La Guida Definitiva del Professionista al Logging Scalabile
Standardizza e struttura il logging di production per i job Spark su Databricks, e ottieni di più dai tuoi log centralizzando i log dei cluster per l'ingestion e l'analisi.
di Zach King
- Best practice di livello production per un logging strutturato e pratico nei job Databricks.
- Centralizzazione dell'archiviazione dei log che scala e semplifica l'elaborazione.
- Creazione di una dashboard AI/BI per analizzare i log.
Introduzione: La Registrazione è Importante, Ecco Perché
Scalare da qualche decina di job a centinaia è una sfida per diverse ragioni, una delle quali è l'osservabilità. L'osservabilità è la capacità di comprendere il sistema analizzando componenti come log, metriche e tracce. Questo è altrettanto rilevante per i team di dati più piccoli con solo poche pipeline da monitorare, e motori di calcolo distribuiti come Spark possono essere difficili da monitorare, eseguire il debug e creare procedure di escalation mature in modo affidabile.
La registrazione è probabilmente la più semplice e di maggiore impatto di questi componenti di osservabilità. Fare clic e scorrere i log, un'esecuzione di job alla volta, non è scalabile. Può richiedere molto tempo, essere difficile da analizzare e spesso richiede competenze specifiche sul flusso di lavoro. Senza costruire standard di registrazione maturi nelle tue pipeline di dati, la risoluzione di errori o fallimenti di job richiede molto più tempo, portando a interruzioni costose, livelli di escalation inefficaci e affaticamento da alert.
In questo blog, ti guideremo attraverso:
- Passaggi per abbandonare le semplici istruzioni di stampa e impostare un framework di registrazione adeguato.
- Quando configurare i log log4j di Spark per utilizzare il formato JSON.
- Perché centralizzare l'archiviazione dei log dei cluster per un'analisi e una query semplici.
- Come creare una dashboard AI/BI centrale in Databricks che puoi impostare nel tuo workspace per un'analisi dei log più personalizzata.
Considerazioni Architettoniche Chiave
Le seguenti considerazioni sono importanti da tenere a mente per adattare queste raccomandazioni di registrazione alla tua organizzazione:
Librerie di Registrazione
- Esistono diverse librerie di registrazione sia per Python che per Scala. I nostri esempi utilizzano Log4j e il modulo standard Python logging.
- La configurazione per le librerie o i framework di registrazione sarà diversa, e dovresti consultare la loro documentazione rispettiva se utilizzi uno strumento non standard.
Tipi di Cluster
- Gli esempi in questo blog si concentreranno principalmente sui seguenti calcoli:
- Al momento della stesura, i seguenti tipi di calcolo hanno un supporto limitato per la consegna dei log, sebbene le raccomandazioni per i framework di registrazione siano ancora valide:
- Lakeflow Declarative Pipelines (precedentemente DLT): Supporta solo log degli eventi
- Serverless Jobs: Non supporta la consegna dei log
- Serverless Notebooks: Non supporta la consegna dei log
Governance dei Dati
- La governance dei dati dovrebbe estendersi ai log dei cluster, poiché i log potrebbero esporre accidentalmente dati sensibili. Ad esempio, quando scrivi log in una tabella, dovresti considerare quali utenti hanno accesso alla tabella e utilizzare un design di accesso basato sul privilegio minimo.
- Dimostreremo come consegnare i log dei cluster ai volumi di Unity Catalog per un controllo degli accessi e una lineage più semplici. La consegna dei log ai volumi è in Anteprima Pubblica ed è supportata solo su calcolo abilitato per Unity Catalog con modalità di accesso Standard o modalità di accesso Dedicata assegnata a un utente.
- Questa funzionalità non è supportata su calcolo con modalità di accesso Dedicata assegnata a un gruppo.
Suddivisione Tecnica della Soluzione
La standardizzazione è fondamentale per l'osservabilità dei log di livello production.. Idealmente, la soluzione dovrebbe accogliere centinaia o addirittura migliaia di job/pipeline/cluster.
Per l'implementazione completa di questa soluzione, visita questo repository qui: https://github.com/databricks-industry-solutions/watchtower
Creazione di un Volume per la consegna centralizzata dei log
Innanzitutto, possiamo creare un Volume di Unity Catalog per essere il nostro archivio file centrale per i log. Non raccomandiamo DBFS poiché non fornisce lo stesso livello di governance dei dati. Raccomandiamo di separare i log per ogni ambiente (ad es. dev, stage, prod) in directory o volumi diversi in modo che l'accesso possa essere controllato in modo più granulare.
Puoi crearlo nell'interfaccia utente, all'interno di un Databricks Asset Bundle (AWS | Azure | GCP), o nel nostro caso, con Terraform:
Assicurati di avere i permessi READ VOLUME e WRITE VOLUME sul volume (AWS | Azure | GCP).
Configurazione della consegna dei log del cluster
Ora che abbiamo un posto centrale dove mettere i nostri log, dobbiamo configurare i cluster per consegnare i loro log in questa destinazione. Per fare ciò, configura la consegna dei log del calcolo (AWS | Azure | GCP) sul cluster.
