Inferenza LLM affidabile su larga scala
Lezioni dalla costruzione di un'infrastruttura di inferenza LLM affidabile
di Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu e Arjun DCunha
- Il serving LLM multi-tenant richiede il ragionamento sulla capacità tra i carichi di lavoro. Le "unità modello" forniscono un'astrazione simile a una VM che consente di allocare, instradare e scalare le risorse GPU per cliente.
- Il bilanciamento del carico consapevole dei costi e l'autoscaling, basati sulle unità modello, hanno permesso di risparmiare oltre l'80% sui costi delle GPU rispetto al provisioning statico, mantenendo al contempo gli obiettivi di latenza.
- Meccanismi di affidabilità del runtime come i controlli di integrità black-box rilevano e recuperano automaticamente dai guasti silenziosi, mentre la profilazione dei colli di bottiglia multimodali ha sbloccato guadagni di throughput 3 volte superiori.
In Databricks, abbiamo creato una piattaforma di inferenza unica che supporta ogni modello all'avanguardia, dai modelli open source come Kimi e Qwen ai modelli proprietari come OpenAI, Gemini e Claude. Alimentiamo l'inferenza per alcune delle più grandi applicazioni agentive al mondo, tra cui Superhuman, Yipit Data, Fox Sports e altre. Oggi, gestiamo più di 120T token al mese.
Ciò che rende difficile l'inferenza LLM su larga scala è l'affidabilità. Poiché gli agenti stanno diventando l'interfaccia del nostro modo di lavorare e vivere, la domanda di inferenza sta crescendo esponenzialmente. Vediamo curve di domanda estremamente variabili che raggiungono il picco durante le ore lavorative.
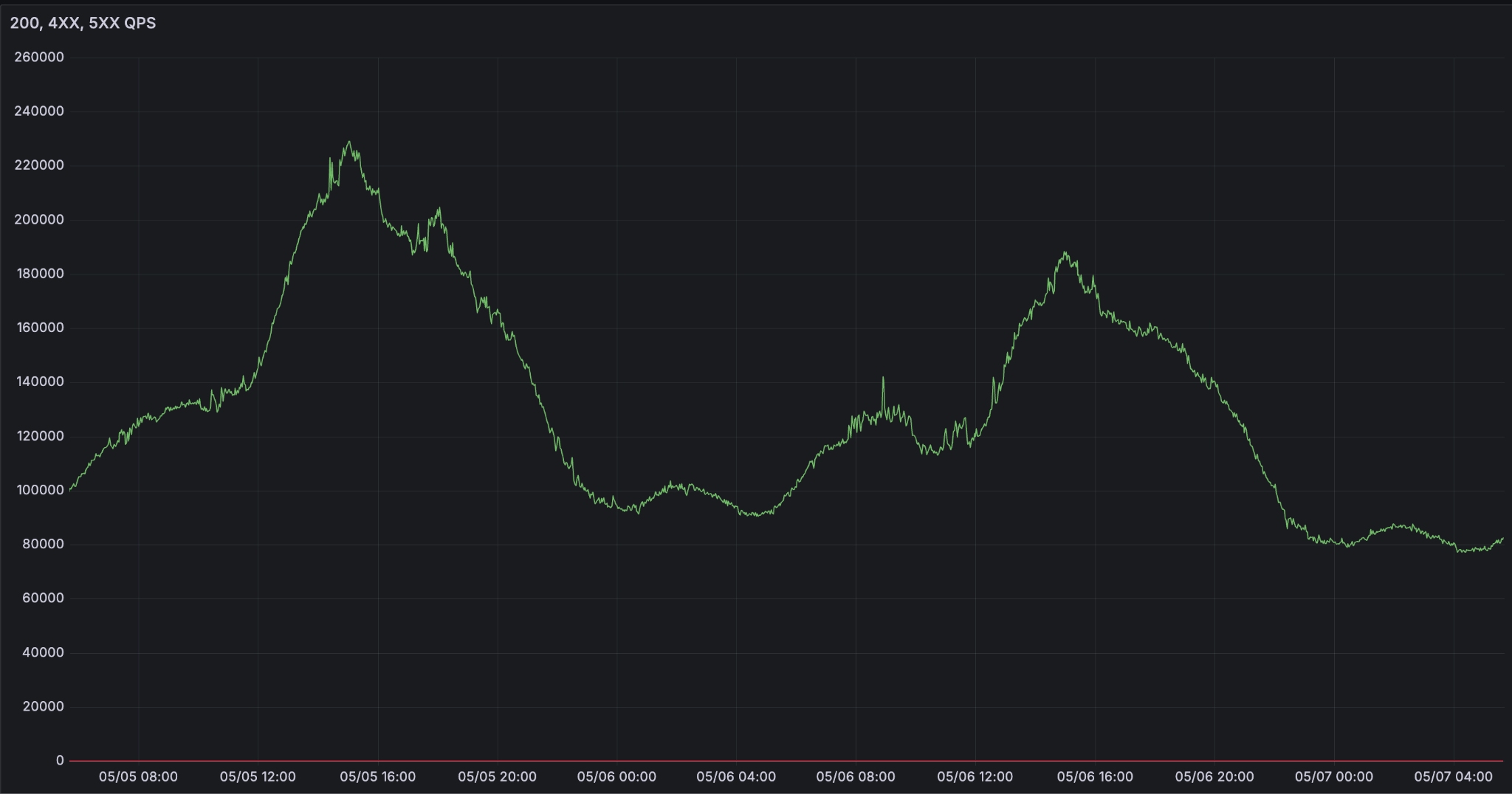
Sfide nell'esecuzione dell'inferenza LLM su larga scala
Cosa significa essere una piattaforma di inferenza affidabile? Il contratto sembra semplice. La disponibilità indica se la richiesta può essere elaborata. Ma, in pratica, casi d'uso diversi hanno requisiti di latenza significativamente diversi, e questo influisce sulla disponibilità. Gli agenti più avanzati non possono permettersi un degrado del tempo di primo token (TTFT) p95 e dei token di output al secondo (OPTS).
In un sistema multi-tenant per l'inferenza LLM, raggiungere sia affidabilità che bassa latenza è una sfida.
Affidabilità
