Considera un approccio ibrido quando sono necessari strumenti legacy, concentrati su Polars per la preparazione di dati pesanti e su pandas per la modellazione e il plotting.
Esistono livelli di compatibilità API per riutilizzare codice DataFrame simile a pandas su Polars. Questi adattatori supportano gli stessi nomi/firme di metodo di pandas con comportamenti simili e possono tradurre le chiamate in operazioni native di Polars. Ma fai attenzione, un livello API non è una conversione, e può introdurre lacune semantiche e nascondere insidie a livello di prestazioni.
Ecco alcuni pattern di refactoring e strategie di migrazione comuni quando si passa da uno stack DataFrame a un altro.
Pattern di refactoring comuni (da pandas a Polars):
Sostituisci l'indicizzazione booleana con .filter() e .select()
- pandas
df2 = df[df["x"] > 0][["id", "x"]]
- Polars
df2 = df.filter(pl.col("x") > 0).select(["id", "x"])
Sostituisci la mutazione in-place con .with_columns()
- pandas
df["y"] = df["x"] * 2
- Polars
df = df.with_columns((pl.col("x") * 2).alias("y"))
Sostituisci np.where / assegnazione condizionale con when/then/otherwise
- pandas
df["tier"] = np.where(df["revenue"] >= 100, "high", "low")
- Polars
df = df.with_columns(
pl.when(pl.col("revenue") >= 100).then("high").otherwise("low").alias("tier")
)
- Riscrivi le aggregazioni groupby in .agg(...) basato su espressioni
- pandas
out = df.groupby("k", as_index=False).agg(total=("v","sum"), users=("id","nunique"))
- Polars
out = df.group_by("k").agg(
pl.col("v").sum().alias("total"),
pl.col("id").n_unique().alias("users"),
)
Preferisci le scansioni lazy per l'ETL basato su file
- pandas
df = pd.read_parquet("events.parquet")
- Polars
out = (
.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id","revenue"])
.group_by("user_id")
.agg(pl.col("revenue").sum().alias("rev"))
.collect()
)
Sostituisci .apply() con espressioni native (o isola le UDF)
- pandas
La maggior parte delle migrazioni di pandas si blocca su .apply(axis=1)
- Polars
Prova a esprimerlo con le espressioni Polars (str.*, dt.*, list.*, when/then).
Se inevitabile, isola una UDF in una piccola colonna/sottoinsieme e specifica return_dtype.
- Link interno: Programmazione Python (ancora: Python per l'analisi dei dati)
Il playbook sull'AI agentiva per l'enterprise

Integrazione e compatibilità dell'ecosistema
Polars e pandas sono progettati per funzionare insieme, ma si basano su modelli di esecuzione e di tipo diversi. L'interoperabilità esiste tramite punti di conversione espliciti, non interni condivisi. Poiché entrambe le librerie possono parlare Apache Arrow, Arrow può essere un livello di interoperabilità chiave, consentendo un trasferimento colonnare efficiente e una conservazione dello schema più pulita.
- Usa tabelle Parquet o Arrow come formato di interscambio
- Evita i CSV per i flussi di lavoro tra librerie
L'interoperabilità è esplicita e intenzionale. Non c'è un motore di esecuzione condiviso o una semantica degli indici. Non c'è inoltre alcuna garanzia di zero-copy. Verifica sempre.
Conversione di dati tra formati: to_pandas() e import polars:
- Da pandas a Polars
- Le colonne di pandas vengono convertite in tipi Polars compatibili con Arrow
- L'indice di pandas viene eliminato a meno che non lo si reset
- Le colonne di tipo object vengono ispezionate e forzate (spesso a Utf8 o a un errore)
- Best practice
- Chiamare
pd_df.reset_index()se l'indice è importante - Normalizzare prima i dtype:
- usa string, Int64, boolean
- evita colonne di oggetti di tipo misto
- Chiamare
- Da Polars a pandas
- Le colonne di Polars vengono convertite in pandas (spesso supportate da Arrow, se disponibile).
- Viene creato un RangeIndex default
- I valori null vengono mappati alle rappresentazioni dei valori mancanti di pandas
- Best practice
- Esegui la conversione una sola volta all'interfaccia, non ripetutamente
- Convalidare i dtype dopo la conversione (in particolare interi e valori nulli)
- Regola generale: converti ai confini del flusso di lavoro, non all'interno di loop o hot path.
Quando si esegue l'integrazione con librerie di visualizzazione e strumenti di plotting, la maggior parte delle librerie di plotting Python si aspetta di ricevere dati in formato pandas (o array NumPy). Polars si integra bene, ma spesso sarà necessario convertire i dati in formato pandas all'interfaccia di plotting, oppure passare direttamente array/colonne.