Ancora una volta, usa l'interfaccia utente, Terraform o un altro metodo preferito; useremo Databricks Asset Bundles (YAML):
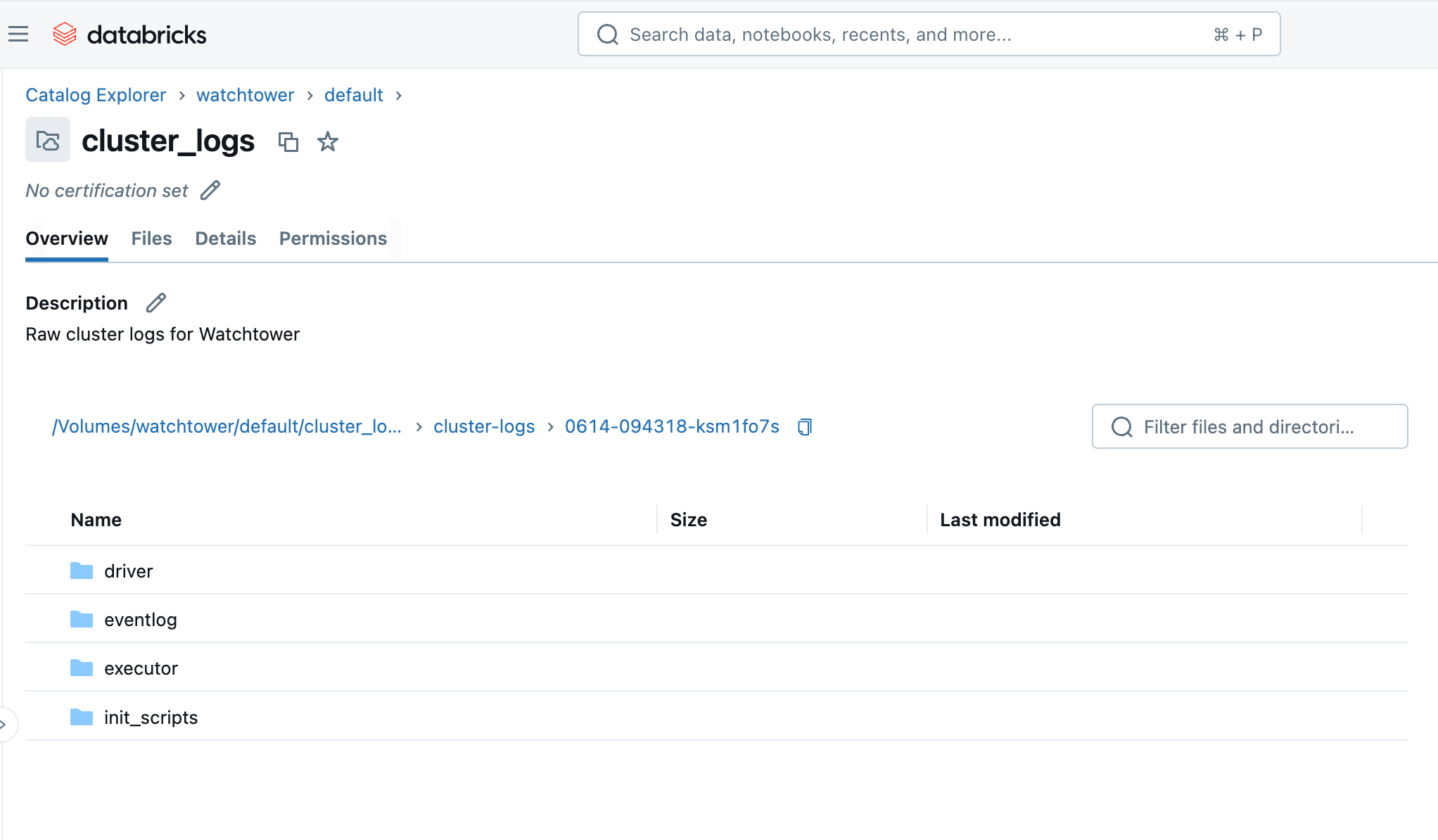
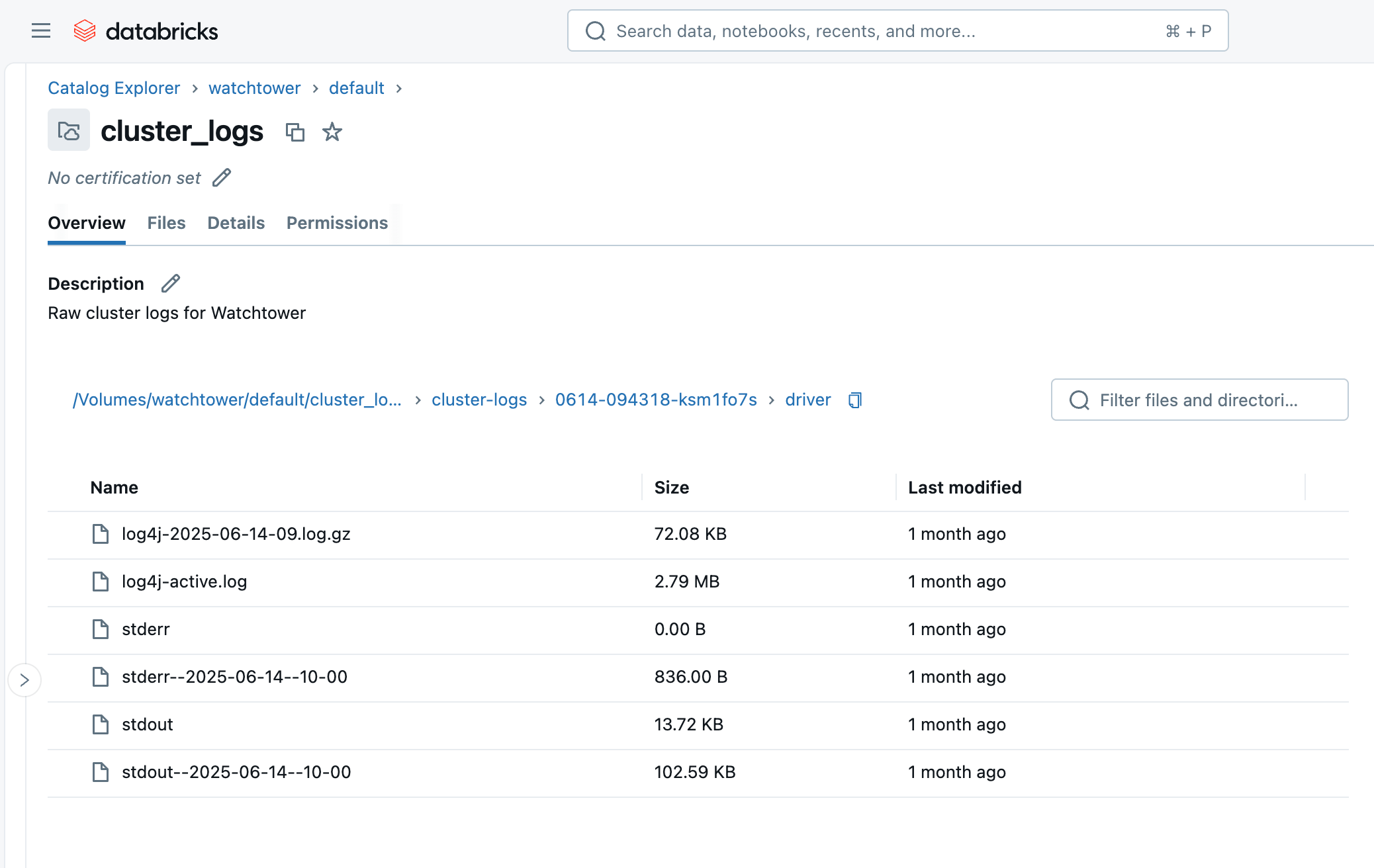
Dopo aver eseguito il cluster o il job, entro pochi minuti, possiamo navigare nel Volume nel Catalog Explorer e vedere i file arrivare. Vedrai una cartella con l'ID del cluster (ad es. 0614-174319-rbzrs7rq), quindi cartelle per ogni gruppo di log:
- driver: Log dal nodo Driver, a cui siamo più interessati.
- executor: Log da ogni Spark executor nel cluster.
- eventlog: log di eventi che puoi trovare nella scheda "Event Log" del cluster, come avvio del cluster, terminazione del cluster, ridimensionamento, ecc.
- init_scripts: Questa cartella viene generata se il cluster ha script di inizializzazione, come il nostro. Vengono create sottocartelle per ogni nodo nel cluster, e quindi stdout e stderr log possono essere trovati per ogni script di inizializzazione eseguito sul nodo.
Applicazione degli Standard: Cluster Policy
Gli amministratori del workspace dovrebbero applicare configurazioni standard quando possibile. Ciò significa limitare l'accesso alla creazione di cluster e fornire agli utenti una Cluster Policy (AWS | Azure | GCP) con la configurazione dei log del cluster impostata su valori fissi come mostrato di seguito:
Impostare questi attributi su un valore "fisso" configura automaticamente la destinazione corretta del Volume e impedisce agli utenti di dimenticare o modificare la proprietà.
Ora, invece di configurare esplicitamente il cluster_log_conf nel tuo file YAML del bundle di asset, possiamo semplicemente specificare l'ID della policy del cluster da utilizzare:
Più di una semplice istruzione print()
Sebbene le istruzioni print() possano essere utili per il debug rapido durante lo sviluppo, risultano inadeguate in ambienti di produzione per diversi motivi:
- Mancanza di struttura: Le istruzioni print() producono testo non strutturato, rendendo difficile l'analisi, l'interrogazione e l'elaborazione dei log su larga scala.
- Contesto limitato: Spesso mancano informazioni contestuali essenziali come timestamp, livelli di log (ad es. INFO, WARNING, ERROR), modulo di origine o ID del job, che sono cruciali per una risoluzione efficace dei problemi.
- Sovraccarico di prestazioni: Istruzioni print() eccessive possono introdurre un sovraccarico di prestazioni poiché attivano una valutazione in Spark. Le istruzioni print() scrivono anche direttamente sull'output standard (stdout) senza buffering o gestione ottimizzata.
- Nessun controllo sulla verbosità: Non esiste un meccanismo integrato per controllare la verbosità delle istruzioni print(), il che porta a log eccessivamente rumorosi o insufficienti nei dettagli.
Framework di logging appropriati, come Log4j per Scala/Java (JVM) o il modulo logging integrato per Python, risolvono tutti questi problemi e sono preferiti in produzione. Questi framework ci consentono di definire livelli di log o verbosità, produrre output in formati leggibili dalle macchine come JSON e impostare destinazioni flessibili.
Si noti inoltre la differenza tra stdout, stderr e log4j nei log del driver Spark:
- stdout: Buffer di output standard dalla JVM del nodo driver. È qui che vengono scritti per impostazione predefinita le istruzioni
print()e l'output generale. - stderr: Buffer di errore standard dalla JVM del nodo driver. È qui che vengono tipicamente scritte le eccezioni/stacktrace, e anche molte librerie di logging predefiniscono stderr.
- log4j: Filtrato specificamente per i messaggi di log scritti con un logger log4j. Potresti vedere questi messaggi anche in stderr.
Python
In Python, ciò comporta l'importazione del modulo di logging standard, la definizione di un formato JSON e l'impostazione del livello di log.