Le prestazioni all'avanguardia richiedono le più recenti GPU con interconnessione ad alta larghezza di banda per il trasferimento della cache KV. Queste configurazioni di calcolo sono fondamentalmente meno affidabili dei sistemi CPU classici e sono costose. Dato che è necessaria una comunicazione all-to-all, il downtime di un singolo nodo richiede la riconfigurazione di molti altri nodi in configurazioni disaggregate di prefill/decode. La rete a larghezza di banda più elevata richiede una connettività single-spine in un singolo rack fisico (ad es. sistemi NVL72). Ciò significa che i guasti in specifici sistemi all'interno di un singolo rack del data center possono creare un'interruzione ad ampio raggio. Trucchi standard nei sistemi distribuiti come multi-AZ o l'utilizzo di tipi di istanze di backup significano mantenere costose GPU di backup inattive, un'opzione proibitiva in termini di costi. Il sovradimensionamento è un altro trucco classico, ma dato che l'offerta di calcolo è così limitata, è estremamente costoso e impraticabile. Pertanto, i sistemi devono rimanere operativi sotto forte stress.
Anche la velocità di rilascio deve rimanere elevata in queste condizioni: la nostra domanda di inferenza è cresciuta di diversi ordini di grandezza anno dopo anno, e alimentare questa crescita spedendo funzionalità innovative è stata una sfida. Funzionalità come immagini, video e classificazione della sicurezza richiedono ciascuna diversi sistemi di pre-elaborazione che devono scalare indipendentemente.
Infine, ottenere prestazioni migliori della concorrenza e supportare nuove architetture di modelli richiede ottimizzazioni che spaziano da kernel personalizzati a motori di inferenza proprietari. Man mano che le architetture cambiano sottilmente, spesso viene introdotto nuovo software di basso livello che può fallire in modi opachi su larga scala, manifestandosi in scenari di debug difficili che vanno da blocchi del server a crash della GPU.
Latenza
Mantenere la latenza sotto controllo con modelli di carico diversi è una sfida. Questo perché il costo per servire una richiesta è altamente variabile e difficile da stimare a priori. Anche server sani sotto carico più pesante elaborano tutte le richieste più lentamente, esponendo un compromesso tra throughput (e quindi efficienza dei costi) e la latenza più bassa necessaria ai prodotti per gestire. Questo può anche manifestarsi come un problema di affidabilità, poiché i server possono entrare in stati non sani inaspettatamente molto rapidamente in base al mix di richieste assegnate loro.