Per la connettività ai database e il supporto dei formati di file, pandas è ideale per le letture ad hoc e la compatibilità con l'ecosistema. Polars è ideale per file di grandi dimensioni, Parquet e analitiche incentrate sui file. Pandas supporta PostgreSQL, MySQL, SQL Server, Oracle, SQLite e qualsiasi database con un driver SQLAlchemy. Polars non è un client di database completo. Si aspetta che i dati arrivino come file o tabelle Arrow. Alcuni database e strumenti possono generare output direttamente in formato Arrow, che Polars può ingerire in modo efficiente.
Entrambi supportano il parsing dei file CSV. Polars è molto veloce con un sovraccarico di memoria inferiore, mentre pandas ha un parsing molto flessibile e gestisce bene i file CSV disordinati, ma il parsing tende a richiedere molta CPU e l'utilizzo della memoria può avere dei picchi.
Polars è superiore per Parquet. Pandas può leggere i file Parquet, ma le attività operative sono solo di tipo eager con pushdown limitato rispetto a Polars. Con l'esecuzione in streaming e un motore colonnare nativo Arrow, Polars può produrre risultati con un aumento della velocità di ordini di grandezza su set di dati di grandi dimensioni.
L'integrazione e la compatibilità con le librerie di machine learning (ML) sono uno dei fattori pratici più importanti quando si sceglie tra pandas e Polars o si utilizzano entrambi. La maggior parte delle librerie di ML si aspetta array NumPy (X: np.ndarray, y: np.ndarray), DataFrame/Series di pandas (comuni nei flussi di lavoro di sklearn) o Arrow. Molte librerie trattano pandas come il contenitore tabulare default. Quindi, se il tuo stack di ML è composto principalmente da sklearn e dal suo ecosistema, pandas rimane il percorso più agevole.
La maggior parte delle librerie di ML non accetta ancora direttamente i DataFrames di Polars come input di prima classe. Polars è ottimo per l'ingegneria delle feature, ma è necessario pianificare la conversione all'interfaccia. Si consiglia di eseguire la preparazione intensiva dei dati in Polars e di convertirli in pandas o NumPy per l'addestramento e l'inferenza del modello.
Ecco una rapida checklist per fornire dati al ML:
- Nessuna colonna a tipo misto
- Tutte le feature numeriche o codificate
- Gestione dei valori nulli (imputati/eliminati/modello che tiene conto dei valori mancanti)
- Ordine delle feature stabile
- Nomi delle feature conservati (se necessario)
- Validazione dello schema di addestramento/inferenza implementata
Considerazioni sulla produzione
Quando si spostano i carichi di lavoro pandas o Polars dai notebook alla produzione, i punti critici riguardano solitamente meno la sintassi e più il runtime, il packaging, la prevedibilità delle prestazioni e l'operabilità. Convalidare il comportamento entro i limiti effettivi di memoria/CPU della destinazione di deployment. Scegliere strategie come il column pruning, il filtraggio precoce e le scansioni in streaming/lazy per i carichi di lavoro basati su file.
Per il runtime e il packaging, assicurati che la versione di Python di produzione corrisponda a quella che testi localmente. Polars viene fornito con codice nativo (Rust) e pandas dipende da NumPy o da motori opzionali come PyArrow e fastparquet. Parquet/Arrow è solitamente la scelta migliore per la produzione, offrendo una migliore stabilità dello schema, letture più veloci e meno sorprese sui tipi di dati rispetto a CSV.
Polars utilizza il multi-threading per impostazione predefinita. Considera l'impostazione/controllo dell'utilizzo dei thread tramite la configurazione dell'ambiente in produzione. L'ottimizzazione lazy di Polars può migliorare il throughput, ma i lavori molto piccoli potrebbero riscontrare un overhead di pianificazione.
Le pipeline di produzione dovrebbero applicare esplicitamente le aspettative sui tipi di dati e sulla nullabilità (entrambe le librerie richiedono di asserire i vincoli). Aggiungere controlli intorno alle unioni per prevenire esplosioni silenziose di righe.
Per l'osservabilità, monitora il runtime, il conteggio delle righe, il conteggio dei valori null per le colonne chiave e le dimensioni dell'output per ogni esecuzione. Aggiungi controlli "stop-the-line" ai confini (prima di pubblicare gli output). E assicurati che gli errori emergano con un contesto utilizzabile (quale partizione/file/tabella, quale controllo non è riuscito).
Convalidare gli output (conteggio delle righe, aggregati, tassi di valori null) e i budget di prestazione (soglie di tempo/memoria). Eseguire i test in container che corrispondono al sistema operativo/glibc di produzione per evitare sorprese con le native wheel.
Strategie di migrazione pratiche
Strategie di migrazione per trasferire un team da pandas a Polars o per adottare Polars insieme a pandas:
- Strangler pattern: quando sono necessari un basso rischio e una continuous delivery, sostituisci un segmento alla volta con Polars mantenendo in esecuzione il vecchio pandas. Converti ai confini.