A partire da Spark 4, o Databricks Runtime 17.0+, un logger strutturato semplificato è integrato in PySpark: https://spark.apache.org/docs/latest/api/python/development/logger.html. L'esempio seguente può essere adattato a PySpark 4 scambiando l'istanza del logger con un'istanza di pyspark.logger.PySparkLogger.
Gran parte di questo codice serve solo a formattare i nostri messaggi di log Python come JSON. JSON è semi-strutturato e facile da leggere sia per gli esseri umani che per le macchine, cosa che apprezzeremo quando ingeriremo e interrogheremo questi log più avanti in questo blog. Se saltassimo questo passaggio, potresti ritrovarti a fare affidamento su espressioni regolari complesse e inefficienti per indovinare quale parte del messaggio sia il livello di log rispetto a un timestamp rispetto al messaggio, ecc.
Naturalmente, questo è piuttosto verboso da includere in ogni notebook o pacchetto Python. Per evitare duplicazioni, questo codice boilerplate può essere impacchettato come codice di utilità e caricato nei tuoi job in alcuni modi:
- Metti il codice boilerplate in un modulo Python sullo spazio di lavoro e usa le importazioni di file dello spazio di lavoro (AWS | Azure | GCP) per eseguire il codice all'inizio dei tuoi notebook principali.
- Compila il codice boilerplate in un file wheel Python e caricalo sui cluster come Libreria (AWS | Azure | GCP).
Scala
Gli stessi principi si applicano a Scala, ma useremo Log4j invece, o più specificamente, l'astrazione SLF4j:
Quando visualizziamo i Log del Driver nell'interfaccia utente, troviamo i nostri messaggi di log INFO e WARN sotto Log4j. Questo perché il livello di log predefinito è INFO, quindi i messaggi DEBUG e TRACE non vengono scritti.

I log Log4j non sono in formato JSON, però! Vedremo come risolvere questo problema la prossima volta.
Logging per Spark Structured Streaming
Per acquisire informazioni utili per i job di streaming, come metriche della sorgente e della destinazione di streaming e progressi della query, possiamo anche implementare StreamingQueryListener di Spark.
Quindi registra il listener di query con la tua sessione Spark:
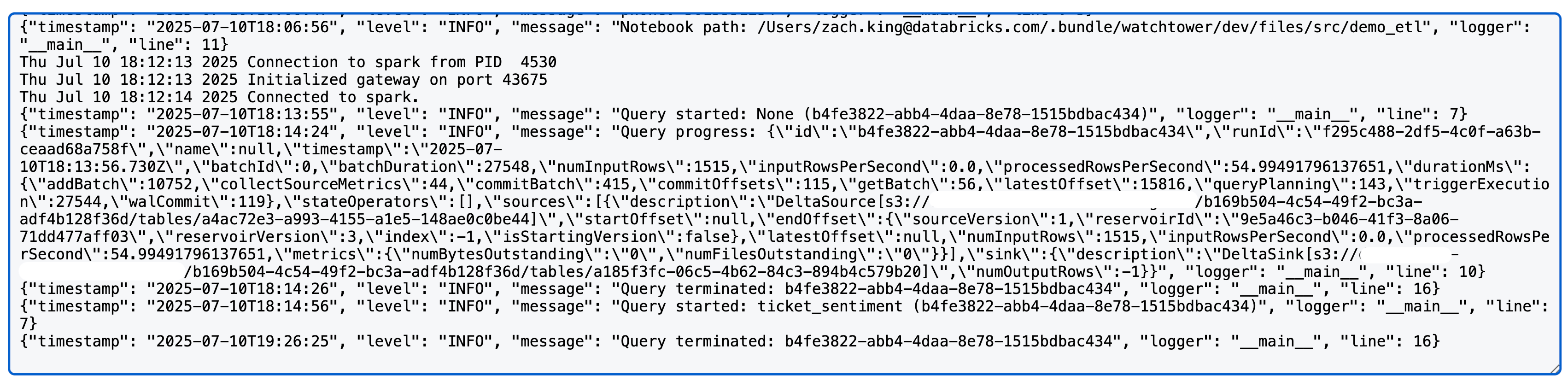
Eseguendo una query di streaming strutturato Spark, vedrai ora qualcosa di simile a quanto segue nei log log4j (nota: in questo caso utilizziamo una sorgente e una destinazione Delta; le metriche dettagliate possono variare a seconda della sorgente/destinazione):
Configurazione dei log Log4j di Spark
Fino ad ora, abbiamo influenzato solo il logging del nostro codice. Tuttavia, guardando i Log del Driver del cluster, possiamo vedere molti più log - la maggior parte, infatti - provengono dall'interno di Spark. Quando creiamo logger Python o Scala nel nostro codice, questo non influenza i log interni di Spark.
Ora esamineremo come configurare i log di Spark per il nodo Driver in modo che utilizzino un formato JSON standard che possiamo facilmente analizzare.
Log4j utilizza un file di configurazione locale per controllare la formattazione e i livelli di log, e possiamo modificare questa configurazione utilizzando uno Script di Inizializzazione del Cluster (AWS | Azure | GCP). Si noti che prima di DBR 11.0, veniva utilizzato Log4j v1.x, che utilizza un file Java Properties (log4j.properties). DBR 11.0+ utilizza Log4j v2.x che utilizza invece un file XML (log4j2.xml).