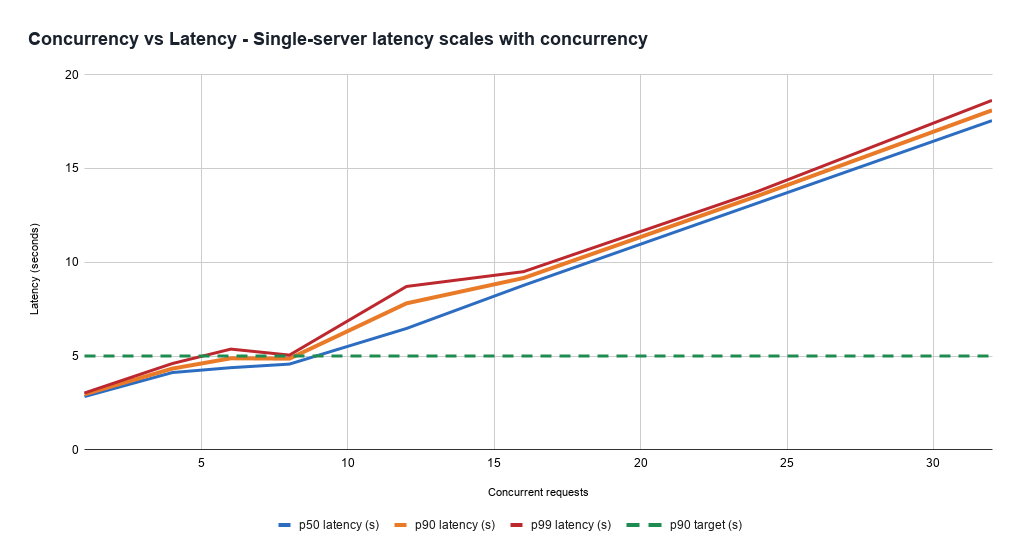
Inoltre, la latenza è dominata dalla generazione di token di output, ma la stima iniziale del costo è difficile, poiché è complicato prevedere quanto a lungo parlerà il modello. Pertanto, l'inferenza a bassa latenza richiede complessi sistemi di gestione della capacità, bilanciamento del carico e prioritizzazione delle richieste.
Architettura generale
Prima di approfondire i dettagli su come affrontare questi problemi, diamo una panoramica generale della nostra infrastruttura di inferenza.
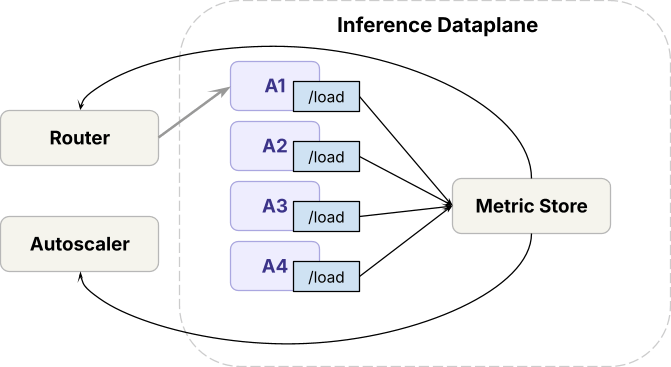
Nel data plane,
- L'inferenza runtime (motori open source e proprietari interni) è distribuita su GPU all'avanguardia
- Per gestire il traffico tra le distribuzioni dei modelli, il data plane esegue un router, che chiamiamo Axon, che bilancia il carico tra le repliche dello stesso modello, e un autoscaler che regola il numero di repliche.
Nel control plane,
- Le richieste passano attraverso il rate limiting prima di raggiungere il data plane.
- In base alle metriche delle richieste, l'algoritmo di gestione della capacità determina quanta capacità GPU ottiene ciascun workload, cosa che l'autoscaler poi applica.
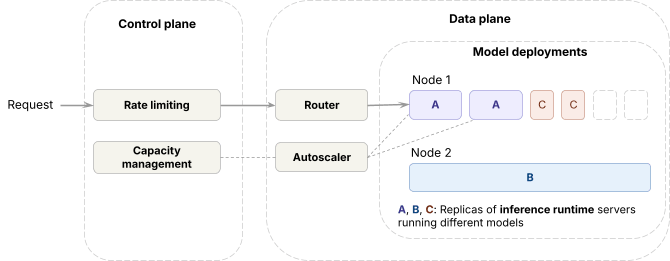
Gestire la capacità
Dobbiamo essere in grado di ragionare approssimativamente sulla capacità: quanta ne abbiamo, quanta ne abbiamo venduta e quanta ne stanno utilizzando i clienti. Per fare ciò, abbiamo introdotto un'astrazione chiamata "unità modello". Se proiettiamo che una replica può elaborare un numero fisso di unità modello al minuto (ad es. 100), possiamo fare le seguenti ipotesi:
- Le richieste con input o output lunghi consumano più unità modello, poiché ne possono completare meno nello stesso intervallo di tempo.