- Usa entrambi – Quando il collo di bottiglia è l'ETL/aggregazione ma a valle ti affidi a strumenti nativi di pandas, usa Polars per join di I/O, groupby e calcolo delle feature; converti il risultato finale in pandas per scikit-learn, plotting e librerie statistiche.
- Riscittura completa di una singola pipeline : quando si desidera una storia di successo chiara e pattern riutilizzabili, scegli una pipeline end-to-end e riscrivila completamente in Polars da usare come implementazione di riferimento interna.
- Parità della doppia esecuzione – Quando la correttezza è fondamentale, esegui le versioni di pandas e Polars affiancate per un certo periodo, confronta output, metriche e costi; passa alla nuova versione una volta dimostrata la parità.
Profilazione delle prestazioni – Per identificare opportunità di ottimizzazione, inizia a tracciare il tempo di esecuzione effettivo (wall time, quanto tempo attende un utente), il picco di memoria, il conteggio delle righe, il conteggio delle colonne e la correttezza dell'output. La maggior parte delle pipeline presenta colli di bottiglia in una delle seguenti aree: I/O, join, groupby, sort, analisi di stringhe o UDF Python. Aggiungi semplici timer intorno a queste fasi. Usa i profiler di pandas (Python) quando sospetti un lavoro a livello di Python e i profiler di Polars per ispezionare un piano di query lazy. Apporta una modifica mirata e riesegui lo stesso benchmark per confrontare.
Considerazioni sull'addestramento del team e sul trasferimento di conoscenze
L'obiettivo è avere successo senza ritardare la consegna o perdere la fiducia nei dati. Assicurati che il team comprenda le motivazioni e possa collegarle a risultati concreti, ovvero quali problemi stiamo risolvendo, quali carichi di lavoro ne traggono maggior beneficio e cosa non cambierà. Assegna la titolarità (responsabile della migrazione, revisori, decisori) per garantire la responsabilità.
Usa pipeline aziendali reali come esempi per renderli più pertinenti e favorirne l'adozione. Poiché Polars è più simile a SQL ma con la sintassi di Python, i cambiamenti più grandi sono a livello di approccio concettuale:
- Da imperativo a dichiarativo
- Da riga per riga a colonna per colonna
- Dallo stato mutabile alle pipeline immutabili
- Da esecuzione immediata a pianificazione ed esecuzione differite
Struttura l'addestramento a più livelli, in modo che i team si sentano produttivi fin da subito. Si potrebbe start con filtraggio, selezione e raggruppamento, prima di passare alle espressioni, alla gestione dei valori null e alle differenze tra i tipi di dati. Successivamente, affronta l'esecuzione lazy e l'ottimizzazione prima di passare ai pattern di migrazione e produzione. Stabilisci una fase ibrida con indicazioni chiare su per cosa è consentito l'uso di pandas, al fine di ridurre l'ansia. Per un trasferimento di conoscenze più rapido, affianca utenti esperti di Polars a utenti che utilizzano prevalentemente pandas.
Convalida pubblicamente la correttezza per creare fiducia, misurare e condividere i successi.
Domande frequenti
- Pandas è meglio di Polars? Nessuno dei due è universalmente migliore; la scelta dipende dai requisiti specifici del flusso di lavoro, dalle dimensioni del set di dati e dalle esigenze di prestazione.
- Cosa è meglio, Polars o pandas? Pandas eccelle per l'analisi interattiva e l'integrazione dell'ecosistema; Polars offre prestazioni migliori per le pipeline di produzione su larga scala.
- Polars è un sostituto di pandas? Polars integra pandas piuttosto che sostituirlo; entrambi servono efficacemente casi d'uso diversi.
- Vale la pena passare a Polars? Dipende dal fatto che si elaborino o meno set di dati di grandi dimensioni, in cui la modalità lazy e l'ottimizzazione delle query di Polars offrono vantaggi misurabili.
Conclusione
Nel decidere quale libreria DataFrame sia più adatta per i tuoi team, non esiste una risposta universale. In genere, pandas è più adatto per set di dati di piccole e medie dimensioni e per l'analisi esplorativa, mentre Polars, con la sua esecuzione lazy, è più adatto per prestazioni elevate su carichi di lavoro di grandi dimensioni (anche più grandi della memoria). A seconda dei tuoi casi d'uso, potresti finire per utilizzarli entrambi, quindi testa piccole porzioni per flussi di lavoro specifici con entrambe le librerie e valuta in base alle tue effettive attività di elaborazione dei dati.
I vostri team devono comprendere i punti di forza e di debolezza dello storage basato su colonne rispetto a quello basato su righe e le loro implicazioni per diversi modelli di query. Le differenze nell'API principale, nella sintassi, nel formato dei dati e nella connessione al database richiederanno una curva di apprendimento quando si passa da una libreria DataFrame all'altra.
Risorse per ulteriori approfondimenti e sperimentazioni:
Creazione di pipeline di dati scalabili
Elaborazione distribuita dei dati
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.