Il file log4j2.xml predefinito sui nodi driver Databricks utilizza un PatternLayout per un formato di log di base:
Cambieremo questo in JsonTemplateLayout usando il seguente script di inizializzazione:
Questo script di inizializzazione sostituisce semplicemente PatternLayout con JsonTemplateLayout. Nota che gli script di inizializzazione vengono eseguiti su tutti i nodi del cluster, inclusi i nodi worker; in questo esempio, stiamo configurando solo i log del driver per motivi di verbosità e perché ingeriremo solo i log del driver in seguito. Tuttavia, il file di configurazione può essere trovato anche sui nodi worker in /home/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties.
Puoi aggiungere a questo script secondo necessità, o cat $LOG4J2_PATH per visualizzare il contenuto completo del file originale per modifiche più semplici.
Successivamente, caricheremo questo script di inizializzazione nel volume di Unity Catalog. Per organizzazione, creeremo un volume separato invece di riutilizzare il nostro volume di log grezzi di prima, e questo può essere realizzato in Terraform in questo modo:
Questo creerà il Volume e caricherà automaticamente lo script di inizializzazione al suo interno.
Ma dobbiamo ancora configurare il nostro cluster per utilizzare questo script di inizializzazione. In precedenza, abbiamo utilizzato una Politica Cluster per applicare la destinazione di consegna dei log, e possiamo fare lo stesso tipo di applicazione per questo script di inizializzazione per garantire che i nostri log Spark abbiano sempre la formattazione JSON strutturata. Modificheremo il JSON della politica precedente aggiungendo quanto segue:
Ancora una volta, l'uso di un valore fisso qui garantisce che lo script di inizializzazione sarà sempre impostato sul cluster.
Ora, se rieseguiamo il nostro codice Spark precedente, possiamo vedere tutti i Log del Driver nella sezione Log4j formattati correttamente come JSON!
Ingestione dei log
A questo punto, abbiamo abbandonato le semplici istruzioni di stampa per il logging strutturato, lo abbiamo unificato con i log di Spark e abbiamo indirizzato i nostri log a un volume centrale. Questo è già utile per sfogliare e scaricare i file di log utilizzando Catalog Explorer o Databricks CLI: databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . --recursive.
Tuttavia, il vero valore di questo hub di logging si vede quando ingeriamo i log in una tabella Unity Catalog. Questo chiude il cerchio e ci fornisce una tabella su cui possiamo scrivere query espressive, eseguire aggregazioni e persino rilevare problemi di performance comuni. Tutto questo lo vedremo tra poco!
L'ingestione dei log è semplice grazie a Lakeflow Declarative Pipelines, e impiegheremo un'architettura a medaglione con Auto Loader per caricare i dati in modo incrementale.
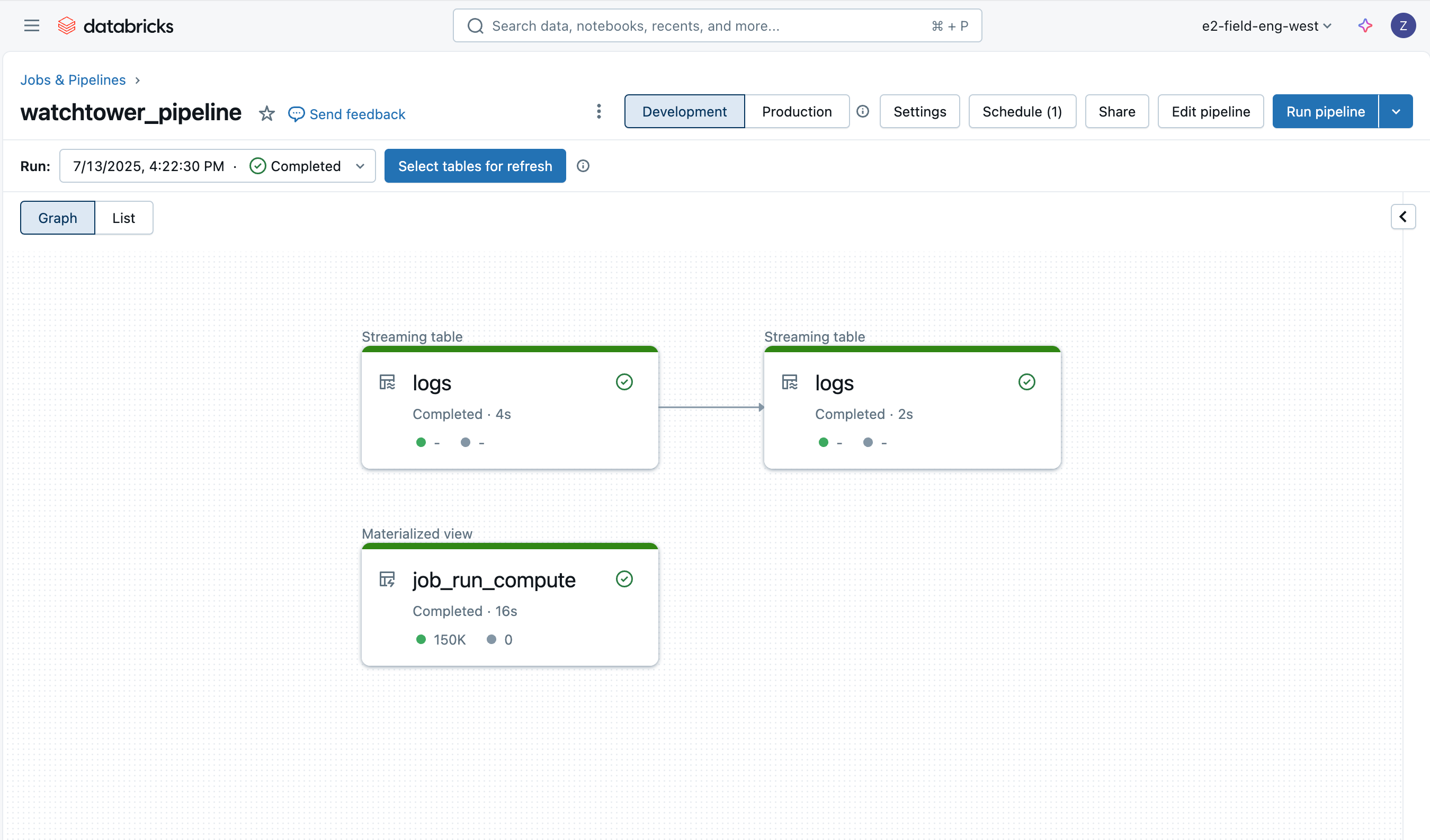
Log Bronze
La prima tabella è semplicemente una tabella bronze per caricare i dati grezzi dei log del driver, aggiungendo alcune colonne aggiuntive come il nome del file, la dimensione, il percorso e l'ora dell'ultima modifica.