- Prefill e decode hanno caratteristiche di throughput diverse, quindi le richieste con output lungo costano di più di quelle con input lungo.
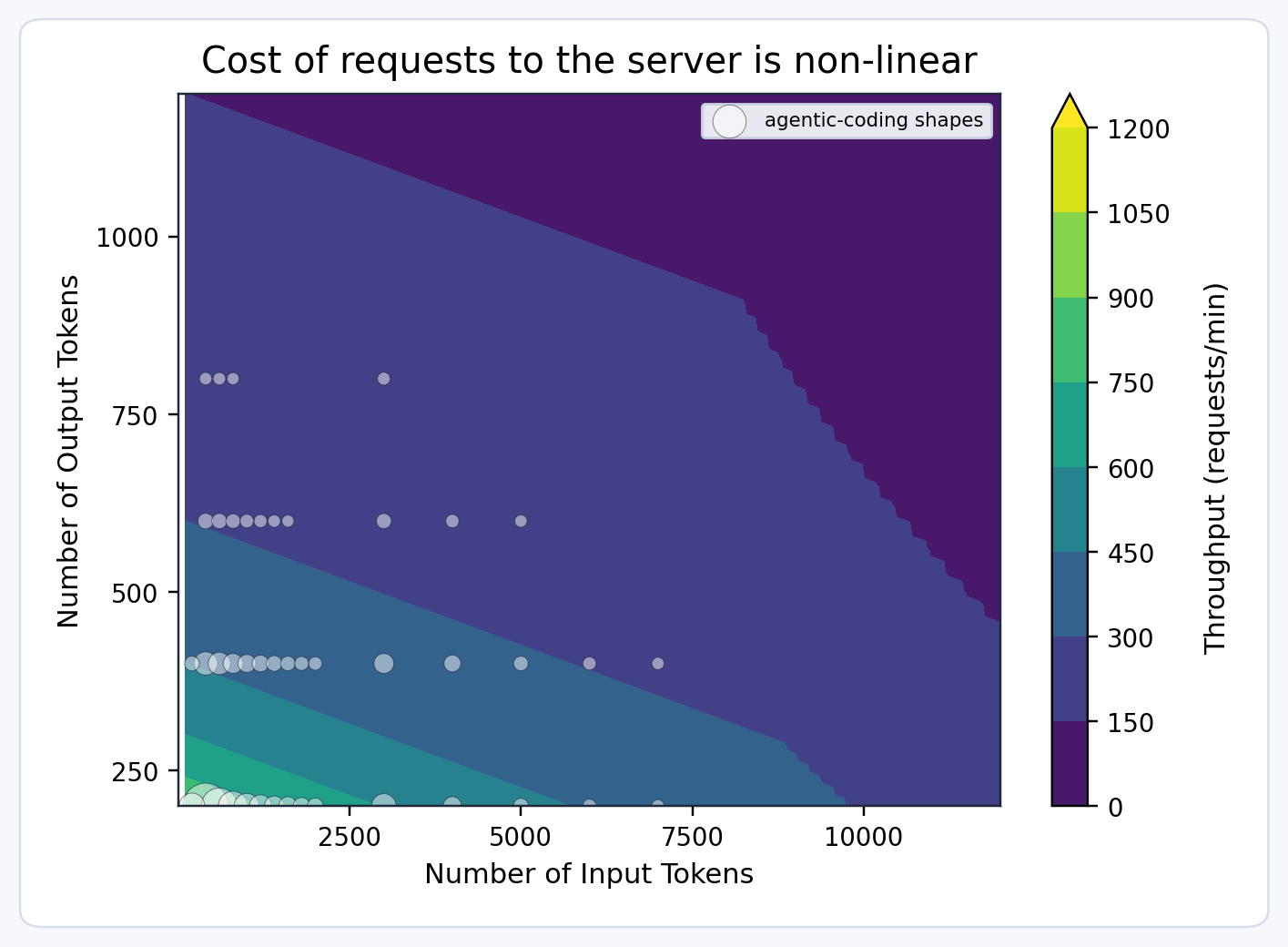
Pertanto, modelliamo il costo della richiesta utilizzando una funzione multidimensionale come:
I coefficienti α, β, γ sono determinati da benchmark automatizzati per ciascun modello su ciascun tipo di hardware. Le unità modello possono essere ulteriormente regolate per ottimizzazioni come la cache del prefisso, e devono tenere conto di funzionalità come la multimodalità.