Utilizzando le aspettative di Lakeflow Declarative Pipeline (AWS | Azure | GCP), otteniamo anche il monitoraggio nativo della qualità dei dati. Vedremo altri controlli di qualità dei dati sulle altre tabelle.
Log Silver
La tabella successiva (silver) è più critica; vorremmo analizzare ogni riga di testo dai log, estraendo informazioni come il livello del log, il timestamp del log, l'ID del cluster e la sorgente del log (stdout/stderr/log4j).
Nota: sebbene abbiamo configurato il logging JSON il più possibile, avremo sempre un certo grado di testo grezzo in forma non strutturata da altri strumenti avviati all'avvio. La maggior parte di questi sarà in stdout, e la nostra trasformazione silver dimostra un modo per mantenere l'analisi flessibile, tentando di analizzare il messaggio come JSON e ricorrendo al regex solo quando necessario.
ID di calcolo
L'ultima tabella nella nostra pipeline è una vista materializzata creata su Databricks System Tables. Memorizzerà gli ID di calcolo utilizzati da ogni esecuzione di job e semplificherà le future join quando vorremo recuperare l'ID del job che ha prodotto determinati log. Nota che un singolo job può avere più cluster, così come task SQL che vengono eseguiti su un warehouse anziché su un cluster di job, da qui l'utilità di pre-calcolare questo riferimento.
Distribuzione della Pipeline
La pipeline può essere distribuita tramite l'interfaccia utente, Terraform o all'interno del nostro asset bundle. Utilizzeremo l'asset bundle e forniremo il seguente YAML delle risorse:
Analizza i log con dashboard AI/BI
Infine, possiamo interrogare i dati dei log tra job, esecuzioni di job, cluster e workspace. Grazie alle ottimizzazioni delle tabelle gestite da Unity Catalog, queste query saranno anche veloci e scalabili. Vediamo un paio di esempi.
Top N Errori
Questa query trova gli errori più comuni riscontrati, aiutando a dare priorità e migliorare la gestione degli errori. Può anche essere un indicatore utile per scrivere runbook che coprano i problemi più comuni.
Top N Job per Errori
Questa query classifica i job in base al numero di errori osservati, aiutando a trovare i job più problematici.
Dashboard AI/BI
Se inseriamo queste query in una dashboard AI/BI di Databricks, avremo ora un'interfaccia centrale per cercare e filtrare tutti i log, rilevare problemi comuni e risolvere i problemi.
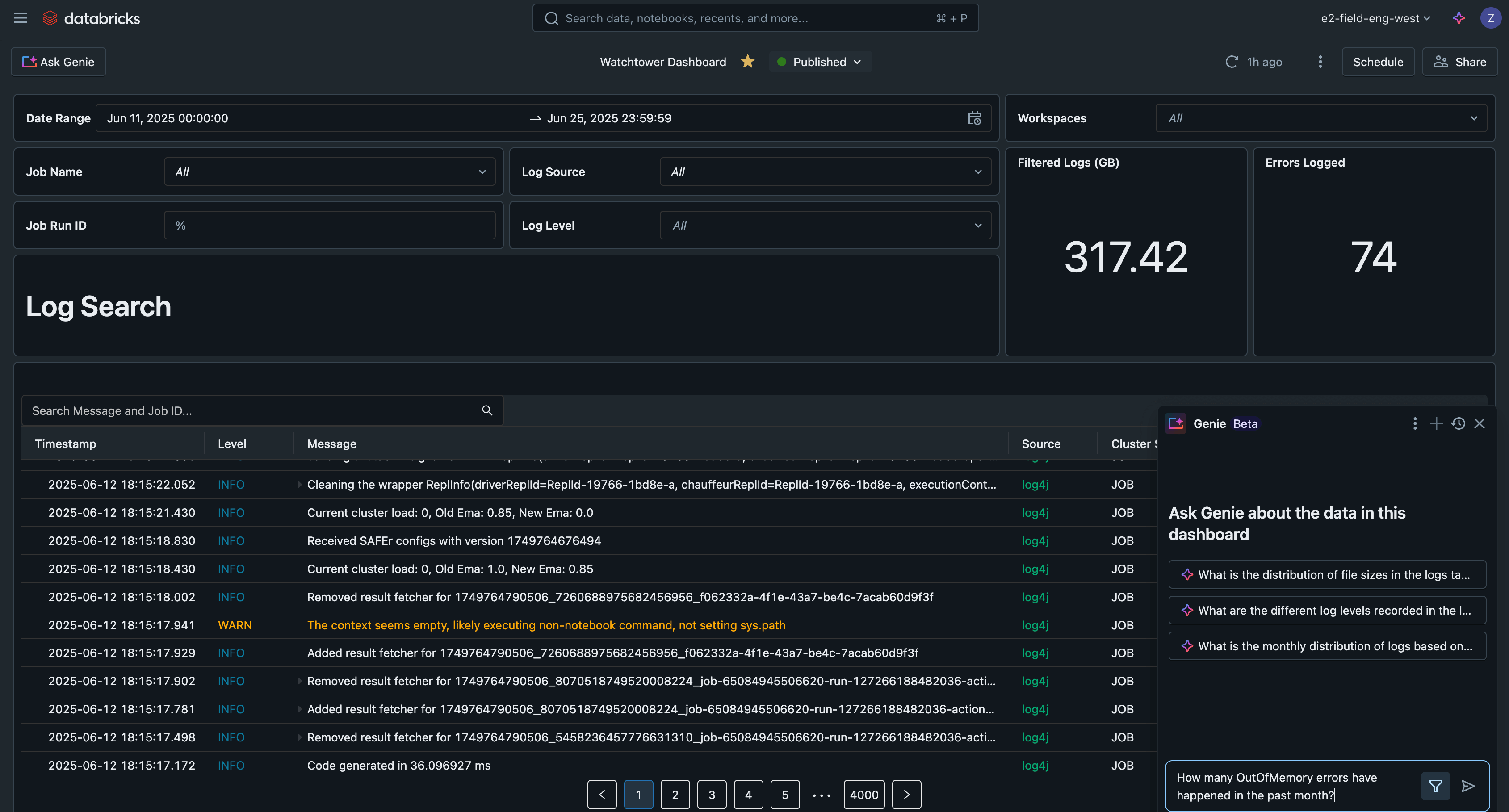
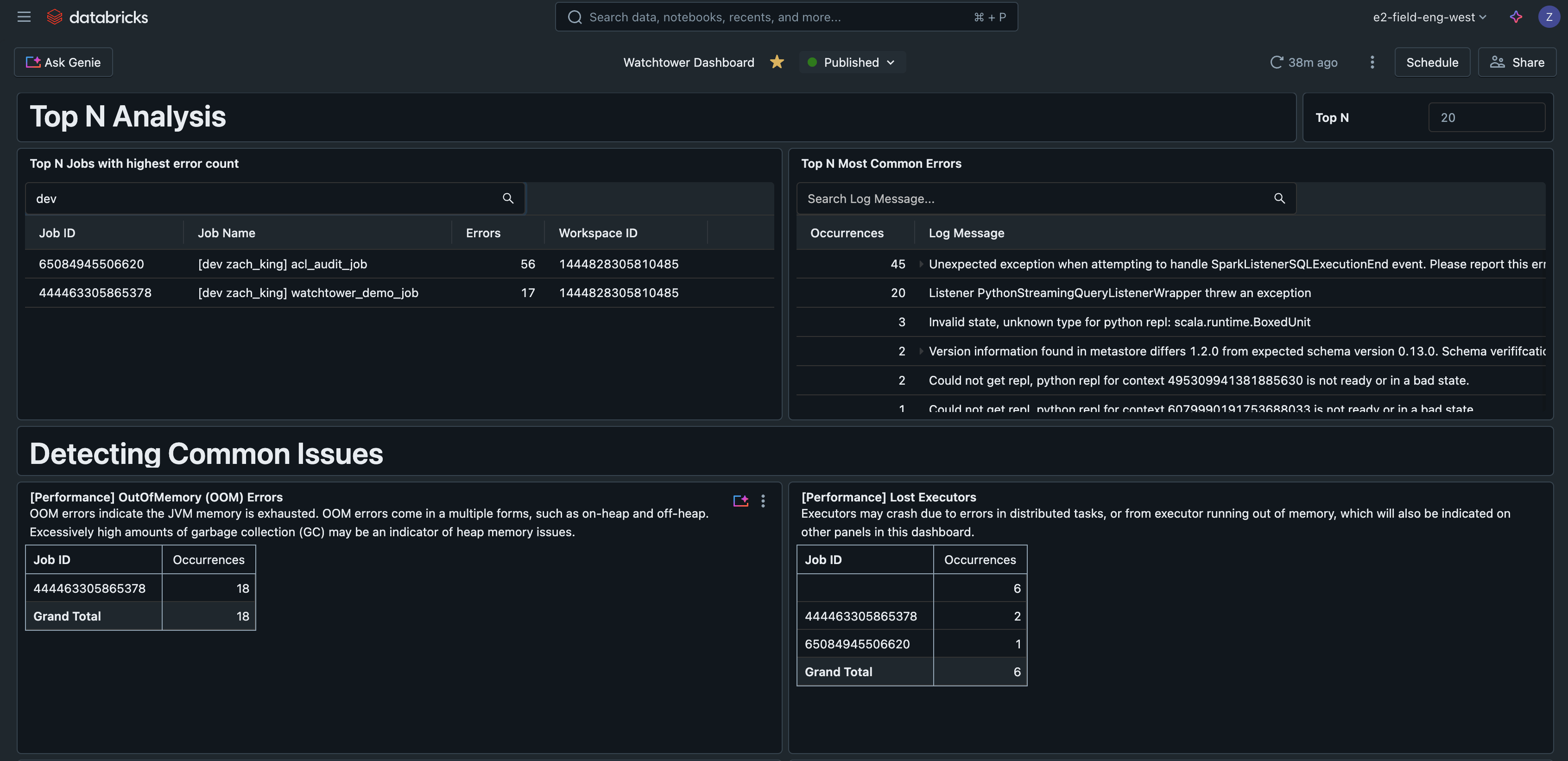
Questa dashboard AI/BI di esempio è disponibile insieme a tutto il resto del codice per questa soluzione su GitHub.