Tali stime sono strutturalmente imperfette, ma servono come modo per scomporre un sistema multi-tenant in qualcosa di più gestibile che assomiglia alle VM cloud. Le VM hanno la proprietà desiderabile di offrire prestazioni prevedibili che possono essere allocate a clienti specifici. Per i carichi di lavoro agentivi di produzione, è importante offrire garanzie su bassa latenza e capacità, e senza tali sistemi di allocazione, il massimo che possiamo fare è offrire capacità "best-effort" che potrebbe essere ritirata se troppi clienti utilizzano il sistema.
Bilanciamento del carico e autoscaling basati sui costi
Poiché le richieste hanno un impatto altamente variabile sui server, è importante prendere decisioni di routing quasi ottimali. In generale, il bilanciamento del carico tende a basarsi su approcci statistici come P2C (power of two choices), che stimano il carico in base alla dimensione della coda e sfruttano il campionamento per ridurre gli overhead di memoria e latenza della comprensione di tutti i possibili target. Tuttavia, le latenze LLM tendono ad essere elevate, il numero di server è inferiore rispetto ai sistemi CPU scalati e il costo di un routing errato è grave. Pertanto, l'inferenza LLM richiede un approccio diverso.
Oggi, utilizziamo Dicer, l'auto-sharder di Databricks, per instradare dinamicamente i carichi di lavoro tra i server. Senza routing basato sul carico, le richieste a contesto lungo causano il surriscaldamento di singoli server mentre altri rimangono sottoutilizzati. Abbiamo integrato le unità modello con Dicer in modo che le decisioni di routing si basino sul carico del server in unità modello anziché su euristiche tradizionali basate sulle richieste. Dicer fornisce anche sessioni stateful, rendendo il routing delle richieste sticky. Le richieste di un workload vanno solo a un sottoinsieme di server, il che migliora i tassi di hit della cache (cruciale per carichi di lavoro sensibili alla latenza come gli agenti di codifica) e limita il raggio d'azione.
Possiamo anche ottimizzare le metriche di carico e persino utilizzare sistemi di routing più ottimali in futuro basati su metriche di costo ad alta fedeltà, man mano che impariamo di più.
Un problema simile esiste nell'autoscaling. I conteggi delle richieste in sospeso da soli non riflettono il carico reale. Un picco di richieste a lungo contesto appare identico a un picco di richieste brevi, e le metriche di CPU e memoria sono analogamente non correlate all'utilizzo effettivo della GPU.
Utilizzando le unità modello, il nostro autoscaler può decidere se aumentare o diminuire lo scaling in base al rapporto di utilizzo delle unità modello. Quando il motore di inferenza è in esecuzione vicino a una certa percentuale delle sue unità modello massime (determinate dal tipo di hardware e dalla forma del carico di lavoro), si avvicina alla massima produttività, il che innesca l'aumento dello scaling. Il contrario innesca la riduzione dello scaling. Invece di regolare manualmente le regole di autoscaling per ogni modello, questo approccio consente un'infrastruttura di scaling indipendente dal modello.
Costruire l'autoscaling sui pattern di inferenza LLM ci ha evitato di scalare sempre al massimo delle repliche. Per i modelli con traffico a raffica, l'autoscaling ha mantenuto i conteggi delle repliche vicini alla domanda effettiva, traducendosi in oltre l'80% di risparmio sulla GPU rispetto al provisioning statico al picco.
Affidabilità del Runtime
Il routing e lo scaling intelligenti hanno fornito una buona base, ma non prevengono i fallimenti a livello di motore. Indipendentemente dal motore di inferenza che implementiamo (il nostro motore interno o opzioni open-source popolari), emergono casi limite e contesa di risorse su scala di produzione. Abbiamo bisogno di meccanismi per rilevare e recuperare automaticamente dai fallimenti.
Rilevamento e recupero da fallimenti silenziosi
Una modalità di fallimento che incontriamo sono gli hang silenziosi. Le richieste che coinvolgono casi limite (output strutturato, input multimodali) possono innescare errori non gestiti nell'architettura multi-processo dei motori di inferenza, causando l'arresto della risposta dei server senza visualizzare errori.