Scenari del Mondo Reale
Come abbiamo dimostrato nella dashboard di riferimento, ci sono molti casi d'uso pratici che una soluzione di logging come questa supporta, ad esempio:
- Ricerca di log in tutte le esecuzioni di un singolo job
- Ricerca di log in tutti i job
- Analisi dei log per gli errori più comuni
- Ricerca dei job con il maggior numero di errori
- Monitoraggio di problemi di performance o avvisi:
- GC Overhead
- Spark spill
- Rilevamento di PII nei log
In uno scenario realistico, i professionisti saltano manualmente da un'esecuzione di job all'altra per dare un senso agli errori e non sanno come dare priorità agli avvisi. Stabilendo non solo log robusti ma anche una tabella standard per memorizzarli, i professionisti possono semplicemente interrogare i log per l'errore più comune a cui dare priorità. Supponiamo che ci sia 1 esecuzione di job fallita a causa di un errore OutOfMemory, mentre ci sono 10 job falliti a causa di un improvviso errore di permessi quando SELECT è stato involontariamente revocato al service principal; il tuo team di reperibilità è normalmente affaticato dal picco di avvisi, ma ora è in grado di rendersi conto rapidamente che l'errore di permessi è una priorità più alta e inizia a lavorare per risolvere il problema al fine di ripristinare i 10 job.
Allo stesso modo, i professionisti hanno spesso bisogno di controllare i log di più esecuzioni dello stesso job per fare confronti. Un esempio reale è correlare i timestamp di un messaggio di log specifico da ogni esecuzione batch del job, con un'altra metrica o grafico (ad esempio, quando è stato registrato "batch completed" rispetto a un grafico del throughput delle richieste su un'API che hai chiamato). L'ingestione dei log semplifica questo, in modo che possiamo interrogare la tabella e filtrare per l'ID del job, e opzionalmente una lista di ID di esecuzione del job, senza dover fare clic su ogni esecuzione una alla volta.
Considerazioni Operative
- I log del cluster vengono recapitati ogni cinque minuti e compressi ogni ora nella destinazione scelta.
- Ricorda di utilizzare tabelle gestite da Unity Catalog con Predictive Optimization e Liquid Clustering per ottenere le migliori prestazioni sulle tabelle.
- I log grezzi non devono essere archiviati indefinitamente, che è il comportamento predefinito quando si utilizza la consegna dei log del cluster. Nella nostra pipeline Declarative Pipelines, utilizzare l'opzione Auto Loader
cloudFiles.cleanSourceper eliminare i file dopo un periodo di conservazione specificato, definito anche comecloudFiles.cleanSource.retentionDuration. È anche possibile utilizzare le regole del ciclo di vita dello storage cloud. - I log degli executor possono anche essere configurati e ingeriti, ma generalmente non sono necessari poiché la maggior parte degli errori viene comunque propagata al driver.
- Considera l'aggiunta di avvisi Databricks SQL (AWS | Azure | GCP) per l'allerta automatizzata basata sulla tabella dei log ingeriti.
- Le pipeline dichiarative di Lakeflow hanno i propri log degli eventi, che è possibile utilizzare per monitorare e ispezionare l'attività della pipeline. Questo log degli eventi può anche essere scritto in Unity Catalog.
Integrazione e Lavori da Fare
I clienti potrebbero anche voler integrare i loro log con strumenti di logging popolari come Loki, Logstash o AWS CloudWatch. Sebbene ognuno abbia i propri requisiti di autenticazione, configurazione e connettività, questi seguirebbero tutti uno schema molto simile utilizzando lo script di inizializzazione del cluster per configurare e spesso eseguire un agente di inoltro dei log.
Punti Chiave
Per riassumere, le lezioni chiave sono:
- Utilizzare framework di logging standardizzati, non istruzioni print, in produzione.
- Utilizzare script di inizializzazione a livello di cluster per personalizzare la configurazione di Log4j.
- Configurare la consegna dei log del cluster per centralizzare i log.
- Utilizzare tabelle gestite da Unity Catalog con Predictive Optimization e Liquid Clustering per le migliori prestazioni delle tabelle.
- Databricks ti consente di ingerire e arricchire i log per un'analisi più approfondita.
Passi Successivi
Inizia a mettere in produzione i tuoi log oggi stesso consultando il repository GitHub per questa soluzione completa qui: https://github.com/databricks-industry-solutions/watchtower!
I Delivery Solutions Architects (DSA) di Databricks accelerano le iniziative di Dati e AI nelle organizzazioni. Forniscono leadership architetturale, ottimizzano le piattaforme per costi e prestazioni, migliorano l'esperienza degli sviluppatori e guidano l'esecuzione di progetti di successo. I DSA colmano il divario tra l'implementazione iniziale e le soluzioni di livello di produzione, lavorando a stretto contatto con vari team, tra cui data engineering, lead tecnici, dirigenti e altri stakeholder per garantire soluzioni su misura e un valore più rapido. Per beneficiare di un piano di esecuzione personalizzato, guida strategica e supporto durante il tuo percorso di dati e AI da parte di un DSA, contatta il tuo Databricks Account Team.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.