Rileviamo questo con controlli di integrità black-box periodici: richieste end-to-end minime inviate quando nessuna richiesta reale è stata completata di recente. Se un controllo di integrità fallisce, la sonda di liveness di Kubernetes riavvia il server. Questo funziona su tutti i motori indipendentemente dall'implementazione interna.
Tuttavia, sotto carico elevato, i controlli di integrità stessi possono andare in timeout, causando alla sonda di liveness l'interruzione di server che sono effettivamente integri. Questo rischia fallimenti a cascata. Per risolvere questo problema, assegniamo alle richieste di controllo di integrità la massima priorità di scheduling, assicurando che vengano completate anche sotto carico pesante. Con controlli di integrità prioritari, l'intero ciclo di rilevamento di un hang, l'interruzione del server non integro e il recupero richiede meno di 5 minuti. I falsi fallimenti della sonda di liveness sono diminuiti da diversi alla settimana a zero.
Gestione del carico imprevisto da richieste multimodali
Quando sono arrivati grandi batch di richieste multimodali, abbiamo visto picchi nei tassi di errore e timeout da una fonte completamente diversa.
Le indagini hanno rivelato che le richieste non raggiungevano nemmeno i processi principali del motore di inferenza. L'elaborazione di richieste di immagini è più dispendiosa in termini di risorse rispetto alle richieste di solo testo, non solo per l'ulteriore codificatore di visione in esecuzione sulle GPU, ma anche per l'elaborazione di immagini intensiva per la CPU. Per alcuni modelli, l'elaborazione delle immagini era estremamente lenta, bloccando completamente il loop degli eventi.
Spostare le operazioni bloccanti in thread e processi separati non ha risolto il problema; le richieste si accumulavano ancora sotto carico elevato di immagini. Quindi abbiamo profilato i processi Python e fatto diverse scoperte:
- Tra tutte le operazioni CPU per le immagini, l'elaborazione delle immagini (ridimensionamento e normalizzazione) è 10 volte più lenta di altre operazioni come la decodifica base64.
- Alcuni modelli Hugging Face utilizzano per impostazione predefinita il processore di immagini basato su PIL, mentre altri utilizzano il processore basato su Torchvision più veloce.
- Negli ambienti containerizzati, OMP_NUM_THREADS (che controlla il numero di thread OpenMP utilizzati da Torch per le operazioni CPU) è impostato per impostazione predefinita sul numero di vCPU della macchina host. Nelle configurazioni multi-tenant, questo è un'impostazione predefinita scadente: un host potrebbe avere 192 vCPU, ma un container ha accesso solo a 12. Il risultato è un numero di thread in esecuzione molto superiore ai core disponibili. Questo porta l'utilizzo della CPU oltre il limite del container e innesca il throttling.
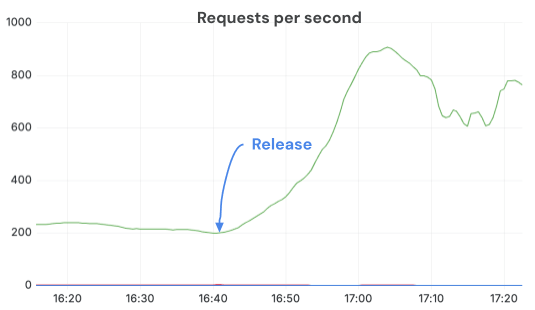
Passando ai processori di immagini basati su Torchvision e configurando correttamente OMP_NUM_THREADS, abbiamo sostenuto QPS molto più elevati e sfruttato appieno le GPU. Dopo la distribuzione della correzione, le richieste completate al secondo sono aumentate di oltre 3 volte con le stesse repliche e lo stesso carico. Il throttling della CPU è scomparso e i server hanno funzionato in uno stato molto più sano.
Conclusione
Servire LLM in modo affidabile su larga scala richiede lavoro in ogni livello dello stack di inferenza. Abbiamo trattato l'infrastruttura di autoscaling e load balancing progettata attorno ai carichi di lavoro LLM e i meccanismi di runtime che rimangono stabili indipendentemente dal motore o dal carico di lavoro. C'è molto di più nella storia: avvio rapido dei container, rollout sicuri su flotte di GPU, gestione della capacità delle GPU tra cloud e regioni. Se questi sono i tipi di problemi su cui vuoi lavorare, stiamo assumendo!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.